
Efficient Associate Rules Mining Based on Topology for Items of Transactional Data
Abstract
:1. Introduction
- Netconfidence [7]: ;
- Conviction [8]: ;
- Added value [9]: ;
- Accuracy [9]: ;
- Interestingness [10]: ;
- Comprehensibility [10]: ;
- Lift [11]: .
2. Preliminaries
- 1 .
- is a topology for A;
- 2 .
- For any , ;
- 3 .
- is a base for the topology .
3. Lattice Structures on the Topology for the Set of Items
3.1. The Lattice on the Topology
3.2. The Lattice on the Quotient Set of the Topology
4. Association Rules Mining from the Quotient Set of the Topology
- 1.
- The topology for the set of items is a complete lattice and displays a hierarchical structure on some itemsets, it can be generated by the base ; generally, each is an itemset and can more fast generate closed itemsets than single items in the existed methods;
- 2.
- All closed itemsets are included in the topology , moreover, a closed itemset is the maximum element of an equivalent class ;
- 3.
- Each itemsets in has the same support; moreover, generators and minimal generators of a closed itemset can be obtained from ;
- 4.
- The complete lattice displays the hierarchical structures on closed itemsets.
- 1.
- The lower approximation of :
- 2.
- The upper approximation of :
4.1. Min-Max Association Rules Mining
| Algorithm 1 Min-Max association rules mining from closed itemsets |
|
| Algorithm 2: Min-Max association rules mining from a fixed itemset |
|
- 1.
- Min-Max association rules are always mined from closed itemsets, in this paper, we prove that closed itemsets are maximum elements of equivalent classes, i.e., equivalent classes can be used to mine Min-Max association rules with confidence 1;
- 2.
- The shortest length antecedents of Min-Max association rules are searched from minimal members of equivalent classes, i.e., and ; in this paper, searching minimal generators are in smaller scope than in all subsets of closed itemsets;
- 3.
- Lower approximations and their minimal generators help us to fast mine Min-Max association rules from a fixed itemset.
4.2. Generalized Association Rules Based on the Lower Approximation
- 1.
- Generalized antecedent association rule (GAR): ;
- 2.
- Generalized conclusion association rule (GCR): ;
- 3.
- Generalized antecedent and conclusion association rule (GACR): .
- 1 .
- ;
- 2 .
- ;
- 3 .
- If , then ;
- 4 .
- If , then .
- 1.
- Redundant association rule of GAR: ;
- 2.
- Redundant association rule of GCR: ;
- 3.
- Redundant association rule of GACR: .
| Algorithm 3: Mining generalized association rules and redundant association rules based on the lower approximation |
|
4.3. Generalized Association Rules Based on the Upper Approximation
- 1.
- Generalized antecedent association rule (gar): ;
- 2.
- Generalized conclusion association rule (gcr): ;
- 3.
- Generalized antecedent and conclusion association rule (gacr): .
- 1 .
- ;
- 2 .
- 3 .
- If , then ;
- 4 .
- If , then .
- 1.
- Redundant association rule of gar: ;
- 2.
- Redundant association rule of gcr: ;
- 3.
- Redundant association rule of gacr: .
