
Emotional Health and Climate-Change-Related Stressor Extraction from Social Media: A Case Study Using Hurricane Harvey

 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Topic Modeling for Public Health
2.2. Social Media for Disaster Relief
3. Methods
3.1. Study Design
3.2. Data Pre-Processing and Feature Engineering
3.3. Emotion Prediction and Stressor Extraction
3.3.1. Text Vectorization
3.3.2. Emotion Prediction Model
3.3.3. LDA Topic-Modeling-Based Stressor Extraction
Optimal Number of Topics Identified
Stressor Extraction from the Identified Topics
4. Results
4.1. Emotion Prediction Results
4.2. Tweet Shoutout
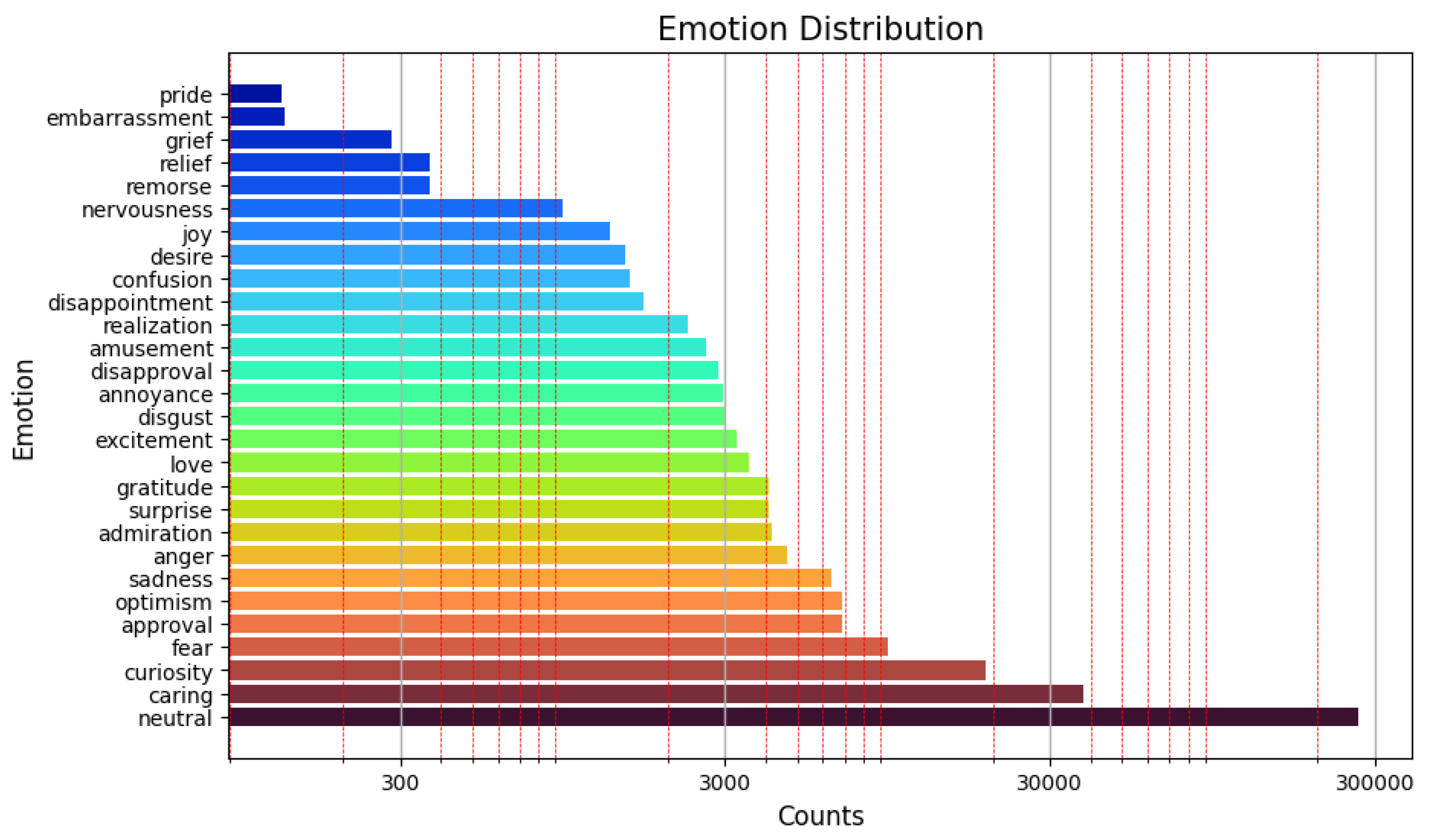
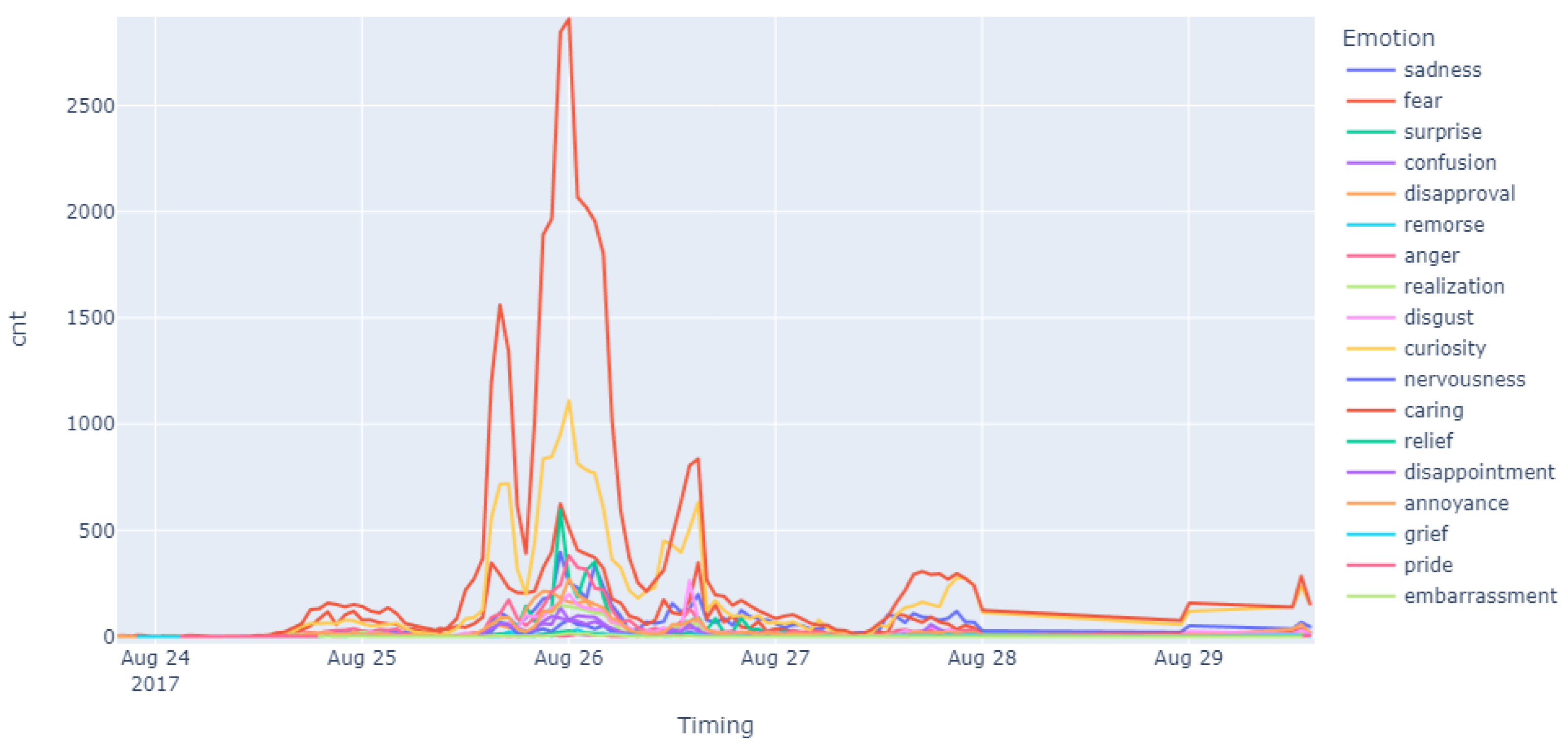
4.3. Emotion Distribution and Evolution
