
Partially Functional Linear Models with Linear Process Errors
1
School of Mathematical Sciences, Tongji University, Shanghai 200092, China
2
Department of Applied Mathematics, Xi’an Jiaotong-Liverpool University, Suzhou 215123, China
*
Author to whom correspondence should be addressed.
Mathematics 2023, 11(16), 3581; https://doi.org/10.3390/math11163581
Submission received: 20 July 2023
/
Revised: 10 August 2023
/
Accepted: 15 August 2023
/
Published: 18 August 2023
(This article belongs to the Special Issue Statistical Modeling for Analyzing Data with Complex Structures)
Abstract
:In this paper, we focus on the partial functional linear model with linear process errors deduced by not necessarily independent random variables. Based on Mercer’s theorem and Karhunen–Loève expansion, we give the estimators of the slope parameter and coefficient function in the model, establish the asymptotic normality of the estimator for the parameter and discuss the weak convergence with rates of the proposed estimators. Meanwhile, the penalized estimator of the parameter is defined by the SCAD penalty and its oracle property is investigated. Finite sample behavior of the proposed estimators is also analysed via simulations.
Keywords:
symptotic normality; convergence rate; linear process error; partial functional linear model; variable selectionMSC:
62J05; 62F121. Introduction
Over the last two decades, there has been an increasing interest in functional data analysis due to its extensive application in biometrics, chemometrics, econometrics, medical research as well as other fields. The functional data are intrinsically infinite in dimension; thus, the classical methods for multivariate observations are no longer applicable. The functional linear model is an important model in functional data analysis, and has been extensively investigated. Ramasy and Silverman [1] systematically introduced the statistical analysis methods for the functional data and described regression relationship between functional covariates and scalar responses by the functional linear models; further investigations include Cardot et al. [2], Cardot and Sarda [3], Li and Hsing [4], and Hall and Horowitz [5], who constructed estimator of slope function in the functional linear model and established its convergence with rates based on the functional principal component analysis (FPCA) technique. For more analysis on the functional data, refer to Hall and Hosseini-Nasab [6], Horváth and Kokoszka [7], Hsing and Eubank [8], Ferraty and Vieu [9], and others.
In real data, the response variable is also affected by other covariates. Shin [10] proposed the following partial functional linear model:
where is the response variable, is a d-dimensional covariate vector with , is a square integrable stochastic process on [0, 1] with , is an unknown d-dimensional parametric vector, is a square integrable unknown coefficient function and V is the regression error, which is independent of .
The spline method, which is frequently employed to investigate functional data, were used in many papers that studied functional data. Based on B-spline, Yuan and Zhang [11] used the residual sum of squares to construct the test statistic of the in the model (1); Hu and Liang [12] considered the empirical likelihood in the single-index partially functional linear model when the observations are missing at random; Jiang and Huang [13]) discussed single-index partially functional linear quantile regression and used B-spline to approximate the link function and the slope function and further establish the convergence rates and asymptotic normality of the estimators. Bouka et al. [14] employed a smoothing spline to study the estimators with a spatial functional linear regression.
However, the spline method has some drawbacks, such as the fact that shifting a control point causes the entire curve to change, making it hard to regulate the curve’s trend locally. Then, in recent years, many researchers have developed an interest in the FPCA approach for analyzing functional data, since this approach enables finite dimensional study of a topic that is inherently infinitely dimensional. The estimation and testing of a partially functional linear varying coefficient model were covered by Feng and Xue [15]. Based on FPCA, Xie et al. [16] examined the rank-based test’s asymptotic characteristics while considering the hypothesis test for the in the model (1). In addition, Hu et al.’s [17] research also concentrated on the estimation issues for additive partial functional linear models with skew-normal errors. Tang et al. [18] proposed a two-step estimation procedure with FPCA in the partial functional partially linear additive model. At the same time, we find there are several papers to discuss penalized estimators related to the partially functional linear model based on FPCA. For instance, Kong et al. [19] applied a group penalty to reduce the effect of significant functional predictors in a high dimension setting; Du et al. [20] analysed estimation and variable selection; Yao et al. [21] selected the important variables based on the SCAD penalty in partially functional linear quantile model; Wu et al. [22] concentrated on building the estimators for the parameter and slope function with the responses being right-censored and the censoring indicators being missing at random, and proposed a variable selection procedure by the method of adaptive lasso penalty.
