
Feature Map Regularized CycleGAN for Domain Transfer

Abstract
:1. Introduction
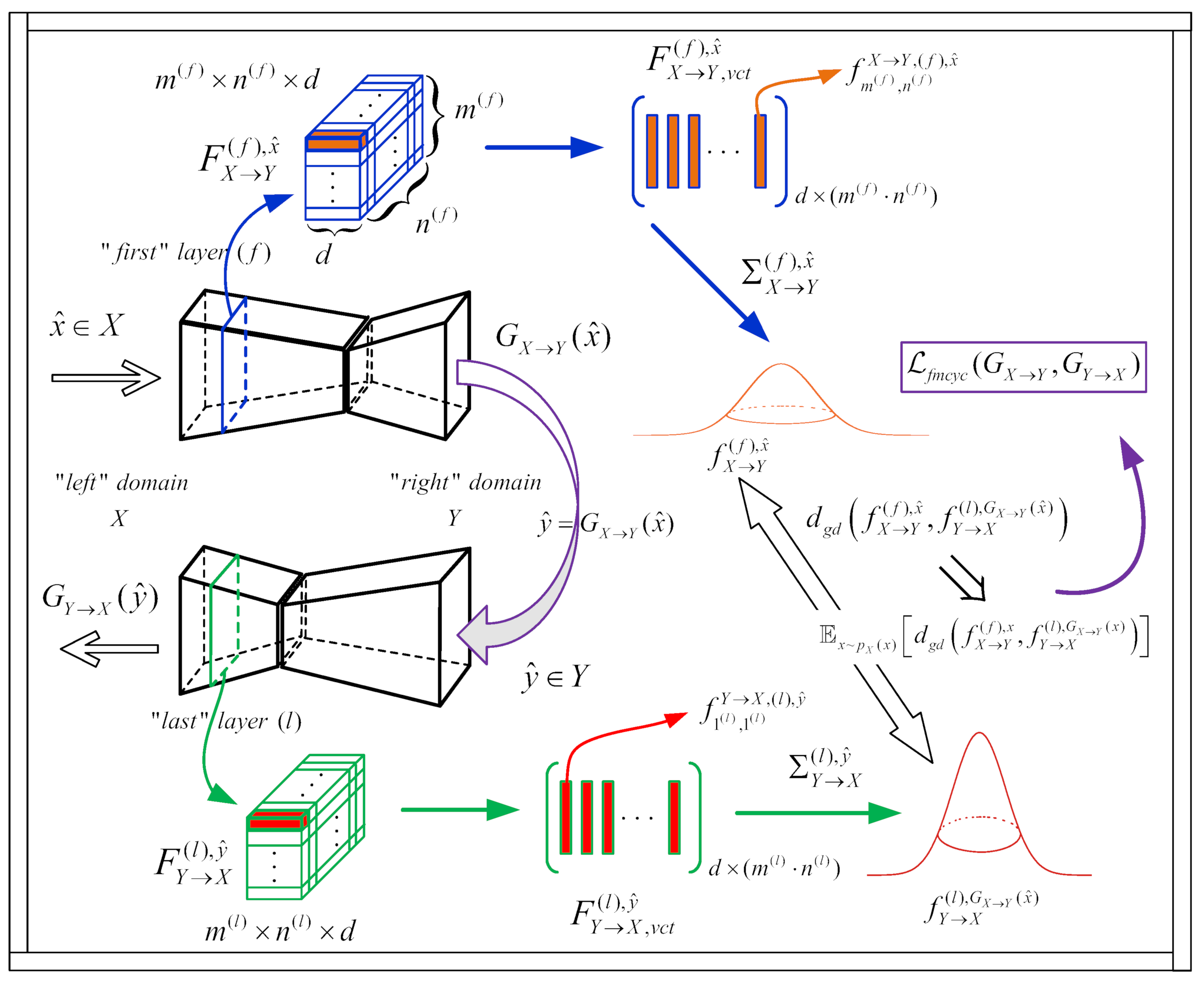
- We impose an additional feature-map-based cycle consistency loss to the overall optimization objective by introducing similarity measures between probability density functions (PDFs) modelling the statistics of the feature maps corresponding to “left” to “right” and “right” to “left” convolutional neural network (CNN) GANs where feature maps belong to the same level, i.e., a layer in the CycleGAN network architecture. Thus, an additional cycle consistency type of penalty term in the form of a similarity measure between PDFs is introduced in the overall cost function. Namely, we compare the distributions built upon the feature maps in the first network layer of the “left” to “right” GAN generator (its encoder) and the feature maps in the last network layer of the “right” to “left” GAN generator (its decoder) in order to achieve the transfer between the two domains that would be closer to bijective mapping.
- We apply various statistics-based measures and Riemannian-metrics, i.e., geodesic ground distance measures between the mentioned PDFs, where we impose the assumption that the PDFs are of the Gaussian type. As there exists an embedding of Gaussians into the cone, i.e., the Riemannian manifold of the symmetric positive definite (SPD) matrices, it is possible to apply various ground distance measures between the mentioned SPD matrices. A chosen ground distance is then minimized as the term in the overall network cost function during the training phase.
