3.1. Prompt with Audio Feature
Among multimodal emotion-recognition tasks, speech emotion recognition predicts emotions using natural-language speech text and audio information. Since audio includes voice information such as pitch, tone, and intonation, a model can be trained with more information than with text only. Therefore, using text and audio together to predict emotions is expected to produce a higher performance in emotion prediction. In addition, downstream task training with prompt learning has recently demonstrated high performance. However, prompt learning in a language model pre-trained on natural-language text cannot use multiple modalities because the fine-tuning process is similar to pre-training. Prompt learning in language models and additional deep-learning layers cannot be used because the input and output of the model originate from natural-language text. Therefore, prompt learning in a language model pre-trained on natural-language text is problematic because it is difficult to use modalities other than those trained in the downstream task.
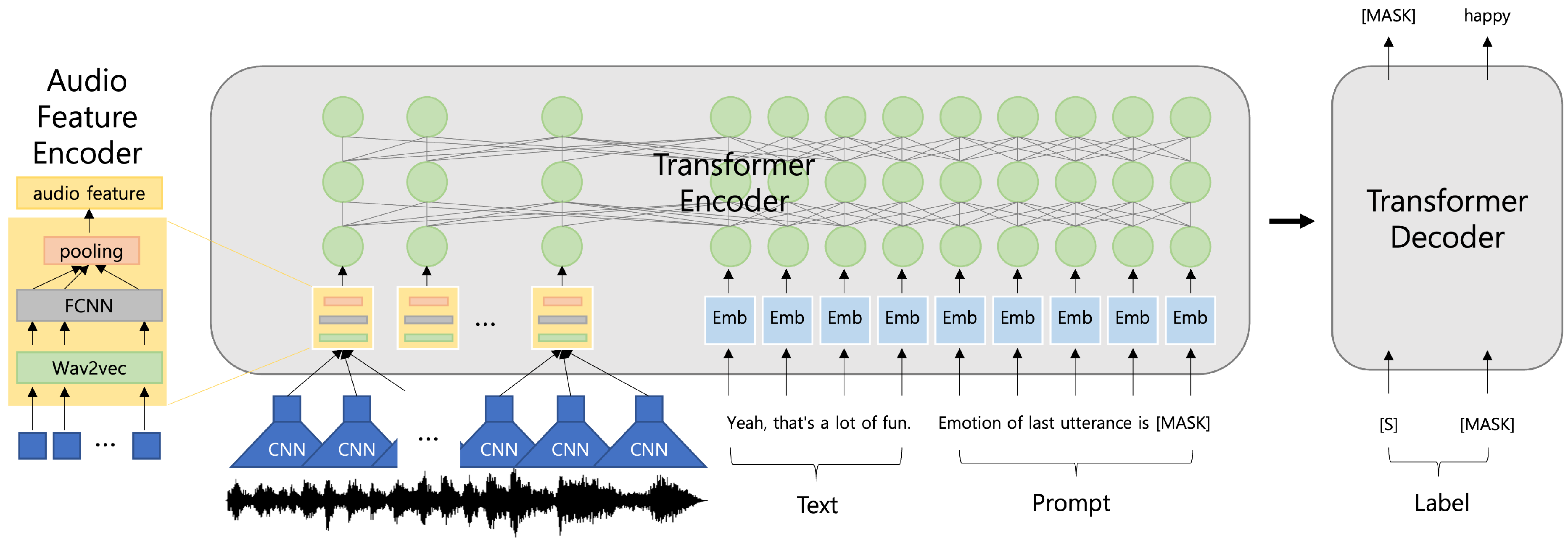
The proposed method jointly uses natural-language text and audio in the prompt-learning process of a text-based pre-trained model for speech emotion-recognition tasks. In other words, the proposed method performs self-attention using both natural-language text and audio in prompt learning using models pre-trained on text. The overall architecture of the proposed method is illustrated in
Figure 1. First, audio feature vectors are extracted using the
Wav2Vec 2.0 [
28] model, a feed-forward neural network (FFCN), and the pooling layer. The natural-language speech text and prompt template are configured with the given conversation data. Subsequently, audio feature vectors, natural-language speech text, and natural-language prompts are used as inputs to models based on the transformer encoder–decoder model [
29]. The natural-language text and audio used as inputs to the model can simultaneously train text and audio features by performing
STSelfAttention inside the transformer model.
The proposed method uses an audio feature encoder to extract audio features and inputs the features into a prompt-based language model. First, the audio features are extracted by inputting the audio data
A into
Wav2Vec 2.0 and FFNN. The pooling layer is then used to extract the audio features by compressing the number of existing
n audio embeddings to
l. The compression of the number of audio embeddings to
l is intended to change the form that can be entered into the transformer model through the audio feature encoder.