It is known that the independence assumption for the model errors, in practical applications, is not always appropriate, especially for sequentially collected economic data, which often exhibit dependence in the errors. Up to now, we have found that Wang et al. [23] established asymptotic normality and weak convergence with rates of the estimators for and , respectively, in model (1) when the errors form a stationary -mixing sequence, while Hu and Liang [24] used the reproducing kernel Hilbert space technique to study the parameter estimator and the convergence rate of the estimator for the slope function with missing observations under under correlated errors , which is called linear process, with , and further defined the penalized estimator of the parameter by the SCAD penalty and a test statistic for check a linear hypothesis.
Motivated by the discussion in Hu and Liang [24], we, in this paper, focus on the partially functional linear model (1) when the regression error V is a linear process deduced by not necessarily independent random variables by using FPCA method. In particular, we give the estimators and of and , investigate the asymptotic normality of and discuss the weak convergence with rates of and . At the same time, the penalized estimator of is defined based on the SCAD penalty introduced by Fan and Li [25] and its oracle property is established. Finite sample behavior of the proposed estimators is also investigated via simulations.
The rest of the paper is organized as follows. In Section 2, we construct the estimators of the parameter and slope function including the penalized estimator of the parameter. The main results are described in Section 3. A simulation study is presented in Section 4. Conclusions are put into Section 5. All proofs are put in Section 6.
2. Estimators
2.1. Least Squares Estimation
Let come from based on model (1), i.e.,
where are assume to be i.i.d. random variables, the errors with and . Set . The operator corresponding to is defined by
Then is positive definite, i.e., for , where , , . If is continuous, then has the following representation by Mercer’s theorem (cf. Hsing and Eubank [8], Theorem 4.6.5, page 120)
where is an orthonormal basis of , and are (eigenvalue, eigenfunction) pairs of , which satisfy , with and with . Without loss generality, we assume . The estimators of are defined by
where are the (eigenvalue, eigenfunction) pairs of corresponding to with Here, the choice method for is to simply let take an arbitrary sign while choosing to minimize over the two possible signs, that is, is chosen so that . Clearly, is an orthonormal basis of and satisfy .
In addition, using Karhunen–Loève expansion (cf. Hsing and Eubank [8], Theorem 2.4.13, page 34,), and have the following expressions
where and . Then and . Thus, the model (2) can be written as
In order to define the estimators of and , we use an approximated form of (3)
which can be rewritten into the following matrix form: where , , , , , . The estimators of can be defined by minimizing the following objective function
Let . When is invertible, we have
Let denote the Kronecker delta, then
which implies . Put , ,
Then and can be rewritten, respectively, as
where and . The estimator of is defined by
2.2. Variable Selection
Variable selection is a crucial step when the dimensionality of the covariate in (1) is high, and it is of great interest to identify the nonzero components in . In this paper, we adopt the SCAD penalty introduced by Fan and Li [25] to get a penalized estimator. In particular, the first order derivative of the SCAD penalty function is
where is a tuning parameter and suggested by Fan and Li [25]. Hence, we define the penalty estimator of as
where and is the j-th component of .
Remark 1.
In simulation below, the tuning parameter ω in (5) is selected by 10-fold cross-validation.
Let be true value of , and put , . Without loss of generality, we assume , where and are the nonzero and zero components of , respectively, i.e., , and the estimator of is defined by .
3. Main Results
In the sequel, let and denote generic finite positive constants, whose values may change from line to line; means ; . For the sake of convenience for statement, we give the following notations.
and for .