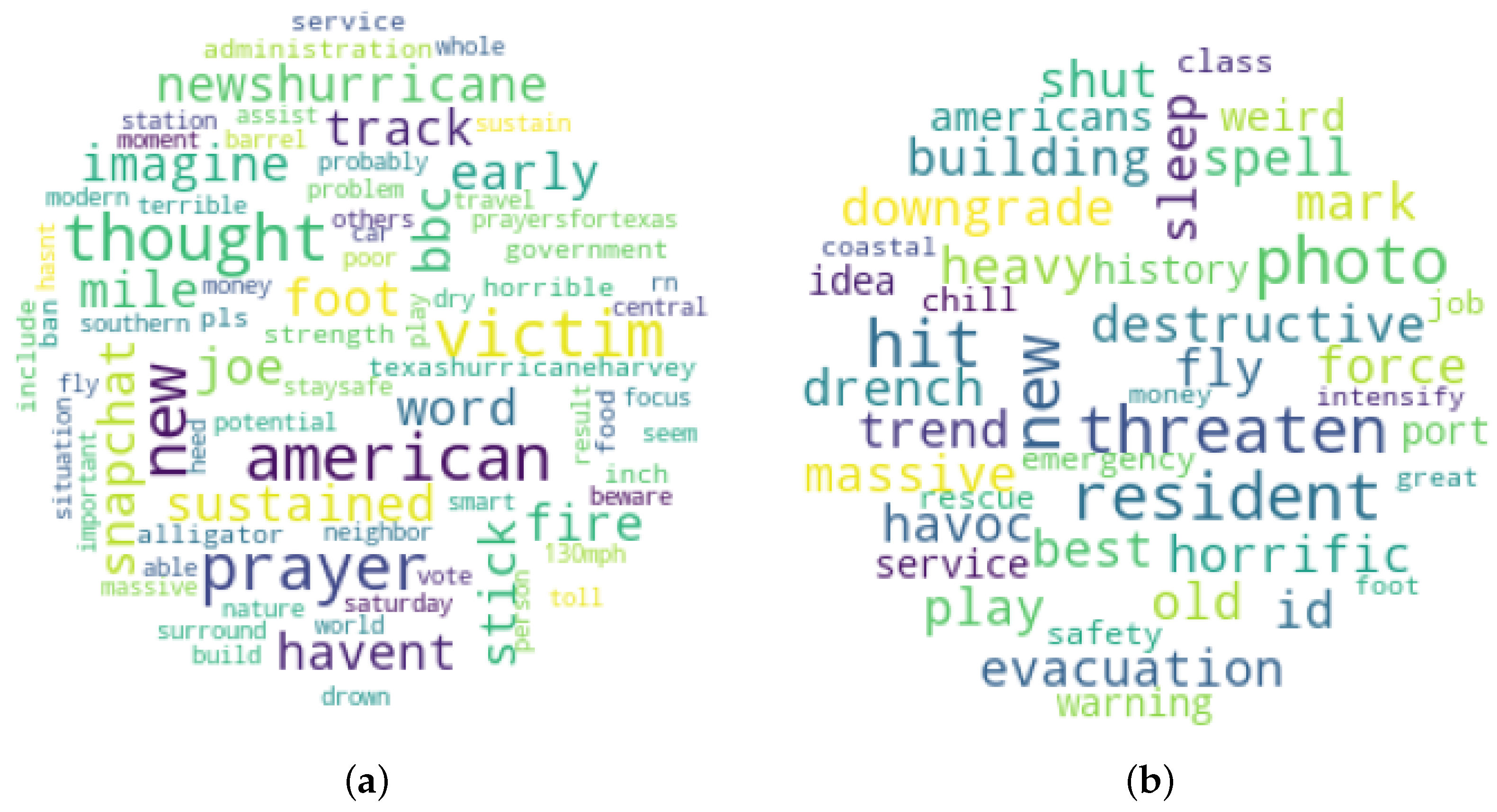
4.4. Stressor Extraction Results
Stressor Insight Analysis
5. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Amadeo, K. Hurricane Harvey Facts, Damage and Costs. Balance. 2018. Available online: https://www.lamar.edu/_files/documents/resilience-recovery/grant/recovery-and-resiliency/hurric2.pdf (accessed on 27 November 2023).