| Algorithm 4 Mining generalized association rules and redundant association rules based on the upper approximation |
|
5. Example Analysis
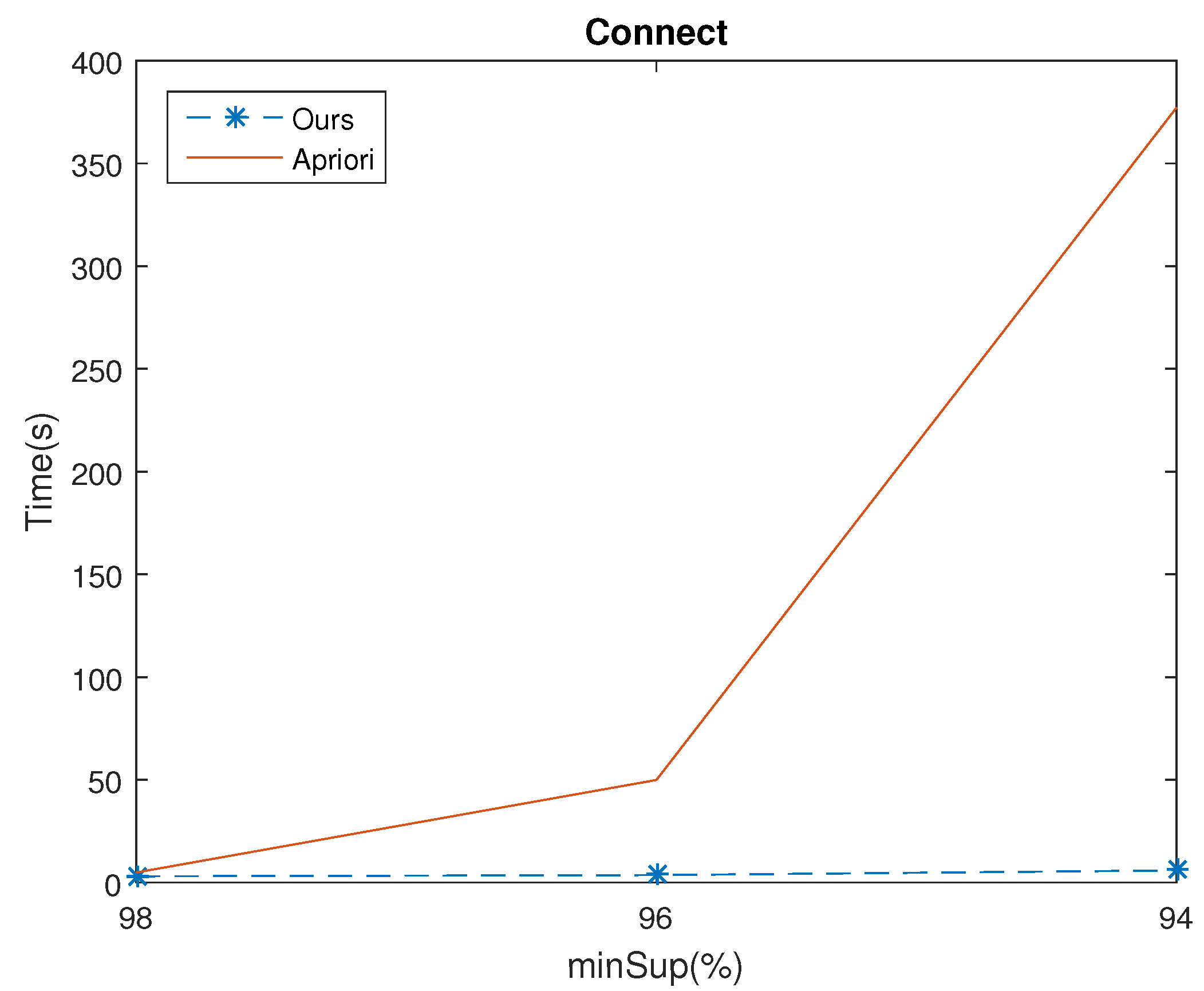
5.1. The Execution Time
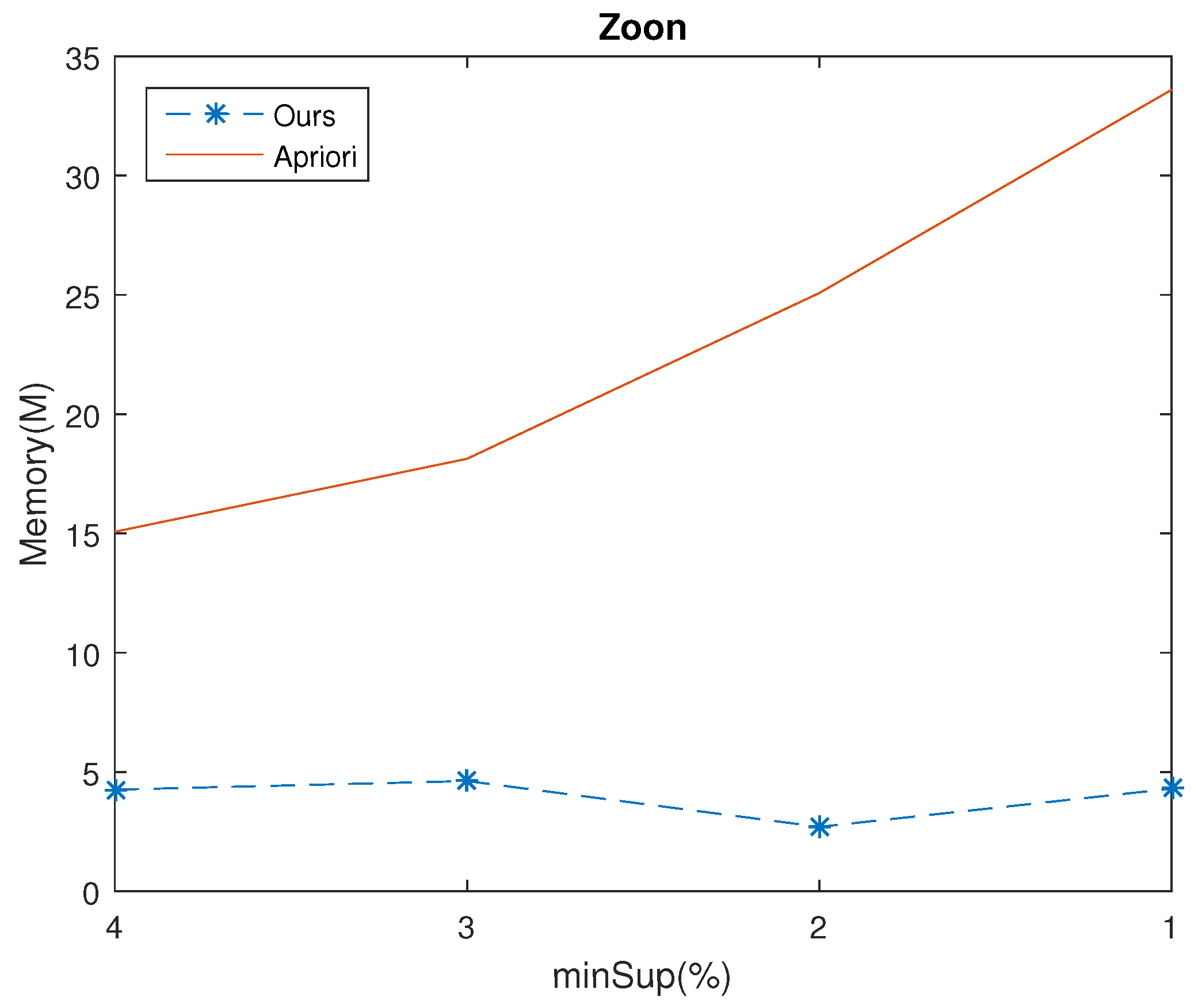
5.2. The Memory Usage
5.3. Numbers of Rules
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | |||||
|---|---|---|---|---|---|
| Basis | |||||
| Attributes | |||||
| Basis | |||||
| Attributes | |||||
| Basis |
| c | 0 | |||
|---|---|---|---|---|
| Members of topology | 4159 | 98 | 54 | 11 |
| Equivalent classes | 237 | 75 | 44 | 11 |
| Equivalent Classes | |||
|---|---|---|---|
| 2 | |||
| 2 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 2 | |||
| 1 | |||
| 2 | |||
| 3 | |||
| 2 | , | ||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 1 | |||
| 2 | |||
| 1 | |||
| 2 | |||
| 2 |
| Numbers | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 |
| Numbers | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 |


| N | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 |
| Numbers | Rule |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 | |
| 7 | |
| 8 | |
| 9 | |
| 10 | |
| 11 | |
| 12 | |
| 13 | |
| 14 | |
| 15 | |
| 16 | |
| 17 | |
| 18 | |
| 19 | |
| 20 | |
| 21 | |
| 22 | |
| 23 | |
| 24 | |
| 25 | |
| 26 | |
| 27 | |
| 28 | |
| 29 | |
| 30 | |
| 31 | |
| 32 | |
| 33 | |
| 34 | |
| 35 | |
| 36 | |
| 37 | |
| 38 | |
| 39 | |
| 40 | |
| 41 |
| Min-Max () | Reliable () | N-Min-Max () | |||
|---|---|---|---|---|---|
| 0.4 | 2528 | (465, 0.82) | (361, 0.86) | 1825 | (420, 0.77) |
| 0.5 | 835 | (175, 0.79) | (135, 0.84) | 514 | (190, 0.63) |
| 0.6 | 228 | (59, 0.74) | (52, 0.77) | 136 | (65, 0.52) |
| 0.7 | 161 | (39, 0.74) | (34, 0.79) | 90 | (41, 0.54) |
| Average | 0.77 | 0.82 | 0.62 |
| Min-Max () | Reliable () | N-Min-Max () | |||
|---|---|---|---|---|---|
| 0.94 | 199,560 | (49,407, 0.75) | (10,220, 0.95) | 88,116 | () |
| 0.95 | 77,206 | (24,794, 0.68) | (5245, 0.93) | 39,768 | (4731, 0.88) |
| 0.96 | 26,856 | (11,452, 0.57) | (2538, 0.91) | 16,356 | (2535, 0.85) |
| 0.97 | 7895 | (4439, 0.44) | (1214, 0.85) | 5690 | (1294, 0.77) |
| Average | 0.61 | 0.91 | 0.85 |
| Template 1 | |
|---|---|
| Reduction of | |
| Rule 1 | |
| Min-Max () | Reliable () | N-Min-Max () | |||
|---|---|---|---|---|---|
