1. Introduction
Type 1 diabetes (T1D) is a metabolic disorder that causes abnormal regulation of blood glucose (BG), which can lead to short- and long-term health complications and even death if not adequately controlled [
1]. Prediction models can learn personalized glucose and insulin dynamics based on sensor measurements and daily activity of each individual. Notwithstanding the widespread use of machine learning techniques for glucose prediction [
2,
3,
4,
5,
6,
7,
8], a dearth of up-to-date literature reviews exists on the subject of modeling strategies applied to personalized BG prediction, as pointed out in [
9]. Currently, glucose prediction models exhibit significant discrepancies with reality due to factors such as sensor noise and delays. As a result, long-term glucose prediction remains poor and continues to be a very challenging task despite the increase in data availability [
10].
Chronic hyperglycemia is the main risk factor for the development of complications in diabetes mellitus; however, it is believed that large or frequent glucose fluctuations may contribute independently to these complications. Glycemic variability (GV) refers to this fluctuation of glucose levels, describing variations throughout the day, including hypoglycemic episodes and postprandial increases, as well as variations in glucose levels at different times of the day and at the same time on different days [
11,
12].
Glycemic control can be assessed by continuous glucose monitoring (CGM) using time in range (TIR), serving as a surrogate for glycated hemoglobin (HbA1c) for use in clinical management [
13]. Compositional data (CoDa) are data that transmit information about the parts of a whole expressed in proportions or percentages, as is the case of the vector of daily times in each of the glucose ranges: time below range (TBR) (<70 mg/dL), TIR (70–180 mg/dL), and time above range (TAR) (>180 mg/dL) [
14], where all the components are positive and of constant sum. Previous studies have treated the percentage of time in the glucose range as a composition, yielding favorable outcomes, and this variable is of paramount importance in this field [
15,
16,
17]. Furthermore, regression models have demonstrated favorable results overall, both in scalar variables and CoDa, due to their simplicity of implementation and robustness in prediction outcomes. Several studies have developed models for prediction in the field of diabetes, such as the relationship between HbA1c and glucose values, adaptive adjustment of bolus calculator parameters, and glucose prediction [
18,
19,
20]. In the literature, regression models for the prediction of diabetes have been previously reported [
21]. In [
22], a total of 89 studies published between 2011 and 2021 were included.
Although regression analysis is a widely used statistical technique, there is limited literature available when it comes to CoDa [
23,
24,
25,
26,
27,
28,
29]. No research has been found that specifically examines the application of CoDa to individualized regression models for diabetes. None of them were related to glucose prediction, mean, or coefficient of variation (CV). Although short-term prediction reviews have been found, there are not many publications with relevant metrics for long-term glycemic state predictions [
30,
31,
32,
33].
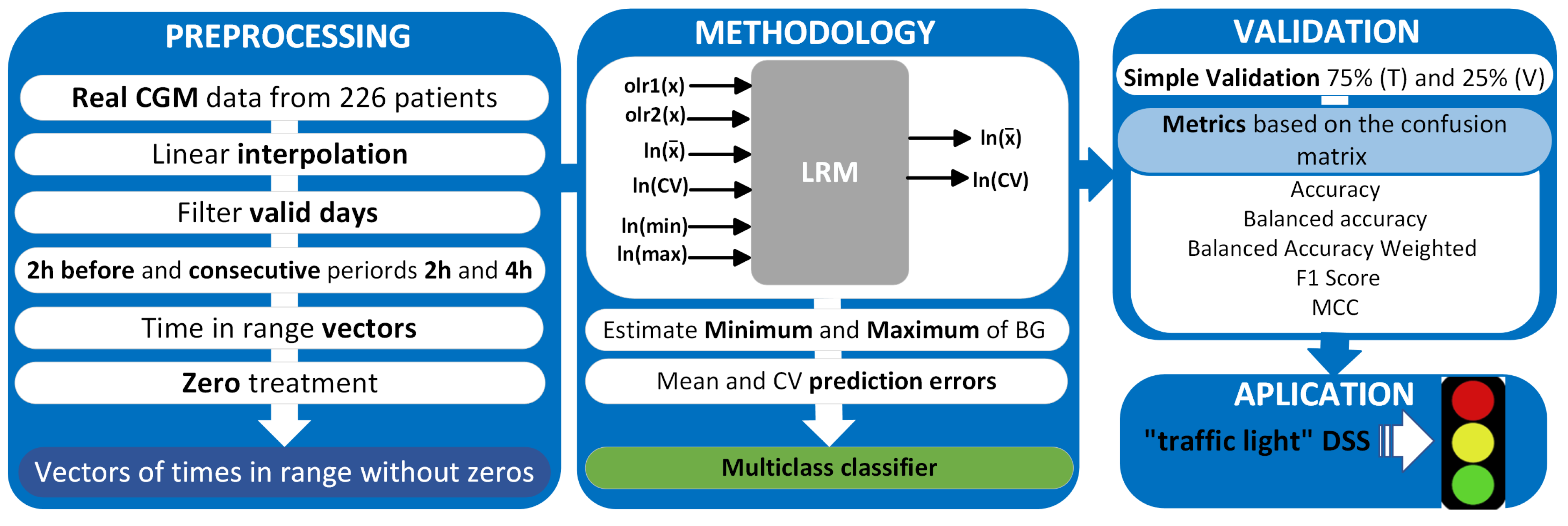
