1. Introduction
This article is an expanded and revised version of the conference paper [
1]. The following motivation encouraged us to delve into this subject. The rapid development of big big-data storage and processing technologies [
2,
3] has led to the emergence of optimization mathematical models in the form of multidimensional linear programming (LP) problems [
4]. Such LP problems arise in industry, economics, logistics, statistics, quantum physics, and other fields [
5,
6,
7]. An important class of LP applications are is non-stationary problems related to optimization in dynamic environments [
8]. For a non-stationary LP problem, the objective function and/or constraints change over the computational process. Examples of non-stationary problems are the following: decision support in high-frequency trading [
9,
10], hydro-gas-dynamics problems [
11], optimal control of technological processes [
12,
13,
14], transportation [
15,
16,
17], and scheduling [
18,
19].
One of the standard approaches to solving non-stationary optimization problems is to consider each change as the appearance of a new optimization problem that needs to be solved from scratch [
8]. However, this approach is often impractical because solving a problem from scratch without reusing information from the past can take too much time. Thus, it is desirable to have an optimization algorithm capable of continuously adapting the solution to the changing environment, reusing information obtained in the past. This approach is applicable for real-time processes if the algorithm tracks the trajectory of the moving optimal point fast enough. In the case of large-scale LP problems, the last requirement necessitates the development of scalable methods and parallel algorithms of LP.
One of the most promising approaches to solving complex problems in real time is the use of neural network models [
20]. Artificial neural networks are a powerful universal tool that is applicableapplies to solving problems in almost all areas. The most popular neural network model is the feedforward neural network. Training and operation of such networks can be implemented very efficiently on GPUs [
21]. An important property of a feedforward neural network is that the time to solve a problem is a known constant that does not depend on the problem parameters. This feature is necessary for real-time mode. Pioneering work on the use of neural networks to solve LP problems is the article by Tank and Hopfield [
22]. The article describes a two-layer recurrent neural network. The number of neurons in the first layer is the number of variables of the LP problem. The number of neurons in the second layer coincides with the number of constraints of the LP problem. The first and second layers are fully connected. The weights and biases are uniquely determined by the coefficients and the right-hand sides of the linear inequalities defining the constraints, and the coefficients of the linear objective function. Thus, this network does not require training. The state of the neural network is described by the differential equation
, where
is an energy function of a special type. Initially, an arbitrary point of the feasible region is fed to the input of the neural network. Then, the signal of the second layer is recursively fed to the first layer. Such processa process leads to convergence to a stable state in which the output remains constant. This state corresponds to the minimum of the energy function, and the output signal is a solution to the LP problem. The Tank and Hopfield approach has been expanded and improved in numerous works (see, for example, [
23,
24,
25,
26,
27]). The main disadvantage of this approach is the unpredictable number of work cycles of the neural network. Therefore, a recurrent network based on an energy function cannot be used to solve large-scale LP problems in real time.
In the recent paper [
28], a
n-dimensional mathematical model for visualizing LP problems was proposed. This model makes it possible to use feedforward neural networks, including convolutional networks [
29], to solve multidimensional LP problems, the feasible region of which is a bounded nonempty-empty set. However, there are practically no works in scientific periodicals devoted to the use of convolutional neural networks for solving LP problems [
30]. The reason isThe reason for this is that convolutional neural networks focus on image processing, but there are no methods for constructing training datasets based on a visual representation of the multidimensional LP problems.
This article describes a new scalable iterative method for solving multidimensional LP problems. This method is called the “apex method”. The apex method allows you to generate training datasets for the development of feedforward neural networks capable of finding a solution to a multidimensional LP problem based on its visual representation. The apex method is based on the predictor—corrector framework. At the prediction step, a point belonging to the feasible region of the LP problem is calculated. The corrector step calculates a sequence of points converging to the exact solution of the LP problem. The rest of the paper is organized as follows.
