
A Flexible Class of Two-Piece Normal Distribution with a Regression Illustration to Biaxial Fatigue Data



Abstract
:1. Introduction
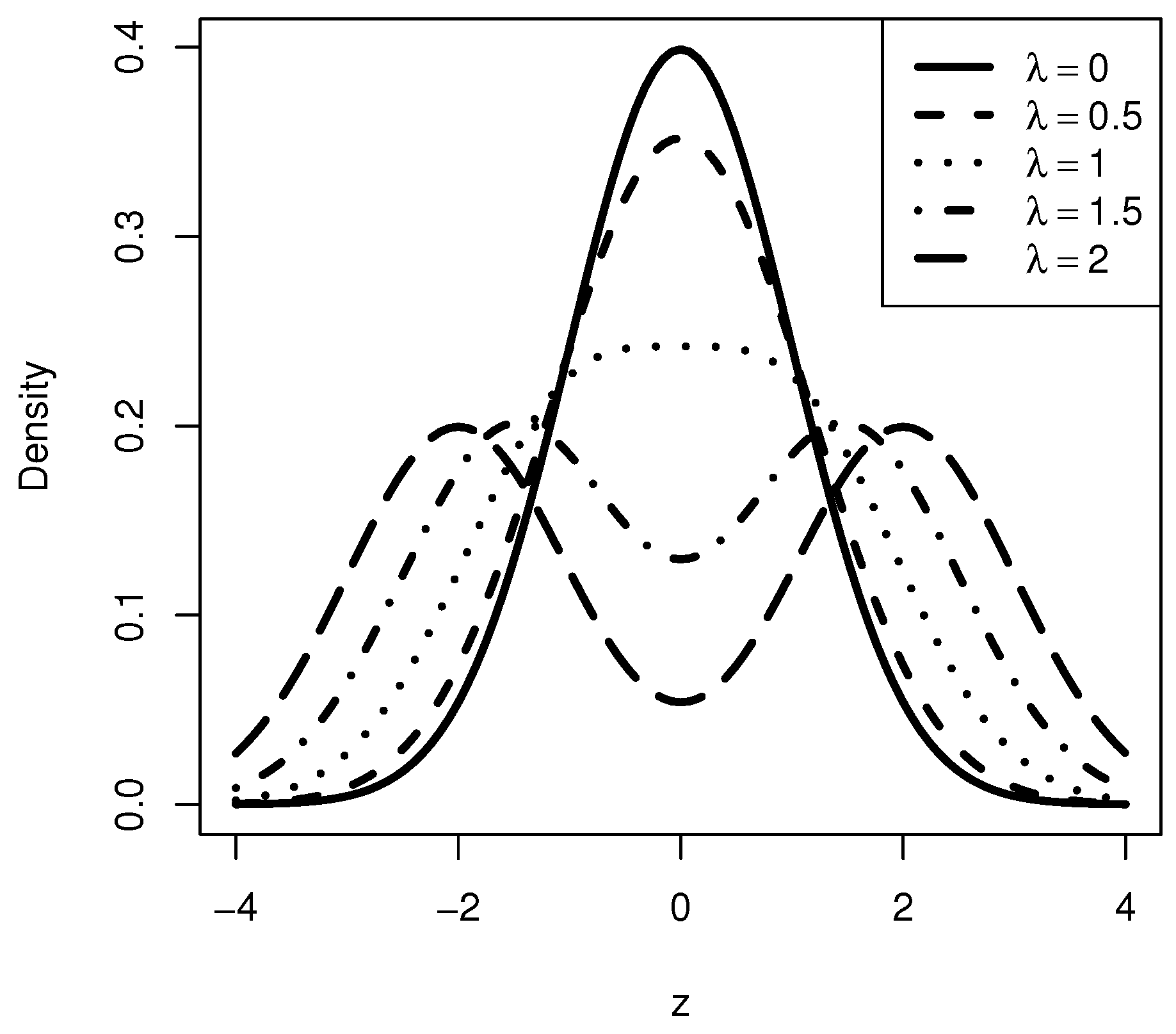
2. The Family of Uni/Bimodal Densities
3. Some Properties of the TN Distribution
3.1. Basic Properties
3.2. Stochastic Representation of the TN Random Variable
3.3. Moments
4. Estimation with Inference and a Simulation Study
4.1. The Maximum Likelihood Estimation
4.2. Simulation Study
- (a)
- Choose the values , , , and the sample size n.
