3.1. Monte Carlo Simuations
In this section, we will demonstrate the optimization effect of the samples added by using the AMLI method on the overall samples by using six groups of Monte Carlo simulations. For the sake of simplicity and to achieve a better visualization effect, the feature dimension n = 1 is defined, and the real function relationship selected is . Since there is a certain error between the observed value of the sample and the actual value, to simulate this effect, we add noise to the samples after data generation.
The distribution of data and the settings of noise and sample size are as follows:
Simulation 1:
Simulation 2:
Simulation 3:
Simulation 4:
Simulation 5:
Simulation 6:
Simulation 1 is used as the control group, and simulations 2 and 3 are used as experimental groups with different sample sizes; simulations 4 and 5 are experimental groups with different feature distributions; simulation 6 is an experimental group with different types of noise (noise distribution parameters are selected to unify the noise variance and to ensure that the expectation is 0). Some verification indicators (e.g., the proportion of samples with an error greater than 0.5, 1, 1.5, 2, or 2.5; and the mean square error (
) between the sample observation values and the actual value) are selected to test the optimization effect of the AMLI method on the original sample after processing.
where
is the observed value of the sample;
is the actual value of the sample;
is the number of total samples after AMLI optimization; and
= 0.5, 1, 1.5, 2, 2.5. Due to the randomness of each experiment, we selected different hyperparameters to perform multiple calibrations in each simulation and calculated the average value of each of the verification indicators for every 100 experiments.
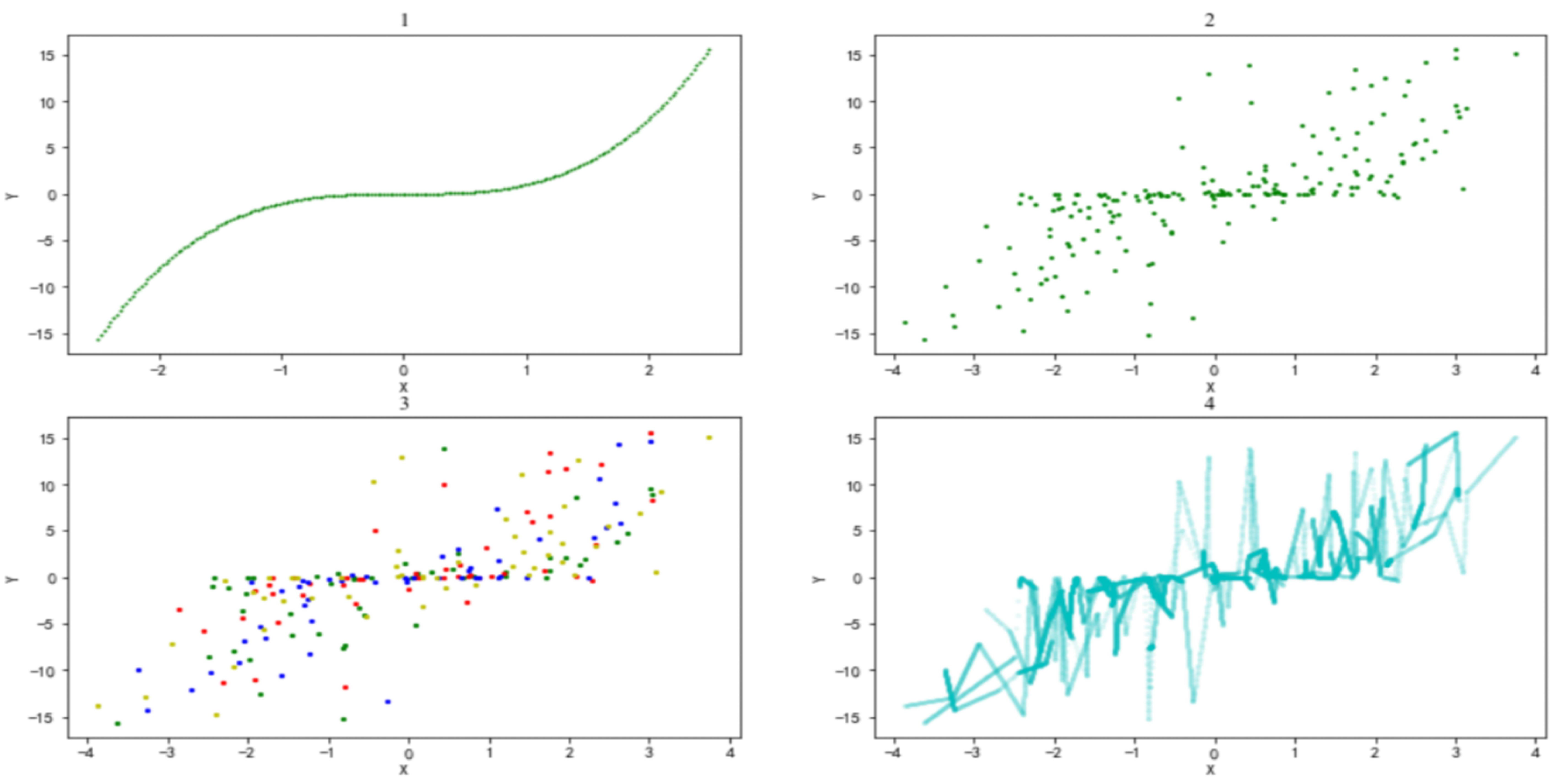