2. Materials and Methods
2.1. Related Works
2.2. Baseline CycleGAN Approach
2.3. Ground Distances
2.4. Proposed FMR CycleGAN Approach
3. Results and Discussion
3.1. Network Architecture
3.2. Evaluation Metrics
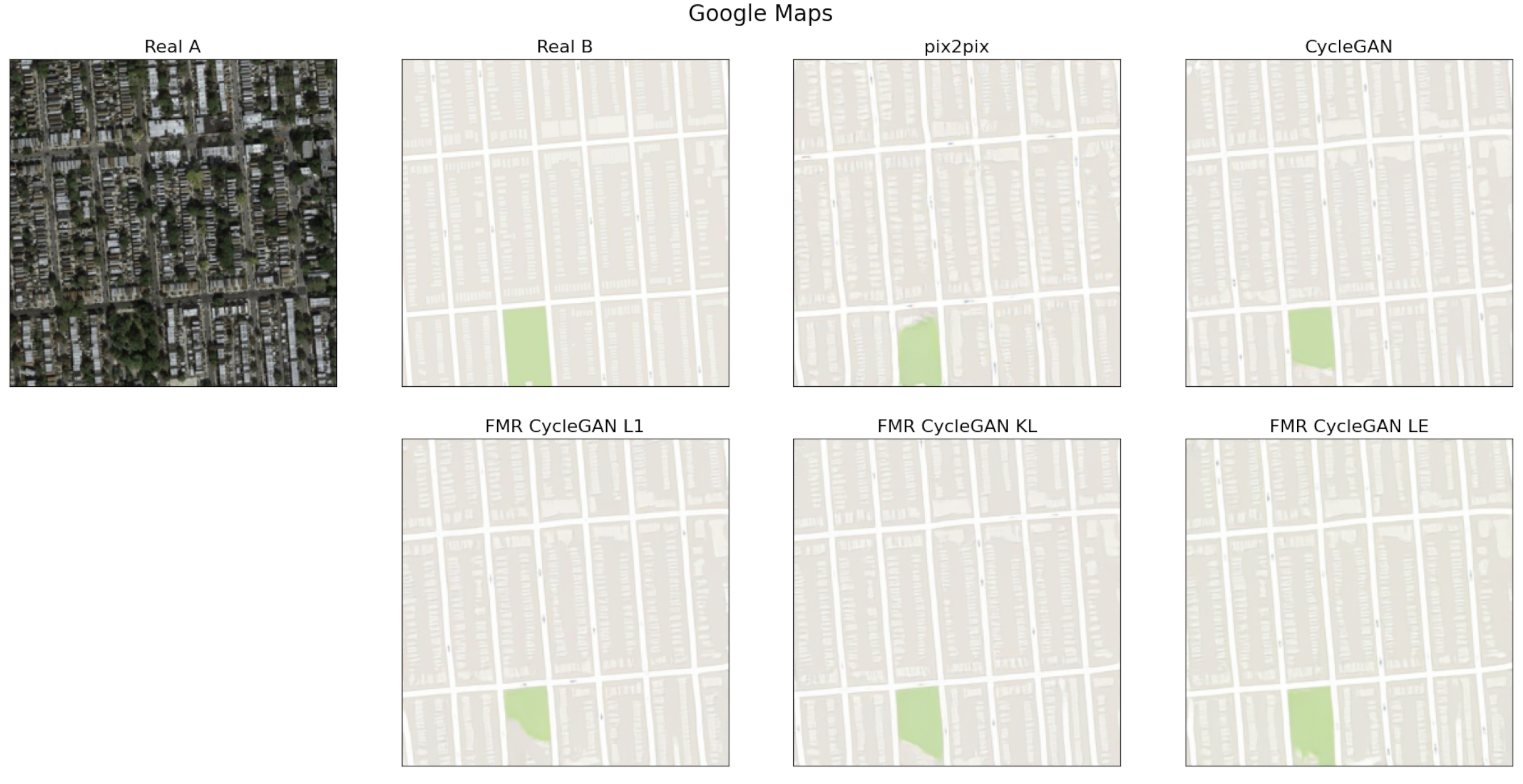
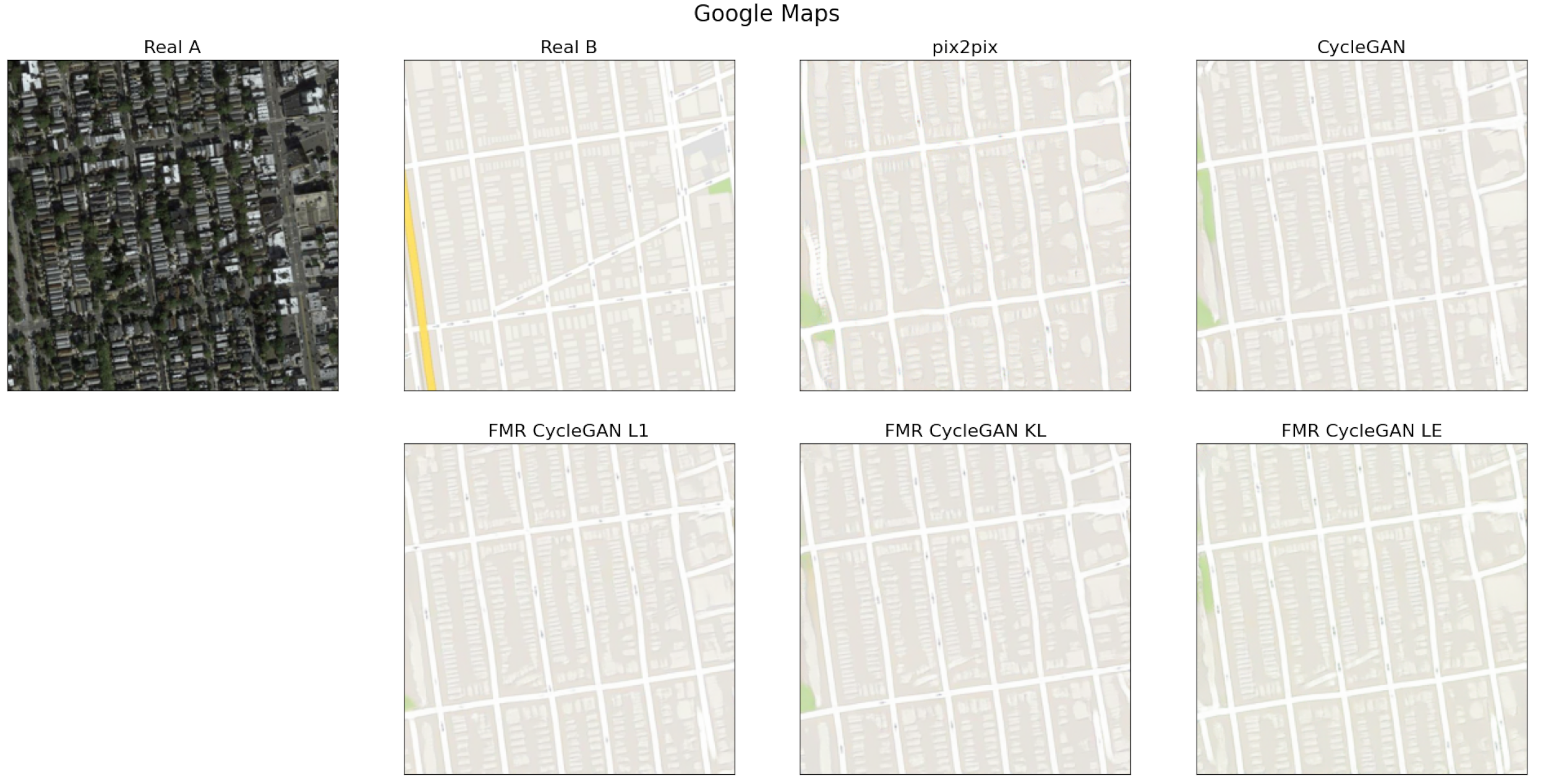
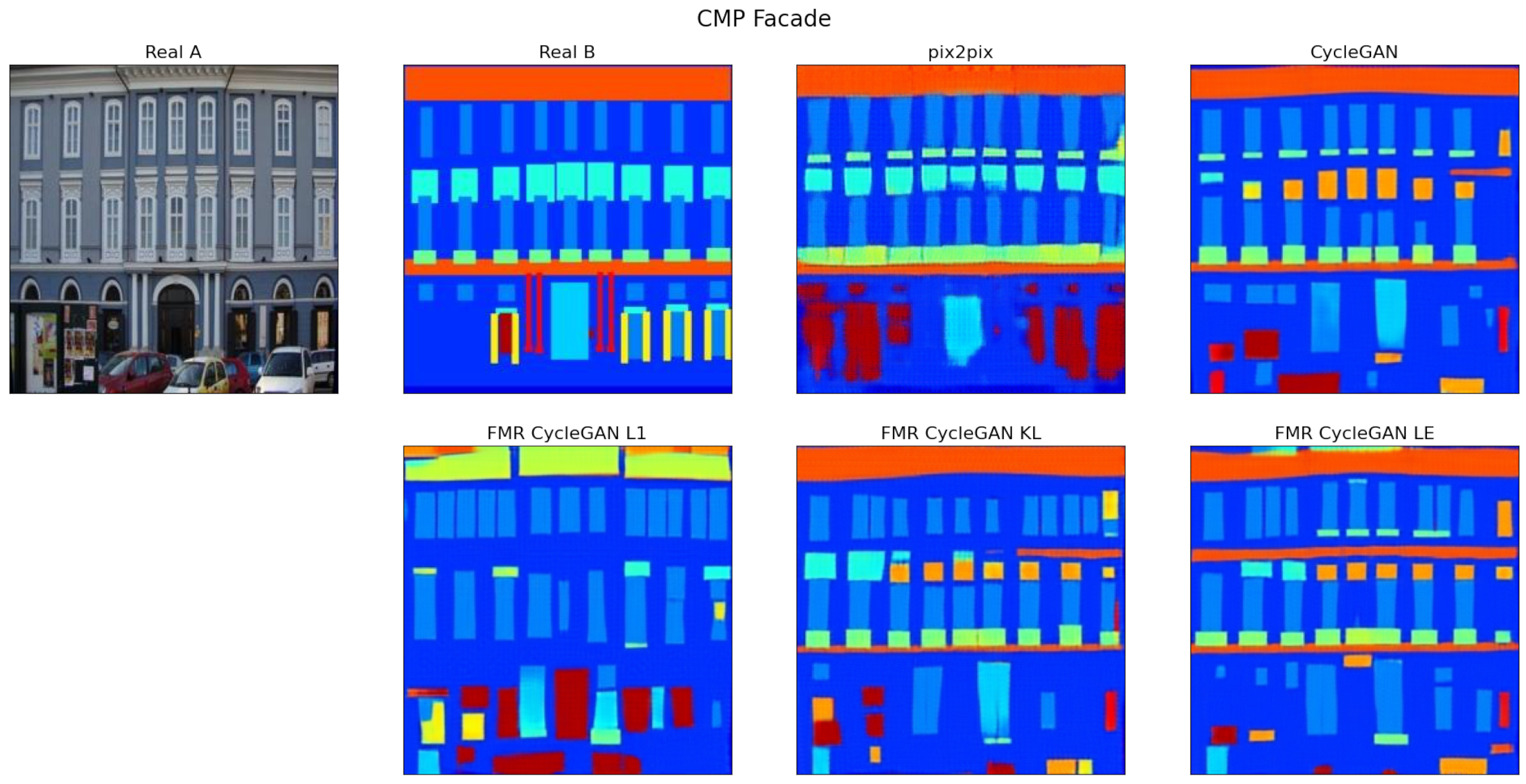
3.3. Experimental Results and Comparisons
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| cGAN | Conditional generative adversarial network |
| CNN | Convolutional neural network |
| FMR | Feature map regularization |
| FCN | Fully convolutional neural network score |
| GAN | Generative adversarial network |
| GE | Gaussian embedding |
| IoU | Intersection over union |
| IGE | Improved Gaussian embedding |
| IQA | Image quality assessment |
| KL | Kullback–Leibler |
| LE | Log-Euclidean |
| ML | Maximum likelihood |
| Probability density function | |
| PLG | Product of Lie groups |
| PSNR | Peak signal-to-noise ratio |
| SoG | Shape of Gaussian |
| SPD | Symmetric positive definite |
| SSIM | Structural similarity index measure |
Appendix A
| sample from the “left” domain X | |
| sample from the “right” domain Y | |
| G | generator network |
| D | discriminator network |
| data distribution | |
| mathematical expectation over | |
| nonlinear generator mappings (direct and the inverse) | |
| discriminator networks for domain X and Y | |
| adversarial loss function | |
| cycle consistency loss function | |
| CycleGAN loss function | |
| multivariate normal distribution | |
| centroid and covariance matrix of | |
| Frobenius matrix norm | |
