1. Introduction
With the rapid development of productivity brought about by technological innovation, reducing energy consumption has increasingly become a demand of various production industries [
1]. At the same time, optimizing the raw materials used in manufacturing has become an important goal of the manufacturing system. In typical heavy industry, plates of metal or steel are the primary raw materials consumed in machinery manufacturing. The design of piece-cutting schemes is a necessary process and the first procedure in machinery manufacturing. Optimized packing schemes in this process can effectively improve the utilization rate of materials, thereby reducing manufacturing cost and improving economic benefits [
2]. Packing-optimization problems deal with placing pieces to be arranged in a packing space in a certain way using the given space and certain constraints to achieve a specific optimization goal. Hereby pieces have different definitions on different occasions. In the metal processing industry, they refer to pieces to be processed; in the leather manufacturing industry, they refer to samples to be cut; and in the transportation industry, they refer to goods to be placed. According to the dimensions of pieces, packing problems can be classified into one-dimensional (1D) packing problems, two-dimensional (2D) packing problems, three-dimensional (3D) packing problems, and multidimensional packing problems. 2D irregular-piece packing [
3,
4], also known as special-shaped-piece packing, is a kind of 2D sheet-packing optimization. Compared to regular-piece packing, irregular-piece packing problems are very different in piece shape, solution strategy, and overlap-detection method. Therefore, they have a more extensive solution space and need more complex packing operations, which makes it challenging to obtain a satisfactory solution in polynomial time [
5]. Many studies focus on obtaining an approximate optimal packing solution in an acceptable time.
Two-dimensional irregular packing is a classic mathematical and combinatorial optimization problem developed for decades. In the initial solution for 2D irregular packing, a single algorithm was applied, such as linear programming, a meta-heuristic algorithm, or a heuristic algorithm. These algorithms adjust the packing of items according to specific rules. Hopper et al. [
