
An Alternative Lambert-Type Distribution for Bounded Data



Abstract
:1. Introduction
2. The New Distribution
2.1. LPHU Random Variable
- The LPHU pdf is not null at the lower end of its support, . Thus, the LPHU has a behavior similar to that of the LU and PHU pdf’s, but with the advantage that it can present unimodal and reverse-unimodal shapes;
- Equation (4) reduces to the PHU, LU, and uniform pdf’s when , and , respectively. Thus, for such parameter choices, the LPHU pdf inherits the shapes of the PHU, LU, and U pdf’s;
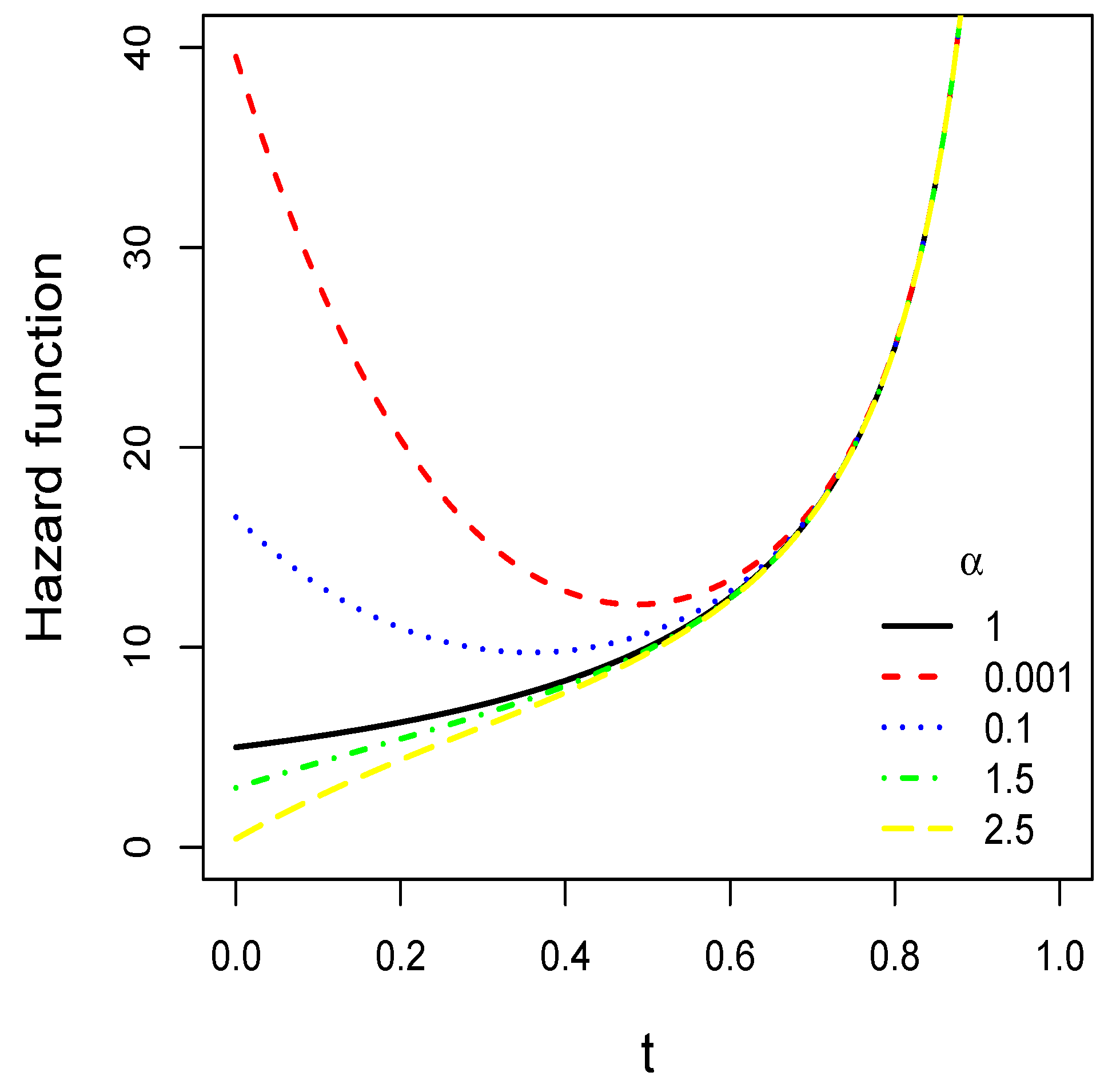
- For and , we observe that the equation leads to the statement that the LPHU pdf may have a critical point atwhere is a maximum or a minimum if or , respectively, such that , where .