- Cooper, S.; Hutchings, P.; Butterworth, J.; Joseph, S.; Kebede, A.; Parker, A.; Terefe, B.; Van Koppen, B. Environmental associated emotional distress and the dangers of climate change for pastoralist mental health. Glob. Environ. Chang. 2019, 59, 101994. [Google Scholar] [CrossRef]
- Aihara, Y.; Shrestha, S.; Sharma, J. Household water insecurity, depression and quality of life among postnatal women living in urban Nepal. J. Water Health 2016, 14, 317–324. [Google Scholar] [CrossRef] [PubMed]
- Stevenson, E.G.; Greene, L.E.; Maes, K.C.; Ambelu, A.; Tesfaye, Y.A.; Rheingans, R.; Hadley, C. Water insecurity in 3 dimensions: An anthropological perspective on water and women’s psychosocial distress in Ethiopia. Soc. Sci. Med. 2012, 75, 392–400. [Google Scholar] [PubMed]
- Ojala, M. Young people and global climate change: Emotions, coping, and engagement in everyday life. Geogr. Glob. Issues Chang. Threat 2016, 8, 1–19. [Google Scholar]
- Friedrich, E.; Wüstenhagen, R. Leading organizations through the stages of grief: The development of negative emotions over environmental change. Bus. Soc. 2017, 56, 186–213. [Google Scholar] [CrossRef]
- Hickman, C.; Marks, E.; Pihkala, P.; Clayton, S.; Lewandowski, R.E.; Mayall, E.E.; Wray, B.; Mellor, C.; van Susteren, L. Climate anxiety in children and young people and their beliefs about government responses to climate change: A global survey. Lancet Planet. Health 2021, 5, e863–e873. [Google Scholar] [CrossRef]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Citeseer, Los Angeles, CA, USA, 23–24 June 2003; Volume 242, pp. 29–48. [Google Scholar]
- Kamath, R.; Ghoshal, A.; Eswaran, S.; Honnavalli, P.B. Emoroberta: An enhanced emotion detection model using roberta. In Proceedings of the IEEE International Conference on Electronics, Computing and Communication Technologies, Bangalore, India, 8–10 July 2022. [Google Scholar]
- Blei, D.M.; Lafferty, J.D. Topic models. Text Min. Classif. Clust. Appl. 2009, 10, 34. [Google Scholar]
- Grassia, M.G.; Marino, M.; Mazza, R.; Misuraca, M.; Stavolo, A. Topic modeling for analysing the Russian propaganda in the conflict with Ukraine. In ASA 2022; Firenze University Press: Firenze, Italy; Genova University Press: Genova, Italy, 2023; p. 245. [Google Scholar]
- Grootendorst, M. BERTopic, Neural topic modeling with a class-base for TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Karas, B.; Qu, S.; Xu, Y.; Zhu, Q. Experiments with LDA and Top2Vec for embedded topic discovery on social media data—A case study of cystic fibrosis. Front. Artif. Intell. 2022, 5, 948313. [Google Scholar] [CrossRef]
