1. Introduction
As a natural choice for modeling the relationship between entities, graphs have been used in many real-world applications, such as online social networks [
1,
2], road networks [
3,
4], and financial transaction networks [
5], etc. Recently, there have been a string of works devoted to analysing graph data [
6]. Among them, the
k-core-based cohesive subgraph search has been studied intensively [
7,
8,
9,
10,
11,
12]. Essentially, a
k-core is a subgraph where each vertex has at least
k neighbors in the subgraph. It has been shown that the
k-core subgraph can be computed in linear time by recursively removing the vertices with neighbor nodes less than
k in the graph [
13]. Due to the computation efficiency,
k-core has been adopted in many cohesive subgraph-mining-related applications [
8,
10,
11,
14,
15,
16].
In the literature, the problem of minimum
k-core computation has been studied, which aims to find a subgraph with the minimum number of vertices satisfying the
k-core constraint, i.e., each vertex has at least
k neighbors. The minimum
k-core has many applications [
17]. For example, in online commercials, it can be used for advertisement delivery with a limited budget [
18]. In social networks, the minimum
k-core has been employed for product recommendation [
18]. In biology, the minimum
k-core is capable of modeling the cell assembly [
14,
15].
Motivation. Although the minimum
k-core model is useful in many real applications, it has its own limitations. Under some circumstances, the network stability is expensive to maintain, because the relationship between two users are maintained at a cost [
19]. In this paper, we advocate the problem of the edge-based minimal
k-core search. The edge-based minimal
k-core is defined as a
k-core in which every edge in the
k-core is indispensable. In other words, if any edge in this subgraph is missing, the subgraph is not a
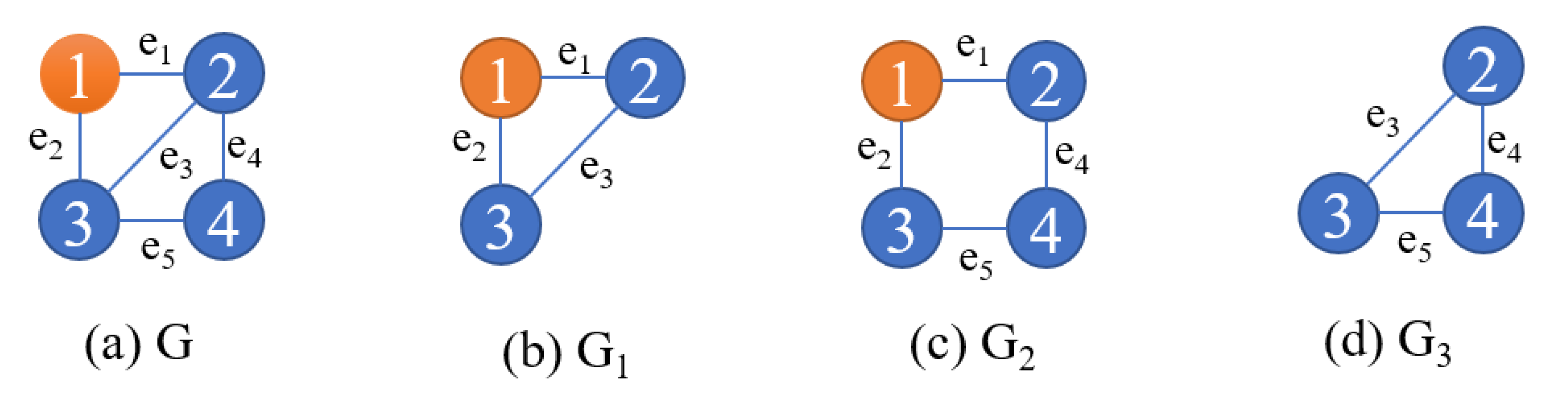
k-core any more. For example, for the graph
G shown in
Figure 1a, we have three different edge-based minimal
k-cores, which are shown in
Figure 1b–d, respectively. The edge-based minimal
k-core plays an important role in many other related problems. Below is a concrete example.
Example 1 (Group Recommendation). It is a common practice to encourage group members to participate in social networks by leveraging the positive influence of friends from the same group. In some applications, such as group recommendations with query vertices (for example, specific users), small k-core subgraphs may be preferred, as large k-core subgraphs may contain many vertices unrelated to the query vertices of online social platforms. The system can recommend items to users based on the information from social groups containing users. Usually, items have been adopted by certain users, among these users there exists interactions. Therefore, on one hand, k-core is a promising model to maintain the structural stability of group members. On the other hand, since it comes at a cost to maintain the relationships between group members, the service provider would like to maintain as small a number of relationships as possible. To achieve the two targets, our edge-based minimal k-core model provides a good solution.
