Author Contributions
Conceptualization, S.L., S.H., R.A. and Z.C.; methodology: S.L., S.H., R.A., M.W.K. and Z.C.; software, S.B.Š.; validation: S.L.; formal analysis, Z.C.; investigation, S.L. and S.B.Š.; resources, S.L., S.H., R.A., M.W.K. and Z.C.; data curation, S.L., S.H., R.A. and M.W.K.; writing–original draft preparation: S.L. and S.B.Š.; writing–review and editing, S.H., R.A., M.W.K. and Z.C.; visualization: S.B.Š.; project administration, S.L. and Z.C.; funding acquisition: Z.C. and S.B.Š. All authors have read and agreed to the published version of the manuscript.
Figure 1.
An overview of the methodology.
Figure 1.
An overview of the methodology.
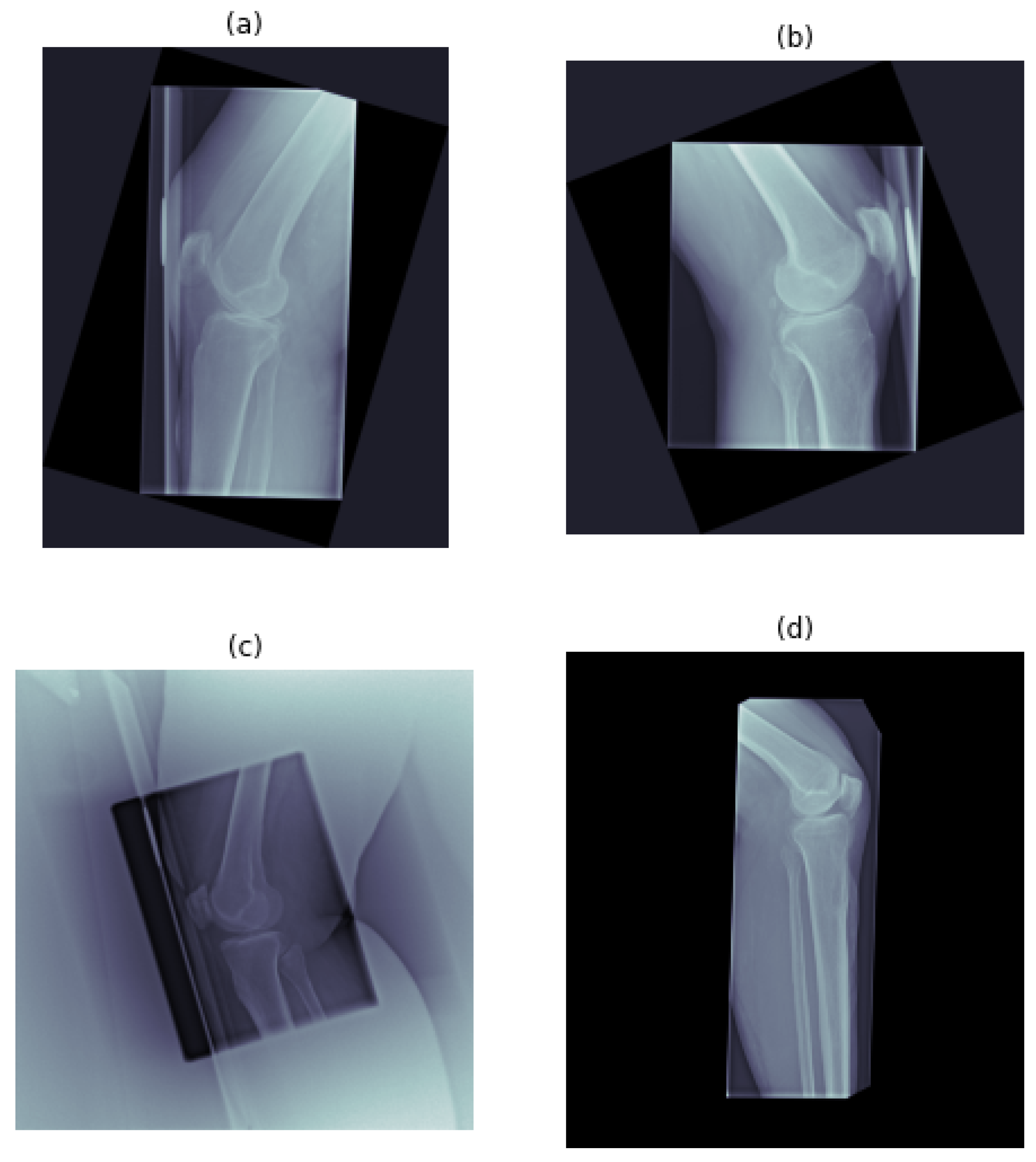
Figure 2.
