
Predicting the Future Appearances of Lost Children for Information Forensics with Adaptive Discriminator-Based FLM GAN

 , , and
, , and
Abstract
:1. Introduction
2. Related Works
3. Major Contribution
- The proposed approach generates future faces that help to continue the investigation, using the Tufts [4] dataset.
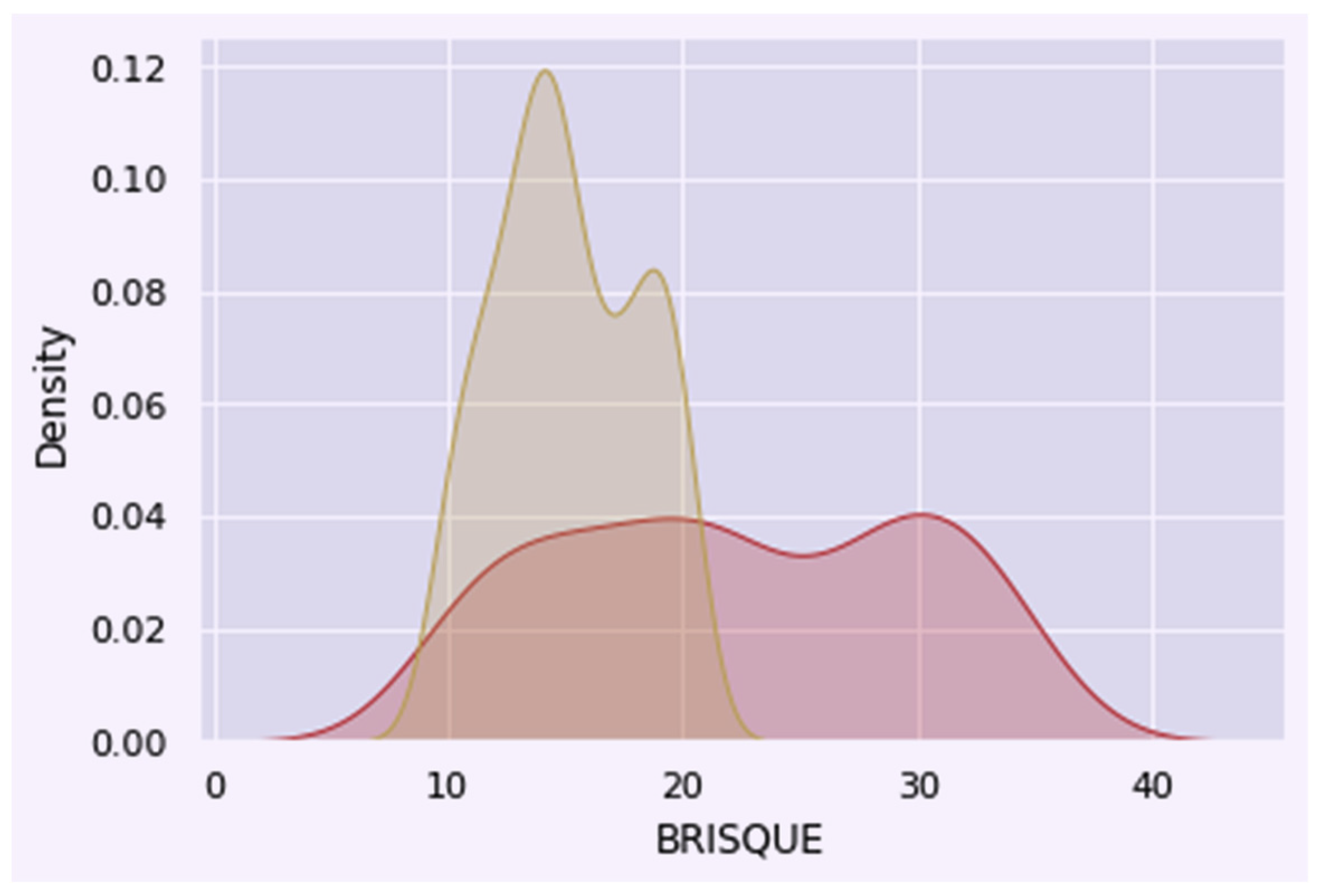
- The BRISQUE quality metrics are analyzed to illustrate model-generated images’ visual quality using KINFACE I and KINFACE II datasets.
- An extensive experiment was carried out to compare the original parent image with the model-generated children’s ideas of equal age using MSE, MSSSIM, ERGAS, SCC, RASE, SAM, and VIFP.
