1. Introduction
With the advent of artificial intelligence and deep learning, automatic speech recognition (ASR) systems have made significant progress in tasks set in controlled environments. However, current automatic speech recognition systems have certain requirements for obtaining high recognition rates, such as test data being homogeneous with training data, a relatively quiet recording environment, a normal speech rate, and reading aloud. To compensate for the shortcomings of automatic speech recognition (ASR) in noisy situations and based on the human bimodal speech perception mechanism, some researchers have proposed a new approach to improving the robustness of ASR systems: combining visual signals with audio signals. Speech recognition based on audiovisual signals is called audiovisual speech recognition (AVSR). AVSR technique provides a good idea for the purpose of “natural language communication between human and machine” by simulating the human bimodal speech perception process based on visual information, such as lip movements. In addition, this technique can be combined with traditional robust speech-recognition techniques to further improve the performances of speech recognition systems.
Based on the multimodal complementary nature of AVSR, the AVSR model has a wide range of applications. For example, it can be applied in conference recording systems to enhance the transcription performance of conference recording systems through the recognition of lip movements by cameras; it can also be applied in command recognition in land vehicles [
1], cell-phone text translation [
2,
3,
4], lip reading for hearing-impaired people [
5], speech recognition of individual speakers who speak at once [
6], and so on.
In order to obtain a better-performing AVSR model, researchers have tried to make the model see as much as possible during the training phase. Therefore, a good dataset is very important. LRW (Lip Reading in the Wild), LRS2, and LRS3 are audio-visual speech recognition datasets collected from in-the-wild videos [
7,
8,
9].
In this article, we selected the three best-performing models for reproduction based on the audio-visual speech recognition on LRS3-TED leaderboard and the audio-visual speech recognition on LRS2 leaderboard. For the recurring models, we designed a series of experiments for comparison, and analyzed the advantages and disadvantages of each model based on the comparison results, providing effective support for later work.
Our work is described in detail in the following section.
Section 2 presents AVSR and Lip reading research results and related work are presented.
Section 3 presents the detailed definition of the AVSR task, the dataset description, and the experimental conditions.
Section 4 details the detailed rationale for the three models compared in this paper.
Section 5 presents the experiments related to the experimental results obtained and analyzes the advantages and disadvantages of the models based on the results.
Section 6 summarizes all the work described in this paper and presents an outlook for the future.
2. Related Work
In 2018, Stavros Petridis et al. [
10] proposed an end-to-end audiovisual model based on residual networks and bi-directional gated recurrent units (BGRU). It learns to extract features from both image pixels and audio waveforms, while also being able to identify words in context using a publicly available dataset (LRW). Its accuracy reached 83.39 percent. The first application of a transformer to the AVSR domain was made by Triantafyllos Afouras et al. in 2018 [
11]. Two lip reading models were compared. One using CTC (connectionist temporal classification) loss, and another using sequence-to-sequence loss, were constructed on the transformer self-attentive architecture. A new dataset, LRS2-BBC, which was created for audiovisual speech recognition and includes thousands of natural sentences from British television, was also constructed and released. Its model greatly exceeds the performance of all previous work on the lip-reading benchmark dataset. The LF-MIMI (Lip-reading for Multiple-Speaker Identification) time-delayed neural network (TDNN) word error rate (WER) absolute reduction proposed by Jianwei Yu et al. in 2020 [
12] outperformed the audio-only baseline, LF-MMI DNN, by up to 29.98 percent. The absolute performance of WER reduction was improved by 4.89 percent compared to the baseline AVSR system using feature fusion [
13]. A ResNet-18 and convolutional enhancement converter (conformer)-based hybrid CTC/attention model has been suggested. This model can be trained in an end-to-end manner. Audio and visual coders are capable of extracting features from original pixels and audio waveforms, respectively. These features are then fed to the conformer, which is fused using a multilayer perceptron (MLP). The model uses a combination of CTC and attention mechanisms to learn to recognize characters. The model achieved a good error rate of 3.7 percent of words. In 2022, Bowen Shi et al. [
14] proposed a self-supervised AVSR framework based on audiovisual HuBERT (AV-HuBERT), a state-of-the-art model for learning audiovisual speech representations. The model achieved an error rate of 1.4 percent and ranked first in performance on the largest available AVSR benchmark dataset, LRS3. In 2022, Xichen Pan et al. [
15] effectively implemented unimodal self-supervised learning to support multimodal AVSR. They trained audio and visual front-ends on a single-peaked dataset and then combined these components into a larger multimodal framework. This framework can recognize parallel audiovisual data as characters by adapting a combination of CTC and seq2seq decoding. The results indicate that the two inherited components from unimodal self-supervised learning function well together and can produce impressive outcomes by fine-tuning the multimodal framework. The model achieved an excellent error word rate of 2.6 percent on the LRS2 dataset. By far, the model performed better than others on the LRS2 dataset.