| 0.90 | 10,614 | (8371, 0.21) | (2483, 0.77) | 9230 | () |
| 0.91 | 5785 | (5050, 0.13) | (1571, 0.73) | 5354 | (1357, 0.75) |
| 0.93 | 2338 | (1948, 0.17) | (688, 0.71) | 2110 | (648, 0.69) |
| 0.95 | 468 | (459, 0.02) | (196, 0.58) | 466 | (195, 0.58) |
| Average | 0.13 | 0.70 | 0.70 |
| Template 1 | |
|---|---|
| Rule 1 | |
References
- Agrawal, R.; Imieliński, T.; Swami, A. Mining Association Rules between Sets of Items in Large Databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; Association for Computing Machinery: New York, NY, USA, 1993; pp. 207–216. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1994; pp. 487–499. [Google Scholar]
- Thamer, M.B.; El-Sappagh, S.; El-Shishtawy, T. A Semantic Approach for Extracting Medical Association Rules. Int. J. Intell. Eng. Syst. 2020, 13, 280–292. [Google Scholar] [CrossRef]
- Razzak, M.I.; Imran, M.; Xu, G. Big data analytics for preventive medicine. Neural Comput. Appl. 2020, 32, 4417–4451. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.N.; Dwivedi, A.D. Precise Marketing Data Mining Method of E-Commerce Platform Based on Association Rules. Mob. Netw. Appl. 2022. [Google Scholar] [CrossRef]
- Reddy, R.V.; Venkateswara Rao, K.; Kameswara Rao, M.; Deepak Kumar, B.P. A Review on Stock Market Analysis Using Association Rule Mining. In Cybernetics, Cognition and Machine Learning Applications; Gunjan, V.K., Suganthan, P.N., Haase, J., Kumar, A., Eds.; Springer Nature Singapore: Singapore, 2023; pp. 171–183. [Google Scholar]
- Ahn, K.I.; Kim, J.Y. Efficient Mining of Frequent Itemsets and a Measure of Interest for Association Rule Mining. J. Inf. Knowl. Manag. 2004, 3, 245–257. [Google Scholar] [CrossRef]
- Brin, S.; Motwani, R.; Ullman, J.D.; Tsur, S. Dynamic itemset counting and implication rules for market basket data. In Proceedings of the 1997 ACM SIGMOD International Conference on Management of Data, Tucson, AZ, USA, 13–15 May 1997; ACM: New York, NY, USA, 1997; pp. 255–264. [Google Scholar]
- Geng, L.; Hamilton, H.J. Interestingness measures for data mining: A survey. ACM Comput. Surv. 2006, 38, 9. [Google Scholar] [CrossRef]
- Ghosh, A.; Nath, B. Multi-objective rule mining using genetic algorithms. Inf. Sci. 2004, 163, 123–133. [Google Scholar] [CrossRef]
- Silverstein, C.; Brin, S.; Motwani, R. Beyond market baskets: Generalizing association rules to dependence rules. Data Min. Knowl. Discov. 1998, 2, 39–68. [Google Scholar] [CrossRef]