- Man, I.; Georges, D.; de Carvalho, T.M.; Saraswati, L.R.; Bhandari, P.; Kataria, I.; Siddiqui, M.; Muwonge, R.; Lucas, E.; Berkhof, J.; et al. Evidence-based impact projections of single-dose human papillomavirus vaccination in India: A modelling study. Lancet Oncol. 2022, 23, 1419–1429. [Google Scholar] [CrossRef]
- Asmundson, G.J.; Taylor, S. Coronaphobia: Fear and the 2019-nCoV outbreak. J. Anxiety Disord. 2020, 70, 102196. [Google Scholar] [CrossRef] [PubMed]
- Manikonda, L. Analysis and Decision-Making with Social Media; Arizona State University: Tempe, AZ, USA, 2019. [Google Scholar]
- Kaplan, A.M. Social Media, Definition, and History. In Encyclopedia of Social Network Analysis and Mining; Alhajj, R., Rokne, J., Eds.; Springer: New York, NY, USA, 2018; pp. 2662–2665. [Google Scholar] [CrossRef]
- Gao, H.; Barbier, G.; Goolsby, R. Harnessing the crowdsourcing power of social media for disaster relief. IEEE Intell. Syst. 2011, 26, 10–14. [Google Scholar] [CrossRef]
- Lindsay, B.R. Social Media and Disasters: Current Uses, Future Options, and Policy Considerations; Technical Report; Library of Congress; Congressional Research Service: Washington, DC, USA, 2011. [Google Scholar]
- Du, H.; Nguyen, L.; Yang, Z.; Abu-Gellban, H.; Zhou, X.; Xing, W.; Cao, G.; Jin, F. Twitter vs news: Concern analysis of the 2018 california wildfire event. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; Volume 2, pp. 207–212. [Google Scholar]
- Nguyen, L.H.; Hewett, R.; Namin, A.S.; Alvarez, N.; Bradatan, C.; Jin, F. Smart and connected water resource management via social media and community engagement. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 613–616. [Google Scholar]
- Yang, Z.; Nguyen, L.; Zhu, J.; Pan, Z.; Li, J.; Jin, F. Coordinating disaster emergency response with heuristic reinforcement learning. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Hague, The Netherlands, 7–10 December 2020; pp. 565–572. [Google Scholar]
- Nguyen, L.; Yang, Z.; Li, J.; Pan, Z.; Cao, G.; Jin, F. Forecasting people’s needs in hurricane events from social network. IEEE Trans. Big Data 2019, 8, 229–240. [Google Scholar] [CrossRef]
- Lu, Y.; Hu, X.; Wang, F.; Kumar, S.; Liu, H.; Maciejewski, R. Visualizing social media sentiment in disaster scenarios. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1211–1215. [Google Scholar]
- Kryvasheyeu, Y.; Chen, H.; Obradovich, N.; Moro, E.; Van Hentenryck, P.; Fowler, J.; Cebrian, M. Rapid assessment of disaster damage using social media activity. Sci. Adv. 2016, 2, e1500779. [Google Scholar] [CrossRef] [PubMed]
- Hurricane Harvey Tweets. 2017. Available online: https://www.kaggle.com/datasets/dan195/hurricaneharvey (accessed on 6 August 2023).
- Ghoshal, A. EmoRoBERTa. 2023. Available online: https://huggingface.co/arpanghoshal/EmoRoBERTa (accessed on 18 August 2023).