Lip reading is one of the most popular methods for visual speech recognition. The main implementation method is to extract the lips of the speaker in the video by frame, arrange the frames in temporal order, and input them into an artificial neural network. Many researchers have been trying various methods to increase the accuracy of lip reading. In 2017, Themos Stafylakis et al. [
16] created a deep learning architecture that functions end-to-end and is intended for visual speech recognition at the word level. It is a combination of spatio-temporal convolution, residuals, and bidirectional long and short-term memory networks. The system achieved an accuracy of 83 percent. In 2020, Peratham W. [
17] proposed a novel deep learning architecture called SpotFast for lip reading at the word level. SpotFast is a modified version of the advanced SlowFast network designed for action recognition. It utilizes time windows as point paths and fast paths that include all frames. In combination with the memory-enhanced transversal transformer, SpotFast’s accuracy was improved by 3.7 percent. The final score was 84.4 percent. In 2022, Dalu Feng et al. [
18] obtained a good score of 88.4 percent using 3D-ResNet and Bi-GRU networks for modeling, along with MixUp for data enhancement. The same year, Pingchuan Ma et al. [
19] stated that a sequence of research studies have proven that temporal masking (TM) is the most crucial method for enhancing data, followed by MixUp. Meanwhile, the densely connected temporal convolutional network (DC-TCN) is the most effective model for isolated word lip reading. Self distillation and word boundary indicators also contribute to an improvement in performance, albeit to a lesser extent. Using all the above-mentioned methods together resulted in a classification accuracy of 93.4 percent, improving the current state-of-the-art performance on the LRW dataset by 4.6 percent.
There are six SOTA approaches for lip-reading recognition on the LRW dataset that have been able to achieve more than 88% accuracy [
20]. The first model is Vosk + MediaPipe + LS + MixUp + SA + 3DResNet-18 + BiLSTM + Cosine WR, which is able to achieve 88.7% accuracy, In 2022, Koumparoulis et al. [