- Baralis, E.; Cagliero, L.; Cerquitelli, T.; Garza, P. Generalized association rule mining with constraints. Inf. Sci. 2012, 194, 68–84. [Google Scholar] [CrossRef] [Green Version]
- Beiranvand, V.; Mobasher-Kashani, M.; Bakar, A.A. Multi-objective PSO algorithm for mining numerical association rules without a priori discretization. Expert Syst. Appl. 2014, 41, 4259–4273. [Google Scholar] [CrossRef]
- Guil, F.; Marín, R. A Theory of Evidence-based method for assessing frequent patterns. Expert Syst. Appl. 2013, 40, 3121–3127. [Google Scholar] [CrossRef]
- Guns, T.; Nijssen, S.; De Raedt, L. Itemset Mining: A Constraint Programming Perspective. Artif. Intell. 2011, 175, 1951–1983. [Google Scholar] [CrossRef] [Green Version]
- Ji, Y.; Ying, H.; Tran, J.; Dews, P.; Mansour, A.; Massanari, R.M. A Method for Mining Infrequent Causal Associations and Its Application in Finding Adverse Drug Reaction Signal Pairs. IEEE Trans. Knowl. Data Eng. 2013, 25, 721–733. [Google Scholar] [CrossRef] [Green Version]
- Kuo, R.J.; Chao, C.M.; Chiu, Y.T. Application of particle swarm optimization to association rule mining. Appl. Soft Comput. 2011, 11, 326–336. [Google Scholar] [CrossRef]
- Luna, J.M.; Romero, J.R.; Ventura, S. Grammar-based multi-objective algorithms for mining association rules. Data Knowl. Eng. 2013, 86, 19–37. [Google Scholar] [CrossRef]
- Rodríguez, D.M.; Rosete, A.; Alcalá-Fdez, J.; Herrera, F. QAR-CIP-NSGA-II: A new multi-objective evolutionary algorithm to mine quantitative association rules. Inf. Sci. 2014, 258, 1–28. [Google Scholar]
- Martínez-Ballesteros, M.; Martínez-Álvarez, F.; Lora, A.T.; Riquelme, J.C. Selecting the best measures to discover quantitative association rules. Neurocomputing 2014, 126, 3–14. [Google Scholar] [CrossRef]
- Pei, Z. Extracting association rules based on intuitionistic fuzzy special sets. In Proceedings of the FUZZ-IEEE, Hong Kong, China, 1–6 June 2008; pp. 873–878. [Google Scholar]
- Shaharanee, I.N.M.; Hadzic, F.; Dillon, T.S. Interestingness measures for association rules based on statistical validity. Knowl. Based Syst. 2011, 24, 386–392. [Google Scholar] [CrossRef]
