
A Fresnel Cosine Integral WASD Neural Network for the Classification of Employee Attrition

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
- A 3-layer feed-forward FCI-WASD classification neural network is developed and the algorithms that handle its training and application are presented in detail.
- A detailed account is given regarding special features of the neural network, such as the implementation of a structure trimming technique as well as the incorporation of lexicographically ordered power tables in the determination of the neural network’s activation functions
- Techniques such as memoization and divide and conquer are applied to various parts of the training and testing procedure in order to speed up execution time.
- The FCI-WASD is applied to two publicly available, highly imbalanced datasets, which we bring into operational form by means of extensive preprocessing and undersampling.
- The performance of the FCI-WASD is compared to an already established WASD neural network as well as other well-performing, popular methods, such as a decision tree (Coarse Tree), a kernel naive Bayes model (KNB), logistic regression (LR) and a linear support vector machine (Linear SVM).
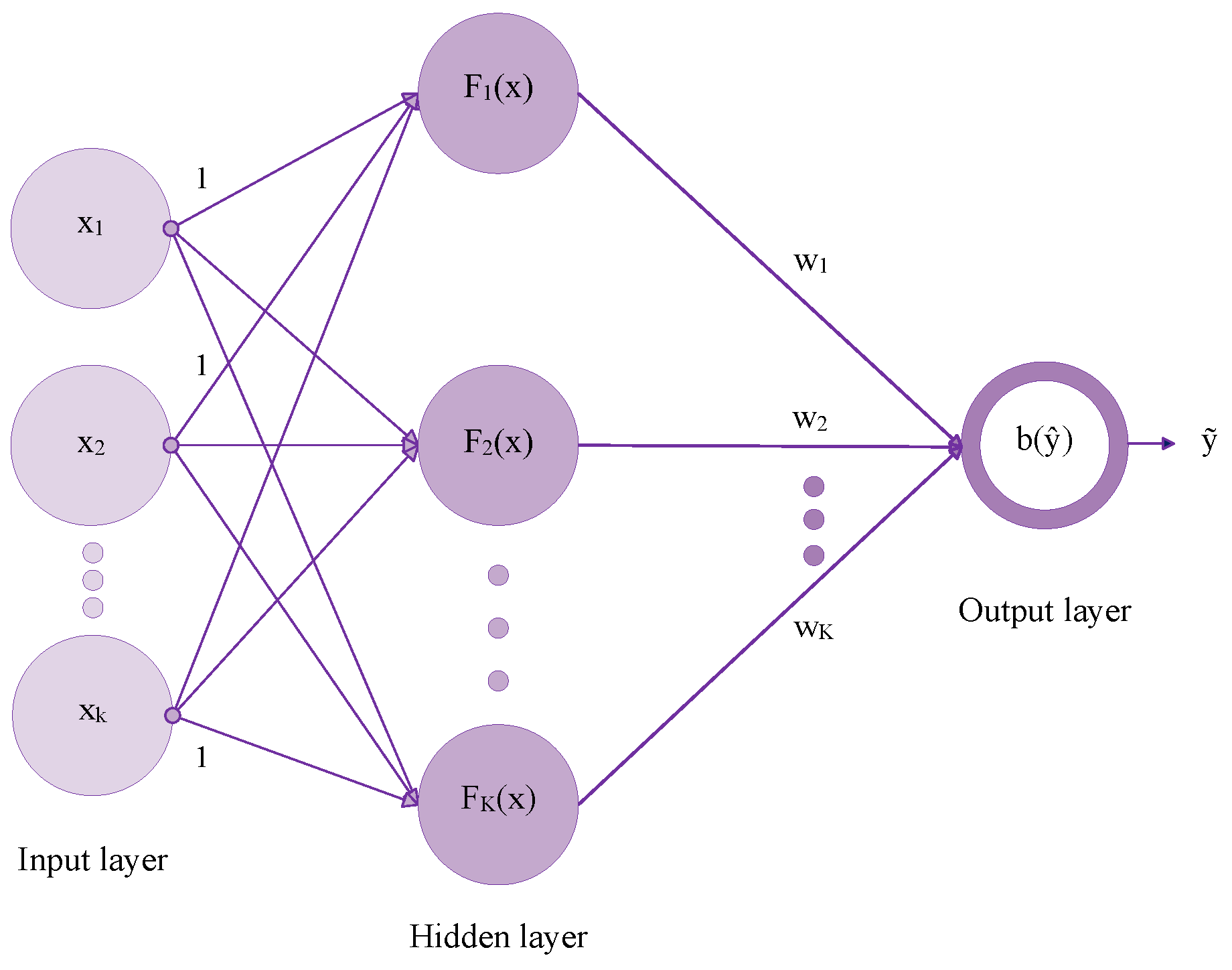
2. The FCI-WASD Classification Neural Network
2.1. Fresnel Cosine Integral Activation Functions, Power Tables and the WDD Process
- C.I: ;
- C.II: and the first nonzero entry of is positive.
