1. Introduction
Rehabilitation robots have established a distinct position in the vast landscape of medical technology. As technological advancements continue to revolutionize healthcare, these robots emerge as a beacon of hope for patients striving to regain functions lost due to traumatic injuries or debilitating conditions [
1,
2]. Beyond the obvious benefits of delivering consistent, precise therapeutic motions, these robots redefine rehabilitative care by transcending traditional boundaries. Their versatility lies not just in the diverse therapeutic regimens they can deliver but also in their adaptability to function across different settings—from sophisticated medical facilities to the comfort of patients’ homes [
3,
4]. This ability to decentralize rehabilitative care ensures that more individuals can access quality therapy, regardless of geographical or logistical barriers. But the potential of these robots is not just in their mechanics or software; it is profoundly intertwined with their control mechanisms [
5,
6]. The need for exact, reliable control becomes even more paramount when we consider the intimate interactions these robots have with patients. Every movement, no matter how minuscule, must be executed with impeccable precision, underscoring the essence of reliability in their control systems.
In the realm of nonlinear systems control, traditional methodologies span from conventional proportional–integral–derivative (PID) schemes to advanced controllers such as fuzzy logic [
7,
8,
9,
10,
11,
12,
13] and optimal control [
14,
15,
16,
17,
18,
19] strategies. Despite their proven utility, these controllers fundamentally rely on precise system models and often falter in the face of intricate, unpredictable disturbances and systemic uncertainties. Acknowledging these limitations, recent scholarly efforts have pivoted towards the conceptualization of state observers. Among these, finite-time observers have emerged prominently, distinguishing themselves by guaranteeing state convergence within a specified finite time as opposed to the asymptotic approach characterized by exponential convergence. This paradigm shift towards finite-time convergence is of considerable interest within control engineering, providing a robust framework that copes more adeptly with the exigencies of real-time system dynamics and the attendant uncertainties [
20]. This approach not only offers a more deterministic outlook on state estimation timelines but also enhances the resilience of control systems against unforeseen disturbances, marking a significant advance over traditional control mechanisms. The promise of finite-time controllers extends to their potential integration with modern modeling techniques, paving the way for more intelligent, adaptive control structures that can outperform classical methods, ensuring more reliable and effective system regulation.
Robotics control, particularly in dynamic and unpredictable environments like rehabilitation, continually faces a plethora of challenges [
3,
21]. While traditional control mechanisms, honed by decades of research and practical use, struggle with the intricacies of modern robotic systems [
22], feedback control has been a pivotal element in systems engineering, undergoing substantial evolution. Originally designed to ensure system stability and performance amid disturbances, feedback control has progressively incorporated advanced computational methods. This transition, from fundamental controllers to more adaptive and robust control strategies, addresses the complexities of contemporary systems. In recent developments, feedback control now includes sophisticated methodologies such as Output Feedback Self-Tuning Controllers [
23]. These cutting-edge controllers adapt their parameters dynamically, learning from the system’s output to incessantly refine control laws. Such self-tuning abilities represent the significant advancement in feedback control technologies, allowing systems to perform efficiently in uncertain scenarios and mirroring the current trend towards more automated and intelligent systems. Nonetheless, these methods still have potential for further enhancement, particularly with the advent of machine learning approaches that have revolutionized nearly all fields, including dynamics modeling and control [
24,
25].
Control engineering is increasingly recognizing deep learning as a significant area of potential. Originating from advanced algorithms adept at extracting insights from extensive and complex datasets, deep learning introduces an unprecedented level of adaptability [
26,
27]. Envision a control system that not only evolves, learns, and adapts over prolonged design cycles but also operates in real time, promptly responding to immediate environmental stimuli [
28,
29]. Deep learning, with its neural networks and layered architectures, can potentially dissect and predict system behaviors with a granularity that could revolutionize adaptive control strategies [
30,
31]. This potential convergence of deep learning with control mechanisms could very well herald the next big leap in controlling complex, uncertain systems [
32]. However, deep learning, like many technological innovations, is not without its shortcomings [
33,
34]. One notable constraint is its limited prowess in extrapolation, particularly in unfamiliar domains [
35]. In the field of rehabilitation robotics, where safety is of utmost importance, unpredictability in system behavior is unacceptable. Solely depending on deep learning without robust control mechanisms may result in ineffective or, in extreme situations, hazardous outcomes. This necessitates the adoption of integrated or hybrid control systems, especially in applications where the stakes are high and the implications of failure are significant. Such strategies are essential to ensure the reliability and safety of robotic systems interacting closely with humans.