Challenges. The problem of edge-based minimal
k-core containing the query node
q search is computationally challenging. Given an undirected graph
, a straightforward solution is to enumerate all
combinations of subgraphs assuming the number of edges in the graph
G is
m and verify whether each of them is an edge-based minimal
k-core containing the query node
q. Clearly, this problem is cost-prohibitive, because the number of edge-based minimal
k-cores containing the query node
q might be exponential to the number of edges. This shows that our problem is even more difficult than other related search problems, such as the minimum
k-core containing the query node
q search, which is NP-hard [
18]. For example, as is shown in
Figure 1, let
and
q be node 1, graph
has the smallest-sized vertex number, thus it is a minimum
k-core with
q. Meanwhile,
is also an edge-based minimal
k-core containing
q in
G. However, though graph
G itself does not have the smallest-sized vertex number,
is able to be found as an edge-based minimal 2-core containing node 1 by deleting edge
from graph
G. Since the concept of “minimal” for the edge-based minimal
k-core is the structural minimum, not simply defined as the minimum number of nodes or edges, the problem of edge-based minimal
k-core might involve extra computation.
Contributions. In order to cope with the computation challenges, we propose efficient query processing techniques. In the field of database research, algorithms which combine backtracking with branch-and-bound techniques are widely adopted to tackle graph-based problems, such as maximal biclique enumeration [
20,
21]. Inspired by these, we propose a competitive branch-and-bound baseline method, namely, the edge deletion algorithm, which explores the search space in a depth first manner. Specifically, the edge deletion algorithm maintains a
k-core structure and recursively deletes the candidate edges from the
k-core structure to generate edge-based minimal
k-cores containing the query node
q. We also propose another baseline named the edge extension algorithm, which searches the edge-based minimal
k-cores containing the query node
q following a bottom–top manner using a depth first search. More specifically, the edge extension algorithm maintains a partial edge-based minimal
k-core containing
q and recursively adds the candidate edges to the partial solution to generate results.