This study presents individualized multiple regression models for each hour of the day aimed at predicting blood glucose (BG) and the CV over extended prediction horizons. The models incorporate a CoDa type regressor (TBR, TIR, TAR), along with other scalar variables that proved valuable in distinguishing when compositional variables exhibited similarities. The dependent variables in the models are the mean and CV of glucose measurements for the next 2 and 4 h.
3. Results
Below are the detailed results for glucose mean and CV prediction as well as metrics for the classification and DSS.
3.1. Overall LRM Test Results
Compared to univariate linear regression, it is not possible to display the strength of the relationship between multiple composition variables (orthogonal basis of different time in ranges of glucose) and a dependent variable (mean, CV) in a single XY scatter plot because X has several potentially influential components [
26].
To test the normality assumption of the residuals, the Shapiro–Wilk test was used, which showed a p-value > 0.05, suggesting that we cannot reject the null hypothesis that the data come from a normally distributed population.
Non-constant variance score and Breusch–Pagan tests were performed to verify the homoscedasticity assumption, that is, “all errors have the same variance”. The results showed a p-value > 0.05, suggesting that the homoscedasticity assumption is met. Additionally, the independence assumption of the errors was checked using the Durbin Watson test, and no evidence of violation of this assumption was found (p-value > 0.05).
3.2. Validation of the Multivariable LRM of Mean and CV Prediction
The results are presented in terms of root mean squared error (RMSE) and mean absolute error (MAE) to estimate performance and evaluate the model fit for the entire cohort at different times of the day.
Figure 4 shows the results for the mean and CV prediction model for the next 2 h and 4 h. We analyzed both errors since the MAE error is more robust and does not give much importance to outliers, unlike the RMSE, which gives more importance to outliers by squaring the absolute value of the difference. As expected, the RMSE error is higher than the MAE error.
The results show that for the CV prediction, both the RMSE and MAE errors for all models were higher when predicting the next 4 h than when predicting the next 2 h. However, this did not happen with the mean glucose prediction, which remained more uniform.
It is very useful to identify glycemic trends at different times of the day, quantify glycemic variability, and stratify the risk of hypoglycemia based on the hours. In the early morning hours (01:00 to 08:00 h), the RMSE and MAE errors were lower for the mean model compared to the rest of the hours. Similarly, for the CV model, the RMSE error during the hours from 00:00 to 07:00 h was lower than the rest of the hours, and the MAE error was lower from 23:00 to 07:00 h. This shows that our model is capable of predicting early morning hours with higher reliability (lower errors). This factor is significant for both the risk of experiencing nocturnal hypoglycemia and the dawn phenomenon, which typically happens between 04:00 and 08:00 h in the morning.
Also, the distributions between the real and predicted means and CV were compared to detect if there were differences between them. The Kolmogorov–Smirnov statistic was used. The main advantage of this statistic is that it is sensitive to differences in both the location and shape of the cumulative distribution function. The results showed a p-value > 0.05 in all time periods, suggesting that we cannot reject the null hypothesis that the analyzed data follow the same distribution.
