4.1. Scene and Software Environment
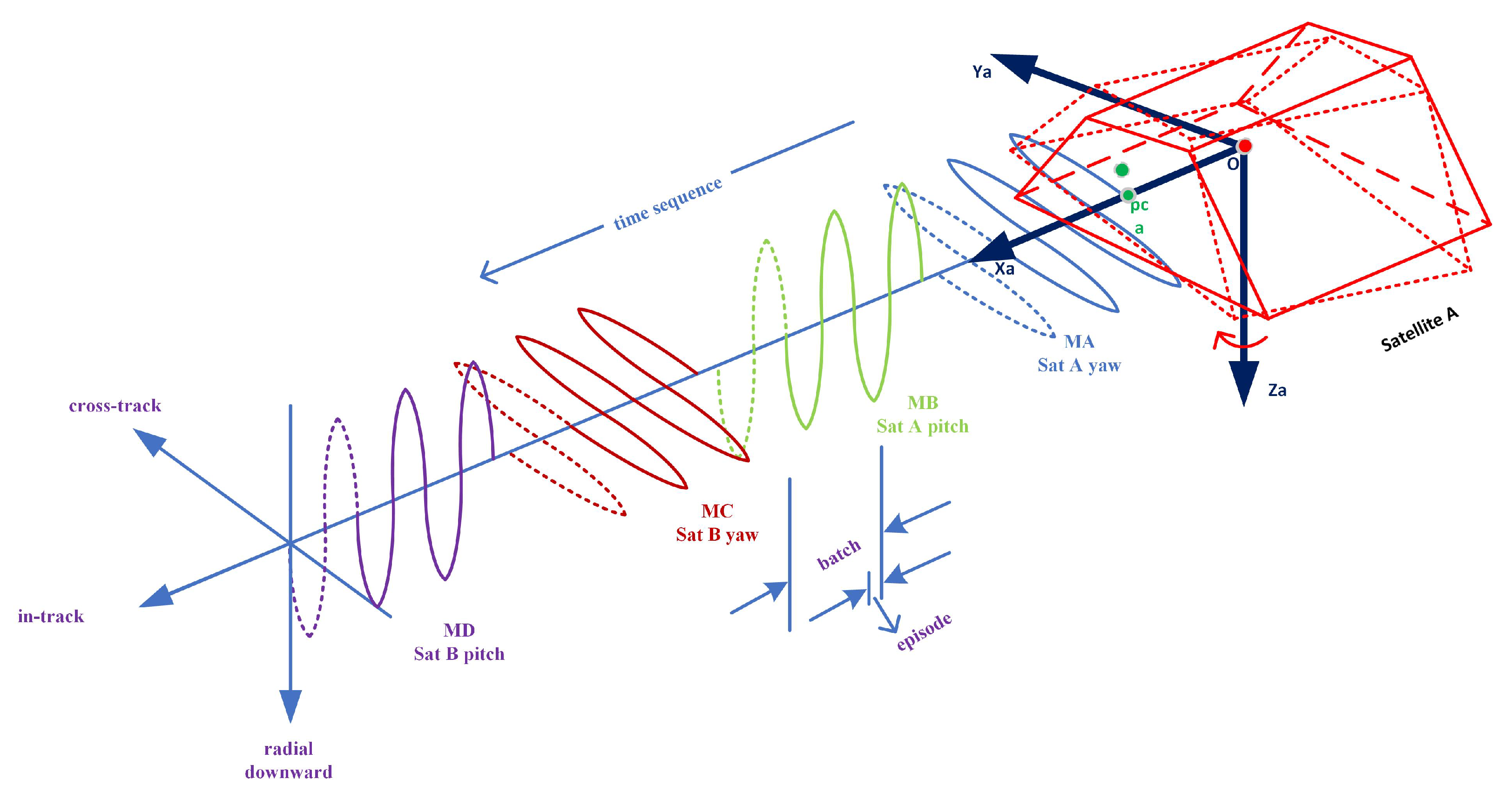
The first step to assess APC calibration performance is using software. Here we use a simple low-Earth-orbit follow-on formation scene in circular orbit with the following parameters: Satellite A orbit altitude: 470 km; inclination: 89 deg; argument of perigee: 0 deg; right ascension of ascending node (RAAN): 0 deg; true anomaly: 0 deg, and satellite B performs a follow-on flight relative to satellite A, with a distance of about 170 km in-track.
