1. Introduction
In the past four decades, data envelopment analysis (DEA), proposed by Charnes et al. [
1], has played a crucial role in the field of performance evaluation. The use of DEA has been prevalent in many areas, such as agriculture, transportation, banking, and so on; see, e.g., [
2,
3,
4]. A system of DEA models is one important branch of the efficiency ranking method of decision-making units (DMUs). In the classic Charnes–Cooper–Rhodes (CCR) model, each DMU uses the weight that is the most favorable to itself to evaluate its efficiency. Hence, the CCR efficiency is also referred to as self-appraisal efficiency. However, in the CCR model, the relative effectiveness of the DMUs evaluated as DEA efficiency cannot be further distinguished. In addition, the inputs and the outputs that are the most favorable for evaluating a particular DMU may not be optimal for evaluating other DMUs. Therefore, the weights established through self-appraisal may sometimes be unrealistic. To improve the discriminant ability of DEA and make its weight more objective and practical, the DEA cross-efficiency evaluation model was proposed in [
5] as an alternative to self-appraisal and an extension to DEA. As the DEA cross-efficiency evaluation model ensures the unique ordering of the DMUs [
6], it is applied in many scenarios such as the sequence of the DMUs’ evaluation, assessing information sharing in supply chain management [
7], portfolio selection [
8], and supplier selection in public procurement [
9].
Within the study of the DEA cross-efficiency evaluation model, the cross-efficiency aggregation method (arithmetic averaging) is a hot topic. However, Wu et al. [
10] observed that it does not lead to a Pareto optimal solution and it loses the connection between weights. Thus, they proposed an aggregated model based on the cross-efficiency method and Shannon entropy (referred as Wu’s method in the subsequent text). Inspired by the evidential reasoning approach, Yang et al. [
11] transformed the cross-efficiency matrix into pieces of evidence first, and then they aggregated the obtained cross-efficiency. To allow the optimism of the decision-maker (DM) towards the optimal relative efficiency and take it into account in the final overall efficiency evaluation, Wang and Chin [
12] proposed the use of the ordered weighted averaging operator weight cross-efficiency aggregation. Moreover, Song and Liu [
13] observed that Wu’s method [
10] assigns the largest weight to the least important DMU, which could be unreasonable, so they proposed a variance coefficient method to overcome this drawback.
The DEA cross-efficiency evaluation model, based on the framework of expected utility theory (EUT), assumes that the DMs are completely rational even if in a risky situation; it does not take the DMs’ subjective attitude into consideration. However, as the decision-making process is conducted by people, the results obtained from the DEA cross-efficiency evaluation model based on EUT assumptions may not be consistent with the realistic situation. To remedy this, Liu et al. [
14] proposed a new cross-efficiency model called prospect cross-efficiency (PCE) by calculating the prospect value of the DMU. At the same time, Deng and Fang [
15] integrated the DEA prospect cross-efficiency evaluation model into fuzzy portfolio asset allocation under the framework of mean-variance-maverick. To avoid the choice dilemma between the aggressive and benevolent cross-efficiency model and to provide a reliable decision-making technique considering non-rational psychological factors for the ranking of the DMUs, Fang and Yang [
16] proposed a comprehensive method using DEA cross-efficiency interval evaluation and cumulative prospect theory. Based on the Dempster–Shafer evidence theory, Fan et al. [
17] obtained the DMU’s weights by considering the cross-efficiency scores as evidence to prove the DMU’s credibility. In order to establish a target efficiency identification model, Shao and Wang [
18] developed several two-stage cross-efficiency evaluation models based on prospect theory so that dynamic reference points are determined by introducing the optimism coefficient. In addition, Yu et al. [
19] developed a common weight DEA model by considering the psychological behaviors of the DMs. Moreover, Mei and Wang [
20] proposed a cross-efficiency aggregation method based on the entropy weight method and prospect theory.
Although the PCE model [
14] considers the risk attitude of the DMs in the cross-efficiency evaluation model, it uses the same fixed point as the reference point. This leads to deviation from the actual DMs’ reference points so that it cannot objectively and reliably reflect the expected gains and losses of the DMs. In addition, the traditional arithmetic average weighting method assigns the same weight to each decision making unit and does not take into account the relative importance of each decision making unit, so it is easy to miss a lot of decision information [
10].
Inspired by existing research results, this paper investigates two aspects. One is to improve the objectivity and fairness of evaluation results. The other is to introduce psychological factors into the model so that they have an influence on decision-making behavior. Moreover, we study the aggregation method of the cross-efficiency and optimize the evaluation results of the model by introducing the risk attitude of the DMs and the entropy contained in the efficiency value.