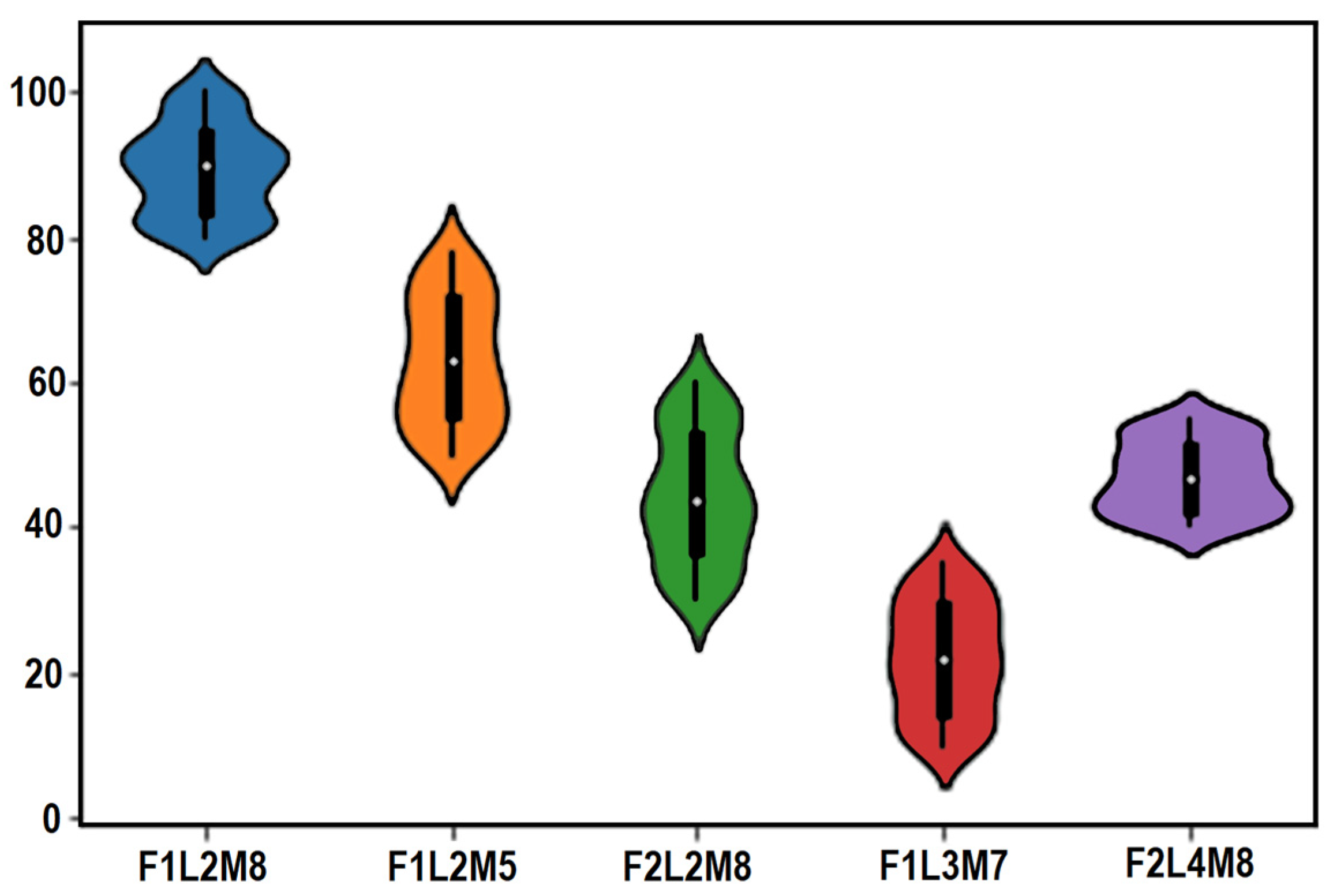
- Various hyper parameters such as F1L2M8, F2L3M5, F2L2M8, F1L3M7, and F2L4M3 compare the proposed model-generated images.
4. Background Analysis
- Multidimensional Cauchy distribution can be used to fill the latent space for any random variable u:
- In the absence of an appropriate moment generating function, the characteristic function is defined as follows:
- The value of distribution greater than one may produce a negative impact on the GAN training process. It leads to the inappropriate formation of data points for generator-generated samples.