21] showed that 3D Conv + EfficientNetV2 + Transformer + TCN can reach 89.52% accuracy, and in the same year, Pingchuan Ma et al. [
19] reported that 3D Conv + ResNet-18 + DC-TCN + KD can achieve the best current accuracy of 94.1%. One SOTA method has only two models and achieved a less than 20% error rate on the LRS2 dataset. In 2022, Haliassos et al. [
22] proposed RAVEn Large WER, which had an error rate of 18.6%. In 2023, Pingchuan Ma et al. [
23] proposed CTC/attention WER, which was able to reach a current-best error rate of 14.6%. Haliassos et al. [
22] showed that their WER of RAVEn Large model could reach an error rate of 23.4%, and in the same year, Pingchuan Ma et al. [
23] showed that the WER of CTC/attention model could reach a current-best error rate of 19.1%.
3. Audiovisual Speech Recognition
3.1. Problem Statement
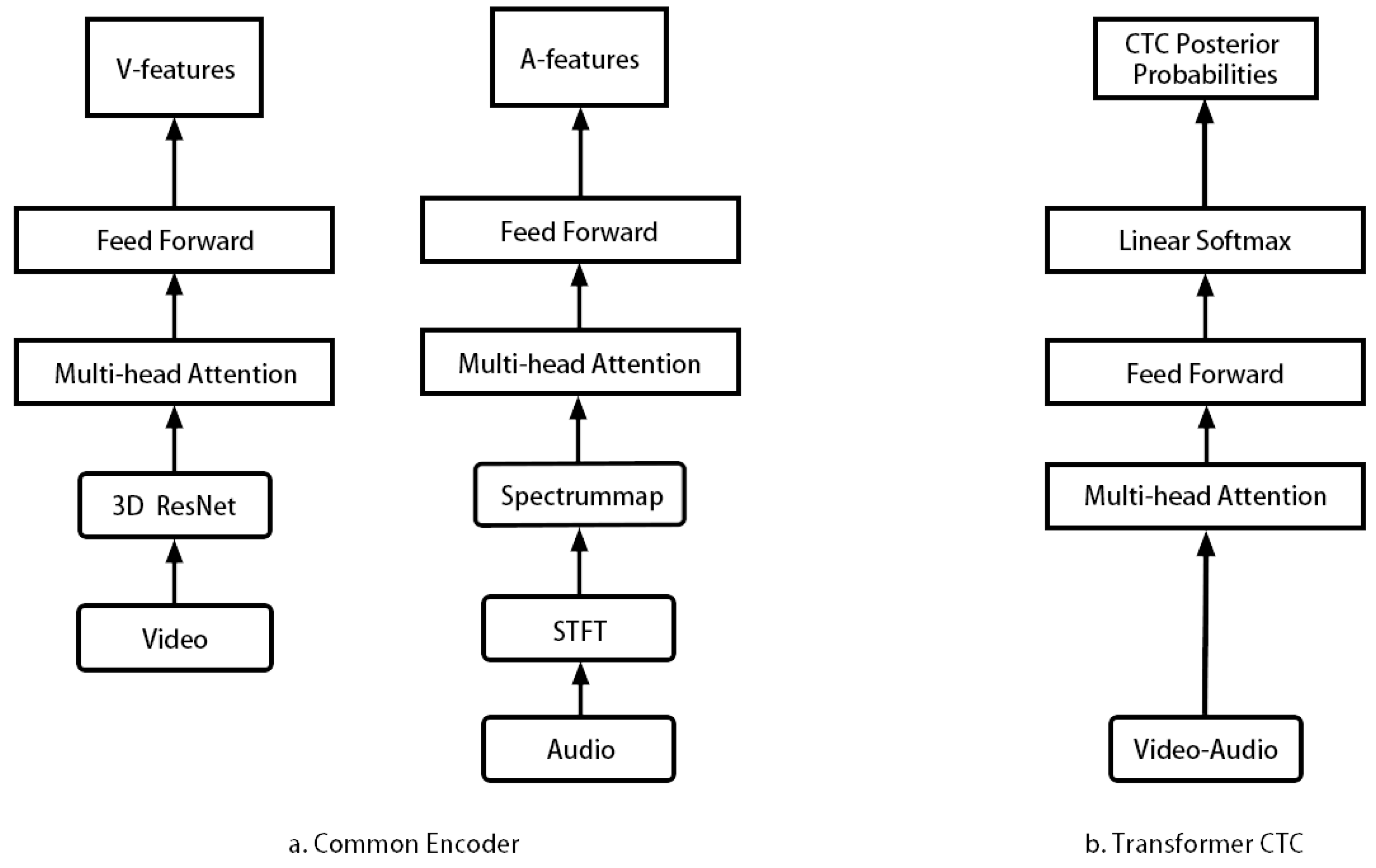
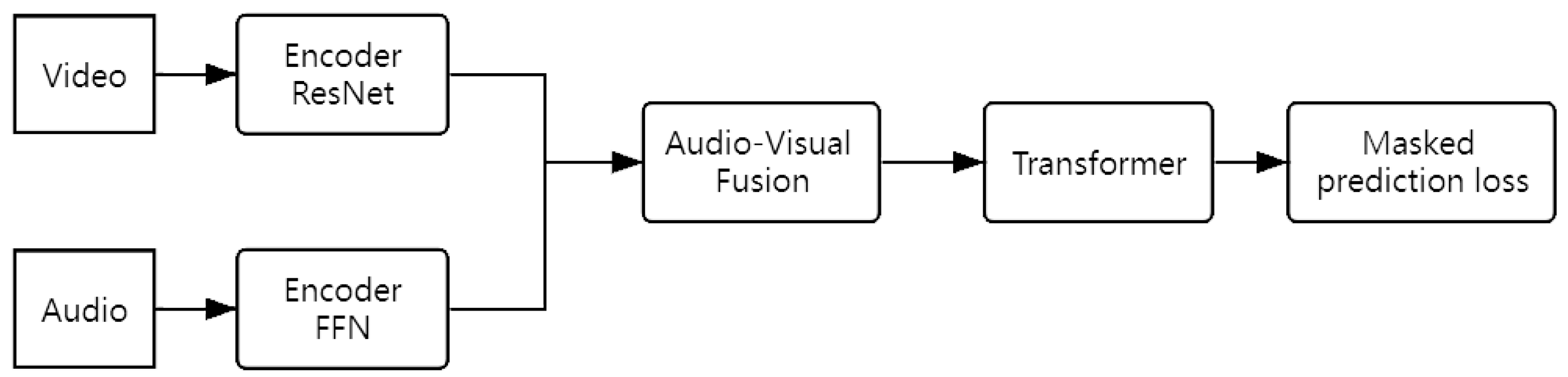
AVSR technology provides a good idea for realizing “human–machine natural language communication” by simulating the human bimodal speech perception process based on visual information such as lip movement. The model captures feature information simultaneously through visual signals and audio signals, and recognizes the speaker’s speech content based on this feature information. The detailed mathematical definition of the problem is given below: represents a data set with n samples, where represents the ith video sample and represents the label corresponding to the video sample.
After the original data are preprocessed, the original video sample is divided into audio samples and image samples according to a certain strategy: . In the fusion stage of the multimodal model, for the early fusion strategy, the audio samples and image samples are first combined and then fed to the feature extractor for feature extraction . For the late fusion strategy, first, the audio samples and image samples are fed to the corresponding encoder to obtain the corresponding feature f—, —and then we merge the two features: . After feature fusion, the fused feature is fed into the to realize speech recognition: .
