

GERPM: A Geographically Weighted Stacking Ensemble Learning-Based Urban Residential Rents Prediction Model
Abstract
:1. Introduction
- Comprehensive analysis of factors influencing rental prices: Using Nanjing City in China as an example, this paper obtains housing-related data from various sources and conducts statistical analysis. This includes real data on rental prices and home attributes, point of interest (POI) data near homes provided by the Baidu Map Open Platform, and economic and demographic data of different regions from the website of the Bureau of Statistics. The study comprehensively analyzes the impact of architectural characteristics, environmental characteristics, and regional characteristics on rental prices and employs the recursive feature elimination and random forest method to select the feature variables that significantly influence rental prices for constructing a prediction model.
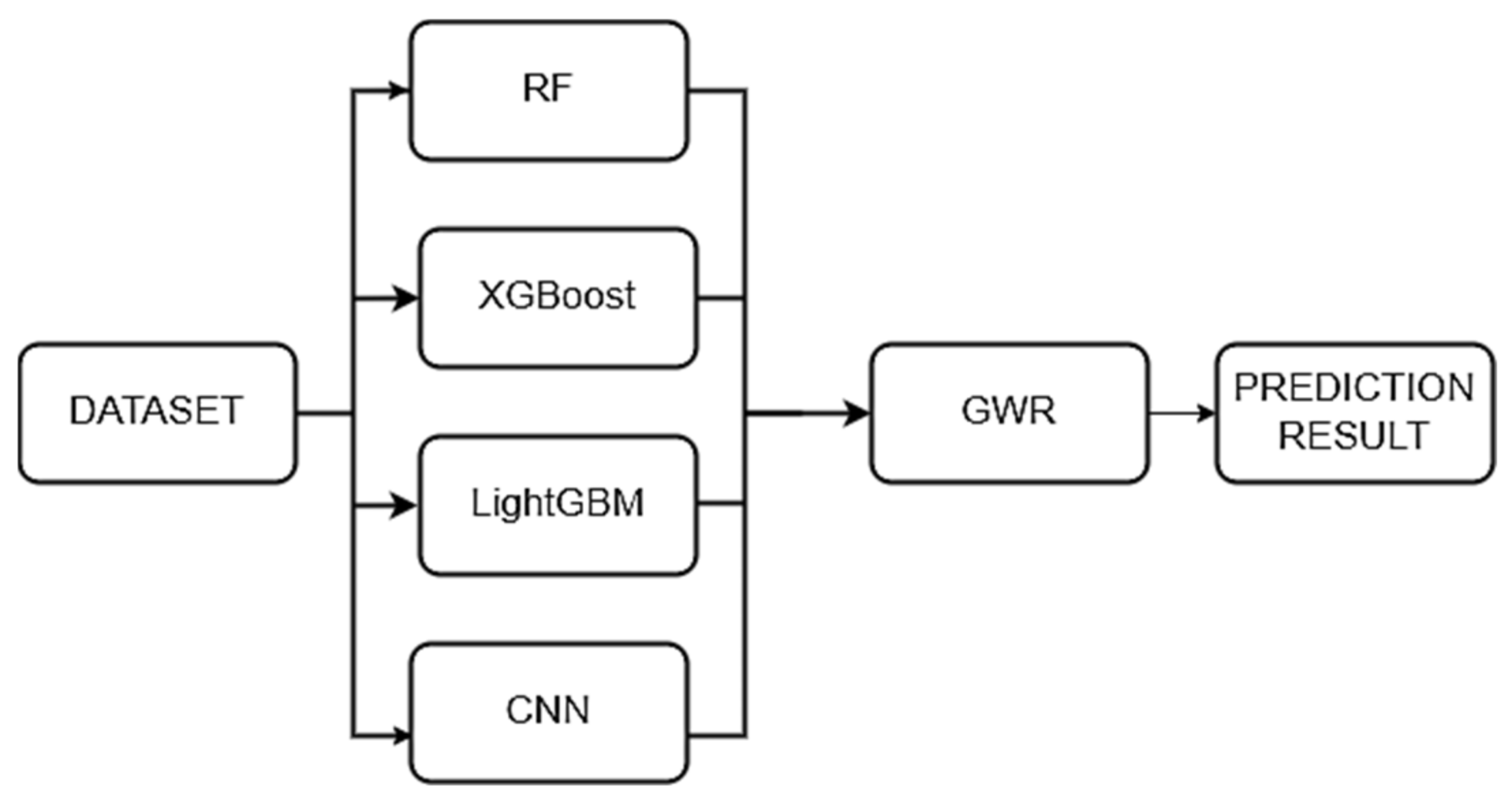
- Development of the GERPM model: GERPM integrates random forest, XGBoost, LightGBM, and CNN models for rental price prediction. The Optuna framework is used for grid search and automatic parameter adjustment to optimize machine learning parameters. The parameter adjustment process is visualized to achieve optimal prediction results. Considering the influence of geographical location on rental prices, spatial autocorrelation testing is conducted, and a stacking-based ensemble learning model that integrates GWR is established. The aforementioned machine learning and deep learning models serve as base learners, while GWR serves as the meta learner.
- Prediction results and robustness analysis: The prediction results of GERPM are compared with individual models, the equal weight combination model, and ensemble learning models that do not consider geographical factors. The performance of GERPM is evaluated using metrics such as mean square error (MSE), root mean square error (RMSE), and coefficient of determination (R2). In addition, GERPM is validated using housing data from other cities such as Shanghai and Hangzhou to assess its robustness.
2. Related Work
3. Proposed Method
3.1. Preprocessing
3.1.1. Data
3.1.2. Missing Value Processing
- Delete: If a feature has more missing values and provides less information, it can be directly deleted. If there are fewer missing values for a feature, we can choose to delete the sample containing the missing value. This is a simple and direct method that is suitable for data with a large sample size and many features. However, when the proportion of missing value data is large, opting to directly delete the sample can disrupt the relationship between the data and affect the comprehensiveness of the data.
- Imputation: If there are fewer missing values for a feature, directly deleting the feature may result in the loss of important information and affect the learning ability of the model. In this case, we can choose to fill in the data using the following methods: mean value filling, proximity value filling, maximum likelihood estimation filling, etc.
- Non processing: Data deletion and imputation can alter the original dataset to a certain extent. Improper processing can introduce new noise and affect the accuracy of prediction. Using no processing methods can ensure the preservation of complete information from the original dataset.
3.1.3. Handling of Abnormal Values
- Statistical analysis: Conduct descriptive statistics on the dataset to obtain information such as mean, maximum, and minimum values. For example, we can use the describe function of the Pandas library in Python, and combine data visualization techniques such as scatter plots, histograms, and kernel density plots to observe the data distribution and identify outliers.