2.2. Related Distributions
- Let , where and . Then, Y follows the nonscaled Lambert-exponential distribution. See Iriarte et al. [7];
- Let , where and . Then, Y follows the Lambert–Rayleigh distribution. See Iriarte et al. [7];
- Let , where and . Then, the distribution of Y is a three-parameter distribution that reduces to the K distribution when . In this case, the cdf of Y is given by , where . Thus, we refer to this distribution as the Lambert–Kumaraswamy distribution.
2.3. Hazard Rate Function
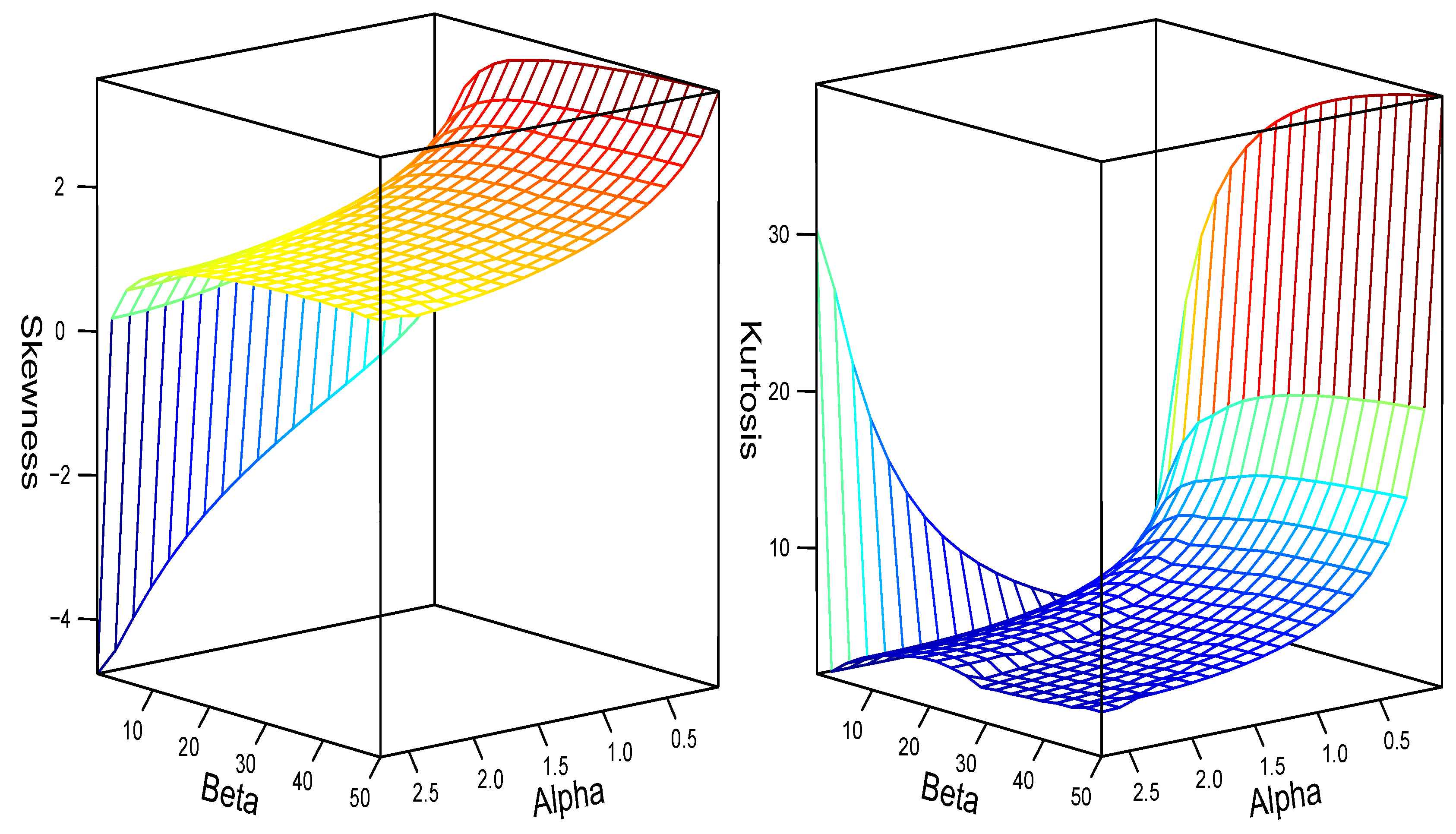
2.4. Skewness and Kurtosis Behavior
3. Parameter Estimation
3.1. ML Estimation
3.2. Computational Guidelines
- Alternatively, the ML estimates can be obtained by solving the optimization problem , subject to , , where is given in Equation (7).
- For this, we use the optim function of the R programming language. An R code is provided in Appendix B.
- Specifically, we consider the L-BGSB-B algorithm [15], which allows us to specify the parameter space. This algorithm requires declaring a value in the parameter space to initialize the iterative process. Taking into account that the PHU distribution is a special case of the LPHU distribution, we consider and , where is the ML estimator of the shape parameter of the PHU distribution.
3.3. Simulation Study
- Generate ;
- Compute .
4. Data Analysis
4.1. Firm’s Risk Management Cost Effectiveness
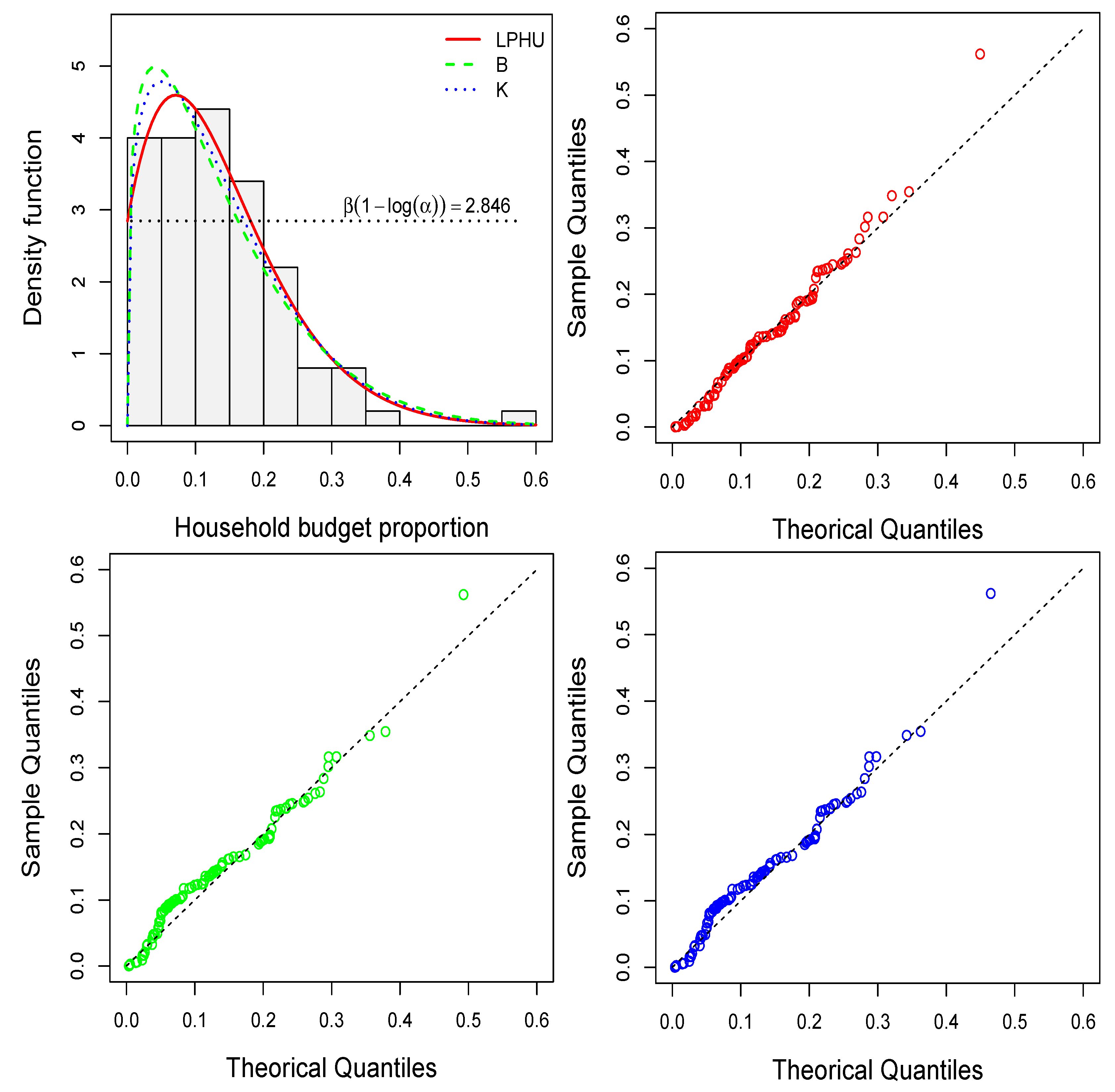