3.2. Description of Datasets
The audio-visual speech recognition datasets, LRW [
7], LRS2 [
8], and LRS3 [
9], have been gathered from videos recorded in natural settings.
3.2.1. Lip Reading in the Wild (LRW)
The dataset is composed of 1000 utterances of 500 unique words, spoken by several speakers. Each video in the dataset is 29 frames long, which is equivalent to 1.16 s. The word is spoken in the middle of the video. The metadata contain the duration of the word, providing information on the start and end frames of the word. The dataset statistics are given in
Table 1.
3.2.2. Lip Reading Sentences 2 (LRS2)
The BBC television dataset comprises numerous spoken sentences. Each sentence has a length of up to 100 characters. The training, validation, and test sets are categorized based on the date of the broadcast. The dataset’s details are outlined in the provided table.
The LRS2-BBC dataset is partitioned into two groups: the development set, which includes the train and validation sets based on the broadcast date, and the test set. This dataset also possesses a “pre-train” subset, containing sentence excerpts that may differ in length from those included in the development set. These excerpts are marked with the alignment boundaries of each word. The pre-training set comprises partial sentences and multiple sentences, and the training set only includes complete single sentences or phrases. Additionally, there is some intersection between the pre-training and training sets.
The LRS2 dataset is made up of 144,482 video clips sourced from multiple BBC programs, totaling up to 224.1 h of content. Within the dataset, there are four distinct groups of utterances. The pre-training group contains 96,318 utterances, which covers 195 h of content. The training group contains 45,839 utterances, which spans 28 h of content. The validation group comprises 1082 utterances and takes up 0.6 h of content, whereas the testing group contains 1243 utterances and spans 0.5 h of content.
It is possible that there could be some inaccuracies in the labeling of both the pre-training and training sets. However, the test set has been thoroughly inspected and confirmed to be accurate, based on our current understanding. As a result, we believe that the test set does not contain any mistakes. The dataset’s statistics are given in
Table 2.
3.2.3. Lip Reading Sentences 3 (LRS3)
This dataset comprises over 400 h of video content, taken from 5594 TED and TEDx talks in English, which were downloaded from YouTube. The dataset contains cropped face tracks in MP4 format, which have a resolution of 224 × 224 and are encoded with the h264 codec at a frame rate of 25 fps. Audio tracks are also included in a single-channel 16-bit 16 kHz format. Furthermore, the dataset includes plain text files containing the corresponding text transcripts of every word and alignment boundaries. The dataset is sorted into three categories: pre-train, train-val, and test. The first two categories share some content, and the last category is entirely separate. The dataset statistics are given in
Table 3. The LRS3 dataset is twice the size of LRS2, and it contains 151,819 utterances, equaling 438.9 h of content. Precisely, the pre-training group comprises 118,516 utterances accounting for 408 h, and the training–validation group consists of 31,982 utterances for 30 h of content. Lastly, the test group contains 1321 utterances and spans 0.9 h of content.
5. Experiment
In this section, we design a series of experiments that reproduce each of the four excellent models mentioned in
Section 3, and we experimented with them in a comprehensive manner.
5.1. Hardware Resources
The composition of the computing resources used in the experiment was as follows: Intel(R) Xeon(R) Gold 6134 CPU @ 3.20 GHz, GPU-Tesla V100 16 GB*2, SSD—5TB, OS—CentOS 6.0.
5.2. Input Features
For audio input, we used a spectral size of 321 dimensions, computed using a 40 ms window with a 10 ms jump length, and a 16 kHz sample rate. Since the sampling rate of the video is 25 frames (40 ms per frame), each video input frame corresponds to 4 acoustic feature frames. We concatenated audio features into groups of 4 to reduce the length of the input sequence while achieving a common time scale for both modalities [
8].
For every video, we utilized dlib to identify and monitor 68 specific features on the face. The input image was 224 × 224 pixels, sampled at 25 frames/s, and contained the speaker’s face. We cropped a 112 × 112 patch covering the area around the mouth, as shown in
Figure 7.
