4. Numerical Example and Discussion
We used a fifth order fluid catalytic reactor example [
39] to analyze X-TFC’s ability to solve the MDRE and MDLE. This example was selected because it was also used by Nguyen and Gajic [
15]. Thus, a fairer comparison with their approach is easier to draw. Matrices
and
are given by
and
The cost weighting matrices are
and
, where
is the identity matrix. Furthermore, the terminal position penalty matrix is given as
Lastly, the final time was
s. The X-TFC method for solving this problem’s MDRE and MDLE was coded by us in MATLAB
® R2021a and run with an Intel Core i7-9700 CPU PC with 64 GB of RAM. In addition, the open-source MATLAB AD software called ADiGator [
40] was used to compute the Jacobians.
Multiple hyperparameters were tuned while testing X-TFC’s ability to solve the MDRE and MDLE. Examples include the type of activation function, the number of neurons, the input weight and bias distributions, the number of training points, and the subinterval period length. The activation functions tested included those that are common in the literature (e.g., sigmoid, hyperbolic tangent, Gaussian, rectified linear unit, etc.). Eventually, we found that the gaussian activation seemed to perform the best. Likewise, 15 neurons were found to be suitable for the SLFNN in the constrained expression of each subinterval. Furthermore, 20 CGL points were used to discretize the domain along each subinterval (i.e., training points). The CGL points are not equidistant and provide more points near the domain’s boundary. It was found that the gradients of the MDRE and MDLE solutions were the sharpest near the terminal end of the domain. Thus, utilizing the CGL points for training points instead of equidistant points enabled a better approximation near the end of the domain (i.e., the Runge phenomenon was avoided).