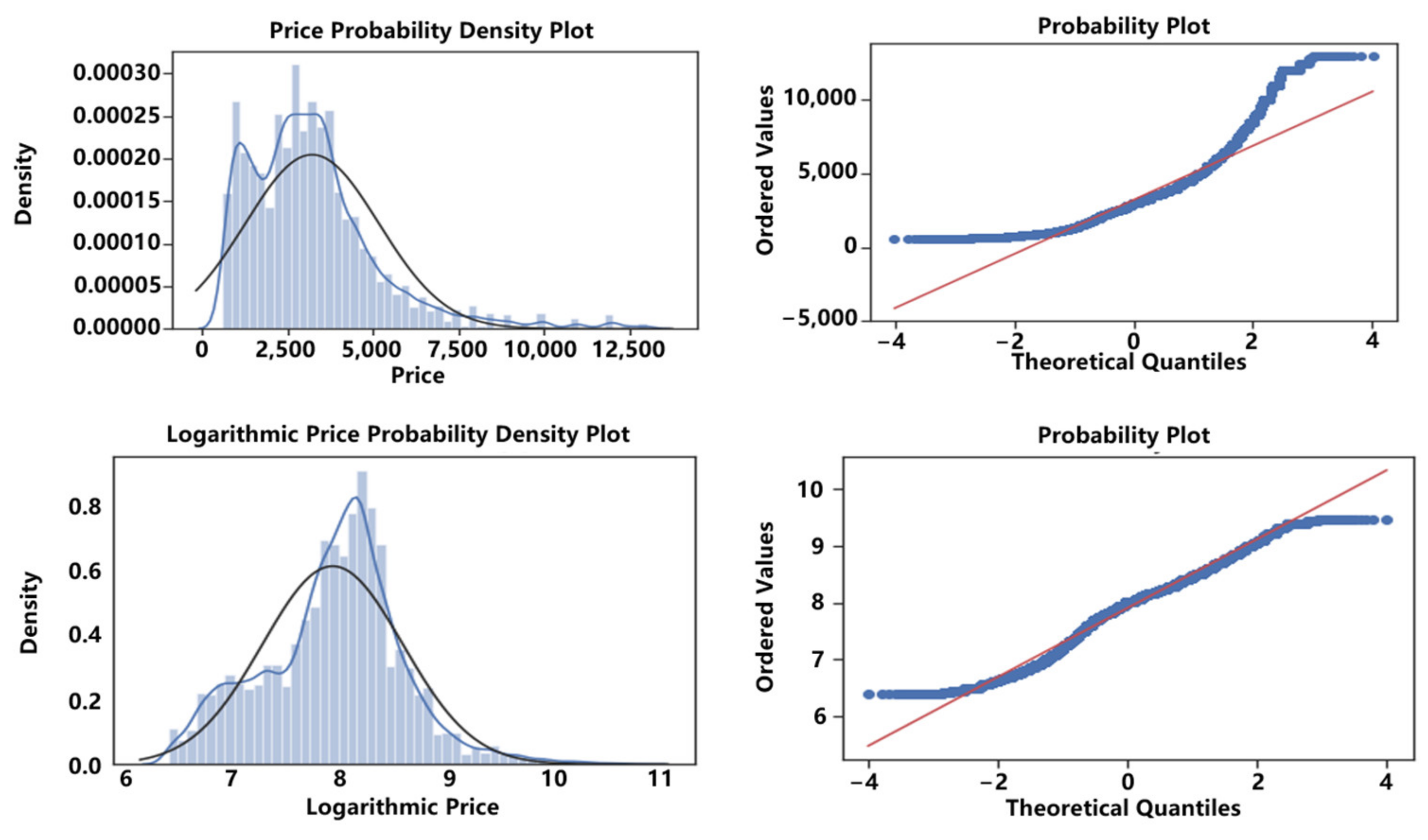
- 3σ Principle: If the data follow a normal distribution or is close to a normal distribution, values that deviate from the average value by more than three times the standard deviation are considered abnormal values. Under this setting, the probability of data other than three times the standard deviation occurring is extremely small, and when it occurs, it can be considered an outlier.
- Boxplot analysis: We can define as the upper quartile and as the lower quartile. Data points that are less than or greater than are considered outliers.
3.1.4. Quantification of Categorical Features
One-Hot Encoding
Quantification of Unit Type Variable
3.1.5. Normalization of Numerical Features
Min–Max Normalization
Z-Score Normalization