In the domain of rehabilitation robotics, the intricate interplay of human biology, robotics, and control systems creates a uniquely complex landscape. These challenges underscore the need for control systems that are not only adaptable to the dynamic nature of human physiology but also exhibit precision in execution to ensure safety and efficacy [
1,
36]. Additionally, as technology marches forward, we envision a future where these robots, already complex, take on even more multifaceted tasks. Such advancements amplify the need for flawless operation, ensuring patient safety and therapeutic efficacy [
37,
38]. Furthermore, as rehabilitation robots move towards becoming an integral part of mainstream healthcare, their broad acceptance is contingent upon delivering consistent and reliable performance. These factors highlight the urgent need for dedicated research. A sole reliance on deep learning or traditional controls is insufficient. A blended approach, combining the strengths of both, is essential.
Addressing the industry’s challenges and requirements, our research proposes an innovative control methodology. We envision a system in which advanced machine learning algorithms are harmoniously integrated with time-tested control methodologies. The cornerstone of our approach is a model-free feedback linearization technique, which is significantly enhanced by the application of deep neural networks. This integration not only fortifies the control system’s adaptability but also ensures a high level of precision and reliability in its operation. Acknowledging the constraints of deep learning, our proposed technology ventures further. In real-time extrapolative contexts, we integrate a robust online observer. This component continuously estimates and adapts to uncertainties, even those beyond the training purview, ensuring our controller remains steadfast and adaptable. Such a design provides a delicate balance—leveraging the predictive might of machine learning while ensuring real-time reliability and adaptability, crucial for the dynamic world of rehabilitation robots.
2. Dynamic of the System
Consider a two-degree-of-freedom (2-DOF) knee rehabilitation robotic system as illustrated in
Figure 1. This design captures the essential elements for simulating the biomechanical dynamics inherent to knee rehabilitation exercises. The system comprises two primary links, each characterized by its unique degree of freedom, denoted as
for the upper link and
for the lower link. We denote
as the vector [
,
], representing the system’s generalized coordinates. The respective masses and lengths associated with these links are labeled as
,
, and
. Springs positioned at the joints suggest an element of elasticity, perhaps designed to emulate the natural compliance found within a human knee. The coordinate points
and
are indicative of specific locations or reference points on the link.
It is important to note that the 2-DOF knee rehabilitation robotic system is meticulously designed for lower limb rehabilitation, specifically targeting the knee joint. The upper link of the robot, referred to as ψ1, is tailored to mimic the human femur, while the lower link, ψ2, aligns with the tibia. These robotic links are purposefully actuated to replicate the natural movements of the human leg during rehabilitation exercises.
A distinctive feature of our system is the incorporation of springs at the joints. These springs introduce controlled compliance, closely resembling the physiological properties of human muscles and ligaments. This design choice ensures a safe and realistic interaction between the robot and the user, facilitating a responsive rehabilitation experience capable of adapting to the varying levels of stiffness and strength exhibited by recovering patients.
Table 1 enumerates and provides descriptions of the parameters and variables of the system.
The practical applications of this design extend beyond basic rehabilitation exercises to encompass post-operative therapy, injury recovery, and strength conditioning. Our system is designed to provide a versatile solution that not only aids in restoring functional mobility but also quantifies patient progress through the collection of accurate kinematic data. As part of our ongoing work, we plan to conduct clinical trials to validate the system’s effectiveness in real-world rehabilitation settings. This step will further bridge the gap between theoretical research and tangible medical benefits, addressing the concerns raised about the interaction of our system with the human body.
