
Stress–Strength Modeling Using Median-Ranked Set Sampling: Estimation, Simulation, and Application
 , , , and
, , , and 
Abstract
:1. Introduction
2. Median-Ranked Set Sampling
- Step 1: From the target population, choose n random samples of size n units each.
- Step 2: In each sample, rank the units according to a variable of interest.
- Step 3: If the sample has an OSS, choose the th lowest ranked unit, i.e., the sample’s median, for measurement from each sample. In the case of an ESS, withdraw from the first samples the th smallest ranked unit, and withdraw from the second samples the th smallest ranked unit.
- Step 4: To generate a sample of size units from MRSS (OSS) data, repeat the cycle times as necessary.
3. Lomax and Inverse Lomax Models
3.1. Expression of R1 for First Model
3.2. Expression of R2 for Second Model
4. Estimator of First Model
4.1. Estimator of R1 with OSS
4.2. Estimator of R1 with ESS
4.3. Estimator of
4.4. Estimator of
5. Estimator of Second Model
5.1. Estimator of R2 with OSS
5.2. Estimator of R2 with ESS
5.3. Estimator of
5.4. Estimator of
6. Simulation Illustration
- The First Model
- Step 1: We generate 1000 MRSS for both stress and strength random variables using Lo distributions.
- MRSS scheme with OSS is selected as: and , where set sizes () = (3, 3), (5, 5), (7, 7) with cycles numbers and the size of sample = (15, 15), (25, 25), (35, 35).
- MRSS scheme with ESS is selected as: and , where set sizes () = (2, 2), (4, 4), (6, 6), with cycles numbers s = sx = sy = 5 and the size of sample = (10, 10),(20, 20),(30, 30).
- MRSS, when stress has OSS and strength has ESS, is selected as: , where set sizes () = (2, 3) and (4, 3) with cycles numbers and the size of sample = (10, 15), (20, 15).
- MRSS, when stress has ESS and strength has OSS, is selected as: , where set sizes () = (3, 2) and (3, 4) with cycles numbers and the size of sample = (15, 10), (15, 20).
- The Second Model
- Step 2: We generate 1000 MRSS for strength random variable with Lo distribution and stress random variable with ILo distribution.
- MRSS with OSS scheme is selected as: and , where set sizes () = (3, 3), (5, 5), (7, 7) with cycles numbers s = sx = sz = 5 and size of sample = (15, 15), (25, 25), (35, 35).
- MRSS with ESS scheme is selected as: and , where set sizes () = (2, 2), (4, 4), (6, 6), with cycles numbers s = sx = sz = 5 and size of sample = (10, 10), (20, 20), (30, 30).
- MRSS, when stress (Z) with ESS and strength (X) with OSS scheme, is selected as:
- , where set sizes () = (3, 2) and (3, 4) with cycles numbers s = sx = sz = 5 and size of sample = (15, 10), (15, 20).
- MRSS, when stress (Z) has OSS and strength (X) has ESS, is selected as:
- and , where set sizes () = (2, 3) and (4, 3) with cycles numbers s = sx = sz = 5 and size of sample (10, 15), (20, 15).
- Step 3: The true values of the reliability function R = R1 = R2 are selected as R = 0.525, 0.608, 0.71, 0.838, and 0.982 for both models.
- Step 4: The ML estimates of parameters in Section 4.1, Section 4.2, Section 4.3 and Section 4.4 are obtained by numerically solving Equations after setting them to zero using the Newton–Raphson method. Consequently, the system reliability is derived after setting these estimates in (6) in each case.
- Step 5: The ML estimates of parameters in Section 5.1, Section 5.2, Section 5.3 and Section 5.4 are obtained by numerically solving Equations after setting them to zero using the Newton–Raphson method. Consequently, the system reliability is derived after setting these estimates in (9) for each case.
- Step 6: Some comparison criteria are selected, including absolute biases (ABs), mean squared errors (MSEs), and relative efficiency (RE) for the first model with respect to the second model, which are all defined by:
- Numerical Results
- The MSE of in the second model is less than that of the first model at true values and 0.608. However, the MSE of in the first model is less than that of the second model at R = 0.71, 0.525, and 0.838 except at (3, 3) (as shown in Table 3).
- In case of dissimilarity, the MSE of in the second model is less than that of the first model for all true values except for R = 0.525 at set size (3, 2) (see Table 6).
- In case of strength with ESS and stress with OSS, the MSE of is less than the MSE of for all true values of R except (R = 0.838) with set size (3,2) (see Table 6).