To improve the performance of the two baselines, we propose new efficient pruning techniques, such as setting the status of edges to compact the search space, size pruning to terminate search branches early, and edge ordering to avoid redundant computation. To further speed up the computation, we propose a graph partitioning technique. In particular, the graph partitioning technique partitions the graph first to reduce the edges in each iteration, and then, we execute the algorithms concurrently and independently on each partition. Intuitively, this parallel computation paradigm can accelerate the computation linearly to the number of partitions.
Our principal contributions are summarized as follows.
We conceive the concept of the edge-based minimal k-core to model a special subgraph with a minimal number of edges while remaining a k-core, and put forward two related subgraph search problems, i.e., the edge-based minimal k-core subgraph search problem (EMK-SS) and the edge-based minimal k-core with a query node q subgraph search problem (EMK-q-SS). The EMK-SS problem is to find all the edge-based minimal k-cores, and the EMK-q-SS problem is to find all the edge-based minimal k-cores containing the query node q in a k-core graph. We prove also that the two problems are NP-complete.
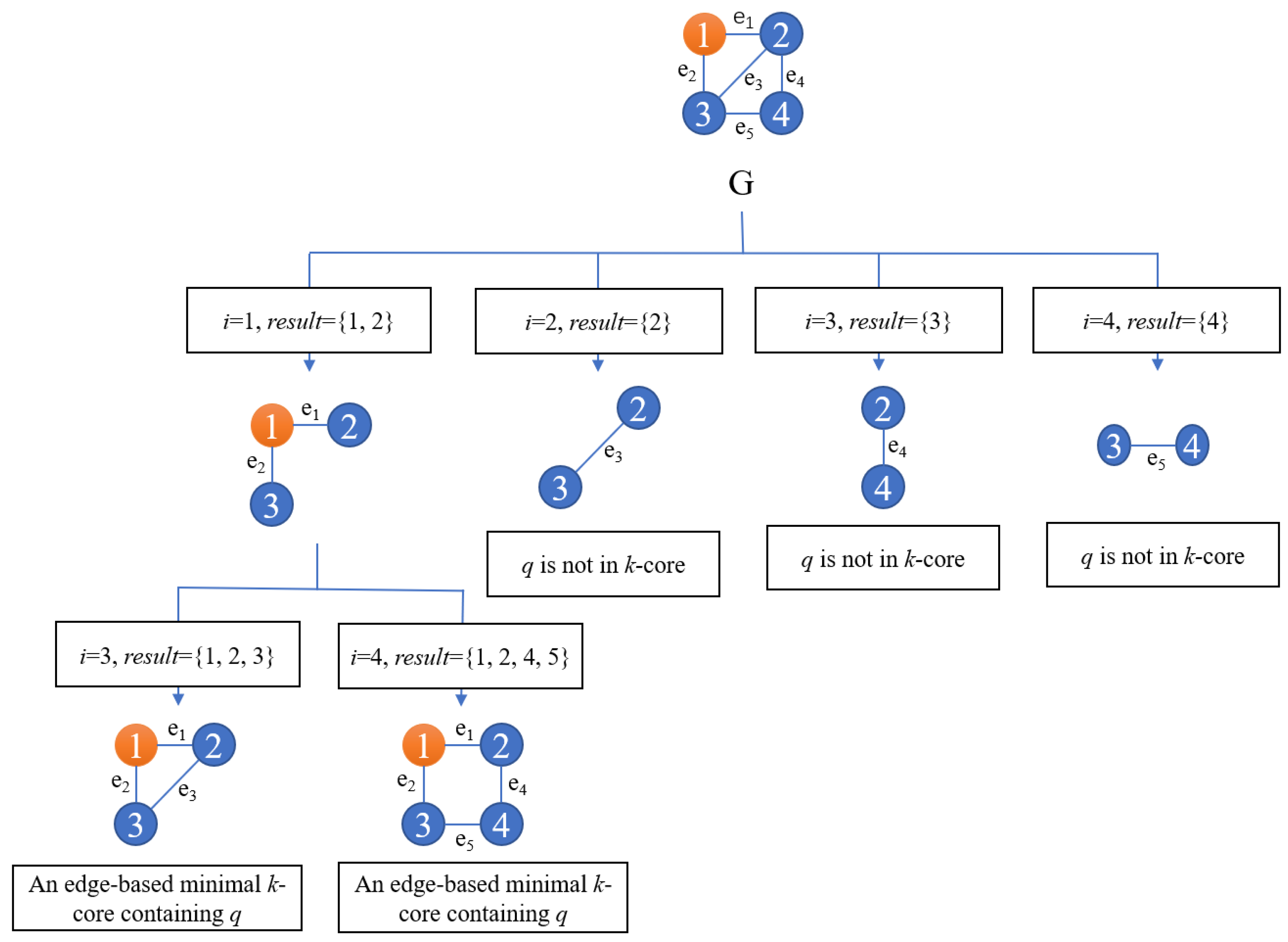
Two algorithms are proposed to solve the EMK-q-SS problem by deleting edges from the candidate set iteratively until one EMK-q is obtained and adding edges to the candidate set iteratively until one EMK-q is obtained, respectively.