Section 2 provides a review of iterative projection-type methods and algorithms for solving linear feasibility problems and LP problems.
Section 3 includes the theoretical basis of the apex method.
Section 4 presents a formal description of the apex method.
Section 4.1 considers the implementation of the pseudoprojection operation in the form of sequential and parallel algorithms and provides an analytical estimation of the scalability of parallel implementation.
Section 4.2 describes the quest stage.
Section 4.3 describes the target stage.
Section 5 presents an informationinformation about the software implementation of the apex method and describes the results of large-scale computational experiments on a cluster computing system.
Section 6 discusses the issues related to the main contribution of this article, the advantages and disadvantages of the proposed approach, possible applications, and some other aspects of using the apex method. In
Section 7, we present our conclusions and comment on possible further studies of the apex method. The final section Notations contains the main symbols used for describing the apex method.
2. Related Work
This section provides an overview of works devoted to iterative projection-type methods used to solve linear feasibility and LP problems. The linear feasibility problem can be stated as follows. Consider the system of linear inequalities in matrix form
where
, and
. To avoid triviality, we assume that
. The linear feasibility problem consists of finding a point
satisfying matrix inequality system (
1). We assume from now on that such a point exists.
Projection-type methods rely on the following geometric interpretation of the linear feasibility problem. Let
be a vector formed by the elements of the
ith row of the matrix
A. Then, the matrix inequality
is represented as a system of inequalities
Here and further on,
stands for the dot product of vectors. We assume from now on that
for all
. For each inequality
, define the closed half-space
and its bounding hyperplane
For any point
, the
orthogonal projection of point
x onto the hyperplane
can be calculated by the equation
Here and below,
denotes the Euclidean norm. Let us define the feasible polytope
that presents the set of feasible points of system (
1). Note thatPlease note that in this case, the polytope
M is a closed convex set. Here, we always assume that
, i.e., the solution of system (
1) exists. In geometric interpretation, the linear feasibility problem consists of finding a point
.
The forefathers of the iterative projection-type methods for solving linear feasibility problems are Kaczmarz and Cimmino. In [
31] (English translation in [
32]), Kaczmarz presented a sequential projections method for solving a consistent system of linear equations
His method, starting from an arbitrary point
, calculates the following sequence of point groups:
for
Here,
is the orthogonal projection onto the hyperplane
defined by Equation (
6). This sequence converges to the solution of system (
8). Geometrically, the method can be interpreted as follows. The initial point
is projected orthogonally onto hyperplane
. The projection is the point
, which now is thrown onto
. The resulting point
is then thrown onto
and gives the point
, etc. As a result, we obtain the last point
from the first point group. The second point group is constructed in the same way, starting from the point
. The process is repeated for
Cimmino proposed in [
33] (English description in [
34]) a simultaneous projection method for the same problem. This method uses the following orthogonal reflection operation
which calculates the point
symmetric to the point
x with respect to the hyperplane
. For the current approximation
, the Cimmino method simultaneously calculates reflections with respect to all hyperplanes
, and then a convex combination of these reflections is used to form the next approximation:
where
,
. When
, Equation (
11) is transformed into the following equation:
Agmon [
35] and Motzkin and Schoenberg [
36] generalized the projection method from equations to inequalities. To solve problem (
1), they introduce the relaxed projection
where
. It is obvious that
. To calculate the next approximation, the relaxed projection method uses the following equation:
where
Informally, the next approximation
is a relaxed projection of the previous approximation
with respect to the furthest hyperplane
bounding the half-space
not containing
. Agmon in [
35] showed that sequence
converges, as
, to a point on the boundary of
M.
Censor and Elfving, in [
37], generalized the Cimmino method to the case of linear inequalities. They consider the relaxed projection onto the half-space
defined as follows:
that gives the equation
Here,
, and
,
. In [
38], De Pierro proposed an approach to convergence proof for this method, which differs from the approach of Censor and Elfving. De Piero’s approach is also acceptable for the case when the underlying system of linear inequalities is infeasible. In this case, for
, sequence (
17) converges to the point that is the minimum of the function
, i.e., it is a weighted (with the weights
) least least-squares solution of system (
1).