- (b)
- Generate .
- (c)
- Compute .
- (d)
- Generate .
- (e)
- If , compute , else .
- (f)
- Compute
5. Practical Data Illustrations
5.1. Illustration 1: Data Fitting
- (a)
- Akaike information criterion (AIC), given by AIC = .
- (b)
- Bayesian information criterion (BIC), given by BIC = .
- (c)
- Corrected AIC (AICc), given by AICc = AIC + ,
5.2. Illustration 2: Regression Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Azzalini, A. A class of distributions which includes the normal ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Elal-Olivero, D. Alpha-skew-normal distribution. Proyecc. J. Math. 2010, 29, 224–240. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Flórez, G.; Bolfarine, H.; Gómez, H.W. The Log-Linear Birnbaum-Saunders Power Model. Methodol. Comput. Appl. Probab. 2017, 19, 913–933. [Google Scholar] [CrossRef]
- Cortés, M.A.; Elal-Olivero, D.; Olivares-Pacheco, J.F. A new class of distributions generated by the extended bimodal-normal distribution. J. Probab. Stat. 2018, 2018, 9753439. [Google Scholar] [CrossRef] [Green Version]
- Hoxhaj, V.; Khattree, R. A study of geometric and statistical curvatures for the skew-normal family of distributions. Commun. Stat.-Simul. Comput. 2018, 47, 2010–2022. [Google Scholar] [CrossRef]
- Elal-Olivero, D.; Olivares-Pacheco, J.F.; Venegas, O.; Bolfarine, H.; Gomez, H.W. On properties of the bimodal skew-normal distribution and an application. Mathematics 2020, 8, 703. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Elal-Olivero, D.; Barrera-Causil, C. Extended Generalized Sinh-Normal Distribution. Mathematics 2021, 9, 2793. [Google Scholar] [CrossRef]
- Martinez-Florez, G.; Tovar-Falon, R.; Elal-Olivero, D. Some new flexible classes of normal distribution for fitting multimodal data. Statistics 2022, 56, 182–205. [Google Scholar] [CrossRef]
- Tsagris, M.; Beneki, C.; Hassani, H. On the folded normal distribution. Mathematics 2014, 2, 12–28. [Google Scholar] [CrossRef] [Green Version]
- Reig, J.; Rodrigo Peñarrocha, V.M.; Rubio Arjona, L.; Martínez-Inglés, M.T.; Molina-García-Pardo, J.M. The Folded Normal Distribution: A New Model for the Small-Scale Fading in Line-of-Sight (LOS) Condition. IEEE Access 2019, 7, 77328–77339. [Google Scholar] [CrossRef]
- Leone, F.C.; Nelson, L.S.; Nottingham, R.B. The folded normal distribution. Technometrics 1961, 3, 543–550. [Google Scholar] [CrossRef]
- Sarkka, S.; Solin, A. Applied Stochastic Differential Equations; Cambridge University Press: Cambridge, UK, 2003; ISBN 9781108186735. [Google Scholar] [CrossRef] [Green Version]
- Abad, J.; Sesma, J. Computation of the regular confluent hypergeometric function. Math. J. 1995, 5, 74–76. [Google Scholar]
- Wang, S.; Chen, W.X.; Chen, M.; Zhou, Y.W. Maximum likelihood estimation of the parameters of the inverse Gaussian distribution using maximum rank set sampling with unequal samples. Math. Popul. Stud. 2023, 30, 1–12. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 29 January 2023).