Example of used XE, per each class: (a) right-oriented, acceptable; (b) left-oriented, acceptable; (c) right-oriented, unacceptable; and (d) left-oriented, unacceptable.
Figure 2.
Example of used XE, per each class: (a) right-oriented, acceptable; (b) left-oriented, acceptable; (c) right-oriented, unacceptable; and (d) left-oriented, unacceptable.
Figure 3.
A visualization of the 5-fold cross-validation procedure.
Figure 3.
A visualization of the 5-fold cross-validation procedure.
Figure 4.
LRK approach (LRK—Left+Right Knees).
Figure 4.
LRK approach (LRK—Left+Right Knees).
Figure 5.
OD-LK/RK hybrid approach schematic (OD—Orientation Discrimination, LK—Left Knees, RK—Right Knees).
Figure 5.
OD-LK/RK hybrid approach schematic (OD—Orientation Discrimination, LK—Left Knees, RK—Right Knees).
Figure 6.
OD-LFK/RFK hybrid approach schematic. (OD—Orientation Discrimination, LFK—Left Flipped Knees, RFK—Right Flipped Knees).
Figure 6.
OD-LFK/RFK hybrid approach schematic. (OD—Orientation Discrimination, LFK—Left Flipped Knees, RFK—Right Flipped Knees).
Figure 7.
The classification performance of the best model across epochs used in training.
Figure 7.
The classification performance of the best model across epochs used in training.
Figure 8.
Confusion matrix of the best-performing model.
Figure 8.
Confusion matrix of the best-performing model.
Table 1.
The main results of the related works, along with the number of images used in the study, as well as the main research topic/type of the images for which the quality assessment is performed (P—Precision, R—Recall, ACC—Accuracy, Spec.—Specificity, Sens.—Sensitivity).
