
Deep Reinforcement Learning Heterogeneous Channels for Poisson Multiple Access

Abstract
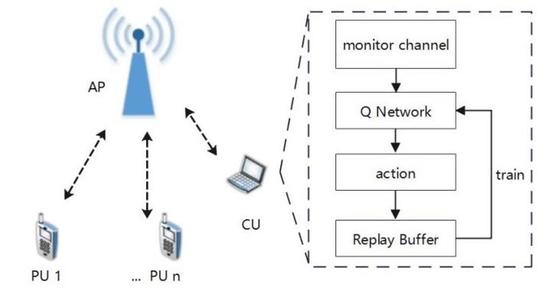
:
1. Introduction
- We propose a DRL-based MCT-DLMA protocol for efficient spectrum utilization in multi-channel HetNets. It can learn to find a near-optimal spectrum access policy by exploiting the collected historical channel information. A salient feature of MCT-DLMA is that it enables CU to multi-channel transmit the data at a time, e.g., via the multi-carrier technology. It can avoid the waste of channel resources in the case of multiple idle channels.
- The proposed MCT-DLMA is optimized for saturated and unsaturated traffic networks, respectively. The experimental results show that the proposed MCT-DLMA can achieve higher throughput than the existing the whittle index policy [31] and the DLMA in static HetNet. In particular, MCT-DLMA also shows the enhanced robustness in dynamic environments, where the PUs communicating with the CU change over the time.
2. Deep Reinforcement Learning Framework
2.1. Q-Learning
2.2. Deep Q Network
- Double DQN: Solve the overestimation problem in DQN [33]. It changes the loss function and uses the target network () to update the loss function as
- Dueling DQN: Change the unbranched neural network structure in DQN [34]. An advantage layer and a value layer are added, which are used to estimate the advantage value of each action and the current state value.
3. System Model and Problem of Interest
- 1.
- TDMA: send data packet in a fixed time slot of a frame.
- 2.
- Q-ALOHA: send data packet with a fixed probability q in each time slot using Q-ALOHA protocol.
- 3.
- Fixed-window ALOHA (FW-ALOHA): randomly generate a value after sending a data packet, and wait for w time slots to send the next time [25].
- 4.
- CU: adopt the MCT-DLMA protocol, it monitors the channel state (BUSY/IDLE) for a period of time in the past and selects the channel to send data packets based on the deep Q network.
4. MCT-DLMA Protocol
4.1. Action
4.2. State
4.3. Reward
4.4. Neural Network
4.5. Algorithm
| Algorithm 1 Double-dueling-deep Q network. |
|
5. Simulation Results
5.1. MCT-DLMA + 3-User TDMA
5.2. MCT-DLMA + TDMA + Q-ALOHA + FW-ALOHA
5.3. MCT-DLMA + 10-User Dynamic TDMA
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, Q.; Swami, A. A Survey of Dynamic Spectrum Access: Signal Processing and Networking Perspectives. In Proceedings of the ICASSP IEEE International Conference Acoust Speech Signal Processing, Honolulu, HI, USA, 15–20 April 2007; Volume 4, pp. IV–1349–IV–1352. [Google Scholar] [CrossRef]
- Colvin, A. CSMA with collision avoidance. Comput. Commun. 1983, 6, 227–235. [Google Scholar] [CrossRef]
- Abramova, M.; Artemenko, D.; Krinichansky, K. Transmission Channels between Financial Deepening and Economic Growth: Econometric Analysis Comprising Monetary Factors. Mathematics 2022, 10, 242. [Google Scholar] [CrossRef]
- Liu, S.; Huang, X. Sparsity-aware channel estimation for mmWave massive MIMO: A deep CNN-based approach. China Commun. 2021, 18, 162–171. [Google Scholar] [CrossRef]