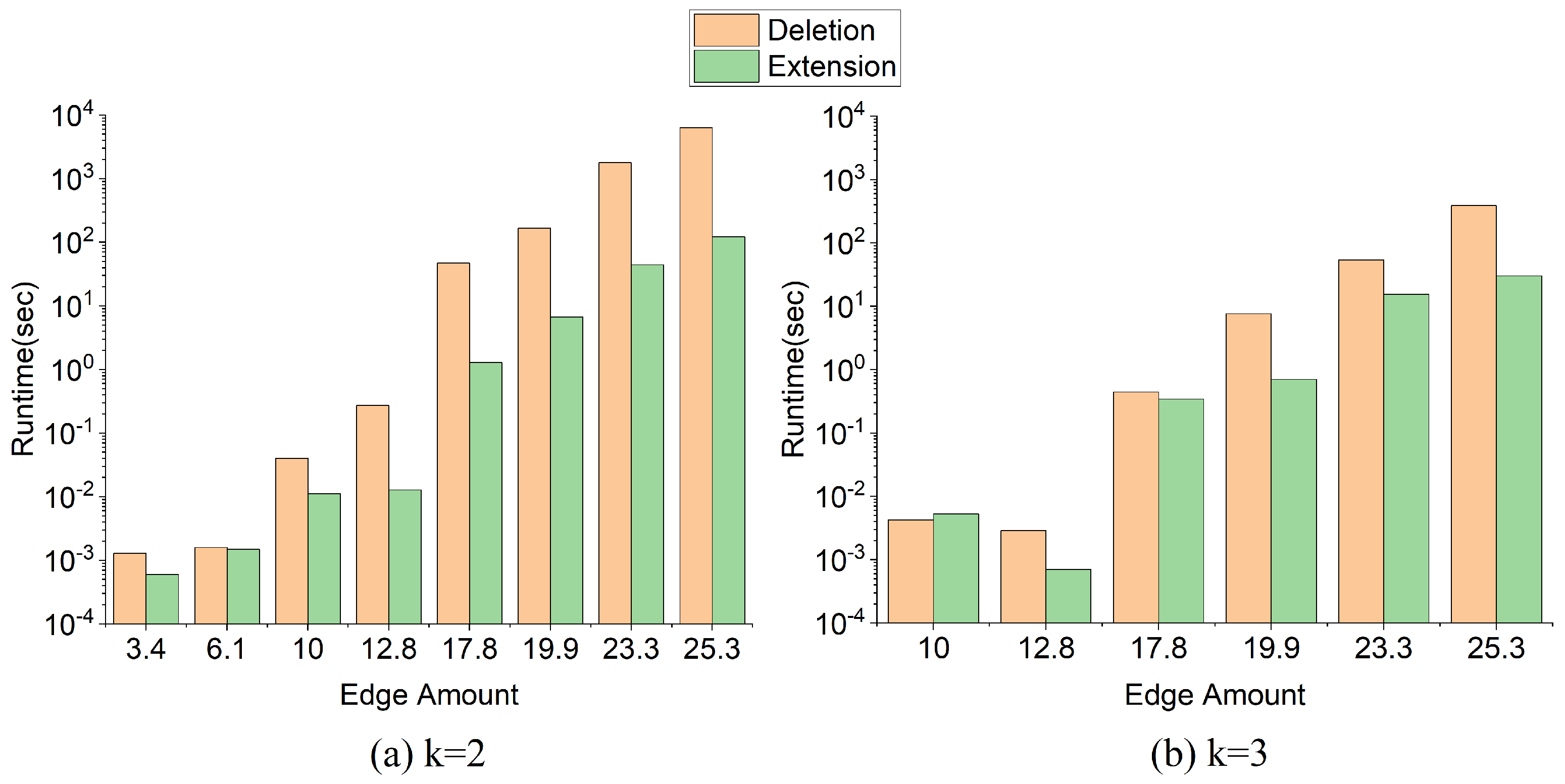
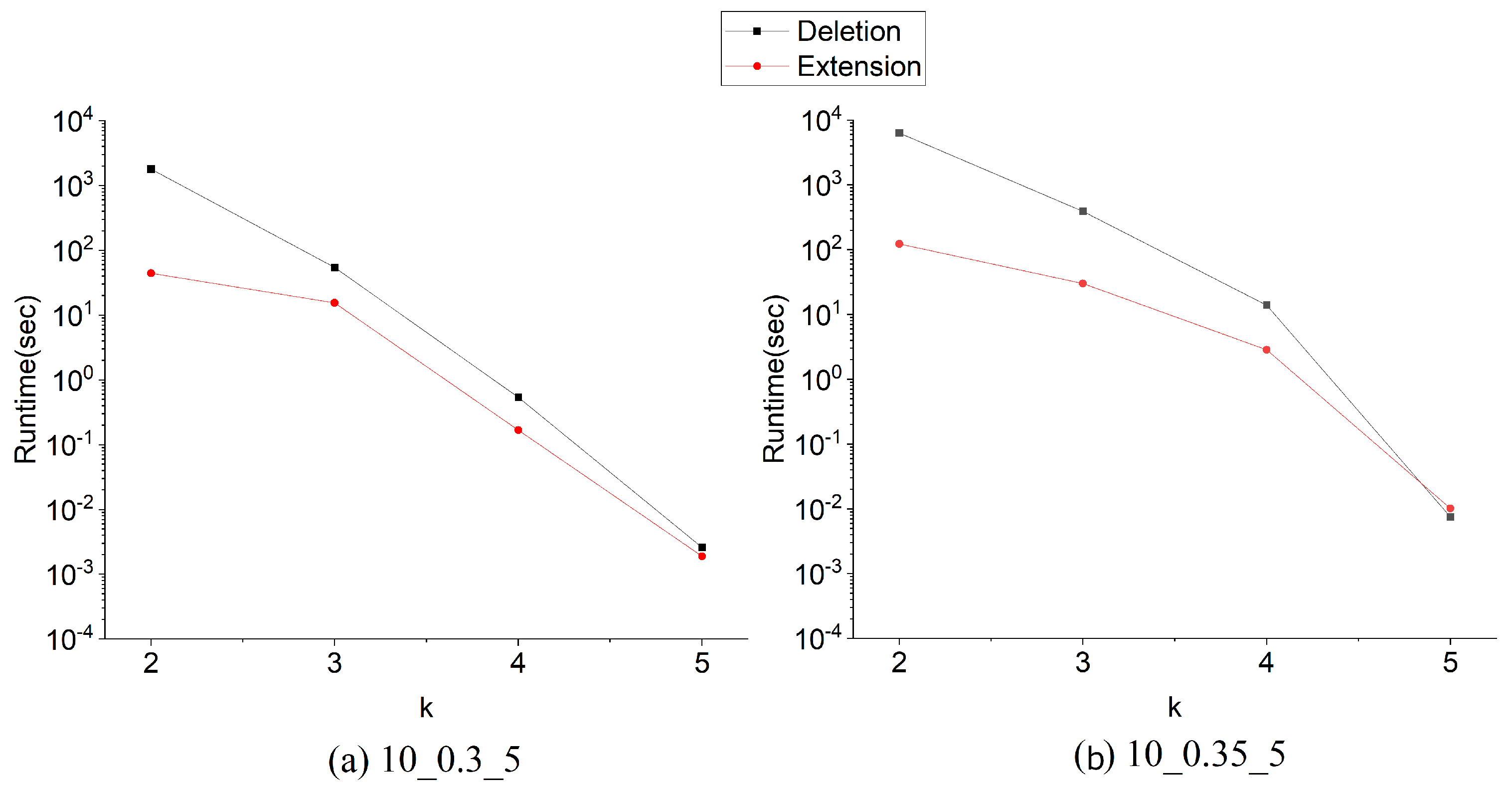
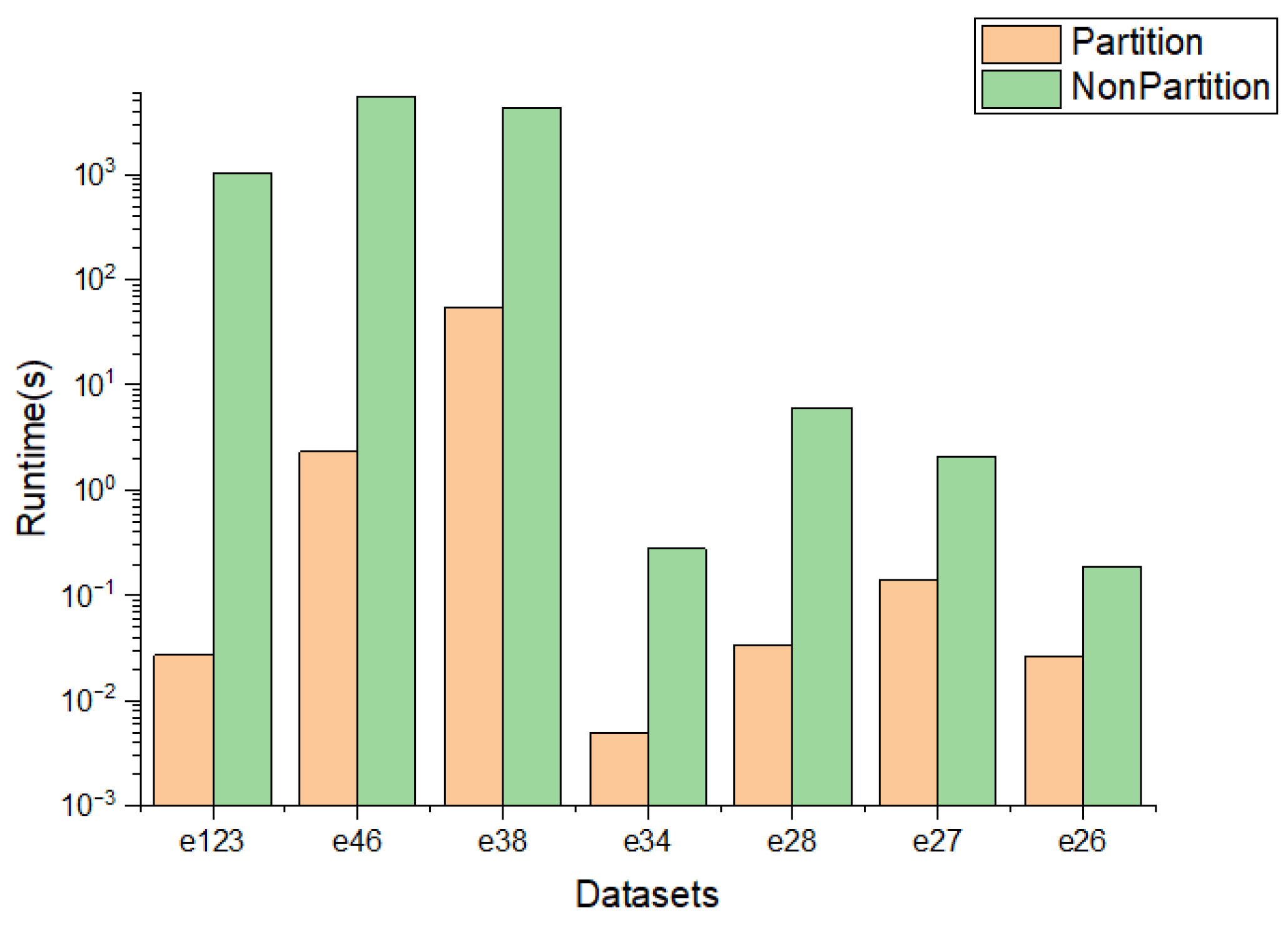
We conduct comprehensive experiments on generated graphs and real graphs to explore the efficiency of the above two algorithms and the speed-up ratio using a graph partition technique. The results show that the two algorithms work effectively and graph partition works well on saving running time and speeds the search process up by up to four orders of magnitude.
2. Preliminaries
In this section, we introduce the concept of a k-core subgraph, an edge-based minimal k-core subgraph, and the edge-based minimal k-core subgraph search problem.
2.1. k-Core Subgraph
Let be an undirected and unweighted graph, where V represents the set of vertices (nodes) and E represents the set of edges. We use and to denote the number of nodes and the number of edges, respectively. Let denote the set of adjacent vertices of node u. We denote is the degree of the node u in G. Given a subgraph S, we denote its vertices as . The number of vertices in S is shown as . When the context is clear, , , and are simplified to , , and S, respectively. We use to denote the largest vertex degree in the graph.