- In order to train the proposed GAN model with latent space , independent random variables distributed with a fixed latent probability distribution as follows:
- The augmentation strategies in our proposed work are closely related to the approaches referred to as random masking [16]. This combines regularizing with augmentation of the existing data for better model performance: the projection of a random subset of dimension interpreted by cut-out augmentation. For a set of deterministic projections , the condition is defined as . Such projections include pixel permutation [17], scaling, and squeezing [18,19,20]. The discrete probabilities to choose identity operator are . For remaining discrete probabilities, it is RK. The mixed form of the projection is represented as follows:
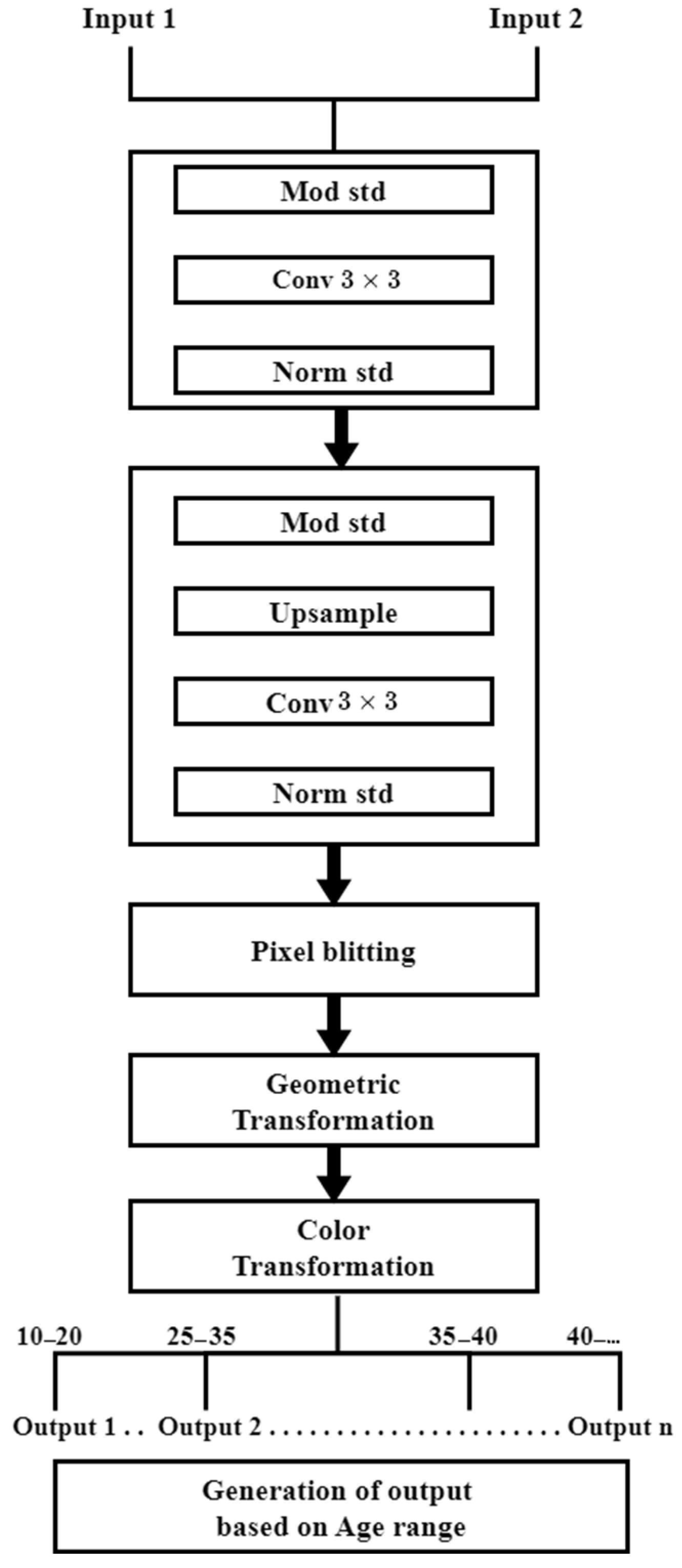
5. Proposed Method
5.1. Data Augmentation
5.2. Pixel Blitting
5.3. Geometric Transformation
5.4. Color Transformation
6. Results
6.1. The proposed model accuracy evaluation with Similarity Index Evaluation Metrices
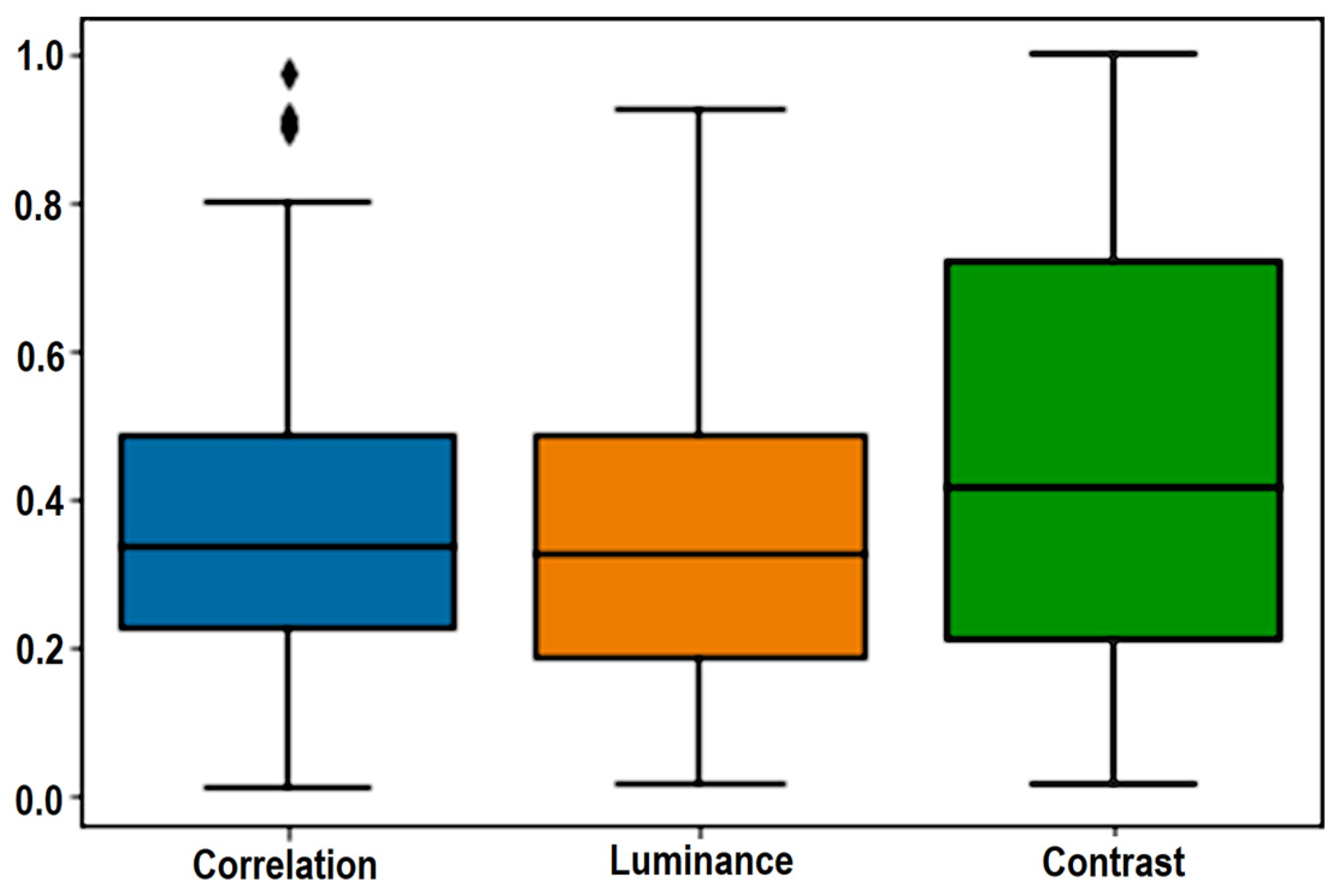
6.2. FLM Model Performance Evaluation-Based Multiscale Extension, Spectral Property, and Visual Information
6.3. Experiment carried out for the Level of Distortion Using Universal Quality Index
6.4. Experiment for the Level of Distortion Using Universal Quality Index
6.5. Experiment for Hyperparameter Selection
6.6. Comparison Carried Out with Other Related Models
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Convolution Kernel | |
| Feature extraction function | |
| Latent Feature | |
| Cauchy Distribution | |
| For any random variable | |
| Generating Function | |
| Independent random variable distributed with fixed latent | |
| Set of deterministic projection | |
| Identity Operator | |
| and | Unique Distribution |
| Transformation Variable | |
| Rotation Angle | |
| Variable for padding | |
| (.) | Uniform Distribution |
| Pixel value accumulated into matrix for image | |
| Translation Matrix |
References
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. Adv. Neural Inf. Process. Syst. 2020, 33, 12104–12114. [Google Scholar]
- Kennett, D. Using genetic genealogy databases in missing persons cases and to develop suspect leads in violent crimes. Forensic Sci. Int. 2019, 301, 107–117. [Google Scholar] [CrossRef] [PubMed]
- Tong, C.; Li, Y.; Jacob, A.P.; Bengio, Y.; Li, W. Mode regularized generative adversarial networks. arXiv 2016, arXiv:1612.02136. [Google Scholar]