- Swapna; Tangelapalli; Saradhi, P.P.; Pandya, R.J.; Iyer, S. Deep Learning Oriented Channel Estimation for Interference Reduction for 5G. In Proceedings of the 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 24–25 September 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Yao, R.; Qin, Q.; Wang, S.; Qi, N.; Fan, Y.; Zuo, X. Deep Learning Assisted Channel Estimation Refinement in Uplink OFDM Systems Under Time-Varying Channels. In Proceedings of the 2021 International Wireless Communications and Mobile Computing (IWCMC), Harbin, China, 28 June–2 July 2021; pp. 1349–1353. [Google Scholar] [CrossRef]
- Rahman, M.H.; Shahjalal, M.; Ali, M.O.; Yoon, S.; Jang, Y.M. Deep Learning Based Pilot Assisted Channel Estimation for Rician Fading Massive MIMO Uplink Communication System. In Proceedings of the 2021 Twelfth International Conference on Ubiquitous and Future Networks (ICUFN), Jeju Island, Republic of Korea, 17–20 August 2021; pp. 470–472. [Google Scholar] [CrossRef]
- Ahn, Y.; Shim, B. Deep Learning-Based Beamforming for Intelligent Reflecting Surface-Assisted mmWave Systems. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; pp. 1731–1734. [Google Scholar] [CrossRef]
- Dong, R.; Wang, B.; Cao, K. Deep Learning Driven 3D Robust Beamforming for Secure Communication of UAV Systems. IEEE Wirel. Commun. Lett. 2021, 10, 1643–1647. [Google Scholar] [CrossRef]
- Al-Saggaf, U.M.; Hassan, A.K.; Moinuddin, M. Ergodic Capacity Analysis of Downlink Communication Systems under Covariance Shaping Equalizers. Mathematics 2022, 10, 4340. [Google Scholar] [CrossRef]
- Ma, H.; Fang, Y.; Chen, P.; Li, Y. Reconfigurable Intelligent Surface-aided M-ary FM-DCSK System: A New Design for Noncoherent Chaos-based Communication. IEEE Trans. Veh. Technol. 2022; Early access. [Google Scholar] [CrossRef]
- Yang, M.; Bian, C.; Kim, H.S. OFDM-Guided Deep Joint Source Channel Coding for Wireless Multipath Fading Channels. IEEE Trans. Cogn. Commun. 2022, 8, 584–599. [Google Scholar] [CrossRef]
- Xu, J.; Ai, B.; Chen, W.; Yang, A.; Sun, P.; Rodrigues, M. Wireless Image Transmission Using Deep Source Channel Coding With Attention Modules. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2315–2328. [Google Scholar] [CrossRef]
- Xu, C.; Van Luong, T.; Xiang, L.; Sugiura, S.; Maunder, R.G.; Yang, L.L.; Hanzo, L. Turbo Detection Aided Autoencoder for Multicarrier Wireless Systems: Integrating Deep Learning Into Channel Coded Systems. IEEE Trans. Cogn. Commun. 2022, 8, 600–614. [Google Scholar] [CrossRef]
- Chen, P.; Shi, L.; Fang, Y.; Lau, F.C.M.; Cheng, J. Rate-Diverse Multiple Access over Gaussian Channels. IEEE Trans. Wirel. Commun. 2023; Early access. [Google Scholar] [CrossRef]
- Fang, Y.; Bu, Y.; Chen, P.; Lau, F.C.M.; Otaibi, S.A. Irregular-Mapped Protograph LDPC-Coded Modulation: A Bandwidth-Efficient Solution for 6G-Enabled Mobile Networks. IEEE Trans. Intell. Transp. Syst. 2021; Early access. [Google Scholar] [CrossRef]
- Mazhari Saray, A.; Ebrahimi, A. MAX- MIN Power Control of Cell Free Massive MIMO System employing Deep Learning. In Proceedings of the 2022 4th West Asian Symposium on Optical and Millimeter-Wave Wireless Communications (WASOWC), Tabriz, Iran, 12–13 May 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Bellemare, M.G.; Naddaf, Y.; Veness, J.; Bowling, M. The arcade learning environment: An evaluation platform for general agents. J. Artif. Intell. Res. 2013, 47, 253–279. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Nasir, Y.S.; Guo, D. Multi-agent deep reinforcement learning for dynamic power allocation in wireless networks. IEEE J. Sel. Areas Commun. 2019, 37, 2239–2250. [Google Scholar] [CrossRef]