4.2. Household Shared Budget for Transportation
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| B | beta distribution |
| K | Kumaraswamy distribution |
| probability density function | |
| ML | maximum likelihood |
| cdf | cumulative distribution function |
| U | uniform distribution |
| LU | Lambert uniform distribution |
| PHU | proportional hazard uniform distribution |
| rf | reliability function |
| hrf | hazard rate function |
| LPHU | Lambert proportional hazard uniform distribution |
| AE | average estimate |
| SD | standard deviation |
| RMSE | root mean square error |
| SE | standard error |
| CP | coverage probability |
| AD | Anderson–Darling |
| CvM | Cramer–von Mises |
| AIC | Akaike information criterion |
| BIC | Bayesian information criterion |
Appendix A. R Codes
Appendix B. R Code
Appendix C. R Code
References
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; John Wiley & Sons: Hoboken, NJ, USA, 1995; Volume 2. [Google Scholar]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Blundell, R.; Duncan, A.; Pendakur, K. Semiparametric estimation and consumer demand. J. Appl. Econom. 1998, 13, 435–461. [Google Scholar] [CrossRef]
- Dey, S.; Mazucheli, J.; Nadarajah, S. Kumaraswamy distribution: Different methods of estimation. Comput. Appl. Math. 2018, 37, 2094–2111. [Google Scholar] [CrossRef]
- Wang, J.Z. A note on estimation in the four-parameter beta distribution. Commun.-Stat.-Simul. Comput. 2005, 34, 495–501. [Google Scholar] [CrossRef]
