
High-Dimensional Distributionally Robust Mean-Variance Efficient Portfolio Selection

Abstract
:1. Introduction
2. Estimation Method
2.1. Low-Rank Structure and DRO Formulation
2.2. Choosing DSR-MVP Parameters
2.2.1. Data-Driven Approach for Choosing
- Gather historical data on asset returns and partition them into appropriate time blocks based on the data frequency, such as using a daily block if the data is collected at a per-second interval. Each block represents the distribution of asset returns for that particular time period, contributing a measure to the ambiguity set of asset returns. Repeating this process for each time block, such as for each day of the year, will yield in our ambiguity set for that year.
- Select a basis from . It is advisable to avoid choosing with accidental large-scale fluctuations in asset returns.
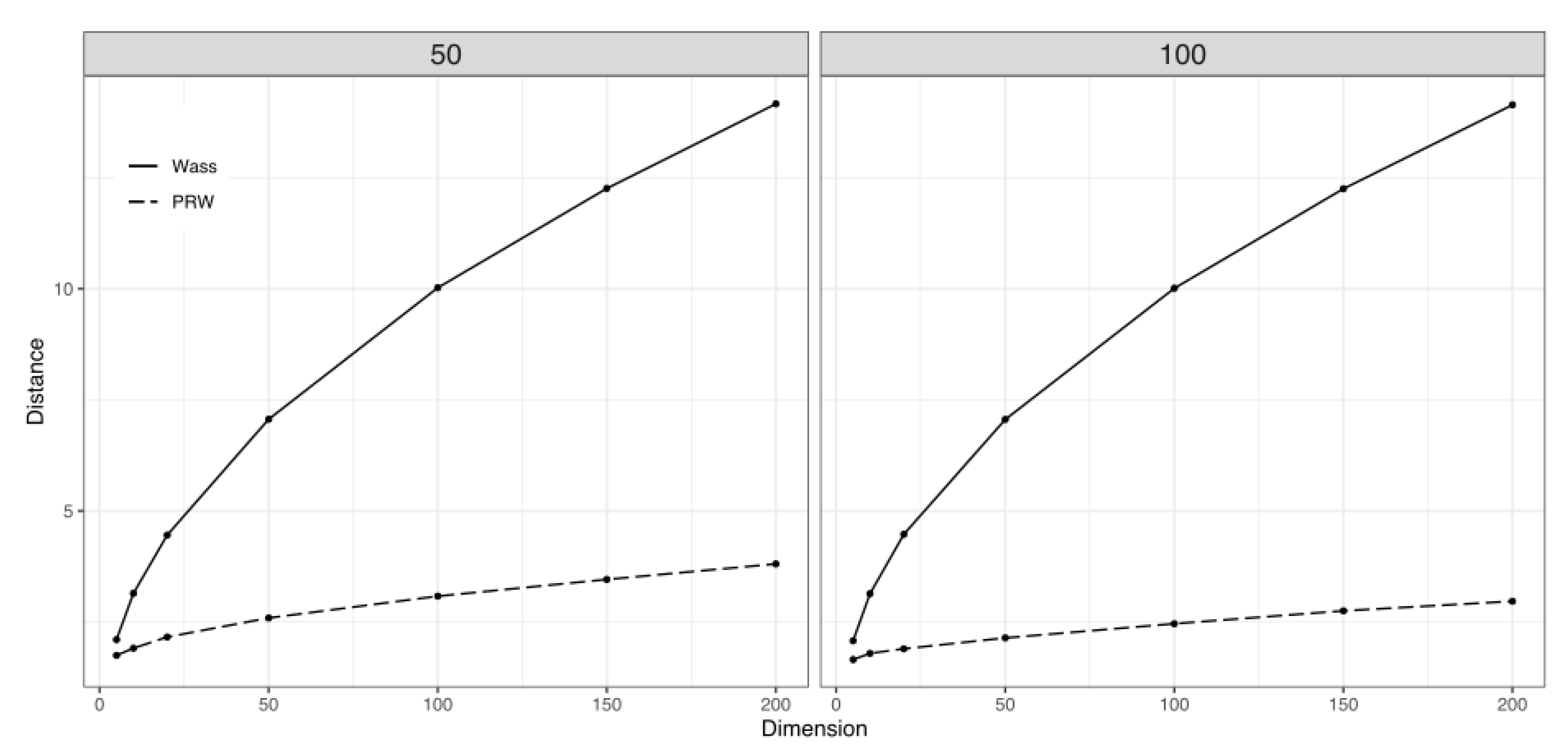
- Compute the sample mean and sample covariance for each . Then, use these estimates to calculate the PRW distance, as defined in (20), between each and the basis . We denote these distances as . Note that calculating the Wasserstein distances directly is more time-consuming and may suffer from the curse of dimensionality if the number of assets is large, whereas the PRW distance does not. Additionally, since we choose using a backward selection approach, using the Wasserstein distance may result in a larger value of , leading to a more conservative MVP.