3.1.6. Logarithmic Processing of Dependent Variables
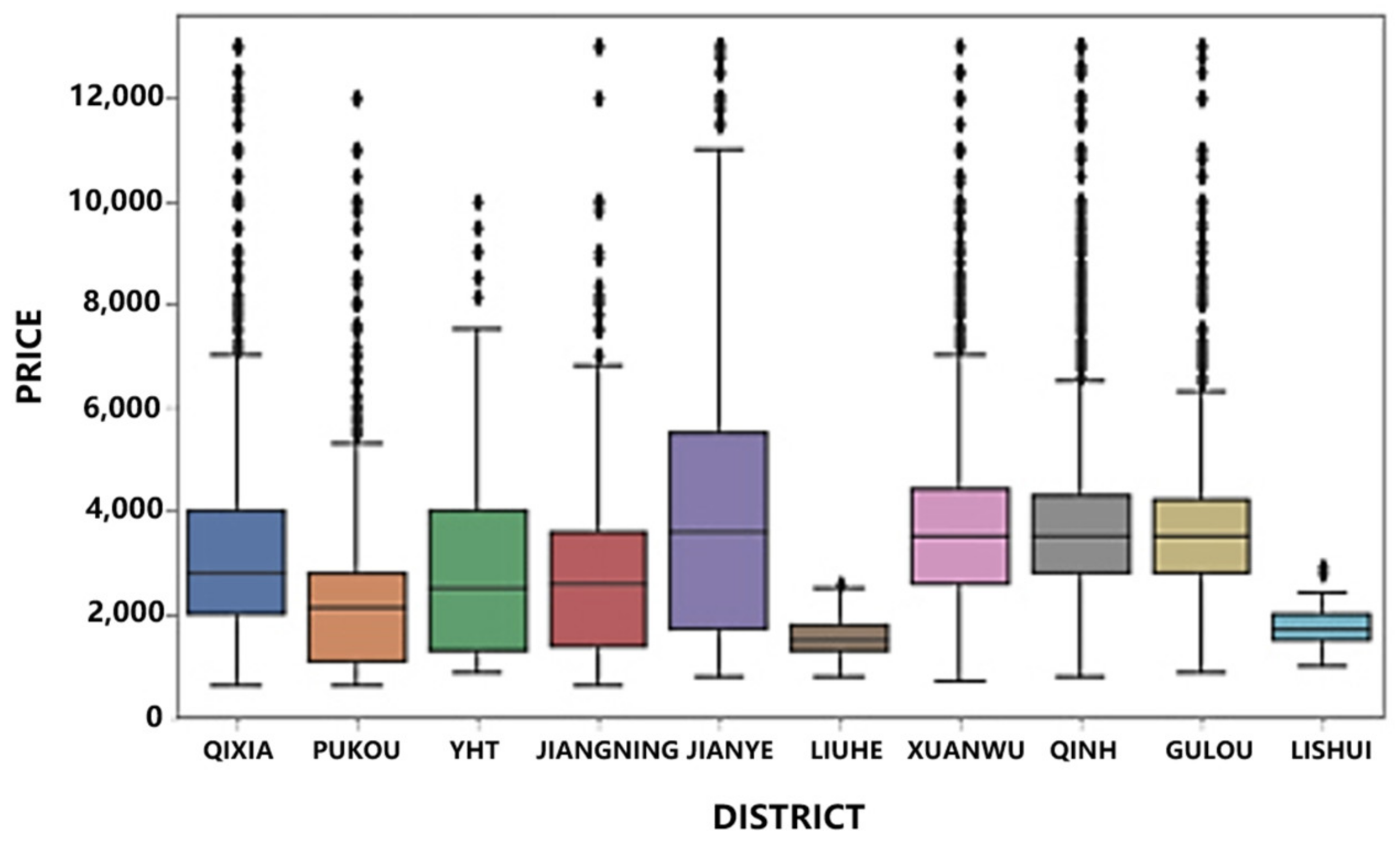
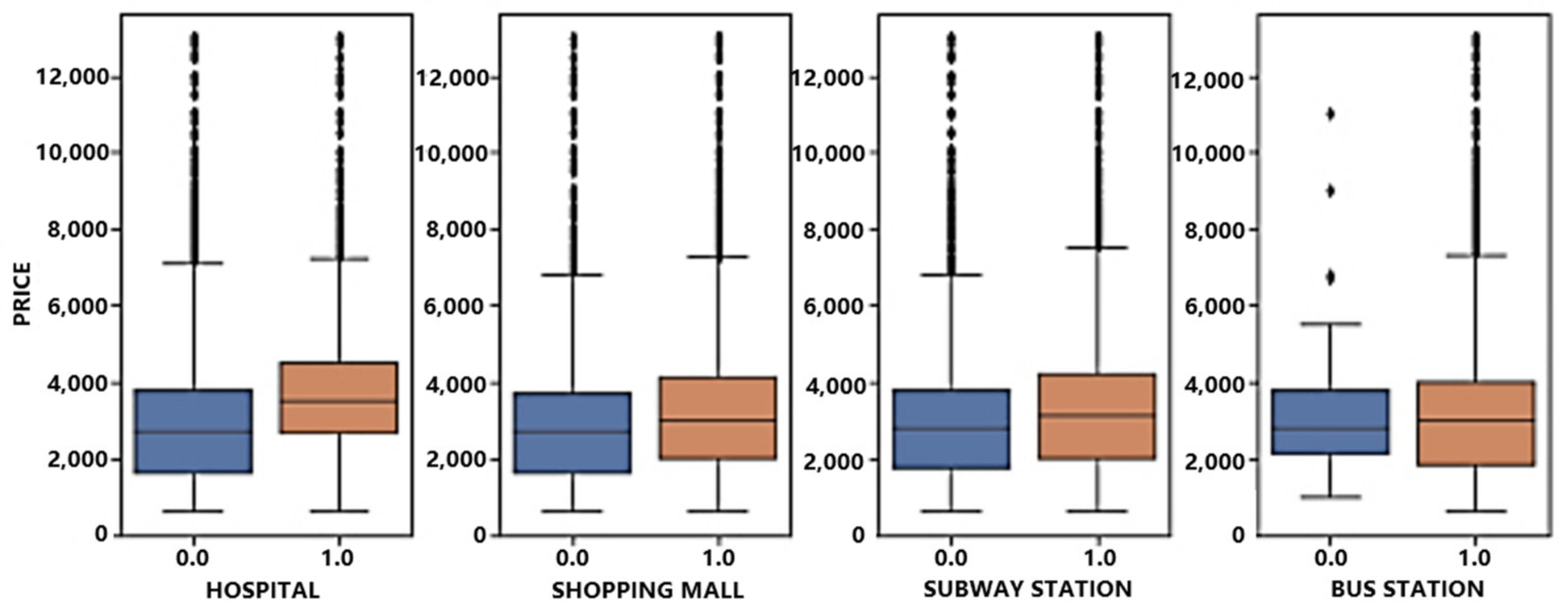
3.1.7. Data Visualization
3.1.8. Variable Selection
- Filter: Features are first selected according to predefined criteria, followed by training the learner. These two parts do not influence each other.
- Wrapper: After multiple training iterations, the model’s performance serves as an evaluation criterion for a subset of features. This method is more computationally intensive than filter-based approaches but offers better results.
- Embedding: The initial step involves selecting a training set, followed by using the selected data to train the learner. This method integrates feature selection and model training processes, optimizing both selection and training simultaneously.