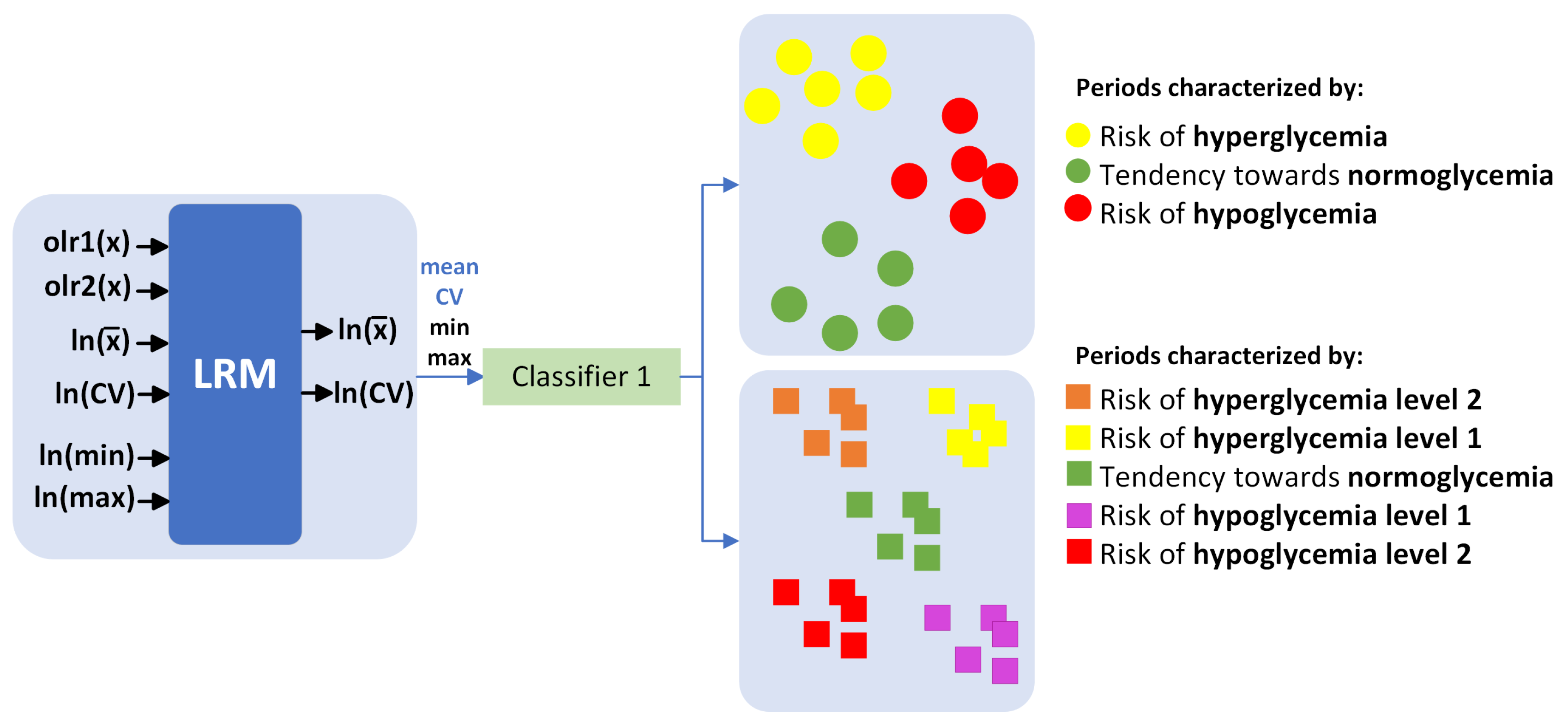
3.3. Application, Example of the “Traffic Light” Proposed for a Specific Patient
“Traffic light” systems for clinical information and clinical support are well known [
46,
47]. Using the multiple linear regression model’s predictions for mean and coefficient of variation, in addition to the estimates for minimum and maximum glucose levels over the next 2 and 4 h, a methodology was implemented to categorize each hour of the day into 3 and 5 categories, as illustrated in
Figure 3. The categorization criteria were defined based on the standards outlined in [
13]. The glucose time in range percentages were as follows: for three categories,
mg/dL,
mg/dL, and
mg/dL. The criteria for the five categories were more stringent:
mg/dL,
mg/dL,
mg/dL,
mg/dL, and
mg/dL. This system provides qualitative information about the future glucose state based on these estimates.