| and vector norms | |
| distance functions | |
| Kullback-Leibler divergence | |
| d | dimensionality of feature space |
| symmetrized Kullback-Leibler divergence | |
| any of the ground distances between d-dimensional Gaussians | |
| determinant of covariance matrix | |
| cone of symmetric positive definite (SPD) matrices | |
| matrices in | |
| spatial dimensions of feature map in layer f of network | |
| f in the superscript denotes the “first” network layer | |
| l in the superscript denotes the “last” network layer | |
| feature map tensor of size in the “first” layer of generator network after processing sample | |
| feature map tensor of size in the “last” layer of generator network after processing sample | |
| feature map tensor in the “first” layer of generator network after processing sample | |
| feature map tensor in the “last” layer of generator network after processing sample | |
| matrix with d dimensional column vectors obtained by reshaping the feature map tensor | |
| matrix of feature map vectors , after processing | |
| column vector of | |
| ML estimates of covariance matrices of unknown PDFs that generated observations (columns) in , i.e., | |
| ML estimates of d dimensional centroids | |
| feature map-based cycle consistency loss function | |
| overall optimization objective with term | |
| weights of regularization terms | |
| structural similarity index measure between images |
References
- Park, T.; Liu, M.-Y.; Wang, T.-C.; Zhu, J.-Y. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2337–2346. [Google Scholar]