- Kaushik, M.; Sharma, R.; Peious, S.A.; Shahin, M.; Yahia, S.B.; Draheim, D. A Systematic Assessment of Numerical Association Rule Mining Methods. SN Comput. Sci. 2021, 2, 348. [Google Scholar] [CrossRef]
- Kuo, R.J.; Gosumolo, M.; Zulvia, F.E. Multi-objective particle swarm optimization algorithm using adaptive archive grid for numerical association rule mining. Neural Comput. Appl. 2019, 31, 3559–3572. [Google Scholar] [CrossRef]
- Wang, H.B.; Gao, Y.J. Research on parallelization of Apriori algorithm in association rule mining. Procedia Comput. Sci. 2021, 183, 641–647. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J. In-Memory Data Anonymization Using Scalable and High Performance RDD Design. Electronics 2020, 9, 1732. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J.; Alavizadeh, H. A Novel Hybrid Approach for Multi-Dimensional Data Anonymization for Apache Spark. ACM Trans. Priv. Secur. 2021, 25, 1–25. [Google Scholar] [CrossRef]
- Bazai, S.U.; Jang-Jaccard, J.; Alavizadeh, H. Scalable, High-Performance, and Generalized Subtree Data Anonymization Approach for Apache Spark. Electronics 2021, 10, 589. [Google Scholar] [CrossRef]
- Calders, T.; Dexters, N.; Gillis, J.J.M.; Goethals, B. Mining frequent itemsets in a stream. Inf. Syst. 2014, 39, 233–255. [Google Scholar] [CrossRef]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: Current status and future directions. Data Min. Knowl. Discov. 2007, 15, 55–86. [Google Scholar] [CrossRef] [Green Version]
- Pei, J.; Han, J.; Mao, R. CLOSET: An Efficient Algorithm for Mining Frequent Closed Itemsets. In Proceedings of the ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, Dallas, TX, USA, 14 May 2000; pp. 21–30. [Google Scholar]
- Wang, J.; Han, J.; Pei, J. CLOSET+: Searching for the best strategies for mining frequent closed itemsets. In Proceedings of the KDD, Washington, DC, USA, 24–27 August 2003; Getoor, L., Senator, T.E., Domingos, P.M., Faloutsos, C., Eds.; ACM: New York, NY, USA, 2003; pp. 236–245. [Google Scholar]
- O’Sullivan, D.; Smyth, B.; Wilson, D.C.; McDonald, K.; Smeaton, A. Improving the Quality of the Personalized Electronic Program Guide. User Model. User-Adapt. Interact. 2004, 14, 5–36. [Google Scholar] [CrossRef] [Green Version]
- Kryszkiewicz, M.; Rybinski, H.; Gajek, M. Dataless Transitions Between Concise Representations of Frequent Patterns. J. Intell. Inf. Syst. 2004, 22, 41–70. [Google Scholar] [CrossRef]