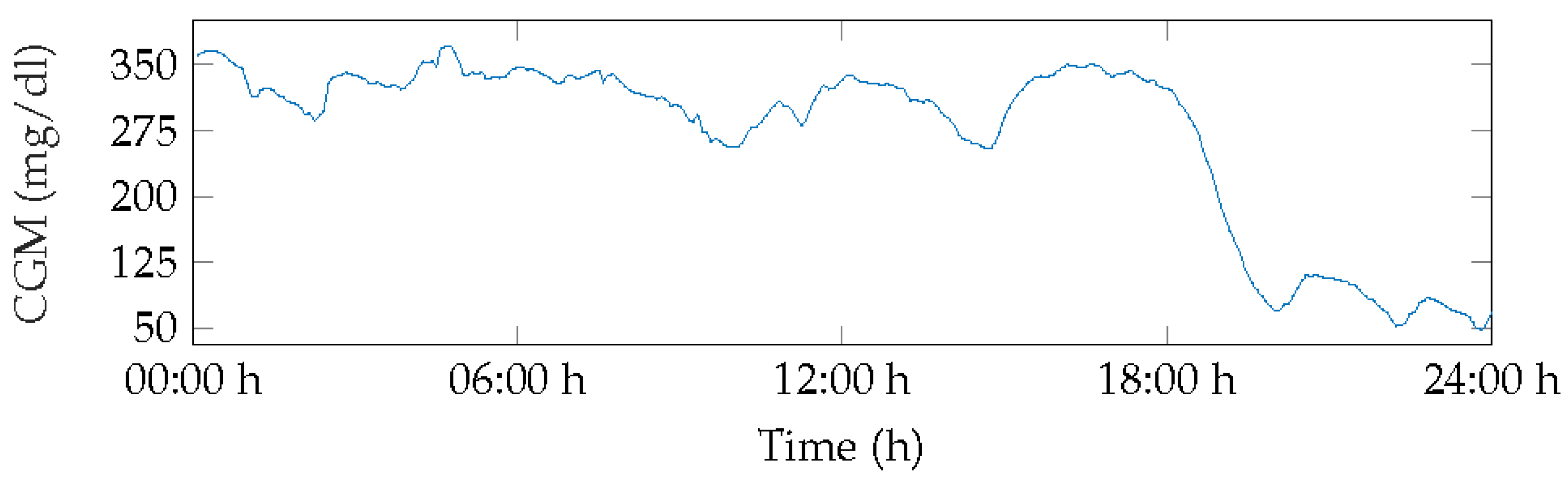
Patient 1, Day 3 Characterized by High Variability
Table 5 presents an example of the proposed “traffic light” system for patient 1. We have analyzed day 3, as it is a day with high glucose variability (36.53%), severe hyperglycemia both during the day and at night, and also the presence of hypoglycemia. Column 4 shows the description for each of the previously mentioned classes. Analyzing the predictions of the states for 3 class (column 2 of
Table 5), it can be seen that from 00:00 to 18:00 h, for every hour in that interval, the model predicted that the patient would be there for the next 2 h in hyperglycemia (>180 mg/dL); the actual states validate that the model was correct every time. During the night period, from 22:00 h of the previous day to 8:00 h, this patient experienced a glucose variability of 6.5%, with a minimum reading of 269 mg/dL and a maximum of 371 mg/dL, indicating severe hyperglycemia.
From 19:00 to 20:00 h, he was in the target glucose range (70–180 mg/dL), a situation that the model also correctly predicted. However, from 21:00 to 23:00 h, the patient was in hypoglycemia, a situation predicted by the model.