| Algorithm 1 Creation of Power Tables | |
| Require: minimum number of rows , number of inputs k | |
| 1: | if then |
| 2: | set |
| 3: | else |
| 4: | initialize as an empty matrix and set |
| 5: | while number of rows in < do |
| 6: | increment by 1 |
| 7: | set to be an empty matrix |
| 8: | compute the m unique integer partitions of consisting of k integers . |
| 9: | for to m do |
| 10: | compute, as rows, the unique permutations of each integer partition |
| 11: | concatenate the resulting permutations to the bottom of |
| 12: | end for |
| 13: | sort by C.II of the graded lexicographic order and concatenate it to the bottom of |
| 14: | end while |
| 15: | end if |
| Ensure: | |
2.2. The WASD Training Algorithm of the FCI-WASD
- Which metric to use so as to keep track of training progress?
- How frequently will the training progress be monitored?
- What will the stopping criterion consist of?
- Will the network’s final structure retain all accumulated neurons?
- If not, then when and under which conditions should the neural network opt to discard neurons?
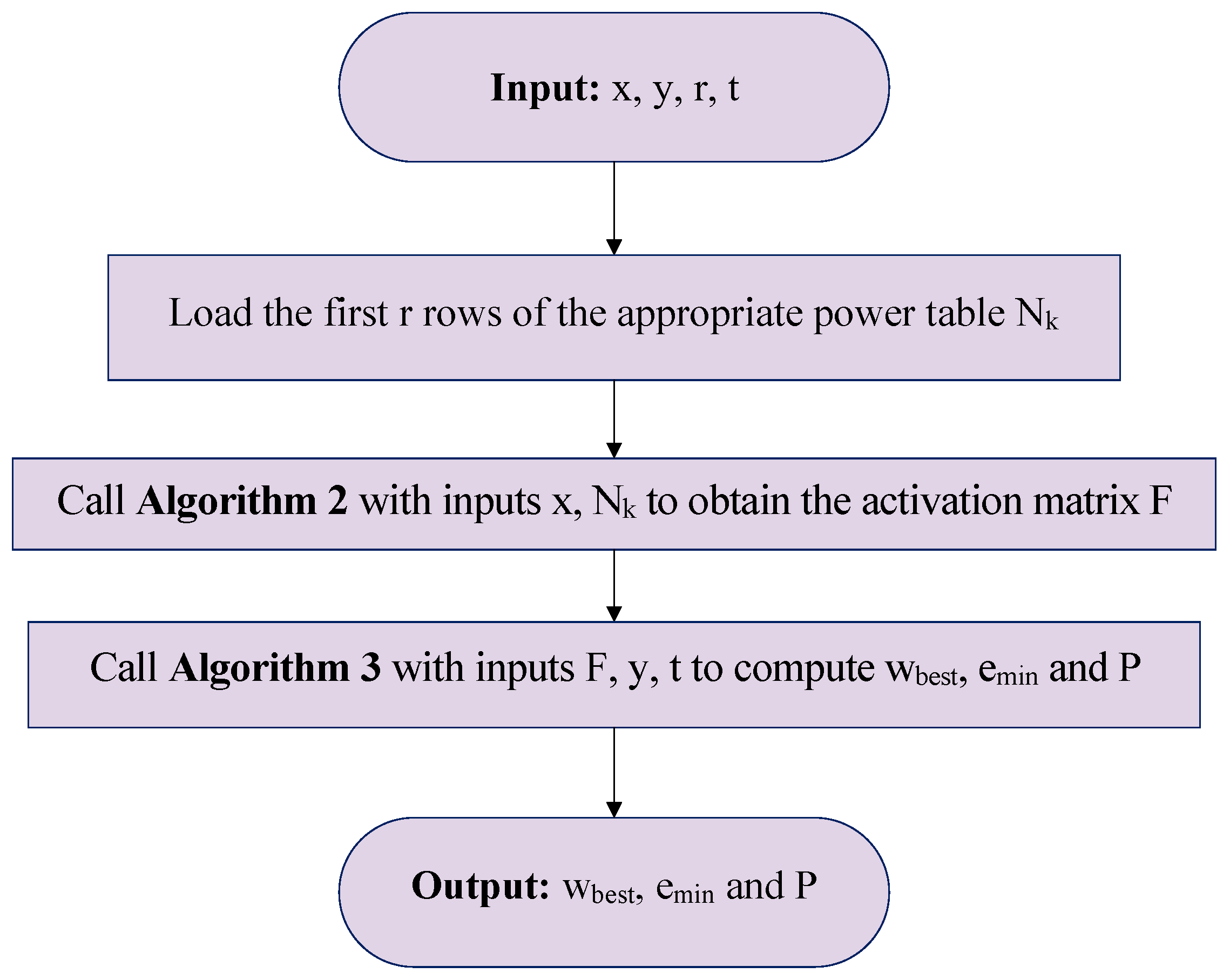
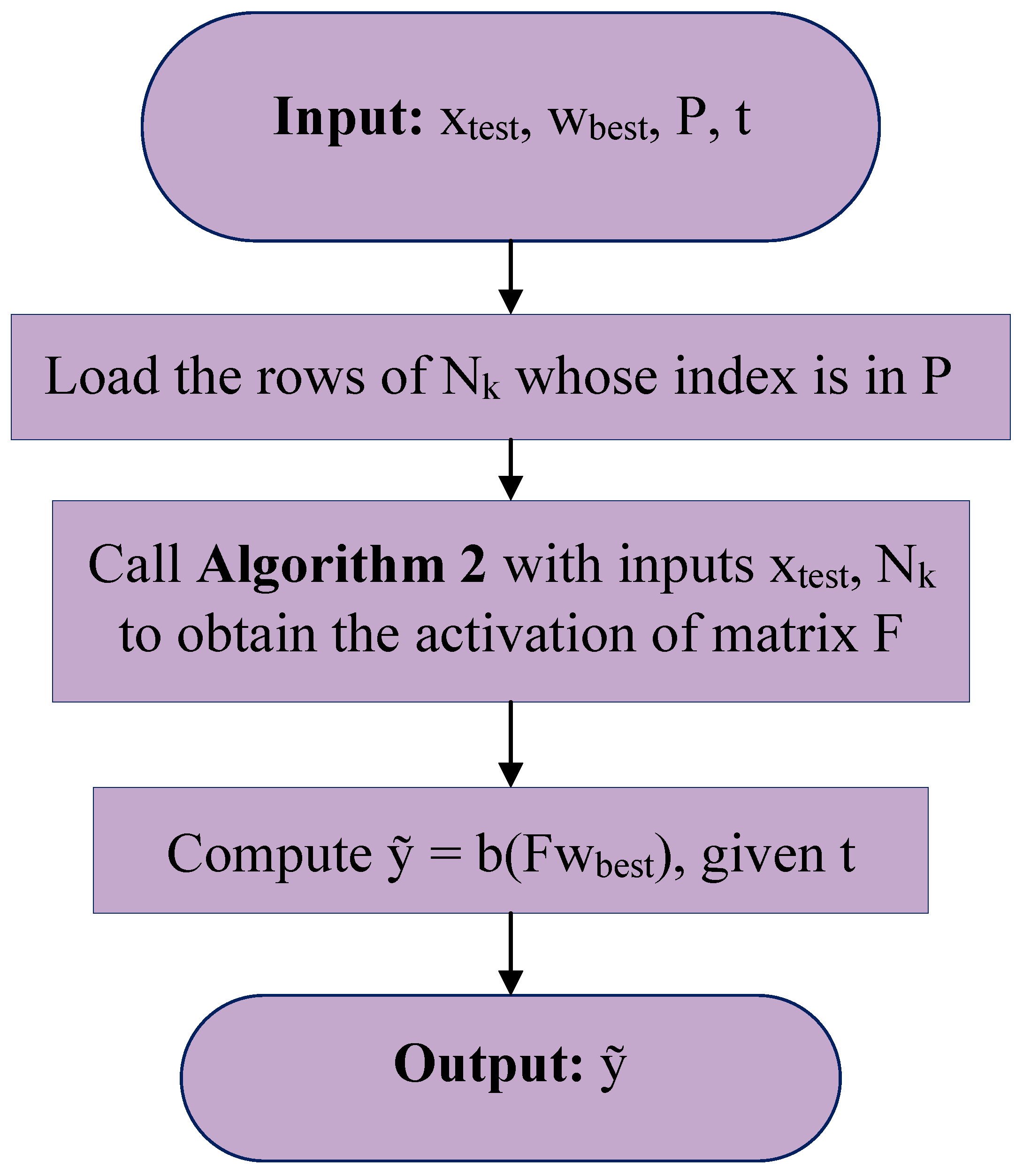
The Step by Step Process Cycle of Constructing and Employing the FCI-WASD
| Algorithm 2 Constructing the activation matrix F | |
| Require: The matrix of inputs x, the power table | |
| 1: | procedure ACTIVATIONMATRIX() |
| 2: | set the number of rows and columns, respectively, in x |
| 3: | set r the number of rows in and set = sum() |
| 4: | initialize the memo M as an NaN array |
| 5: | set F = zeros |
| 6: | for to r do |
| 7: | set f = zeros |
| 8: | for to k do |
| 9: | set n = |