- Select as the th percentile of the empirical distribution of . The user-defined confidence level can be determined through cross-validation. In our empirical study, we found that choosing as the median of leads to better out-of-sample performance compared to selecting the minimum or maximum. However, users can try different percentile levels to find a more suitable value for . It is worth noting that since the distribution of depends on the choice of k, it is necessary to estimate k even when using cross-validation to determine .
2.2.2. Methods for Choosing k
3. Monte Carlo Simulations
3.1. Setting
3.2. Comparison of Methods of Choosing k
3.3. Performance of Various GMVP Estimators
3.4. Robustness of Various MVP Estimators
4. Empirical Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Markowitz, H. Portfolio Selection. J. Financ. 1952, 7, 77–91. [Google Scholar]
- DeMiguel, V.; Nogales, F.J. Portfolio Selection with Robust Estimation. Oper. Res. 2009, 57, 560–577. [Google Scholar] [CrossRef] [Green Version]
- Michaud, R.O. The Markowitz Optimization Enigma: Is ’Optimized’ Optimal? Financ. Anal. J. 1989, 45, 31–42. [Google Scholar] [CrossRef]
- DeMiguel, V.; Garlappi, L.; Uppal, R. Optimal Versus Naive Diversification: How Inefficient is the 1-N Portfolio Strategy? Rev. Financ. Stud. 2009, 22, 1915–1953. [Google Scholar] [CrossRef] [Green Version]
- Merton, R.C. On estimating the expected return on the market: An exploratory investigation. J. Financ. Econ. 1980, 8, 323–361. [Google Scholar] [CrossRef]
- Jagannathan, R.; Ma, T. Risk Reduction in Large Portfolios: Why Imposing the Wrong Constraints Helps. J. Financ. 2003, 58, 1651–1683. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Liao, Y.; Mincheva, M. Large covariance estimation by thresholding principal orthogonal complements. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2013, 75, 603–680. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ding, Y.; Li, Y.; Zheng, X. High dimensional minimum variance portfolio estimation under statistical factor models. J. Econom. 2021, 222, 502–515. [Google Scholar] [CrossRef]
- Cai, T.T.; Hu, J.; Li, Y.; Zheng, X. High-dimensional minimum variance portfolio estimation based on high-frequency data. J. Econom. 2020, 214, 482–494. [Google Scholar] [CrossRef]
- Ledoit, O.; Wolf, M. Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. J. Empir. Financ. 2003, 10, 603–621. [Google Scholar] [CrossRef] [Green Version]
- Ledoit, O.; Wolf, M. A well-conditioned estimator for large-dimensional covariance matrices. J. Multivar. Anal. 2004, 88, 365–411. [Google Scholar] [CrossRef] [Green Version]