The input weight and bias distributions were tested with a randomized uniform distribution and a deterministic low-dispersion one-dimensional Halton sequence. The robustness of the X-TFC algorithm was shown by performing a 100-run Monte Carlo simulation where the uniform input weights and biases varied. On the other hand, the deterministic Halton sequence typically covers a bounded region more uniformly and densely when few points are used (remember, we only have 15 neurons in each SLFNN). Thus, we hypothesized that distributing the input weights and biases with a Halton sequence may exude a more accurate solution, and we wished to test it. Whether a uniform distribution or Halton sequence was used, the input weights and biases were bounded by and , respectively.
Considerable time was taken exploring the size of a subinterval
h. As expected, larger subintervals meant the X-TFC constrained expressions failed to approximate the MDRE and MDLE solutions accurately. Indeed, a global constrained expression with large
N and
L values resulted in singular
and
matrices within Equations (
32) and (
35). A subinterval period of
s,
, and
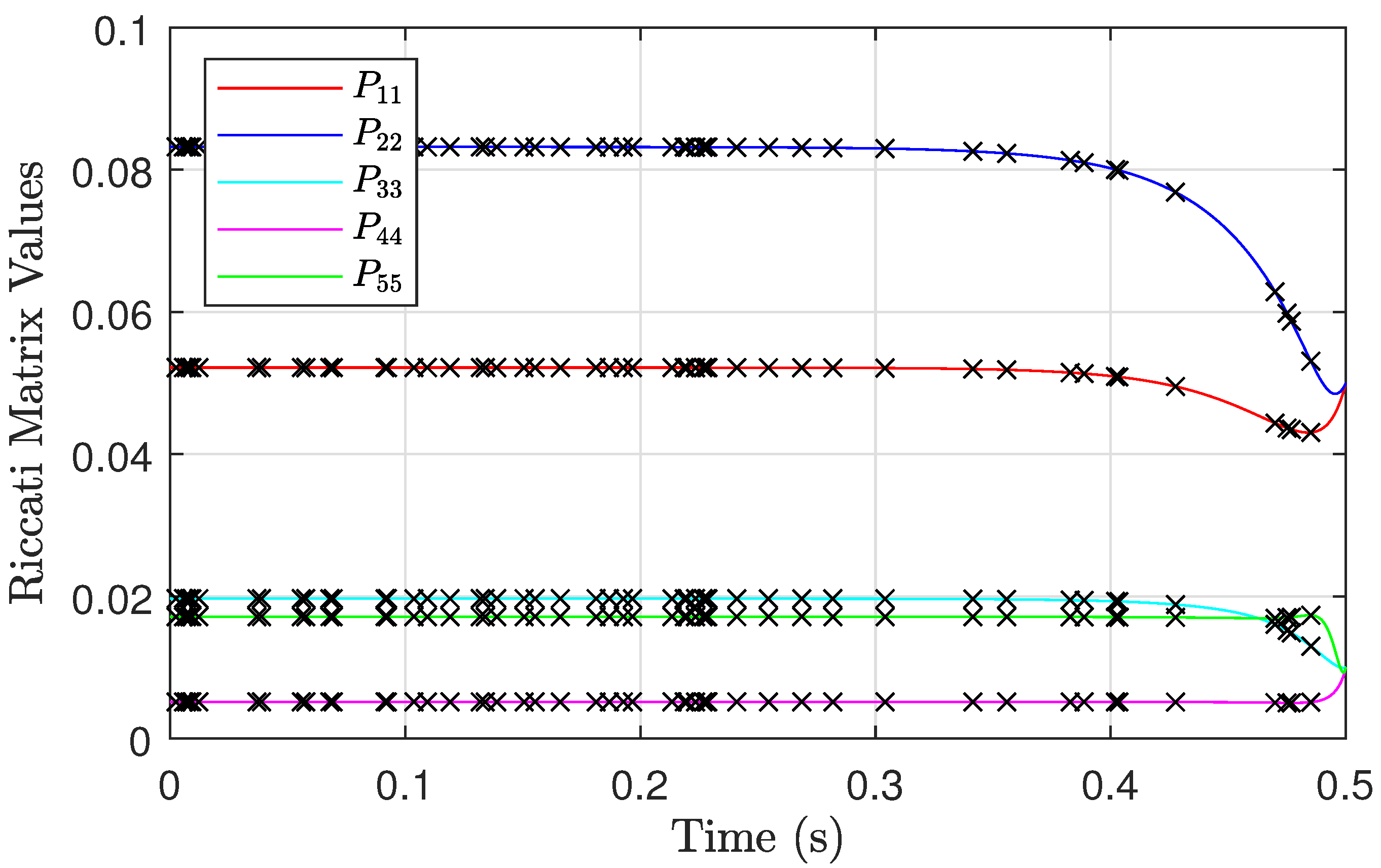
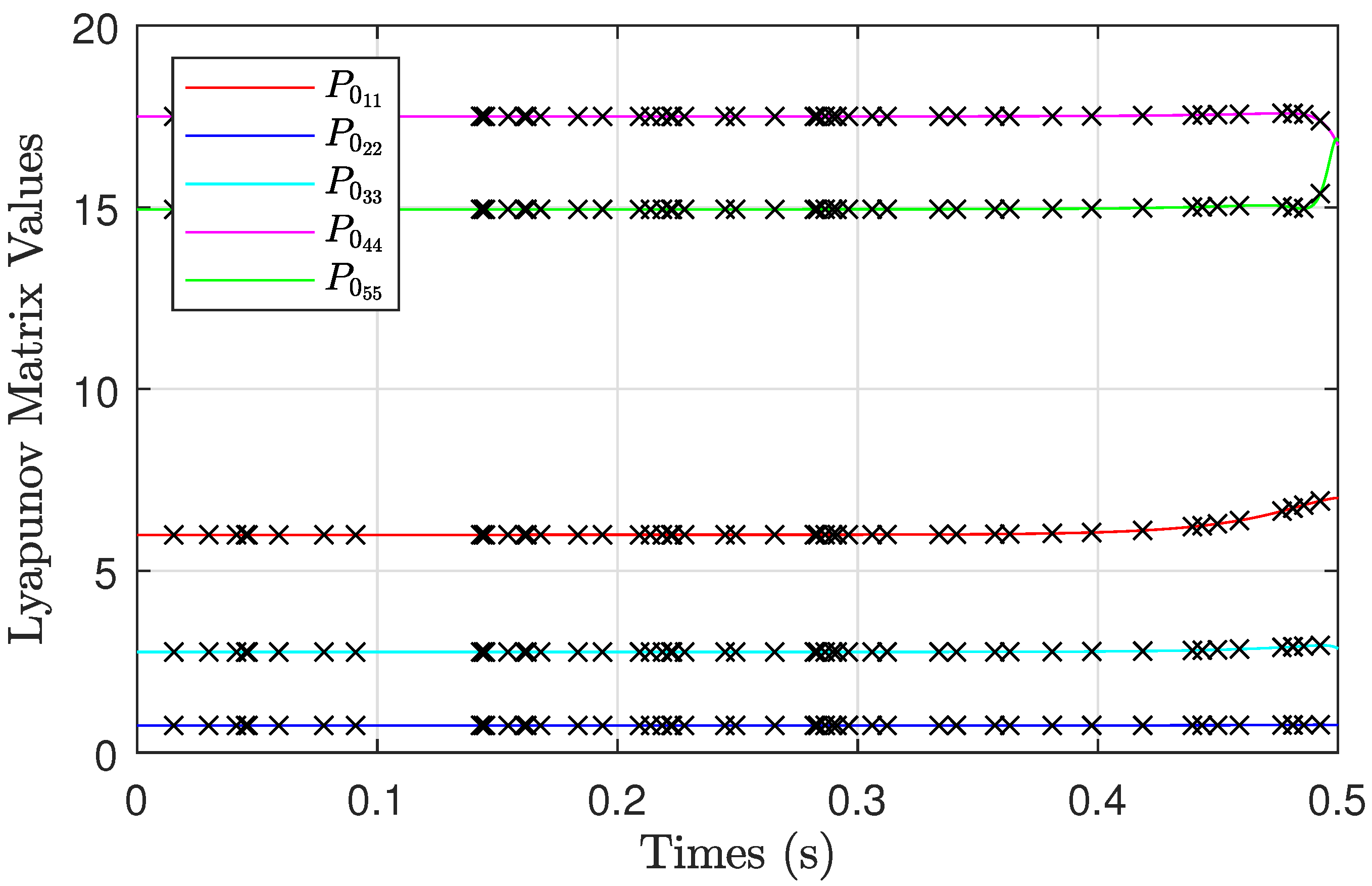
provided near-perfect results. The MDRE and MDLE trajectories when such a value of
h was used are presented in
Figure 2 and