| 10: | if sum(isnan()) == m then |
| 11: | set = , as in Equation (2) |
| 12: | end if |
| 13: | set = |
| 14: | end for |
| 15: | set = prod(f,2) |
| 16: | end for |
| 17: | end procedure |
| Ensure: The matrix F | |
| Algorithm 3 Hidden layer trimming process | |
| Require: The activation matrix F, the response vector y and a threshold | |
| 1: | |
| 2: | given t, as in Equation (1) |
| 3: | |
| 4: | set r the number of columns in F |
| 5: | |
| 6: | for to r do |
| 7: | kept = |
| 8: | f = kept) |
| 9: | |
| 10: | |
| 11: | |
| 12: | if then |
| 13: | |
| 14: | |
| 15: | P = kept |
| 16: | end if |
| 17: | end for |
| Ensure: The optimal weights vector , the final training , and the vector P containing the indices/positions of the essential neurons. | |
3. Applications on Employee Attrition Classification
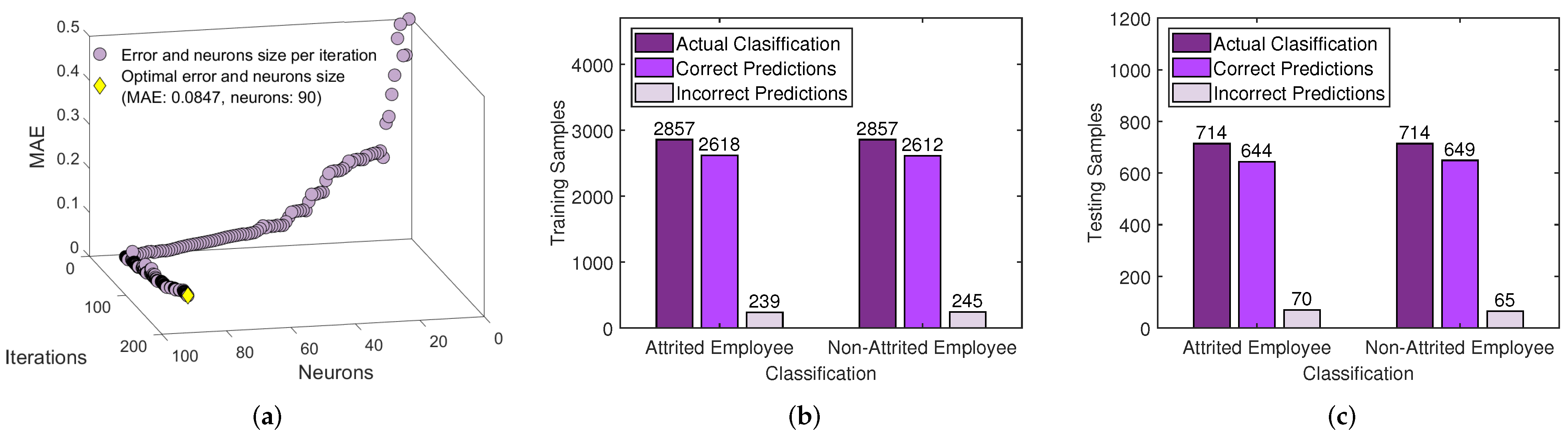
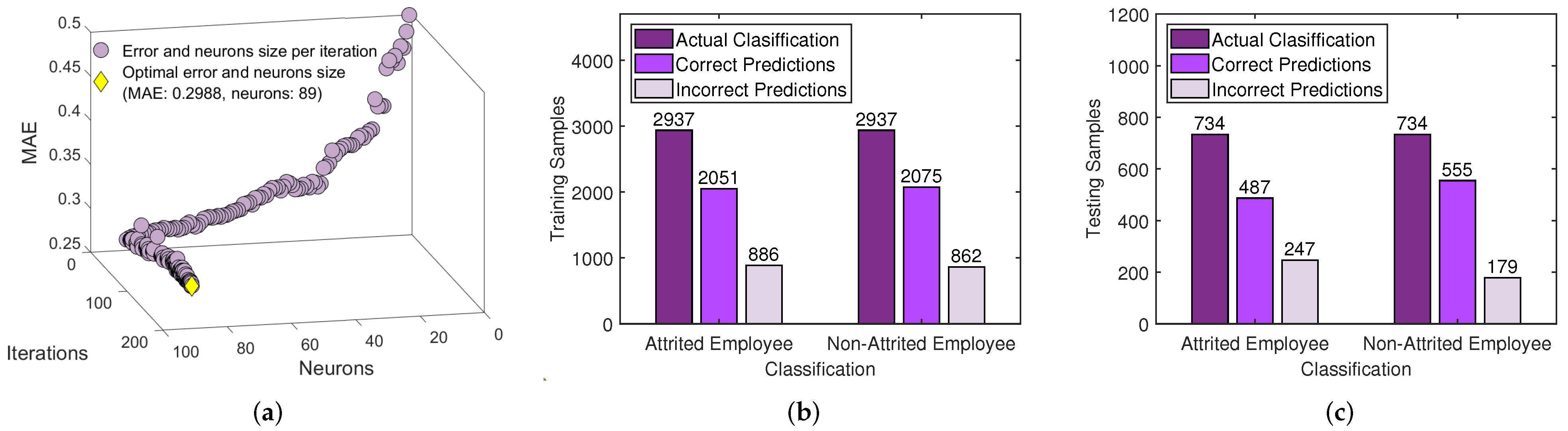
3.1. Employee Attrition Dataset I: Description and Preprocessing and Results of the FCI-WASD
3.2. Employee Attrition Dataset II: Description, Preprocessing and Results of the FCI-WASD
3.3. Collective Results, Model Comparison and Statistical Tests
4. Conclusions
- Extension of the FCI-WASD to a multi-layer neural network could perhaps boost its performance and thus may be worth investigating.
- An ensemble classifier consisting of WASD models may also lead to a high performance model, therefore such a task may be worth considering.
- One could also investigate the comparison between WASD and radial basis function neural networks, or even experimenting with other transfer functions other than Fresnel cosine integrals, such as sigmoid, softplus, etc.