5.3. Model Setup
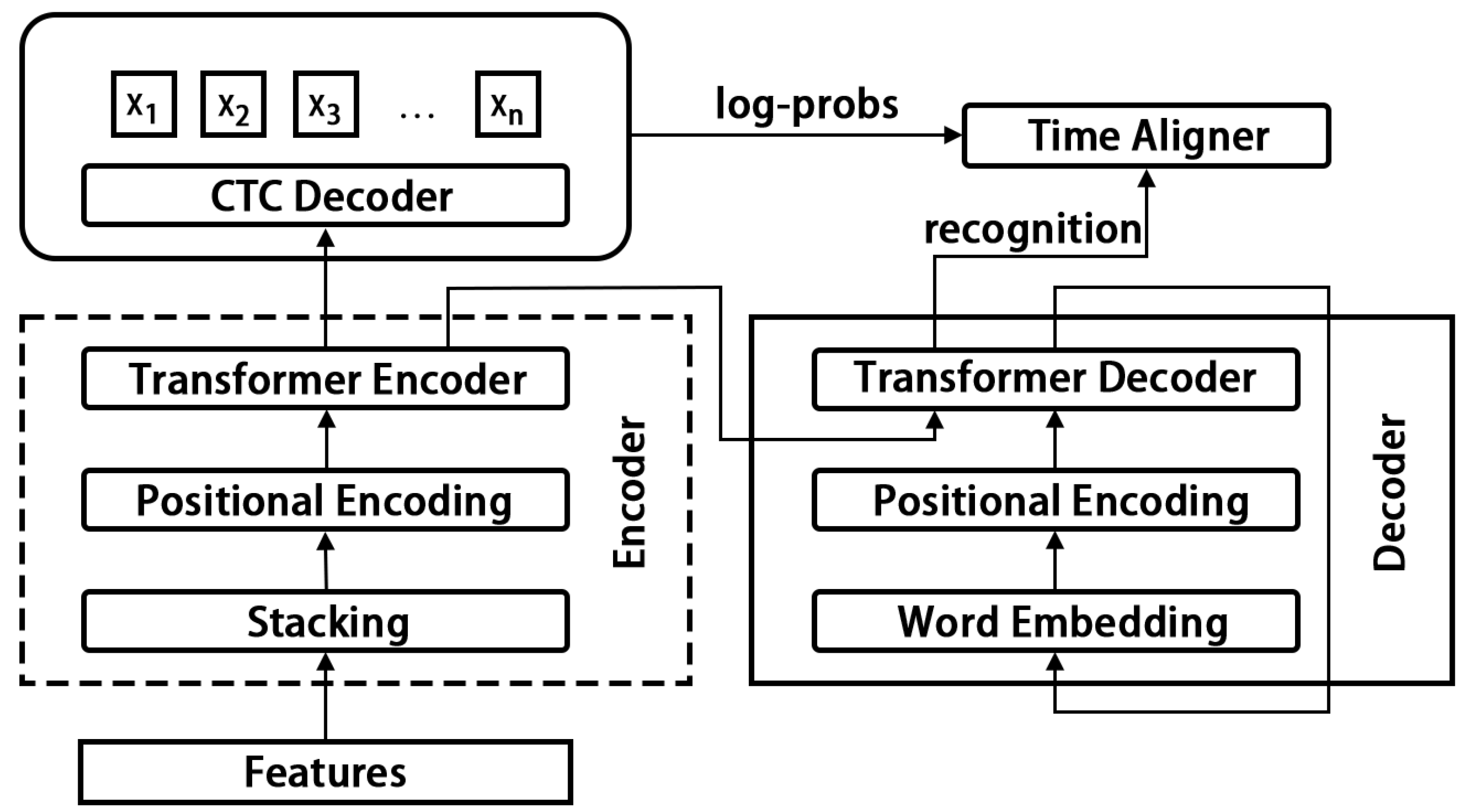
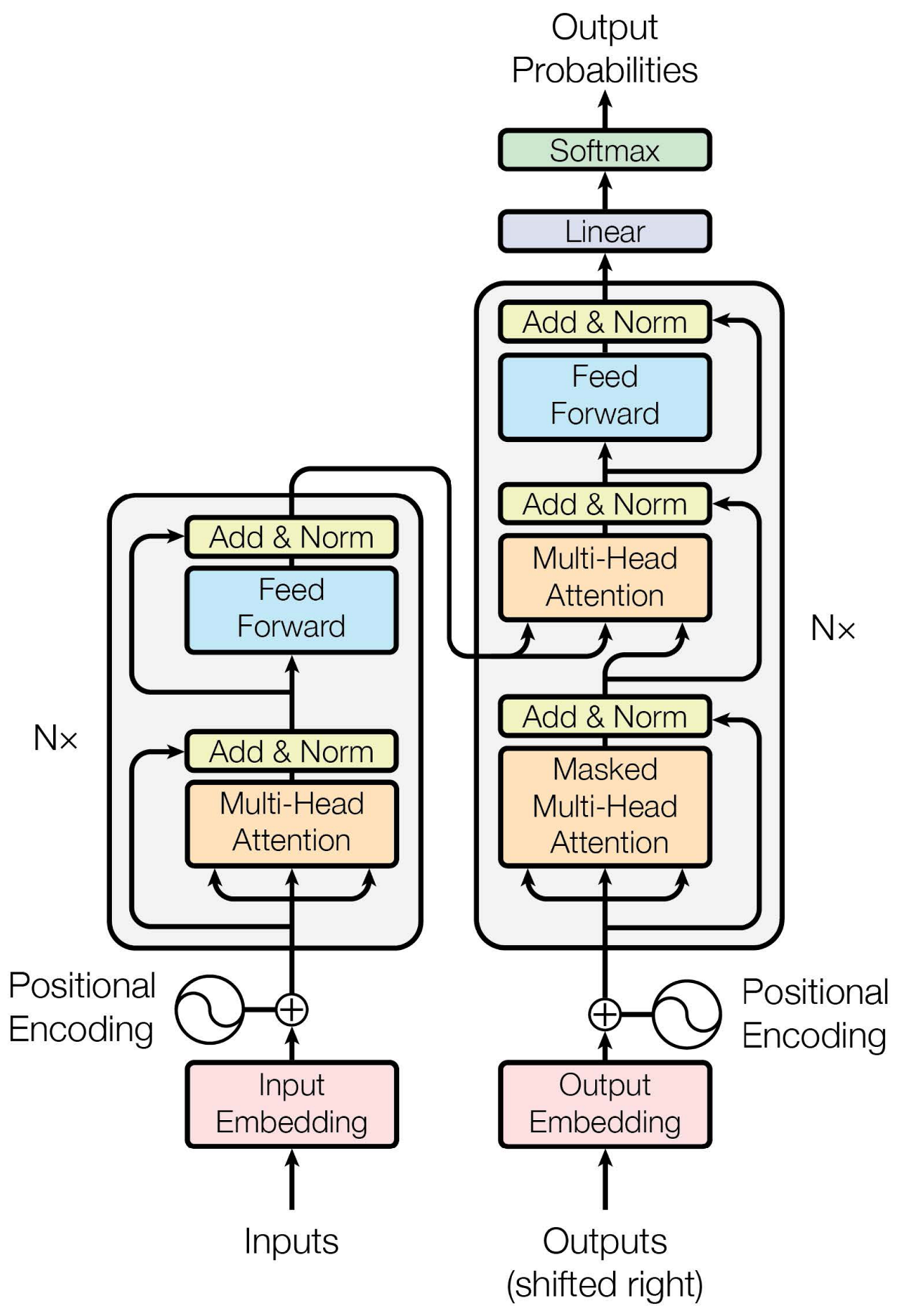
5.3.1. Transformer-CTC
The PyTorch library was used to implement the system, and it was trained on a Tesla V100 GPU with 16 GB of memory. The Adam optimizer was used with default parameters and an initial learning rate of , which was decreased by a factor of 2 when the validation error stopped improving, eventually reaching a final learning rate of . For all models, we used a dropout with and label smoothing.
When dealing with a large number of timesteps, sequence-to-sequence learning can be slow to converge because the decoder initially struggles to extract relevant information from all the input steps. Despite not having any recurrent modules in our models, we found that implementing a curriculum instead of training on full sentences immediately was helpful.
Our approach involves starting with single-word examples and gradually increasing the sequence length as the network trains. These shorter sequences are parts of the longer sentences in the dataset. We noticed that the rate of convergence on the training set was much faster, and the curriculum reduced overfitting by augmenting the data in a natural way.
We first trained the networks on the frozen features of the pre-trained sets from MV-LRS, LRS2-BBC, and LRS3-TED. To handle the variation in utterance lengths, we padded the sequences with zeros to a maximum length, which we steadily increased. We then fine-tuned the model end-to-end on the train-val set of either LRS2-BBC or LRS3-TED, depending on which set we were evaluating.
