1. Introduction
The IoT concept was proposed by Kevin Ashton in 1999, and there are many sectors in developed and developing countries that have investigated IoT-based projects [
1,
2,
3,
4]. Thus, an IoT application relies on uniquely identifiable objects with sensing, connectivity, and interoperation capabilities [
5]. It is worth mentioning that a certain number of IoT-based standards have been developed, while there are still some research challenges for designing IoT middleware and providing security [
6]. Then, the SIoT was proposed as an extension of IoT technology. The idea of the SIoT consists of establishing social relationships between IoT devices. Moreover, the SIoT aims to provide decentralized intelligence by allowing IoT objects to become social and smart. Along with decentralizing the intelligence, an SIoT object can request support from its social IoT objects to complete a specific request. More importantly, the Quality of Experience (QoE) is high in the SIoT, which may also lead to creating a business model by monetizing information and connectivity sharing [
7]. Upon receiving the client’s request, the SIoT object checks if it can handle the received request. Elsewhere, the request will be forwarded to its friends. Therefore, selecting social friends is a crucial step that impacts the reliability of the SIoT application [
8]. As stated in [
7,
9], five important social relationships can be established between SIoT objects, as summarized in
Table 1.
There needs to be standard architecture for the SIoT. Nevertheless, there are four available SIoT architectures: device, global connection, platform, and application layers [
10]. As reported in [
11], the SIoT has been successfully applied to a smart home for home safety and energy efficiency. One of the big challenges of the SIoT is related to identifying and communicating relevant data, given that the SIoT data may be structured/instructed [
9]. Additionally, various types of SIoT data, including audio, video, and text, can be accessed and communicated in an SIoT network. In this regard, the authors of [
12] developed a realistic SIoT dataset extracted from a smart city scenario. The considered dataset allows the incorporation of static and mobile devices. Besides, the data model allows the creation of a profile for each object to define the potential set of offered services and applications that can be deployed. More specifically, an analysis of the impact of each social relationship on network navigability was presented in [
12]. The topic of the data analysis of the SIoT has been addressed in many recent papers [
13,
14].
Lakshmanaprabu et al. [
15] introduced a framework for effectively classifying SIoT data. The developed framework was based on map-reduce and a supervised classifier model. In particular, the SIoT was investigated for analyzing the trajectories of many users. Therefore, a recommendation system was developed in [
15,
16] for service discovery using the knowledge–desire–intention (KDI) model. Another topic that has attracted researchers concerns sentiment analysis in the SIoT. Notably, three levels of sentiment analysis exist, and they embrace the document level, sentence level, and aspect level. The first level categorizes sentiments from the entire document, while the second predicts the sentiment popularities expressed in each sentence. The aspect level is more efficient than the first and the second levels, as it classifies sentiments expressed in opinions [
17]. Despite the amount of SIoT data, the multimodality and accuracy of sentiment analysis are the main challenges.
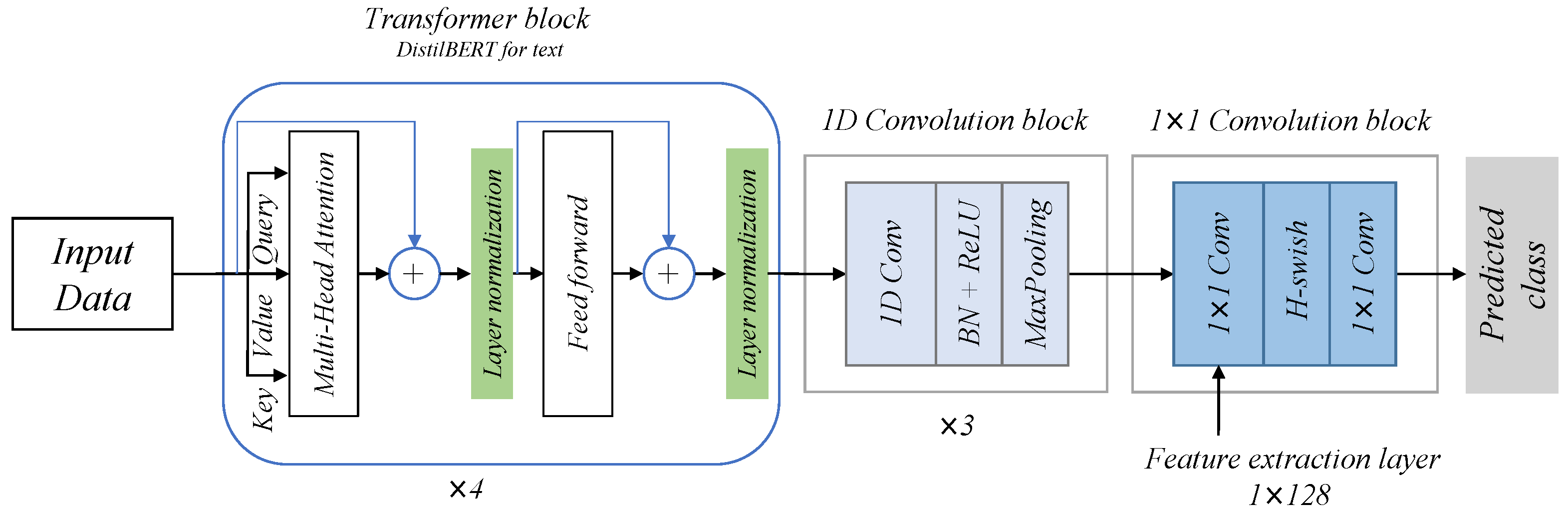
Therefore, this paper aimed to develop a novel multimodal deep learning model that can predict the user-generated data sentiment, activity, event, crisis-related event, or social-media-related event in the SIoT. This model depends on an architecture combining two model structures, including Transformers and Convolution Neural Networks (CNN) as feature extraction methods and using an alternative feature selection method. Actually, those features refer to the representations or patterns used to discriminate between the classes/groups of data; some of these features are redundant. Therefore, the combination of Transformer and the CNN can help with learning different levels of features and extracting meaningful representations such as contextual representations in textual data. The feature selection method is developed according to the behavior of Chaos Game Optimization (CGO) [
18], which simulates the concepts of chaos theory [
19]. Based on these concepts, CGO has been applied to solve different optimization techniques, including constrained engineering design problems [
20], parameter extraction of the three-diode photovoltaic model [
21], energy futures price forecasting [
22], and proton exchange membrane fuel cells [
23]. The developed method starts by constructing the DL architecture, named the Transformer CNN (TransCNN), and uses it to extract the features from the tested datasets. This process is followed by dividing the dataset into training and testing, then using the binary version of CGO to find the relevant features of the training set from those extracted ones. After that, the best solution (relevant features) is used to reduce the size of the testing set by removing the irrelevant features and to evaluate the quality of those features using different performance metrics.