- Finally, to have the chance to test the FCI-WASD on an even larger, real world dataset, would be both a challenge as well as a tremendous opportunity that would help in asserting with confidence whether the model has stepped in the right direction as well as whether it is capable of bringing value to a company.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alsheref, F.K.; Fattoh, I.E.; M Ead, W. Automated prediction of employee attrition using ensemble model based on machine learning algorithms. Comput. Intell. Neurosci. 2022, 2022, 7728668. [Google Scholar] [CrossRef]
- Sexton, R.S.; McMurtrey, S.; Michalopoulos, J.O.; Smith, A.M. Employee turnover: A neural network solution. Comput. Oper. Res. 2005, 32, 2635–2651. [Google Scholar] [CrossRef]
- Al-Darraji, S.; Honi, D.G.; Fallucchi, F.; Abdulsada, A.I.; Giuliano, R.; Abdulmalik, H.A. Employee attrition prediction using deep neural networks. Computers 2021, 10, 141. [Google Scholar] [CrossRef]
- Hom, P.W.; Lee, T.W.; Shaw, J.D.; Hausknecht, J.P. One hundred years of employee turnover theory and research. J. Appl. Psychol. 2017, 102, 530–545. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Hryniewicki, M.K.; Cheng, F.; Fu, B.; Zhu, X. Employee turnover prediction with machine learning: A reliable approach. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 6–7 September 2018; pp. 737–758. [Google Scholar] [CrossRef]
- Mansor, N.; Sani, N.S.; Aliff, M. Machine learning for predicting employee attrition. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 435–445. [Google Scholar] [CrossRef]
- Simos, T.E.; Mourtas, S.D.; Katsikis, V.N. Time-varying Black-Litterman portfolio optimization using a bio-inspired approach and neuronets. Appl. Soft Comput. 2021, 112, 107767. [Google Scholar] [CrossRef]
- Leung, M.F.; Wang, J. Cardinality-constrained portfolio selection based on collaborative neurodynamic optimization. Neural Netw. 2022, 145, 68–79. [Google Scholar] [CrossRef]
- Leung, M.F.; Wang, J. Minimax and biobjective portfolio selection based on collaborative neurodynamic optimization. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2825–2836. [Google Scholar] [CrossRef]
- Bai, L.; Zheng, K.; Wang, Z.; Liu, J. Service provider portfolio selection for project management using a BP neural network. Ann. Oper. Res. 2022, 308, 41–62. [Google Scholar] [CrossRef]
- Yaman, I.; Dalkılıç, T.E. A hybrid approach to cardinality constraint portfolio selection problem based on nonlinear neural network and genetic algorithm. Expert Syst. Appl. 2021, 169, 114517. [Google Scholar] [CrossRef]
- Mourtas, S.D.; Katsikis, V.N. Exploiting the Black-Litterman framework through error-correction neural networks. Neurocomputing 2022, 498, 43–58. [Google Scholar] [CrossRef]
- Katsikis, V.N.; Mourtas, S.D. Diversification of time-varying tangency portfolio under nonlinear constraints through semi-integer beetle antennae search algorithm. AppliedMath 2021, 1, 63–73. [Google Scholar] [CrossRef]
- Katsikis, V.N.; Mourtas, S.D. Computational Management. In Modeling and Optimization in Science and Technologies; Chapter Portfolio Insurance and Intelligent Algorithms; Springer: Cham, Switzerland, 2021; Volume 18, pp. 305–323. [Google Scholar] [CrossRef]
- Mourtas, S.D.; Katsikis, V.N.; Drakonakis, E.; Kotsios, S. Stabilization of stochastic exchange rate dynamics under central bank intervention using neuronets. Int. J. Inf. Technol. Decis. 2023, 22, 855–883. [Google Scholar] [CrossRef]
- Simos, T.E.; Katsikis, V.N.; Mourtas, S.D. Multi-input bio-inspired weights and structure determination neuronet with applications in European Central Bank publications. Math. Comput. Simul. 2022, 193, 451–465. [Google Scholar] [CrossRef]
- Guo, D.; Nie, Z.; Yan, L. Novel discrete-time Zhang neural network for time-varying matrix inversion. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 2301–2310. [Google Scholar] [CrossRef]