- Zhu, P.; Abdal, R.; Qin, Y.; Wonka, P. Sean: Image synthesis with semantic region-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5104–5113. [Google Scholar]
- Lee, C.-H.; Liu, Z.; Wu, L.; Luo, P. Maskgan: Towards diverse and interactive facial image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5549–5558. [Google Scholar]
- Tang, H.; Xu, D.; Yan, Y.; Torr, P.H.; Sebe, N. Local class-specific and global image-level generative adversarial networks for semantic-guided scene generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7870–7879. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Alami Mejjati, Y.; Richardt, C.; Tompkin, J.; Cosker, D.; Kim, K.I. Unsupervised attention-guided image-to-image translation. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; Volume 32, pp. 3693–3703. [Google Scholar]
- Tomei, M.; Cornia, M.; Baraldi, L.; Cucchiara, R. Art2real: Unfolding the reality of artworks via semantically-aware image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5849–5859. [Google Scholar]
- Song, Y.; Yang, C.; Lin, Z.; Liu, X.; Huang, Q.; Li, H.; Kuo, C.-C.J. Contextual-based image inpainting: Infer, match, and translate. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, M.-Y.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-Shot Unsupervised Image-to-Image Translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10551–10560. [Google Scholar]
- Zhao, L.; Mo, Q.; Lin, S.; Wang, Z.; Zuo, Z.; Chen, H.; Xing, W.; Lu, D. UCTGAN: Diverse image inpainting based on unsupervised cross-space translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5741–5750. [Google Scholar]