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Nelder, J.A.; Mead, R. A simplex algorithm for function minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Kim, H.J. On a class of two-piece skew-normal distributions. Statistics 2005, 39, 537–553. [Google Scholar] [CrossRef]
- Rieck, J.R.; Nedelman, J.R. A log-linear model for the Birnbaum-Saunders distribution. Technometrics 1991, 33, 51–60. [Google Scholar]
- Barros, M.; Galea, M.; Gonzalez, M.; Leiva, V. Influence diagnostics in the tobit censored response model. Stat. Methods Appl. 2010, 19, 379–397. [Google Scholar] [CrossRef]
- Ortega, E.M.; Bolfarine, H.; Paula, G.A. Influence diagnostics in generalized log-gamma regression models. Comput. Stat. Data Anal. 2003, 42, 165–186. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 10 | 3 | 2.5 | 2 | 1.5 | 1 | 0.8 | 0.6 | 0.4 | 0.2 | |
| Ratio | 0.9950 | 0.9489 | 0.9299 | 0.9020 | 0.8645 | 0.8249 | 0.8124 | 0.8037 | 0.7993 | 0.7979 |
| n | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | RMSE | Mean | RMSE | Mean | RMSE | |||||
| 50 | 0.0024 | 0.0024 | 0.1827 | 0.9620 | 0.0380 | 0.1998 | 0.7869 | 0.0369 | 0.4608 | |
| 100 | 0.0018 | 0.0018 | 0.1271 | 0.9888 | 0.0112 | 0.163 | 0.7103 | 0.0397 | 0.3770 | |
| 0.75 | 150 | 0.0012 | 0.0012 | 0.1013 | 1.0038 | 0.0038 | 0.1428 | 0.7147 | 0.0353 | 0.3358 |
| 200 | −0.0009 | 0.0009 | 0.0893 | 1.0038 | 0.0038 | 0.1310 | 0.7167 | 0.0333 | 0.3053 | |
| 300 | 0.0007 | 0.0007 | 0.0721 | 1.0028 | 0.0028 | 0.1142 | 0.7177 | 0.0323 | 0.2667 | |
| 500 | −0.0005 | 0.0005 | 0.0559 | 1.0024 | 0.0024 | 0.0953 | 0.7208 | 0.0292 | 0.2183 | |
| 50 | −0.0026 | 0.0026 | 0.2059 | 0.9909 | 0.0091 | 0.1757 | 1.2736 | 0.0236 | 0.3674 | |
| 100 | −0.0024 | 0.0024 | 0.1427 | 0.9932 | 0.0068 | 0.1200 | 1.2663 | 0.0163 | 0.2426 | |
| 1.25 | 150 | 0.0022 | 0.0022 | 0.1147 | 0.9935 | 0.0065 | 0.0937 | 1.2645 | 0.0145 | 0.1873 |
| 200 | −0.0022 | 0.0022 | 0.1005 | 0.9963 | 0.0037 | 0.0800 | 1.2580 | 0.0080 | 0.1596 | |
| 300 | 0.0007 | 0.0007 | 0.0802 | 0.9960 | 0.0040 | 0.0628 | 1.2579 | 0.0079 | 0.1256 | |
| 500 | 0.0002 | 0.0002 | 0.0630 | 0.9999 | 0.0001 | 0.0494 | 1.2505 | 0.0005 | 0.0982 | |
| 50 | −0.0029 | 0.0029 | 0.1885 | 0.9782 | 0.0218 | 0.1245 | 1.8084 | 0.0584 | 0.2971 | |
| 100 | 0.0024 | 0.0024 | 0.1259 | 0.9852 | 0.0148 | 0.0841 | 1.7871 | 0.0371 | 0.1956 | |
| 1.75 | 150 | 0.0014 | 0.0014 | 0.1030 | 0.9912 | 0.0088 | 0.0684 | 1.7734 | 0.0234 | 0.1606 |
