1. Introduction
Consider a two-dimensional block-structured discrete-time Markov chain (DTMC)
on the state space
, where
and
are sets of non-negative integers and real numbers, respectively. Denote by
the Borel
-field of the set
. The transition probability law is time homogeneous and is characterized by the following transition kernel
where
,
and
. Recall that a two-dimensional function
is called a kernel if it is a measurable function in
x for each
, and a non-negative measure on
for each
. When
, we write
to be
for simplicity. Note that the kernel function
is stochastic in the sense that
for all
i and all
x. The level and phase of each state
are respectively represented by the first component
i and the second component
x. For any
, define
to be the
i level set. Then, the state space
E can be decomposed as
. For
, the corresponding
n-step transition kernel is given by
Two different types of block-structured discrete-time Markov chains are the focus of this paper. The first one is the discrete-time GI/M/1-type Markov chain, whose transition kernel matrix
is level independent and has the following lower-Hessenberg block form:
The second one is the discrete-time M/G/1-type Markov chain, whose transition kernel matrix
is level independent and has the following upper-Hessenberg block form:
These block-structured Markov chains are of the special features that the transition of the level is skip-free to the right or skip-free to the left, respectively.
Tweedie [
1] proposed the GI/M/1-type Markov chain with a continuous phase set and demonstrated that the positive recurrent GI/M/1-type Markov chain is of the operator-geometric stationary distribution. Thus, Tweedie [
1] extended the well-known results for the GI/M/1-type Markov chain with a finite phase set, which was derived by Neuts [
2]. Tweedie’s finding was later applied by Breuer [
3] to investigate the stationary distribution for the embedded GI/G/k queue with a Lebsegue-dominated inter-arrival time distribution. A positive recurrent tridiagonal block-structured quasi-birth-death (QBD) process with a continuous phase set, as well as a computational framework of its stationary distribution, are investigated by Nielsen and Ramaswami [
4]. They also demonstrated the motivation for investigating a model with a continuous phase set. The computational framework was recently extended and improved by Jiang et al. [
5] by incorporating the wavelet transform approach.
The GI/M/1-type and M/G/1-type Markov chains with a finite phase set were investigated systematically by Neuts in 1981 [
2] and 1989 [
6], respectively. Effective solver tools for solving the stationary distribution for these chains were developed by Bini et al. in [
7], based on the algorithms collected in [
8]. It is known that the matrices
R and
G are key matrices for solving stationary distributions for GI/M/1-type and M/G/1-type Markov chains, respectively. Since
R and
G are closely connected by Ramaswami dual and Bright dual, the computation of matrix
R for GI/M/1-type chains can be reduced to the computation of matrix
G for M/G/1-type Markov chains ([
9,
10,
11,
12]). Several effective algorithms have been developed to compute the matrix
G, such as functional iteration, Newton iteration, invariant subspace method, cyclic reduction and Ramaswami Reduction. Please refer to [
13] for a detailed description of the algorithms.
As far as we know, the following two issues are still not well addressed in the literature:
(i) For a positive recurrent GI/M/1-type Markov chain with a continuous phase set, numerical algorithms for computing the stationary distribution are missing, although the theoretical framework has been established in [
1],
(ii) M/G/1-type Markov chains are of the same importance as GI/M/1-type Markov chains. However, both the theoretical and computational framework are missing for M/G/1-type Markov chains with a continuous phase set.
The current research is motivated to investigate the above two issues. This paper is organized into six sections. We provide an overview of DTMCs on a general state space and the wavelet series expansion in two dimensions in
Section 2. The GI/M/1-type Markov chains are introduced in
Section 3, most of which are well known in the literature [
1], except for the computational analysis. The analysis of stationary distributions for M/G/1-type Markov chains is performed in
Section 4. Numerical experiments, including a brief description of numerical algorithms and two illustrative examples, are presented in
Section 5. Comparisons among different algorithms are executed with respect to the accuracy and speed of calculation. Conclusions are presented in
Section 6. Please refer to
Table A1 for a summary of frequently used notations.
3. -Type Markov Chains
Consider a GI/M/1-type Markov chain
, whose transition law
P given by (
1) satisfies that for any
Define the kernel
to be the expected number of visits to
, starting from
under the taboo set of
. From [
1], we know that the censored Markov chain
of the GI/M/1-type Markov chain on the zero level set
has the following transition kernel
The following theorem is taken from [
1], which characterizes the invariant probability measure for GI/M/1-type Markov chains with a continuous phase set.
Theorem 2 ([
1]).