- Yuan, Y.; Liu, S.; Zhang, J.; Zhang, Y.; Dong, C.; Lin, L. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 701–710. [Google Scholar]
- Zhang, Y.; Liu, S.; Dong, C.; Zhang, X.; Yuan, Y. Multiple cycle-in-cycle generative adversarial networks for unsupervised image super-resolution. IEEE Trans. Image Process. 2019, 29, 1101–1112. [Google Scholar] [CrossRef] [PubMed]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, C.; Zheng, H.; Yu, Z.; Zheng, Z.; Gu, Z.; Zheng, B. Discriminative region proposal adversarial networks for high-quality image-to-image translation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 770–785. [Google Scholar]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- AlBahar, B.; Huang, J.-B. Guided image-to-image translation with bi-directional feature transformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, South Korea, 27 October–2 November 2019; pp. 9016–9025. [Google Scholar]
- Abady, L.; Dimitri, G.; Barni, M. Detection and localization of GAN manipulated multi-spectral satellite images. In Proceedings of the ESANN, Bruges, Belgium, 5–7 October 2022; pp. 339–344. [Google Scholar]
- Hosseini-Asl, E.; Zhou, Y.; Xiong, C.; Socher, R. Robust domain adaptation by augmented cyclic adversarial learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems—Interpretability and Robustness for Audio, Speech and Language Workshop, Montreal, QC, Canada, 3–8 December 2018; pp. 3–8. [Google Scholar]
- Qi, C.; Chen, J.; Xu, G.; Xu, Z.; Lukasiewicz, T.; Liu, Y. SAG-GAN: Semi-supervised attention-guided GANs for data augmentation on medical images. arXiv 2020, arXiv:2011.07534. [Google Scholar]