To reflect the optimization effect of the AMLI method more visually, below, we describe the AMLI processing process of simulation 1 in detail. First, 200 samples are generated evenly in the interval of (−2.5, 2.5) (
Figure 1(1)). Second, noise that obeys the standard normal distribution is added to the feature variables (
Figure 1(2)). Third, to achieve a better visualization effect, original samples are divided into only four categories (just to achieve a better visualization effect, and the verification index is not necessarily optimal) (i.e., the hyperparameter
K = 4) with labels of different colors (
Figure 1(3)). Fourth, given the small interval of the definition domain, high values of the unit distance filling parameter are selected, and sample filling is performed after setting the hyperparameter
= 100. After the filling, the sample size reaches 3035 (
Figure 1(4)).
The comparison of the visualization effects in
Figure 1(2) and
Figure 1(4) indicates that after processing with the AMLI method, the samples can adaptively fit the functional relationship between
x and
y.
By using the above method, the parameters of the six simulations are calibrated, and the verification indicators are calculated, as shown in
Table 1.
Remark 1. The optimal effect of each simulation is determined by the lowest after AMLI processing by traversing all the hyperparameter values according to the grid search method.
Clearly, after the AMLI processing, the of the samples and the proportion of various error samples have been optimized, most of the added dummy samples are valid ones, the increase in the sample size does not significantly weaken the AMLI’s optimization effect, the samples that obey the normal distribution have better optimization performance, and even the uniformly distributed noise shows good robustness. In many cases, the AMLI method performs well in data optimization.