- Pasquier, N.; Bastide, Y.; Taouil, R.; Lakhal, L. Efficient mining of association rules using closed itemset lattices. Inf. Syst. 1999, 24, 25–46. [Google Scholar] [CrossRef]
- Zaki, M.J. Scalable algorithms for association mining. IEEE Trans. Knowl. Data Eng. 2000, 12, 372–390. [Google Scholar] [CrossRef] [Green Version]
- Zaki, M.J.; Hsaio, C.J. Efficient Algorithms for Mining Closed Itemsets and Their Lattice Structure. IEEE Trans. Knowl. Data Eng. 2005, 17, 462–478. [Google Scholar] [CrossRef]
- Hashem, T.; Ahmed, C.F.; Samiullah, M.; Akther, S.; Jeong, B.S.; Jeon, S. An efficient approach for mining cross-level closed itemsets and minimal association rules using closed itemset lattices. Expert Syst. Appl. 2014, 41, 2914–2938. [Google Scholar] [CrossRef]
- Liu, H.; Liu, L.; Zhang, H. A fast pruning redundant rule method using Galois connection. Appl. Soft Comput. 2011, 11, 130–137. [Google Scholar] [CrossRef]
- Cagliero, L.; Cerquitelli, T.; Garza, P.; Grimaudo, L. Misleading Generalized Itemset discovery. Expert Syst. Appl. 2014, 41, 1400–1410. [Google Scholar] [CrossRef] [Green Version]
- Cagliero, L.; Garza, P. Itemset generalization with cardinality-based constraints. Inf. Sci. 2013, 244, 161–174. [Google Scholar] [CrossRef] [Green Version]
- Baralis, E.; Cagliero, L.; Cerquitelli, T.; D’Elia, V.; Garza, P. Expressive generalized itemsets. Inf. Sci. 2014, 278, 327–343. [Google Scholar] [CrossRef] [Green Version]
- Boulicaut, J.F.; Bykowski, A.; Rigotti, C. Free-sets: A condensed representation of boolean data for the approximation of frequency queries. Data Min. Knowl. Discov. 2003, 7, 5–22. [Google Scholar] [CrossRef]
- Bykowski, A.; Rigotti, C. DBC: A condensed representation of frequent patterns for efficient mining. Inf. Syst. 2003, 28, 949–977. [Google Scholar] [CrossRef] [Green Version]
- Chiang, D.A.; Wang, Y.F.; Wang, Y.H.; Chen, Z.Y.; Hsu, M.H. Mining disjunctive consequent association rules. Appl. Soft Comput. 2011, 11, 2129–2133. [Google Scholar] [CrossRef]
- Calders, T.; Goethals, B. Non-derivable itemset mining. Data Min. Knowl. Discov. 2007, 14, 171–206. [Google Scholar] [CrossRef] [Green Version]
- Li, H.; Chen, H. Mining non-derivable frequent itemsets over data stream. Data Knowl. Eng. 2009, 68, 481–498. [Google Scholar] [CrossRef]