- Malik, T.S.; Malik, K.R.; Afzal, A.; Ibrar, M.; Wang, L.; Song, H.; Shah, N. RL-IoT: Reinforcement Learning-based Routing Approach for Cognitive Radio-enabled IoT Communications. IEEE Internet Things J. 2022, 10, 1836–1847. [Google Scholar] [CrossRef]
- Yang, H.; Xiong, Z.; Zhao, J.; Niyato, D.; Xiao, L.; Wu, Q. Deep Reinforcement Learning-Based Intelligent Reflecting Surface for Secure Wireless Communications. IEEE Trans. Wirel. Commun. 2021, 20, 375–388. [Google Scholar] [CrossRef]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep Reinforcement Learning for Dynamic Multichannel Access in Wireless Networks. IEEE Trans. Cogn. Commun. 2018, 4, 257–265. [Google Scholar] [CrossRef] [Green Version]
- Naparstek, O.; Cohen, K. Deep multi-user reinforcement learning for distributed dynamic spectrum access. IEEE Trans. Wirel. Commun. 2018, 18, 310–323. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Wang, T.; Liew, S.C. Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Hu, J. Performance Analysis of the IEEE 802.11p EDCA for Vehicular Networks in Imperfect Channels. In Proceedings of the 2021 20th International Conference on Ubiquitous Computing and Communications (IUCC/CIT/DSCI/SmartCNS), London, UK, 20–22 December 2021; pp. 535–540. [Google Scholar] [CrossRef]
- Ruan, Y.; Zhang, Y.; Li, Y.; Zhang, R.; Hang, R. An Adaptive Channel Division MAC Protocol for High Dynamic UAV Networks. IEEE Sens. J. 2020, 20, 9528–9539. [Google Scholar] [CrossRef]
- Cao, J.; Cleveland, W.S.; Lin, D.; Sun, D.X. Internet traffic tends toward Poisson and independent as the load increases. In Nonlinear Estimation and Classification; Springer: Berlin/Heidelberg, Germany, 2003; pp. 83–109. [Google Scholar]
- Liu, X.; Sun, C.; Yu, W.; Zhou, M. Reinforcement-Learning-Based Dynamic Spectrum Access for Software-Defined Cognitive Industrial Internet of Things. IEEE Trans. Ind. Inform. 2022, 18, 4244–4253. [Google Scholar] [CrossRef]
- Liu, X.; Sun, C.; Zhou, M.; Lin, B.; Lim, Y. Reinforcement learning based dynamic spectrum access in cognitive Internet of Vehicles. China Commun. 2021, 18, 58–68. [Google Scholar] [CrossRef]
- Liu, K.; Zhao, Q. Indexability of restless bandit problems and optimality of whittle index for dynamic multichannel access. IEEE Trans. Inf. Theory 2010, 56, 5547–5567. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Hasselt, H.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the 33rd International Conference on Machine Learning (ICML), PMLR, New York, NY, USA, 20–22 June 2016; pp. 1995–2003. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Chen, P.; Yu, G.; Wang, S. Deep Reinforcement Learning Heterogeneous Channels for Poisson Multiple Access. Mathematics 2023, 11, 992. https://doi.org/10.3390/math11040992
Zhang X, Chen P, Yu G, Wang S. Deep Reinforcement Learning Heterogeneous Channels for Poisson Multiple Access. Mathematics. 2023; 11(4):992. https://doi.org/10.3390/math11040992
Chicago/Turabian StyleZhang, Xu, Pingping Chen, Genjian Yu, and Shaohao Wang. 2023. "Deep Reinforcement Learning Heterogeneous Channels for Poisson Multiple Access" Mathematics 11, no. 4: 992. https://doi.org/10.3390/math11040992