Figure 3. The predicted values of the PINN, once it was trained, are also shown in those two figures. As one can see, the predicted values at various time instances (i.e., test points never seen before by the PINN during training) for both the Riccati and Lyapunov diagonal elements match up with the trained solution. This is important because the main benefit of using X-TFC to solve the MDRE or MDLE is that the combined constrained expressions represent a closed-form analytical expression of the solution once trained and Theorem 1 is confirmed. Many other methods that numerically solve the MDRE or MDLE require interpolation between the discretization points (e.g., KE, RK4, and NG). One other thing worth mentioning is that a straight line initial guess similar to what is shown in
Figure 1 was used to generate
Figure 2 and
Figure 3.
Since our numerical example is taken from Reference [
15], we decided to use an identical benchmark as well: the Kalman–Englar (KE) method. More specifically, we computed the L1-normwise errors
. For comparison, these errors were computed from six methods: X-TFC to solve the MDRE with the weight and biases uniformly distributed (PI-MDRE unif.), X-TFC to solve the MDLE with the weight and biases uniformly distributed (PI-MDLE unif.), X-TFC to solve the MDRE with the weight and biases picked from the Halton sequence (PI-MDRE halt.), X-TFC to solve the MDLE with the weight and biases picked from the Halton sequence (PI-MDLE halt.), the Lyapunov approach from Nguyen and Gajic (NG), and the Runge–Kutta 4 method (RK4). When the input weights and biases are uniformly distributed, they are effectively randomized, and the algorithm’s performance will vary between runs. Hence, we performed a Monte Carlo simulation where the uniform distribution varied the input weights and biases. Since the Halton sequence is deterministic, a Monte Carlo simulation was not necessary to quantify its performance.