The main contributions can be summarized as follows:
We propose TransCNN as a new DL architecture as our main feature extractor with pluggable components that exploit textual and numerical data.
We present an alternative FS technique based on a binary version of Chaos Game Optimization (CGO).
We evaluated the efficiency of the developed method by comparing with other models and using different SIoT datasets.
The rest of this study is organized as follows:
Section 2 presents the related works of the techniques applied to handle the SIoT dataset.
Section 3 introduces the background of Transformer-based models and chaos game optimization. The proposed method is presented in
Section 4. The results and their discussion are given in
Section 5. The conclusion is presented in
Section 6.
2. Related Works
The authors of [
24] presented a framework for mining Twitter and analyzing users’ perceptions of the SIoT. The proposed framework allows us to obtain a Twitter feed. The data cleaning and pre-processing detects slang, applies lemmatization, and removes stop words. After that, extensive sentiment analysis was conducted based on an Improved Popularity Classifier (IPC), SentiWordNet (SWNC), Fragment Vector Model (FVM), and hybrid classifier that combines the IPC and SWNC. The experimental results discussed in [
24] demonstrated that the FVM, which is a semi-supervised algorithm, achieved the best accuracy of 94.88%. The approach presented in [
24] is simple to apply. However, it has yet to be compared to other benchmark techniques. Further, it is limited to unimodal text.
The work presented in [
25] targeted the classification of sentiments in Twitter real-time data, where multiple-sentence tweets and multi-tweet threads were considered. Thus, Reference [
25] explored a Hierarchical Attention Network (HAN) that was developed based on a Recurrent Neural Network (RNN) composed of GRU/LSTMs and attention mechanisms. In particular, the main motivation for the approach described in [
25] consists of analyzing sentiments in real-time Twitter data, including multiple sentences, as well as multiple tweets. Moreover, the HAN allows one to read a full sentence, and then, the attention mechanism selects the most-significant words. Next, the HAN outputs a sentence that incorporates the semantic content of the input sentence. Additionally, the HAN includes a sentence hierarchy process for creating document embedding. Two English tweet datasets, including the Standard Twitter sentiment Gold standard (STC-Gold) and the SemEval-2017 datasets, were used for evaluating the proposed HAN, which achieved an accuracy of 71.7% and 94.6%, respectively. The evaluation of the results of the approach introduced in [
25] is limited to two datasets. Additionally, the authors did not exploit multimodal text.
So far, the problem of multimodal sentiment analysis has been studied in many research papers. The model explained in [
26] integrated interactive Transformer and Softmax mapping. The former can detect the current interactive information between modalities, while the latter projects each modality in a new space for further fusion. The Multimodal Opinion Sentiment and Emotion Intensity (CMU-Mosei) (
http://multicomp.cs.cmu.edu/resources/cmu-mosei-dataset/, accessed on 2 January 2020) and Multimodal EmotionLines (Meld) (
https://affective-meld.github.io/, accessed on 2 January 2020) datasets were selected for testing the proposed approach, which demonstrated good results compared to the benchmark techniques. In particular, the best accuracy achieved by the proposed approach was 82.47% for binary classification. We mention that the contribution introduced in [
26] was limited to linguistic and acoustic modalities.
The contribution presented in [
27] considered two levels of multimodal fusion for sentiment analysis. The first level combines text with audio and combines text with video features. The Softmax fusion was applied to combine the prediction results. The Multimodal Corpus of Sentiment Intensity (CMU-Mosi), CMU-Mosei, and Interactive Emotional Dyadic Motion Capture (Iemocap) (
https://sail.usc.edu/iemocap/, accessed on 2 January 2020) datasets were evaluated, and the proposed approach outperformed the benchmark techniques for binary and multi-classification, where the best-achieved accuracy attained a value of 97.86%. The effectiveness of the approach presented in [
27] is mainly related to fusion at the data and decision levels.
The framework published in [
28] allows a dynamic fusion of various modalities for sentiment analysis. Besides, the authors of [
28] suggested and validated a new loss function that supported finding the suitable target sub-space. Considering the CMU-Mosi and CMU-Mosei datasets, the approach described in [
28] achieved the best accuracy among the benchmark techniques for the two evaluated datasets, and the best accuracy attained a value of 87.5%. Notably, the framework designed in [
28] performs the fusion of audio, visual, and language data. Unfortunately, the validation of the results was limited to two datasets.
The idea presented in [
29] focused on human multimodal language based on a network that extracts multimodal sequence features. Thus, the model proposed in [
29] considers language, vision, and acoustics. More specifically, the Gated Recurrent Unit (GRU) network [
30] was explored to generate internal modal information. Then, the Softmax function was used to calculate the correlation between two timestamps. Finally, the ReLU function and Sigmoid layer were used for sentiment analysis. The proposed method was validated using the CMU-Mosei dataset, where the proposed approach demonstrated the best F1-score for binary sentiment classification. It achieved good results for six label classifications for emotion classification. We mention that the best accuracy achieved by the method proposed in [
30] was 93.1%. More specifically, the approach published in [
31] enables analyzing multimodal sentiment while considering the constraint of time delay between multimodal signals.