In order to list the main results in this paper, we impose the following assumptions.
- (A0)
- Let random variables be identical distributed with or square uniformly integrable and satisfy .
- (A1)
- a.s., and .
- (A2)
- .
- (A3)
- For each j, and , for some .
- (A4)
- For each j and some : (i) ; (ii) for each k.
- (A5)
- .
- (A6)
- Let be i.i.d. random variables and satisfy a.s., a.s., which is k-th diagonal element of and is a positive definite matrix. Assume that for .
- (A7)
- , , .
Remark 2.
- (a)
- It is easy to verify .
- (b)
- (A1)–(A3), (A4)(i), (A5) and (A6) are general regularization conditions in the partially functional linear model (cf. Shin [10]); when decrease in (A3), implies . (A1) implies . In fact,which implies .
- (c)
- From (A3) and (A4)(ii), we have
Theorem 1.
Let (A0)–(A6) hold with a.s. and a.s. for . Then
Theorem 2.
Let (A0)–(A6) hold, then
Remark 3.
When and for , and is i.i.d. random variables, Theorems 1 and 2 can reduce to Theorems 3.1 and 3.2 of Shin [10], respectively.
Theorem 3.
Suppose that (A0)–(A7) hold. If and , then
- (1)
- Selection consistency: ;
- (2)
- Asymptotic normality: If a.s. and a.s. for , then where and is related to , which is corresponding to , is a -dimensional subvector of for .
4. Simulation Study
4.1. Least Squares Estimation
In this subsection, we use the Monte Carlo simulation to study the performance for the proposed methods. The data are generated from the following model:
where , and . Taking , and . For in (6), let
and m be chosen by the CPV method (see Horváth and Kokoszka [7], page 41), i.e.,
Let be an process: where and . Thus, .
In the simulation, we take and sample sizes and 200. For each sample size, we replicate simulations and take grid points of equal interval in . The mean square error (MSE) of the estimators and of and is defined, respectively, as
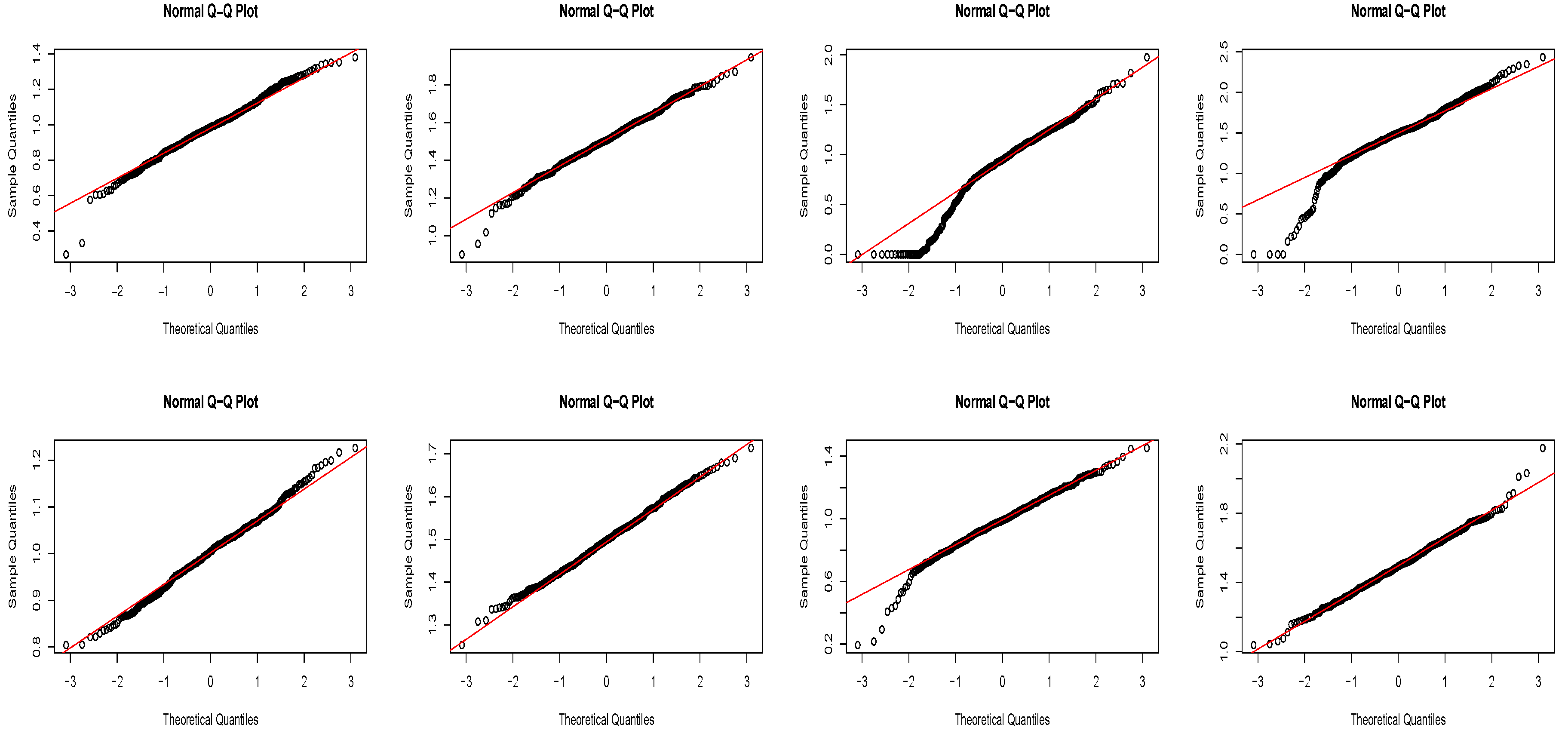
In Figure 1, we draw Q-Q plots of the estimators and with sample sizes n = 50, 200 and . Figure 1 illustrates that more points fall near the line as and the value of ; more points on either sides are away from the line when and . This implies the quality of fit decreases as the dependence of the observations increases, i.e., the value of increases, and that the normality in the distribution of the estimators increases as the sample size n increases, which comfirms the asymptotic normality in Theorem 1.