2.1. Model of the System
The kinetic energy of the 2-DOF knee rehabilitation robot can be formulated mathematically as follows:
where
and
stand for the generalized coordinates for the system depicted in
Figure 1. Also, in our formulations,
The distance from joint
to the center of mass of link
is represented by
, where
can assume values of 1 or 2. The masses of links 1 and 2 are denoted as
and
, respectively. Furthermore,
signifies the moment of inertia of link
about an axis orthogonal to the plane of illustration and situated at its center of mass. The system’s potential energy can be articulated mathematically as follows:
Utilizing Lagrange’s equation, the dynamic equations governing the system can be derived as:
where the inertia matrix,
, stands as a symmetric and positive definite matrix of size
. Furthermore,
encompasses the collective influence of Coriolis and centripetal forces. The gravitational forces acting on the system are depicted by
. The Jacobian matrix is denoted by
and is presumed to be nonsingular. The force vector, governed by constraints, is symbolized by
and the input torque, represented by
. Utilizing Lagrange’s equation, the components constituting this motion equation (delineated in Equation (3)) are detailed as:
The force vector and Jacobian matrix are described as follows:
To recast the motion equation for the 2DOF multi-input multi-output rehabilitation robot into a state-space format, we set
=
and
=
. Accordingly, the dynamic behavior of the robot is articulated as:
From which, drawing upon Equations (3)–(5), the following can be derived:
The presented equation delineates the state space of the system, wherein each component may be subject to uncertainty. This is particularly true given that the robot interacts with patients, and the forces and uncertainties can vary considerably between individuals. Relying solely on this dynamic motion for controller design in rehabilitation robots may not be practical for real-world applications. At the very least, the results might be suboptimal due to the inherent uncertainties. In the subsequent section, we introduce a deep neural network to model the system, rendering our controller design independent of the system’s model. The deep neural network’s capacity for function approximation allows the controller to adeptly learn the system’s nonlinear dynamics.
2.2. Proposed Neural State-Space Model
Neural state-space models fall under a class of models that utilize neural networks to capture the functions characterizing a system’s nonlinear state-space description [
24,
39,
40,
41,
42,
43,
44,
45]. In classical control theory, these models serve to elucidate the behavior of dynamic systems, highlighting the interplay between the system’s inputs, outputs, and intrinsic states. Consider a typical state-space format characterized by the subsequent mathematical expression. The system’s mathematical configuration is delineated as:
where
and
are static non-linear mappings, which are dynamically modeled using a deep neural network as opposed to the model derived in the prior section. In this context, our deep neural networks provide a robust mechanism to depict and comprehend nonlinear associations, rendering them particularly apt for shaping state-space models of analogous systems. We introduce a neural state-space model where the state equation is underscored by neural networks. This network encapsulates the function delineating the system’s state behaviors. While we employ deep forward neural networks in this instance, one could also adopt recurrent neural structures, such as LSTM or GRU, or alternative architectural designs, contingent on the unique attributes of the system under consideration.
In the neural state-space model, the deep neural network is calibrated using system data. This calibration process refines the network parameters to reduce the variance between the model’s forecasts and the system’s actual behavior. Several methods, including gradient descent and backpropagation, are applicable to this optimization. After the training phase, the neural state-space model serves to emulate the system’s behavior, deduce its inherent states from provided inputs and outputs, and anticipate forthcoming system reactions.
3. Proposed Control Technique
In the control of nonlinear systems, there is a shift from classic controllers like PID towards advanced observers for better handling of disturbances and uncertainties. Finite-time observers, in particular, are gaining prominence for their ability to guarantee convergence within a fixed period, offering a more reliable approach for real-time applications. This innovative direction suggests the possibility of integrating finite-time control strategies with modern modeling techniques, potentially leading to smarter and more resilient control solutions in engineering.
Here we take advantage of both the finite-time observer and deep forward neural networks. The controller we propose capitalizes on a pre-trained deep neural network as the system’s state space. However, no deep neural network is flawless, and inevitably there will be uncertainties and unanticipated scenarios that surpass the bounds of the training process. To address this, a finite-time estimator is integrated to discern unknown disturbances and uncertainties. Given the limitations of the deep neural network in extrapolation, it might fall short in estimating these within the designed finite-time control framework. Regardless of these intricate uncertainties and disturbances, the intended finite-time control should guide the states of the rehabilitation robot towards the desired position. Consequently, we consider the dynamic of the systems in a realistic form as follows:
in which
denotes all uncertain terms that the deep neural network is not able to accurately model. Now, we propose the robust and finite-time approach as follows:
where
and
respectively denote the desired path and its time derivative.
and
denote the error vector and its derivate, respectively, and they are given by
and
. Our proposed technique combines a neural state-space model determined by a deep neural network, represented by
and
. This is complemented by a feedback linearization strategy, characterized by the terms
, and a finite-time accurate observer denoted by term
. We propose the disturbance compensator
as follows:
in which
are positive design parameters and
,
, and
are auxiliary variables used for designing the proposed observer.