3.2. Analysis of Hyperparameter Taking Values
In this section, we discuss the patterns of setting the parameters of
K and
in the AMLI method. First, we examine the setting of parameter
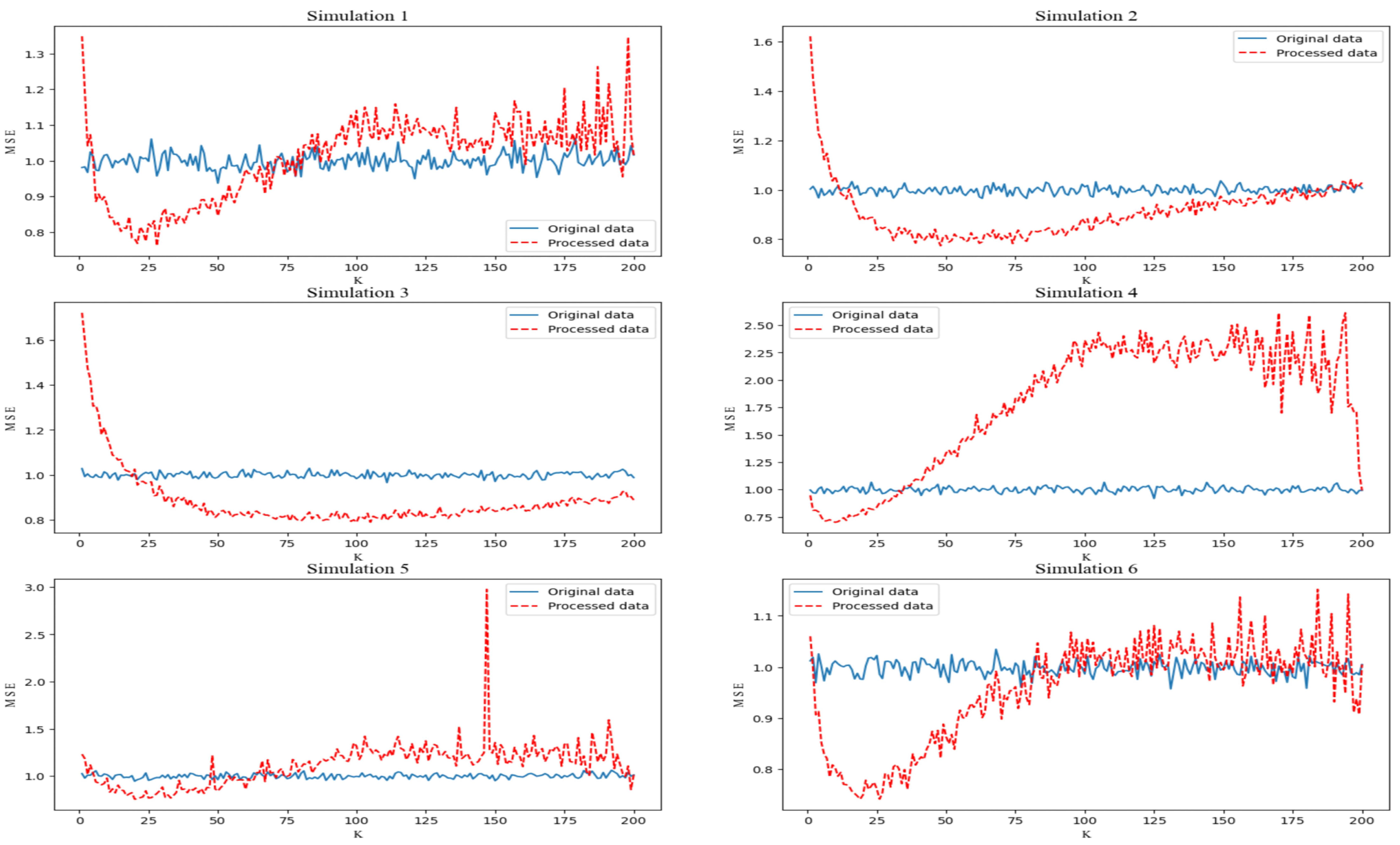
K. For the above simulation, we set the parameter
= 100; perform traversal iterations consecutively by setting
; and obtain the average value of the index for one hundred iterations at each setting. The change trend of the MSE index before and after the AMLI processing is shown in
Figure 2.
At fixed parameter values, the optimal value of K increases with the increase in the sample size; the value range of K varies under different distributions of variables; and the change in the noise distribution has little impact on the optimal value of K.