6,
7] studied the application of meta-heuristic and heuristic algorithms in 2D and 3D nesting. Bennell et al. [
8] discussed a 2D irregular packing problem and related geometric problems. A solution to a packing problem of 2D irregular pieces developed from the previous rectangular-envelope algorithm [
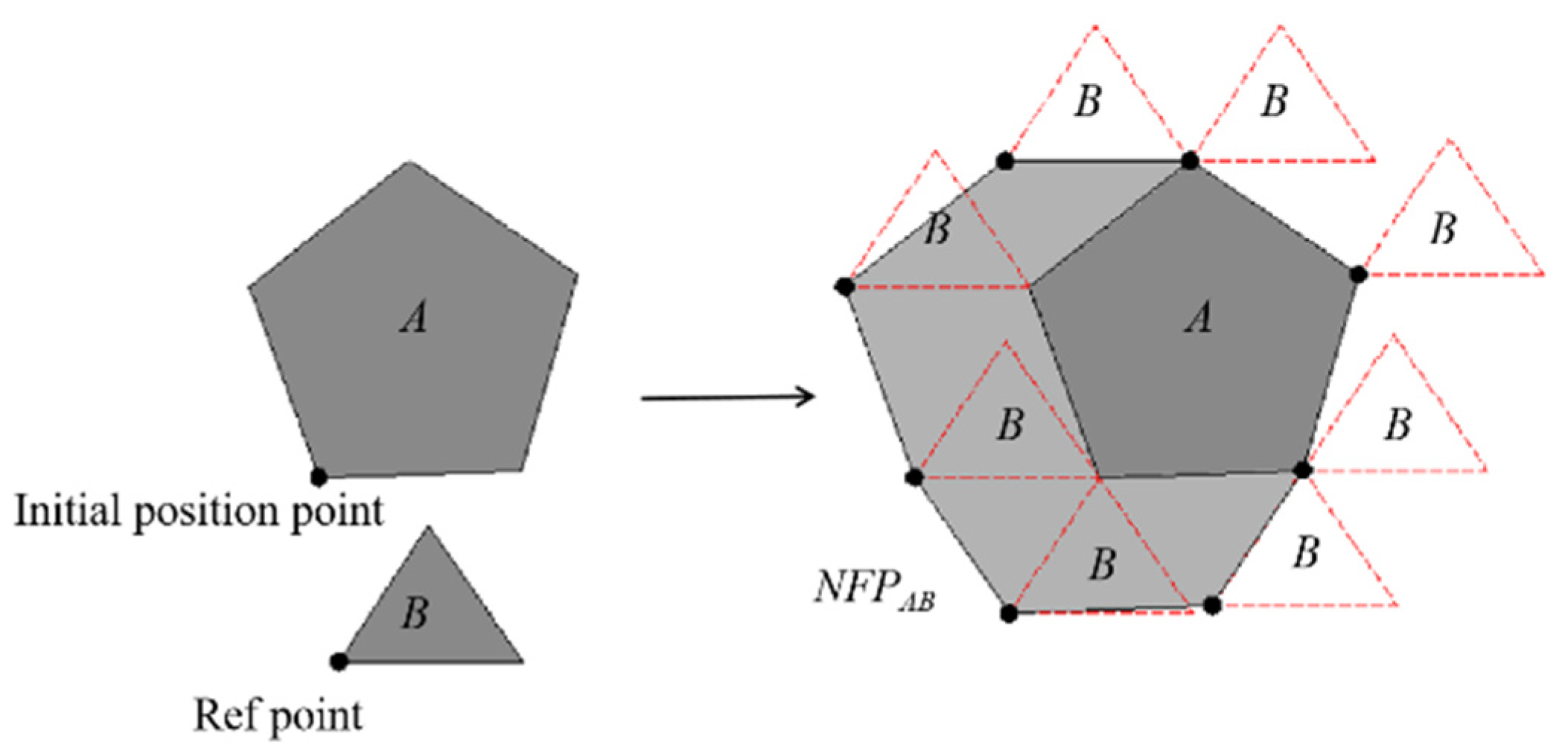
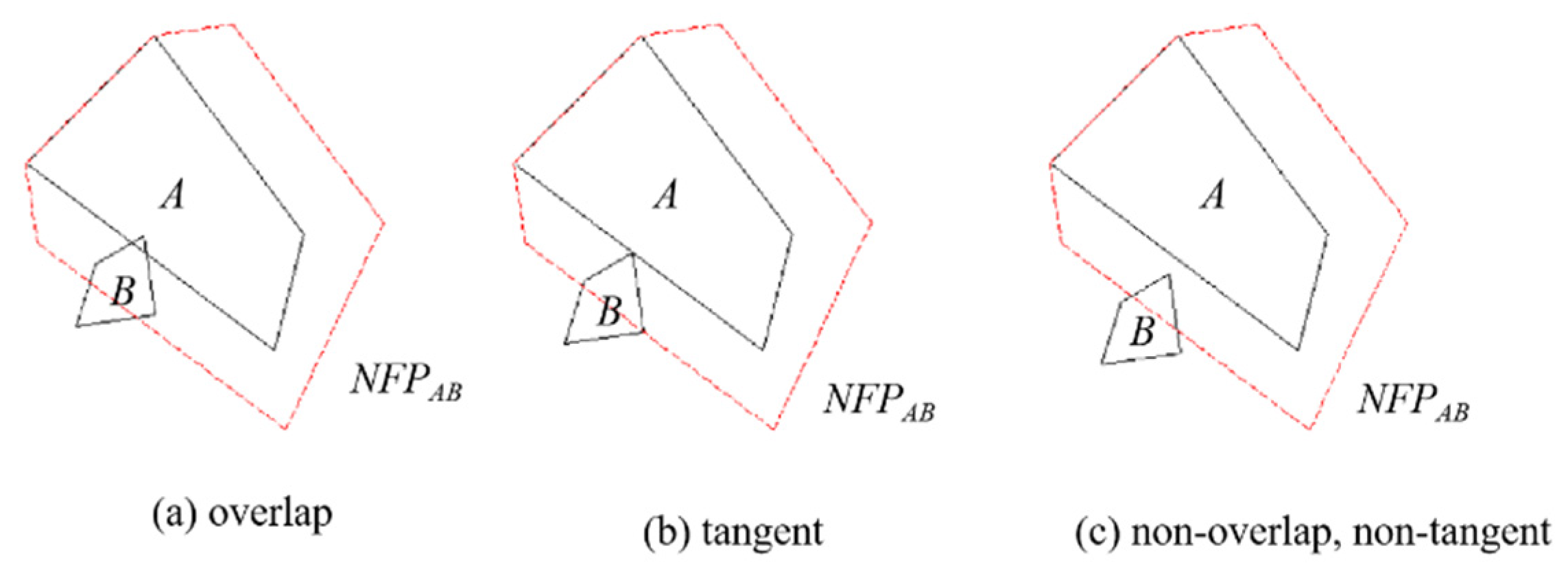
9] is adjacent packing based on real shape, which is an update and improvement of the packing method. Among the piece-packing methods based on real shapes, no-fit polygons (NFP) [
10,
11], raster methods (also called pixel methods) [
12], linear programming (LP), and mixed integer linear programming (MIP) [
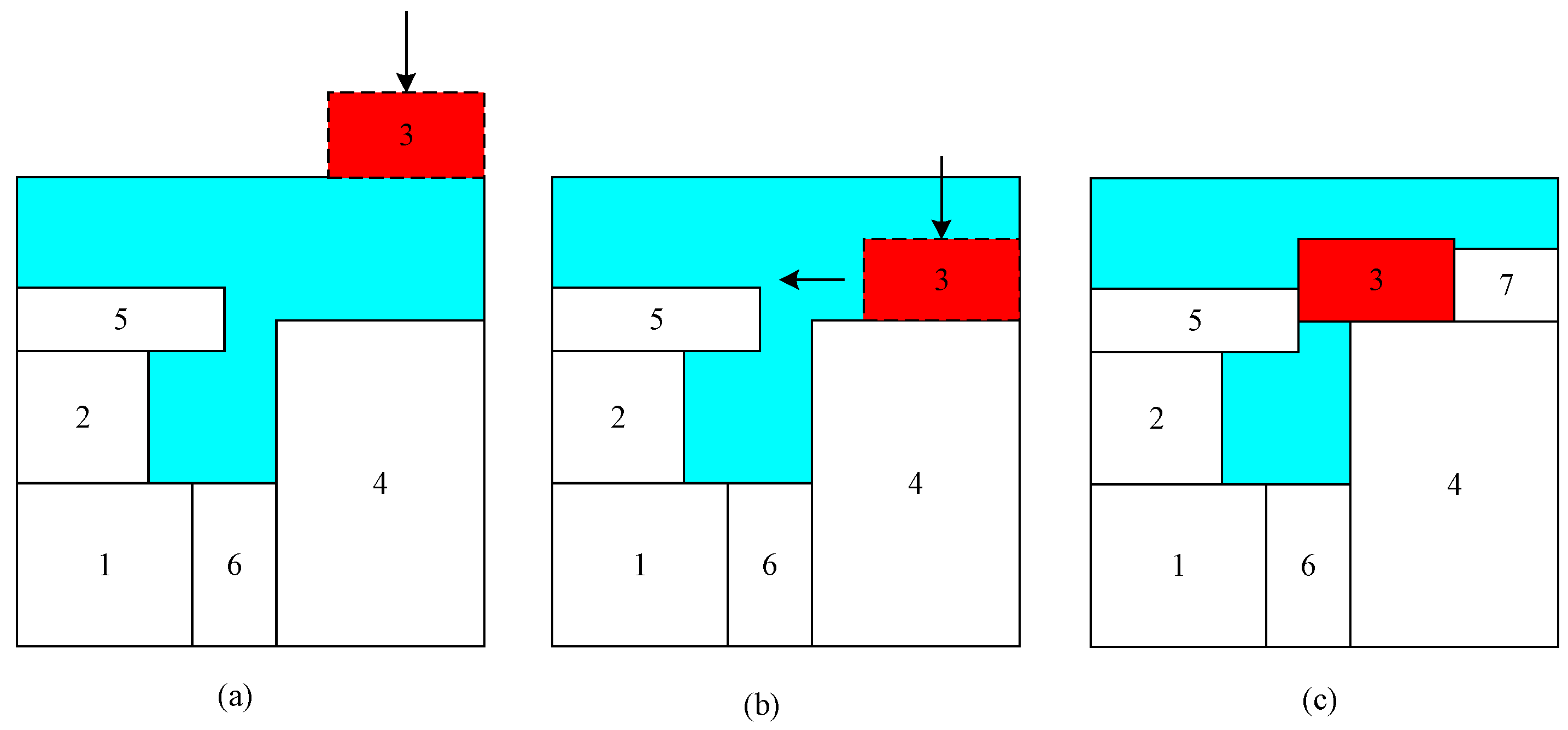
13] are generally used to judge overlapping of pieces. Regarding placement rules, the bottom-eft (BL) [
14] algorithm is the most commonly used method. Another problem worth studying is the sequence optimization of pieces, which is crucial to the final packing result [
11]. Baosu Guo et al. [
15] showed that the mathematical model for the 2D packing problem is mature, and there has been almost no disruptive technology in recent years. Another study [
16] showed that most of the current packing algorithms improve the original method. However, with updates in packing technology, hybrid algorithms are increasingly used. Improvement of packing technology is not only the optimization of sequence or position but also the improvement of multiple packing-technology points simultaneously. Danyadi et al. [
17] proposed a bacterial-evolution method aiming at the three-dimensional version of the bin packing problem in actual logistics, and fuzzy logic was utilized in the fitness calculation. Elkeran [
18] adopted a method of combining irregular pieces in pairs and combining them with a rectangular-envelope algorithm to solve a packing problem of irregular pieces. This could effectively reduce the blank area, but the computational complexity was significantly increased. Sato et al. [