Theorem 1. Using the suggested robust intelligent control approach, system (9) consistently adheres to the desired state, even when confronted with unforeseen uncertainties and perturbations in the training of the neural state space of the system.
Remark 1. The robust online observer is a critical component in the presented control scheme for rehabilitation robots, as it addresses a significant challenge in the realm of automated systems: the ability to manage uncertainties and variations in real-time. This observer functions as a dynamic element within the control system, continuously analyzing and adjusting to the discrepancies between the predicted and actual performance of the robot. Its integration is particularly vital because, despite the model-free nature of the control method and the initial learning of system dynamics, there remains an inherent unpredictability in real-world scenarios. The use of this observer allows the system to not just rely on pre-learned data but to actively adapt to new situations, ensuring both the safety and effectiveness of the robotic rehabilitation process. By continually estimating and compensating for unforeseen variations and uncertainties, the robust online observer significantly enhances the reliability of the control system, a crucial aspect in medical applications where patient-specific needs and safety are paramount.
Proof. In the initial step, we demonstrate that the estimator precisely approximates the composite nonlinearity,
. To initiate, we introduce the auxiliary error variables in the following manner:
Taking into account Equations (9)–(15), one can derive the following:
where Equation (19) is equivalent to
in which
denotes the bound for the unknown term
. As established in Lemma 2 of reference [
46], the estimation errors
and
converge to zero within a finite time. Consequently, after a short time range
, the following equations are valid:
Up to this point, we have demonstrated that the estimation is accurate, and the proposed observer compensates for inaccuracies in deep neural network estimation. Now, to show the stability of whole closed-loop systems, we introduce the following Lyapunov function
The time derivative of the Lyapunov function as presented in Equation (22) can be expressed as:
Substituting the proposed control input into Equation (23), we obtain:
In Equation (21), we demonstrated
; consequently, with the results in Equation (24) it is directly deduced that
This derivative being a negative definite signifies the stability of the closed-loop system. As a result, the closed-loop system naturally gravitates towards the desired trajectory, ensuring that the error dynamics eventually reduce to zero. Importantly, this stability is maintained regardless of the precision of the neural state-space estimator or the chosen initial conditions. □