- Jin, L.; Zhang, Y.; Li, S. Integration-enhanced Zhang neural network for real-time-varying matrix inversion in the presence of various kinds of noises. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 2615–2627. [Google Scholar] [CrossRef]
- Mao, M.; Li, J.; Jin, L.; Li, S.; Zhang, Y. Enhanced discrete-time Zhang neural network for time-variant matrix inversion in the presence of bias noises. Neurocomputing 2016, 207, 220–230. [Google Scholar] [CrossRef]
- Liao, B.; Xiao, L.; Jin, J.; Ding, L.; Liu, M. Novel complex-valued neural network for dynamic complex-valued matrix inversion. J. Adv. Comput. Intell. Intell. Inform. 2016, 20, 132–138. [Google Scholar] [CrossRef]
- Chen, K.; Yi, C. Robustness analysis of a hybrid of recursive neural dynamics for online matrix inversion. Appl. Math. Comput. 2016, 273, 969–975. [Google Scholar] [CrossRef]
- Zhang, Y.; Jin, L.; Guo, D.; Fu, S.; Xiao, L. Three nonlinearly-activated discrete-time ZNN models for time-varying matrix inversion. In Proceedings of the 8th International Conference on Natural Computation, Chongqing, China, 29–31 May 2012; pp. 163–167. [Google Scholar] [CrossRef]
- Jia, L.; Xiao, L.; Dai, J.; Cao, Y. A novel fuzzy-power zeroing neural network model for time-variant matrix Moore-Penrose inversion with guaranteed performance. IEEE Trans. Fuzzy Syst. 2021, 29, 2603–2611. [Google Scholar] [CrossRef]
- Precup, R.E.; Tomescu, M.L.; Preitl, S.; Petriu, E.M. Fuzzy logic-based stabilization of nonlinear time-varying systems. Int. J. Artif. Intell. 2009, 3, 24–36. [Google Scholar]
- Precup, R.E.; Tomescu, M.L.; Dragos, C.A. Stabilization of Rössler chaotic dynamical system using fuzzy logic control algorithm. Int. J. Gen. Syst. 2014, 43, 413–433. [Google Scholar] [CrossRef]
- Huang, C.; Jia, X.; Zhang, Z. A modified back propagation artificial neural network model based on genetic algorithm to predict the flow behavior of 5754 aluminum alloy. Materials 2018, 11, 855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.; Liu, P.X.; Liu, S. Adaptive neural synchronization control for bilateral teleoperation systems with time delay and backlash-like hysteresis. IEEE Trans. Cybern. 2017, 47, 3018–3026. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wang, J. Obstacle avoidance of redundant manipulators using a dual neural network. In Proceedings of the IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 2747–2752. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, H.; Zhang, Z.; Xiao, L.; Guo, D. Acceleration-level repetitive motion planning of redundant planar robots solved by a simplified LVI-based primal-dual neural network. Robot. Comput.-Integr. Manuf. 2013, 29, 328–343. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, X.; Xiao, L.; Li, W.; Fan, Z.; Zhang, W. Weights and structure determination of articial neuronets. In Self-Organization: Theories and Methods; Nova Science: New York, NY, USA, 2013. [Google Scholar]
- Zhang, Y.; Chen, D.; Ye, C. Deep Neural Networks: WASD Neuronet Models, Algorithms, and Applications; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Simos, T.E.; Katsikis, V.N.; Mourtas, S.D. A fuzzy WASD neuronet with application in breast cancer prediction. Neural Comput. Appl. 2021, 34, 3019–3031. [Google Scholar] [CrossRef]
- Simos, T.E.; Katsikis, V.N.; Mourtas, S.D. A multi-input with multi-function activated weights and structure determination neuronet for classification problems and applications in firm fraud and loan approval. Appl. Soft Comput. 2022, 127, 109351. [Google Scholar] [CrossRef]
- Gupta, A.K. Numerical Methods Using MATLAB; MATLAB Solutions Series, Berkley; Springer Press: New York, NY, USA, 2014. [Google Scholar]
- HR Dataset. Available online: https://www.kaggle.com/datasets/kadirduran/hr-dataset?resource=download. (accessed on 2 February 2023).
- Capstone Project-IBM Employee Attrition Prediction. Available online: https://www.kaggle.com/datasets/rushikeshghate/capstone-projectibm-employee-attrition-prediction?resource=download. (accessed on 2 February 2023).