Given a graph G and an integer k, a k-core subgraph S of G is the maximal connected subgraph in which the degree of every vertex in S is larger than or equal to k. In order to simplify the expression, later we use k-core to denote the k-core subgraph. For a node u in G, if it exists in k-core but cannot be contained in -core, we say the core number of node u is k and denote it as . If the context is clear, we abbreviate this as . The core number of a graph G is the biggest one among the core numbers of all nodes in the graph and is marked as .
2.2. The Edge-Based Minimal k-Core Subgraph
Given a graph G and an integer k, an edge-based minimal k-core subgraph S is a k-core in which the deletion of any edge will make k-core vanish in S. In other words, there is no k-core in S if any edge is deleted.
Example 2. Given a graph G and , Figure 1 shows all the edge-based minimal 2-cores in graph G. , and are three edge-based minimal 2-core subgraphs on G, as the absence of any edge in these subgraphs will result in the disappearance of 2-core in them, which fits with the concept of edge-based minimal k-core. 2.3. Problem Definition
Problem 1. Edge-based minimal k-core subgraph search problem (EMK-SS). Given a graph G, an integer k, and a query node q, the edge-based minimal k-core subgraph search problem is to find all the possible edge-based minimal k-core subgraphs.
Problem 2. Edge-based minimal k-core with a query node q subgraph search problem (EMK-q-SS).
Given a graph G, an integer k, and a query node q, the edge-based minimal k-core subgraph search problem is to find all the possible edge-based minimal k-core subgraphs that include the query node q.
Example 3. In Figure 1, given a graph G and , we set node 1, which is painted orange, as the query node, and are edge-based minimal 2-core subgraphs on G including the query node since every edge in the subgraphs is critical for edge-based minimal 2-core construction. 2.4. Problem Complexity
Theorem 1. The edge-based minimal k-core subgraph search problem is NP-complete.
Proof of Theorem 1. The decision version of this problem is as follows:
: Given a graph G and integer s .
: Does G has a k-core with edge number s?
Obviously, given a solution of the problem, a nondeterministic Turing machine checks if the choice is true in polynomial time. Therefore, the edge-based minimal
k-core subgraph search problem belongs to NP. Furthermore, if we restrict the problem by considering only instances in which the number of edges of the
k-core is s, then the original problem can be transformed into a clique problem [
22]. Hence, the edge-based minimal
k-core subgraph search problem is NP-complete.
The problem of finding all edge-based minimal
k-cores also requires graphical enumeration, which refers to the art of counting the number of graphs with a specific property. Note that for some problems. to count the number of graphs with a given property is harder than to determine if there exists a graph that satisfies such a property. For instance, “Given a graph
G and a fixed value
, how many distinct
k-cores are there for
G?” is not a trivial problem and it empirically depends on the density of the graph. Enumeration problems associated with NP-complete problems are NP-hard [
22]. This is true since the enumeration version of the problem must be at least as hard as the decision version of the problem. Hence, the enumeration of edge-based minimal
k-cores is NP-hard. □
Theorem 2. The edge-based minimal k-core subgraph containing the query node q search problem is NP-complete.
Proof of Theorem 2. It is clear that the EMK-
q-SS problem belongs to NP. Now we show that the EMK-
q-SS problem is NP-complete by reducing the problem of finding the maximum clique that contains
q (MC-
q) to it. MC-
q is proved to be NP-complete in reference [
23]. Let
be a graph, and let
q be the query vertex. Consider the decision problem that corresponds to the optimization problem of MC-
q: Determine whether
G has a clique of at least
edges that contains
q. We can construct the following decision problem for EMK-
q-SS. Determine whether a solution
exists such that
and it satisfies the EMK-
q conditions: (i)
q is an endpoint for some edges in
H; (ii)
is connected; and (iii)
for any vertex
v in
. If
H is the answer, then apparently
is a clique, as any node in
H has degree
. □
3. Edge Deletion Algorithm
Inspired by [
15], we propose a backtrack algorithm for the problem. The main idea of the algorithm is to delete edges one by one in
G until we obtain the edge-based minimal
k-core. In order to accelerate the process, we first prune the original graph
G to a
k-core using a state-of-the-art algorithm [
13] for core decomposition. In the process of obtaining the result, we check if the query node is in the result set in each recursive call. The pseudocode is shown in Algorithm 1.
| Algorithm 1: Edge Deletion Algorithm. |
![Mathematics 11 03407 i001]() |
Firstly we compute the k-core in graph G. Then, we use a backtrack algorithm described in Algorithm 2 to carry out the edge deletion operation. In Algorithm 2, we use set to record the partial solution, and set is used to record the degrees of all nodes. In the beginning of each recursive call, we check if the query node is in the partial solution, if not, we just return (lines 1–3). We will decide whether degrees of nodes in are all less than k and not enough to support a k-core structure and decide if it is time to check whether the partial solution is an edge-based minimal k-core or not (line 4). If the answer is yes, then we will use the edge-based minimal k-core judge algorithm described in Algorithm 3 to check if the partial solution is exactly an edge-based minimal k-core and report the solution as an edge-based minimal k-core if there is no problem in the check process. If the nodes in are exactly an edge-based minimal k-core, we will report it and return (lines 5–8). In the main iteration, we delete one edge and update the degree of the two endpoints of the deleted edge before stepping into the next backtrack process (lines 12–16). When we finally backtrack to the current iteration, we resume the deleted edge and the degree of its endpoints (lines 18–21).