The research in this paper is mainly based on the work of [
13,
14]. The main contributions of this study are as follows:
Compared to the classic CCR model, the proposed approach completely sorts the DMUs. In addition, psychological factors of the DMs are introduced so that the results are more realistic.
Taking the risk attitudes of the DMs into consideration, the endogenous and exogenous reference points are determined, and the convex combination of free parameters is constructed to calculate the final prospect value.
By combining the Shannon entropy with the DEA cross-efficiency evaluation model, the proposed approach avoids the weight deviation of the traditional model and retains the decision information in the evaluation process.
The rest of this paper is organized as follows.
Section 2 introduces the DEA cross-efficiency evaluation model, prospect theory, and Shannon entropy.
Section 3 discusses the proposed approach.
Section 4 demonstrates the proposed approach through a numerical example and an empirical case applied to the Chinese mutual fund market.
Section 5 gives the conclusions.
3. Proposed Approach
As noted in
Section 2.2, the selection of reference points significantly impacts the computation of prospect value. Hence, we first introduce some special reference points and show how they derive the prospect value, and then explain the process for our selection of reference points.
Usually, reference points are selected at (1) the zero point, (2) the positive ideal point, (3) the negative ideal point, (4) the mean value, and (5) the median [
14]. For example, in [
24], the best DMU is defined as the positive ideal point. Now, we define the positive ideal point as the best DMU and the negative ideal point as the worst DMU. For a positive ideal point, it represents the least input and the most output, so the DMU can gain benefits through the least input and the most output. For a negative ideal point, it represents more input and less output, which is a loss for the DM. Thus, we choose the best and the worst value as the
exogenous reference points to reflect external competitive advantages, and the mean value is regarded as the endogenous reference points to reflect the DMUs’ own characteristics in our proposed approach.
Let
and
be the
ith input and the
rth output of the DMUs, respectively. For the endogenous reference point, we consider using the average of the DMU’s inputs and outputs, defined as
and
respectively. The average value is simple and representative; it is more in line with the thinking habits of the DMs using the average as a reference point.