The two satellites are propagated separately in the inertial frame, using high-accuracy numerical integration, and the relative orbit information is calculated from the differences. The satellite construction model from GRACE is used for the attitude perturbations analysis in space condition [
30].
The gravitational and non-gravitational accelerations used here are summarized as in
Table 1.
To fully test and verify the APC calibration accuracy in space missions, the authors have conducted APC calibration simulation (ACS) software development based on a MATLAB/Simulink environment. The core of ACS is maneuver control and RL scene, as shown in
Figure 5. During ACS simulation, both GA and NGA dynamics are propagated, with periodic oscillation maneuvers of all kinds performed sequentially, as in
Section 2.1, including mirror maneuvers. All the data from ACS are put together into the RL block, in which the typical RL algorithm and TDAAC algorithm can be performed with on-line/off-line maneuver parameters regulating. The final evaluation of APC calibration accuracy can be provided using synchronized script files. Note ACS can also function as a standard high-accuracy modelling software that provides preliminary Level-1B data in a 5 s sampling rate, from initial 1 January 2000, 12:00:00 GPS time [
22], including onboard instrument output of GPS navigation data, MWR ranging, star camera quaternions, accelerations and Laser ranging interferometer (LRI) data [
11].
4.2. ASC Simulation Using Traditional Method
Here we first provide the APC calibration results without the RL process. Suppose we known the fixed real position of APC
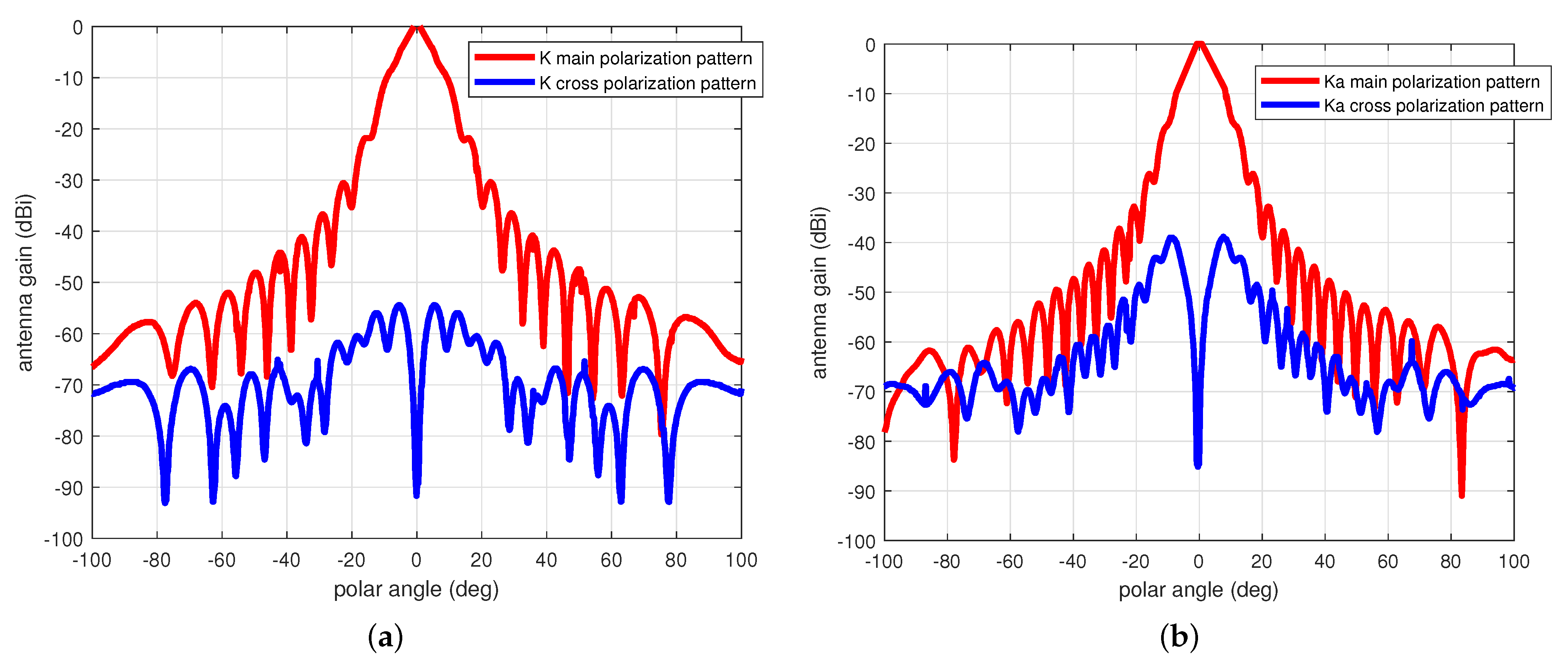
in the spacecraft frame, for both satellite A and B. The real models of K/Ka dual frequency antenna gain pattern and induced signal process noise are used. The moment of inertia for the two satellites are
and the attitude maneuver control is simply conducted through a PID algorithm. APC with period maneuver is used here with maximin amplitude of 1 deg in yaw direction, 3 deg in pitch direction, and the period of the oscillation is set to about 250 s. Note the period maneuver parameters are constrained by the ADCS system of the satellite platform and attitude actuators on-board.