- Bao, F.; Neumann, M.; Vu, N.T. CycleGAN-based emotion style transfer as data augmentation for speech emotion recognition. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 2828–2832. [Google Scholar]
- Meng, Z.; Li, J.; Gong, Y. Cycle-consistent speech enhancement. arXiv 2018, arXiv:1809.02253. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Tanaka, K.; Hojo, N. CycleGAN-vc2: Improved CycleGAN-based non-parallel voice conversion. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 6820–6824. [Google Scholar]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-dehaze: Enhanced CycleGAN for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Lu, Y.; Tai, Y.W.; Tang, C.K. Attribute-guided face generation using conditional CycleGAN. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 282–297. [Google Scholar]
- Shaham, T.R.; Gharbi, M.; Zhang, R.; Shechtman, E.; Michaeli, T. Spatially-adaptive pixelwise networks for fast image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 14882–14891. [Google Scholar]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 31, pp. 701–709. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1857–1865. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29, pp. 469–477. [Google Scholar]
- Shrivastava, A.; Pfister, T.; Tuzel, O.; Susskind, J.; Wang, W.; Webb, R. Learning from simulated and unsupervised images through adversarial training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2107–2116. [Google Scholar]
- Ohkawa, T.; Inoue, N.; Kataoka, H.; Inoue, N. Augmented cyclic consistency regularization for unpaired image-to-image translation. In Proceedings of the 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 362–369. [Google Scholar]
- Pang, Y.; Lin, J.; Qin, T.; Chen, Z. Image-to-image translation: Methods and applications. IEEE Trans. Multimed. 2021, 24, 3859–3881. [Google Scholar] [CrossRef]
- Chernoff, H. A Measure of asymptotic efficiency for tests of a hypothesis based on the sum of observations. Ann. Math. Stat. 1952, 493–507. [Google Scholar] [CrossRef]
- Bhattacharyya, A. On a measure of divergence between two statistical populations defined by their probability distributions. Bull. Calcutta Math. Soc. 1943, 35, 99–109. [Google Scholar]
- Thomas, M.; Joy, A.T. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006; ISBN 0-471-24195-4. [Google Scholar]
- Gong, L.; Wang, T.; Liu, F. Shape of gaussians as feature descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 2366–2371. [Google Scholar]
- Lovrić, M.; Min-Oo, M.; Ruh, E.A. Multivariate normal distributions parameterized as a Riemannian symmetric space. J. Multivar. Anal. 2000, 74, 36–48. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Wang, Q.; Zhang, L. A novel Earth mover’s distance methodology for image matching with Gaussian mixture models. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1689–1696. [Google Scholar]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Fast and simple calculus on tensors in the log-Euclidean framework. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Palm Springs, CA, USA, 26–29 October 2005; pp. 115–122. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