Suppose that the GI/M/1-type Markov Chain with a continuous phase set is Ψ-
irreducible and Harris positive recurrent. Then, its unique stationary probability measure Π
, decomposed by , satisfies the following recursive formulawhere the kernel is the minimal non-negative solution of the following equationand is uniquely determined by Applying Theorem 2 and Theorem 1, we can obtain the following theorem directly.
Theorem 3. Suppose that the GI/M/1-type Markov Chain with a continuous phase set is ψ-irreducible and Harris positive recurrent and that Assumption 1 holds.
(i) The kernels and are in , whose associated matrices are, respectively, denoted by , and .
(ii) The invariant probability measure is in . Let be the associated row vector of , i.e., , where is the density of , and is defined in Section 2.2. Then, we haveandwhere and is the vector of 1’s with an appropriate dimension. 4. -Type Markov Chains
In this section, we consider a M/G/1-type Markov Chain
, whose transition law
P, given by (
1), satisfies that for any
Define
to be the first return time to the level set
for any
. For any
and any
, define the following kernel function
which is independent of
i due to the level independent structure of the chain. The first result is about the kernel
, which plays a key role in analyzing M/G/1-type Markov chains.
Theorem 4. Suppose that the M/G/1-type Markov chain is ψ-irreducible. For any , the kernel is the minimal nonnegative solution of the following equationwhere is the i-fold convolution of the kernel itself. Proof. We first show that the kernel
is a solution of Equation (
4).
By conditioning on the state of the first transition, the kernel
can be decomposed as follows
We will use the inductive arguments to show
Since the chain is level independent, when
, we have
for any
. Suppose that
satisfies
By conditioning on the state of the first hitting on level
and using the strong Markov property, we have
Substituting (
6) into (
5), we have
where we exchange the order between integration and summation by Fubini theorem.
Next we demonstrate that
is the minimal non-negative solution of (
4). We divide the proof into two steps.
We first define a sequence of kernels
by setting
, and
Let
be any solution of Equation (
4). Obviously,
. Suppose that
, then
for
. Moreover, we have
Similarly, if we assume inductively that
, we have
and so
is monotonically increasing in
N. Hence, the limit
exists. Further, we have
By taking the limit of both sides of Equation (
6) and using the dominated convergence theorem, we know that the kernel
is a solution of (
4), i.e.,
We further have that is the minimal solution since .
Next, we need to prove that
. Define
Obviously, we know that
. By conditioning on the state of the first transition, we have
By conditioning on the state of the first return time to level
and repeating the same arguments, we have
By (
8) and (
9), we can deduce that
Finally, note that
, and so from (
6), we have by induction
. Taking the limit as
gives
, as required. □
In the following, we will investigate numerical computing issues of the invariant probability distribution for M/G/1-type chains. The key point is to set up the Ramaswami algorithm, a well-known result for M/G/1-type chains with finite phases, for the M/G/1-type chains with continuous phases.
Theorem 5. Suppose that the M/G/1-type Markov chain is ψ-irreducible and Harris positive recurrent. Let the unique invariant probability measure be Π
with , . Then, the measure Π
satisfies the following recursive formulawhereand is a unique solution of the equation . Proof. By (
6), we know that for any
and
, the kernel function
is the probability that the Markov chain first returns to level
by hitting the state
, given that it starts from the state
. The transition kernel function of the Markov chain embedded at epochs of visits to the set
is given by
We now explain how to determine the transition kernel
. The first
k block columns of the kernel function
are the same as those of
, since the chain
can only move down by one level at a time. As for the
th (i.e., last) block column of
, its first entry is as follows.
The equality (
11) can be proved in a similar way.
Since this chain is -irreducible and a Harris positive recurrent, for , starting from x, the set M will almost certainly be returned infinitely, and so is the censored Markov chain . Thus, is also -irreducible and a Harris positive recurrent. Let be the unique invariant probability measure of .
Next, we will demonstrate that
is also an invariant measure of the censored chain
. Define the measure
by
By Propostion 10.4.8 in [
14], we know that
and that
is invariant measure for
. Since
is assumed to be a Harris positive recurrent, the invariant measure is unique up to a constant. This shows that
for some constant
c, from which and (
12), and we have
Since
, we can obtain
Thus, we have proved that
is an invariant measure of
. Taking into account the last block equation of
, we have
To determine
, we reset
and consider the censored chain
, whose transition kernel is given by
By (
13), we know that
. □
Applying Theorem 5 and performing the wavelet series expansion, we can obtain the following theorem directly.
Theorem 6. Suppose that the M/G/1-type Markov chain is ψ-irreducible and Harris positive recurrent and that Assumption 1 holds.