The model’s objective presented in [
31] is to handle the problem of the dynamic weights of multimodal data. To this end, a Bidirectional Encoder Representation Transformer (BERT) [
32] and a Transformer encoder [
33] were adopted. Hence, the CMU-Mosei and CMU-Mosi datasets were used, and the results discussed in [
32] were evaluated in terms of the mean absolute error, Pearson correlation, and accuracy. It is worth mentioning that the approach proposed in [
31] provided the best results for all performance metrics for the two datasets. It is worth mentioning that the framework presented in [
31] is based on different encoding techniques for dealing with multimodal data. Hence, BERT was adopted to provide lexical embedding, while the Transformer’s encoder was proven to be effectivefor visual and acoustic data. Another advantage of the framework described in [
31] is that it was tested for aligned and non-aligned data.
The authors of [
34] proposed an Integrating Consistency and Difference Network (ICDN) that relies on mapping transfer between different modalities. The mapping transfer was also investigated to extract multimodal features. The CMU-Mosi and CMU-Mosei datasets were explored to validate the proposed approach for multi-classification and regression tasks. More specifically, the approach presented in [
34] attained the best results regarding the accuracy, F1-score, mean absolute error, and correlation compared to the baseline techniques. The best-achieved accuracy for binary and multi-classification was 83.8% and 52.0%, respectively. The major advantage of the ICDN over related works concerns the reduction of interference between irrelevant modalities. The model presented in [
35] can support inter- and intra-modality dynamics. Further, the asymmetric window is used to represent the asymmetric weights of context. The approach presented in [
35] was tested on the CMU-Mosi dataset, and it achieved the best accuracy and the best F1-score of 80% and 79.9%, respectively. The model introduced in [
35] is limited to analyzing sentiments in user-generated videos.
The authors of [
36] recently developed a self-attention fusion framework that considers text, audio, and visual features. Hence, the proposed framework allows the detection of internal and external features’ correlation. It is built based on an attention network, which takes the three stated features and outputs the attention scores to indicate the importance of each feature. More specifically, the self-attention framework is hierarchical and based on a read–write mechanism to capture the correlation of different modalities. The experimental results shown in [
36] were conducted using the CMU-Mosi dataset and showed the effectiveness of the self-attention mechanism for increasing the accuracy compared to the benchmark techniques.
With the high-quality results obtained using the previously discussed method, they still had some limitations with respect to their quality. For example, the ability to balance between global and local search still requires more improvements. Since this will influence the quality of the selected features that will reflect the classification accuracy, this motivated us to propose an alternative FS method based on the integration between the CGO and TransCNN as a DL model.
3. Background
In this section, the background of Chaos Game Optimization (CGO) is introduced (as in Algorithm 1). In general, CGO emulates the concepts of chaos theory [
18,
37]. The CGO is similar to other MH techniques, which generate a set of solutions (i.e., eligible seeds)
X as defined in the following formula:
where
D represents the dimension of the solution.
is a random value belonging to [0, 1].
Thereafter, the fitness value of
is computed, and the solution that has the best fitness is assigned as the best solution
. The next process is to compute the mean values of the chosen solutions, named the Mean Group (
). Then, a temporary triangle is constructed according to
, and
. Then, each temporary triangle produces four new solutions (seeds) as defined in the following equations.
where
and
are random values generated from [0, 1].
refers to the factorial used to simulate the movement limitations of
X. The value of
can be updated using the following formula:
where
denotes a uniformly random value.
and
are the random integer values. Then, the fitness value of the four seeds is computed, then we replace the worst solutions with these new solutions. After that, the stop conditions are checked, and in case they are satisfied, the updating process is stopped and the best solution returned.
| Algorithm 1 Algorithm of CGO. |
- 1:
Input: - 2:
D: the number of starting eligible seeds. - 3:
Initialize the starting positions () with random values of eligible seeds (). - 4:
Output: - 5:
G: the global best eligible seed. - 6:
Method: - 7:
Compute the objective function for each eligible seed. - 8:
repeat - 9:
for to D do - 10:
Create a mean group (). - 11:
Construct temporary triangles on three vertices of , G, and . - 12:
Create new seeds by Equations ( 2) to ( 5). - 13:
if boundaries are crossed by new seeds then - 14:
Position limitations can be adjusted for new seeds. - 15:
end if - 16:
Assess the fitness of new points. - 17:
if new seeds have a higher objective function than the last initial eligible seeds then - 18:
Substitute the last points by the new ones. - 19:
end if - 20:
if the best solution is achieved then - 21:
Amend G. - 22:
end if - 23:
end for - 24:
until The iteration criterion has been met. - 25:
Return G.