19] not only adopted a heuristic paired-pack algorithm but also used a simulated annealing algorithm to guide the search process of the packing sequence and obtain specific packing effects. Beyaz et al. [
20] proposed a hyperheuristic algorithm for solving a 2D irregular packing problem, which showed excellent robustness. In recent research on 2D irregular packing problems, Rao et al. [
21] used a search algorithm hybridized with beam search and tabu search (BSTS), combined with a novel placement principle to complete packing of 2D irregular pieces. They obtained some results comparable to advanced algorithms in a short time. Souza Queiroz et al. [
22] proposed a tailored branch-and-cut algorithm for a two-dimensional irregular-strip packing problem with an uncertain demand for the items to be cut, and developed a two-stage stochastic programming model considering discrete and finite scenarios, which achieved good nesting results. At present, the mainstream 2D irregular piece packing algorithms in the world are a hybrid algorithm based on metaheuristic sequencing algorithms (such as the particle swarm optimization algorithms [
23], genetic algorithms [
24], ant colony algorithms [
25], and tabu search algorithms [
21,
26]); and a positioning algorithm based on NFP geometric operations (such as BL [
27], bottom-left fill (BLF) [
28], and maximal rectangles bottom-left (MAXRECTS-BL) [
29,
30]). Although the existing research on 2D irregular packing problems has made significant achievements and been applied to practical engineering problems, there are still some problems to be solved. First, solutions based on heuristic algorithms have poor universality, and the computing performance based on different data sets shows significant differences. Second, the intelligent optimization algorithm can fall into the local optimum on some problems, and the calculation cost is high. The latest literature review on packing problems [
15] shows that machine learning and deep learning algorithms may be helpful for sequential optimization of packing problems in the future. However, there is currently a lack of research in this area.