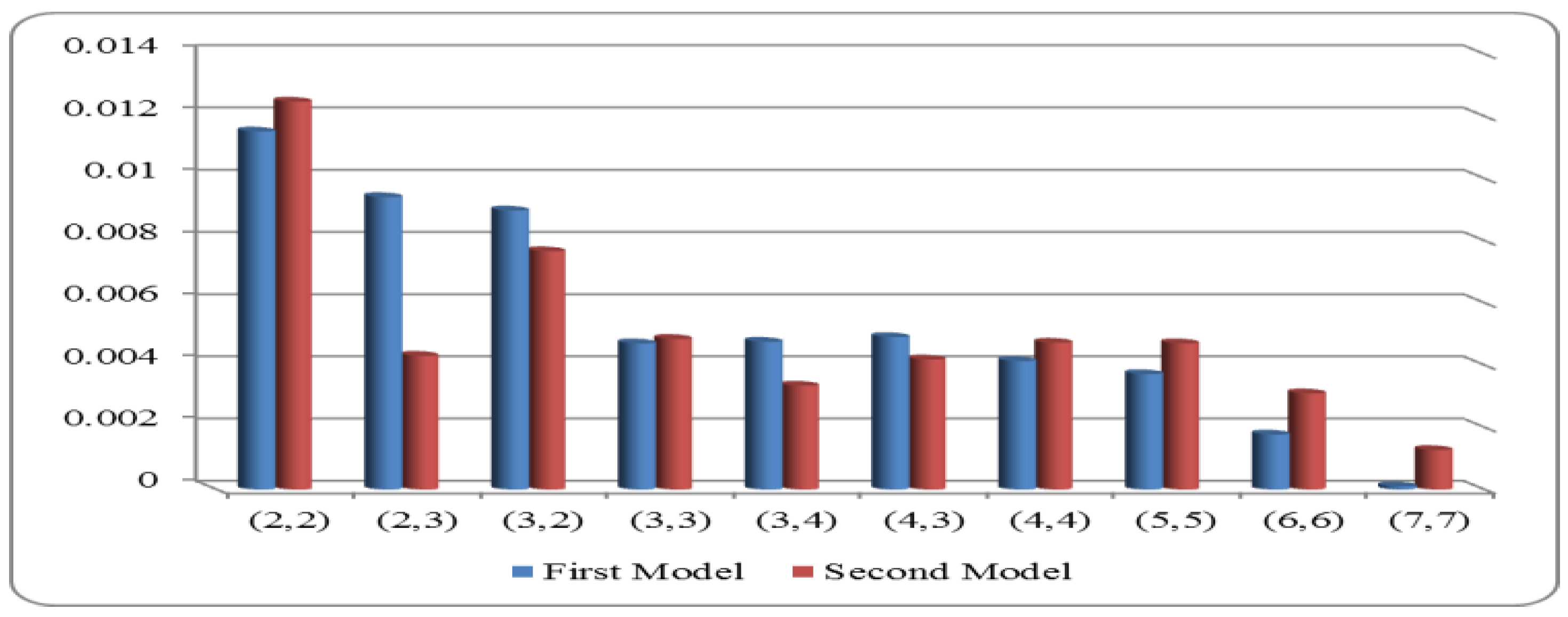
- Figure 2 shows that the MSE of is less than for all set sizes at R = 0.608.
- The MSE of the system reliability is less than for all OSS at R = 0.525, as shown in Figure 1.
- Figure 3 indicates that the MSE of the system reliability is less than for all similar set sizes (ESS and OSS) at R = 0.71.