3.2. Model Implementation
3.2.1. Base Learners and Meta Learner
Random Forest
LightGBM
XGBoost
CNN
Meta Learner
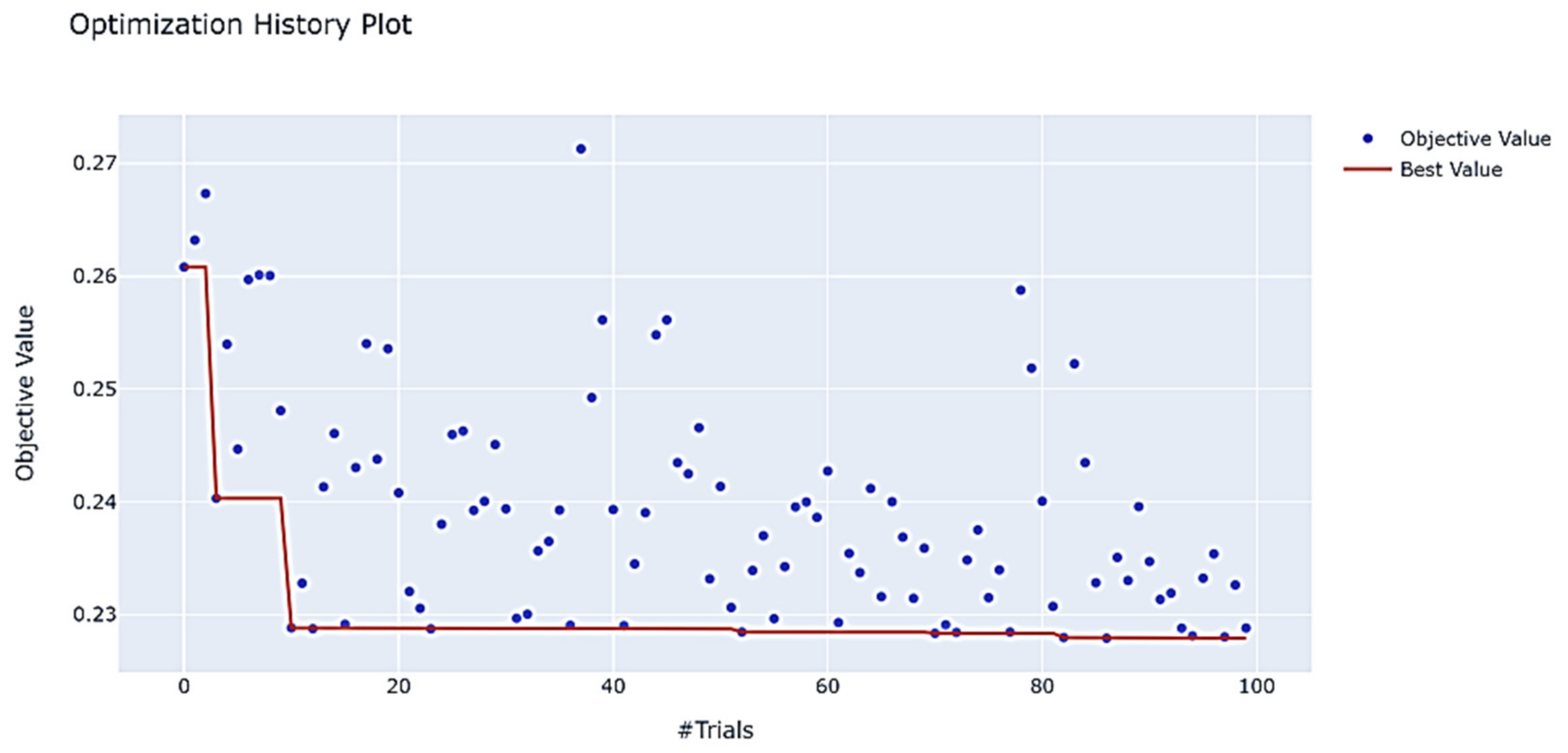
3.2.2. Parameter Tuning
Random Forest Model Parameter Tuning
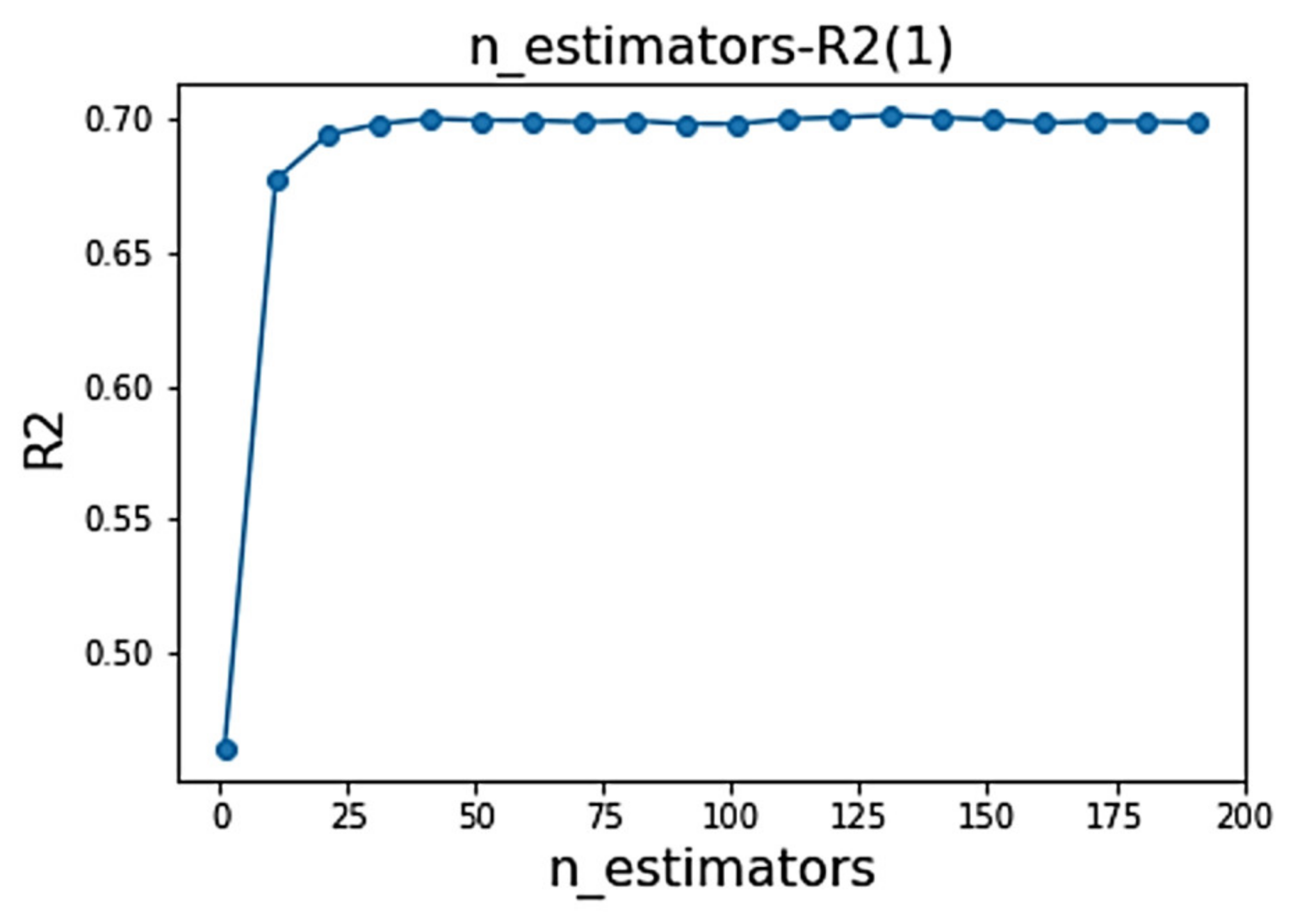
- n_estimators—the number of decision trees, which is also the iteration number of weak learners;
- max_features—the number of randomly selected features for each decision tree;
- min_samples_split—the minimum number of samples required to split internal nodes;
- min_samples_leaf—the minimum number of samples that should be present on a leaf node.