- Karen, P.; Wan, Q.; Agaian, S.; Rajeev, S.; Kamath, S.; Rajendran, R.; Rao, S.; Rao, S.P.; Kaszowska, A.; Taylor, H.; et al. A comprehensive database for benchmarking imaging systems. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 509–520. [Google Scholar]
- Teterwak, P.; Sarna, A.; Krishnan, D.; Maschinot, A.; Belanger, D.; Liu, C.; Freeman, W.T. Boundless: Generative adversarial networks for image extension. In Proceedings of the IEEE/CVF International Conference on Computer Vision, San Francisco, CA, USA, 19 June 1985; pp. 10521–10530. [Google Scholar]
- Cai, Z.; Xiong, Z.; Xu, H.; Wang, P.; Li, W.; Pan, Y. Generative adversarial networks: A survey toward private and secure applications. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Jabbar, A.; Li, X.; Omar, B. A survey on generative adversarial networks: Variants, applications, and training. ACM Comput. Surv. (CSUR) 2021, 54, 1–49. [Google Scholar] [CrossRef]
- Pascual, S.; Bonafonte, A.; Serra, J. SEGAN: Speech enhancement generative adversarial network. arXiv 2017, arXiv:1703.09452. [Google Scholar]
- Yufan, Z.; Chen, C.; Xu, J. Learning High-Dimensional Distributions with Latent Neural Fokker-Planck Kernels. arXiv 2021, arXiv:2105.04538. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhang, H.; Venkatesh, S.; Ramachandra, R.; Raja, K.; Damer, N.; Busch, C. MIPGAN-Generating Strong and High Quality Morphing Attacks Using Identity Prior Driven GAN. IEEE Trans. Biom. Behav. Identity Sci. 2021, 3, 365–383. [Google Scholar] [CrossRef]
- Schaefer, S.; McPhail, T.; Warren, J. Image deformation using moving least squares. In ACM SIGGRAPH 2006 Papers; Association for Computing Machinery: New York, NY, USA, 2006; pp. 533–540. [Google Scholar]
- Bichsel, M. Automatic interpolation and recognition of face images by morphing. In Proceedings of the Second International Conference on Automatic Face and Gesture Recognition, Killington, Vermont, 14–16 October 1996; IEEE: New York, NY, USA, 1996. [Google Scholar]
- Makrushin, A.; Neubert, T.; Dittmann, J. Automatic generation and detection of visually faultless facial morphs. In Proceedings of the International Conference on Computer Vision Theory and Applications, Porto, Portugal, 27 February–1 March 2017; SciTePress: Setubal, Portugal, 2017. [Google Scholar]
- Tero, K.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Anwar, S.; Meghana, S. A pixel permutation based image encryption technique using chaotic map. Multimed. Tools Appl. 2019, 78, 27569–27590. [Google Scholar] [CrossRef]
- Atkins, C.B.; Bouman, C.A.; Allebach, J.P. Optimal image scaling using pixel classification. In Proceedings of the 2001 International Conference on Image Processing (Cat. No. 01CH37205), Thessaloniki, Greece, 7–10 October 2001; IEEE: New York, NY, USA, 2001. [Google Scholar]