7. Real Data Applications
- Data I (X):
| 6.53 | 7 | 10.42 | 14.48 | 16.1 | 22.7 | 34 | 41.55 | 42 | 45.28 | 49.4 | 53.62 |
| 63 | 64 | 83 | 84 | 91 | 108 | 112 | 129 | 133 | 133 | 139 | 140 |
| 140 | 146 | 149 | 154 | 157 | 160 | 160 | 165 | 146 | 149 | 154 | 157 |
| 160 | 160 | 165 | 173 | 176 | 218 | 225 | 241 | 248 | 273 | 277 | 297 |
| 405 | 417 | 420 | 440 | 523 | 583 | 594 | 1101 | 1146 | 1417 |
- Data II (Y, Z):
| 12.2 | 23.56 | 23.74 | 25.87 | 31.98 | 37 | 41.35 | 47.38 | 55.46 | 58.36 |
| 63.47 | 68.46 | 78.26 | 74.47 | 81.43 | 84 | 92 | 94 | 110 | 112 |
| 119 | 127 | 130 | 133 | 140 | 146 | 155 | 159 | 173 | 179 |
| 194 | 195 | 209 | 249 | 281 | 319 | 339 | 432 | 469 | 519 |
| 633 | 725 | 817 | 1776 |
8. Conclusions and Summary
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Birnbaum, Z. On a use of the Mann-Whitney statistic. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Berkley, CA, USA, 26–31 December 1956; pp. 13–17. [Google Scholar]
- Downton, F. The estimation of Pr(Y< X) in the normal case. Technometrics 1973, 15, 551–558. [Google Scholar]
- Constantine, K.; Tse, S.-K.; Karson, M. Estimation of P (Y<X) in the gamma case. Commun. Stat. Simul. Comput. 1986, 15, 365–388. [Google Scholar]
- Awad, A.M.; Gharraf, M.K. Estimation of P(Y<X) in the Burr case: A comparative study. Commun. Stat. Simul. Comput. 1986, 15, 389–403. [Google Scholar]
- Kundu, D.; Gupta, R.D. Estimation of P[Y<X] for generalized exponential distribution. Metrika 2005, 61, 291–308. [Google Scholar]
- Kundu, D.; Gupta, R.D. Estimation of P[Y<X] for Weibull distributions. IEEE Trans. Reliab. 2006, 55, 270–280. [Google Scholar]
- Hassan, A.S.; Al-Sulami, D. Estimation of P[Y<X] in the case of exponentiated Weibull distribution. Egypt Stat. J. 2008, 52, 76–95. [Google Scholar]
- Rao, G.S.; Aslam, M.; Kundu, D. Burr-XII distribution parametric estimation and estimation of reliability of multicomponent stress-strength. Commun. Stat. Theory Methods 2015, 44, 4953–4961. [Google Scholar] [CrossRef]
- Rao, G.S.; Bhatti, F.A.; Aslam, M.; Albassam, M. Estimation of reliability in a multicomponent stress–strength system for the exponentiated moment-based exponential distribution. Algorithms 2019, 12, 246. [Google Scholar] [CrossRef] [Green Version]
- Kotz, S.; Pensky, M. The Stress-Strength Model and Its Generalizations: Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- McIntyre, G.A. A method for unbiased selective sampling, using ranked sets. Aust. J. Agric. Res. 1952, 3, 385–390. [Google Scholar] [CrossRef]
- Takahasi, K.; Wakimoto, K. On unbiased estimates of the population mean based on the sample stratified by means of ordering. Ann. Inst. Stat. Math. 1968, 20, 1–31. [Google Scholar] [CrossRef]
- Zamanzade, E. EDF-based tests of exponentiality in pair ranked set sampling. Stat. Pap. 2019, 60, 2141–2159. [Google Scholar] [CrossRef]
- Alghamdi, S.M.; Bantan, R.A.; Hassan, A.S.; Nagy, H.F.; Elbatal, I.; Elgarhy, M. Improved EDF-based tests for Weibull distribution using ranked set sampling. Mathematics 2022, 10, 4700. [Google Scholar] [CrossRef]
- Muttlak, H.A. Median ranked set sampling. J. Appl. Stat. Sci. 1997, 6, 245–255. [Google Scholar]