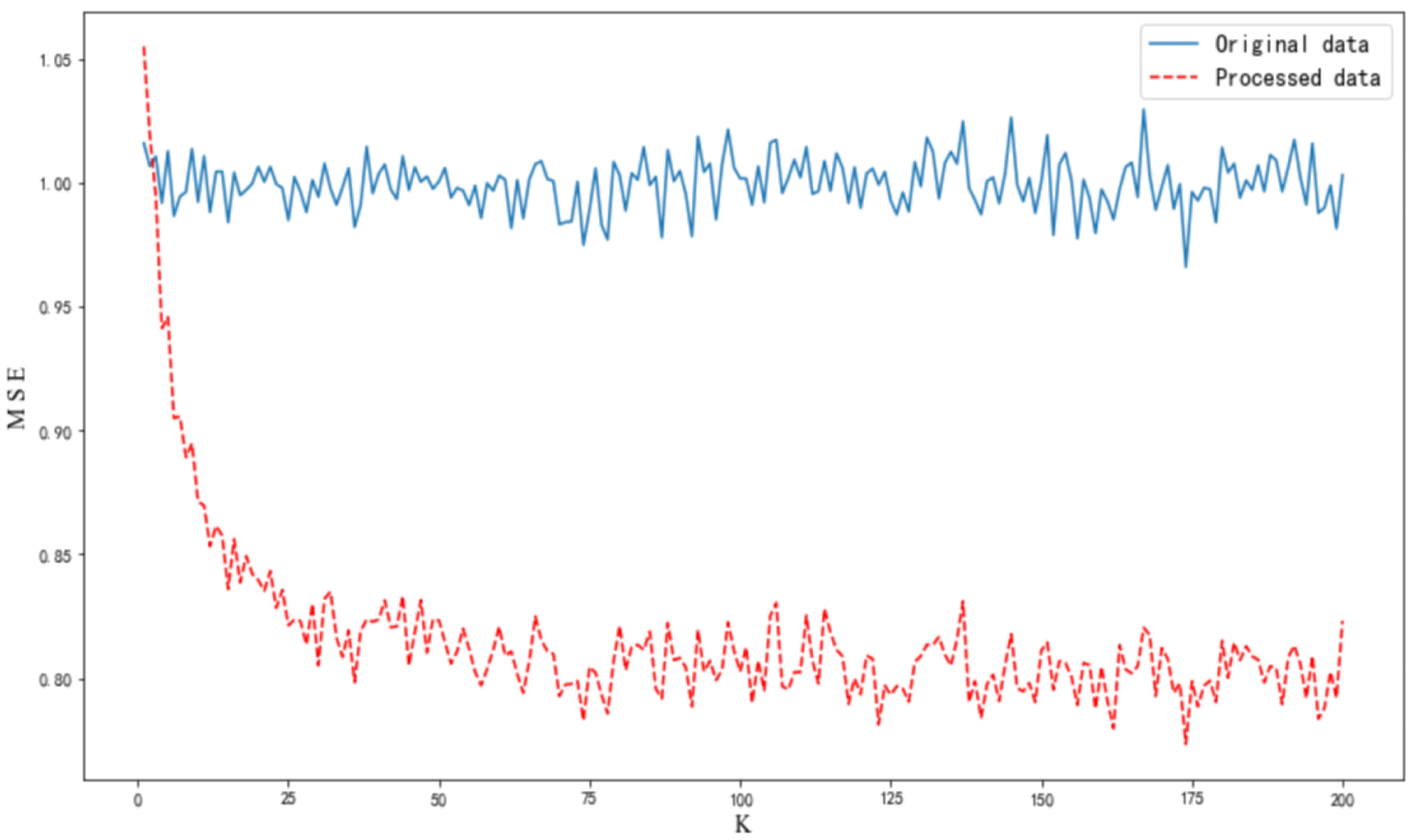
Next, we examine the pattern of the setting of parameter
. In the case of simulation 1, under the condition of
to take the optimal value, traversal iterations are performed consecutively by setting the parameter
; the results are shown in
Figure 3. Clearly, the fluctuation of the sample
after optimization by using the AMLI method decreases with the increase in the value of filling parameter
.







{kind=link}
{kind=link}
{kind=link}