- Ledoit, O.; Wolf, M. Nonlinear Shrinkage of the Covariance Matrix for Portfolio Selection: Markowitz Meets Goldilocks. Rev. Financ. Stud. 2017, 30, 4349–4388. [Google Scholar] [CrossRef] [Green Version]
- Huber, P.J. Robust Estimation of a Location Parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Hampel, F. Contributions to the Theory of Robust Estimation; University Microfilms: Ann Arbor, MI, USA, 1976. [Google Scholar]
- Perret-Gentil, C.; Victoria-Feser, M.P. Robust Mean-Variance Portfolio Selection. SSRN Electron. J. 2007. [Google Scholar] [CrossRef] [Green Version]
- Scarf, H. A Min-Max Solution of an Inventory Problem. In Studies in the Mathematical Theory of Inventory and Production; Rand Corporation: Santa Monica, CA, USA, 1958; pp. 201–209. [Google Scholar]
- Blanchet, J.; Chen, L.; Zhou, X.Y. Distributionally Robust Mean-Variance Portfolio Selection with Wasserstein Distances. Manag. Sci. 2022, 68, 6382–6410. [Google Scholar] [CrossRef]
- DeMiguel, V.; Garlappi, L.; Nogales, F.J.; Uppal, R. A Generalized Approach to Portfolio Optimization: Improving Performance by Constraining Portfolio Norms. Manag. Sci. 2009, 55, 798–812. [Google Scholar] [CrossRef] [Green Version]
- Olivares-Nadal, A.V.; DeMiguel, V. Technical Note—A Robust Perspective on Transaction Costs in Portfolio Optimization. Oper. Res. 2018, 66, 733–739. [Google Scholar] [CrossRef]
- Esfahani, M.P.; Kuhn, D. Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations. Math. Program. 2018, 171, 115–166. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Fan, C.; Ho, N.; Cuturi, M.; Jordan, M.I. Projection Robust Wasserstein Distance and Riemannian Optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 9383–9397. [Google Scholar]
- Paty, F.P.; Cuturi, M. Subspace Robust Wasserstein Distances. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5072–5081. [Google Scholar]
- Deshpande, I.; Hu, Y.T.; Sun, R.; Pyrros, A.; Siddiqui, N.; Koyejo, S.; Zhao, Z.; Forsyth, D.; Schwing, A. Max-Sliced Wasserstein Distance and its use for GANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10648–10656. [Google Scholar]
- Nguyen, K.; Ho, N.; Pham, T.; Bui, H. Distributional Sliced-Wasserstein and Applications to Generative Modeling. arXiv 2020, arXiv:2002.07367. [Google Scholar]
- Kuhn, D.; Esfahani, P.M.; Nguyen, V.A.; Shafieezadeh-Abadeh, S. Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning. In Operations Research & Management Science in the Age of Analytics; Informs: Catonsville, MD, USA, 2019. [Google Scholar]