|
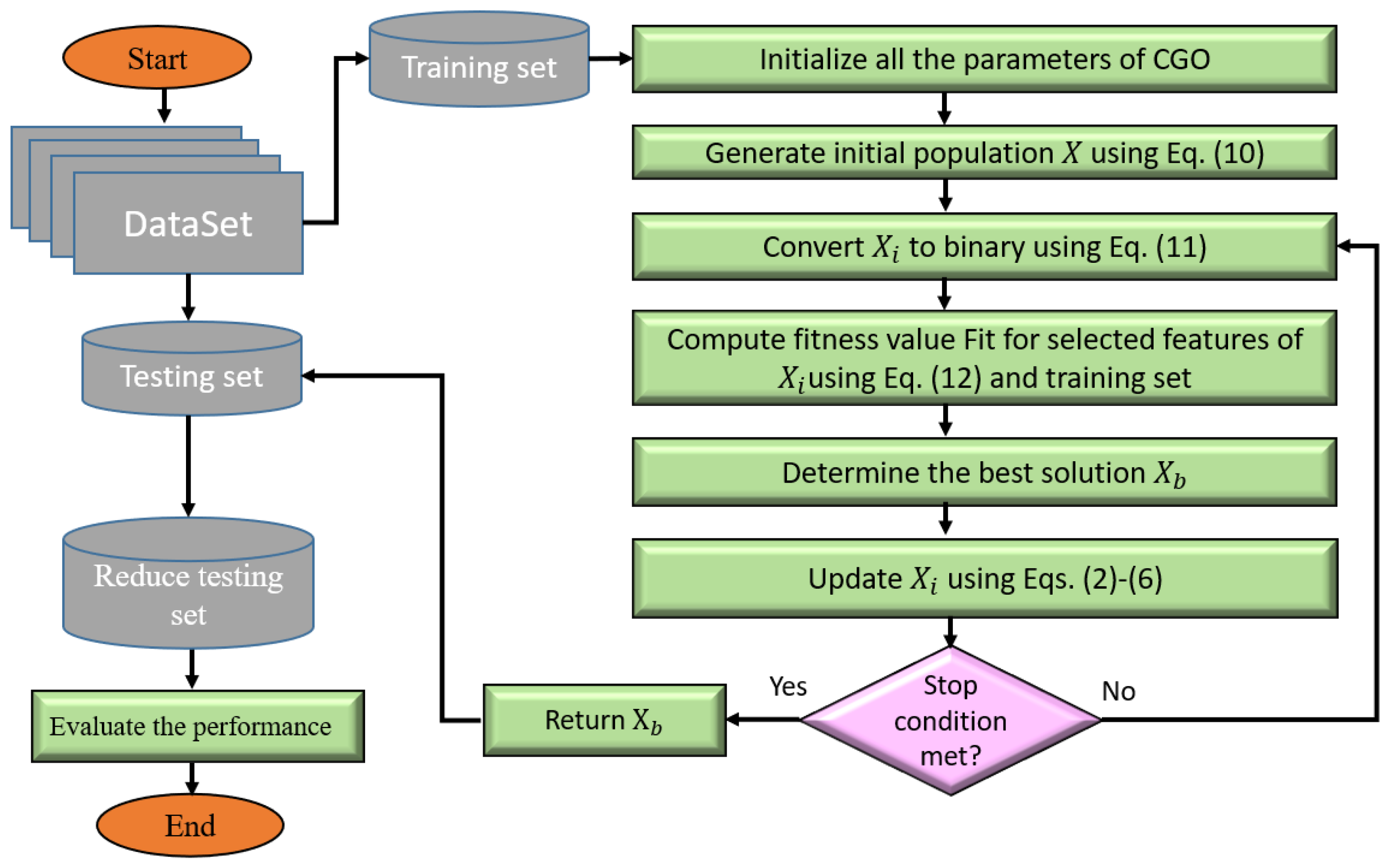
5. Experiments and Results
Within this section, we discuss the results of the developed SIoT model based on the CGO algorithm as the FS technique and the TransCNN as the feature extraction approach. The performance of a modified CGO is compared with a set of ten algorithms including the Honey Badger Algorithm (HBA) [
46], Grey Wolf Optimizer (GWO) [
47], Dwarf Mongoose Optimization (DMOA) [
48], Chameleon (Chame) [
49], Electric Fish Optimization (EFO) [
50], Arithmetic Optimization Algorithm (AOA) [
51], Aquila Optimizer (AO) [
52], Reptile Search Algorithm (RSA) [
53], LSHADE [
54], and Self-adaptive Differential Evolution algorithm (SaDE) [
55]. In this experiment, we used the original values of the parameters of each of these algorithms. In addition, for a fair comparison, we set the number of iterations and the number of solutions to 30 and 20, respectively. Those algorithms were conducted using Matlab 2014b installed on a computer with Windows 10 64 bit with 8 GB RAM Intel Core i5 processor.
5.1. Dataset Description
During our experiments, we used several datasets covering a variety of data types, tasks, and attributes related to SIoT applications.
Table 2 lists the attributes and tasks we used in our experiments. For instance, Human Activity Recognition (HAR), healthcare, event detection, and sentiment analysis were the tasks. The data types included numerical and text. The total datasets used to validate the proposed framework was eight. For the numerical datasets, we used the following datasets from the UCI repository: GPS trajectories dataset, GAS sensors dataset, Hepatitis dataset, MovementAAL (Indoor User Movement Prediction from RSS) dataset, and UCI HAR dataset. For the text datasets, we used the following datasets: STS-Gold [
56], SemEval2017 Task4 dataset [
57] and C6 dataset [
58]. In addition, 77% and 33% split ratios for the training and testing set were used, respectively. In addition, the new version of the extracted features using the proposed DL model is given in
Table 3.
5.2. Evaluation Metrics
In our experiments, several evaluation indicators were used to validate the proposed framework and present a clear insight into the performance of the developed optimization method. In addition, we combined the common evaluation metrics to perform a fair comparison against state-of-the-art methods, including accuracy, fitness value, sensitivity, and specificity. The used evaluation metrics are defined as follows [
59]:
where
represents the average accuracy and
represents the highest obtained accuracy value.
is the number of iterations or runs. TP, TN, FP, and FN represent the True Positive, True Negative, False Positive, and False Negative rates from the confusion matrix representing the classification report [
59].
is calculated as:
where
represents the average sensitivity based on
, which is also known as the true positive rate, representing the rate of predicting positive classes.
