
Research on Intelligent Control Method of Launch Vehicle Landing Based on Deep Reinforcement Learning

Abstract
:1. Introduction
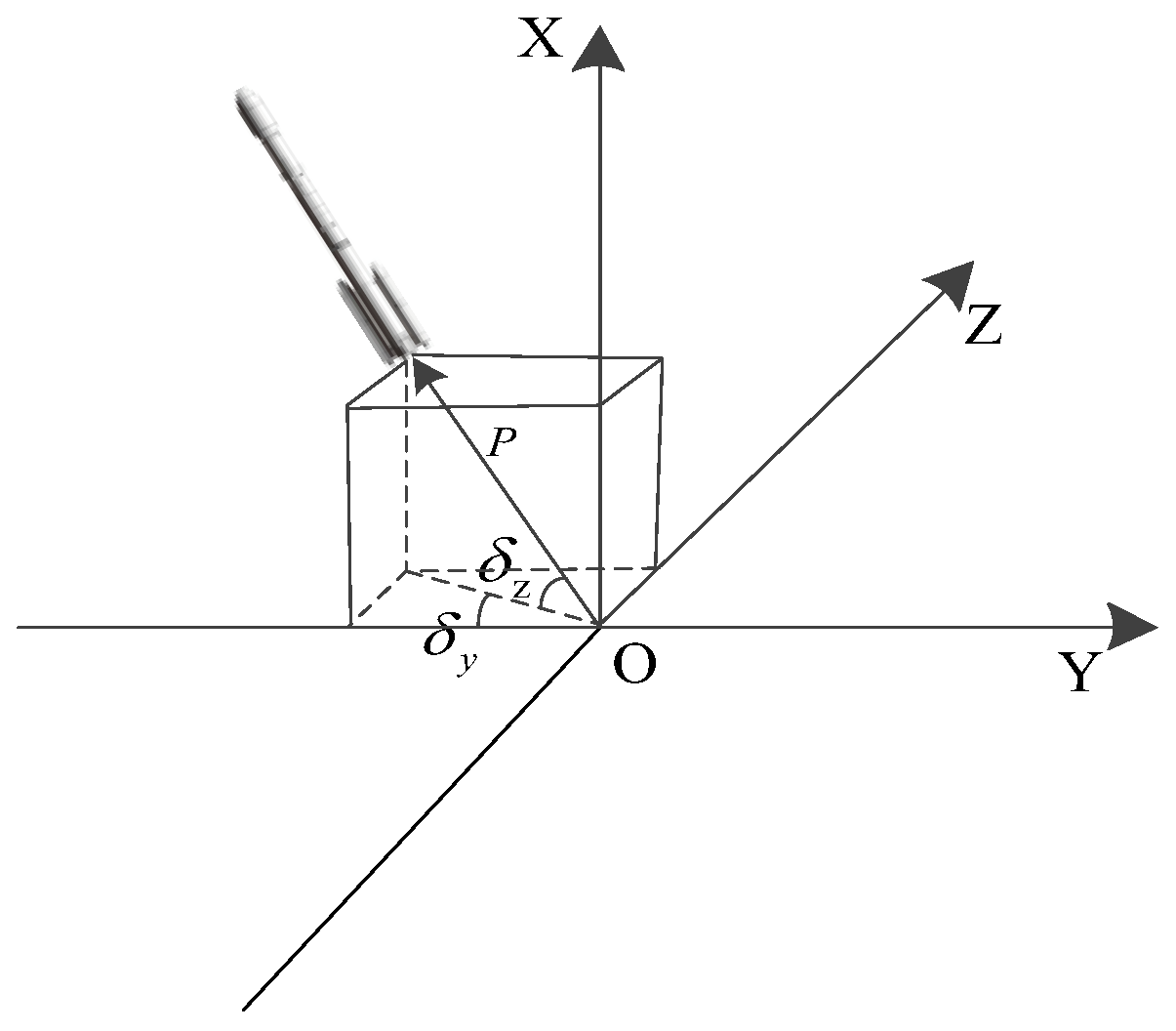
2. Launch Vehicle Landing Model
3. Launch Vehicle Landing Markov Decision Process
3.1. Design of State Space and Action Space
3.2. State Transition Probability
3.3. Reward Function Design
4. Deep Reinforcement Learning Algorithm
4.1. PPO Algorithm
4.2. Improve PPO Algorithm
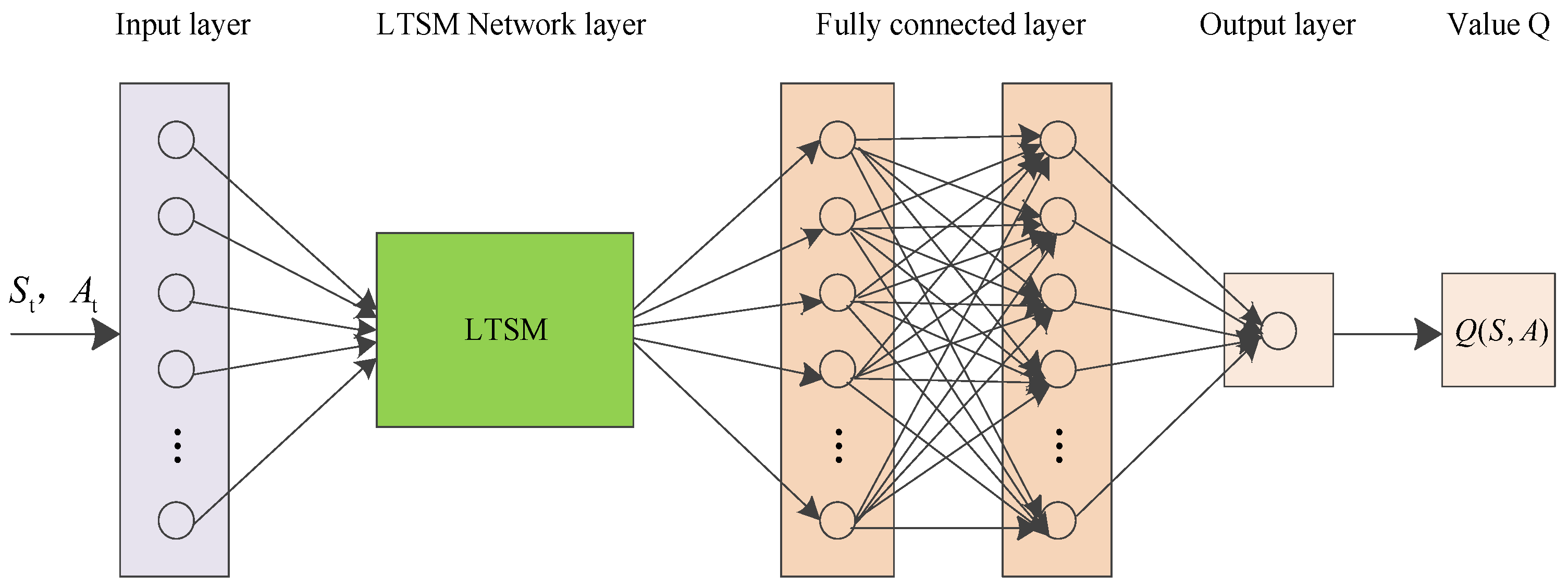
4.2.1. LTSM Network
4.2.2. Imitation Learning
4.2.3. Overall Algorithm Framework
5. Simulation Verification and Analysis
5.1. Simulation Scenario Settings
5.2. Simulation Parameter Settings
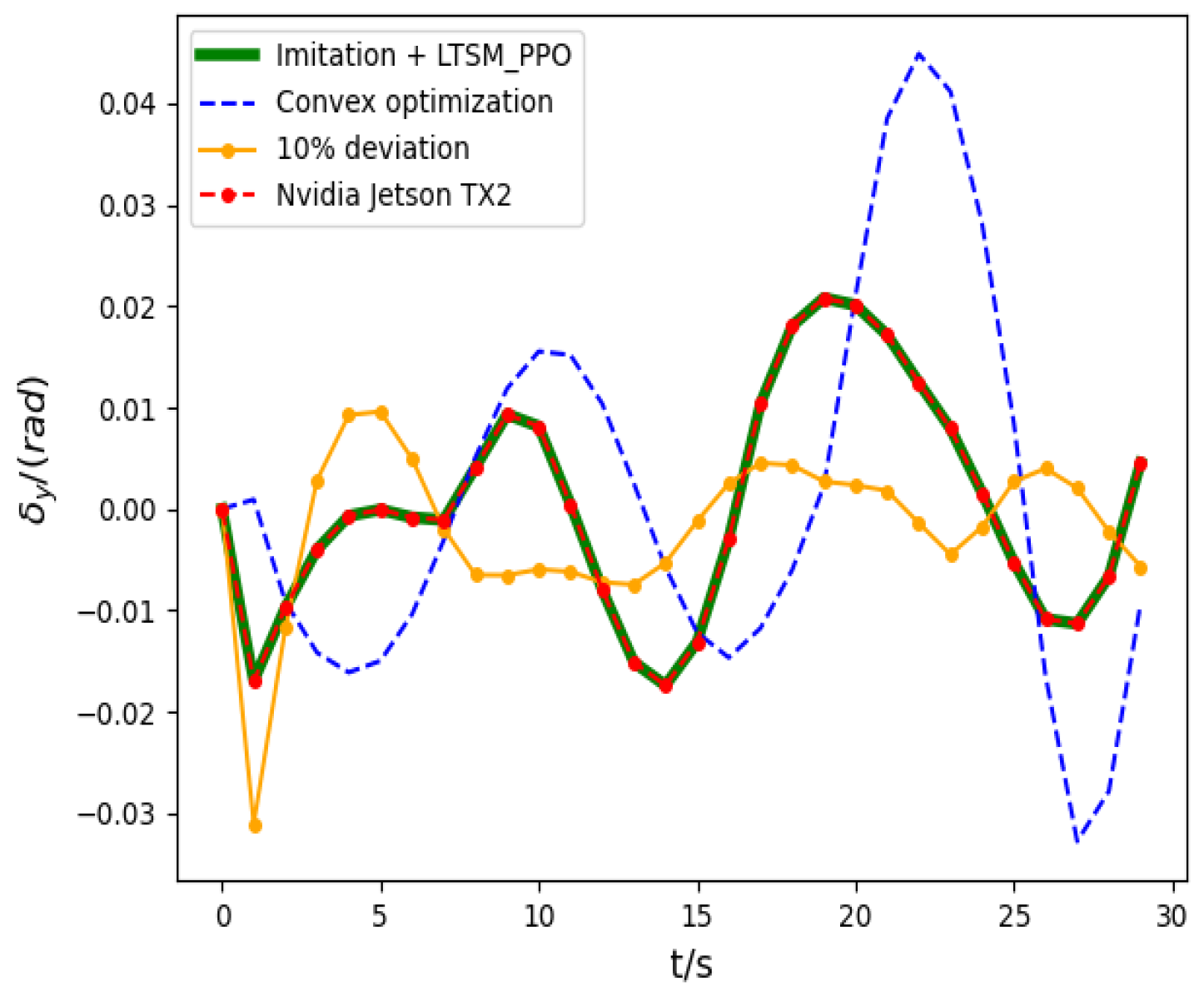
5.3. Analysis of Simulation Results
5.4. Simulation Verification
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, X.F.; Peng, Q.B.; Zhang, H.L. Analysis and reflection on the development history of manned launch vehicles at Home and abroad. Manned Spacefl. 2019, 26, 783–793. [Google Scholar]
- Jo, B.U.; Ahn, J. Optimal staging of reusable launch vehicles for minimum life cycle cost. Aerosp. Sci. Technol. 2022, 127, 107703. [Google Scholar] [CrossRef]
- Jones, H.W. The recent large reduction in space launch cost. In Proceedings of the 48th International Conference on Environmental Systems, Albuquerque, NM, USA, 8–12 July 2018. [Google Scholar]
- Mukundan, V.; Maity, A.; Shashi Ranjan Kumar, S.R.; Rajeev, U.P. Terminal Phase Descent Trajectory Optimization of Reusable Launch Vehicle. IFAC-PapersOnLine 2022, 55, 37–42. [Google Scholar] [CrossRef]