The parameters
and
represent the concavity and convexity of the value function, respectively, and satisfy the constraints
;
is the loss-aversion coefficient. Ref. [
25] suggested that
,
.
For the exogenous reference point, we choose the worst and the best DMUs. Let the worst DMU be the reference point of the DM. Then the overall exogenous prospect gain values of DMU
is given by
and
respectively. Here,
and
are the worst bounds for the inputs and the outputs of DMU
, respectively.
Let the best DMU be the reference point of the DM. Then the overall exogenous prospect loss values of DMU
are given by
and
respectively. Here,
and
are the best bounds for the inputs and the outputs of DMU
, respectively.
In what follows, we present an entropy-based prospect cross-efficiency evaluation (EPCE) model as
where
and
represents the self-appraisal efficiencies, i.e., the CCR efficiency.
It follows from [
13] that the variation coefficient
can be calculated by
where
can be obtained by Equation (
6), and
Thus, the aggregating weights
can be determined by
In the aforementioned remarks,
and
are the free parameters that can be adjusted according to the subjective wishes of the DM, where
. Here,
represents the degree of the DM’s preference for the internal versus external reference point of the evaluation question. A larger
indicates that the DM considers the internal reference point (i.e., the mean value) to be more meaningful;
represents the DM’s risk appetite, and a larger
reflects a more optimistic DM. The parameter
is the loss-aversion coefficient, which can be regarded as the ratio of sensitivity of the DM to gains and losses. As
and
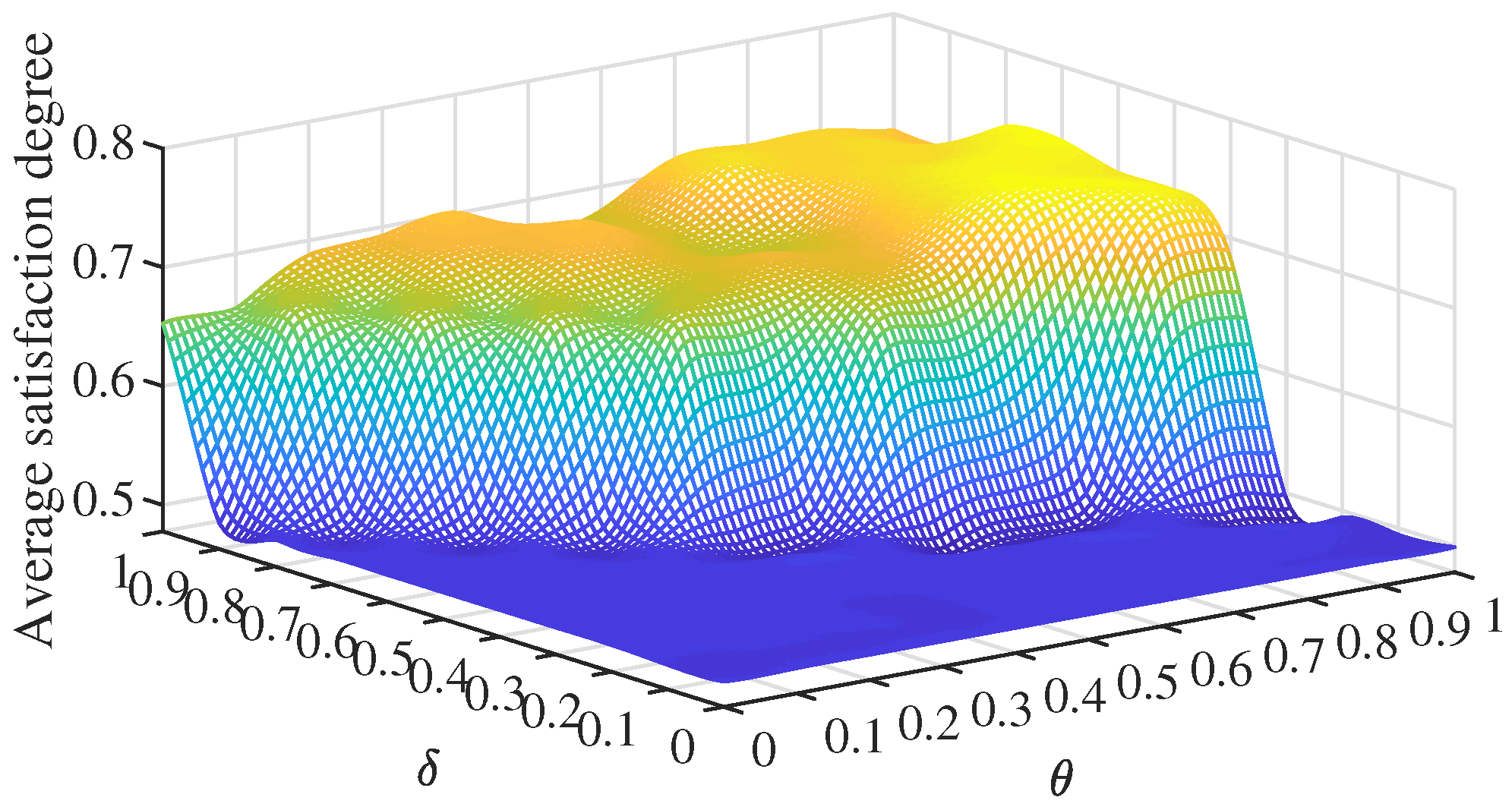
are adjustable parameters, their optimal range needs to be determined before conducting the final efficiency evaluation. For this purpose, we refer to the concept of satisfaction proposed by Wu et al. [
26].
Definition 2. For each DMU, the satisfaction degree can be defined aswhere (upper bound) and (lower bound) are defined asandrespectively. Finally, the aggregated efficiency values calculated by our proposed EPCE model can be expressed as
where
is the optimal objective values of the above model (
14).
Thus, we establish the framework of the problem and derive the original cross-efficiency matrix. By solving model (
2), the self-appraisal efficiencies
can be obtained. For DMU
, we calculate their peer-appraisal efficiencies
and the initial cross-efficiencies
via Equations (
3) and (
4).