5.3. Results and Discussion
The comparison results between the developed CGO and others are given in
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8. In
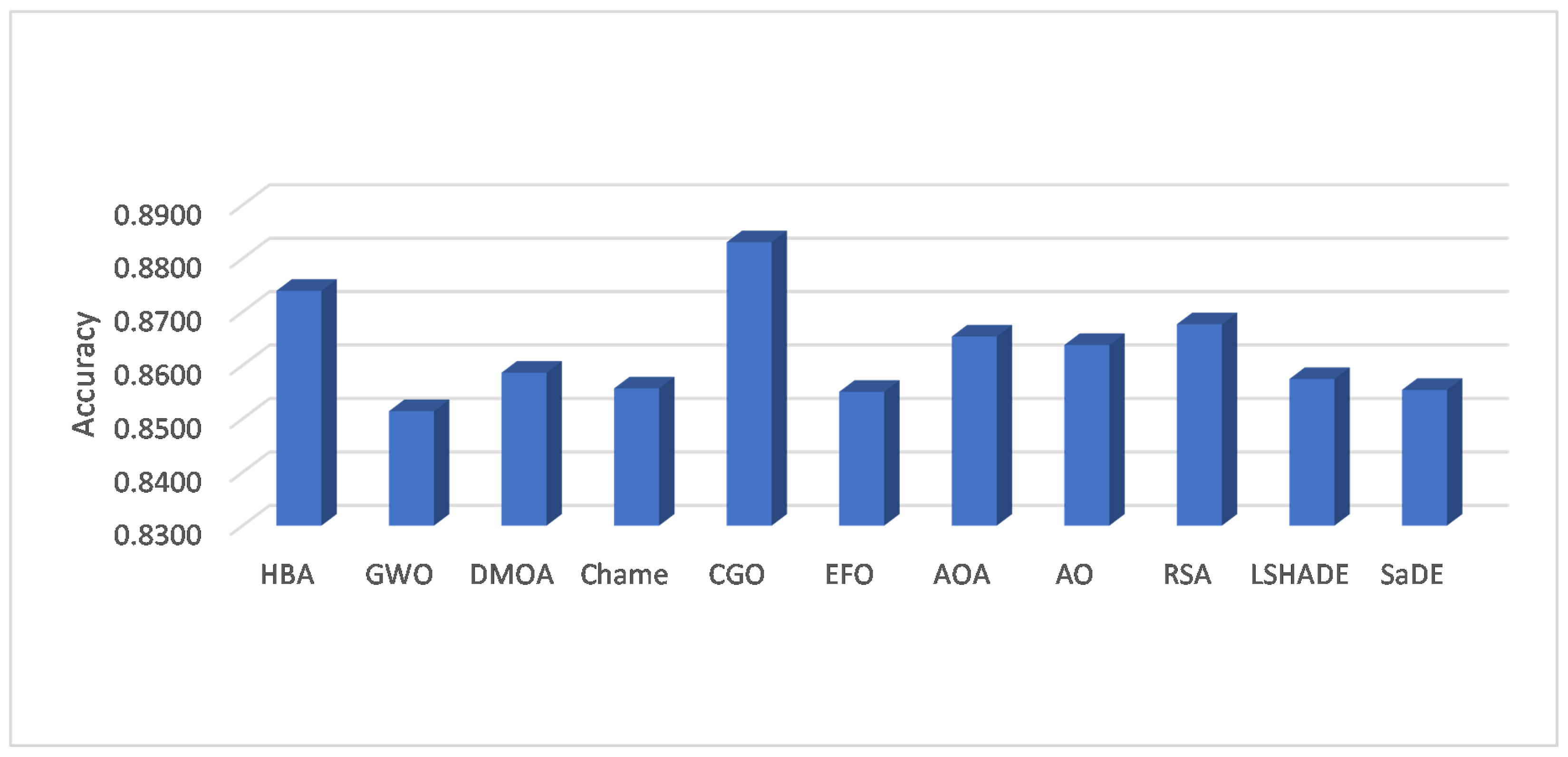
Table 4, the average classification accuracy is shown, and it can be seen that the developed CGO performs better on seven datasets. This nearly represents 88% of the total number of datasets. This is followed by the HBA, which has the best accuracy for one dataset: Hepatitis. CGO and the HBA obtained the same accuracy, equal to 94.10%, on the STSGold dataset in terms of textual datasets. In addition,
Figure 3 depicts the average accuracy among the eight datasets, and we can observe that CGO has a higher value. In terms of average accuracy, CGO outperformed the HBA by more than 1%. This indicates the efficiency of CGO over all other methods, whereas the HBA is ranked second and the RSA third.