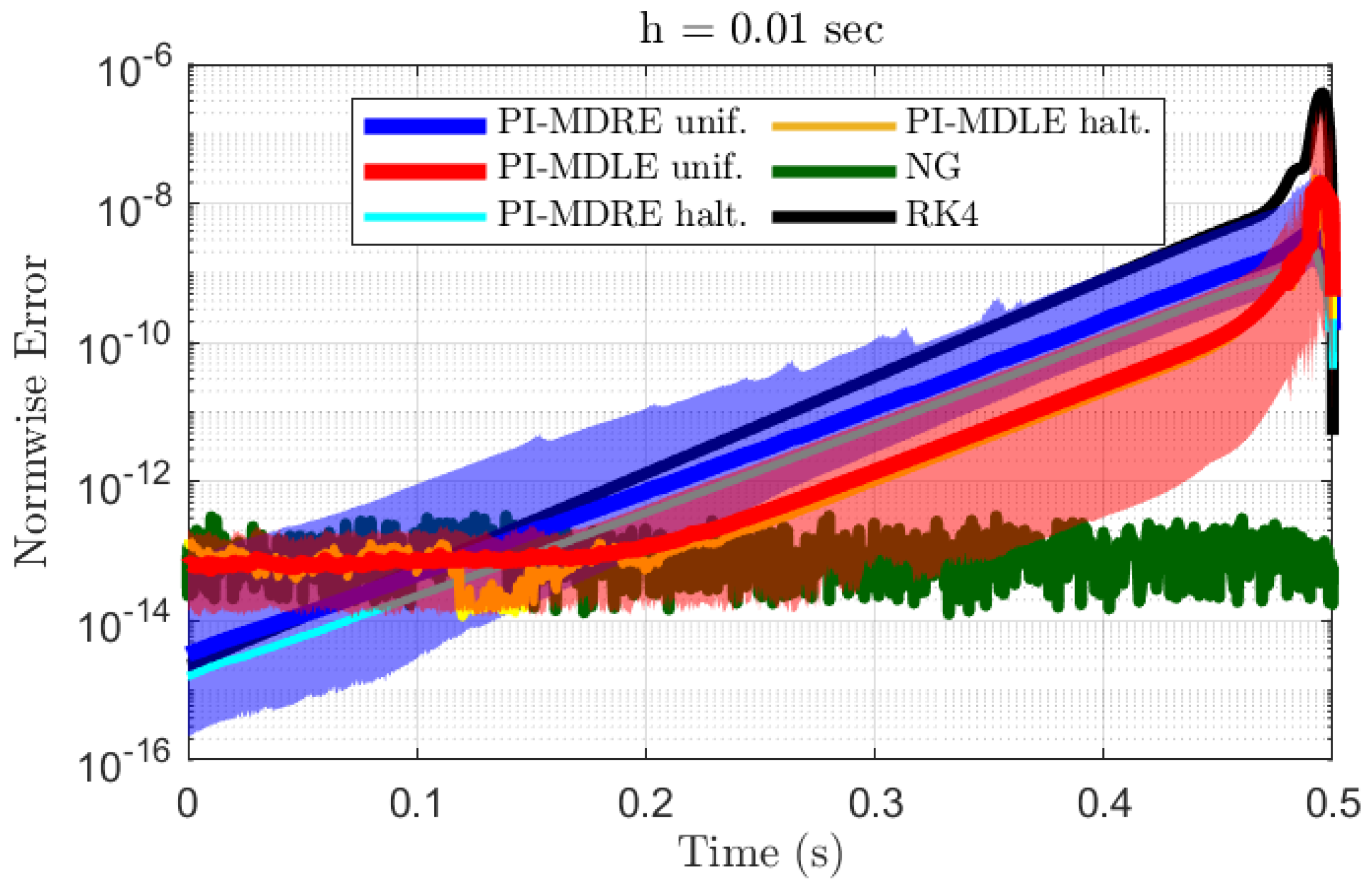
Figure 4 and
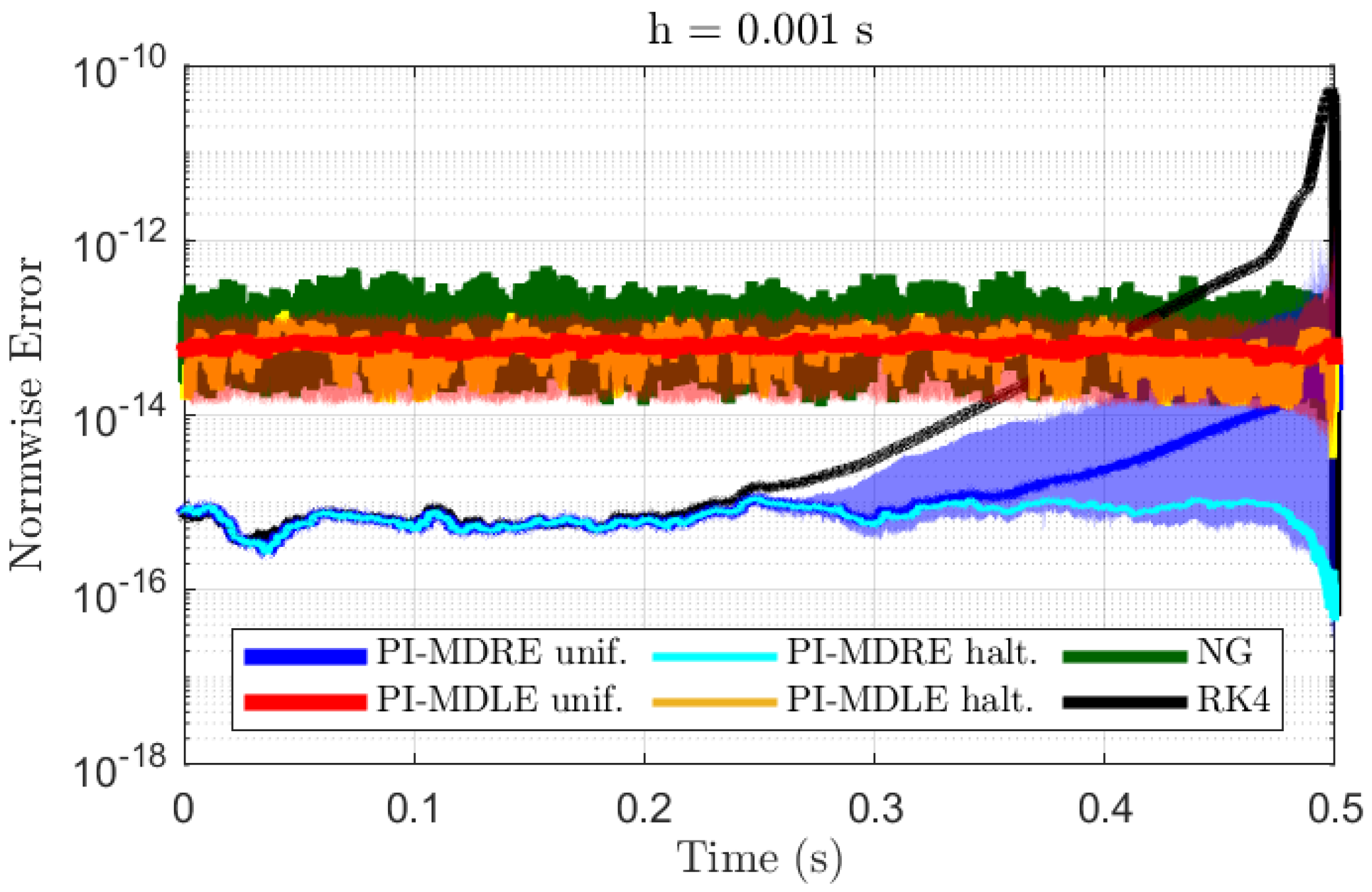
Figure 5 show the L1-normwise errors of the methods when the subinterval time span was selected as
and
s, respectively.
We can see from
Figure 4 that the NG method is more consistently close to the KE method when
s. The RK4 and PI-MDRE errors are larger near
but decrease below the NG errors once the MDRE solution approaches a straight line near
. The PI-MDLE errors follow the same trend, except that they mirror the NG error once they are at the same magnitude. Since the PI-MDLE methods approximate the MDLE used in the NG method, this is no surprise. The PI-MDLE errors remain better than RK4’s throughout the entire time domain, while the PI-MDRE unif. errors can be higher than RK4’s. However, if the weight and biases are selected with the Halton sequence, X-TFC is more accurate than RK4 when
s.