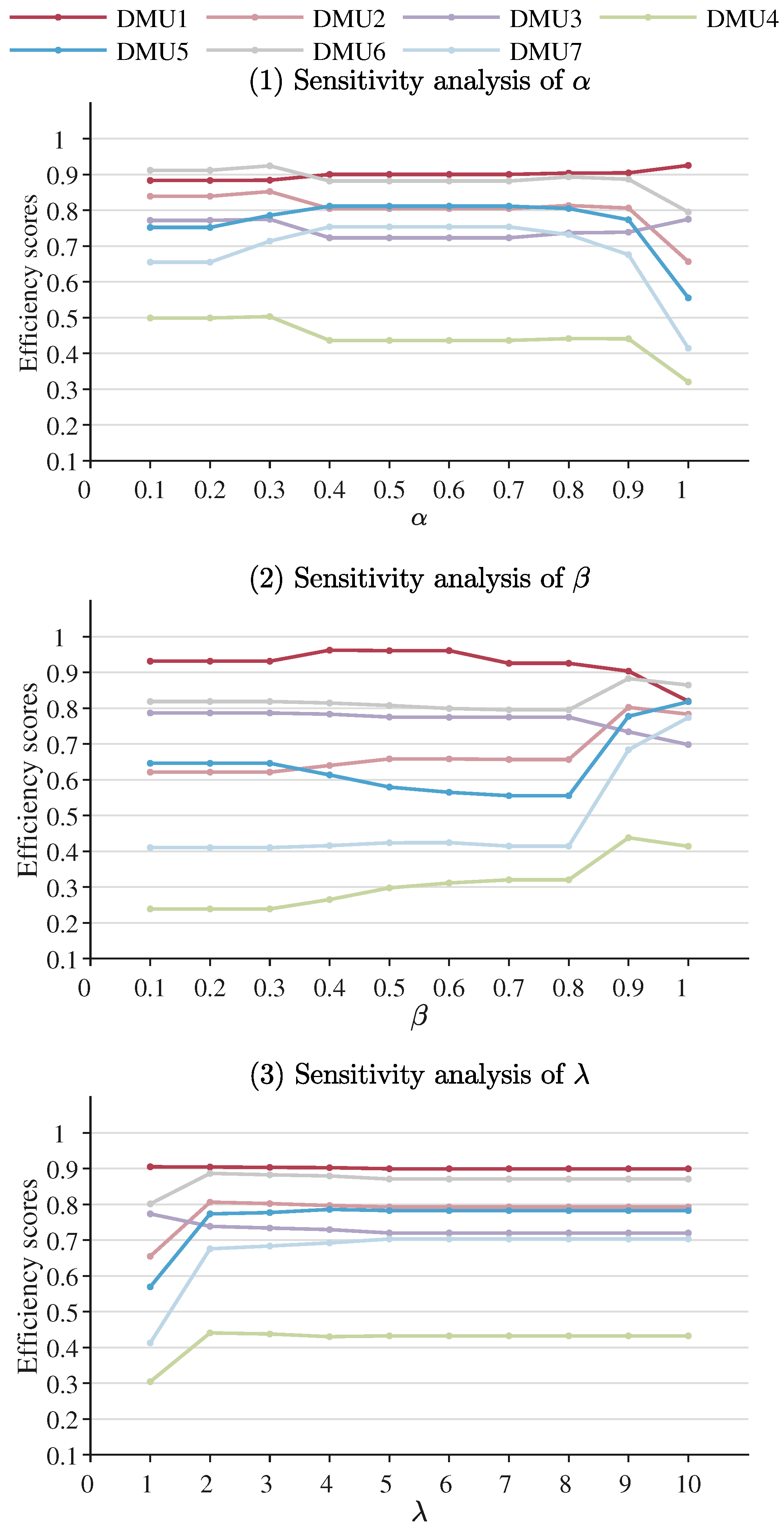
By calculating its satisfaction degree with the EPCE evaluation results for each DMU, we can obtain the evaluation result with the smallest satisfaction degree variance as the final result of the proposed approach. The minimum variance means that all DMUs have the highest recognition consistency for the evaluation result; and in the evaluation result are the optimal parameter values corresponding to the final result.
Considering the limitations and egoism of each DMU assessment, the amount of information contained in the results may vary. Now we introduce Shannon entropy into model (
14) so that the final aggregated cross-efficiency
for each DMU
can be easily solved by Equations (
18)–(
24).
To summarize the foregoing analysis, the proposed integrated approach using prospect theory and Shannon entropy can be described as Algorithm 1.
| Algorithm 1: Entropy-based prospect cross-efficiency evaluation method. |
- Input:
input matrix X and output matrix Y - 1:
- 2:
Calculate prospect value , , , , , and from Equations ( 8)–( 13) - 3:
Calculate prospect cross-efficiency weights from model ( 14) - 4:
Calculate efficiency values from Equations ( 18)–( 20) - 5:
Calculate corresponding satisfaction degree for all possible values of and from Equation ( 21), and choose the optimal parameters’ combination which has the highest average satisfaction degree - 6:
Calculate the final aggregated EPCE efficiency values from Equation ( 24) - Output:
|






{kind=link}
{kind=link}
{kind=link}