- Hajighorbani, S.; Aliakbari Saba, R. Stratified median ranked set sampling: Optimum and proportional allocations. J. Stat. Res. Iran JSRI 2012, 9, 87–102. [Google Scholar] [CrossRef] [Green Version]
- Sengupta, S.; Mukhuti, S. Unbiased estimation of P(X>Y) for exponential populations using order statistics with application in ranked set sampling. Commun. Stat. Theory Methods 2008, 37, 898–916. [Google Scholar] [CrossRef]
- Muttlak, H.A.; Abu-Dayyeh, W.A.; Saleh, M.F.; Al-Sawi, E. Estimating P(Y<X) using ranked set sampling in case of the exponential distribution. Commun. Stat. Theory Methods 2010, 39, 1855–1868. [Google Scholar]
- Akgül, F.G.; Şenoğlu, B. Estimation of P (X<Y) using ranked set sampling for the Weibull distribution. Qual. Technol. Quant. Manag. 2017, 14, 296–309. [Google Scholar]
- Akgül, F.G.; Acıtaş, Ş.; Şenoğlu, B. Inferences on stress–strength reliability based on ranked set sampling data in case of Lindley distribution. J. Stat. Comput. Simul. 2018, 88, 3018–3032. [Google Scholar] [CrossRef]
- Safariyan, A.; Arashi, M.; Arabi Belaghi, R. Improved point and interval estimation of the stress–strength reliability based on ranked set sampling. Statistics 2019, 53, 101–125. [Google Scholar] [CrossRef]
- Al-Omari, A.I.; Almanjahie, I.M.; Hassan, A.S.; Nagy, H.F. Estimation of the stress-strength reliability for exponentiated Pareto distribution using median and ranked set sampling methods. Comput. Mater. Contin. 2020, 64, 835–857. [Google Scholar]
- Esemen, M.; Gurler, S.; Sevinc, B. Estimation of stress–strength reliability based on ranked set sampling for generalized exponential distribution. Int. J. Reliab. Qual. Saf. Eng. 2021, 28, 2150011. [Google Scholar] [CrossRef]
- Hassan, A.S.; Al-Omari, A.I.; Nagy, H.F. Stress–Strength reliability for the generalized inverted exponential distribution using MRSS. Iran. J. Sci. Technol. Trans. A Sci. 2021, 45, 641–659. [Google Scholar] [CrossRef]
- Al-Omari, A.I.; Hassan, A.S.; Alotaibi, N.; Shrahili, M.; Nagy, H.F. Reliability estimation of inverse Lomax distribution using extreme ranked set sampling. Adv. Math. Phys. 2021, 2021, 4599872. [Google Scholar] [CrossRef]
- Yousef, M.M.; Hassan, A.S.; Al-Nefaie, A.H.; Almetwally, E.M.; Almongy, H.M. Bayesian estimation using MCMC method of system reliability for inverted Topp-Leone distribution based on ranked set sampling. Mathematics 2022, 10, 3122. [Google Scholar] [CrossRef]
- Hassan, A.S.; Elshaarawy, R.S.; Onyango, R.; Nagy, H.F. Estimating system reliability using neoteric and median RSS data for generalized exponential distribution. Int. J. Math. Math. Sci. 2022, 2022, 2608656. [Google Scholar] [CrossRef]
- Wu, W.; Wang, B.X.; Chen, J.; Miao, J.; Guan, Q. Interval estimation of the two-parameter exponential constant stress accelerated life test model under Type-II censoring. Qual. Technol. Quant. Manag. 2022. [Google Scholar] [CrossRef]
- Abbas, K.; Tang, Y. Objective Bayesian analysis of the Frechet stress–strength model. Stat. Probab. Lett. 2014, 84, 169–175. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, A.; An, L.; Li, M. Bayesian inference of system reliability for multicomponent stress-strength model under Marshall-Olkin Weibull distribution. Systems 2022, 10, 196. [Google Scholar] [CrossRef]