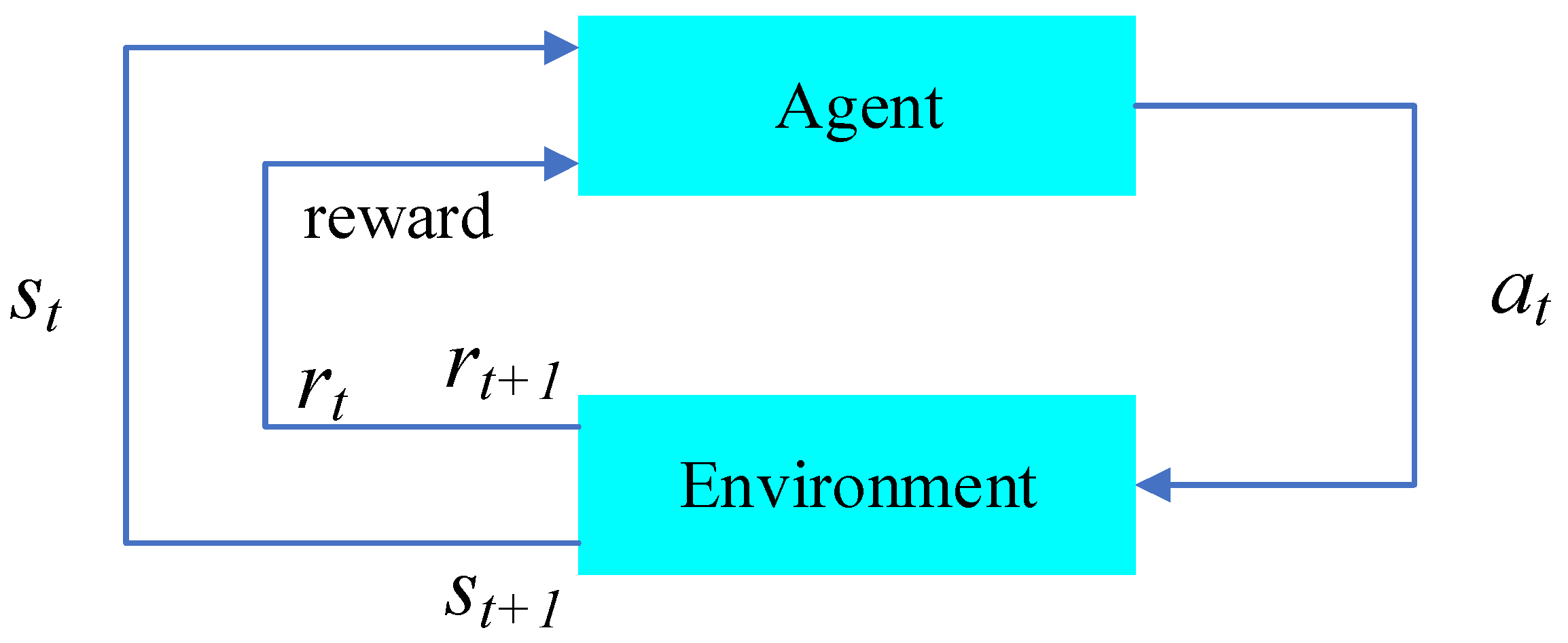
In recent years, artificial intelligence technology represented by RL has been widely studied and successfully applied in operational-research optimization, showing great potential to solve combinatorial optimization problems [
31]. RL models the sequential-decision problem in operations research as an MDP and solves it. It improves the strategy by exploring and interacting with the environment. The characteristics of learning and online learning make it an important branch of machine learning research. Wang et al. [
32] established a mathematical model and completed optimization of a centrifugal pump by using an artificial intelligence method. Kara et al. [
33] solved a single-stage inventory decision-making problem considering product life using an RL method based on Sarsa-learning and Q-learning. Zhang et al. [
34] used an improved Q-learning algorithm based on bounded table search to solve random customer demand and obtained good results. Kong et al. [
35] tried to build a unified framework for solving linear combination optimization problems based on RL and used the knapsack problem as an example, whereby the gap between their results and optimal solutions was less than 5%. Chengbo Wang et al. [
36] proposed using Q-learning to solve a problem of unmanned-ship-path planning. Laterre et al. [
37] designed an algorithm based on ranked reward and applied it to a 2D bin packing problem; then the strategy was evaluated and improved using deep neural networks and Monte Carlo trees [
38]. Wang Shijin et al. [
39] studied a dynamic JSP problem of three scheduling rules by using Q-learning. The results showed that the Q-learning method can improve the agent’s adaptability. Zhao et al. [
40] solved a 2D rectangular packing problem by using a Q-learning search. As a progression of reinforcement learning, deep reinforcement learning (DRL) is also a mainstream machine learning method, which has led to some achievements in many fields, including combinatorial optimization. For example, Bello et al. [
41] used a deep learning architecture and RL training to obtain the optimal solution for a large-scale TSP problem, and save computing costs. Hu et al. [
42] and Duan et al. [
43] used a pointer network, in combination with supervised learning or RL training, and combined it with certain heuristic algorithms to solve a 3D bin packing problem. Even so, the shape of 2D irregular pieces is special, resulting in high requirements for the input settings of neural networks. To the best of our knowledge, there is no research on deep reinforcement learning algorithms for 2D irregular packing problems, or on using reinforcement learning algorithms to solve 2D irregular-piece packing problems. The investigation of packing technology based on reinforcement learning can provide improved technical support for reinforcement training processes in deep reinforcement learning algorithms, explore new 2D irregular packing solutions, model designs, and expand the application field of machine learning. In addition, research on the solution method based on machine learning of 2D irregular-piece packing can reduce the design error, which leads to great practical application potential.