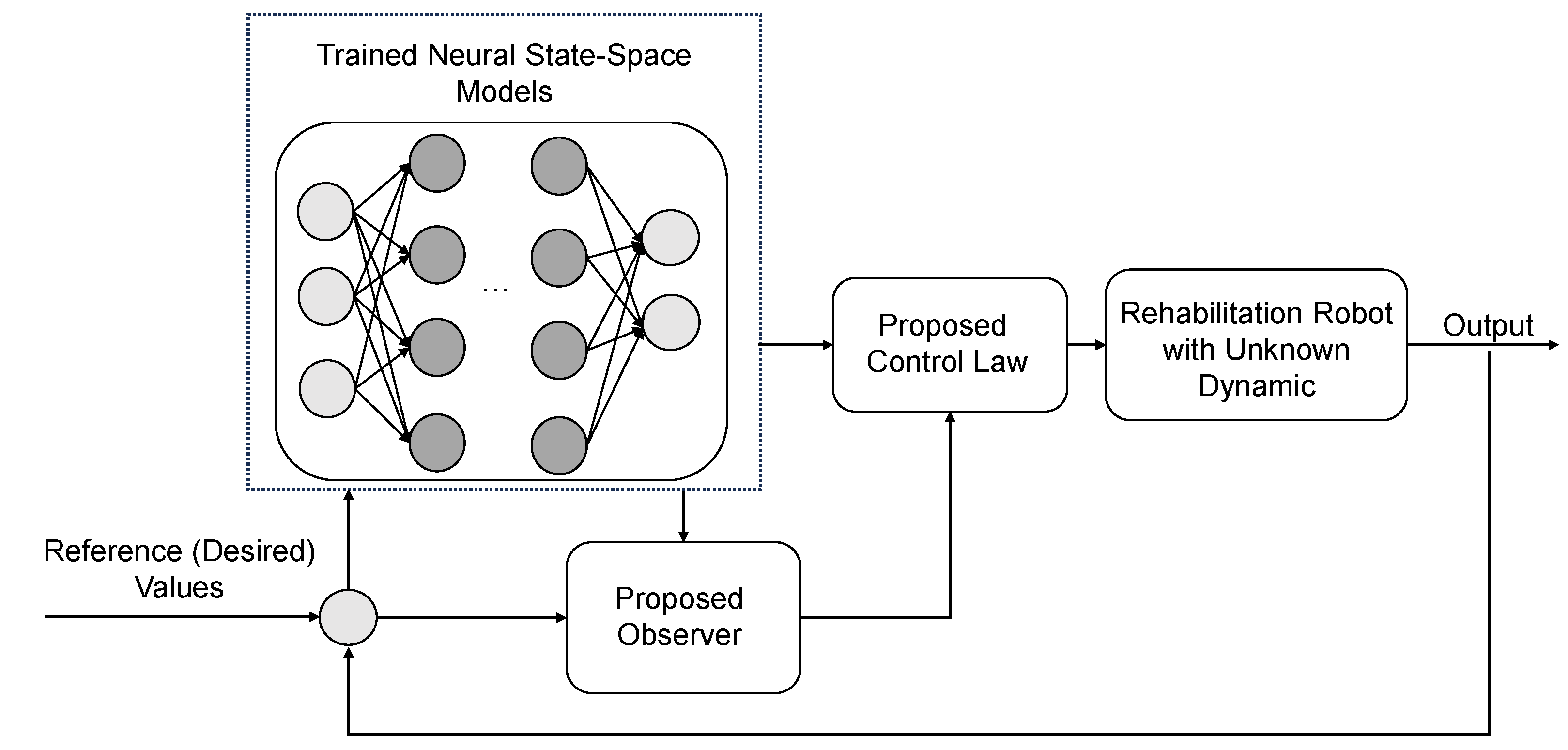
Figure 2 depicts the suggested control strategy. This approach integrates robust control as proposed in Equation (10), facilitating the accommodation of disturbances within the model. Such a configuration guarantees that the controller remains adaptive and robust, making it ideal for managing rehabilitation robots.
4. Numerical Simulations
In this section, we assess the efficacy of the proposed approach using various examples. Specifically, in Examples 1 and 2, we showcase the capability of the proposed technique in managing the unknown intricate dynamics of the system under two distinct initial conditions. The values of the system’s parameters are defined according to the values listed in
Table 1. In Example 3, we leverage data derived from the algorithm to achieve control objectives that change over time.
4.1. Training Neural State-Space Model
For data generation, we used step inputs of varying amplitudes (with the amplitude altered randomly) to excite the system, subsequently measuring and logging the position and velocity of both links in the 2-DOF robot. These data were sourced by simulating the system model as described in Equation (6).
In our research, we employed a two-layer multi-layer perceptron (MLP) neural network, each layer containing 128 nodes. We selected the hyperbolic tangent (tanh) activation function for its effectiveness in normalizing outputs. The network’s initial weights were set using the Glorot initializer, and biases were initialized to zeros, providing a stable starting point for training. The model was trained over 2000 epochs using the Adam optimizer, a choice that ensures efficient and adaptive learning. This setup strikes a balance between learning capacity and computational efficiency, tailored to the demands of our state estimation task.
The accumulated training data were then utilized to train the neural network in an offline mode. For this training, 100 time histories of states of the system and their corresponding derivatives were utilized. A representative sample from these 100 samples, as employed in the training phase, is illustrated in
Figure 3. Although the dataset may appear modest in size, it is sufficient for several reasons:
- -
The diversity of the data: The time histories were generated using varying amplitudes of step inputs, which provided a rich set of dynamic responses from the system, encompassing a wide range of possible states.
- -
Suitability for a shallow network: The neural network employed is relatively shallow; such networks can effectively model complex relationships without the need for large volumes of data that might be required for deeper networks.