The Cimmino-like methods allow efficient parallelization, since orthogonal projections (reflections) can be calculated simultaneously and independently. The article [
39] investigates the efficiency of parallelization of the Cimmino-like method on Xeon Phi manycore processors. In [
40], the scalability of the Cimmino method for multiprocessor systems with distributed memory is evaluated. The applicability of the Cimmino-like method for solving non-stationary systems of linear inequalities on computing clusters is considered in [
41].
As a recent work, we can mention article [
42], which extends the Agmon-Motzkin-Schoenberg relaxation method for the case of semi-infinite inequality systems. The authors consider the system with an infinite number of inequalities in the finite-dimensional Euclidean space
:
where
I is an arbitrary infinite index set. The main idea of the method is as follows. Let the hyperplane
be the biggest violation with respect to
x. Let
be an arbitrary initial point. If the current iteration
is not a solution of system (
18), then let
be the orthogonal projection of
onto a hyperplane
(
) near the biggest violation
. If system (
18) is consistent, then the sequence
generated by the described method converges to the solution of this system.
Solving systems of linear inequalities is closely related to LP problems, so projection-type methods can be effectively used to solve this class of problems. The equivalence of the linear feasibility problem and the LP problem is based on the primal-dual LP problem. Consider the primal LP problem in the matrix form:
where
,
,
, and
. Let us construct the dual problem with respect to problem (
19):
where
. The following primal-dual equality holds:
In [
43,
44], Eremin proposed the following method based on the primal-dual approach. Let the inequality system
define the feasible region of primal problem (
19). This system is obtained by adding to the system
the vector inequality
. In this case,
, and
. Let
stand the
ith row of the matrix
. For each inequality
, define the closed half-space
and its bounding hyperplane
Let
stand the orthogonal projection of point
x onto the hyperplane
:
Let us define the projection onto the half-space
:
This projection has the following two properties:
Define
as follows:
In the same way, define the feasible region of dual problem (
20) as follows:
where
,
, and
. Denote
and define
as follows:
Now, define
as follows:
which is corresponding to Equation (
21). Here,
stands for the concatenation of vectors.
Finally, define
as follows:
If the feasible region of the primal problem is a bounded and nonempty set, then the sequence
converges to the point
, where
is the solution of primal problem (
19), and
is the solution of dual problem (
20).
Article [
45] proposes a method for solving non-degenerate LP problems based on calculating the orthogonal projection of some special point, independent of the main part of data describing the LP problem, onto a problem-dependent cone generated by the constraint inequalities. Actually, tThis method solves a symmetric positive definite system of linear equations of a special kind. The author demonstrates a finite algorithm of an active-set family that is capable of calculating orthogonal projections for problems with up to thousands of rows and columns. The main drawback of this method is a a significant increasing increase in the dimension of the primary problem.
In article [
46], Censor proposes the linear superiorization (LinSup) method as a tool for solving LP problems. The LinSup method does not guarantee finding to find the minimum point of the LP problem, but it directs the linear feasibility-seeking algorithm that it uses toward a point with a decreasing value of the objective function. This process is not identical with to that employed by LP solvers but it is a possible alternative to the sSimplex method for problems of huge size. The basic idea of LinSup is to add an extra term, called perturbation term, to the iterative equation of the projection method. The perturbation term steers the feasibility-seeking algorithm toward reduced the objective function values. In the case of LP problem (
19), the objective function is
, and LinSup adds
as a perturbation term to iterative Equation (
17):
Here, is a perturbation parameter.