If
, then X-TFC starts to really shine in terms of accuracy. The PI-MDRE unif.’s maximum and PI-MDRE halt. errors were both better than the RK4 and NG errors. The PI-MDLE unif. and PI-MDLE halt. errors were only a slight improvement over NG’s. They did not vary as much between time increments, and their magnitude was slightly lower than the NG method. As can be seen from
Figure 2 and
Figure 3, the sharpest Riccati and Lyapunov matrix solutions are near
. This explains why the errors for most of the methods when
and RK4 when
were at their worst. Interestingly, the sharp gradients were well approximated by X-TFC for solving the MDRE directly with
. If one wishes to approximate the gradients of the MDRE the most consistently, then using the Halton sequence to sample the input weights and biases would be recommended.
The PI-MDLE errors may not have been as low as those for PI-MDRE, but using X-TFC to compute the MDLE and transforming the Lyapunov solution into the Riccati solution via Equation (
16) was faster than solving the MDRE with X-TFC directly. This was because the MDLE is linear, while the MDRE is nonlinear. Thus, X-TFC for computing the MDRE on each subinterval requires multiple iterations of classic linear least squares, while computing the MDLE only needs one. This benefit overcame the extra time-consuming computation needed to obtain the MDRE solution from the MDLE solution. Even if we provide an excellent initial guess to the nonlinear X-TFC solver, the computation still will not achieve the quickness of a linear X-TFC solver. This can be seen in
Table 1, which shows statistics on the number of iterations it took for PI-MDRE halt. to converge for each subinterval when a straight line and RK4’s solution were used as an initial guess. Note that the input weights and biases were sampled from the Halton sequence for obtaining these measurements, and an
s was used. All statistics were higher/worse when a nonideal initial guess was used.
The amount of time it took for the various methods to come up with a solution at the training points (i.e., discretization points) and find a solution at the test points (i.e., prediction) is shown in
Table 2. The PI-MDRE halt. measurement involved using RK4 as an initial guess. MATLAB’s
timeit routine was used to record all run times. Furthermore, MATLAB’s
interpn routine, which performs linear interpolation on a vector, was used to compute the KE, NG, and RK4 predictions. We developed our own MATLAB functions to perform PI-MDRE halt. and PI-MDLE halt. prediction. They just consisted of plugging the computed unknowns back into the constrained expressions at the necessary time point. It must also be mentioned that we developed the code for carrying out the training of all methods, and certain coding inconsistencies might warrant the
Table 2 comparison to not be utterly fair between the KE, NG, and RK4 methods. Nonetheless, it is very apparent that the PI-MDRE halt. and PI-MDLE halt. runs are not as fast as the state-of-the-art methods. The inversion performed by the least squares step in X-TFC is costly for this numerical example. Still, once the SLFNN is trained, X-TFC can predict the MDRE solution faster than MATLAB’s built-in
interpn routine.
As one can see, the PI-MDRE halt. training time was exceptionally high compared to the other methods. Even though the iterative least squares performed for each subinterval were computationally expensive, it was not the main driving force behind PI-MDRE halt.’s high run time. The calculation of the Jacobians via AD with ADiGator ended up being the most computationally expensive, as is shown in
Table 3. Note that “accumulated” in the table implies all time measurements for each subinterval were summed together. A quicker run time for finding the MDRE solution with X-TFC directly could be achieved by deriving expressions for the Jacobians analytically. We used AD for prototype reasons.