LightGBM Model Parameter Tuning
- n_estimators: trial.suggest_int (“n_estimators”, 100, 2000, step = 10)—the number of iterations, selected based on the characteristics of the dataset, with a search range of (100, 2000).
- learning_rate: trial.suggest_float (“learning_rate”, 0.01, 0.2)—learning rate, controlling the convergence speed, with a search range of (0.01, 0.2).
- max_depth: trial.suggest_int (“max_depth”, 3, 10)—the maximum depth of the tree model, the most important parameter to prevent overfitting and has a significant impact on model performance, with a search range of (3, 10).
- num_leaves: trial.suggest_int (“num_leaves”, 20, 3000, step = 20)—the number of leaf nodes on a tree, working with max_depth to control the shape of the tree, with a search range of (20, 3000).
- min_data_in_leaf: trial.suggest_int (“min_data_in_leaf”, 10, 100, step = 10)—the minimum amount of data on a leaf, with a search range of (10, 100).
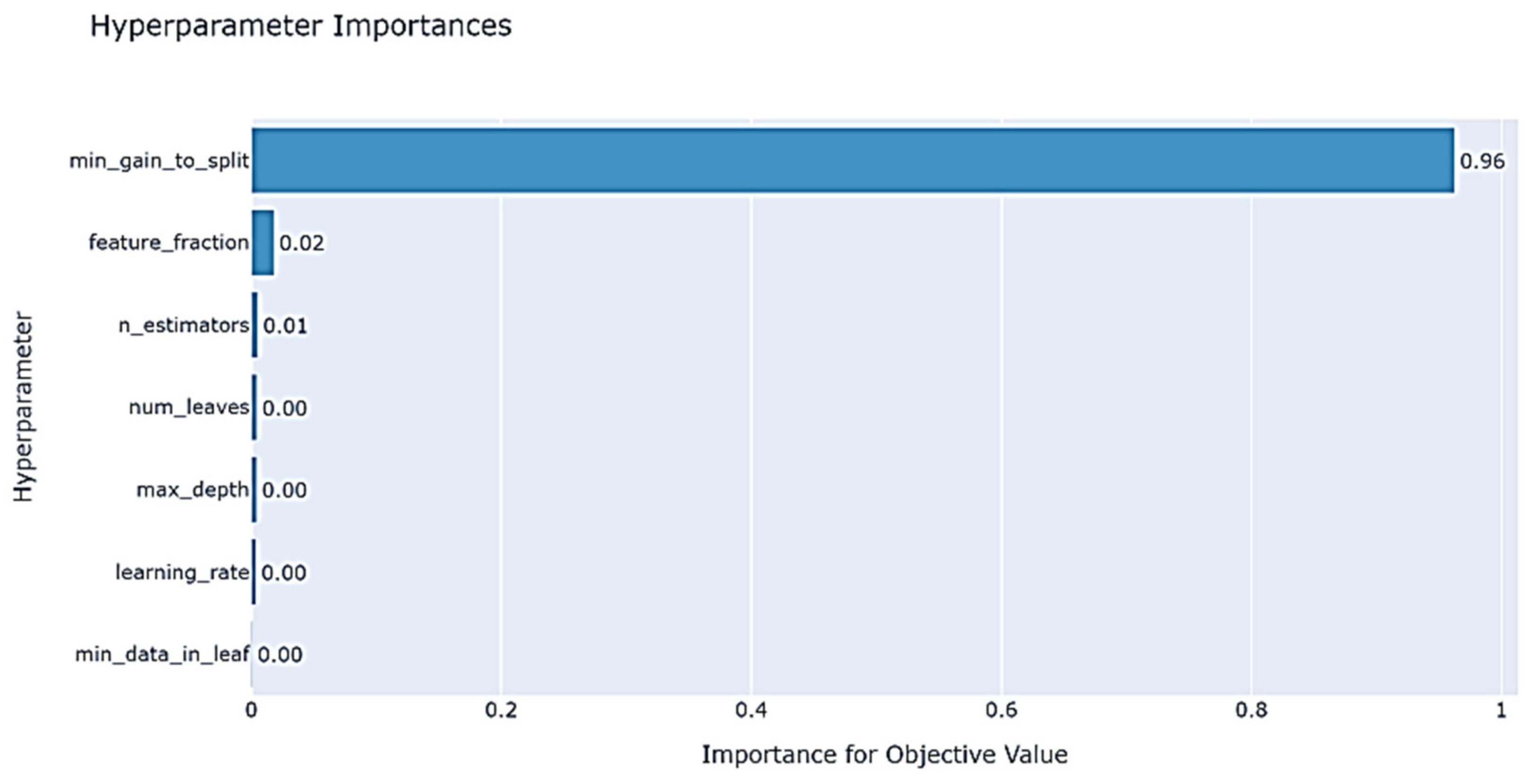
- min_gain_to_split: trial.suggest_float (“min_gain_to_split”, 0, 15)—the minimum gain threshold for splitting, with a search range of (0, 15).
- feature_fraction: trial.suggest_float (“feature_fraction”, 0.2, 0.95, step = 0.1)—randomly selects the feature ratio in each iteration, with a search range of (0.2, 0.95).
XGBoost Model Parameter Tuning
- learning_rate: trial.suggest_categorical (‘learning_rate’, (0.008, 0.009, 0.01, 0.012, 0.014, 0.016, 0.018, 0.02))—the learning rate, controlling the convergence rate. After the experiments, the learning rate search range is determined to be between 0.01 and 0.02.
- n_estimators: trial.suggest_int (“n_estimators”, 1,002,000, step = 10)—the number of iterations, selected based on the characteristics of the dataset, with a search range of (100, 2000).
- max_depth: trial.suggest_categorical (‘max_depth’, [3, 6, 9, 12, 15, 18, 21, 24])—the maximum depth of a tree model, the most important parameter to prevent overfitting, and has an important impact on model performance. The search range for max_depth is from 3 to 25 in terms of integers.
- min_child_weight: trial.suggest_int (‘min_child_weight’, 1, 100)—the minimum sample weight sum in the leaf node. If the sum of sample weights for a leaf node is less than min_child_weight, the split process ends. The search range is (1, 100).
CNN Model Parameter Tuning
- Activation function of neurons: The activation function enables neural networks to have the ability to perform non-linear prediction. It converts the results of each layer of neural networks after linear calculations into non-linearities. The ReLU function has the ability to zero out the output of certain neurons, thereby suppressing overfitting.
- Dropout Layer: During the training process of the neural network, some neurons are randomly selected for deletion to suppress overfitting.
- Batch_size: The batch size refers to the amount of data randomly input during each iteration of neural network training. If the batch size is too small, gradient updates are too slow, and while if it is too large, the global optimal solution becomes difficult to determine.