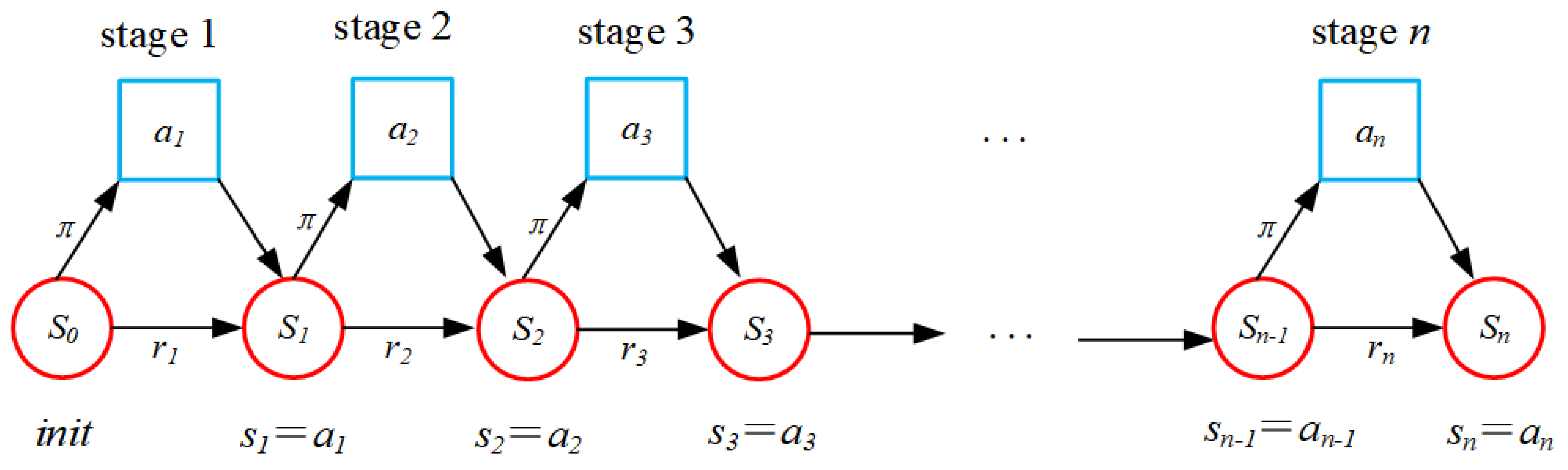
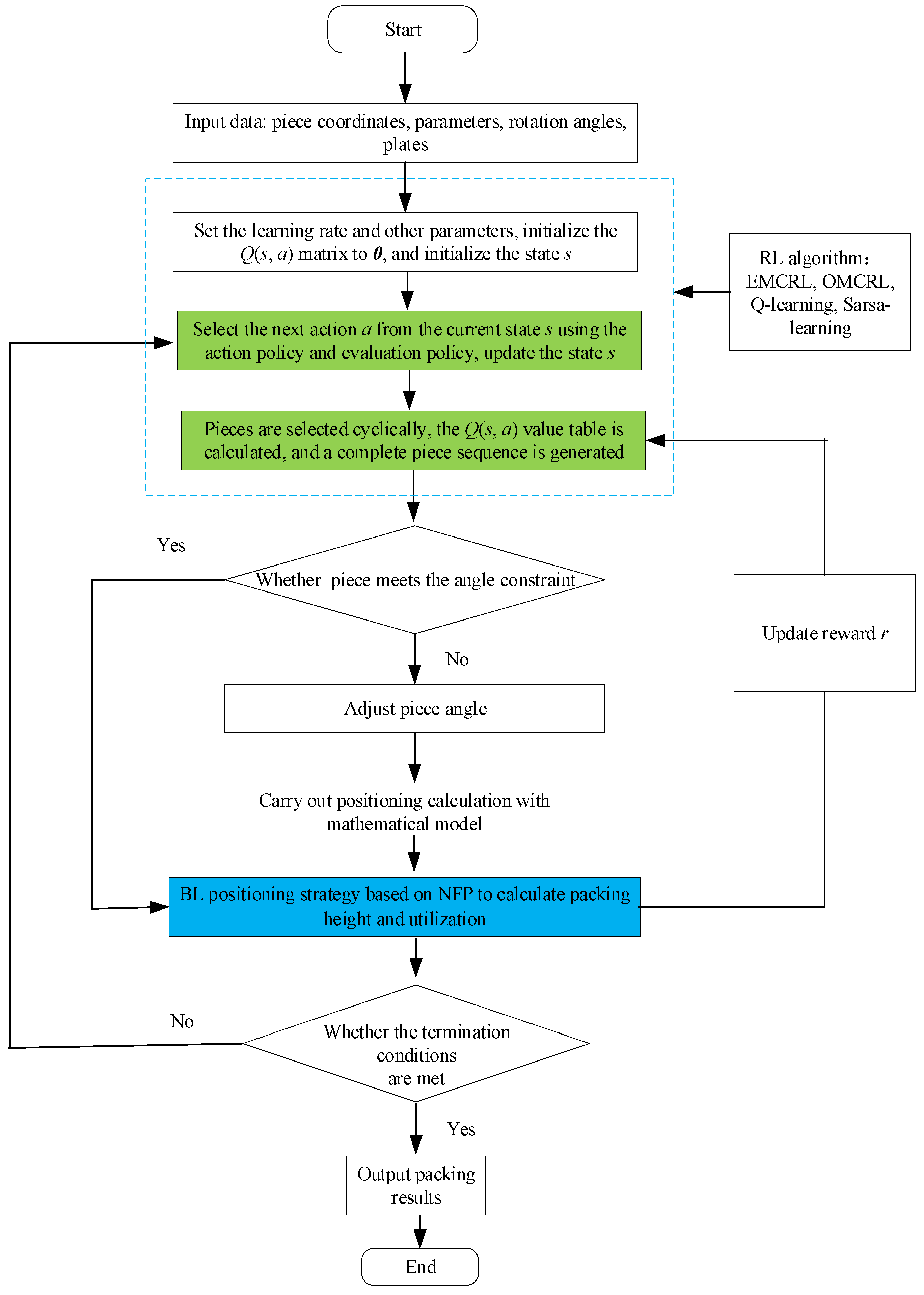
In this paper, research on 2D irregular-piece packing using RL methods is proposed for the first time to compensate for the weakness of traditional packing algorithms. We adopted a piece-sequence-generation method based on MC learning, Q-learning, and Sarsa-learning and designed a reward- and strategy-update mechanism based on piece packing. Combined with the classical BL positioning algorithm, packing of a 2D irregular piece can be realized. Finally, the piece packing test based on actual shapes was carried out with standard instances, proving the algorithm’s effectiveness. In this paper, the packing problem is summarized first; then the 2D irregular packing problem is described and modeled. Secondly, a positioning strategy based on NFP and principles of sequence optimization based on an RL algorithm are introduced. Finally, the experimental settings and results are analyzed, and the significance and limitations of the algorithm are summarized and discussed.