- Hamrouni, T.; Yahia, S.B.; Nguifo, E.M. Sweeping the disjunctive search space towards mining new exact concise representations of frequent itemsets. Data Knowl. Eng. 2009, 68, 1091–1111. [Google Scholar] [CrossRef]
- Barrenechea, E.; Sola, H.B.; Campión, M.J.; Induráin, E.; Knoblauch, V. Topological interpretations of fuzzy subsets. A unified approach for fuzzy thresholding algorithms. Knowl. Based Syst. 2013, 54, 163–171. [Google Scholar] [CrossRef]
- Syau, Y.R.; Lin, E.B. Neighborhood systems and covering approximation spaces. Knowl. Based Syst. 2014, 66, 61–67. [Google Scholar] [CrossRef]
- Wang, S.; Liu, D. Knowledge representation and reasoning for qualitative spatial change. Knowl. Based Syst. 2012, 30, 161–171. [Google Scholar] [CrossRef]
- Pei, Z.; Ruan, D.; Meng, D.; Liu, Z. Formal concept analysis based on the topology for attributes of a formal context. Inf. Sci. 2013, 236, 66–82. [Google Scholar] [CrossRef]
- Zhang, Y.; Pei, Z.; Shi, P. Association rule mining based on topology for attributes of multi-valued information systems. Int. J. Innov. Comput. Inf. Control. Ijicic 2013, 9, 1679–1690. [Google Scholar]
- Ganter, B.; Wille, R. Formal Concept Analysis: Mathematical Foundations; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Pawlak, Z.; Skowron, A. Rough sets and Boolean reasoning. Inf. Sci. 2007, 177, 41–73. [Google Scholar] [CrossRef] [Green Version]
- Qin, K.; Yang, J.; Pei, Z. Generalized rough sets based on reflexive and transitive relations. Inf. Sci. 2008, 178, 4138–4141. [Google Scholar] [CrossRef]
- Zhang, H.P.; Ouyang, Y.; Wang, Z. Note on “Generalized rough sets based on reflexive and transitive relations”. Inf. Sci. 2009, 179, 471–473. [Google Scholar] [CrossRef]
- Freund, M. On the notion of concept I. Artif. Intell. 2008, 172, 570–590. [Google Scholar] [CrossRef]
- Srikant, R.; Agrawal, R. Mining Generalized Association Rules. In Proceedings of the 21st International Conference on Very Large Databases, Zurich, Switzerland, 11–15 September 1995; pp. 407–419. [Google Scholar]
- Wu, C.M.; Huang, Y.F. Generalized association rule mining using an efficient data structure. Expert Syst. Appl. 2011, 38, 7277–7290. [Google Scholar] [CrossRef]
- Apriori Algorithm. Available online: http://www.mathworks.com/matlabcentral/fileexchange/42541-association-rules/ (accessed on 1 September 2022).