- Jamitzky, F.; Stark, R.W.; Bunk, W.; Thalhammer, S.; Räth, C.; Aschenbrenner, T.; Morfill, G.E.; Heckl, W.M. Scaling-index method as an image processing tool in scanning-probe microscopy. Ultramicroscopy 2001, 86, 241–246. [Google Scholar] [CrossRef] [PubMed]
- Prashanth, H.S.; Shashidhara, H.L.; Murthy, K.B. Image scaling comparison using universal image quality index. In Proceedings of the 2009 International Conference on Advances in Computing, Control, and Telecommunication Technologies, Bangalore, India, 28–29 December 2009; IEEE: New York, NY, USA, 2009. [Google Scholar]
- Bora, A.; Price, E.; Dimakis, A.G. AmbientGAN: Generative Models from Lossy Measurements, Vancouver Convention Center, Vancouver, BC, Canada, 30 April–3 May 2018; ICLR, 2018. [Google Scholar]
- The CIFAR-10 Dataset. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 2 February 2023).
- Rouse, D.M.; Hemami, S.S. Understanding and simplifying the structural similarity metric. In Proceedings of the 15th International Conference on Image Processing, Vietri sul Mare, Italy, 12 October 2008; IEEE: New York, NY, USA, 2008; pp. 1188–1191. [Google Scholar]
- Renza, D.; Martinez, E.; Arquero, A. A new approach to change detection in multispectral images by means of ERGAS index. IEEE Geosci. Remote Sens. Lett. 2012, 10, 76–80. [Google Scholar]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar]
- Yang, C.; Everitt, J.H.; Bradford, J.M. Yield estimation from hyperspectral imagery using spectral angle mapper (SAM). Trans. ASABE 2008, 51, 729–737. [Google Scholar] [CrossRef]
- Kuo, T.Y.; Su, P.C.; Tsai, C.M. Improved visual information fidelity based on sensitivity characteristics of digital images. J. Vis. Commun. Image Represent. 2016, 40, 76–84. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C. A universal image quality index. IEEE Signal Process. Lett. 2002, 9, 81–84. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. Blind/referenceless image spatial quality evaluator. In Proceedings of the Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR), Pacific Grove, CA, USA, 6–9 November 2011; IEEE: New York, NY, USA, 2011; pp. 723–727. [Google Scholar]
- Lu, J.; Zhou, X.; Tan, Y.P.; Shang, Y.; Zhou, J. Neighborhood repulsed metric learning for kinship verification. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 7, 331–345. [Google Scholar]
- Psychological Image Collection at Stirling (PICS). Available online: http://pics.psych.stir.ac.uk/2D_face_sets.htm (accessed on 12 January 2023).