- Fournier, N.; Guillin, A. On the rate of convergence in Wasserstein distance of the empirical measure. Probab. Theory Relat. Fields 2015, 162, 707–738. [Google Scholar] [CrossRef] [Green Version]
- Ledoit, O.; Wolf, M. Spectrum estimation: A unified framework for covariance matrix estimation and PCA in large dimensions. J. Multivar. Anal. 2015, 139, 360–384. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysi; Springer: Berlin, Germany, 2002. [Google Scholar]
- Velicer, W.F.; Eaton, C.A.; Fava, J.L. Construct Explication through Factor or Component Analysis: A Review and Evaluation of Alternative Procedures for Determining the Number of Factors or Components. In Problems and Solutions in Human Assessment: Honoring Douglas N. Jackson at Seventy; Springer US: Boston, MA, USA, 2000; Chapter 3; pp. 41–71. [Google Scholar]
- Horn, J. A rationale and test for the number of factors in factor analysis. Psychometrika 1965, 30, 179–185. [Google Scholar] [CrossRef] [PubMed]
- Buja, A.; Eyuboglu, N. Remarks on Parallel Analysis. Multivar. Behav. Res. 1992, 27, 509–540. [Google Scholar] [CrossRef] [PubMed]
- Bai, J.; Ng, S. Determining the Number of Factors in Approximate Factor Models. Econometrica 2002, 70, 191–221. [Google Scholar] [CrossRef] [Green Version]
- Onatski, A. Determining the Number of Factors from Empirical Distribution of Eigenvalues. Rev. Econ. Stat. 2010, 92, 1004–1016. [Google Scholar] [CrossRef]
- Ahn, S.C.; Horenstein, A.R. Eigenvalue Ratio Test for the Number of Factors. Econometrica 2013, 81, 1203–1227. [Google Scholar] [CrossRef]
- Muirhead, R.J. Latent Roots and Matrix Variates: A Review of Some Asymptotic Results. Ann. Statist. 1978, 6, 5–33. [Google Scholar] [CrossRef]
- Kritchman, S.; Nadler, B. Non-Parametric Detection of the Number of Signals: Hypothesis Testing and Random Matrix Theory. IEEE Trans. Signal Process. 2009, 57, 3930–3941. [Google Scholar] [CrossRef]
- Choi, Y.; Taylor, J.; Tibshirani, R. Selecting the number of principal components: Estimation of the true rank of a noisy matrix. Ann. Statist. 2017, 45, 2590–2617. [Google Scholar] [CrossRef]
- Wang, J. Factor Analysis For High-dimensional Data. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2016. [Google Scholar]
- Rothman, A.J. Positive definite estimators of large covariance matrices. Biometrika 2012, 99, 733–740. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Percentile of | KS Test (p-Value) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Estimator | min | 25% | 50% | 75% | max | H1 | H2 | H3 | ||
| 50 | 100 | 1.26 | 2.617 | 3.224 | 3.968 | 8.886 | N = 50, T = 100 | |||
| 50 | 100 | 1.298 | 2.639 | 3.216 | 3.982 | 8.897 | 1 | 0.718 | 0.770 | |