- Zhuang, L.; Xu, A.; Wang, B.; Xue, Y.; Zhang, S. Data analysis of progressive-stress accelerated life tests with group effects. Qual. Technol. Quant. Manag. 2022. [Google Scholar] [CrossRef]
- Bryson, M.C. Heavy-tailed distributions: Properties and tests. Technometrics 1974, 16, 61–68. [Google Scholar] [CrossRef]
- Balkema, A.A.; De Haan, L. Residual life time at great age. Ann. Probab. 1974, 2, 792–804. [Google Scholar] [CrossRef]
- Chahkandi, M.; Ganjali, M. On some lifetime distributions with decreasing failure rate. Comput. Stat. Data Anal. 2009, 53, 4433–4440. [Google Scholar] [CrossRef]
- Hassan, A.S.; Al-Ghamdi, A.S. Optimum step stress accelerated life testing for Lomax distribution. J. Appl. Sci. Res. 2009, 51, 2153–2164. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; John Wiley & Sons, Inc.: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Ahsanullah, M. Record values of the Lomax distribution. Stat. Neerl. 1991, 45, 21–29. [Google Scholar] [CrossRef]
- Hassan, A.S.; Zaky, A.N. Entropy Bayesian estimation for Lomax distribution based on record. Thail. Stat. 2021, 19, 95–114. [Google Scholar]
- Helmy, B.A.; Hassan, A.S.; El-Kholy, A.K. Analysis of uncertainty measure using unified hybrid censored data with applications. J. Taibah Univ. Sci. 2021, 15, 1130–1143. [Google Scholar] [CrossRef]
- Kleiber, C.; Kotz, S. Statistical Size Distributions in Economics and Actuarial Sciences; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003; Volume 470. [Google Scholar]
- Ge, S.; McKenzie, J.; Voss, C.; Wu, Q. Exchange of groundwater and surface-water mediated by permafrost response to seasonal and long term air temperature variation. Geophys. Res. Lett. 2011, 38, 1–6. [Google Scholar] [CrossRef] [Green Version]
- Singh, S.K.; Singh, U.; Yadav, A.S. Reliability estimation for inverse Lomax distribution under type Π censored data using Markov chain Monte Carlo method. Int. J. Math. Stat. 2016, 17, 128–146. [Google Scholar]
- Yadav, A.S.; Singh, S.K.; Singh, U. On hybrid censored inverse Lomax distribution: Application to the survival data. Statistica 2016, 76, 185–203. [Google Scholar]
- Efron, B. Logistic regression, survival analysis, and the Kaplan-Meier curve. J. Am. Stat. Assoc. 1988, 83, 414–425. [Google Scholar] [CrossRef]
- Hassan, A.S.; Nagy, H.F. Reliability estimation in multicomponent stress-strength for generalized inverted exponential distribution based on ranked set sampling. Gazi Univ. J. Sci. 2022, 35, 314–331. [Google Scholar]
- Hassan, A.S.; Nagy, H.F.; Muhammed, H.Z.; Saad, M.S. Estimation of multicomponent stress-strength reliability following Weibull distribution based on upper record values. J. Taibah Univ. Sci. 2020, 14, 244–253. [Google Scholar] [CrossRef] [Green Version]
- Hassan, A.S.; Elshaarawy, R.S.; Nagy, H.F. Parameter estimation of exponentiated exponential distribution under selective ranked set sampling. Stat. Transit. New Ser. 2022, 23, 37–58. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| All Observations | Selected Samples | ||||
|---|---|---|---|---|---|
| X1(1) | X1(v) | X1(n) | X1(v) | ||
| Xv−1(1) | Xv−1(v) | Xv−1(n) | Xv−1(v) | ||
| Xv(1) | Xv(v) | Xv(n) | Xv(v) | ||
| Xn−1(1) | Xn−1(v) | Xn−1(n) | Xv−1(v) | ||
| Xn(1) | Xn(v) | Xn(n) | Xn(v) | ||
| All Observations | Selected Samples | |||||