Article [
47] presents an enthusiastic artificial-free linear programming method based on a sequence of jumps and the simplex method. It performsis performed in three phases. Starting with phase 1, it guarantees the existence of a feasible point by relaxing all non-acute constraints. With this initial starting feasible point, in phase 2, it sequentially jumps to the improved objective feasible points. The last phase reinstates the rest of the non-acute constraints and uses the dual simplex method to find the optimal point.
Article [
28] proposes a mathematical model for the visual representation of multidimensional LP problems. To visualize a feasible LP problem, an objective hyperplane
is introduced, the normal to which is the gradient of the objective function
. In the case of seeking the maximum, the objective hyperplane is positioned in such a way that the value of the objective function at all its points is greater thenthan the value of the objective function at all points of the convex polytope
M, which is the feasible region of the LP problem. For any point
, the objective projection
onto
M is defined as follows:
Here, denotes the orthogonal projection onto . On the objective hyperplane , a rectangular lattice of points is constructed, where K is the number of lattice points in one dimension. Each point is mapped to the real number . This mapping generates a matrix of dimension , which is an image of the LP problem. This approach opens up the possibility of using feedforward-forward artificial neural networks, including convolutional neural networks, to solve multidimensional LP problems. One of the main obstacles to the implementation of this approach is the problem of generating a training set. The literature review shows that there is no suitable method capable of constructing such a training set compatible with the described approach. In the next sections, we present such a method.
5. Implementation and Computational Experiments
We implemented a parallel version of the apex method in C++ using the BSF-skeleton [
50], which is based on the BSF parallel computation model [
49]. The BSF-skeleton encapsulates all aspects related to the parallelization of a program using the MPI library. The source code of this implementation is freely available at
https://github.com/leonid-sokolinsky/Apex-method (accessed on 1 March 2023). Using this program, we investigated the scalability of the apex method. The computational experiments were conducted on the “Tornado SUSU” computing cluster [
51], whose specifications are shown in
Table 1.
As test problems, we used random synthetic LP problems generated by the program FRaGenLP [
52]. A verification of solutions obtained by the apex method was performed using the program VaLiPro [
53]. We conducted a series of computational experiments in which we investigated the dependence of speedup and parallel efficiency on the number of worker nodes used. The results are presented in
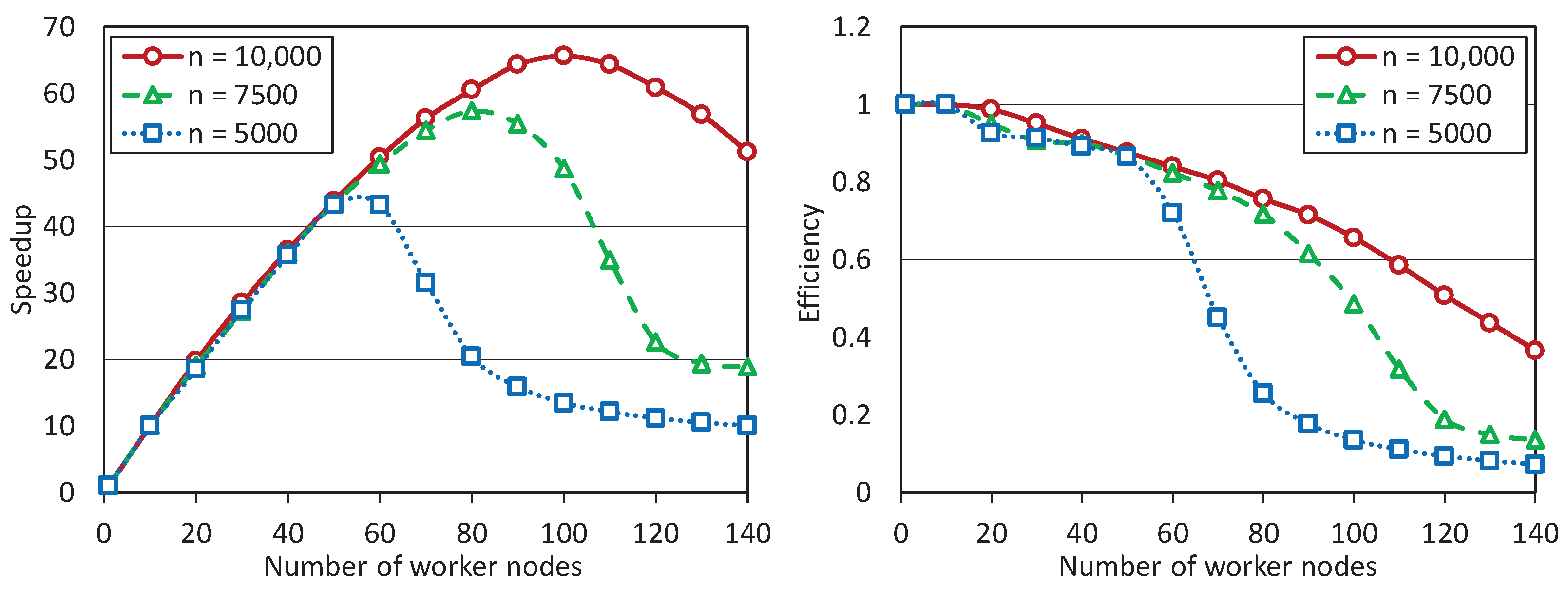
Figure 2.
Here, the speedup
is defined as the ratio of the time
required by the parallel algorithm using one master node and one worker node to solve a problem to the time