| 50 | 100 | 1.059 | 2.682 | 3.291 | 4.015 | 8.851 | ||||
| 100 | 100 | 1.614 | 3.685 | 4.531 | 5.55 | 10.382 | N = 100, T = 100 | |||
| 100 | 100 | 1.648 | 3.654 | 4.549 | 5.549 | 10.460 | 1 | 0.740 | 0.614 | |
| 100 | 100 | 1.605 | 3.791 | 4.643 | 5.614 | 9.945 | ||||
| 200 | 100 | 2.499 | 5.19 | 6.4 | 7.698 | 14.395 | N = 200, T = 100 | |||
| 200 | 100 | 2.446 | 5.157 | 6.388 | 7.681 | 14.364 | 1 | 0.399 | 0.356 | |
| 200 | 100 | 2.265 | 5.384 | 6.569 | 7.763 | 15.088 | ||||
| BN | AH | PA | KN | BN | AH | PA | KN | ||
|---|---|---|---|---|---|---|---|---|---|
| 0.03 | 0.062 | 0.52 | 0.942 | 0 | 0.18 | 0.34 | 0 | 0.76 | 0 |
| 0.06 | 0.12 | 0.066 | 0.914 | 0 | 0.21 | 0.372 | 0 | 0.658 | 0 |
| 0.09 | 0.116 | 0.004 | 0.912 | 0 | 0.24 | 0.39 | 0 | 0.6 | 0 |
| 0.12 | 0.224 | 0 | 0.886 | 0 | 0.27 | 0.386 | 0 | 0.514 | 0 |
| 0.15 | 0.256 | 0 | 0.818 | 0 | 0.30 | 0.374 | 0 | 0.436 | 0 |
| , | ||||||||
|---|---|---|---|---|---|---|---|---|
| Choice of | ||||||||
| R.R. | p-value | Trans | 25% | 50% | 75% | |||
| 2.703 (0.349) | [0/0/0] | 0.466 (0.117) | R.R. | 5.689 (3.472) [0] | 6.396 (3.991) [0] | 7.757 (4.893) [0] | ||
| 1.382 (0.066) | [1/1/1] | 0.105 (0.004) | Trans | 0.073 (0.01) | 0.07 (0.011) | 0.066 (0.012) | ||
| 1.331 (0.065) | [1/1/1] | 0.102 (0.004) | R.R. | 2.067 (0.363) | 2.174 (0.437) | 2.429 (0.629) | ||
| 9.926 (-) | [0/0/0] | 0.012 (-) | Trans | 0.1 (0.005) | 0.097 (0.005) | 0.093 (0.006) | ||
| , | ||||||||
| Choice of | ||||||||
| R.R. | p-value | Trans | 25% | 50% | 75% | |||
| 2.362 (0.365) | [0/0/0] | 0.577 (0.18) | R.R. | 2.278 (0.369) [0] | 2.354 (0.402) [0] | 2.516 (0.473) [0] | ||
| 1.313 (0.029) | [1/1/1] | 0.104 (0.003) | Trans | 0.09 (0.004) | 0.089 (0.004) | 0.087 (0.004) | ||
| 1.237 (0.03) | [1/1/1] | 0.109 (0.003) | R.R. | 1.717 (0.151) | 1.772 (0.171) | 1.861 (0.204) | ||
| 9.926 (-) | [0/0/0] | 0.012 (-) | Trans | 0.102 (0.003) | 0.1 (0.003) | 0.097 (0.003) | ||
| , | ||||||||
| Choice of | ||||||||
| R.R. | p-value | Trans | 25% | 50% | 75% | |||
| 1.3 (0.054) | [1/1/1] | 0.227 (0.024) | R.R. | 1.699 (0.112) [0] | 1.725 (0.118) [0] | 1.783 (0.131) [0] | ||
| 1.285 (0.017) | [1/1/1] | 0.104 (0.002) | Trans | 0.097 (0.002) | 0.097 (0.002) | 0.095 (0.002) | ||
| 1.158 (0.021) | [1/1/1] | 0.125 (0.006) | R.R. | 1.519 (0.074) | 1.545 (0.079) | 1.597 (0.09) | ||
| 9.926 (-) | [0/0/0] | 0.012 (-) | Trans | 0.103 (0.002) | 0.102 (0.002) | 0.1 (0.002) | ||
| (a) Risk | ||||||
|---|---|---|---|---|---|---|
| Year | ||||||
| 2003 | 3.23 *** | 2.50 * | 2.15 | 4.64 *** | 2.14 | 2.10 |
| 2004 | 3.27 *** | 3.31 *** | 2.36 | 3.59 *** | 2.46 | 2.35 |
| 2005 | 3.18 *** | 3.07 *** | 2.10 | 3.31 *** | 2.4 | 2.12 |