4.1. Varying Subinterval Length
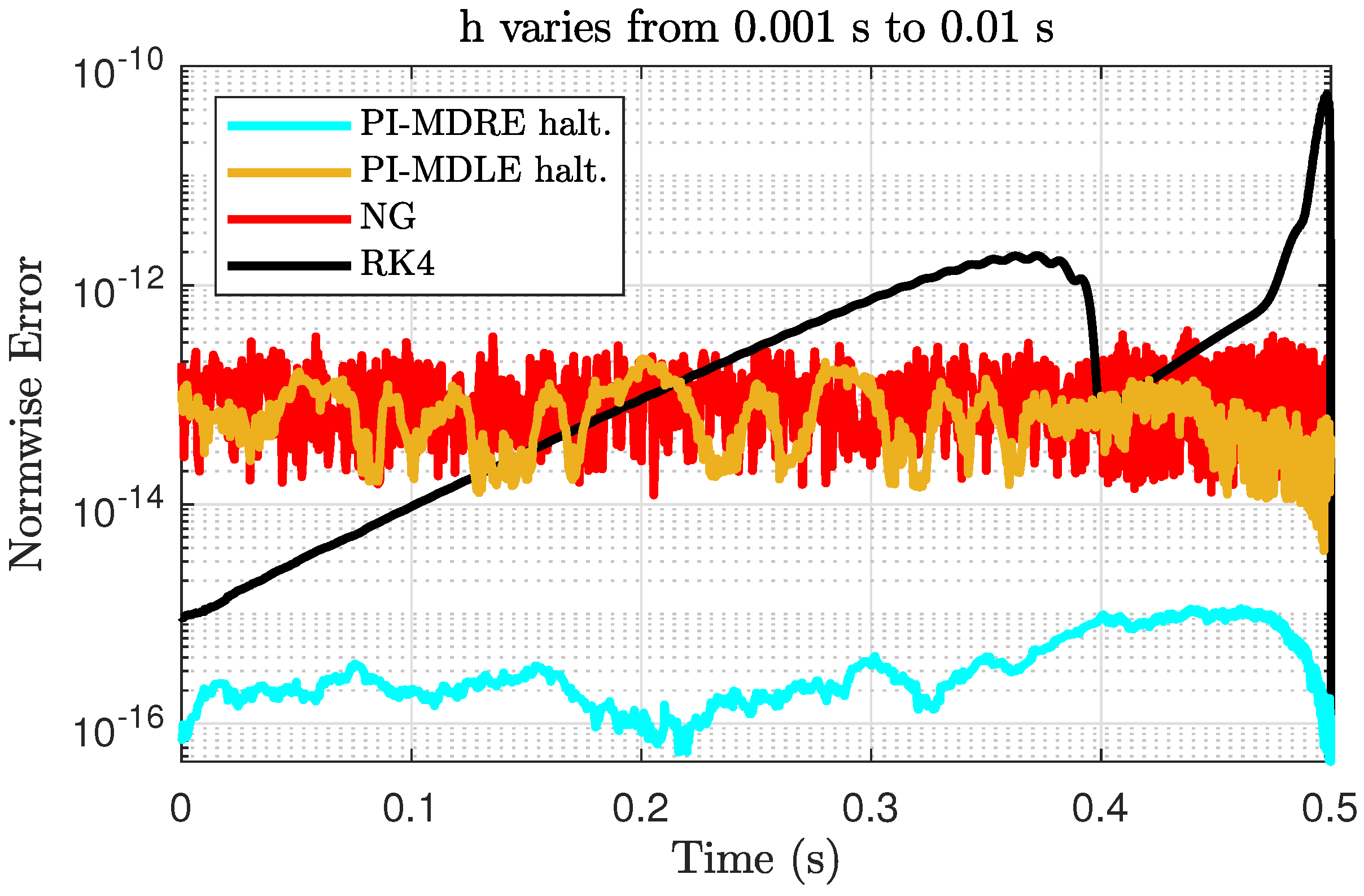
A key question remains: can the execution time of X-TFC be improved while maintaining its accuracy if the subinterval lengths vary? In short, the answer is yes. We decided to keep the subinterval lengths at
h = 0.01 s between
and
h = 0.001 s between
, where the solution gradients are the sharpest. As
Figure 6 shows, both the PI-MDRE halt. and PI-MDLE halt. errors are similar to when
h = 0.001 s for the entire domain (i.e., see
Figure 5).
Table 4 shows that the prediction time with a varying subinterval length remains practically unchanged, but the training times are reduced by more than half when compared with
Table 2. The computation time from using X-TFC to solve the MDLE is even competitive with the state-of-the-art numerical methods. Using X-TFC to solve the MDRE is still not competitive in terms of computation time because of the iterative nature of the algorithm. However,
Table 5 shows that its accumulated least squares run time is only about a second. More efficient coding practicing and analytic computation of the Jacobians could drastically reduce PI-MDRE’s total run time to the order of a single second, or even lower, making it as quick as the other state-of-the-art methods.
4.2. Advantages and Disadvantages of X-TFC Compared with State-of-the-Art Methods
The previous numerical study compared solving the MDRE with X-TFC directly and indirectly with the KE, NG, and RK4 methods. How well they compared with X-TFC in terms of accuracy (using the KE method as a benchmark) and computation time was discussed in detail. Here they are summarized for clarity.