In Table 1, we report the bias and MSEs, of the estimators for , and . From Table 1, we can draw the following conclusions:
- (1)
- For the same sample size n, the values of MSE, MSE and increase with increasing;
- (2)
- With the same , if the sample size n increases, then the values of MSE, MSE and decrease;
- (3)
- Changes of the sample size n and have a little effect on the biases of and .
4.2. Variable Selection
In this subsection, we add six independent covariates with () to model (6), and take . Set C as the average number of components in correctly estimated to be zero, IC as the average number of components in incorrectly estimated to be zero, C-fit as the probability of exactly fitting the model and MSE( as the mean square error of the estimator for .
Figure 2 shows Q-Q plots of the estimators for and with , 200 and 0.9 by using the SCAD penalty function. The performance from Q-Q plots in this instance is comparable to that in Section 4.1. The asymptotic normality in Theorem 3 is verified as sample size rises because the Q-Q plots are more aligned with the normality; when the value of is increasing, the poorer imitative impact is observed.
In Table 2, we represent the values of C, IC, C-fit and MSE(. Table 2 indicates the following conclusion:
- (1)
- When the sample size n increases with the same , the value of MSE( decreases;
- (2)
- (i)
- If the sample size n increases with the same , the average number of zero coefficients correctly estimated to be zero is close to 5 and the average number of components in incorrectly estimated to be zero is near 0 and even is 0 when or . This verifies the selection consistency in Theorem 3;
- (ii)
- When the value of dereases with the same sample size, the average number of zero coefficients correctly estimated to be zero increases, and the average number of components in incorrectly estimated to be zero decreases;
- (3)
- As the sample size n increases with the same or decreases with the same sample size, the probability of exactly fitting the model increases.