|---|---|---|---|---|---|---|
| X1(1) | X1(b) | X1(b+1) | X1(n) | X1(b) | ||
| Xb(1) | Xb(b) | Xb(b+1) | Xb(n) | Xb(b) | ||
| Xb+1(1) | Xb+1(b) | Xb+1(b+1) | Xb+1 (n) | Xb+1(b+1) | ||
| Xn(1) | Xn(b) | Xn(b+1) | Xn(n) | Xn(b+1) | ||
|
(n1, n2) (n1, n3) | True R | First Model | Second Model | RE | ||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | |||||
| (3, 3) | 0.982 | 0.96024 | 0.02166 | 0.00104 | 0.99058 | 0.00858 | 0.00003 | 34.67 |
| (5, 5) | 0.98457 | 0.00257 | 0.00014 | 0.97239 | 0.00961 | 0.00001 | 14.00 | |
| (7, 7) | 0.99015 | 0.00825 | 0.00011 | 0.98537 | 0.00337 | 0.00001 | 11.00 | |
| (3, 3) | 0.838 | 0.77398 | 0.06389 | 0.00677 | 0.88606 | 0.04819 | 0.00393 | 1.72 |
| (5, 5) | 0.84373 | 0.00574 | 0.00217 | 0.88288 | 0.04501 | 0.00318 | 0.68 | |
| (7, 7) | 0.85776 | 0.01989 | 0.00044 | 0.85442 | 0.01655 | 0.00093 | 0.47 | |
| (3, 3) | 0.71 | 0.76275 | 0.05252 | 0.00470 | 0.75806 | 0.04783 | 0.00484 | 0.97 |
| (5, 5) | 0.71950 | 0.00927 | 0.00371 | 0.76365 | 0.05343 | 0.00470 | 0.79 | |
| (7, 7) | 0.70000 | 0.01023 | 0.00010 | 0.72248 | 0.01226 | 0.00127 | 0.08 | |
| (3, 3) | 0.608 | 0.52167 | 0.08643 | 0.00908 | 0.74632 | 0.03609 | 0.00510 | 1.78 |
| (5, 5) | 0.61885 | 0.01070 | 0.00416 | 0.62782 | 0.01973 | 0.00261 | 1.59 | |
| (7, 7) | 0.60530 | 0.00285 | 0.00226 | 0.60895 | 0.00086 | 0.00130 | 1.74 | |
| (3, 3) | 0.525 | 0.51710 | 0.00814 | 0.00283 | 0.56285 | 0.03764 | 0.00605 | 0.47 |
| (5, 5) | 0.51258 | 0.01266 | 0.00071 | 0.54453 | 0.01932 | 0.00361 | 0.20 | |
| (7, 7) | 0.50915 | 0.01610 | 0.00048 | 0.52627 | 0.00106 | 0.00118 | 0.41 | |
|
(n1, n2) (n1, n3) | True R | First Model | Second Model | RE | ||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | |||||
| (2, 2) | 0.982 | 0.93803 | 0.04387 | 0.00480 | 0.96686 | 0.01514 | 0.00058 | 8.28 |
| (4, 4) | 0.99142 | 0.00952 | 0.00015 | 0.98849 | 0.00649 | 0.00002 | 7.50 | |
| (6, 6) | 0.98235 | 0.00035 | 0.00011 | 0.98712 | 0.00512 | 0.00001 | 11.00 | |
| (2, 2) | 0.838 | 0.76102 | 0.07685 | 0.01825 | 0.81638 | 0.02149 | 0.00535 | 3.41 |
| (4, 4) | 0.83720 | 0.00068 | 0.00261 | 0.88852 | 0.05065 | 0.00356 | 0.73 | |
| (6, 6) | 0.84532 | 0.00733 | 0.00124 | 0.86985 | 0.03198 | 0.00248 | 0.50 | |
| (2, 2) | 0.71 | 0.72385 | 0.01362 | 0.01151 | 0.63840 | 0.07183 | 0.01247 | 0.92 |
| (4, 4) | 0.75943 | 0.04920 | 0.00413 | 0.72616 | 0.01593 | 0.00472 | 0.88 | |
| (6, 6) | 0.71257 | 0.00234 | 0.00177 | 0.74404 | 0.03381 | 0.00309 | 0.57 | |
| (2, 2) | 0.608 | 0.63588 | 0.02773 | 0.01371 | 0.59726 | 0.01083 | 0.01177 | 1.16 |
| (4, 4) | 0.54436 | 0.06374 | 0.00427 | 0.62976 | 0.02167 | 0.00426 | 1.00 | |
| (6, 6) | 0.57038 | 0.03771 | 0.00370 | 0.63634 | 0.02825 | 0.00175 | 2.11 | |
| (2, 2) | 0.525 | 0.56868 | 0.04347 | 0.01729 | 0.50611 | 0.01910 | 0.00981 | 1.76 |
| (4, 4) | 0.53195 | 0.00674 | 0.00459 | 0.58016 | 0.05495 | 0.00563 | 0.82 | |
| (6, 6) | 0.51445 | 0.01079 | 0.00064 | 0.57413 | 0.04891 | 0.00352 | 0.18 | |
|
(n1, n2) (n1, n3) | True R | First Model | Second Model | RE | ||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | |||||
| (2, 3) | 0.982 | 0.9528 | 0.0292 | 0.0016 | 0.9846 | 0.0026 | 0.00004 | 40.00 |
| (4, 3) | 0.9558 | 0.0261 | 0.0011 | 0.9872 | 0.0015 | 0.00001 | 110.00 | |