The main advantage of using X-TFC to solve the MDRE directly is that its error is consistently near machine-level throughout the domain when the subinterval length is suitably small, along subintervals that contain sharp gradients, and when the Halton sequence is used to initialize the input weights and biases. If the input weights and biases are randomized, then the solution obtained may be worse than the NG method along subintervals that contain sharp gradients. However, our results show it is still better than the RK4 method. Thus, PI-MDRE halt. is the most accurate between the NG and RK4 methods, as long as the the subinterval length is small. When the subinterval length is large, the NG method is the most accurate. The main disadvantage of using X-TFC to solve the MDRE directly is that its computation run time during training is one to two orders of magnitude higher than the state-of-the-art methods. This is due to the iterative nature of the algorithm and the Jacobian computations with AD. Future work should involve computing the Jacobians analytically.
Solving the MDRE indirectly with X-TFC by solving the MDLE significantly speeds up training time. Its training time is even more competitive with the state-of-the-art methods than when solving the MDRE directly. Regardless, solving the MDRE indirectly with X-TFC is only slightly more accurate than the NG method when a small subinterval length is used (i.e., less standard deviation throughout the domain, see
Figure 5). Thus, if one is using X-TFC to solve the MDRE, one should do so directly if accuracy is the primary concern and indirectly if computational speed is needed. Still, though, the training speed achieved appears to not be better than the state-of-the-art methods. Although X-TFC, whether solving the MDRE directly or indirectly, is not as fast during training as the state-of-the-art methods, it is faster when predicting the solution on points not seen during training. This is possible because X-TFC gives a closed-form solution. The solution provided by the state-of-the-art methods is not closed-form and requires interpolation to generalize.
One way that was explored in which the speed of X-TFC for solving the MDRE can be improved while still maintaining machine-level accuracy is by varying the subinterval lengths. Large subintervals during regions of the domain where the solution is the most smooth allows for fewer computations to be performed, which speeds up run time. Since the solution on those subintervals is very smooth, it is still well approximated with small SLFNN. For regions of the domain where the solution is not very smooth, containing relatively sharp gradients, a small subinterval is still needed to achieve machine-level accuracy throughout the domain of the solution. Indeed, future work will involve adaptively determining the subinterval length such that it can be as large as possible while keeping the accuracy as low as possible.
5. Conclusions
How X-TFC, a PINN with functional interpolation, can be used to solve the MDRE directly and indirectly by solving an MDLE has been shown. In addition, comparisons between each proposed approach and several other methods (e.g., KE, NG, and RK4) have been made. The purpose of the comparison was to determine the accuracy and computational efficiency of both proposed approaches. Employing X-TFC to solve the MDRE directly yielded the best accuracy amongst all other approaches when the time domain was decomposed into short intervals and the hyperparameters of the network were initialized with a deterministic sequence. When X-TFC was used to solve the MDRE indirectly by solving the MDLE, the accuracy of the former proposed approach could not be matched but was still slightly better than the NG method. It is also worth mentioning that the testing error of the proposed approaches was low, validating the maximum bound estimate on X-TFC’s generalization error.
Using X-TFC to solve the MDLE was much quicker than solving the MDRE directly. Both proposed approaches were not as quick as the state-of-the-art methods during training with a fixed subinterval length. However, when the subinterval length was varied, such that it was shorter during steeper solution gradients and larger otherwise, using X-TFC to solve the MDLE was nearly as quick as the other approaches. X-TFC for solving the MDRE directly still could not match the speed of the state-of-the-art methods, but computing the Jacobians analytically could reduce its run time more. Even though both proposed approaches did not achieve quicker training times, both achieved quicker run times while predicting the solution than the state-of-the-art methods. Therefore, if a control engineer wishes to design a Riccati controller offline at several points and then predict the control between those points online, X-TFC can be a suitable option. However, solving the MDRE in real time with X-TFC to formulate a closed-loop controller may not be quick enough for many optimal control problems. Future work will attempt to see if adaptively varying the subinterval length fixes this issue. Another option would be to solve the linear TPBVP, shown as Equation (4), with X-TFC. Solving the linear TPBVP will likely be quicker because fewer DEs are present in the TPBVP than are in the MDRE. Furthermore, the domain may not need to be decomposed and solved sequentially. Naturally, X-TFC’s ability to solve this TPBVP will be investigated in future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}