5. Computational Experiments and Discussion
The algorithm was written in Python. Computational tests of hybrid RL methods for 2D irregular-piece packing were performed on a computer with a 2.30 GHz AMD Ryzen 7 3750H CPU with 4 kernels and 8 GB of RAM. To test the performance of the proposed algorithmic model, the method was tested using packing problem instances, which were also used as benchmark problems in other studies. The data file for the test was obtained from the EURO Special Interest Group on Cutting and Packing (ESICUP,
https://www.euro-online.org/websites/esicup/data-sets/ accessed on 8 September 2022). The sample information for these data is provided in
Table 1. The total number of episodes
m was set to 300, the discount factor
γ = 1, and the constant
C = 100, which is a reasonable parameter setting obtained through many experimental calculations. The random exploration rate
ε was 0.1, and the learning rate
α was 0.5 [
30]. In order to avoid random deviation caused by convergence of the RL method, the packing height
H returned after each episode was recorded. Meanwhile, the smaller
H between the current minimum packing height and the packing height returned by the last episode was taken as the updated optimal packing height, and the sequence of corresponding pieces was the current optimal packing sequence.
For each case, the packing algorithm based on hybrid RL was run 10 times and partially obtained better packing results compared to the corresponding literature (i.e., the genetic algorithm of bottom-left (GABL) [
53], a hybrid nesting algorithm based on heuristic placement strategy and an adaptive genetic algorithm (AGAHA) [
54], a simulated annealing hybrid algorithm (SAHA) [
55], and the hybrid beam search with tabu search algorithm (BSTS) [
21]). The differences in the computing environments of these algorithms are shown in
Table 2. The relevant algorithm parameters are described in the corresponding literature.
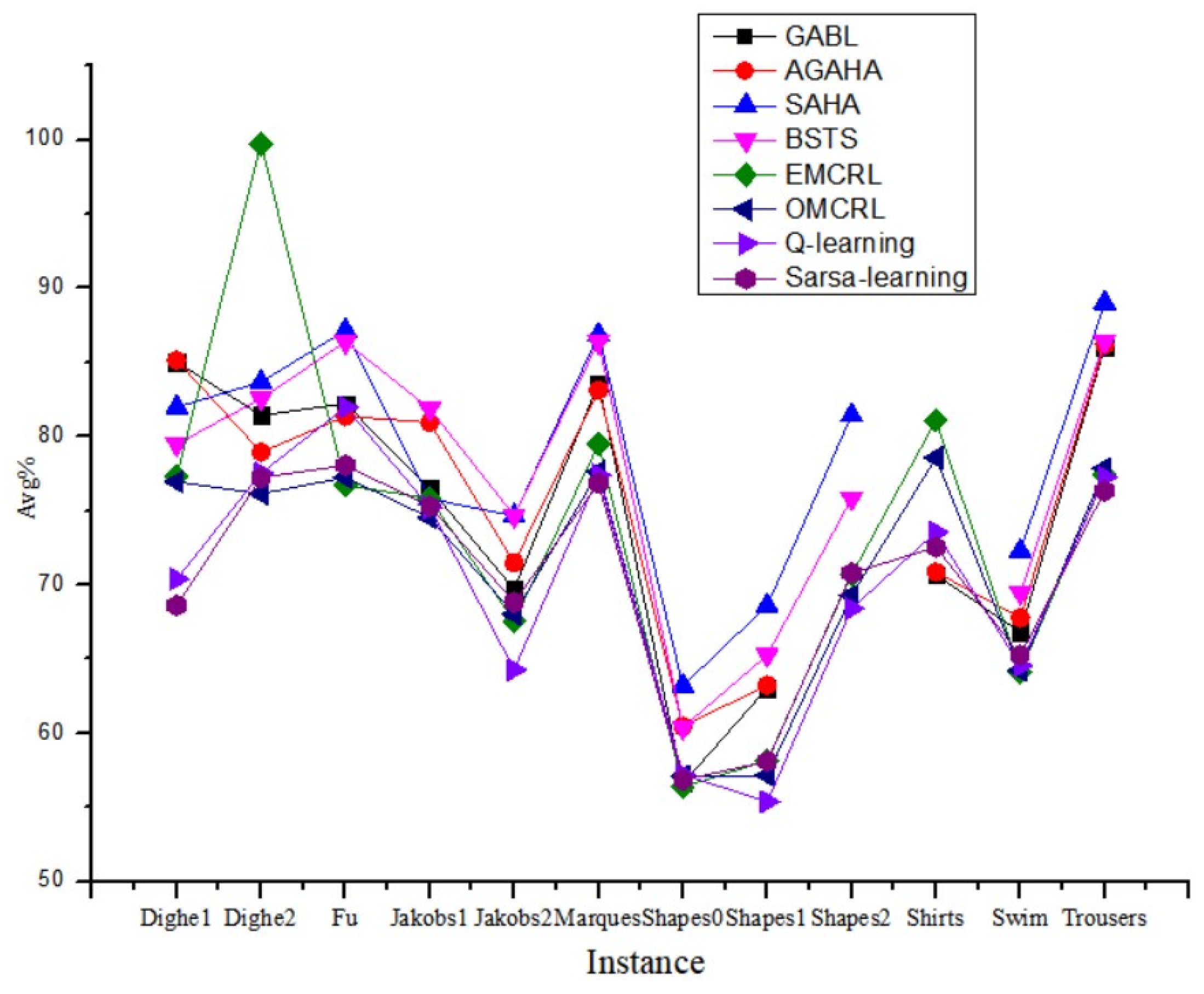
Table 3 and
Table 4 present the experimental results of these excellent algorithms and the packing results of our hybrid RL algorithm for a 2D irregular packing problem, respectively. Taking the instance as the horizontal coordinate, and the average utilization rate of the plate as the vertical coordinate, the results in
Table 3 and
Table 4 were processed into a curve, as shown in
Figure 8, representing the average utilization rate of the plate calculated based on different algorithms for each instance.