- Epoch: Completing a round of learning using all the data is known as completing the training process. Increasing the number of epochs is conducive to iteratively adjusting the weight parameters of the model towards their optimal value.
- Loss Function: The model parameters are updated by calculating the model’s error during the training process. This study employs the mean square as its loss function.
- Optimizer: A neural network with multiple layers and parameters may require a significant amount of time to train. To accelerate the training process, different optimizers provide different optimization paths based on their respective principles. Selecting an appropriate optimizer can reduce the training time and improve the overall training efficiency. This study utilizes the Adam optimizer with a learning rate of 0.001.
3.2.3. Constructing an Ensemble Learning Model Based on Stacking
Analysis of Spatial Autocorrelation
Building a Stacking Ensemble Learning Model
4. Results and Analysis
4.1. Evaluation Metrics
4.2. Prediction Results Comparison and Analysis
4.3. Robustness Analysis
4.3.1. Prediction Results of Residential Rents in Shanghai
4.3.2. Prediction Results of Rental Prices in Hangzhou City
4.4. Summary
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rajan, U.; Seru, A.; Vig, V. The failure of models that predict failure: Distance, incentives, and defaults. J. Financ. Econ. 2015, 115, 237–260. [Google Scholar] [CrossRef]
- Neloy, A.A.; Haque, H.M.S.; Islam, M.M.U. Ensemble Learning Based Rental Apartment Price Prediction Model by Categorical Features Factoring. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019. [Google Scholar]
- Zhang, X.Y. Rent Prediction Based on Stacking Regression Model and Baidu Map API. Master’s Thesis, Lanzhou University, Lanzhou, China, 2022. [Google Scholar]
- Henderson, J.V.; Ioannides, Y.M. A Model of Housing Tenure Choice. Am. Econ. Rev. 1983, 73, 98–113. [Google Scholar]
- Ioannides, Y.M.; Rosenthal, S.S. Estimating the Consumption and Investment Demands for Housing and Their Effect on Housing Tenure Status. Rev. Econ. Stat. 1994, 76, 127–141. [Google Scholar] [CrossRef]
- Shen, H.; Li, L.; Zhu, H.; Liu, Y.; Luo, Z. Exploring a Pricing Model for Urban Rental Houses from a Geographical Perspective. Land 2021, 11, 4. [Google Scholar] [CrossRef]
- Zhai, D.; Shang, Y.; Wen, H.; Ye, J. Housing price, housing rent, and rent-price ratio: Evidence from 30 cities in China. J. Urban Plan. Dev. 2018, 144, 04017026. [Google Scholar] [CrossRef]
- Bin, J.; Gardiner, B.; Li, E.; Liu, Z. Multi-Source Urban Data Fusion for Property Value Assessment: A Case Study in Philadelphia. Neurocomputing 2020, 404, 70–83. [Google Scholar] [CrossRef]
- Li, H.; Wei, Y.D.; Wu, Y. Analyzing the private rental housing market in shanghai with open data. Land Use Policy 2019, 85, 271–284. [Google Scholar] [CrossRef]
- Valente, J.; Wu, S.; Gelfand, A.; Sirmans, C.F. Apartment rent prediction using spatial modeling. J. Real Estate Res. 2005, 27, 105–136. [Google Scholar] [CrossRef]
- Choi, S.J.; Kim, S. Why do landlords include utilities in rent? Evidence from the 2000 Housing Discrimination Study (HDS) and the 2002 American Housing Survey (AHS). J. Hous. Econ. 2012, 21, 28–40. [Google Scholar] [CrossRef]
- Han, L.; Wei, Y.D.; Yu, Z.; Tian, G. Amenity, accessibility and housing values in metropolitan USA: A study of Salt Lake County, Utah. Cities 2016, 59, 113–125. [Google Scholar]
- Song, W.X.; Ma, Y.Z.; Chen, Y.R. Spatial and temporal variations in home price sales and rental prices in Nanjing urban area and their influencing factors. Geosci. Prog. 2018, 37, 1268–1276. [Google Scholar]
- Liu, C. Research on the Influencing Factors and Prediction of Housing Prices in Beijing. Master’s Thesis, Dalian University of Technology, Dalian, China, 2019. [Google Scholar]
- Islam, M.D.; Li, B.; Islam, K.S.; Ahasan, R.; Mia, M.R.; Haque, M.E. Airbnb rental price modeling based on Latent Dirichlet Allocation and MESF-XGBoost composite model. Mach. Learn. Appl. 2022, 7, 100208. [Google Scholar] [CrossRef]
- Xie, Y.; Zhang, W.; Ji, M.Z.; Peng, J.; Huang, Y.H. Application analysis of housing month rent prediction based on XGBoost and LightGBM algorithms. Comput. Appl. Softw. 2019, 36, 151–155. [Google Scholar]
- Liang, R. Based on Machine Learning Model Research on Housing Rent in Shenzhen. Master’s Thesis, Huazhong Normal University, Wuhan, China, 2020. [Google Scholar]
- Liu, S.Y. Machine Learning Methods for Analyzing the Influencing Factors of Urban Rental Prices. Master’s Thesis, Nankai University, Tianjin, China, 2021. [Google Scholar]
- Kang, Y.; Zhang, F.; Peng, W.; Gao, S.; Rao, J.; Duarte, F.; Ratti, C. Understanding house price appreciation using multi-source big geo-data and machine learning. Land Use Policy 2021, 111, 104919. [Google Scholar] [CrossRef]
- Wang, X.; Wen, J.; Zhang, Y.; Wang, Y. Real estate price forecasting based on SVM optimized by PSO. Optik 2014, 125, 1439–1443. [Google Scholar] [CrossRef]
- Tang, X.B.; Zhang, R.; Liu, L.X. Research on Prediction of Second-hand House Prices in Beijing Based on Bat Algorithm SVR Model. Stat. Res. 2018, 35, 71–81. [Google Scholar]
- Aziz, M.A.; Nurrahim, F.; Susanto, P.E.; Windiatmoko, Y. Boarding House Renting Price Prediction Using Deep Neural Network Regression on Mobile Apps. arXiv 2020, arXiv:2101.02033. [Google Scholar]
- Wang, P.Y.; Chen, C.T.; Su, J.W.; Wang, T.Y.; Huang, S.H. Deep learning model for house price prediction using heterogeneous data analysis along with joint self-attention mechanism. IEEE Access 2021, 9, 55244–55259. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Branco, P.; Zhang, H. Imbalanced Multimodal Attention-Based System for Multiclass House Price Prediction. Mathematics 2023, 11, 113. [Google Scholar] [CrossRef]