Equation (
1) extracts the audio embedding by inputting the given audio data
A into the
Wav2Vec 2.0 model. Subsequently, the input audio embeddings are extracted from
Wav2Vec 2.0 to FFNN, such as Equation (
2), to extract
n audio embedding vectors
.
is the
i-th audio embedding that passes the
Wav2Vec 2.0 model and FFNN.
n denotes the number of extracted audio embedding vectors.
and
are learnable parameters. Equation (
3) compresses the existing
n audio embedding vectors to
l.
is the
x-th audio embedding. The hyper-parameter
l is the number of audio-embedding vectors to be compressed.
S in Equation (
4) represents the
l audio feature passing through the
Wav2Vec 2.0 model, FFNN, and pooling layer. Pooling is performed using mean pooling.
Prompt learning is a methodology in which a model specifies the tasks to be performed and returns the result in text written in natural language. In this paper, speech emotion recognition was solved using prompt learning. In the proposed method, “Emotion of the last utterance is <MASK>” is used as a prompt for the speech emotion recognition task. The transformer decoder then generates an emotion token (neutral, joyful, etc.) corresponding to the prompt <MASK>. The natural-language speech text
and natural-language prompt
are used as inputs for prompt learning. Subsequently, the natural-language speech text and natural-language prompts are converted into the word embedding for each token for use as input to the transformer model with
Embedding. This process is expressed as follows:
in Equation (
5) represents the natural-language speech text data in the speech emotion-recognition task.
D is a word embedding for each token of
.
in Equation (
6) is a natural-language prompt such as “Emotion of current utterance is <MASK>”.
P denotes the word embedding for each token in the prompt. For example, “Yeah, that’s a lot of fun” is a speech text
and the number of speech text tokens is
a. “Emotion of last utterance is <MASK>” is a prompt
and the number of prompt tokens is
b. The speech text and prompt are tokenized by a tokenizer. Then, the word embedding
D = {
} of the utterance text and the word embedding
P = {
} of the prompt are extracted.
In this paper, prompt learning was performed using transformer-based encoder–decoder models, such as T5 [
3] and BART [
30]. In the self-attention step of the text-based pre-trained transformer encoder, the query, key, and value are all trained with unimodal data, such as natural-language text embedding. Therefore, it is difficult to use multimodal data as the input in prompt learning of text-based pre-trained transformer-based encoder–decoder models. The proposed method is
STSelfAttention, which uses natural-language text and audio together in the prompt learning of text-based pre-trained models. The proposed
STSelfAttention method performs self-attention using audio, natural-language text, and natural-language prompt embeddings concurrently to generate the query, key, and value. Subsequently, self-attention is performed with the query, key, and value containing each modality and data feature. In this paper, various modalities of information were used in prompt learning using text-based pre-trained models by replacing the existing transformer encoder’s self-attention with
STSelfAttention. This process is expressed as follows:
Equations (
7)–(
9) generate the query, key, and value in
STSelfAttention.
,
, and
are learnable parameters. Equation (
10) is an expression of
STSelfAttention. In this paper, self-attention was replaced with
STSelfAttention in the existing transformer encoder.
3.2. Prompt with Previous Context
In speech emotion-recognition tasks, the emotions of the previous utterance can affect the emotion of the current utterance. Therefore, in this study, we propose a method to deduce contextual information on emotions and previous utterances as important information for predicting the emotions expressed by a given utterance. To use the contextual information of emotions and previous utterances, the previous and current utterances are used concurrently as inputs in the transformer model. It was also configured to simultaneously predict the emotions for current and previous utterances while training the model. In addition, “Emotion of current utterance is <MASK>” and “Emotion of last utterance is <MASK>” are used as prompts to predict emotions of the previous and current utterances, respectively. In this paper, [] is the input to the transformer encoder to predict the x-th utterance. In this case, is the natural-language speech text for the x-th utterance, and is a natural-language prompt for predicting the emotion of the x-th utterance. Hyper-parameter k is the number of previous utterances to be used. Thereafter, the emotional words for each <MASK> are predicted in reverse order in the transformer decoder. As a result, [] is generated as the transformer decoder output. is an emotion token (e.g., neutral, joyful) for the x-th utterance.
In addition, we added emotions from previous utterances to the training loss function to induce training on emotion-change information over time. To differentiate between the learning weight and the contextual information of the previous and current utterance, predictive loss functions for each of the current and previous emotions were constructed. The predictive loss function of the current emotion is an LM loss, which predicts the emotion word of the current utterance by receiving the speech and prompt for the previous and current utterances and the audio of the current utterance. The predictive loss function of the previous emotions is an LM loss for generating [
] auto-regressively. In the process of constructing the training loss, we differentiate between the predictive loss functions of the current and previous emotions, causing the model to focus more on predicting the current emotion. This process is expressed as follows:
Equation (
11) is a loss function for the current emotion prediction, and Equation (
12) is a loss function for the previous emotion prediction.
and
are natural-language text, natural-language prompts, and audio data for the
x-th utterance, respectively.
is an emotion word for the
x-th utterance. The hyper-parameter
d is a constant that regulates the weight of the loss function relative to the previous emotions. Equation (
13) represents the final loss function for training. In the reference step, we generate only the emotion word
for the current utterance.








{kind=link}