5. Conclusions
By using the least square method, based on FPCA, we construct the estimators of parameter and coefficient function in the partially functional linear models with linear process errors and establish asymptotic normality of parameter estimator and the rate of convergence of the estimator for the coefficient function. Additionally, we use the SCAD penalty to define the estimator of the parameter and discuss its oracle property.
However, the proposed method has some limitations. First, in this study, we approximate the expansion of the function part into partial sum form by using the FPCA method, which may leave out data information due to the truncation value m. Second, while, in practice, there exists missing data, this work considers the scenario of complete data. Therefore, in the event of missing data, our proposed method may be inapplicable. In the future, we are interested in figuring out a way to reduce data information loss and take missing data into account.
6. Proof of Main Results
In proof below, we use the following notations: for linear operator T, let , for ; for matrix ; for , set , , ,
and .
Lemma 1
(Shin [10] ).
- (1)
- Let , then , and for
- (2)
- Suppose that (A1), (A3), (A4)(i), (A5) and (A6) are satisfied. Then Further, if are identical distributed with or square uniformly integrable,
Lemma 2
(Pollard [26], page 171). Let be a sequence of random variables and be increasing sequence of σ-fields such that is measurable with respect to , and for . Assume that and for some constant and every . Then .
Lemma 3.
For , let be random variables with and . Set with . Assume that is independent of , and that are identical distributed with or square uniformly integrable. Then
Proof.
Note that So which yields □
Lemma 4.
If (A1) and for each k hold, then and , where , .
Proof.
From , using (A1) we have
□
Lemma 5.
Let and be two sequences of independent random variables, then for any and we have
Proof.
Using independence between and , it follows that
□
Proof of Theorem 1.
We write (cf. the proof of Theorem 3.1 in Shin [10])
Lemma 1 implies . Thus, it suffices to show that , and
Step 1. We prove . By applying Lemmas 1 and 3, it follows
which yields .
Step 2. We prove . From , we know that the k-th () element of is
Since , Then, to prove , we need only to prove that
To do these, we need the following results (i) and (ii), their proofs can be found in Hall and Horowitz [5]:
- (i)
- If we have .
- (ii)
- . Furthermore, let , then .
Note that , then, from , we have
Using we get
The result (ii) implies on , hence using (11) and , On we have
By and , we find
When and using the conclusion and Lemma 4
The inequation (5.16) in Hall and Horowitz [5] shows , thus, from we have
On , we have Obviously, from we have
and for . Then, in view of (A3), (A4) and Lemma 4, we obtain
On , one can write
According to (A3) and (A4), by using Lemma 4 we have
Then, (10) is verified.
By and using , it follows that, for any
which implies .
Now, we use Lemma 2 to prove . In fact, , where . Set
Then is measurable with respect to , and for , . Thus, from Lemma 2, we only need to verify that
We first prove (13). Applying a.s., we can write
The law of large numbers implies , hence from we obtain
Since is a sequence of independent random vectors with , we have
which gives . Therefore, (13) is proved.
We next prove (14). Using Lemma 5, we write
According to the moment inequality for sum of independent random variables, we can write
By , we have
When are identical distributed, from we have ; when are square uniformly integrable, we have . Hence . Therefore, , further we verify (14). □
Proof of Theorem 2.
Applying Lemmas 1 and 3 and , following the proof line in the proof of Theorem 3.2 in Shin [10], one can prove this result. □
Proof of Theorem 3.
(1) Let and . we first prove that for any and a large constant ,
which implies there exists a local minimizer such that .
In fact, . Let . Using the Taylor expansion, we have
and from , it follows that
where , and . (8), (10) and (9) imply . Hence, from Theorem 2 and we have
Next, we consider . Clearly, , where and is defined in the proof of Theorem 1 and further in the proof of Theorem 1, it holds that and . Thus, .
From Lemma 1, we have , which implies .