- FEI Face Database. Available online: http://fei.edu.br/~cet/facedatabase.htm (accessed on 8 February 2023).
- Eklavya, S.; Korshunov, P.; Colbois, L.; Marcel, S. Vulnerability analysis of face morphing attacks from landmarks and generative adversarial networks. arXiv 2020, arXiv:2012.05344. [Google Scholar]
- Khan, M.; Chakraborty, S.; Astya, R.; Khepra, S. Face detection and recognition using OpenCV. In Proceedings of the 2019 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 18–19 October 2019; pp. 116–119. [Google Scholar]
- Phillips, P.J.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 4, 295–306. [Google Scholar]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 947–954. [Google Scholar]
- Kozyra, K.; Trzyniec, K.; Popardowski, E.; Stachurska, M. Application for Recognizing Sign Language Gestures Based on an Artificial Neural Network. Sensors 2022, 22, 9864. [Google Scholar] [CrossRef] [PubMed]
- Back, T.; Gunter, R.; Hans-Paul, S. Evolutionary Programming and Evolution Strategies: Similarities and Differences. In Proceedings of the Second Annual Conference on Evolutionary Programming, Evolutionary Programming Society, San Francisco, CA, USA, 10–12 July 1993; pp. 11–22. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Proceedings of the 30th Conference on Neural Information Processing System (NIPS), Bercelona, Spain, 5–10 December 2016. [Google Scholar]
- Federic, P.; Keith, W. Computer Facial Animation; AK Peters: Wellesley, MA, USA, 1996. [Google Scholar]
- Lecture Notes Series on Computing: Volume 4, Computing in Euclidean Geometry, 2nd ed.; World Scientific: Singapore, 1995; pp. 225–265. Available online: https://www.worldscientific.com/worldscibooks/10.1142/2463#t=aboutBook (accessed on 11 December 2022).
- Das, H.S.; Das, A.; Neog, A.; Mallik, S.; Bora, K.; Zhao, Z. Early detection of Parkinson’s disease using fusion of discrete wavelet transformation and histograms of oriented gradients. Mathematics 2022, 10, 4218. [Google Scholar] [CrossRef]
- Ghosh, S.; Banerjee, S.; Das, S.; Hazra, A.; Mallik, S.; Zhao, Z.; Mukherji, A. Evaluation and Optimization of Biomedical Image-Based Deep Convolutional Neural Network Model for COVID-19 Status Classification. Appl. Sci. 2022, 12, 10787. [Google Scholar] [CrossRef]
- Bhandari, M.; Neupane, A.; Mallik, S.; Gaur, L.; Qin, H. Auguring Fake Face Images Using Dual Input Convolution Neural Network. J. Imaging 2022, 9, 3. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Chen, K.; Xu, Y. Study of face recognition technology based on STASM and its application in video retrieval. In Computational Intelligence, Networked Systems and Their Applications: International Conference of Life System Modeling and Simulation, LSMS 2014 and International Conference on Intelligent Computing for Sustainable Energy and Environment, ICSEE 2014, Shanghai, China, 20–23 September 2014, Proceedings, Part II; Springer: Berlin/Heidelberg, Germany, 2014; pp. 219–227. [Google Scholar]
- Milborrow, S.; Nicolls, F. Active Shape Models with SIFT Descriptors and MARS; VISAPP: Setubal, Portugal, 2014. [Google Scholar]
- Saladi, S.; Karuna, Y.; Koppu, S.; Reddy, G.R.; Mohan, S.; Mallik, S.; Qin, H. Segmentation and Analysis Emphasizing Neonatal MRI Brain Images Using Machine Learning Techniques. Mathematics 2023, 11, 285. [Google Scholar] [CrossRef]
- Bora, K.; Mahanta, L.B.; Borah, K.; Chyrmang, G.; Barua, B.; Mallik, S.; Zhao, Z. Machine Learning Based Approach for Automated Cervical Dysplasia Detection Using Multi-Resolution Transform Domain Features. Mathematics 2022, 10, 4126. [Google Scholar] [CrossRef]