- Divina, F.; Gilson, A.; Goméz-Vela, F.; García Torres, M.; Torres, J.F. Stacking ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef] [Green Version]
- Jiang, M.; Liu, J.; Zhang, L.; Liu, C. An improved Stacking framework for stock index prediction by leveraging tree-based ensemble models and deep learning algorithms. Phys. A Stat. Mech. Its Appl. 2020, 541, 122272. [Google Scholar] [CrossRef]
- Kshatri, S.S.; Singh, D.; Narain, B.; Bhatia, S.; Quasim, M.T.; Sinha, G.R. An empirical analysis of machine learning algorithms for crime prediction using stacked generalization: An ensemble approach. IEEE Access 2021, 9, 67488–67500. [Google Scholar] [CrossRef]
- Lei, Y.T. Prediction of House Prices of Hardcover Houses Based on Regression Model Integration. Master’s Thesis, Lanzhou University, Lanzhou, China, 2020. [Google Scholar]
- Truong, Q.; Nguyen, M.; Dang, H.; Mei, B. Housing price prediction via improved machine learning techniques. Procedia Comput. Sci. 2020, 174, 433–442. [Google Scholar] [CrossRef]
- Srirutchataboon, G.; Prasertthum, S.; Chuangsuwanich, E.; Pratanwanich, P.N.; Ratanamahatana, C. Stacking ensemble learning for housing price prediction: A case study in Thailand. In Proceedings of the 13th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 21–24 January 2021. [Google Scholar]
- Denisko, D.; Hoffman, M.M. Classification and interaction in random forests. Proc. Natl. Acad. Sci. USA 2018, 115, 1690–1692. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, J.W.; Yang, Y. Ensemble Learning Methods: A Research Review. J. Yunnan Univ. (Nat. Sci. Ed.) 2018, 40, 1082–1092. [Google Scholar]
- Tang, C.F.; Nu, E.; Ai, Z. Research on Network Intrusion Detection Based on LightGBM. Comput. Appl. Softw. 2022, 39, 298–303+311. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Zhu, M.; Guan, X.; Li, Z.; He, L.; Wang, Z.; Cai, K. sEMG-Based Lower Limb Motion Prediction Using CNN-LSTM with Improved PCA Optimization Algorithm. J. Bionic Eng. 2023, 20, 612–627. [Google Scholar] [CrossRef]
- Chen, C.; Du, Z.; He, L.; Shi, Y.; Wang, J.; Dong, W. A Novel Gait Pattern Recognition Method Based on LSTM-CNN for Lower Limb Exoskeleton. J. Bionic Eng. 2021, 18, 1059–1072. [Google Scholar] [CrossRef]
- Wang, J.; Wu, D.; Gao, Y.; Wang, X.; Li, X.; Xu, G.; Dong, W. Integral Real-time Locomotion Mode Recognition Based on GA-CNN for Lower Limb Exoskeleton. J. Bionic Eng. 2022, 19, 1359–1373. [Google Scholar] [CrossRef]
- Zhang, J.J. Remaining Life Prediction of Aeroengine Based on Attention Mechanism and CNN-BiLSTM Model. J. Electron. Meas. Instrum. 2022, 36, 231–237. [Google Scholar]
- Cong, Y.R.; Wang, Y.G.; Yu, L.J.; Li, G.D. Spatio-temporal impact of land use factors on passenger flow in urban rail transit stations. Urban Rail Transit Res. 2021, 24, 116–121. [Google Scholar]
- Zakaria, F.; Fatine, F.A. Towards the hedonic modelling and determinants of real estates price in Morocco. Soc. Sci. Humanit. Open 2021, 4, 100176. [Google Scholar] [CrossRef]
- Won, J.; Lee, J.S. Investigating How the Rents of Small Urban Houses Are Determined: Using Spatial Hedonic Modeling for Urban Residential Housing in Seoul. Sustainability 2018, 10, 31. [Google Scholar] [CrossRef] [Green Version]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| price | monthly rental price of the home, in CNY |
| area | area of the home, in square meters |
| district | administrative district where the home is located |
| unit type | unit type of the home, such as a unit with one bedroom, one living room, and one bathroom |
| orientation | orientation of the home, including south, north, east, west, southeast, etc. |
| floor | floor of the home, including low floor, medium floor, and high floor |
| total number of floors | total number of floors of the building |
| rental method | whole lease or share lease |
| gas | whether the home has gas |
| elevator | whether the home has an elevator |
| fitment | whether the home is well decorated |
| longitude | rental home’s longitude |
| latitude | rental home’s latitude |
| District | A, in People | B, in 100 Million Yuan | C, in 100 Million Yuan | D, in 100 Million Yuan | E, in 100 Million Yuan |
|---|---|---|---|---|---|
| Xuanwu | 537,825 | 1205.94 | 105.08 | 1184.73 | 1129.77 |
| Qinhuai | 740,809 | 1324.42 | 110.52 | 1231.05 | 1031.04 |
| Jianye | 534,257 | 1214.95 | 161.66 | 837.71 | 451.24 |
| Gulou | 940,387 | 1921.08 | 176.59 | 1767.93 | 1145.73 |
| Pukou | 1,171,603 | 490.48 | 78.17 | 282.28 | 150.10 |
| Qixia | 987,835 | 1708.88 | 151.76 | 723.35 | 512.01 |
| Yuhuatai | 608,780 | 1015.55 | 91.58 | 832.05 | 731.18 |
| Jiangning | 1,926,117 | 2810.47 | 265.30 | 1219.78 | 1032.02 |
| Liuhe | 946,563 | 567.56 | 52.72 | 289.02 | 294.05 |
| Lishui | 491,336 | 1000.95 | 81.88 | 435.55 | 398.12 |
| Variable | Distance to Nearest Subway Station | Distance to Nearest Shopping Mall | Distance to Nearest Hospital | Distance to Nearest Bus Stop |
|---|---|---|---|---|
| missing quantity | 9 | 10 | 3 | 42 |
| missing ratio | 0.03% | 0.04% | 0.01% | 0.17% |
| Encoding before | Encoding after | ||
|---|---|---|---|
| low floor | 1 | 0 | 0 |
| medium floor | 0 | 1 | 0 |
| high floor | 0 | 0 | 1 |
| Before Processing | After Processing | |
|---|---|---|
| deviation | 3.3 | −0.08 |
| kurtosis | 19.2 | 0.13 |
| Before Variable Selection | After Variable Selection |
|---|---|