- Hind Saleh, A.A.; Moria, K. Detection of Hate Speech using BERT and Hate Speech Word Embedding with Deep Model. Appl. Artif. Intell. 2023, 37, 2166719. [Google Scholar] [CrossRef]
- Gupta, S.; Lakra, S.; Kaur, M. Study on BERT Model for Hate Speech Detection. In Proceedings of the 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 5–7 November 2020; pp. 1–8. [Google Scholar] [CrossRef]
- D`Sa, A.G.; Illina, I.; Fohr, D. BERT and fastText Embeddings for Automatic Detection of Toxic Speech. In Proceedings of the 2020 International Multi-Conference on: “Organization of Knowledge and Advanced Technologies” (OCTA), Tunis, Tunisia, 6–8 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Hoang, M.; Bihorac, O.A.; Rouces, J. Aspect-Based Sentiment Analysis using BERT. In Proceedings of the 22nd Nordic Conference on Computational Linguistics, Turku, Finland, 30 September–2 October 2019; Hartmann, M., Plank, B., Eds.; Linköping University Electronic Press: Turku, Finland, 2019; pp. 187–196. [Google Scholar]
- Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An Effective BERT-Based Pipeline for Twitter Sentiment Analysis: A Case Study in Italian. Sensors 2021, 21, 133. [Google Scholar] [CrossRef]
- Gu, J.C.; Li, T.; Liu, Q.; Ling, Z.H.; Su, Z.; Wei, S.; Zhu, X. Speaker-Aware BERT for Multi-Turn Response Selection in Retrieval-Based Chatbots. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Online, 19–20 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2041–2044. [Google Scholar] [CrossRef]
- Xu, Z.; Zhu, P. Using BERT-Based Textual Analysis to Design a Smarter Classroom Mode for Computer Teaching in Higher Education Institutions. Int. J. Emerg. Technol. Learn. 2023, 18, 114–127. [Google Scholar] [CrossRef]
- To, Q.G.; To, K.G.; Huynh, V.A.N.; Nguyen, N.T.Q.; Ngo, D.T.N.; Alley, S.J.; Tran, A.N.Q.; Tran, A.N.P.; Pham, N.T.T.; Bui, T.X.; et al. Applying Machine Learning to Identify Anti-Vaccination Tweets during the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2021, 18, 4069. [Google Scholar] [CrossRef]
- Zhu, J.; Weng, F.; Zhuang, M.; Lu, X.; Tan, X.; Lin, S.; Zhang, R. Revealing Public Opinion towards the COVID-19 Vaccine with Weibo Data in China: BertFDA-Based Model. Int. J. Environ. Res. Public Health 2022, 19, 13248. [Google Scholar] [CrossRef]
- Rahali, A.; Akhloufi, M.A. MalBERT: Using Transformers for Cybersecurity and Malicious Software Detection. arXiv 2021, arXiv:2103.03806. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Demszky, D.; Movshovitz-Attias, D.; Ko, J.; Cowen, A.; Nemade, G.; Ravi, S. GoEmotions: A Dataset of Fine-Grained Emotions. arXiv 2020, arXiv:2005.00547. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Chen, T.H.; Thomas, S.W.; Hassan, A.E. A survey on the use of topic models when mining software repositories. Empir. Softw. Eng. 2016, 21, 1843–1919. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the 22nd Annual international ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 50–57. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Mimno, D.; Wallach, H.M.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Scotland, UK, 27–31 July 2011; Association for Computational Linguistics: Cambridge, MA, USA, 2011; pp. 262–272. [Google Scholar]
- Thorndike, R. Who belongs in the family? Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Value of Parameter |
|---|---|---|
| input_ids | (None, 50) | 0 |
| token_type_ids | (None, 50) | 0 |
| roberta | (32, 50, 768) | 124,055,040 |
| emotion | (28, 1) | 612,124 |
| Likes | Replies | Retweets | Tweet Counts | ||||
|---|---|---|---|---|---|---|---|
| Emotion | Mean | Max | Mean | Max | Mean | Max | |
| caring | 6.11 | 993 | 0.32 | 267 | 2.03 | 876 | 37,965 |
| curiosity | 2.51 | 842 | 0.35 | 117 | 1.38 | 773 | 19,068 |
| fear | 3.09 | 977 | 0.36 | 303 | 2.14 | 644 | 9502 |
| sadness | 4.41 | 846 | 0.39 | 71 | 3.06 | 577 | 6362 |
| anger | 3.81 | 846 | 0.44 | 141 | 1.38 | 785 | 4633 |
| surprise | 5.78 | 827 | 0.52 | 94 | 4.93 | 898 | 4103 |