Table 1.
The main results of the related works, along with the number of images used in the study, as well as the main research topic/type of the images for which the quality assessment is performed (P—Precision, R—Recall, ACC—Accuracy, Spec.—Specificity, Sens.—Sensitivity).
| Ref. | Quality Assessment Type | Images | Scores |
|---|
| [13] | Fetal sonograph | 14,700 | P = 0.97, Sens. = 0.95, ACC = 0.94, F1 = 0.96, Spec. = 0.94, AUC = 0.96 |
| [14] | Angiography imagery | 200 | ACC = 0.97 |
| [15] | Teledermatological photography | 39,509 | F1 = 0.73 ± 0.01 |
| [16] | Fundus photography | 216 | ACC = 0.98, Sens. = 0.99, Spec. = 0.95 |
| [17] | Ankle radiography | 950 | ACC = 0.94 |
| [18] | Lumbar MRI | 95 | R = 0.82, AUC = 0.77 |
| [19] | Retinopathy images | 4000 | AUC = 0.97, Sens. = 0.94, Spec. = 0.84 |
| [20] | Facial skin ultrasounds | 17,425 | ACC = 0.92 |
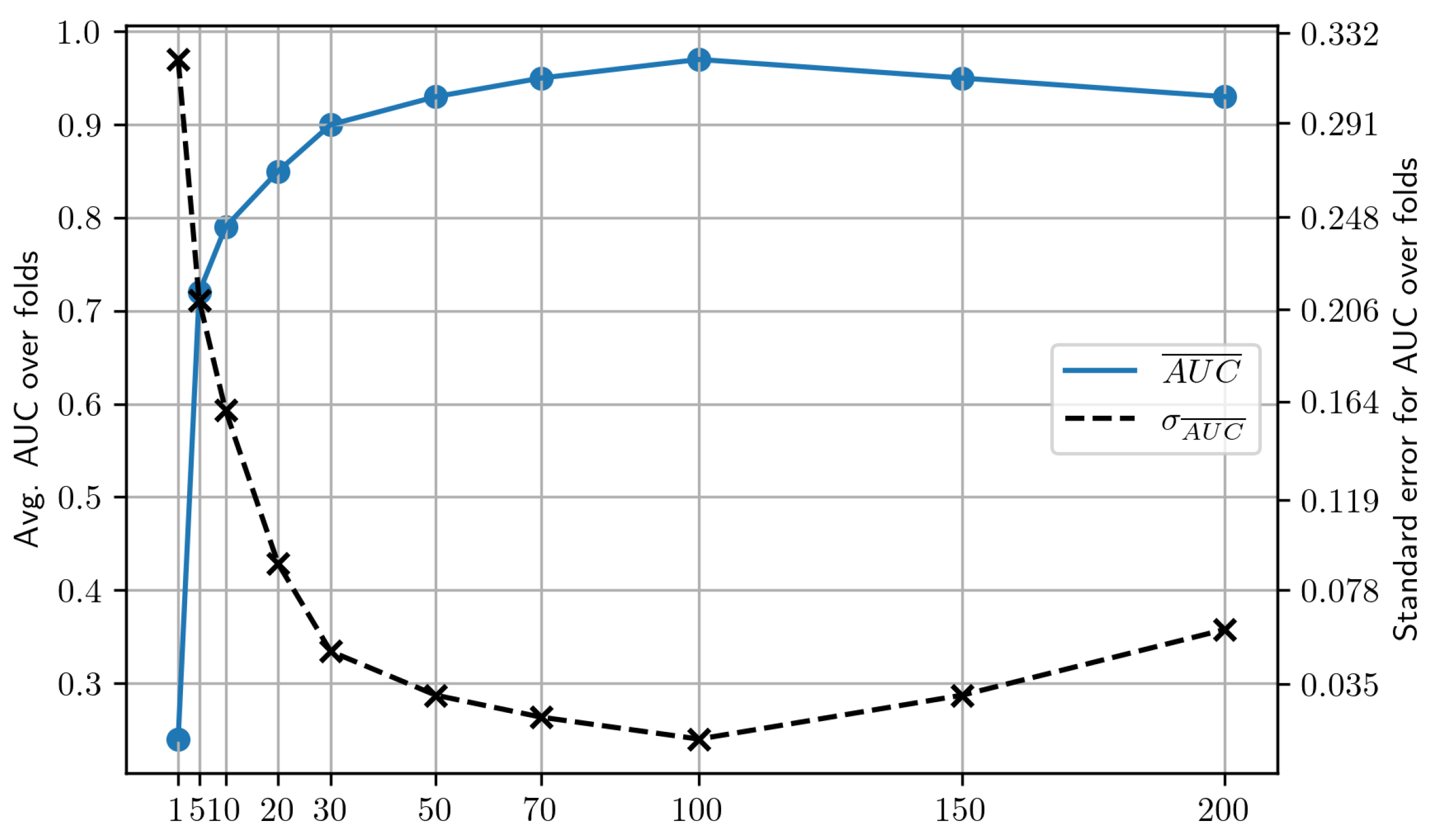
Table 2.
Possible hyperparameter values.
Table 2.
Possible hyperparameter values.
| Hyperparameter | Possible Values |
|---|
| Solver | ‘adam’, ‘rmsprop’, ‘adagrad’, ‘adadelta’, ‘adamax’, ‘nadam’ |
| Number of epochs | 1, 5, 10, 20, 30, 50, 70, 100, 150, 200 |
| Batch size | 1, 4, 8, 16, 32, 64 |
Table 3.
Results of the orientation discrimination model, for each used architecture, and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
Table 3.