Still considering the prediction of 2 h, by analyzing the results for 5 class, from 00:00 to 17:00 h, the model predicted severe hyperglycemia, being more specific than when it was analyzed for 3 class. It was found that the minimum glucose was 244 mg/dL and the maximum was 329 mg/dL, and the CV for 2 h was between 2% and 8%. However, at 18:00 h, the model predicted risk of hyperglycemia; here we verified that the patient had a minimum of 70 mg/dL and a maximum of 321 mg/dL with a CV of glucose for the next 2 h of 40%, and vector time in range was 0% below 70 mg/dL, and 50% for both TIR and hyperglycemia above 180 mg/dL, that is, half of the next 2 h was spent time in normoglycemia and the rest in hyperglycemia.
Hence, at 19:00 and 20:00 h, the patient will behave in range time. At 21:00 and 22:00 h, the model predicted risk of hypoglycemia; however, the validation corroborated that it was accurate for 21:00 h, but for 22:00 h, the real state reported severe hypoglycemia. The time vector in range glucose reported 66% of time below 70 mg/dL, 33.3% in TIR, and 0% above 180 mg/dL. For 23:00 h, both the model and reality reported severe hypoglycemia. In practice, as we have shown in this example, it is expected that the patient will have the 24 models for each hour of the day, and the prediction model will update him on his future status for the next 2 h.
Figure 5 displays the BG measurements for Patient 1 for day 3. This day showed severe hyperglycemia for over 50% of the time, with the first minimum peak at 70 mg/dL occurring at 20:00 h, increasing glucose levels, and levels remaining in range until 22:00 h before dropping to hypoglycemia level 1 with few normoglycemic measurements.
3.4. Results of the Metrics for Multi-Class Classification
Once the actual and predicted data from the validation data were classified, the confusion matrix was created for each of the 24 models and each of the 226 patients. Although this is an individualized model, the metrics results are shown for the entire cohort.
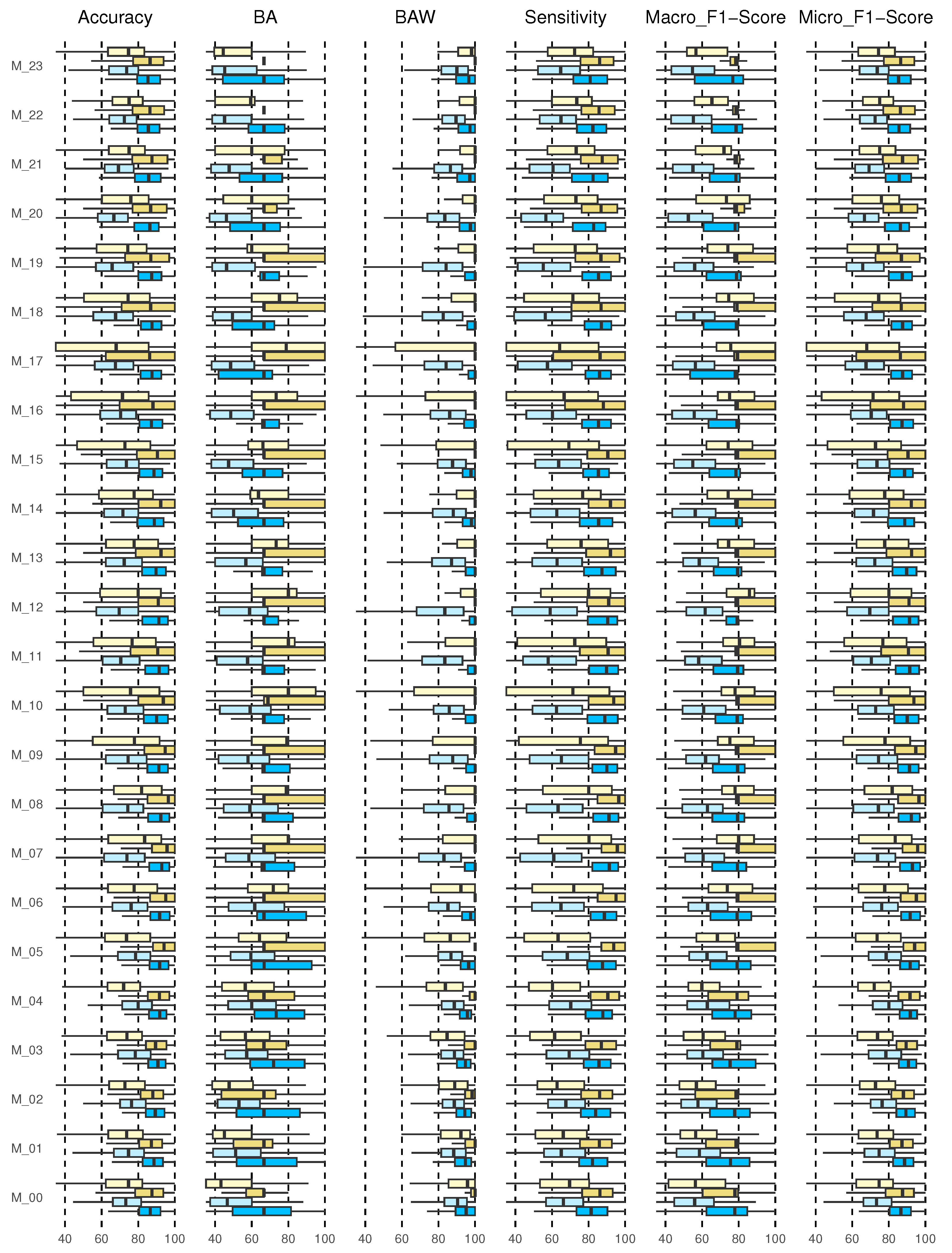
Figure 6 shows the results for accuracy, BA, BAW, sensitivity, and macro and micro F1-scores. Each of the results will be discussed below.
3.4.1. Accuracy Results
The accuracy returns a general measure of how correctly the model predicts for all samples. The results for the entire cohort are shown in the boxplot in
Figure 6 (first graph on the left).
The diagrams show the results of the predictions of the 24 models (M_00, M_01, …, M_23) corresponding to each hour of the day. The prediction of 2 h and 4 h with 3 and 5 classes are shown. This type of graph allows us to identify outliers and compare distributions, as well as knowing in a comfortable and fast way how 50% of the central values are distributed. The dimensions of the boxes are determined by the distance of the 25th–75th interquartile ranges. At all times, these distances were greater when the prediction horizon (PH) was longer (4 h), and they increased for the 5-class categorization.