The APC calibration simulation lasted for 4000 s with 4 full sub-maneuvers, 1000 s each, and sampling time is 5 s.
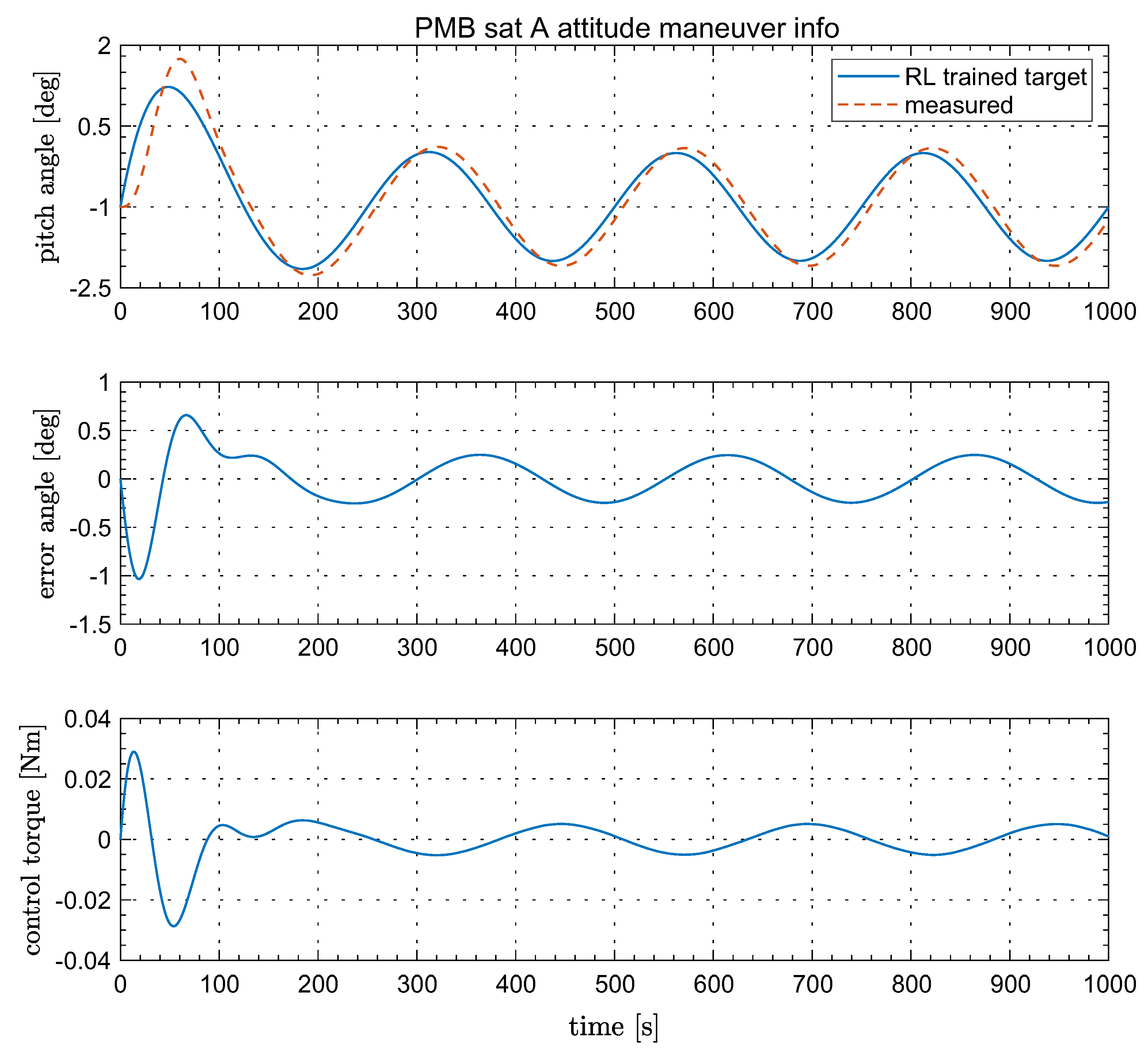
Figure 6 provided the simulated attitude results of satellite A, through sub-maneuver A and B in yaw and pitch directions. The data include target attitude, real attitude from measurement, attitude control error and the attitude control torque. By using the traditional APC batch algorithm, we have the final APC estimation value of
With Equation (
8) in
Section 2.1, the APC calibration error is 0.243 mrad for sat A, 0.254 mrad for sat B.
4.3. RL Simulation Using ACS Software
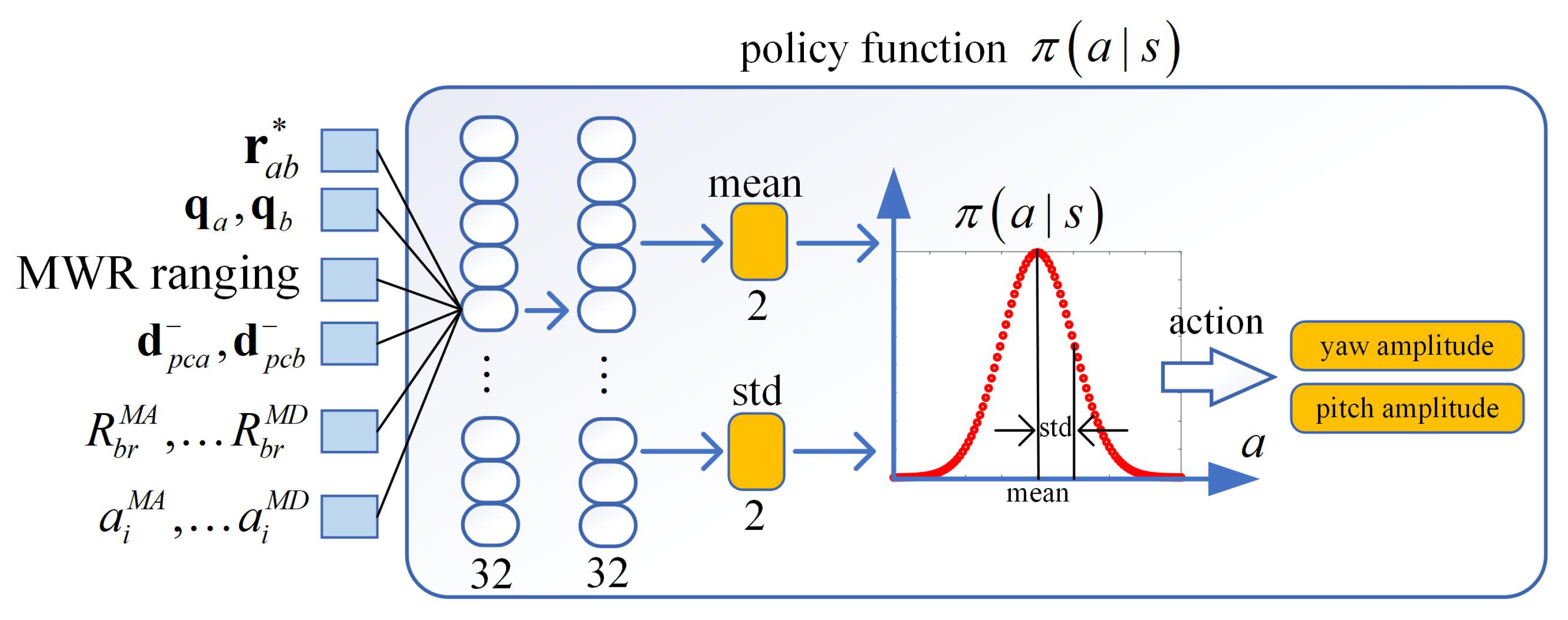
To test the APC calibration algorithm with the RL process in a software environment, here we use two neural networks that approximate the value prediction and action taken. The NN consist of input, hidden layer and output layer, while the input of both networks including measurement from carrier phase differential GPS
, attitude from star sensor
, and MWR ranging, and states vector, as in
Section 2.1. The hidden and output layer composed of neural nodes with affine transformation and nonlinear mapping functions, as
where
is the output of the
j-th node in
i-th layer,
is the stacked output of the previous layer,
are the weights and biases of the
i-th layer, and
is the activation function. Here we use the critic network of 2 hidden layers of 64 nodes, with the Rectified Linear Unit (ReLU) activation function.