| (2, 3) | 0.838 | 0.7936 | 0.0443 | 0.0067 | 0.7910 | 0.0469 | 0.00460 | 1.46 |
| (4, 3) | 0.8088 | 0.0290 | 0.0026 | 0.8106 | 0.0272 | 0.00324 | 0.80 | |
| (2, 3) | 0.71 | 0.6500 | 0.0603 | 0.0094 | 0.6730 | 0.0372 | 0.00430 | 2.19 |
| (4, 3) | 0.6712 | 0.0391 | 0.0049 | 0.7388 | 0.0285 | 0.00418 | 1.17 | |
| (2, 3) | 0.608 | 0.5539 | 0.0542 | 0.0072 | 0.5957 | 0.0124 | 0.00310 | 2.32 |
| (4, 3) | 0.5716 | 0.0365 | 0.0042 | 0.6163 | 0.0082 | 0.00281 | 1.49 | |
| (2, 3) | 0.525 | 0.4905 | 0.0347 | 0.0060 | 0.5229 | 0.0023 | 0.00380 | 1.58 |
| (4, 3) | 0.5008 | 0.0244 | 0.0040 | 0.5218 | 0.0035 | 0.00375 | 1.07 | |
|
(n1, n2) (n1, n3) | True R | First Model | Second Model | RE | ||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | |||||
| (3, 2) | 0.982 | 0.95787 | 0.02403 | 0.00120 | 0.99079 | 0.00879 | 0.00003 | 40.00 |
| (3, 4) | 0.95881 | 0.02309 | 0.00109 | 0.98603 | 0.00403 | 0.00002 | 54.50 | |
| (3, 2) | 0.838 | 0.79422 | 0.04366 | 0.00858 | 0.87494 | 0.03706 | 0.00373 | 2.30 |
| (3, 4) | 0.79285 | 0.04503 | 0.00609 | 0.89043 | 0.05255 | 0.00387 | 1.57 | |
| (3, 2) | 0.71 | 0.68619 | 0.02404 | 0.00897 | 0.74987 | 0.03965 | 0.00766 | 1.17 |
| (3, 4) | 0.67922 | 0.03101 | 0.00475 | 0.74780 | 0.03758 | 0.00334 | 1.42 | |
| (3, 2) | 0.608 | 0.60754 | 0.00056 | 0.01069 | 0.64849 | 0.04041 | 0.00894 | 1.20 |
| (3, 4) | 0.59465 | 0.01345 | 0.00468 | 0.64240 | 0.03431 | 0.00443 | 1.06 | |
| (3, 2) | 0.525 | 0.51268 | 0.01256 | 0.00876 | 0.64921 | 0.04112 | 0.00979 | 0.89 |
| (3, 4) | 0.51665 | 0.00859 | 0.00654 | 0.55037 | 0.02516 | 0.00424 | 1.54 | |
| (n1, n2) (n1, n3) | True R | First Model | Second Model | RE | ||||
|---|---|---|---|---|---|---|---|---|
| AB | MSE | AB | MSE | |||||
| (2, 2) | 0.525 | 0.56868 | 0.04347 | 0.01729 | 0.50611 | 0.01910 | 0.00981 | 1.76 |
| (2, 3) | 0.49050 | 0.03470 | 0.00600 | 0.52290 | 0.00230 | 0.00380 | 1.58 | |
| (3, 2) | 0.51268 | 0.01256 | 0.00876 | 0.64921 | 0.04112 | 0.00979 | 0.89 | |
| (3, 3) | 0.51710 | 0.00814 | 0.00283 | 0.56285 | 0.03764 | 0.00605 | 0.47 | |
| (3, 4) | 0.51665 | 0.00859 | 0.00654 | 0.55037 | 0.02516 | 0.00424 | 1.54 | |
| (4, 3) | 0.50080 | 0.02440 | 0.00400 | 0.52175 | 0.00346 | 0.00375 | 1.07 | |
| (4, 4) | 0.53195 | 0.00674 | 0.00459 | 0.58016 | 0.05495 | 0.00563 | 0.82 | |
| (5, 5) | 0.51258 | 0.01266 | 0.00071 | 0.54453 | 0.01932 | 0.00361 | 0.20 | |
| (6, 6) | 0.51445 | 0.01079 | 0.00064 | 0.57413 | 0.04891 | 0.00352 | 0.18 | |
| (7, 7) | 0.50915 | 0.01610 | 0.00048 | 0.52627 | 0.00106 | 0.00118 | 0.41 | |
| (2, 2) | 0.608 | 0.63588 | 0.02773 | 0.01371 | 0.59726 | 0.01083 | 0.01177 | 1.16 |
| (2, 3) | 0.55390 | 0.05420 | 0.00720 | 0.59570 | 0.01240 | 0.00310 | 2.32 | |
| (3, 2) | 0.60754 | 0.00056 | 0.01069 | 0.64849 | 0.04041 | 0.00894 | 1.20 | |
| (3, 3) | 0.52167 | 0.08643 | 0.00908 | 0.74632 | 0.03609 | 0.00510 | 1.78 | |
| (3, 4) | 0.59465 | 0.01345 | 0.00468 | 0.64240 | 0.03431 | 0.00443 | 1.06 | |
| (4, 3) | 0.57160 | 0.03650 | 0.00420 | 0.61624 | 0.008152 | 0.00280 | 1.50 | |
| (4, 4) | 0.54436 | 0.06374 | 0.00427 | 0.62976 | 0.02167 | 0.00426 | 1.00 | |
| (5, 5) | 0.61885 | 0.01070 | 0.00416 | 0.62782 | 0.01973 | 0.00261 | 1.59 | |
| (6, 6) | 0.57038 | 0.03771 | 0.00370 | 0.63634 | 0.02825 | 0.00175 | 2.11 | |