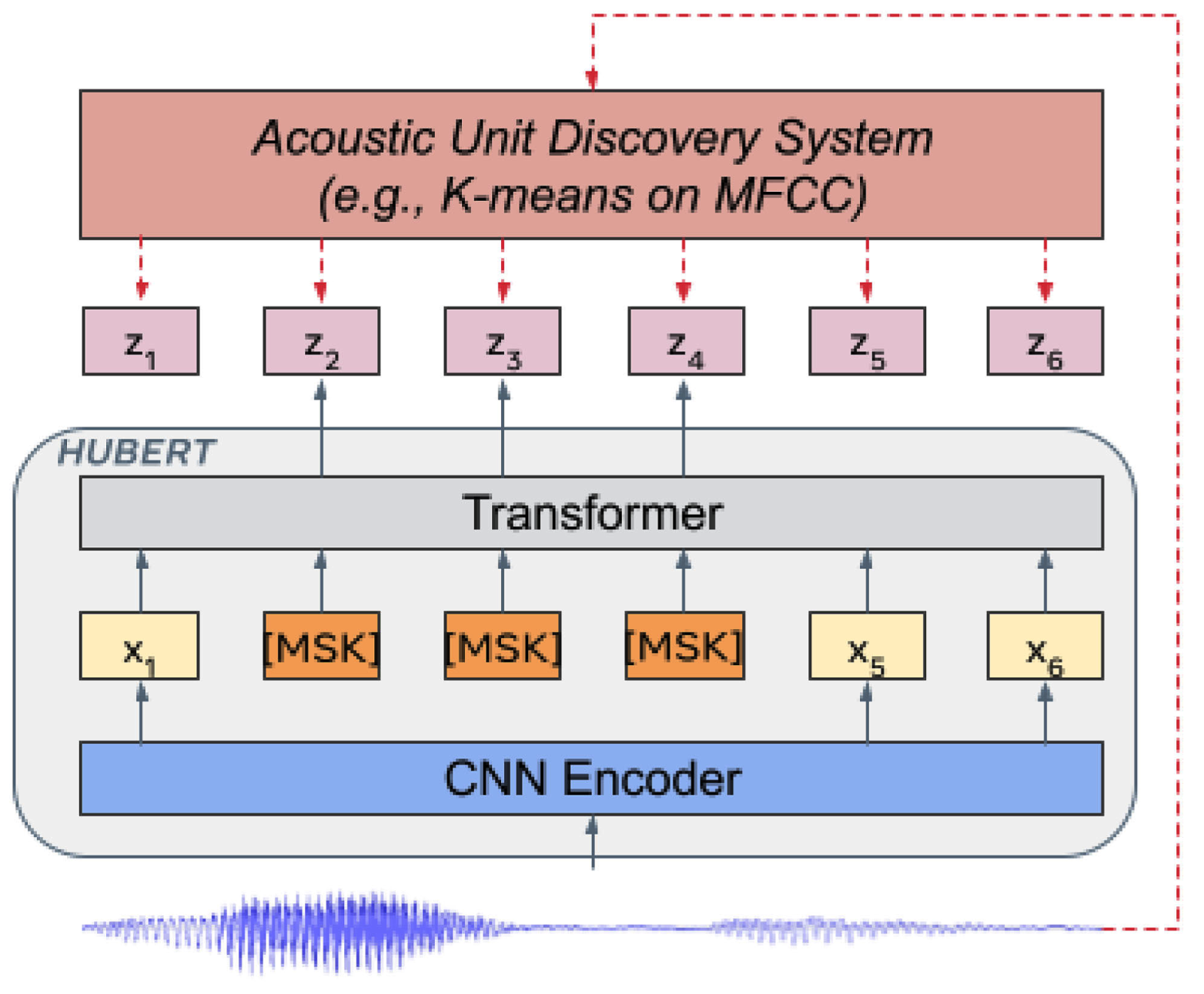
5.3.2. AV-HuBERT
The model takes in lip regions of interest (ROIs) for visual data and log filterbank energy features for audio data. The image encoder is based on a modified version of ResNet-18, and the audio encoder is a simple linear projection layer. There are two different model configurations: BASE which has 12 transformer blocks, and LARGE which has 24 transformer blocks. For BASE, each transformer block has an embedding dimension/feedforward dimension/attention head of 768/3072/12. For LARGE, these values are 1024/4096/16. The numbers of parameters in BASE and LARGE are 103 M and 325 M, respectively.
To improve the robustness of the AV-HuBERT model, noise enhancement was performed on the audio information. By training the model on noisy data, the ability of the model to resist noise was significantly improved.
To improve the input audio quality, we used discourse mixing, which selects random speech samples from the same small batch. To enhance the noise in pre-training, we used a wide range of sources, including non-speech noise, such as ambient and babble noise. To ensure the primary discourse is identified correctly, the intersection between the secondary and primary discourse should be less than 50 percent in WavLM, which focuses on pure audio self-supervised learning. Our approach is flexible and not restricted in terms of noise mixing, as the accompanying visual stream helps differentiate the primary and secondary discourse.
Our approach is unconstrained and more flexible in terms of mixing noise, since the accompanying visual stream disambiguates the primary and secondary discourse.
5.3.3. Moco
The final AVSR model was achieved through a series of training stages.
Firstly, the audio front-end was pre-trained through self-supervised learning using wav2vec 2.0 for the audio modality. Then, the audio front- and back-end were trained with dedicated decoders through the audio-only (AO) setting.
For the visual modality, the visual front-end was pre-trained through self-supervised learning and then modified to be trained through sequence classification at the word level for video clips in LRW data. The visual front-end was then used in the visual-only (VO) model with the visual back-end and dedicated decoders.
The final AVSR model was trained after the audio-only and visual-only models converged. Due to computational constraints, the audio and visual back-end outputs were pre-computed, and only the parameters in the fusion module and decoders were learned in the final stage.