| 2006 | 3.32 *** | 2.53 *** | 1.90 | 3.31 *** | 2.01 | 1.91 |
| 2007 | 3.64 *** | 3.16 * | 2.31 | 4.51 *** | 2.91 | 2.33 |
| 2008 | 6.79 * | 6.53 | 4.49 | 10.81 *** | 4.63 | 4.51 |
| 2009 | 6.25 *** | 5.62 ** | 3.60 | 8.59 *** | 3.43 | 3.71 |
| 2010 | 4.08 *** | 2.67 | 2.56 | 5.23 *** | 2.56 | 2.49 |
| 2011 | 3.86 ** | 3.11 | 2.66 | 6.49 *** | 2.98 | 2.70 |
| 2012 | 3.67 *** | 2.53 *** | 2.05 | 3.79 *** | 1.94 | 2.01 |
| 2013 | 3.46 *** | 2.92 ** | 2.39 | 3.35 *** | 2.45 | 2.35 |
| 2014 | 3.32 *** | 3.39 *** | 2.12 | 3.11 ** | 2.51 | 2.15 |
| 2015 | 3.97 ** | 4.81 *** | 3.02 | 4.15 ** | 3.63 | 3.09 |
| 2016 | 4.73 *** | 5.6 *** | 2.73 | 3.84 | 2.79 | 2.56 |
| 2017 | 4.09 *** | 2.78 *** | 2.12 ** | 1.99 | 1.64 | 1.81 |
| 2018 | 4.58 *** | 4.13 ** | 3.06 | 4.01 * | 3.31 | 3.00 |
| 2019 | 4.42 *** | 3.74 *** | 2.54 | 3.25 ** | 2.36 | 2.32 |
| 2020 | 8.56 * | 8.86 * | 5.55 | 8.53 | 5.73 | 5.59 |
| 2021 | 5.64 *** | 4.94 *** | 3.04 | 3.83 *** | 2.7 | 2.98 |
| (b) Sharpe Ratio | ||||||
| Year | ||||||
| 2003 | 0.54 * | 0.75 | 1.15 | 0.95 | 1.24 | 1.21 |
| 2004 | 0.88 | 0.88 | 1.20 | 0.72 | 1.05 | 1.01 |
| 2005 | 0.17 | 0.32 | 0.29 | 0.53 | 0.48 | 0.35 |
| 2006 | 0.16 | 0.68 | 0.76 | 0.70 | 0.82 | 0.78 |
| 2007 | 0.20 | 0.31 | 0.35 | 0.39 | 0.47 | 0.44 |
| 2008 | −0.05 | −0.21 | −0.11 | −0.01 | −0.13 | −0.12 |
| 2009 | −0.26 | 0.13 | 0.23 | 0.65 | 0.23 | 0.09 |
| 2010 | 0.48 | 0.48 | 0.49 | 0.76 | 0.57 | 0.50 |
| 2011 | 0.55 | 0.86 | 0.46 | 0.26 | 0.53 | 0.52 |
| 2012 | 0.24 | 0.12 | 0.40 | 0.61 | 0.36 | 0.41 |
| 2013 | 0.87 | 0.65 | 0.67 | 1.01 | 0.89 | 0.72 |
| 2014 | 0.49 | 0.64 | 0.83 | 0.72 | 0.82 | 0.87 |
| 2015 | 0.32 | 0.44 | 0.5 | 0.29 | 0.35 | 0.49 |
| 2016 | 0.00 | 0.08 | 0.48 | 0.60 | 0.45 | 0.57 |
| 2017 | 0.06 | 0.39 | 0.49 | 1.14 | 0.94 | 0.63 |
| 2018 | 0.09 | 0.47 | 0.33 | 0.34 | 0.51 | 0.46 |
| 2019 | 0.52 | 0.55 | 1.10 | 1.07 | 1.09 | 1.05 |
| 2020 | 0.22 | −0.08 | 0.10 | 0.52 | 0.29 | 0.12 |
| 2021 | 0.10 * | 0.29 | 0.73 | 0.74 | 0.72 | 0.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Jing, H.; Kao, C. High-Dimensional Distributionally Robust Mean-Variance Efficient Portfolio Selection. Mathematics 2023, 11, 1272. https://doi.org/10.3390/math11051272
Zhang Z, Jing H, Kao C. High-Dimensional Distributionally Robust Mean-Variance Efficient Portfolio Selection. Mathematics. 2023; 11(5):1272. https://doi.org/10.3390/math11051272
Chicago/Turabian StyleZhang, Zhonghui, Huarui Jing, and Chihwa Kao. 2023. "High-Dimensional Distributionally Robust Mean-Variance Efficient Portfolio Selection" Mathematics 11, no. 5: 1272. https://doi.org/10.3390/math11051272