required by the parallel algorithm using one master node and
L worker nodes to solve the same problem:
The parallel efficiency
is calculated as the ratio of the speedup
to the number
L of worker nodes:
The computations were performed with the following dimensions: 5000, 7500, and 10,000. The number of inequalities was 10,002, 15,002, and 20,002, respectively. The experiments showed that the scalability boundary of the parallel apex algorithm depends significantly on the size of the LP problem. For , the scalability boundary was approximately 55 worker nodes. For the problem of dimension , this boundary increased to 80 nodes, and for the problem of dimension n = 10,000, it was close to 100 nodes. Further increasing the problem size caused the compiler error: “insufficient memory”. It should be noted that the computations were performed in the double double-precision floating-point format occupying 64 bits in computer memory. An attempt to use the single-precision floating-point format occupying 32 bits failed because the apex algorithm stopped to convergeconverging. Parallel efficiency also significantly depends on the size of the LP problem. For , the efficiency dropped below 50% at 70 worker nodes. For and n = 10,000, the 50% drop of the efficiency occurred at 110 and 130 worker nodes, respectively.
The experiments have also shown that the parameter
used in Equation (
117) to calculate the apex point
z at the quest stage has a negligible effect on the total time of solving the problem when this parameter has large values (more then than 100,000). If the apex point is not far enough away from the polytope, then its pseudoprojection-projection can be an interior point of some polytope face. If the apex point is taken far enough away from the polytope (the value
was used in the experiments), then the pseudoprojection-projection always fell into one of the polytope vertices. AlsoAdditionally, we would like to note that, in the case of synthetic LP problems generated by the program FRaGenLP, all computed points in the sequence
were vertices of the polytope. The computational experiment showed that more than 99% of the time spent for solving the LP problem by the apex method was taken up by the calculation of pseudoprojections (Step 18 of Algorithm 3). At that, theThe calculation of one approximation
for a problem of dimension
n = 10,000 on 100 worker nodes took 44 min.
We also tested the apex method on a subset of LP problems from the Netlib-LP repository [
54] available at
https://netlib.org/lp/data (accessed on 1 March 2023). The Netlib suite of linear optimization problems includes many real real-world applications like such as stochastic forestry problems, oil refinery problems, flap settings of aircraft, pilot models, audit staff scheduling, truss structure problems, airline schedule planning, industrial production, and allocation models, image restoration problems, and multisector economic planning problems. It contains problems ranging in size from 32 variables and 27 constraints up to 15,695 variables and 16,675 constraints [
55]. The exact solutions (optimal values of objective functions) of all problems were obtained from paper [
56]. The results are presented in
Table 2.