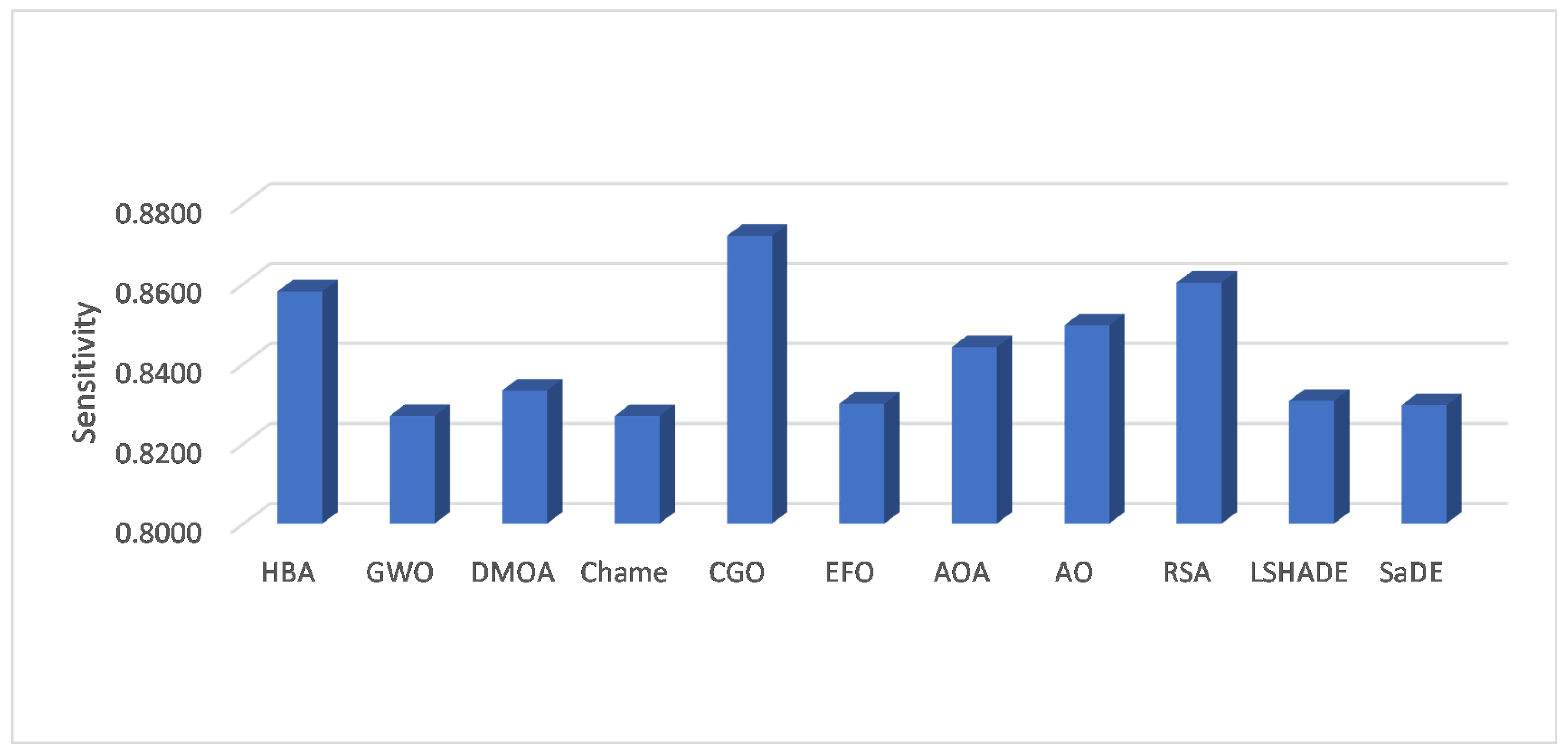
According to the sensitivity values given in
Table 5, it can be noticed that CGO and the HBA have the best sensitivity values for three and two datasets, respectively. They are followed by the RSA, EFO, and GWO, which have the highest sensitivity for one dataset. In addition, the average sensitivity among the eight datasets, as in
Figure 4, shows that CGO is the best algorithm. The RSA follows CGO, which provided a sensitivity better than the other methods, and the HBA is in the third position according to the sensitivity measure.
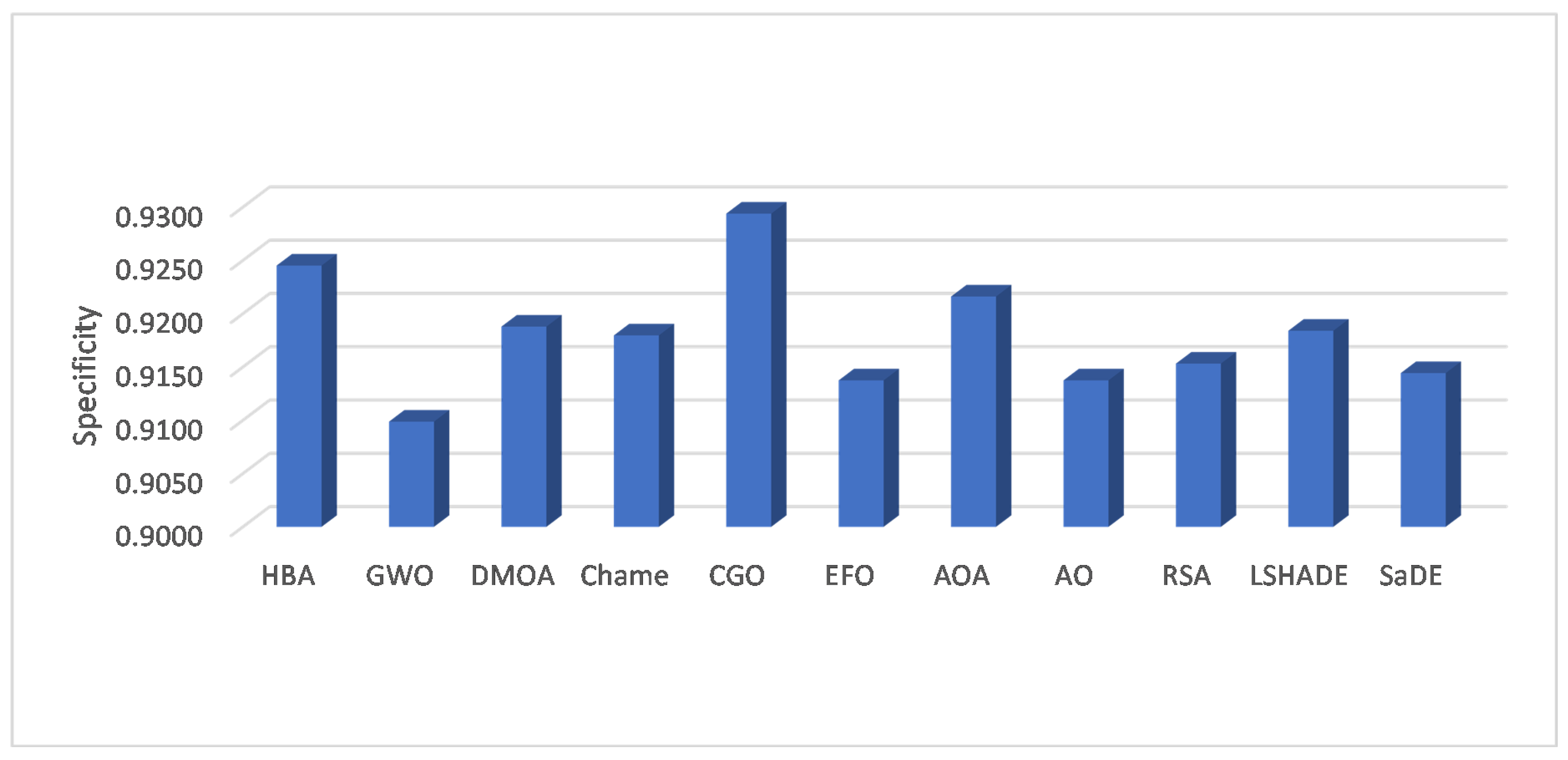
Table 6 illustrates the specificity value obtained using CGO and the other methods. These values show that the HAB and CGO have nearly the same performance since both have the best value for the four datasets. In addition, they have the same value for the two datasets named Trajectory and Sensors. At the same time, the RSA provides results better than the other methods in terms of specificity. The same observation can be noticed in
Figure 5, which depicts the average specificity among the eight datasets.