For the prediction of 2 h, 3 and 5 classes, it is evident that the median is located in the center of the box, then the distribution is symmetric and the mean, median, and mode coincide, except for 2 h 3 class (M_04, M_07, M_11, M_14, M_20) and for 2 h, 5 class (M_07, M_08). For the prediction of 4 h, 3 class for schedules M_00 and M_06 to M_18, negative asymmetry is shown, as the longest part is the lower part of the median. Therefore, the data were concentrated in the upper part of the distribution. Here, the mean is usually less than the median; this shows dispersion in the data, not a greater value. For the prediction of 2 h and 4 h for 3 classes at all times, an accuracy greater than 85% was reached at all times of the day with a 75th quartile close to 100%. For 5 classes, the 4 h forecast presented better performance, although the data were more dispersed, with a 75th close to 90% for all times.
3.4.2. Balanced Accuracy and Balanced Accuracy Weighted Results
Figure 6 shows the results of the BA and BAW (second and third graph, respectively, from left to right). The results of the BA for 2 h, 3 classes for schedules M_00 to M_05 and M_15 behave symmetrically; however, the model for schedules M_13, M_17, M_20, M_21, and M_23 show negative asymmetry. For the 4 h forecast, except for the hours M_00 to M_02, there was positive asymmetry. For M_22 and M_23, all the results were concentrated in the median. At all times, the 75th quartile was above 70%. For the prediction to 5 classes, symmetry was observed only for 2 h in M_03, M_04, and M_07 to M_10. For the rest, there was generally positive asymmetry. Here, the 75th quartile was above 60%; however, it improved for the 4 h forecast, exceeding 80%. The results for 3 classes are satisfactory, although no symmetric distribution was observed in the results for any model. In all cases, the median was greater than 90% and the 75th quartile close to 100%. For the prediction with 5 classes, the results were observed to be more dispersed, especially in the hours from M_08 to M_10, M_16, and M_17. Symmetry was not observed.
3.4.3. Sensitivity Results
The results show that, for the prediction with 3 classes, the median was above 80% in all cases, with the 75th quartile close to 100%. However, the cohort data were more dispersed when 5 classes were evaluated, finding the median close to 75% for all hours and with a greater dispersion in daytime hours from M_05 to M_20 (
Figure 6 (fourth graph from left to right)).