- Fagerland, M.W.; Lydersen, S.; Laake, P. The McNemar test for binary matched-pairs data: Mid-p and asymptotic are better than exact conditional. BMC Med. Res. Methodol. 2013, 13, 91. [Google Scholar] [CrossRef] [PubMed] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Dataset | FCI-WASD | Chebyshev WASD | Coarse Tree | |||
|---|---|---|---|---|---|---|
| EA.I | EA.II | EA.I | EA.II | EA.I | EA.II | |
| MAE | 0.09453 | 0.29019 | 0.12255 | 0.33038 | 0.11415 | 0.34401 |
| TP | 0.90896 | 0.75613 | 0.94118 | 0.83515 | 0.94258 | 0.67302 |
| FP | 0.09103 | 0.24387 | 0.05882 | 0.16485 | 0.05742 | 0.32698 |
| TN | 0.90196 | 0.66349 | 0.81373 | 0.50409 | 0.82913 | 0.63896 |
| FN | 0.09803 | 0.33651 | 0.18627 | 0.49591 | 0.17087 | 0.36104 |
| Precision | 0.90896 | 0.75613 | 0.94118 | 0.83515 | 0.94258 | 0.67302 |
| Recall | 0.90264 | 0.69202 | 0.83478 | 0.62743 | 0.84654 | 0.65086 |
| Accuracy | 0.90546 | 0.70981 | 0.87745 | 0.66962 | 0.88585 | 0.65599 |
| F-measure | 0.90579 | 0.72266 | 0.88479 | 0.71654 | 0.89198 | 0.66175 |
| Model Dataset | KNB | LR | Linear SVM | |||
| EA.I | EA.II | EA.I | EA.II | EA.I | EA.II | |
| MAE | 0.14426 | 0.32629 | 0.23459 | 0.30245 | 0.21499 | 0.29837 |
| TP | 0.81373 | 0.55995 | 0.80392 | 0.68665 | 0.87395 | 0.68529 |
| FP | 0.18627 | 0.44005 | 0.19608 | 0.31335 | 0.12605 | 0.31471 |
| TN | 0.89776 | 0.78747 | 0.72689 | 0.70845 | 0.69608 | 0.71798 |
| FN | 0.10224 | 0.21253 | 0.27311 | 0.29155 | 0.30392 | 0.28202 |
| Precision | 0.81373 | 0.55995 | 0.80392 | 0.68665 | 0.87395 | 0.68529 |
| Recall | 0.88838 | 0.72487 | 0.74642 | 0.70195 | 0.74197 | 0.70845 |
| Accuracy | 0.85574 | 0.67371 | 0.76541 | 0.69755 | 0.78501 | 0.70163 |
| F-measure | 0.84942 | 0.63182 | 0.77411 | 0.69421 | 0.80257 | 0.69668 |
| FCI-WASD vs. | EA.I | EA.II | ||
|---|---|---|---|---|
| Null Hypothesis | p-Value | Null Hypothesis | p-Value | |
| Coarse Tree | Rejected | 0.018056 | Rejected | 3.757 × 10 |
| KNB | Rejected | 1.7245 × 10 | Rejected | 0.010873 |
| LR | Rejected | 1.3126 × 10 | Not rejected | 0.29788 |
| Linear SVM | Rejected | 3.1406 × 10 | Not rejected | 0.49207 |
| Chebyshev WASD | Rejected | 0.00016552 | Rejected | 0.00055711 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alharbi, H.; Alshammari, O.; Jerbi, H.; Simos, T.E.; Katsikis, V.N.; Mourtas, S.D.; Sahas, R.D. A Fresnel Cosine Integral WASD Neural Network for the Classification of Employee Attrition. Mathematics 2023, 11, 1506. https://doi.org/10.3390/math11061506
Alharbi H, Alshammari O, Jerbi H, Simos TE, Katsikis VN, Mourtas SD, Sahas RD. A Fresnel Cosine Integral WASD Neural Network for the Classification of Employee Attrition. Mathematics. 2023; 11(6):1506. https://doi.org/10.3390/math11061506
Chicago/Turabian StyleAlharbi, Hadeel, Obaid Alshammari, Houssem Jerbi, Theodore E. Simos, Vasilios N. Katsikis, Spyridon D. Mourtas, and Romanos D. Sahas. 2023. "A Fresnel Cosine Integral WASD Neural Network for the Classification of Employee Attrition" Mathematics 11, no. 6: 1506. https://doi.org/10.3390/math11061506