(i) The kernels , and are in , whose associated matrices satisfies that (ii) The invariant probability measure is in . Let be the associated row vector of . Then, the associated matrices satisfywhere . Remark 1. (i) We note that the entries in the associated matrices of a kernel function may be negative. Hence, the associated transition kernel matrices and cannot construct a stochastic transition matrix.
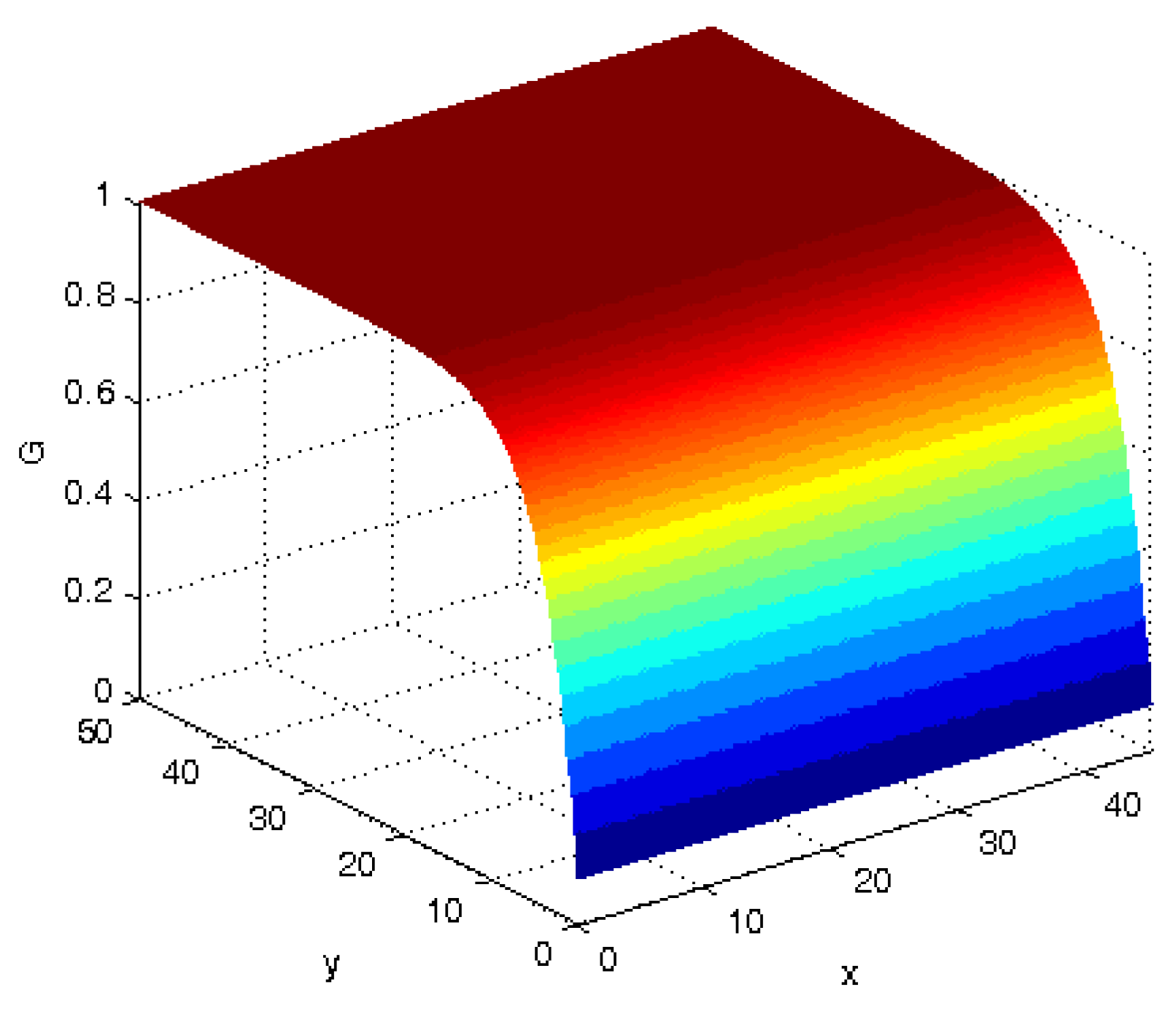
(ii) We now consider numerical algorithms for computing the associated matrix . In the literature, several known algorithms, including the functional iteration ([17,18]), Newton iteration ([19]), invariant subspace method ([20]), cyclic reduction ([21]) and Ramaswami Reduction ([22]), have been developed to solve the G-matrix for M/G/1-type chains with a finite phase. For a collection of these algorithms, please refer to [13]. Similar to what we did in Theorems 4 and 5, we can set up the corresponding algorithms for by modifying these algorithms from the finite phase to the general phase. We omit the details in order to avoid tedious presentations. 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