| 200 | 0.0007 | 0.0007 | 0.0881 | 0.9931 | 0.0069 | 0.0595 | 1.7696 | 0.0196 | 0.1387 | |
| 300 | 0.0007 | 0.0007 | 0.0722 | 0.9959 | 0.0041 | 0.0483 | 1.7614 | 0.0114 | 0.1108 | |
| 500 | 0.0005 | 0.0005 | 0.0561 | 0.9973 | 0.0027 | 0.0370 | 1.7568 | 0.0068 | 0.0860 | |
| 50 | 0.0017 | 0.0017 | 0.1603 | 0.9749 | 0.0251 | 0.1086 | 2.3349 | 0.0849 | 0.3094 | |
| 100 | −0.0011 | 0.0011 | 0.1095 | 0.9885 | 0.0115 | 0.0762 | 2.2870 | 0.0370 | 0.2115 | |
| 2.25 | 150 | 0.0010 | 0.0010 | 0.0913 | 0.9913 | 0.0087 | 0.0610 | 2.2772 | 0.0272 | 0.1663 |
| 200 | 0.0003 | 0.0003 | 0.0799 | 0.9940 | 0.0060 | 0.0530 | 2.2690 | 0.0190 | 0.1438 | |
| 300 | −0.0003 | 0.0003 | 0.0652 | 0.9961 | 0.0039 | 0.0431 | 2.2620 | 0.0120 | 0.1174 | |
| 500 | 0.0000 | 0.0000 | 0.0495 | 0.9979 | 0.0021 | 0.0337 | 2.2571 | 0.0071 | 0.0896 | |
| 50 | −0.0010 | 0.0010 | 0.1504 | 0.9766 | 0.0234 | 0.1045 | 2.8469 | 0.0969 | 0.3530 | |
| 100 | 0.0013 | 0.0013 | 0.1046 | 0.9877 | 0.0123 | 0.0729 | 2.7987 | 0.0487 | 0.2368 | |
| 2.75 | 150 | 0.0012 | 0.0012 | 0.0849 | 0.9927 | 0.0073 | 0.0596 | 2.7795 | 0.0295 | 0.1881 |
| 200 | 0.0002 | 0.0002 | 0.0739 | 0.9937 | 0.0063 | 0.0514 | 2.7747 | 0.0247 | 0.1622 | |
| 300 | 0.0000 | 0.0000 | 0.0594 | 0.9954 | 0.0046 | 0.0418 | 2.7671 | 0.0171 | 0.1305 | |
| 500 | −0.0001 | 0.0001 | 0.0464 | 0.9979 | 0.0021 | 0.0322 | 2.7596 | 0.0096 | 0.1012 | |
| 50 | −0.0020 | 0.0020 | 0.1430 | 0.9766 | 0.0234 | 0.1030 | 3.6225 | 0.1225 | 0.4255 | |
| 100 | 0.0006 | 0.0006 | 0.1003 | 0.9878 | 0.0122 | 0.0705 | 3.5596 | 0.0596 | 0.2760 | |
| 3.50 | 150 | 0.0006 | 0.0006 | 0.0824 | 0.9910 | 0.0090 | 0.0589 | 3.5447 | 0.0447 | 0.2319 |
| 200 | −0.0004 | 0.0004 | 0.0711 | 0.9934 | 0.0066 | 0.0508 | 3.5315 | 0.0315 | 0.1980 | |
| 300 | −0.0001 | 0.0001 | 0.0579 | 0.9965 | 0.0035 | 0.0409 | 3.5188 | 0.0188 | 0.1561 | |
| 500 | −0.0001 | 0.0001 | 0.0452 | 0.9979 | 0.0021 | 0.0316 | 3.5118 | 0.0118 | 0.1205 | |
| 50 | 0.0014 | 0.0014 | 0.1425 | 0.9763 | 0.0237 | 0.1021 | 5.6955 | 0.1955 | 0.6362 | |
| 100 | −0.0013 | 0.0013 | 0.0997 | 0.9876 | 0.0124 | 0.0719 | 5.5985 | 0.0985 | 0.4298 | |
| 5.50 | 150 | 0.0013 | 0.0013 | 0.0827 | 0.9910 | 0.0090 | 0.0591 | 5.5679 | 0.0679 | 0.3476 |
| 200 | 0.0009 | 0.0009 | 0.0709 | 0.9934 | 0.0066 | 0.0509 | 5.5489 | 0.0489 | 0.2961 | |
| 300 | −0.0004 | 0.0004 | 0.0575 | 0.9958 | 0.0042 | 0.0405 | 5.5321 | 0.0321 | 0.2330 | |
| 500 | 0.0003 | 0.0003 | 0.0450 | 0.9980 | 0.0020 | 0.0318 | 5.5174 | 0.0174 | 0.1812 | |