The algorithm shown in Algorithm 3, named isMinimal, that we apply to determine the edge-based minimal
k-core works as follows. According to the definition of the edge-based minimal
k-core, we delete one of the edges in the
k-core and check if there is no
k-core in the input subgraph any more. If there is still a
k-core, then the subgraph we obtained is not an edge-based minimal
k-core. We do this until all the edges have experienced being deleted to be checked. Note that if there is a node in the result set with degree equal to
k, then we only need to delete one of its adjacent edges to check if the edge-based minimal
k-core is decomposed.
| Algorithm 2: Deletion(). |
![Mathematics 11 03407 i002]() |
| Algorithm 3: isMinimal. |
![Mathematics 11 03407 i003]() |
Correctness. As we can see, in Algorithms 1 and 2, we will choose one edge to delete in each recursion. In the later recursion, the edge to be deleted is ordered by index after the current recursion. Backtracking occurs when no edges can be deleted any more to destroy the k-core structure or an edge-based minimal k-core is found, since even if the search goes on to the next recursion and still keeps going until there is no edge to be chosen, there will be no more edge-based minimal k-core to be found. When backtracking to the current recursion, we will choose an edge that has not been processed in the previous level as well as the same level in the search tree. Therefore, the solutions are complete and not repeated with one another.
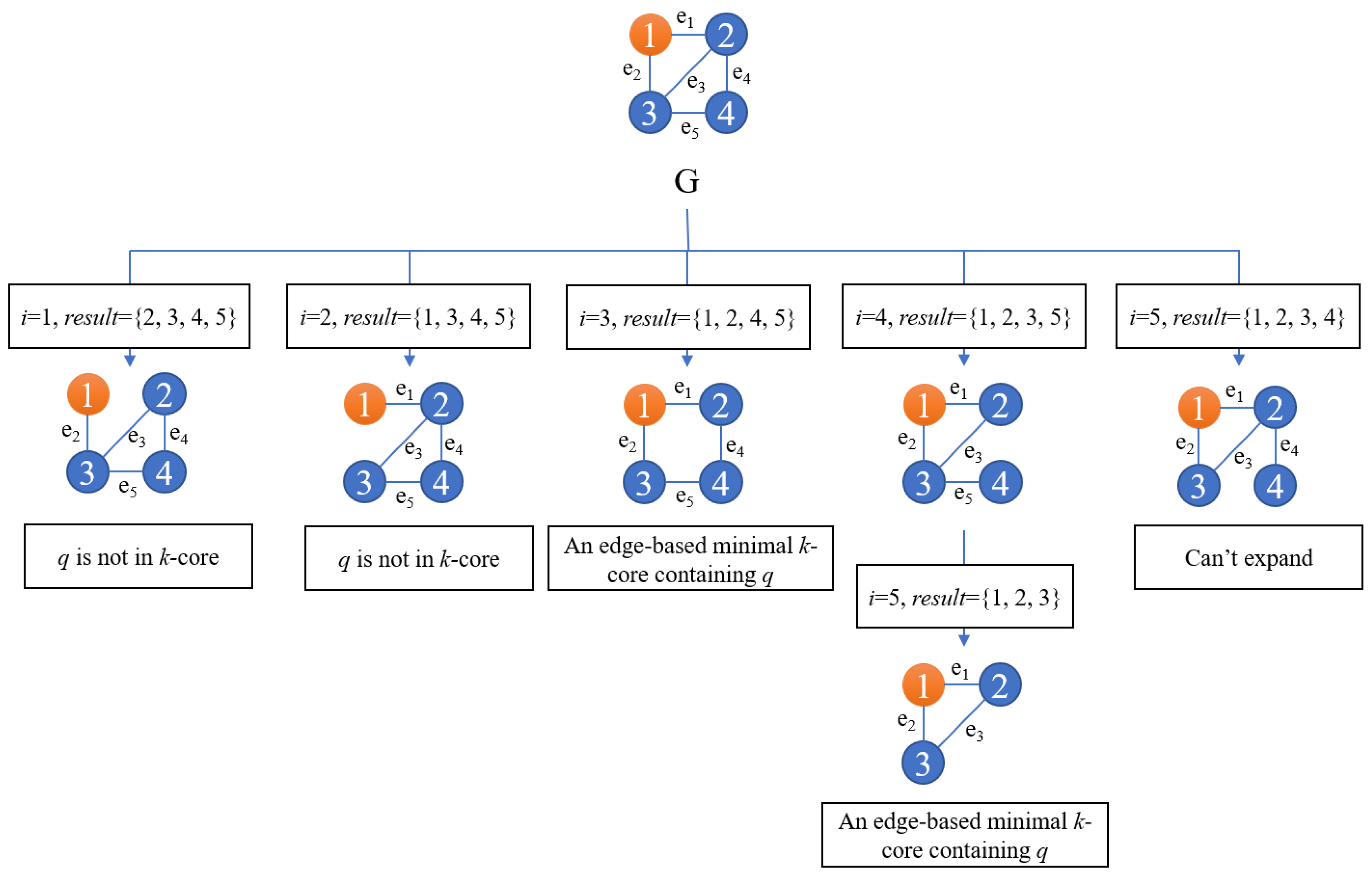
Example 4. Figure 2 shows the procedure of employing the edge deletion algorithm to search edge-based minimal 2-cores containing node 1 in the given graph G. Each edge is represented as a letter “e” and a subscript, which is also the process order. For example, edge 1 is denoted as and is to be processed at the first step. As shown in Figure 2, if edge 1 is selected to be deleted, then the query node q is not contained in the result set, so the program returns to the previous step, in which edge 1 is restored. In accordance with loop order, the next edge to be deleted is edge 2, q is not contained in the result set too after removing edge 2. Next, edge 3 is selected to be deleted, this time, an edge-based minimal k-core containing node 1 is obtained. Another edge-based minimal k-core containing node 1 occurs when edge 4 is removed and soon edge 5 is deleted. We return to the state when edge 4 is deleted and find there are no edges left to be processed. As a result, we return to the original state and choose edge 5 to be deleted. As no edges remain as candidates to be chosen, we judge the current subgraph is not satisfying and return. The algorithm is finished. Pruning. It is apparent that if the degree of a node in k-core is equal to
k, then once the node loses one of its adjacent edges, it will not satisfy the degree constraint of
k-core any more. For instance, in
Figure 2, when edge 4 is deleted, edge 5 has to be chosen to be deleted, for node 4 is not contained in 2-core definitely and not contained in edge-based minimal 2-core naturally.
Therefore, we reindex the adjacent edges of nodes with degree in k-core equal to k to be in the same status. If we delete one adjacent edge of this kind of node, other adjacent edges of this node will be deleted too.