These experiments showed that the relative error of the rough solution calculated at the quest stage was less than or equal to 0.2, excluding the
adlittle,
blend, and
fit1d problems. The relative error of the refined solution calculated at the target stage was less than
, excluding the
kb2 and
sc105, for which the error was
and
, respectively. The runtime varied from a few seconds for
afiro to tens of hours for
blend. One of the main parameters affecting the convergence rate of the apex method was the parameter
used in Step 12 of the parallel Algorithm 2 calculating the pseudoprojection. All runs are available on
https://github.com/leonid-sokolinsky/Apex-method/tree/master/Runs (accessed on 1 March 2023).
6. Discussion
In this section of the article, we will discuss some issues related to the scientific contribution and applicability of the apex method in practice and give answers to the following questions.
- 1.
What is the scientific contribution of this article?
- 2.
What is the practical significance of the apex method?
- 3.
What is our confidence that the apex method always converges to the exact solution of the LP problem?
- 4.
How can we speed up the convergence of the Algorithm 1 calculating a pseudoprojection on the feasible polytope M?
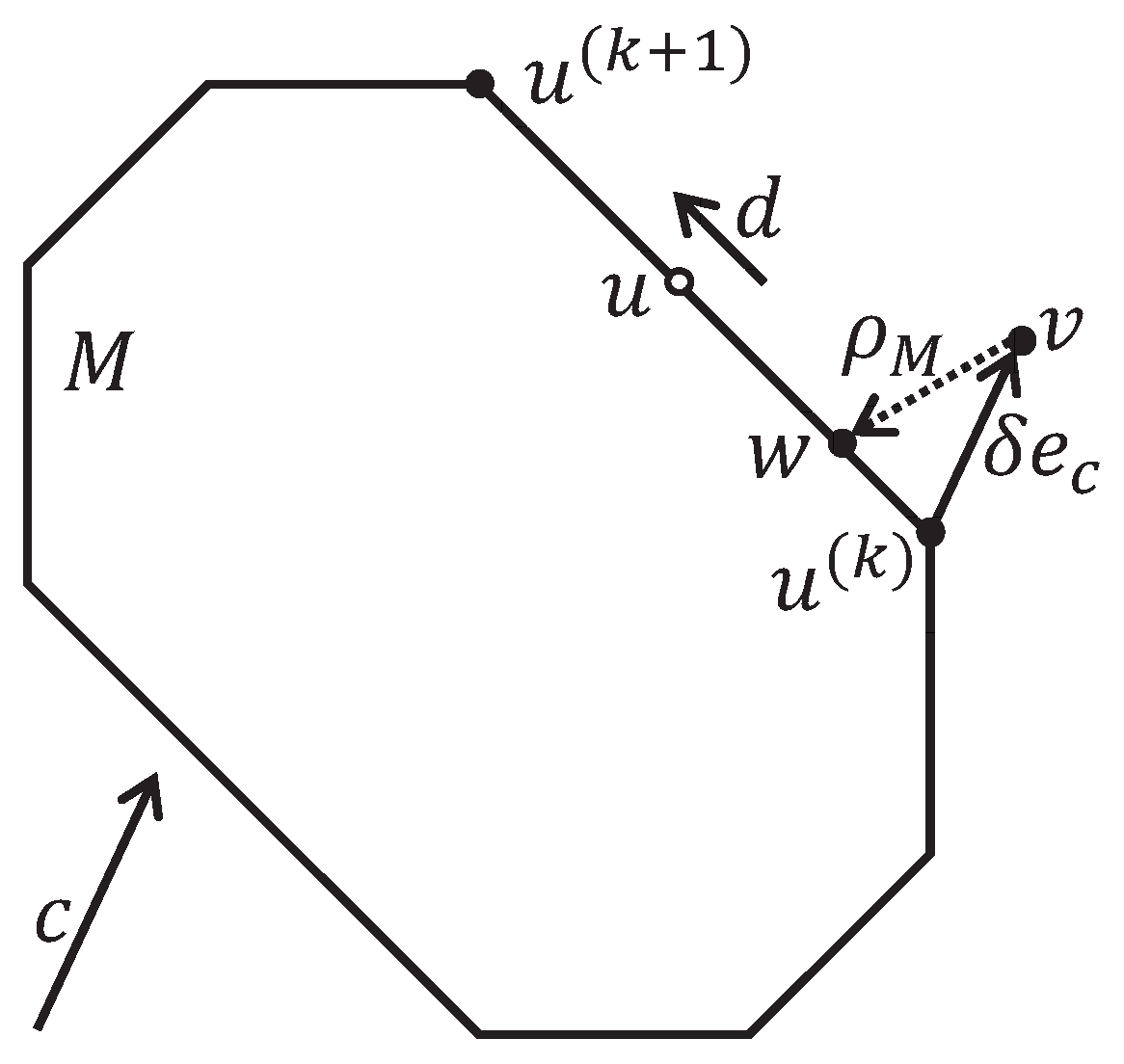
The main scientific contribution of this article is that it presents the apex method that allows, for the first time, as far as we know, to construct a path close to optimal on the surface of a feasible polytope from a certain starting point to the exact solution of the LP problem. Here, the optimal path refers to a path of the minimum length according to the Euclidean metric. By intuition, moving in the direction of the greatest increase in the value of the objective function will give us the shortest path to the point of maximum of the objective function on the surface of the feasible polytope. We intend to present a formal proof of this fact in a futurefuture work.