- Smith, R.L. Maximum likelihood estimation in a class of nonregular cases. Biometrika 1985, 72, 67–90. [Google Scholar] [CrossRef]
- Iriarte, Y.A.; de Castro, M.; Gómez, H.W. The Lambert-F distributions class: An alternative family for positive data analysis. Mathematics 2020, 8, 1398. [Google Scholar] [CrossRef]
- Corless, R.M.; Gonnet, G.H.; Hare, D.E.; Jeffrey, D.J.; Knuth, D.E. On the LambertW function. Adv. Comput. Math. 1996, 5, 329–359. [Google Scholar] [CrossRef]
- Brito, P.; Fabiao, F.; Staubyn, A. Euler, Lambert, and the Lambert W function today. Math. Sci. 2008, 33. [Google Scholar]
- Iriarte, Y.A.; de Castro, M.; Gómez, H.W. An alternative one-parameter distribution for bounded data modeling generated from the Lambert transformation. Symmetry 2021, 13, 1190. [Google Scholar] [CrossRef]
- Martínez-Florez, G.; Moreno-Arenas, G.; Vergara-Cardozo, S. Properties and inference for proportional hazard models. Rev. Colomb. Estad. 2013, 36, 95–114. [Google Scholar]
- Adler, A. lamW: Lambert-W Function. 2015. R Package Version 2.1.1. Available online: https://doi.org/10.5281/zenodo.5874874 (accessed on 5 January 2023).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Soetaert, K. rootSolve: Nonlinear Root Finding, Equilibrium and Steady-State Analysis of Ordinary Differential Equations. 2009. R Package Version 1.6. Available online: https://CRAN.R-project.org/package=rootSolve (accessed on 5 January 2023).