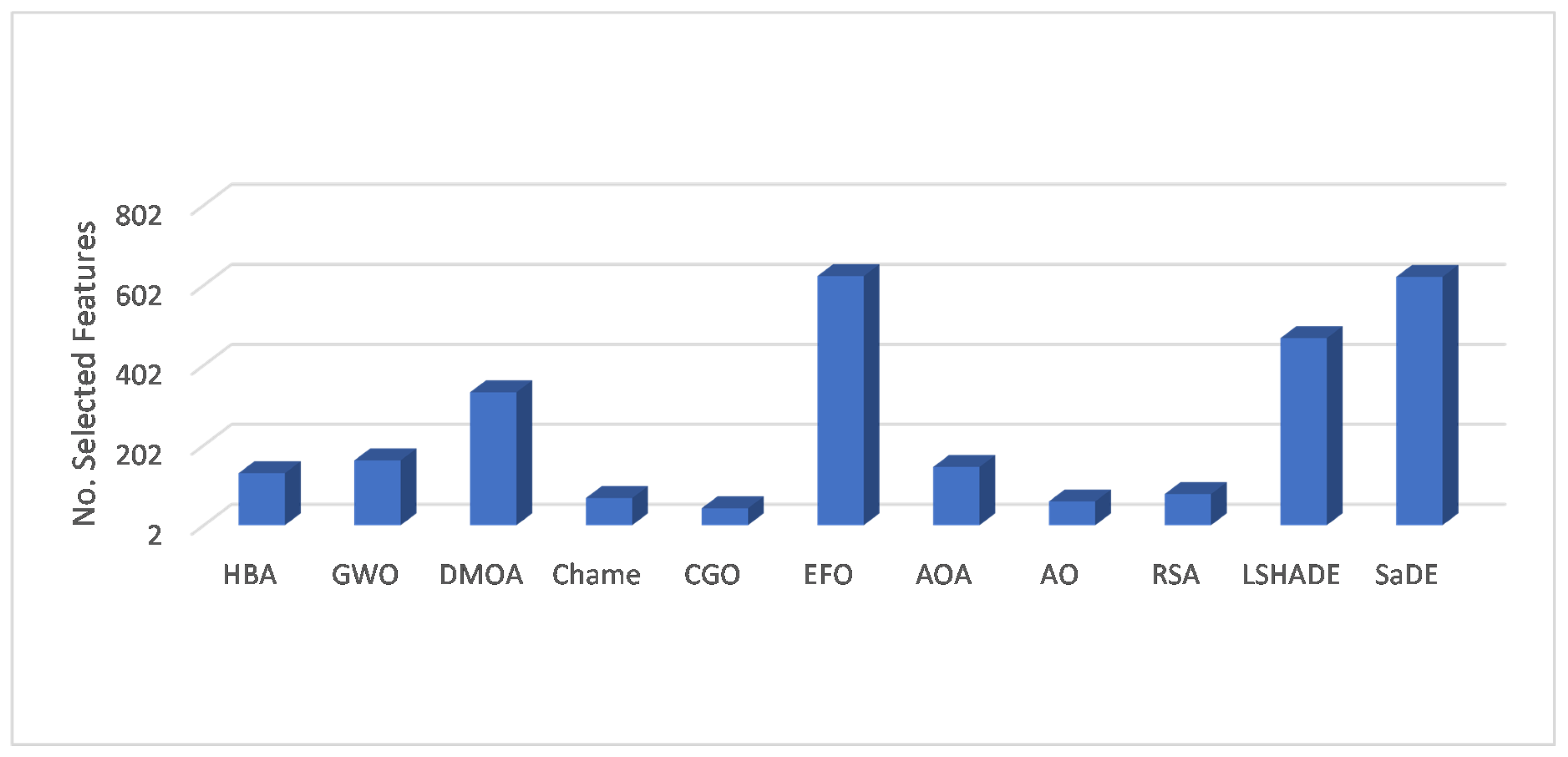
Table 7 depicts the average of the selected features obtained using CGO and the other methods. From those results, we can notice that the smallest number of selected features is obtained using CGO for the five datasets. The HBA, AO, and RSA have the smallest number of selected features in one dataset. Moreover, it can be seen from
Figure 6 that CGO has a loweraverage of the selected features among the tested datasets, followed by AO, and the RSA, which are the second and third, respectively, best algorithms according to the selected features.