5.4. Experiment Results
To evaluate the performances of the models more objectively, we used the best-known audiovisual databases LSR2 and LSR3 to evaluate the performance of each model in the presence and absence of noise in each of the three datasets.
5.4.1. ASR (Audio Speech Recognition)
The results for pure speech recognition are shown in
Table 4. It can be seen that in the experiments, the Transformer-CTC model performed best in automatic speech recognition with a WER of 0.123 on the LRS2 dataset and 0.244 on the LRS3 dataset. Some examples of successful model predictions are shown in
Table 5.
5.4.2. Lips Only (Visual Speech Recognition)
The results for pure visual speech recognition are shown in
Table 6. It can be seen that in the experiments, the ResNet-18 and convolution-augmented transformer (conformer) model performed best for lip reading (pure visual speech recognition), which achieved a WER of 0.261 on the LRS2 dataset and 0.323 on the LRS3 dataset. Some examples of successful model predictions are shown in
Table 7.
5.4.3. Audio-Visual Speech Recognition
The results for audio-visual speech recognition are shown in
Table 8. It can be seen that in the experiments, the AV-HuBERT model performed best in audiovisual speech recognition, with a WER of 0.137 on the LRS2 dataset and a WER of 0.0176 on the LRS3 dataset. Although the Transformer-CTC-based audio-visual speech recognition model performed well on the LRS2 dataset with a WER of 0.076, it did not perform as well on the LRS3 dataset with a WER of 0.164. An example of using the model to predict LRS3 is shown in the following
Table 9. We can see that most of the sentences in the LRS3 dataset that were predicted to have errors are relatively long, and the language model in the TM-CTC decoder was trained on the LRS2 dataset, which has relatively shorter sentences compared to LRS3. Therefore, in the future, we could try to use a mixed dataset of LRS2 and LRS3 and more audiovisual datasets as the training set of the language model, which is expected to achieve better training results.
5.5. Analysis
Through a series of experiments, we found that the performance of Moco+word2vec was the best among the three replicate models in both ASR and AVSR. By combining a CNN and a transformer, the model has both the excellent feature extraction ability of a CNN and the excellent receptive field of a transformer, so the feature extraction ability of the model is greatly improved, especially in lip reading. Since the main purpose of AVSR is to improve the accuracy of speech recognition through lip reading, the accuracy of the lip reading part has a very important impact on the overall performance of AVSR. Xichen Pan et al. designed a pre-training front-end model using LRW (word-level dataset) to train an excellent word-level-lip-reading front-end model and used this model as a pre-training model to greatly improve the performance of the lip reading part. The performance of the lip-reading part was greatly improved, and thus, the overall AVSR model performed much better than other models. Moreover, the method uses a hybrid of Conv and ransformer to extract features, which was found to be effective in extracting more valuable information.
However, the current study still has some shortcomings: Not only the three models we reproduced, but also almost all AVSR models in existence have been trained with a single dataset. Take the TM-CTC model as an example. Since it was trained on the training set of LRS2, its performance on the LRS3 test set is much worse than that on the LRS2 test set. In fact, LRS2 and LRS3 are similar data sets, just like their names imply—similar but different. This situation often occurred in our practical applications of the models as well. No matter which dataset the model is trained on, the training set must not contain the actual scenarios of our future applications in real life. Such an ability to adapt the model to all domains that are similar to but different from the training set is called the domain-adaptation capability.
Therefore, the research in the field of AVSR is mainly limited by feature-extraction ability and domain-generalization ability, and we can continue to go deeper in this direction in future research to further improve the performances of AVSR models.
6. Conclusions
In this paper, we presented the principles associated with several state-of-the-art visual speech recognition models and compared the performances of these models on the LRS2 and LRS3 datasets by replication. We used WER as an evaluation criterion. By observing the experimental results, we found that Moco built the network framework by using a combination of a convolutional network and transformer, and that the model outperforms the other two models in terms of AO, VO, and AVSR. While comparing their performances, we analyzed the problems of the current AVSR model, mainly in feature extraction and domain generalization, based on the experience accumulated during the research. Our research lays the foundation for further improving the performance of the AVSR model.
Although many important results have been achieved in audiovisual speech recognition, there are still many issues that need further investigation and research—for example, improving the recognition accuracy in noisy environments and enhancing its anti-interference capability. In addition, it is important to optimize the algorithm, reduce the use of computational resources, and improve its real-time performance and efficiency. Moreover, adding more diverse corpora to the database is also an important way to improve recognition performance. With the continuous development of technology and the expansion of application scenarios, there is still a lot of room for development in the field of audiovisual speech recognition processing. It is expected that the future research directions will focus more on practical applications, such as those in smart homes, smart customer service, smart driving, and other fields. At the same time, with the popularization of 5G and other new generation communication technologies, it will provide more efficient technical support for the field of audio-visual speech-recognition processing.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}