| (7, 7) | 0.60530 | 0.00285 | 0.00226 | 0.60895 | 0.00086 | 0.00130 | 1.74 | |
| (2, 2) | 0.71 | 0.72385 | 0.01362 | 0.01151 | 0.63840 | 0.07183 | 0.01247 | 0.92 |
| (2, 3) | 0.65000 | 0.06030 | 0.00940 | 0.67300 | 0.03720 | 0.00430 | 2.19 | |
| (3, 2) | 0.68619 | 0.02404 | 0.00897 | 0.74987 | 0.03965 | 0.00766 | 1.17 | |
| (3, 3) | 0.76275 | 0.05252 | 0.00470 | 0.75806 | 0.04783 | 0.00484 | 0.97 | |
| (3, 4) | 0.67922 | 0.03101 | 0.00475 | 0.74780 | 0.03758 | 0.00334 | 1.42 | |
| (4, 3) | 0.67120 | 0.03910 | 0.00490 | 0.73876 | 0.02853 | 0.00418 | 1.17 | |
| (4, 4) | 0.75943 | 0.04920 | 0.00413 | 0.72616 | 0.01593 | 0.00472 | 0.88 | |
| (5, 5) | 0.71950 | 0.00927 | 0.00371 | 0.76365 | 0.05343 | 0.00470 | 0.79 | |
| (6, 6) | 0.71257 | 0.00234 | 0.00177 | 0.74404 | 0.03381 | 0.00309 | 0.57 | |
| (7, 7) | 0.70000 | 0.01023 | 0.00010 | 0.72248 | 0.01226 | 0.00127 | 0.08 | |
| (2, 2) | 0.838 | 0.76102 | 0.07685 | 0.01825 | 0.81638 | 0.02149 | 0.00535 | 3.41 |
| (2, 3) | 0.79360 | 0.04430 | 0.00670 | 0.79100 | 0.04690 | 0.00460 | 1.46 | |
| (3, 2) | 0.79422 | 0.04366 | 0.00858 | 0.87494 | 0.03706 | 0.00373 | 2.30 | |
| (3, 3) | 0.77398 | 0.06389 | 0.00677 | 0.88606 | 0.04819 | 0.00393 | 1.72 | |
| (3, 4) | 0.79285 | 0.04503 | 0.00609 | 0.89043 | 0.05255 | 0.00387 | 1.57 | |
| (4, 3) | 0.80880 | 0.02900 | 0.00260 | 0.81064 | 0.02723 | 0.00324 | 0.80 | |
| (4, 4) | 0.83720 | 0.00068 | 0.00261 | 0.88852 | 0.05065 | 0.00356 | 0.73 | |
| (5, 5) | 0.84373 | 0.00574 | 0.00217 | 0.88288 | 0.04501 | 0.00318 | 0.68 | |
| (6, 6) | 0.84532 | 0.00733 | 0.00124 | 0.86985 | 0.03198 | 0.00248 | 0.50 | |
| (7, 7) | 0.85776 | 0.01989 | 0.00044 | 0.85442 | 0.01655 | 0.00093 | 0.47 | |
| (2, 2) | 0.982 | 0.93803 | 0.04387 | 0.00480 | 0.96686 | 0.01514 | 0.00058 | 8.28 |
| (2, 3) | 0.95280 | 0.02920 | 0.00160 | 0.98458 | 0.00258 | 0.00004 | 40.00 | |
| (3, 2) | 0.95787 | 0.02403 | 0.00120 | 0.99080 | 0.00879 | 0.00003 | 40.00 | |
| (3, 3) | 0.96024 | 0.02166 | 0.00104 | 0.99070 | 0.00858 | 0.00003 | 34.67 | |
| (3, 4) | 0.95881 | 0.02309 | 0.00109 | 0.98603 | 0.00403 | 0.00002 | 54.50 | |
| (4, 3) | 0.95580 | 0.02610 | 0.00110 | 0.98721 | 0.00148 | 0.00001 | 110.00 | |
| (4, 4) | 0.99142 | 0.00952 | 0.00015 | 0.98849 | 0.00649 | 0.00002 | 7.50 | |
| (5, 5) | 0.98457 | 0.00257 | 0.00014 | 0.97239 | 0.00961 | 0.00001 | 14.00 | |
| (6, 6) | 0.98235 | 0.00035 | 0.00011 | 0.98712 | 0.00512 | 0.00001 | 11.00 | |
| (7, 7) | 0.99015 | 0.00825 | 0.00011 | 0.98537 | 0.00337 | 0.00001 | 11.00 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, A.S.; Almanjahie, I.M.; Al-Omari, A.I.; Alzoubi, L.; Nagy, H.F. Stress–Strength Modeling Using Median-Ranked Set Sampling: Estimation, Simulation, and Application. Mathematics 2023, 11, 318. https://doi.org/10.3390/math11020318
Hassan AS, Almanjahie IM, Al-Omari AI, Alzoubi L, Nagy HF. Stress–Strength Modeling Using Median-Ranked Set Sampling: Estimation, Simulation, and Application. Mathematics. 2023; 11(2):318. https://doi.org/10.3390/math11020318
Chicago/Turabian StyleHassan, Amal S., Ibrahim M. Almanjahie, Amer Ibrahim Al-Omari, Loai Alzoubi, and Heba Fathy Nagy. 2023. "Stress–Strength Modeling Using Median-Ranked Set Sampling: Estimation, Simulation, and Application" Mathematics 11, no. 2: 318. https://doi.org/10.3390/math11020318