| 50 | 0.0024 | 0.0024 | 0.1426 | 0.9746 | 0.0254 | 0.1031 | 7.7772 | 0.2772 | 0.8682 | |
| 100 | −0.0024 | 0.0024 | 0.1012 | 0.9888 | 0.0112 | 0.0712 | 7.6243 | 0.1243 | 0.5719 | |
| 7.50 | 150 | 0.0014 | 0.0014 | 0.0813 | 0.9921 | 0.0079 | 0.0586 | 7.5866 | 0.0866 | 0.4630 |
| 200 | −0.0008 | 0.0008 | 0.0716 | 0.9936 | 0.0064 | 0.0502 | 7.5636 | 0.0636 | 0.3925 | |
| 300 | 0.0003 | 0.0003 | 0.0569 | 0.9949 | 0.0051 | 0.0407 | 7.5504 | 0.0504 | 0.3168 | |
| 500 | −0.0001 | 0.0001 | 0.0447 | 0.9976 | 0.0024 | 0.0319 | 7.5263 | 0.0263 | 0.2460 | |
| n | Mean | Variance | Median | Skewness | Kurtosis |
|---|---|---|---|---|---|
| 500 | 3210.356 | 695710.6 | 3175 | 0.0714 | 2.068 |
| Estimates | BN | TSN | MN | TN |
|---|---|---|---|---|
| 3201.66 | 3207.42 | 2514.5 | 3223.49 | |
| (5.620) | (26.03) | (58.2) | (27.59) | |
| 481.088 | 772.68 | 196,301.1 | 466.23 | |
| (8.782) | (25.76) | (36,787.4) | (20.09) | |
| 3896.8 | ||||
| (65.6) | ||||
| 236,577.6 | ||||
| (42,231.6) | ||||
| 1.771 | 0.4967 | 1.4815 | ||
| (0.539) | (0.0442) | (0.0904) | ||
| AIC | 8238.39 | 8109.67 | 8097.09 | 8094.22 |
| AICc | 8240.43 | 8111.75 | 8099.26 | 8096.34 |
| BIC | 8246.82 | 8122.31 | 8118.16 | 8106.86 |
| Estimates | N | SNC | SHN | TN |
|---|---|---|---|---|
| 12.289 | 12.419 | 12.279 | 12.235 | |
| (0.405) | (0.320) | (0.389) | (0.309) | |
| −1.672 | −1.706 | −1.670 | −1.665 | |
| (0.112) | (0.088) | (0.108) | (0.086) | |
| 0.4088 | 0.416 | 0.245 | ||
| (0.042) | (0.050) | (0.034) | ||
| −0.698 | 0.410 | 1.309 | ||
| (0.294) | (0.042) | (0.302) | ||
| AIC | 53.25 | 54.00 | 52.74 | 51.39 |
| AICc | 56.22 | 57.50 | 55.71 | 54.84 |
| BIC | 58.73 | 59.32 | 58.22 | 58.70 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salinas, H.; Bakouch, H.; Qarmalah, N.; Martínez-Flórez, G. A Flexible Class of Two-Piece Normal Distribution with a Regression Illustration to Biaxial Fatigue Data. Mathematics 2023, 11, 1271. https://doi.org/10.3390/math11051271
Salinas H, Bakouch H, Qarmalah N, Martínez-Flórez G. A Flexible Class of Two-Piece Normal Distribution with a Regression Illustration to Biaxial Fatigue Data. Mathematics. 2023; 11(5):1271. https://doi.org/10.3390/math11051271
Chicago/Turabian StyleSalinas, Hugo, Hassan Bakouch, Najla Qarmalah, and Guillermo Martínez-Flórez. 2023. "A Flexible Class of Two-Piece Normal Distribution with a Regression Illustration to Biaxial Fatigue Data" Mathematics 11, no. 5: 1271. https://doi.org/10.3390/math11051271