As for , from (A7) we get
Therefore, for , we have , which yields (15) since is a positive definite matrix.
Note that Then
where . Thus, for any satisfying , by (A7) and Theorem 2, and we find
then the sign of is dominated by the sign of . Note that is the estimator of . Then as .
(2) From the proof in (1) above, we know and . Hence, from (16) we get
where , and . Due to Lemma 1, we can obtain . Then, by (A7),
Similar to the proof of Theorem 1, we have , where and are similarly defined as and , which are related to for . Then, following the proof line in Step 2 and Step 3 of the proof of Theorem 1, one can verify □
Author Contributions
Conceptualization, Y.H.; Methodology, Y.H.; Software, Y.H.; Formal analysis, Y.H.; Data curation, Y.H.; Writing—original draft, Y.H.; Writing—review & editing, Z.P.; Visualization, Z.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
In this paper, Monte Carlo simulation method was used for data analysis, and R software was used to generate the required data. No new data were created in this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ramsay, J.O.; Silverman, B.W. Functional Data Analysis; Springer: New York, NY, USA, 1997. [Google Scholar]
- Cardot, H.; Ferraty, F.; Sarda, P. Spline estimators for the functional linear model. Stat. Sin. 2003, 13, 571–591. [Google Scholar]
- Cardot, H.; Sarda, P. Linear Regression Models for Functional Data. In The Art of Semiparametrics; Contributions to Statistics; Physica-Verlag: Heidelberg, Germany, 2006; pp. 49–66. [Google Scholar]
- Li, Y.; Hsing, T. On rates of convergence in functional linear regression. J. Multivar. Anal. 2007, 98, 1782–1804. [Google Scholar] [CrossRef]
- Hall, P.; Horowitz, J.L. Methodology and convergence rates for functional linear regression. Ann. Stat. 2007, 35, 70–91. [Google Scholar] [CrossRef]
- Hall, P.; Hosseini-Nasab, M. On properties of functional principal components analysis. J. R. Stat. Soc. Ser. B Stat. Methodol. 2006, 68, 109–126. [Google Scholar] [CrossRef]
- Horváth, L.; Kokoszka, P. Inference for Functional Data with Applications; Springer: New York, NY, USA, 2012. [Google Scholar]
- Hsing, T.; Eubank, R. Theoretical Foundations of Functional Data Analysis, with an Introduction to Linear Operators; John Wiley & Sons, Ltd.: Chichester, UK, 2015. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer: New York, NY, USA, 2006. [Google Scholar]
- Shin, H. Partial functional linear regression. J. Stat. Plan. Inference 2009, 139, 3405–3418. [Google Scholar] [CrossRef]
- Yuan, M.G.; Zhang, Y. Test for the parametric part in partial functional linear regression based on B-spline. Commun. Stat.-Simul. Comput. 2021, 50, 1–15. [Google Scholar] [CrossRef]
- Hu, Y.P.; Liang, H.Y. Empirical likelihood in single-index partially functional linear model with missing observations. Commun. Stat.-Theory Methods 2022. [Google Scholar] [CrossRef]
- Jiang, Z.Q.; Huang, Z.S. Single-index partially functional linear quantile regression. Commun. Stat.-Theory Methods 2022. [Google Scholar] [CrossRef]
- Bouka, S.; Dabo-Niang, S.; Nkiet, G.M. On estimation and prediction in spatial functional linear regression model. Lith. Math. J. 2023, 63, 13–30. [Google Scholar] [CrossRef]
- Feng, S.; Xue, L. Partially functional linear varying coefficient model. Statistics 2016, 50, 717–732. [Google Scholar] [CrossRef]