- -
Convergence of the loss function: The loss function, as shown in
Figure 4 of our paper, exhibits a strong convergence pattern. After a significant initial decrease, it stabilizes with minor fluctuations, indicating that the network has successfully captured the underlying system dynamics.
Figure 4 depicts the loss function evolution during the neural network training for representing the system’s neural state-space model. This loss function offers a perspective into the neural network’s optimization history. Observing this function allows us to gauge the evolution and convergence of the training, confirming that the neural network effectively represents the core dynamics of the system.
4.2. Example 1
Figure 5 showcases the control outcomes for link 1 and link 2 of the rehabilitation robot, utilizing the proposed control methodology with initial system states defined as
. The visuals effectively highlight the notable proficiency of the recommended robust adaptive controller. Also, this figure illustrates the controller’s adeptness, integrating a neural state-space model combined with a finite-time observer and feedback linearization term, in tackling the control challenges of a completely unknown system. It is noteworthy that no information from the system’s model is employed, underscoring the method’s relevance for real-world applications. This intrinsic capacity to navigate uncertainties is paramount when controlling rehabilitation robots.
4.3. Example 2
To further gauge the efficacy of our proposed controller, we conducted an auxiliary test by altering the initial state values of the system. We present the system’s time history and control input when the ignition velocities of the robot links deviate from zero, differing from the previous example. The chosen initial states for this test are .
Figure 6 provides insight into the controller’s capability to ensure system stability under these varied conditions. Moreover, the controller consistently operates within a permissible spectrum, guaranteeing viable control signal magnitudes. Remarkably, even when faced with wholly unknown system dynamics, the proposed controller showcases the excellent performance, accomplishing state stabilization in under 0.2 time units.
4.4. Example 3
We now examine a scenario where the reference values for links 1 and 2 are represented by a step function and differ from one another. The initial conditions remain consistent with the previously discussed example (Example 2).
Figure 7 presents the outcomes for this scenario. As depicted in the figure, both links adhere to their respective reference points and achieve these points within a short timeframe. The controller operates based on the error dynamics and the knowledge derived from the pre-trained neural state space.
In summary, our simulations reveal that the introduced control methodology excels in tracking control for the rehabilitation robot, even when faced with entirely unknown dynamics. It ensures the system’s stability and robustness. These results underscore the effectiveness of the proposed control strategy and highlight its suitability for real-world scenarios characterized by unexpected dynamics and prevalent uncertainties.
5. Conclusions
In this study, we introduced an innovative control scheme tailored for rehabilitation robots, emphasizing the integration of machine learning algorithms with classical control techniques. As the field of robotic rehabilitation continues its swift evolution, the need for a reliable and precise control mechanism becomes ever more pressing. Our methodology responds to this imperative by seamlessly integrating adaptability with precision. It is designed to accommodate the unique rehabilitation needs of each patient, ensuring personalized therapy without compromising on safety and effectiveness. Central to our approach is the model-free feedback linearization control mechanism, enriched by the capabilities of deep neural networks. Even though the controller operates without a predefined model, learning system dynamics primarily during the training phase, we incorporated an online observer. This observer ensures real-time, robust estimation of uncertainties, facilitating the system’s adaptability to challenges that might arise beyond its initial training. Our reliance on the Lyapunov stability theorem offered the requisite verification of the controller’s stability. For numerical simulations, at first, we generated data by applying step inputs with randomly varied amplitudes to a simulated 2-DOF robotic system, capturing the resulting positions and velocities. This simulation provided 100 time histories of the system’s states and their derivatives, which served as the training dataset for our neural network. Post-training, we implemented the model in three distinct numerical simulations with varying initial conditions and step references for each robotic link. These simulations demonstrated the efficacy of our controller, showcasing its robust performance and adaptability to unknown and dynamic uncertainties. While our presented approach lays a robust foundation for controlling rehabilitation robots, there remain avenues for further enhancements. One such recommendation would be to explore the integration of finite-time control policies as an alternative to feedback linearization. Such an integration could potentially elevate the agility and overall performance of the control system, ensuring even more efficient and responsive rehabilitation robot operations in diverse scenarios.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}