- Song, Z.; Pan, H.; Wang, C.; Gong, Q. Development of flight control technology for Long March launch vehicle. J. Astronaut. 2020, 41, 868–879. [Google Scholar]
- Wei, C.; Ju, X.; He, F.; Pan, H.; Xu, S. Adaptive augmented control of active segment of launch vehicle. J. Astronaut. 2019, 40, 918–927. [Google Scholar]
- Ma, W.; Yu, C.; Lu, K.; Liu, J.; Si, W.; Li, W. Guidance and Control Technology of “Learning” launch vehicle. Aerosp. Control 2019, 38, 3–8. [Google Scholar]
- Zhang, H.P.; Lu, K.F.; Cao, Y.T. Application status and development Prospect of Artificial Intelligence Technology in “Learning” launch vehicle. China Aerosp. 2021, 8–13. [Google Scholar] [CrossRef]
- Hwang, J.; Ahn, J. Integrated Optimal Guidance for Reentry and Landing of a Rocket Using Multi-Phase Pseudo-Spectral Convex Optimization. Int. J. Aeronaut. Space Sci. 2022, 23, 766–774. [Google Scholar] [CrossRef]
- Botelho, A.; Martinez, M.; Recupero, C.; Fabrizi, A.; De Zaiacomo, G. Design of the landing guidance for the retro-propulsive vertical landing of a reusable rocket stage. CEAS Space J. 2022, 14, 551–564. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Vasquez-Jalpa, C.; Nakano-Miyatake, M.; Escamilla-Hernandez, E. A deep reinforcement learning algorithm based on modified Twin delay DDPG method for robotic applications. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; pp. 743–748. [Google Scholar] [CrossRef]