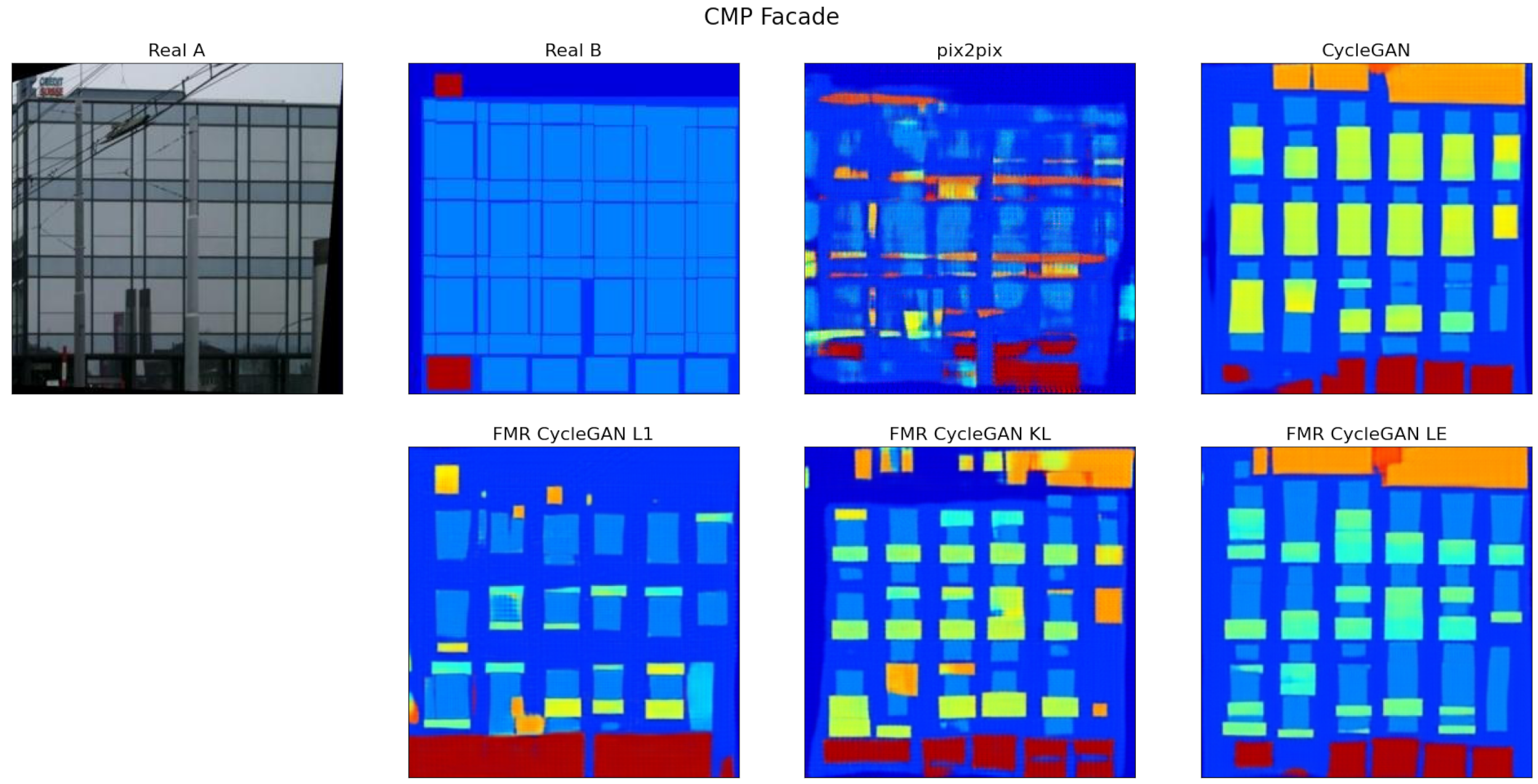{kind=link}
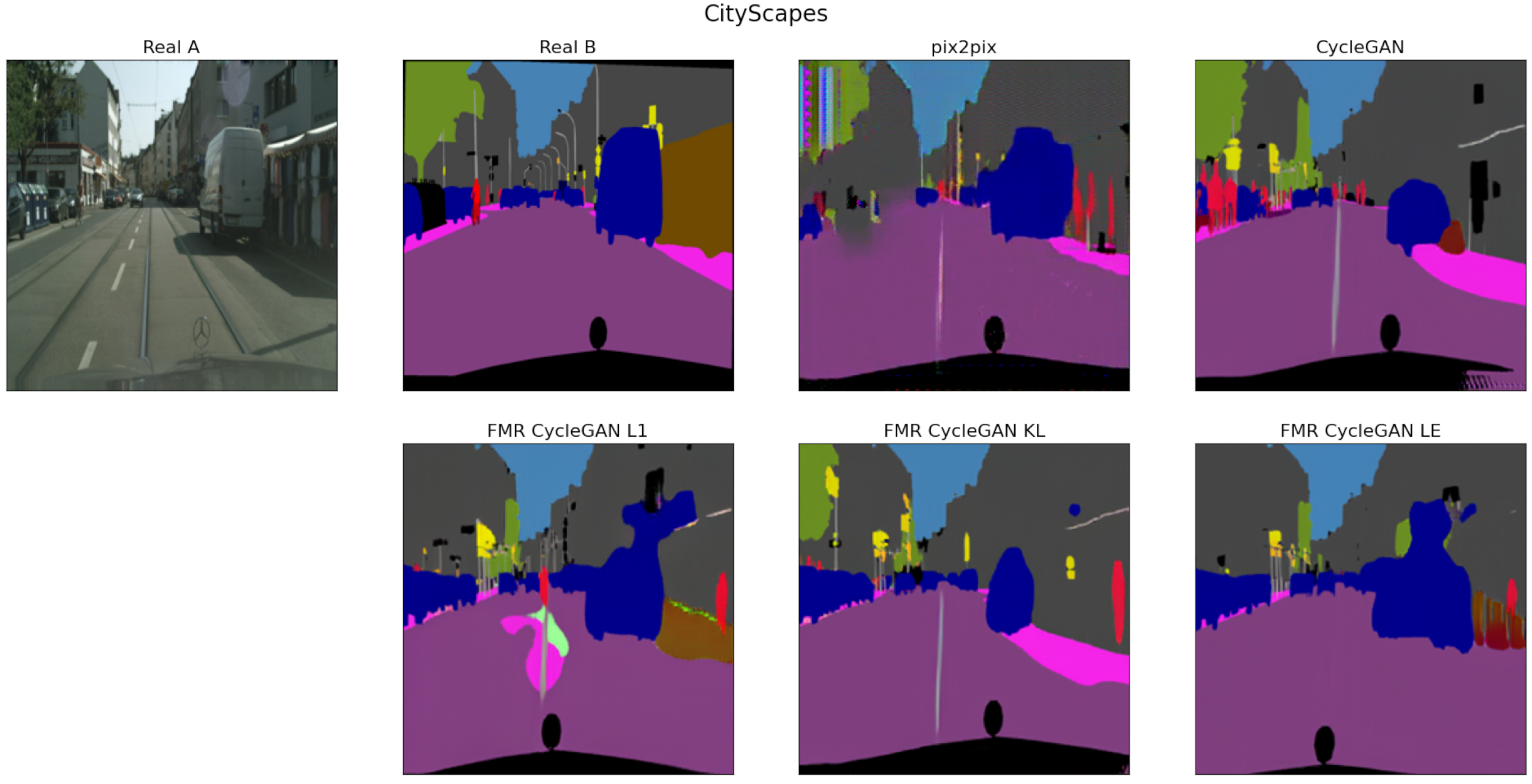{kind=link}
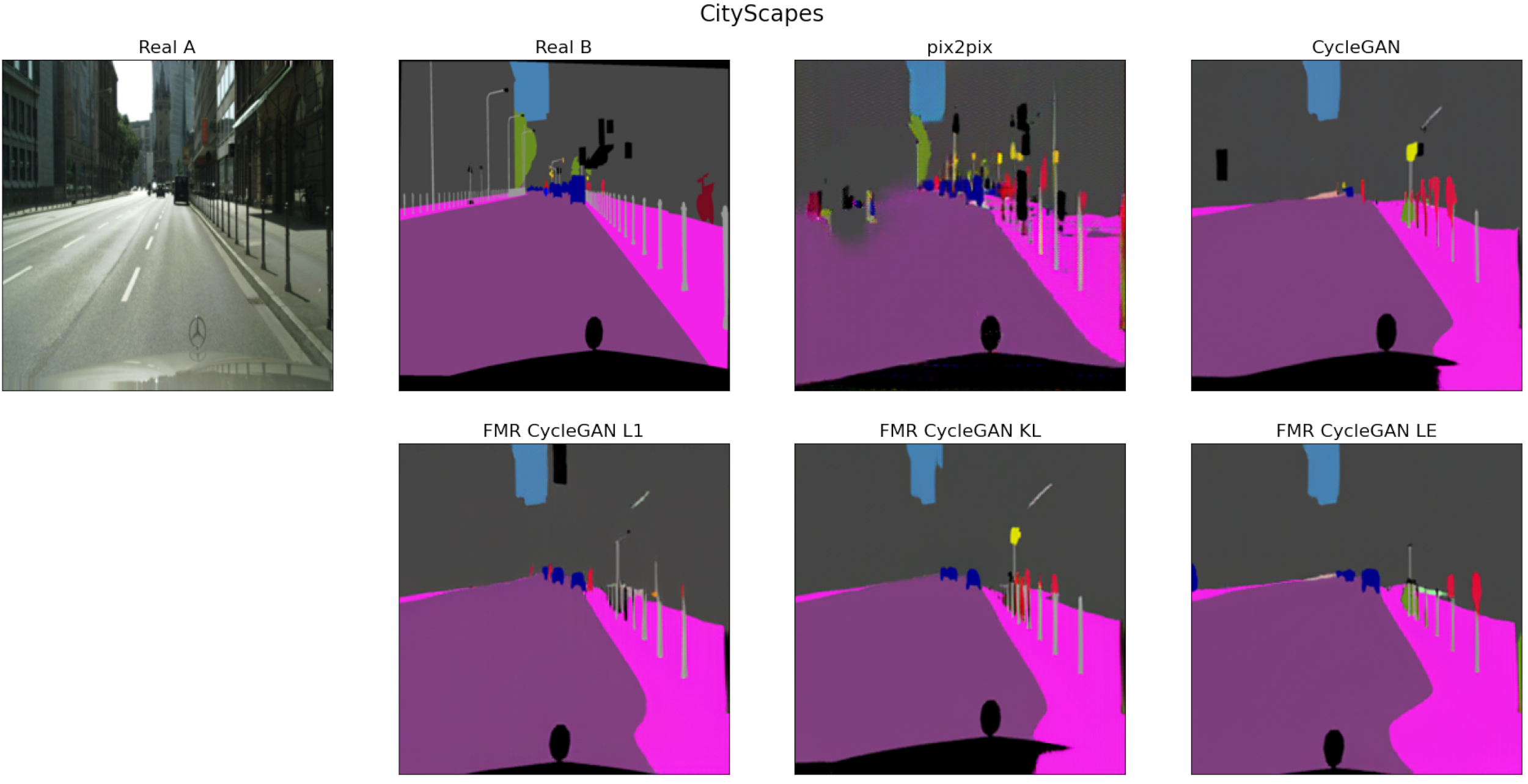{kind=link}
| Dataset/Task | pix2pix | CycleGAN | FMR CycleGAN | ||
|---|---|---|---|---|---|
| Google Maps | 30.01 | 30.24 | 31.15 | 30.85 | 30.32 |
| CMP Fasade | 14.25 | 10.98 | 10.81 | 11.45 | 11.37 |
| CityScapes | 19.51 | 17.12 | 17.89 | 18.86 | 17.34 |
| Dataset/Task | pix2pix | CycleGAN | FMR CycleGAN | ||
|---|---|---|---|---|---|
| Google Maps | 0.69 | 0.73 | 0.76 | 0.74 | 0.73 |
| CMP Fasade | 0.42 | 0.27 | 0.31 | 0.29 | 0.28 |
| CityScapes | 0.59 | 0.54 | 0.58 | 0.65 | 0.56 |
| Image-to-Image | FCN Score Type | |||
|---|---|---|---|---|
| Translation Method | Pixel Acc. | Mean Acc. | Mean IoU | |
| supervised: | pix2pix | 0.71 | 0.25 | 0.18 |
| unsupervised: | CycleGAN | 0.52 | 0.17 | 0.11 |
| CoGAN | 0.40 | 0.10 | 0.06 | |
| SimGAN | 0.20 | 0.10 | 0.04 | |
| FMR CycleGAN | 0.59 | 0.22 | 0.15 | |
| 0.56 | 0.20 | 0.17 | ||
| 0.15 | 0.17 | 0.13 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krstanović, L.; Popović, B.; Janev, M.; Brkljač, B. Feature Map Regularized CycleGAN for Domain Transfer. Mathematics 2023, 11, 372. https://doi.org/10.3390/math11020372
Krstanović L, Popović B, Janev M, Brkljač B. Feature Map Regularized CycleGAN for Domain Transfer. Mathematics. 2023; 11(2):372. https://doi.org/10.3390/math11020372
Chicago/Turabian StyleKrstanović, Lidija, Branislav Popović, Marko Janev, and Branko Brkljač. 2023. "Feature Map Regularized CycleGAN for Domain Transfer" Mathematics 11, no. 2: 372. https://doi.org/10.3390/math11020372