- Levi, O.; Mallik, M..; Arava, Y.S. ThrRS-Mediated Translation Regulation of the RNA Polymerase III Subunit RPC10 Occurs through an Element with Similarity to Cognate tRNA ASL and Affects tRNA Levels. Genes 2023, 14, 462. [Google Scholar] [CrossRef]
- Mallik, S.; Seth, S.; Bhadra, T.; Zhao, Z. A Linear Regression and Deep Learning Approach for Detecting Reliable Genetic Alterations in Cancer Using DNA Methylation and Gene Expression Data. Genes 2020, 11, 931. [Google Scholar] [CrossRef]
- Mallik, S.; Mukhopadhyay, A.; Maulik, U. ANWAR: Rank-based weighted association rule mining from gene expression and methylation data. IEEE Trans. Nanobioscience 2014, 14, 59–66. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Generated Image | Original Image | MSE | RMSE | PSNR | SSIM |
|---|---|---|---|---|---|
 |  | 3505.1024 | 40.0425 | 12.5616 | (0.3667, 0.5163) |
 |  | 3605.1084 | 30.0425 | 11.4312 | (0.4334, 0.5132) |
 |  | 1505.1034 | 48.0316 | 13.2114 | (0.4667, 0.4328) |
 |  | 1202.6273 | 41.8561 | 11.1255 | (0.4107, 0.4630) |
 |  | 1403.6883 | 42.5757 | 13.2367 | (0.5817, 0.5532) |
 |  | 1515.6861 | 41.5731 | 14.1244 | (0.3836, 0.4111) |
 |  | 6419.2100 | 80.1199 | 10.0559 | (0.2712, 0.3246) |
 |  | 1906.7972 | 43.6668 | 15.3277 | (0.4908, 0.5103) |
| Model Generated Image | Original Image | MSE | RMSE | PSNR | SSIM |
|---|---|---|---|---|---|
 |  | 2235.0545 | 50.3423 | 12.8512 | (0.5127, 0.5687) |
 |  | 2347.4649 | 45.3470 | 14.2722 | (0.5032, 0.6289) |
 |  | 2213.8913 | 41.0704 | 12.6132 | (0.5381, 0.6013) |
 |  | 2532.1281 | 46.3587 | 11.5791 | (0.6212, 0.6864) |
 |  | 2730.0744 | 52.2501 | 13.7690 | (0.5308, 0.6178) |
 |  | 2402.9915 | 49.0203 | 14.3232 | (0.5122, 0.5651) |
 |  | 2156.5758 | 46.4389 | 14.7931 | (0.5032, 0.6289) |
 |  | 5314.2476 | 72.8988 | 10.8763 | (0.5459, 0.5977) |
| Model Generated Image | Original Image | MSSSIM | ERGAS | RASE | SAM | VIFP |
|---|---|---|---|---|---|---|
 |  | (0.5021 + 0j) | 16,381.1031 | 1573.8216 | 0.3577 | 0.0892 |
 |  | (0.3174 + 0j) | 16,522.5801 | 2503.2524 | 0.3152 | 0.0823 |
 |  | (0.3667 + 0j) | 19,423.197 | 2807.7506 | 0.2728 | 0.0557 |
 |  | (0.3250 + 0j) | 19,535.8021 | 2632.0759 | 0.3208 | 0.1354 |
 |  | (0.3067 + 0j) | 10,832.9807 | 2005.2324 | 0.3054 | 0.0720 |
 |  | (0.3100 + 0j) | 18,026.6801 | 2557.6952 | 0.3726 | 0.0990 |
 |  | (0.2519 + 0j) | 29,463.8512 | 4270.3793 | 0.5429 | 0.0299 |
 |  | (0.5167 + 0j) | 12,382.3081 | 1770.8513 | 0.3176 | 0.0993 |
 |  | (0.2121 + 0j) | 18,222.7227 | 2551.4187 | 0.2521 | 0.0382 |
 |  | (0.2568 + 0j) | 11,582.3176 | 2351.7226 | 0.3861 | 0.0392 |
 |  | (0.2428 + 0j) | 19,252.7421 | 2151.4684 | 0.2424 | 0.0186 |
 |  | (0.2167 + 0j) | 11,583.2172 | 2551.7425 | 0.2863 | 0.0595 |
 |  | (0.4250 + 0j) | 19,637.9001 | 2831.0789 | 0.4609 | 0.1253 |
 |  | (0.4067 + 0j) | 20,832.9807 | 3005.2324 | 0.4054 | 0.0720 |
 |  | (0.5100 + 0j) | 18,026.6801 | 2557.6952 | 0.3726 | 0.0990 |
 |  | (0.3355 + 0j) | 23,438.1978 | 3370.8904 | 0.4237 | 0.0716 |
| Model | Proposed Work | Limitation | Dataset |
|---|---|---|---|
| Latent Neural Fokker [9] –Planck kernels | It is a latent distribution-based approach with a plug and play implementation of GAN-based methods. | Dwinghyper-parameter tuning KL divergence became more sensitive. | CIFARIO [22] |
| MIPGAN [11] | The shelf verification and face recognition system [12] for studying vulnerability to generate new data. | Pre-selection of ethnicity, Mad performance detonated in empirical evaluation. | FFHQ [15] |
| AIRF [13] | This approach combines optimal morph field with Gaussian distribution to evaluate Bayes’ formation. | The illustration is implemented, or the images are grayscale. | MIT face |