- Xie, T.F.; Cao, R.Y.; Yu, P. Rank-based test for partial functional linear regression models. J. Syst. Sci. Complex. 2020, 33, 1571–1584. [Google Scholar] [CrossRef]
- Hu, Y.; Xue, L.; Zhao, J.; Zhang, L. Skew-normal partial functional linear model and homogeneity test. J. Stat. Plan. Inference 2020, 204, 116–127. [Google Scholar] [CrossRef]
- Tang, Q.G.; Tu, W.; Kong, L.L. Estimation for partial functional partially linear additive model. Comput. Stat. Data Anal. 2023, 177, 107584. [Google Scholar] [CrossRef]
- Kong, D.; Xue, K.; Yao, F.; Zhang, H.H. Partially functional linear regression in high dimensions. Biometrika 2016, 103, 147–159. [Google Scholar] [CrossRef]
- Du, J.; Xu, D.; Cao, R. Estimation and variable selection for partially func- tional linear models. J. Korean Stat. Soc. 2018, 474, 436–449. [Google Scholar] [CrossRef]
- Yao, F.; Sue-Chee, S.; Wang, F. Regularized partially functional quantile regression. J. Multivar. Anal. 2017, 156, 39–56. [Google Scholar] [CrossRef]
- Wu, C.X.; Ling, N.X.; Vieu, P.; Liang, W.J. Partially functional linear quantile regression model and variable selection with censoring indicators MAR. J. Multivar. Anal. 2023, 197, 105189. [Google Scholar] [CrossRef]
- Wang, Y.F.; Du, J.; Zhang, Z.G. Partial functional linear models with dependent errors. Acta Math. Appl. Sin. 2017, 40, 49–65. (In Chinese) [Google Scholar]
- Hu, Y.P.; Liang, H.Y. Functional regression with dependent error and missing observation in reproducing kernel Hilbert spaces. J. Korean Stat. Soc. 2023. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Pollard, D. Convergence of Stochastic Processes; Springer: New York, NY, USA, 1984. [Google Scholar]
Figure 1.
Q-Q plots of and with (the first row), (the second row), (the first and second column) and (the third and fourth column).
Figure 1.
Q-Q plots of and with (the first row), (the second row), (the first and second column) and (the third and fourth column).

Figure 2.
Q-Q plots of the estimators for with (the first row), (the second row), (the first and second column) and (the third and fourth column) by the method of SCAD.
Figure 2.
Q-Q plots of the estimators for with (the first row), (the second row), (the first and second column) and (the third and fourth column) by the method of SCAD.


{kind=link}
{kind=link}
Table 1.
Values of bias, MSEs for , and with and .
| n | MSE | Bias | ||||
|---|---|---|---|---|---|---|
| 50 | 0.1 | 0.0207 | 0.0245 | 1.8649 | 0.0040 | −0.0050 |
| 0.9 | 0.1010 | 0.1288 | 6.1297 | 0.0078 | −0.0118 | |
| 200 | 0.1 | 0.0051 | 0.0052 | 0.4606 | 0.0044 | −0.0058 |
| 0.9 | 0.0289 | 0.0268 | 2.1421 | 0.0040 | −0.0120 | |
Table 2.
Values of C, IC, C-fit and MSE(.
| n | C | IC | C-Fit | MSE( | |
|---|---|---|---|---|---|
| 50 | 0.1 | 4.94 | 0 | 0.8675 | 0.0847 |
| 0.9 | 4.12 | 0.048 | 0.759 | 0.5204 | |
| 200 | 0.1 | 5.424 | 0 | 0.928 | 0.0173 |
| 0.9 | 4.982 | 0 | 0.873 | 0.0900 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hu, Y.; Pang, Z. Partially Functional Linear Models with Linear Process Errors. Mathematics 2023, 11, 3581. https://doi.org/10.3390/math11163581
AMA Style
Hu Y, Pang Z. Partially Functional Linear Models with Linear Process Errors. Mathematics. 2023; 11(16):3581. https://doi.org/10.3390/math11163581
Chicago/Turabian StyleHu, Yanping, and Zhongqi Pang. 2023. "Partially Functional Linear Models with Linear Process Errors" Mathematics 11, no. 16: 3581. https://doi.org/10.3390/math11163581
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.