By analyzing
Table 3 and
Table 4 and
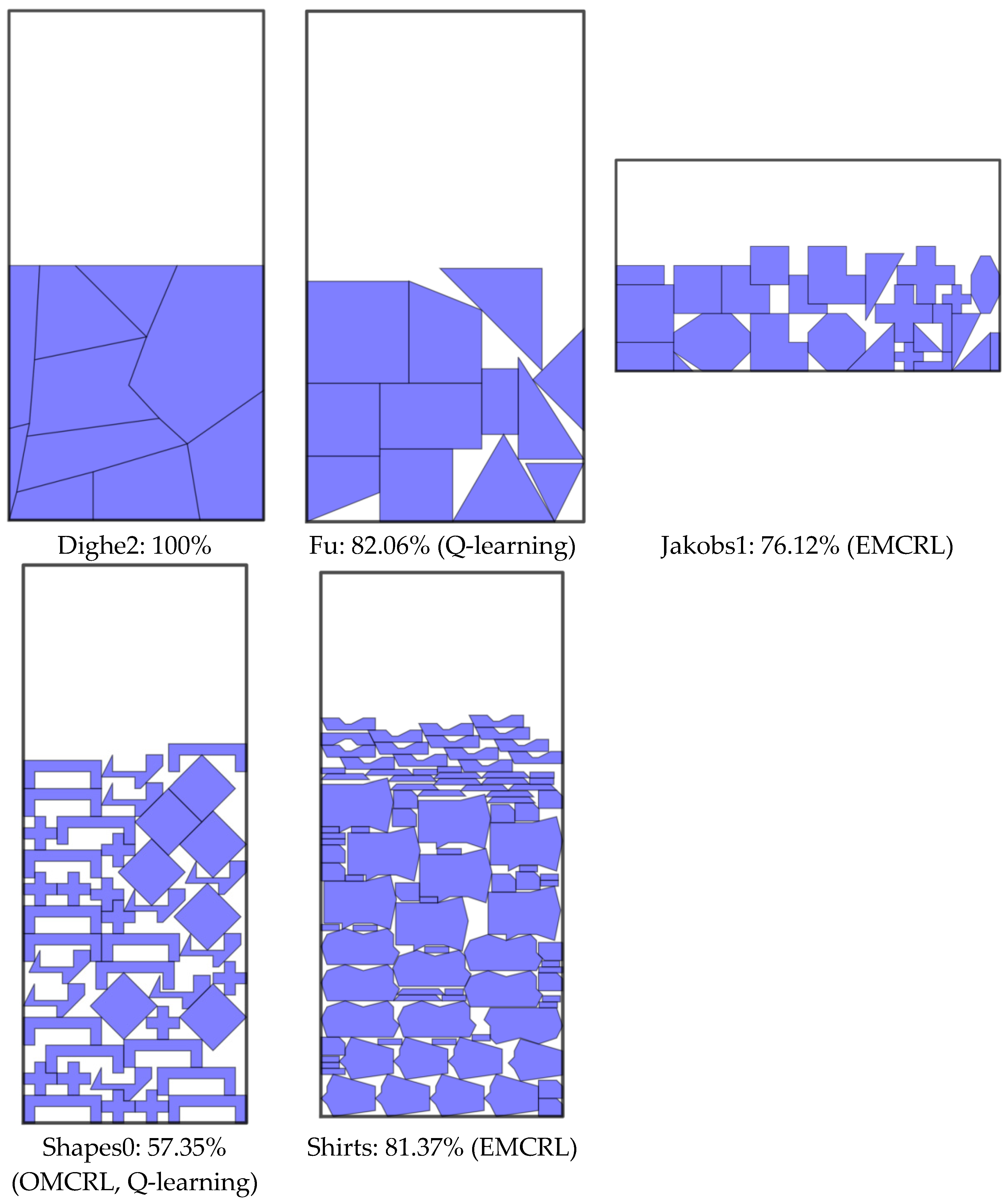
Figure 8, it is evident that our packing algorithm based on hybrid RL can achieve improved packing results compared to corresponding studies in some instances. The better results of our hybrid RL algorithm are highlighted in blue. Results below an average of 1% between algorithms are underlined. Moreover, the best results among the four RL algorithms analyzed are shown in bold. For the same instance, the solution results of different algorithms show the same changing trend, while in different instances, the packing results show great volatility, which shows the importance and complexity of algorithm design. In the four classic RL packing calculations based on 12 instances, the EMCRL algorithm has produced the optimal solution for five instances. The OMCRL algorithm and Q-learning algorithm have obtained the optimal solution for two and three instances, respectively, and the same optimal utilization rate of plates has been achieved on the instance based on Shapes0. The calculation based on the Sarsa-learning algorithm also obtained the optimal solution for three instances. In this view, the algorithm based on EMCRL has the strongest optimization among the four classic RL algorithms. Compared with the results of the classic heuristic algorithm in the relevant literature, the EMCRL algorithm has acquired a better solution for three instances (Dighe2, Jakobs1, Shirts), while the calculations based on the OMCRL algorithm and Q-learning algorithm have obtained a better solution for two instances (Shapes0, Shirts) and three instances (Fu, Shapes0, Shirts), respectively. Although the Sarsa-learning algorithm produced a better solution for only one instance (Shirts) compared with the GABL and AGAHA algorithms, there is a less than 1% result gap for the instance Jakobs2 compared to the GABL method. In other words, compared with the GABL algorithm, AGAH algorithm, SAHA algorithm, and BSTS algorithm, better results for three (Dighe2, Shapes0, Shirts), three (Dighe2, Fu, Shirts), two (Dighe2, Jakobs1) and one (Dighe2) instance can be produced using the packing algorithm based on hybrid RL. Specifically, the EMCRL algorithm can achieve 100% utilization for instance Dighe2, which is approximately 10% higher than the result of the relevant heuristic algorithms (GABL, AGAHA, SAHA, BSTS). This is also the best calculation result among the four RL algorithms. For example, in Shirts the results based on the hybrid RL algorithm exceeds the results of 71.53% plate utilization in the classic heuristic algorithm (GABL, AGAHA). In addition, in most calculation results based on the RL algorithm, the gap between the optimal utilization rate and the average utilization rate is less than 3%, which indicates the algorithm’s stability. From the above analysis, it can be seen that the hybrid RL algorithm can obtain comparable results or better results than some classic heuristic algorithms in certain instances. The EMCRL algorithm can produce better solutions, while the Sarsa-learning algorithm produces the least optimal solutions and has the most limited optimization effect. The layout of the best results for five instances of the packing algorithm based on RL can be found in
Figure 9.