For the purpose of the policy function approximate, the actor NN is used with ReLU nodes in hidden layers, and a sinusoidal function for limited output layer. The final output provides the mean and standard deviation of two normal distributions for the yaw and pitch maneuvers amplitude angle in the form of a probability distribution function, and the results feedback to the ACS target quaternion block as marked ① in
Figure 5. The NN diagram for the proposed RL-based APC calibration is depicted in
Figure 7 and
Figure 8 as
The training target is to minimize the APC estimation error from the batch algorithm, with the optimal periodic oscillation amplitude, rather than the nominal designed 1 deg around 3 deg initial bias angle in yaw maneuver. Note the K band antenna gain would decrease dramatically out of 6 deg in the main lobe, so we just need to sample actions within 3 deg from the policy, avoiding the whole action space exploration. The similar settings also apply to the pitch maneuver with 3 deg amplitude around −1 deg initial bias angle. The instant reward function is given as
where the definition of
can be found in Equation (
9), and
denote reward function weights.
The final target APC estimation accuracy interval is a trade-off situation that have to be considered for RL implementation. Here we use the idea of shrinking goal interval, with 0.003 mrad decreasing for each training episode [
25]. The purpose of doing this is to avoid lack of training with a quick APC calibration process finished, under a large goal interval; and also avoid low chances of reaching the goal interval through the exploration step.
The RL training episode consists of 100 steps each, with each step of 0.05 s in the ACS software. This timing sequence can be easily interpolated into an attitude control system for on-line APC maneuver execution.
Table 2 below provided the parameters used during simulation:
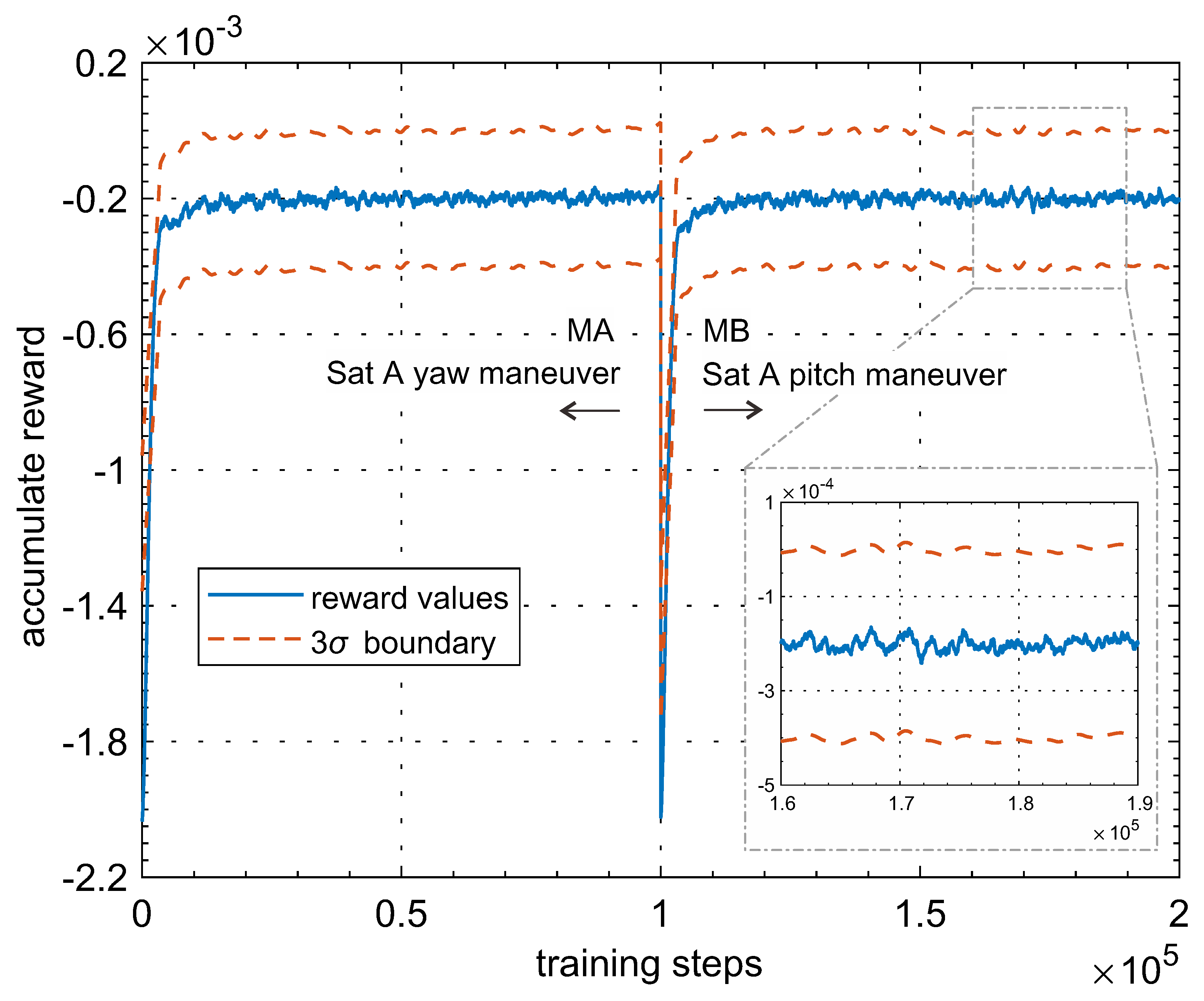
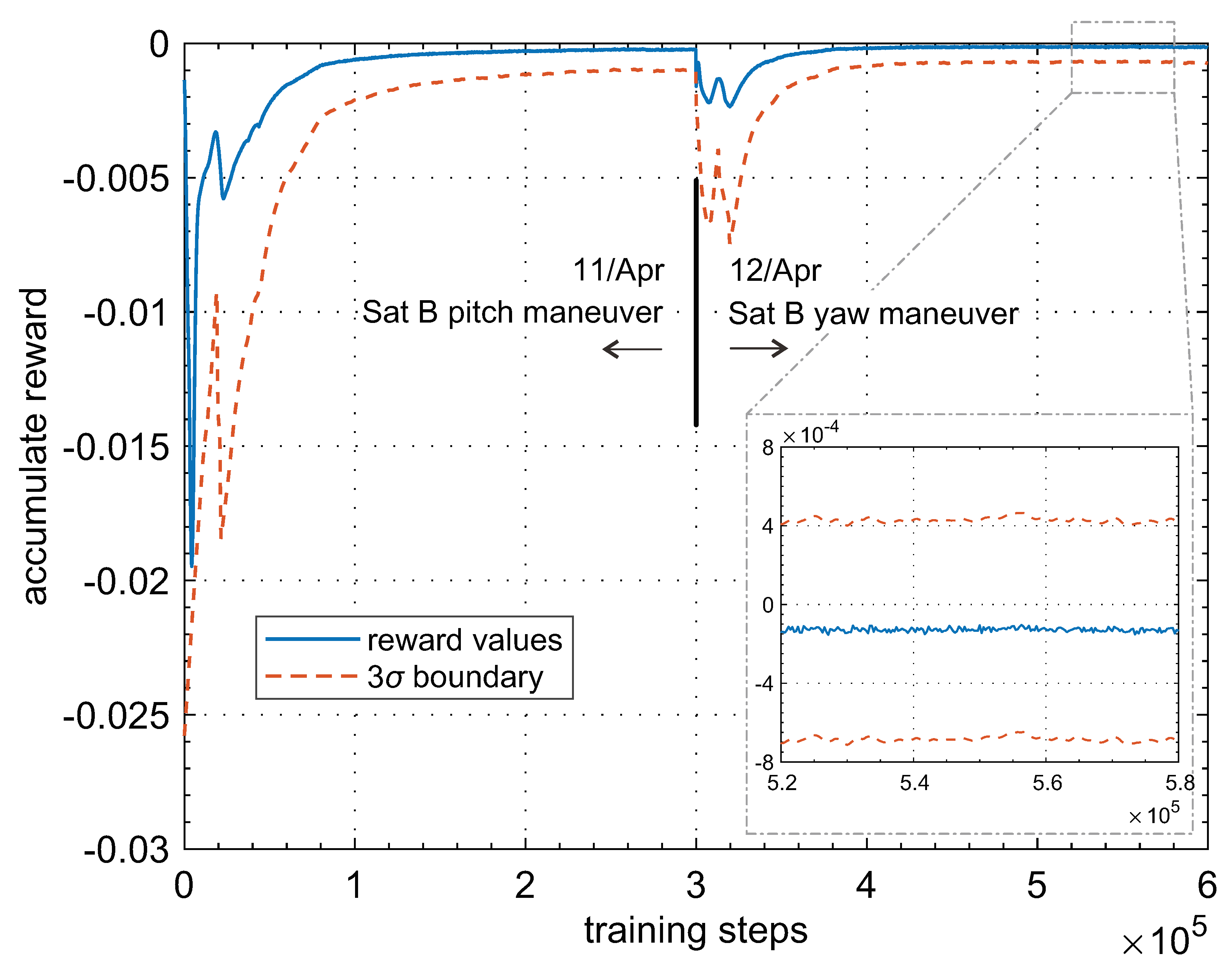
The data collected from the RL training process during APC calibration are shown in
Figure 9 as a solid red line for reward and dotted green lines for deviation. Only the results of satellite A from sub-maneuvers A and B are provided here for the purpose of simplicity. We may find that the training results converged gradually to the real APC position. According to the definition of reward in Equation (
9), the policy NN can be trained to steady within about 40 thousand steps, and the final APC calibration error may be below 2 mrad, as in zoom in subfigure in
Figure 9, which is more accurate than the traditional batch algorithm. After the post-data statistics, we found the accumulated reward is improved from MA to MB, after the training NN converges. The reason may be explained as this: the APC position is composed of elevation and horizontal values in the antenna coordinate frame, which can be estimated through on-orbit maneuvers in yaw and pitch directions for one satellite. Surely more accuracy results may be obtained after two maneuvers. Similar results can be found for satellite B through sub-maneuvers C and D, which are not shown here.
It is interesting to explore what kind of sub-maneuvers trajectory we may obtain from the NN training process. The target attitude maneuver amplitude finally converged to about 1.1 deg for both MA and MB, in yaw and pitch direction.
Figure 10 provides the MB pitch angle values with attitude control error and control torque. The trained target amplitude, not considering the constraints of satellite ADCS, is mainly affected by the emission gain of the antenna. The optimal attitude amplitude balances the APC observation sensitivity in yaw and pitch directions and the deteriorated MWR ranging error outside the antenna main-lobe.