| area, bedroom, living room, bathroom, subway, bus, shopping mall, hospital, park, office building, supermarket, population, population proportion, regional GDP, general public budget income, added value of the tertiary industry, total retail sales of social consumer goods, floor_0, floor_1, floor_2, gas_0, gas_1, whole_rent_0, whole_rent_1, elevator_0, elevator_1, decoration_0, decoration_1, orientation_0, orientation_1 | area, bedroom, bathroom, distance to the nearest subway station, distance to the nearest shopping mall, distance to the nearest hospital, distance to the nearest bus stop, park, population, regional GDP, floor_1, elevator_1, decoration_0, decoration_1 |
| Variable Name | Variable Description | |
|---|---|---|
| default value | - | 0.690 |
| n_estimators | 120 | 0.702 |
| max_depth | 12 | 0.705 |
| max_features | 9 | 0.706 |
| min_samples_split | 9 | 0.701 |
| min_samples_leaf | 6 | 0.698 |
| Parameter Name | Parameter Value |
|---|---|
| n_estimators | 120 |
| max_depth | 12 |
| max_features | 9 |
| min_samples_split | 2 |
| min_samples_leaf | 4 |
| Parameter Name | Parameter Value |
|---|---|
| learning_rate | 0.02 |
| max_depth | 7 |
| n_estimators | 800 |
| min_data_in_leaf | 10 |
| min_gain_to_split | 0.017 |
| num_leaves | 1020 |
| feature_fraction | 0.9 |
| Parameter Name | Parameter Value |
|---|---|
| learning_rate | 0.012 |
| max_depth | 9 |
| n_estimators | 1630 |
| min_child_weight | 19 |
| Parameter Name | Parameter Value |
|---|---|
| dropout | 0.3 |
| epoch | 50 |
| batch_size | 32 |
| Model | MSE | RMSE | |
|---|---|---|---|
| RF | 0.714 | 0.08 | 0.282 |
| LightGBM | 0.742 | 0.0736 | 0.269 |
| XGBoost | 0.734 | 0.0748 | 0.271 |
| CNN | 0.732 | 0.0642 | 0.253 |
| equal weight method | 0.828 | 0.194 | 0.44 |
| stacking (OLS) | 0.858 | 0.052 | 0.228 |
| GERPM | 0.87 | 0.047 | 0.216 |
| Before Variable Selection | After Variable Selection |
|---|---|
| area, bedrooms, living rooms, bathrooms, subways, buses, shopping malls, hospitals, parks, office buildings, supermarkets, permanent population in each district, general public budget revenue in each district, operating revenue of service industry enterprises above designated size in each district, GDP in each district, and floors_0, floor_1, floor_2, gas_0, gas_1, whole rent_0, whole rent_1, elevator_0, elevator_1, decoration_0, decoration_1, orientation_0, orientation_1 | area, rooms, subways, supermarkets, office buildings, shopping malls, hospitals, permanent residents in each district, operating income of service industry enterprises above designated size in each district, GDP in each district, elevator_1, decoration_0, decoration_1 |
| Parameter Name | Parameter Value |
|---|---|
| n_estimators | 149 |
| max_depth | 17 |
| max_features | 4 |
| min_samples_split | 3 |
| min_samples_leaf | 1 |
| Parameter Name | Parameter Value |
|---|---|
| learning_rate | 0.077 |
| max_depth | 5 |
| n_estimators | 690 |
| min_data_in_leaf | 80 |
| min_gain_to_split | 0.006 |
| num_leaves | 2420 |
| feature_fraction | 0.2 |
| Parameter Name | Parameter Value |
|---|---|
| learning_rate | 0.014 |
| max_depth | 25 |
| n_estimators | 2000 |
| min_child_weight | 10 |
| Parameter Name | Parameter Value |
|---|---|
| optimizer | Adam |
| dropout | 0.3 |
| epoch | 100 |
| batch_size | 32 |
| Model | MSE | RMSE | |
|---|---|---|---|
| RF | 0.77 | 0.065 | 0.254 |
| LightGBM | 0.742 | 0.0740 | 0.270 |
| XGBoost | 0.743 | 0.0745 | 0.268 |
| CNN | 0.85 | 0.042 | 0.205 |
| equal weight method | 0.842 | 0.16 | 0.4 |
| stacking (OLS) | 0.927 | 0.02 | 0.145 |
| GERPM | 0.944 | 0.016 | 0.126 |
| Before Variable Selection | After Variable Selection |
|---|---|
| area, bedroom, living room, bathroom, subway, bus, shopping mall, hospital, park, office building, supermarket, floor_0, floor_1, floor_2, gas_0, gas_1, whole_rent_0, whole_rent_1, elevator_0, elevator_1, decoration_0, decoration_1, orientation_0, orientation_1 | area, bedroom, bathroom, subway, shopping mall, hospital, bus, elevator_0, decoration_0, decoration_1, floor_1 |
| Parameter Name | Parameter Value |
|---|---|
| n_estimators | 199 |
| max_depth | 9 |
| max_features | 5 |
| min_samples_split | 7 |
| min_samples_leaf | 0.64 |
| Parameter Name | Parameter Value |
|---|---|
| learning_rate | 0.176 |
| max_depth | 7 |
| n_estimators | 1780 |
| min_data_in_leaf | 20 |
| min_gain_to_split | 0.017 |
| num_leaves | 1000 |
| feature_fraction | 0.9 |
| Parameter Name | Parameter Value |
|---|---|
| learning_rate | 0.018 |
| max_depth | 9 |
| n_estimators | 1860 |
| min_child_weight | 19 |
| Parameter Name | Parameter Value |
|---|---|
| optimizer | Adam |
| dropout | 0.3 |
| epoch | 50 |
| batch_size | 64 |
| Model | MSE | RMSE | |
|---|---|---|---|
| RF | 0.633 | 0.121 | 0.346 |
| LightGBM | 0.631 | 0.122 | 0.348 |
| XGBoost | 0.635 | 0.121 | 0.346 |
| CNN | 0.71 | 0.1 | 0.317 |
| equal weight method | 0.75 | 0.226 | 0.475 |
| stacking (OLS) | 0.79 | 0.083 | 0.288 |
| GERPM | 0.84 | 0.056 | 0.236 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, G.; Tang, Y. GERPM: A Geographically Weighted Stacking Ensemble Learning-Based Urban Residential Rents Prediction Model. Mathematics 2023, 11, 3160. https://doi.org/10.3390/math11143160
Hu G, Tang Y. GERPM: A Geographically Weighted Stacking Ensemble Learning-Based Urban Residential Rents Prediction Model. Mathematics. 2023; 11(14):3160. https://doi.org/10.3390/math11143160
Chicago/Turabian StyleHu, Guang, and Yue Tang. 2023. "GERPM: A Geographically Weighted Stacking Ensemble Learning-Based Urban Residential Rents Prediction Model" Mathematics 11, no. 14: 3160. https://doi.org/10.3390/math11143160