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/ (accessed on 1 September 2022).
- Xu, Y.; Li, Y.; Shaw, G. Reliable representations for association rules. Data Knowl. Eng. 2011, 70, 555–575. [Google Scholar] [CrossRef]











| 1 | 0 | 0 | 0 | 1 | |
| 1 | 0 | 1 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 1 | |
| 0 | 1 | 1 | 0 | 0 | |
| 1 | 1 | 1 | 1 | 1 | |
| 0 | 0 | 1 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 1 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | |
| 0 | 0 | 1 | 1 | 1 | |
| 0 | 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 1 | |
| 0 | 0 | 1 | 1 | 0 | |
| 0 | 1 | 0 | 0 | 1 | |
| 1 | 0 | 1 | 0 | 1 | |
| 0 | 0 | 1 | 1 | 0 | |
| 1 | 1 | 1 | 0 | 1 | |
| 1 | 0 | 1 | 1 | 1 | |
| 1 | 1 | 0 | 0 | 1 | |
| 1 | 0 | 0 | 0 | 1 | |
| 0 | 0 | 1 | 1 | 0 |
| 1 | 0 | 0 | 0 | 1 | |
| 0 | 1 | 0 | 0 | 1 | |
| 0 | 0 | 1 | 0 | 0 | |
| 0 | 0 | 1 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 1 |
| Equivalent Class | |||
|---|---|---|---|
| Min-Max Association Rule | (Support, Confidence) |
|---|---|
| Itemsets | Lower Approximations | The Set of Equivalent Classes |
|---|---|---|
| Itemsets | Min-Max Association Rules | (Support, Confidence) |
|---|---|---|
| Dataset | Transactions | Original Attributes | Attributes after Conversion |
|---|---|---|---|
| Zoo | 101 | 17 | 15 |
| Mushroom | 8124 | 23 | 126 |
| Connect-4 | 67,557 | 43 | 129 |
| Chess | 3196 | 36 | 108 |
| Dataset | Number of Rules | ||
|---|---|---|---|
| Apriori | Ours | ||
| Chess | 95 | 472 | 700 |
| 90 | 10,742 | 9482 | |
| 85 | 95,482 | 43,116 | |
| 80 | 552,564 | 111,768 | |
| 75 | 2,336,556 | 253,836 | |
| Mushroom | 50 | 1146 | 172 |
| 45 | 2704 | 291 | |
| 40 | 5006 | 483 | |
| 35 | 14,107 | 903 | |
| 30 | 45,145 | 903 | |
| Connect | 98 | 1544 | 380 |
| 96 | 27,340 | 1480 | |
| 94 | 201,928 | 3848 | |
| Zoon | 4 | 29,288 | 8136 |
| 3 | 35,204 | 8826 | |
| 2 | 48,578 | 5110 | |
| 1 | 64,868 | 8174 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Pei, Z.; Zhang, C.; Hao, F. Efficient Associate Rules Mining Based on Topology for Items of Transactional Data. Mathematics 2023, 11, 401. https://doi.org/10.3390/math11020401
Li B, Pei Z, Zhang C, Hao F. Efficient Associate Rules Mining Based on Topology for Items of Transactional Data. Mathematics. 2023; 11(2):401. https://doi.org/10.3390/math11020401
Chicago/Turabian StyleLi, Bo, Zheng Pei, Chao Zhang, and Fei Hao. 2023. "Efficient Associate Rules Mining Based on Topology for Items of Transactional Data" Mathematics 11, no. 2: 401. https://doi.org/10.3390/math11020401