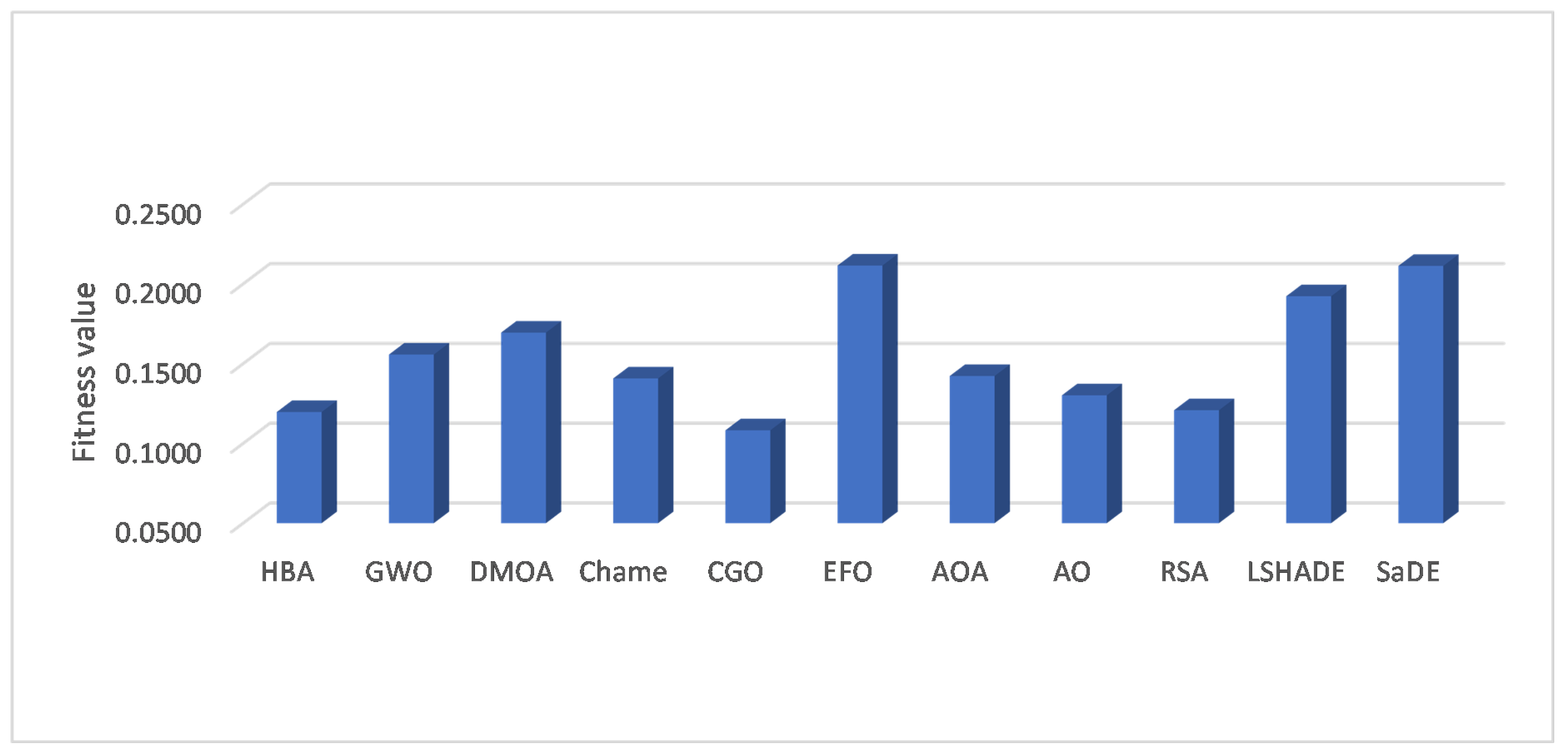
Finally,
Table 8 shows the average fitness value obtained using the competitive algorithms to handle the SIoT datasets. From these results, one can see that CGO has the smallest fitness value for five datasets, followed by the HBA, which has the smallest value for two datasets. The average fitness value overall for the eight datasets is depicted in
Figure 7, and we can observe from this figure that the CGO has nearly a 0.10 fitness value, which is the smallest value. At the same time, the HBA can obtain a fitness value smaller than other methods.
For further analysis, the results obtained using CGO and the other methods are given in
Table 9. These results represent the mean rank obtained using the Friedman test. This test aims to determine whether there is a significant difference between the developed method and other methods. From those results, we can notice that the developed CGO has the best mean rank based on the accuracy, sensitivity, specificity, number of features, and fitness value. The HBA follows this in terms of the accuracy, sensitivity, specificity, and fitness value. However, according to the performance of the algorithms based on the value of several features, AO is ranked second.
From the previous discussion, it can been noticed that the CGO algorithm has a high ability to increase the prediction performance with a minimum number of features. This was achieved because CGO can balance the exploration and exploitation phases during the search process.
5.4. Future Work
The developed framework can be extended to future work to other applications, including medical, agriculture, and others. In addition, it can be modified using fractional calculus and another hybrid mechanism. Meanwhile, searching for the optimal hyper-parameters of the proposed DL models using MH algorithms can be beneficial to improve the framework’s overall performance.
6. Conclusions and Future Work
This paper developed an alternative Social Internet of Things (SIoT) technique based on integrating the advantages of the Deep Learning (DL) model and meta-heuristic approach. The DL, the TransCNN, was applied to extract the features from the tested dataset. At the same time, Chaos Game Optimization (CGO) is an MH technique used to determine the relevant features. To evaluate the performance of the developed SIoT model, we compared it with ten other well-known methods, including the HBA, GWO, DMOA, Chame, EFO, AOA, AO, RSA, LSHADE, and SaDE. These methods were applied as FS methods and have demonstrated their efficiency. According to the obtained results, the developed SIoT provided better performance than the other models based on the accuracy, specificity, sensitivity, and fitness value.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}