| AFR [14] | This method extracts facial landmark coordinates and averages them, splicing the visual flaws with inverse warping. | The local analysis of skin texture produces color inconsistencies. | ECVP [31], FET [32] |
| VAFM [33] | It is a combined approach based on OpenCV [34] and Face Morpher [33]. | Lack of quality index factors. | FERET [35], FRGC [36], FRLL [37]. |
| Our Model | It is based on StyleGan ADA with enhanced augmentation and scaling features. | Further research needs to be carried out for output quality improvement. | FFHQ [15], kinfaceW [30] |
| Model Generated Image | Original Image |
|---|---|
| MIPGAN [11] | |
| Network Architecture | Architecture of StyleGan [15] |
| Approach | The input latent code embedded into an intermediate latent space. |
| Convolutional Layer | 3 × 3 |
| Feature Maps | 1× |
| Weight Demodulation | StyleGan [15] |
| Path Length Regularization | X |
| Lazy Regularization | X |
| GPU | ✓ |
| Mixed Processor | X |
| Learning Rate | 5 |
| Optimizer | AMSGrad [38] |
| Model Generated Image | Original Image |
|---|---|
| AMFIFV [13] | |
| Network Architecture/Model | SPFM (Simple parameterized Face Model) [39] |
| Approach | Frontal view-based metamorphosis with automatic uniform illumination. |
| Convolutional Layer | -- |
| Feature Maps | SPFM [39] |
| Weight Demodulation | Inverse Distance |
| Path Length Regularization | ✓ |
| Lazy Regularization | X |
| Number of GPU | -- |
| Mixed Processor | X |
| Learning Rate | -- |
| Model Generated Image | Original Image |
|---|---|
| AFR [16] | |
| Network Architecture | Delaunay triangulations [40] |
| Approach | Forward and Backward Mapping performed to warp |
| Convolutional Layer | -- |
| Feature Maps | [14] |
| Weight Demodulation | [14] |
| Path Length Regularization | X |
| Lazy Regularization | X |
| Number of GPU | -- |
| Mixed Processor | X |
| Learning Rate | -- |
| Model Generated Image | Original Image |
|---|---|
| VAFM [33] | |
| Network Architecture | FaceMorph [33], Webmorph [41] |
| Approach | |
| Convolutional Layer | -- |
| Feature Maps | -- |
| Weight Demodulation | STASM [42] |
| Path Length Regularization | X |
| Lazy Regularization | X |
| Number of GPU | ✓ |
| Mixed Processor | X |
| Learning Rate | ✓ |
| Model Generated Image | Original Image |
|---|---|
| Network Architecture | Revised architecture of AISG [1] |
| Approach | Broken into modulation based on feature map |
| Convolutional Layer | 3 × 3 |
| Feature Maps | 1× |
| Weight Demodulation | AISG [1] |
| Path Length Regularization | ✓ |
| Lazy Regularization | X |
| Number of GPU | 1 |
| Mixed Processor | X |
| Learning Rate | 2 |
| Mapping Net Depth | 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhattacharjee, B.; Debnath, B.; Das, J.C.; Kar, S.; Banerjee, N.; Mallik, S.; De, D. Predicting the Future Appearances of Lost Children for Information Forensics with Adaptive Discriminator-Based FLM GAN. Mathematics 2023, 11, 1345. https://doi.org/10.3390/math11061345
Bhattacharjee B, Debnath B, Das JC, Kar S, Banerjee N, Mallik S, De D. Predicting the Future Appearances of Lost Children for Information Forensics with Adaptive Discriminator-Based FLM GAN. Mathematics. 2023; 11(6):1345. https://doi.org/10.3390/math11061345
Chicago/Turabian StyleBhattacharjee, Brijit, Bikash Debnath, Jadav Chandra Das, Subhashis Kar, Nandan Banerjee, Saurav Mallik, and Debashis De. 2023. "Predicting the Future Appearances of Lost Children for Information Forensics with Adaptive Discriminator-Based FLM GAN" Mathematics 11, no. 6: 1345. https://doi.org/10.3390/math11061345