- Duan, J.; Eben Li, S.; Guan, Y.; Sun, Q.; Cheng, B. Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data. IET Intell. Transp. Syst. 2020, 14, 297–305. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Z.-X.; Dong, W.-H.; Wang, X.; Shi, J.; Teng, H.-L.; Dai, X.-W.; Yau, S.S.-T.; Liang, C.-H.; Feng, P.-F.; et al. Microwave integrated circuits design with relational induction neural network. arXiv 2019, arXiv:1901.02069. [Google Scholar]
- He, L.K.; Zhang, R.; Gong, Q.H. Returnable launch vehicle landing guidance based on reinforcement learning. Aerosp. Def. 2019, 4, 33–40. [Google Scholar] [CrossRef]
- Li, B.H.; Wu, Y.J.; Li, G.F. Hierarchical reinforcement learning guidance with threat avoidance. Syst. Eng. Electron. Technol. 2022, 33, 1173–1185. [Google Scholar] [CrossRef]
- Blackmore, L.; Acikmese, B.; Scharf, D.P. Minimum-Landing-Error Powered-Descent Guidance for Mars Landing Using Convex Optimization. J. Guid. Control Dyn. 2010, 33, 1161–1171. [Google Scholar] [CrossRef]
- Guo, J.; Xiang, Y.; Wang, X.; Shi, P.; Tang, S. An online trajectory planning method for rocket vertical recovery based on HP pseudospectral homotopy convex optimization. J. Astronaut. 2022, 43, 603–614. [Google Scholar]
- Wang, X.Y.; Li, Y.F.; Quan, Z.Y.; Wu, J.B. Optimal trajectory-tracking guidance for reusable launch vehicle based on adaptive dynamic programming. Eng. Appl. Artif. Intell. 2023, 117, 105497. [Google Scholar] [CrossRef]
- Ignatyev, D.I.; Shin, H.S.; Tsourdos, A. Sparse online Gaussian process adaptation for incremental backstepping flight control. Aerosp. Sci. Technol. 2023, 136, 108157. [Google Scholar] [CrossRef]