The practical significance of the apex method is based on the issue of applying feedforward-forward neural networks, including convolutional neural networks, to solve LP problems. In recenta recent paper [
28], a method of visual representation of
n-dimensional LP problems was proposed. This method constructs an image of the feasible polytope
M in the form of a matrix
I of dimension
using the rasterization technique. A vector antiparallel to the gradient vector of the objective function is used as the view ray. Each pixel value in
I is proportional to the value of the objective function at the corresponding point on the surface of a feasible polytope
M. Such an image makes it possible to use a feedforward neural network to construct the optimal path on the surface of the feasible polytope to the solution of the LP problem. Actually, tThe feedforward neural network can directly calculate the vector
d in Algorithm 3, making the calculation of pseudoprojection redundant. The advantage of this approach is that the feedforward-forward neural network works in real time, which is important for robotics. We are not aware of other methods that solvessolve LP problems in real time. However, applying a feedforward neural network to solve LP problems involves the task of preparing a training dataset. The apex method provides the possibility to construct such a training dataset.
Proposition 6 states that Algorithm 3 converges to some point on the surface of the feasible polytope M in a finite number of steps, but leaves open the question of whether the terminal point will be a solution to the LP problem. According to Proposition 8, the answer to this question is positive if, in Algorithm 3, the pseudoprojection is replaced by the metric projection. However, there are no methods for constructing the metric projection for an arbitrarily bounded convex polytope. Therefore, we are forced to use the pseudoprojection. Numerous experiments show that the apex method converges to the solution of the LP problem, but this fact requires a formal proof. We plan to make such a proof in our future work.