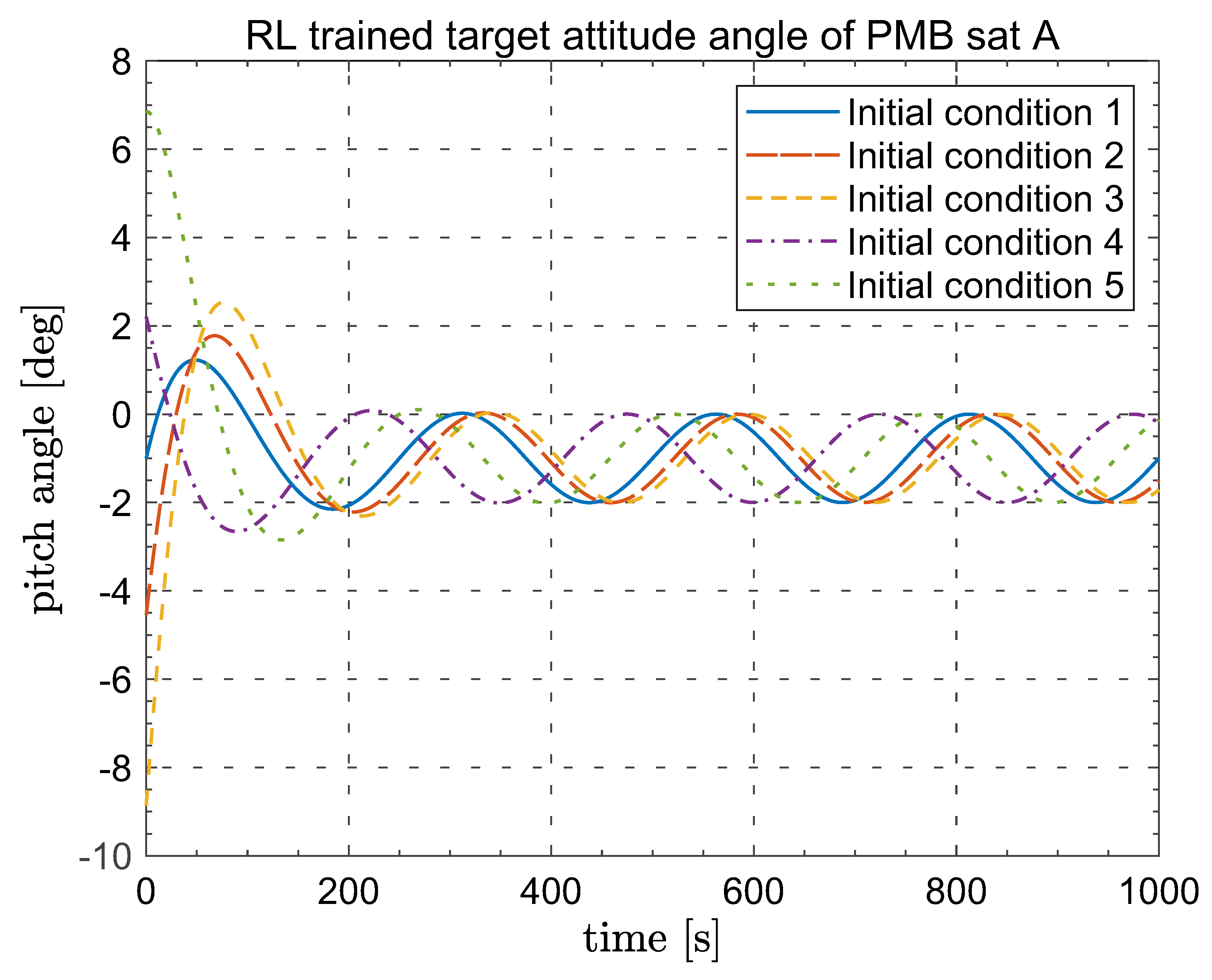
Moreover,
Figure 11 provided the trained target amplitude of MB pitch angles under different initial conditions. We may find that the trained output converge quickly with the expected values as shown before, which verified the effectiveness of the proposed method.
Recall that the initial attitude angles for APC calibration are predefined as 3 deg in yaw maneuver, and −1 deg in pitch. It would be curious to find what results we may obtain if the initial angles changed.
Figure 12 shows the modified policy NN with output, including both initial angles and amplitudes. The final results after simulation are as follows: initial angles around 2.8 deg in yaw and −1.5 deg in pitch, and the amplitudes converged to about 1 deg for yaw and pitch. The trained initial pitch angle, around −1.5 deg, is reasonable since the predefined −1 deg is aiming to get LOS pointing between satellite A and B on-orbit, in orbit frame, and −1.5 deg can obtain more sensitive MWR observing data for APC estimation.
RL-based APC calibration can obtain better results after training, compared with traditional batch algorithm. More importantly, the RL architecture can be extended to deep training applications such as the feedback to attitude control system, as number mark ② in
Figure 5, or extended to linear calibration maneuvers with proof mass states and attitude dynamic equations. Those would be provided in the authors’ following publications.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}