3.4.4. F1-Score
In this study for the prediction with 3 classes, the results of the median for the entire model for the prediction at both 2 h and 4 h was higher than 80%, with a 75th quartile close to 100%, thus, the same in the hours from M_05 to M_19, indicating that the algorithm performs well in all classes. However, for 5 classes, the median for 2 h in all cases was above 60% but for 4 h in some cases above 70% (M_06 to M_21).
Micro-average considers all units together, without taking into account possible differences between classes, just like accuracy. Both measures give more importance to large classes, because they only consider all units together. In our case, all classes are important, so we should not underestimate the small ones. In addition, at some times the large classes for our model are usually TIR, which, although they provide information, do not suggest any corrective action. Even so, the results showed a median higher than 8% and 75% for when there are 3 classes and 5 classes, respectively. Very scattered results were not observed in any case, although there was a difference between the prediction with 3 and 5 classes.
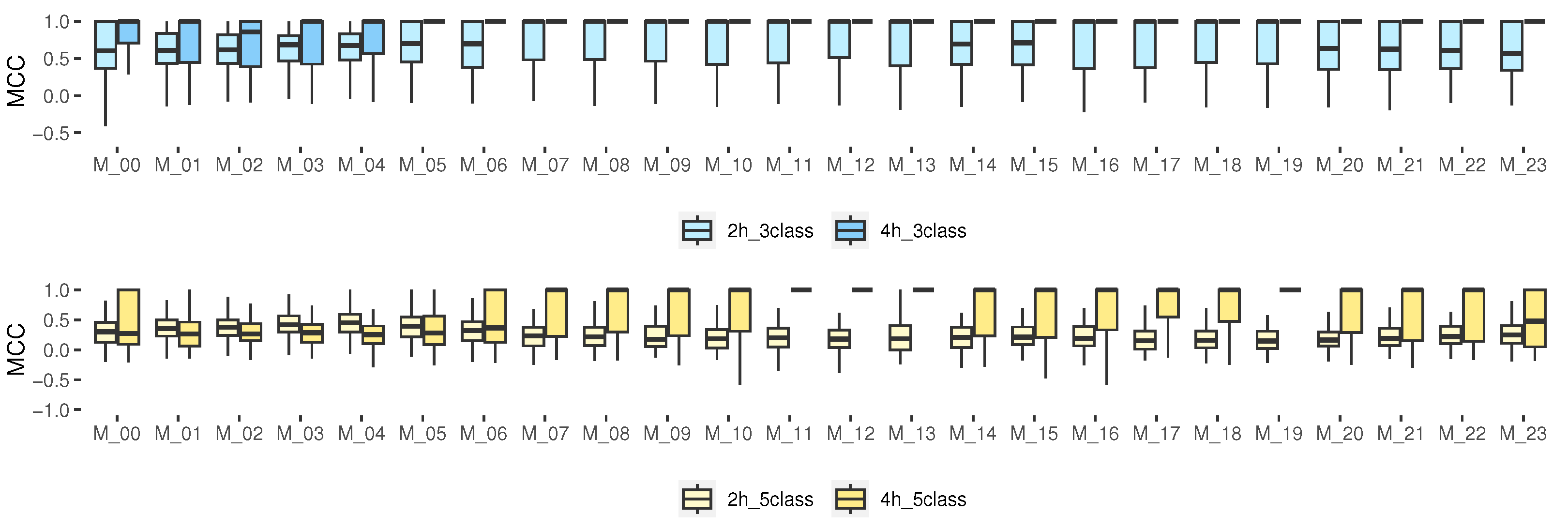
3.4.5. Matthews Correlation Coefficient for Multi-Class Classification
Among the advantages of this metric, we can see that MCC includes all the entries of the confusion matrix in both the numerator and the denominator [
48,
49]. Our results (
Figure 7) show that, for the prediction with 3 classes, especially for 4 h, the median for the hours from M_05 to M_23 was 1, indicating a perfect prediction. However, for 5 classes, such a median was only obtained for the models from M_07 to M_22 for 4 h. The rest of the hours, the median was close to 0.5 (greater than 0.5 is considered good). For some isolated cases, it was close to 0, which corresponds to a random prediction of the model, and some very isolated samples were below zero, which indicated a totally incorrect prediction. For 3 classes, it could be considered as an accurate model; however, for some schedules of 5 classes, it indicates that the model is not better than a random prediction.