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Schmit, J.T.; Roth, K. Cost effectiveness of risk management practices. J. Risk Insur. 1990, 57, 455–470. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control. 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Faraway, J.; Marsaglia, G.; Marsaglia, J.; Baddeley, A. Goftest: Classical Goodness-of-Fit Tests for Univariate Distributions. R Package Version 1.2-3. 2021. Available online: https://CRAN.R-project.org/package=goftest (accessed on 5 January 2023).
- Croissant, Y.; Graves, S. Ecdat: Data Sets for Econometrics. R Package Version 0.4-2. 2022. Available online: https://CRAN.R-project.org/package=Ecdat (accessed on 5 January 2023).
- Chen, G.; Balakrishnan, N. A general purpose approximate goodness-of-fit test. J. Qual. Technol. 1995, 27, 154–161. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distribution | AIC | BIC | AD | CvM | ||
|---|---|---|---|---|---|---|
| LPHU | 0.012 | 1.889 | −174.3 | −169.7 | 0.484 | 0.616 |
| (0.016) | (0.496) | |||||
| K | 0.664 | 3.440 | −153.3 | −148.7 | 0.025 | 0.039 |
| (0.071) | (0.620) | |||||
| B | 0.612 | 3.797 | −148.2 | −143.7 | 0.009 | 0.013 |
| (0.085) | (0.715) |
| Non-Rejection Rate | Hit Rate | |||
|---|---|---|---|---|
| Distribution | AIC | BIC | ||
| LPHU | 0.734 | 0.718 | 0.836 | 0.836 |
| B | 0.502 | 0.479 | 0.130 | 0.130 |
| K | 0.562 | 0.531 | 0.034 | 0.034 |
| Distribution | AIC | BIC | ||||
|---|---|---|---|---|---|---|
| LPHU | 1.996 | 9.222 | −209.5 | −204.3 | 0.112 | 0.715 |
| (0.259) | (0.933) | |||||
| B | 1.302 | 8.217 | −203.1 | −197.8 | 0.213 | 1.308 |
| (0.166) | (1.228) | |||||
| K | 1.273 | 10.539 | −105.1 | −199.9 | 0.177 | 1.092 |
| (0.116) | (2.385) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Varela, H.; Rojas, M.A.; Reyes, J.; Iriarte, Y.A. An Alternative Lambert-Type Distribution for Bounded Data. Mathematics 2023, 11, 667. https://doi.org/10.3390/math11030667
Varela H, Rojas MA, Reyes J, Iriarte YA. An Alternative Lambert-Type Distribution for Bounded Data. Mathematics. 2023; 11(3):667. https://doi.org/10.3390/math11030667
Chicago/Turabian StyleVarela, Héctor, Mario A. Rojas, Jimmy Reyes, and Yuri A. Iriarte. 2023. "An Alternative Lambert-Type Distribution for Bounded Data" Mathematics 11, no. 3: 667. https://doi.org/10.3390/math11030667