The main drawback of the apex method is the slow rate of convergence to the solution of the LP problem. The LP problem, which takes several seconds to find the optimal solution by standard linear programming solvers, may take several hours to solve by the apex method. Computational experiments demonstrated that more than 99% of the time spent for solving the LP problem by the apex method was taken by the calculation of pseudoprojections. Therefore, the issue of speeding up the process of calculating the pseudoprojection is urgent. In the apex method, the pseudoprojection is calculated by Algorithm 1, which belongs to the class of projection-type methods discussed in detail in
Section 2. In the case of closed bounded polytope
, the projection-type methods have a low linear rate of convergence:
where
is some constant, and
is a parameter that depends on the angles between the half-spaces corresponding to the faces of the polytope
M [
57]. This means that the distance between adjacent approximations decreases at each iteration by a constant factor of less than 1. For small angles, the convergence rate can decrease todecrease to values close to zero. This fundamental limitation of the projection-type methods cannot be overcome. However, we can reduce the number of half-spaces used to compute the pseudoprojection. According to Proposition 3, the solution of LP problem (
38) belongs to some
c-recessive half-space. Hence, in Algorithm 1 calculating the pseudoprojection, we can take into account only the
c-recessive hyperplanes. On average, this reduces the number of half-spaces by two times. Another way to reduce the pseudoprojection calculation time is to parallelize Algorithm 1, as was done in Algorithm 2. However, the degree of parallelism in this case, in this case, will be limited by the theoretical estimation (
115).
7. Conclusions and Future Work
In this paper, we proposed a new scalable iterative method for linear programming called the “apex method”. The key feature of this method is constructing a path close to optimal on the surface of the feasible region from a certain starting point to the exact solution of the linear programming problem. The optimal path refers to a path of the minimum length according to the Euclidean metric. The main practical contribution of the apex method is that it opens the possibility of using feedforward neural networks to solve multidimensional LP problems.
The paper presents a theoretical basis used to construct the apex method. The half-spaces generated by the constraints of the LP problem are considered. These half-spaces form the feasible polytope M, which is a closed bounded set. These half-spaces are divided into two groups with respect to the gradient c of the linear objective function: c-neutral-dominant and c-recessive. The necessary and sufficient condition for the c-recessivity is obtained. It is proved that the solution of to the LP problem lies on the boundary of a c-recessive half-space. The equation defining the apex point not belonging to any c-recessive half-space is derived. The apex point is used to calculate the initial approximation on the surface of the feasible polytope M. The apex method constructs a path close to optimal on the surface of the feasible polytope M from this initial approximation to the solution of the LP problem. To do this, it uses a parallel algorithm constructing the pseudoprojection, which is a generalization of the notion of metric projection. For this parallel algorithm, an analytical estimation of the scalability bound is obtained. This estimation says that the scalability boundary of the parallel algorithm, of calculating the pseudoprojection on a cluster computing system, does not exceed processor nodes, where m is the number of constraints of the linear programming problem. The algorithm constructing a path close to optimal on the surface of the feasible polytope, from the initial approximation to the exact solution of the linear programming problem, is described. The convergence of this algorithm is proven.
The parallel version of the apex method is implemented in C++ using the BSF-skeleton based on the BSF parallel computation model. Large-scale computational experiments were conducted to investigate the scalability of the apex method on a cluster computing system. These experiments show that, for a synthetic scalable linear programming problem with a dimension of 10,000 and a constraint number of 20,002, the scalability boundary of the apex methods is close to 100 processor nodes. At the same time, these experiments showed that more than 99% of the time spent for solving the LP problem by the apex method was taken by the calculation of pseudoprojections.
In addition, the apex method was used to solve 10 problems from the Netlib-LP repository. These experiments showed that the relative error varied from to . The runtime ranged from a few seconds for to tens of hours. The main parameter affecting the convergence rate of the apex method was the precision of calculating the pseudoprojection.
Our future research directions on this subject are as followingfollows. We plan to develop a new method for calculating the pseudoprojection onto the feasible polytope of the LP problem. The basic idea is to reduce the number of half-spaces used in one iteration. At the same time, the number of these half-spaces should remain large enough to enable the efficient parallelization. The new method should outperform Algorithm 2 in terms of convergence rate. We will also need to prove that the new method converges to a point that lies on the boundary of the feasible region. In addition, we plan to investigate the usefulness of utilizusing the linear superiorization technique [
46] in the apex method.







{kind=link}
{kind=link}