It can be seen from
Table 4 and
Figure 8 that the EMCRL algorithm can achieve better optimization results than the other three RL algorithms, which is related to the reward–return setting of the packing. When each piece to be packed is traversed, and the reciprocal of the packing height is used as a reward, it coincides with the reward–return strategy after each complete episode of the EMCRL. The data generation of EMCRL is more diverse than that of OMCRL, which is better for learning the update optimization of the sequence. Compared with Sarsa-learning, the Q-learning algorithm returns better packing optimization results, which is related to its sequence-update strategy. The difference between the two can be observed in Formulas (8) and (9). The decision-making piece is the same, but the global situation is considered by Sarsa-learning when performing actions (that is, the next action will be determined when updating the current
Q value). Nevertheless, Q-learning chooses the action with the greatest current benefit every time, regardless of other states, meaning it is greedier. As a result, the Q-learning algorithm is similar to the EMCRL and has more diverse data, therefore it can achieve better learning efficiency and optimization effects. In addition, the hybrid RL algorithm can obtain comparable or better results than some classic heuristic algorithms in certain instances. The possible reasons are that, on the one hand, the reinforcement-learning search based on self-learning can gain a better packing sequence, and an appropriate positioning algorithm can obtain a better packing effect. On the other hand, pieces in different instances have various complexities, and the classic heuristic algorithm is inefficient in solving certain instances. Therefore, research of 2D irregular packing needs further exploration and improvement. There is a difference of more than a 5% result gap between the optimal utilization rate and the average utilization rate in the calculation based on the EMCRL algorithm, which is related to the agent exploration mechanism analyzed above. The use of this exploration mechanism can efficiently find the optimal solution and may lead to greater randomness.
6. Conclusions
In this work, we establish a mathematical model for 2D irregular-piece packing and propose a novel solution scheme based on a hybrid reinforcement learning algorithm (Monte Carlo learning, Q-learning, and Sarsa-learning) to solve 2D irregular-piece packing problems. The algorithm is an early attempt to solve the 2D irregular packing problem by using the machine learning method. In the solution process, the piece packing sequence is self-learning optimized, and combined with the classic BL positioning algorithm based on NFP, to achieve 2D irregular-piece packing. During this process, mechanisms of reward–return and strategy-update based on piece packing are designed, and policy evaluation strategies of different RL methods are applied. Then, the packing results of different RL algorithms are compared.
The results show that the packing algorithm based on hybrid RL is an applicable and effective algorithm for the irregular packing problem, which can achieve 2D irregular-piece packing in an acceptable time. The proposed algorithm produces five better results and one comparable result within 1% of the average results for each of the 12 benchmark problems. That is, compared with some classic heuristic algorithms, the packing algorithm based on hybrid RL can achieve a partially similar or better optimization effect. At the same time, the EMCRL algorithm can achieve better results than the OMCRL algorithm, Q-learning algorithm, and Sarsa-learning algorithm, which provides a scheme for solving packing problems with different requirements. On the one hand, the packing algorithm based on RL can obtain a better packing utilization rate. On the other hand, the piece sequence to be arranged can be self-learning to reduce the probability of falling into local optimization and improve the reliability and intelligence of packing. These are of positive significance to practical packing applications. Furthermore, this algorithm is an early attempt at reinforcement learning to solve 2D packing problems, which provides a foundation for subsequent deep reinforcement learning to solve packing problems and has far-reaching theoretical significance. However, the update of the sequence of the algorithm depends on the update of the reward table, which needs more time to learn a better sequence. Moreover, there are many parameters in the proposed RL algorithm, which produce various results according to different settings, with certain complexity and uncertainty. Furthermore, for packing problems of a large scale, the search based on RL will cost a lot of time. For packing of pieces with certain defects, the performance of the proposed algorithm may be affected.
In future work, the packing performance based on the hybrid RL algorithm will be explored more deeply according to different packing characteristics, such as pieces with holes and defective plates. In addition, deep reinforcement learning based on neural networks will be investigated further to improve solutions to packing problems caused by variable variety batch production in actual heavy industry production.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}