| disgust | 3.55 | 773 | 0.45 | 103 | 2.29 | 687 | 3024 |
| annoyance | 4.90 | 765 | 0.51 | 91 | 2.10 | 848 | 2948 |
| disapproval | 3.79 | 732 | 0.46 | 45 | 2.08 | 458 | 2856 |
| realization | 6.18 | 759 | 0.58 | 84 | 2.90 | 546 | 2315 |
| … | |||||||
| grief | 7.58 | 887 | 0.26 | 7 | 1.51 | 117 | 283 |
| embarrassment | 1.06 | 11 | 0.17 | 2 | 0.22 | 5 | 133 |
| pride | 9.73 | 456 | 0.33 | 15 | 2.45 | 123 | 130 |
| Stressor | Important Terms |
|---|---|
| Care of Family & Friend | praying, family, friend, path, everyone, affect, safety, pray, people, stay, area, state, hit, keep, protection, home |
| Landfall danger | make, landfall, pray, late, mess, danger, breaking, early, friday, news, expect, path, rockport, powerful, people, terrify |
| Closures | due, close, today, cancel, join, school, emergency, safety, government, stay, saturday, service, pray, office, weekend, day |
| Power | power, nothing, home, without, port, enough, dry, focus, play, ban, leave, damage, go, cover, thousand, resident |
| Safety update | update, sending, latest, night, terrifying, homeless, prayer, suffer, siege, wrong, everyones, love, positive, path, safety, affect |
| Lack of resources | need, guy, water, give, last, dear, end, world, help, safe, stay, night, pray, go, everyone, time, people |
| Destruction | cause, expect, check, damage, die, lot, flooding, ill, story, catastrophic, whole, rainfall, event, hard, people, go, see, hit |
| Fake News | us, bad, feel, year, work, fake, powerful, news, ask, hit, threaten, strengthen, report, likely, major |
| Evacuation plan | flee, continue, intensify, run, doings, thousand, people, closely, camp, evacuation, arrive, forget, time, strengthen, assist, path, watch, safety |
| Flood | flood, catastrophic, watch, hit, start, wake, destruction, local, area, home, path, rescue, people, time |
| Concern for animals | cant, animal, morning, believe, terrify, reach, stand, leave, people, go, think, imagine, good, keep |
| Warnings | tonight, thinking, land, safety, warning, devastating, stay, moment, nature, heed, path, friend, everyone, pray, hit, family |
| Heavy rain | rain, upgrade, bless, find, problem, heavy, hold, 10, inch, breaking, foot, expect, day, safety, hit, huge |
| Shelter needs and death toll | eye, shelter, city, pet, death, aid, sandy, vote, rise, horrible, toll, face, cancel, find, flooding, show, ask |
| Oil & Gas price rise | price, report, stop, gas, fema, oil, food, impact, rise, news, expect, high, affect, bad |
| Landfall Preparedness | prepare, think, high, let, attention, wishing, drown, pay, safety, stay, pray, path, rain, brace, make, landfall, catastrophic |
| Finance | ready, sure, wont, realize, medium, massive, money, make |
| Response | call, tell, response, save, watching, inside, predict, track, life, hard |
| Climate change policy update demand | change, climate, handle, deluge, administration, make, much, DoE, say, check, evacuate, show, good, people, cnn, rainfall |
| Alligator | move, turn, follow, beware, tropical, alligator, consider, people, news, see, hit, path, safety |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bui, T.; Hannah, A.; Madria, S.; Nabaweesi, R.; Levin, E.; Wilson, M.; Nguyen, L. Emotional Health and Climate-Change-Related Stressor Extraction from Social Media: A Case Study Using Hurricane Harvey. Mathematics 2023, 11, 4910. https://doi.org/10.3390/math11244910
Bui T, Hannah A, Madria S, Nabaweesi R, Levin E, Wilson M, Nguyen L. Emotional Health and Climate-Change-Related Stressor Extraction from Social Media: A Case Study Using Hurricane Harvey. Mathematics. 2023; 11(24):4910. https://doi.org/10.3390/math11244910
Chicago/Turabian StyleBui, Thanh, Andrea Hannah, Sanjay Madria, Rosemary Nabaweesi, Eugene Levin, Michael Wilson, and Long Nguyen. 2023. "Emotional Health and Climate-Change-Related Stressor Extraction from Social Media: A Case Study Using Hurricane Harvey" Mathematics 11, no. 24: 4910. https://doi.org/10.3390/math11244910