4. Discussion
DSSs have proven to be useful tools for patients and physicians [
2,
46,
47]. Although glucose profiles have been treated as CoDa vectors in previous studies [
15,
16,
17], there is no application in this branch of mathematics that is focused on predicting the mean and the CV as an information system or DSS tool for patients with T1D at specific hours of the day oriented to wide PH (2 h and 4 h). In this work, CoDa variables and transformed scalars have been used to predict the mean and CV of glucose in patients with T1D. In addition, the different times of the day of the patients have been categorized to provide an idea of the behavior of glucose in the next 2 h and 4 h. The results have been validated using a sample of 226 adult patients from a real cohort.
Although no study was found that predicted the mean and CV for patients with T1D at a PH of 120 and 240 min, prior research has focused on glucose prediction within time horizons ranging from 15 to 120 min [
3,
4,
5,
6,
7,
8]. As expected, the longer the forecast horizon, the greater the error. Specifically, for a 120 min PH, errors typically exceed 45 mg/dL, as reported in previous studies [
5,
6,
8,
50].
The results show that the MAE mean prediction error is between 23 and 36 mg/dL for all times, when predicting at both 2 h and 4 h. The CV is between 4 and 7% for the 2 h prediction and between 6 and 8% for the 4 h prediction. The RMSE and MAE prediction error of the mean and CV at all times of the day was higher for the 4 h forecast horizon in the entire cohort, but the early morning times presented a lower error. It was confirmed that the CV at this time was lower than during the daytime hours.
Previous studies have used some of these metrics based on the confusion matrix to evaluate the performance of different methodologies [
48,
49]. In [
48], population outcomes for the mid-term continuous prediction module to predict hypoglycemia and population outcomes for the nocturnal hypoglycemic events predictor module are reported, with average mean of accuracy of 86.1% and 80.1%, respectively. Also, mean sensitivity of 48.5% and 44%, respectively, was reported. Here, there was a mean MCC of 0.51 with a minimum of −0.18 and a maximum of 0.86 for the mid-term continuous prediction module to predict hypoglycemia. In [
49], a cohort of 10 real patients was studied using support vector machines. The researchers presented the results, which evaluated the model’s performance with and without including physical activity measures. The findings showed that the median sensitivity for both scenarios was 71% and 70%, respectively. Furthermore, analyzing individual patients revealed that the median F1-scores ranged from 37% (patient 12) to 80% (patient 45), indicating varying levels of accuracy. Remarkably, excluding physical activity measures did not result in significant changes in this metric. Additionally, the reported MCC varied from 0.2 (patient 12) to 0.67 (patient 56).
The DSS provided interesting results in different metrics, such as accuracy, BA, BAW, sensitivity, F1-score, and MCC. They were higher than 90% for the entire cohort for 3 classes, but for 5 classes they decreased, obtaining results above 80%. Therefore, the system will be more reliable and accurate when 3 classes are used according to some metrics.
It should be noted that the results for the 4 h prediction, both for the 3 and 5 class scenarios, exhibited greater dispersion, which underscores the variability within the cohort; nevertheless, they yielded satisfactory outcomes. The outcomes presented in this article pertain to the entire cohort; however, it is an individualized model, and it is important to acknowledge that some patients achieved better results than others. Therefore, the results are presented in a median and interquartile range format. The prediction results were all below 45 mg/dL for every time frame. Furthermore, a model is proposed for each hour of the day, taking into account daytime, nighttime, and postprandial time frames, which are of particular interest due to the impact of day-to-day variability. We predict not only the mean but also the CV, as within a specific time range, the mean can remain the same while the CV varies. This could pose significant risks in patients with type 1 diabetes. Additionally, predictions have been made for extended prediction horizons (2 and 4 h), which are often challenging to achieve good results. The authors anticipate that this model should be updated and adjusted over time, considering the habits and characteristics of individual patients.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