- Simplicio, P.; Marcos, A.; Bennani, S. Reusable Launchers: Development of a Coupled Flight Mechanics, Guidance, and Control Benchmark. J. Spacecr. Rocket. 2019, 57, 74–89. [Google Scholar] [CrossRef]
- Song, Y.; Zhang, W.; Miao, X.Y.; Zhang, Z.; Gong, S. Online guidance algorithm for the landing phase of recoverable rocket power. J. Tsinghua Univ. 2021, 61, 230–239. [Google Scholar]
- Zhang, Y.; Huang, C.; Li, X.F. Online Attitude Adjustment Planning Method for Long March 5 Launch Vehicle. Missile Space Launch Technol. 2021, 3, 22–25. [Google Scholar]
- Howard, M. Multi-Agent Machine Learning: A Reinforcement Approach; China Machine Press: Beijing, China, 2017. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Gallego, V.; Naveiro, R.; Insua, D.R. Reinforcement learning under threats. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 9939–9940. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.Y.; Huang, S.J. Behavioral cloning method based on demonstrative active sampling. J. Nanjing Univ. Aeronaut. Astronaut. 2021, 53, 766–771. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rocket Parameter | Value |
|---|---|
| Length | 40 m |
| Diameter | 3.66 m |
| Quality | 50 t |
| Specific impulse | 360 s |
| Atmospheric density | |
| Acceleration of gravity | |
| Aerodynamic drag coefficient | 0.82 |
| Initial position (x, y, z) | (2000 m, −1600 m, 50 m) |
| Initial velocity (vx, vy, vz) | (−90 m/s, 180 m/s, 0) |
| Landing site location (x, y, z) | (0, 0, 0) |
| Attitude angle limitation during landing | |
| Terminal position constraint | r ≤ 20.0 m |