Complexity. The main time cost is produced by the algorithm deletion shown in Algorithm 2, so we only discuss the complexity of deletion. Suppose the number of edges in
k-core is
. We start to delete from the first edge, in the first recursive call we have
different choices of edges from
k-core in the worst case, in the second recursive call we have
edges to choose from. As the function goes on, we delete edges until we obtain the result we want, or we have no edges to delete. Hence, in the worst case there are
nested loops and the time complexity is given by
if we assume that in each recursive call the processing time is
. In fact, in each recursive call, we need to compute the core number of vertices in the set
in order to check if the current graph induced by edges in
is an edge-based minimal
k-core. This is achieved with the help of the core decomposition method, whose time complexity is
(suppose
) [
13]. Notice that in the check function
isMinimal we need to delete each edge and compute core number separately. So the total complexity is
.
Considering the additional edge reindex operation, the new complexity will be if we denote the number of edges after reindexing as .
7. Related Works
The
k-core computation problem is a fundamental problem in graph data mining and was first introduced by Seidman [
24]. Seidman also derived an algorithm to obtain
k-core of a given graph by removing the nodes with degree less than
k recursively.
k-core can be used in various applications, such as specific organization function prediction or understanding biology [
25,
26,
27,
28], maintaining stability in mutualistic ecosystems [
29], internet graph evaluation at the autonomous system level in computer science [
30,
31], to measure users’ influence in social networks [
9,
32,
33,
34], determining nodes’ impact in information spreading [
35,
36,
37], and community exploration in community detection [
38,
39,
40]. Batagelj and Zaversnik [
13] designed a linear in-memory algorithm to derive core numbers of vertices in a graph using a variant of bin-sort. In order to provide core decomposition for large graphs that are stored in secondary storage, I/O efficient algorithms for core decomposition have been proposed [
41,
42].
The minimum
k-core search problem is attractive in k-core problems [
10,
15], for it is able to offer a reasonable strategy when the budget is limited in applications such as advertisement delivery. In [
15], minimum
k-cores are used to model cell assemblies and are obtained by using a backtrack search tree. Ref. [
18] aims at finding the smallest
k-core containing the given query nodes and delivers an approximate method which extends the partial solution from the query nodes.
Some researchers have studied the problem of minimum
k-core in variant models. In [
12], the authors try to obtain the minimum
k-core after finding
b edges to delete in the graph given budget
b. The problem definition has been developed into two ways, one is to obtain the remaining graph with the least nodes, the other is to obtain the remaining graph with the least edges after
b edges have been removed [
43].















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}