| Terminal velocity constraint | v ≤ 10 m/s |
| Terminal attitude deviation constraint |
| Parameter | Value |
|---|---|
| PPO algorithm learning rate | 0.0003 |
| BC algorithm learning rate | 0.0003 |
| Maximum number of training steps | 2048 |
| Training lot size | 64 |
| Reward discount rate | 0.99 |
| Estimate the clipping coefficient of the advantage function | 0.2 |
| Generalized dominance estimation parameters | 0.95 |
| Name | Terminal Position Accuracy/(m) | Terminal Speed Accuracy/(m/s) | Fuel Consumption/(kg) | Calculation Speed/(ms) | |
|---|---|---|---|---|---|
| Imitation + LTSM_PPO | 8.4 | 4.9 | (−1.6, −0.9, 0.009) | 3820.0 | 2.5 |
| Convex optimization | 11.9 | 12.9 | (−1, 0.25, 0.003) | 3970.4 | 243 |
| 10% deviation | 10.0 | 7.5 | (−1.5, 0.25, 0.008) | 3827.1 | 7.4 |
| Nvidia Jetson TX2 | 8.4 | 4.9 | (−1.6, −0.9, 0.009) | 3820.0 | 9.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, S.; Bai, H.; Zhao, D.; Zhou, J. Research on Intelligent Control Method of Launch Vehicle Landing Based on Deep Reinforcement Learning. Mathematics 2023, 11, 4276. https://doi.org/10.3390/math11204276
Xue S, Bai H, Zhao D, Zhou J. Research on Intelligent Control Method of Launch Vehicle Landing Based on Deep Reinforcement Learning. Mathematics. 2023; 11(20):4276. https://doi.org/10.3390/math11204276
Chicago/Turabian StyleXue, Shuai, Hongyang Bai, Daxiang Zhao, and Junyan Zhou. 2023. "Research on Intelligent Control Method of Launch Vehicle Landing Based on Deep Reinforcement Learning" Mathematics 11, no. 20: 4276. https://doi.org/10.3390/math11204276