Results of the orientation discrimination model, for each used architecture, and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
| | | | |
|---|
| | | | | | | |
| AlexNet | 0.94 | 0.03 | 0.94 | 0.03 | 0.95 | 0.02 |
| ResNet50 | 0.92 | 0.11 | 0.92 | 0.10 | 0.93 | 0.09 |
| ResNet101 | 0.95 | 0.08 | 0.96 | 0.08 | 0.95 | 0.07 |
| ResNet152 | 0.99 | 0.00 | 0.98 | 0.01 | 0.99 | 0.00 |
| Xception | 0.97 | 0.09 | 0.96 | 0.03 | 0.97 | 0.04 |
| | | | | | | |
| AlexNet | 0.94 | 0.04 | 0.94 | 0.04 | 0.95 | 0.03 |
| ResNet50 | 0.92 | 0.10 | 0.93 | 0.09 | 0.94 | 0.06 |
| ResNet101 | 0.95 | 0.06 | 0.96 | 0.05 | 0.95 | 0.05 |
| ResNet152 | 0.99 | 0.01 | 0.98 | 0.02 | 0.99 | 0.01 |
| Xception | 0.97 | 0.08 | 0.96 | 0.04 | 0.96 | 0.04 |
| | | | | | | |
| AlexNet | 0.94 | 0.04 | 0.94 | 0.04 | 0.95 | 0.04 |
| ResNet50 | 0.92 | 0.09 | 0.93 | 0.09 | 0.94 | 0.08 |
| ResNet101 | 0.95 | 0.07 | 0.96 | 0.04 | 0.95 | 0.05 |
| ResNet152 | 0.99 | 0.01 | 0.98 | 0.01 | 0.99 | 0.00 |
| Xception | 0.97 | 0.08 | 0.95 | 0.03 | 0.96 | 0.04 |
| | | | | | | |
| AlexNet | 0.96 | 0.03 | 0.97 | 0.03 | 0.96 | 0.03 |
| ResNet50 | 0.94 | 0.09 | 0.93 | 0.09 | 0.92 | 0.08 |
| ResNet101 | 0.98 | 0.07 | 0.98 | 0.03 | 0.96 | 0.04 |
| ResNet152 | 0.99 | 0.01 | 0.99 | 0.01 | 1,00 | 0.00 |
| Xception | 0.99 | 0.08 | 0.99 | 0.02 | 0.99 | 0.03 |
| | | | | | | |
| AlexNet | 0.93 | 0.05 | 0.92 | 0.06 | 0.94 | 0.05 |
| ResNet50 | 0.91 | 0.10 | 0.93 | 0.09 | 0.96 | 0.08 |
| ResNet101 | 0.93 | 0.07 | 0.94 | 0.06 | 0.95 | 0.07 |
| ResNet152 | 0.99 | 0.01 | 0.97 | 0.02 | 0.99 | 0.00 |
| Xception | 0.96 | 0.08 | 0.92 | 0.04 | 0.94 | 0.04 |
| | | | | | | |
| AlexNet | 0.96 | 0.03 | 0.97 | 0.03 | 0.96 | 0.03 |
| ResNet50 | 0.94 | 0.09 | 0.93 | 0.09 | 0.92 | 0.08 |
| ResNet101 | 0.98 | 0.07 | 0.98 | 0.03 | 0.96 | 0.04 |
| ResNet152 | 0.99 | 0.01 | 0.99 | 0.01 | 1,00 | 0.00 |
| Xception | 0.99 | 0.08 | 0.99 | 0.02 | 0.99 | 0.03 |
| | | | | | | |
| AlexNet | 0.93 | 0.05 | 0.92 | 0.06 | 0.94 | 0.05 |
| ResNet50 | 0.91 | 0.10 | 0.93 | 0.09 | 0.96 | 0.08 |
| ResNet101 | 0.93 | 0.07 | 0.94 | 0.06 | 0.95 | 0.07 |
| ResNet152 | 0.99 | 0.01 | 0.97 | 0.02 | 0.99 | 0.00 |
| Xception | 0.96 | 0.08 | 0.92 | 0.04 | 0.94 | 0.04 |
Table 4.
Hyperparameters for the highest-performing OD network (ResNet152), used to achieve the scores in
Table 3.
Table 4.
Hyperparameters for the highest-performing OD network (ResNet152), used to achieve the scores in
Table 3.
| Image Size | Solver | Batch Size | Epochs |
|---|
| ‘adam’ | 64 | 70 |
| ‘adamax’ | 32 | 70 |
| ‘adam’ | 32 | 100 |
Table 5.
Results of models trained with the LRK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
Table 5.
Results of models trained with the LRK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
| | | | |
|---|
| | | | | | | |
| AlexNet | 0.76 | 0.16 | 0.78 | 0.12 | 0.81 | 0.11 |
| ResNet50 | 0.83 | 0.05 | 0.84 | 0.04 | 0.84 | 0.04 |
| ResNet101 | 0.84 | 0.04 | 0.84 | 0.04 | 0.85 | 0.03 |
| ResNet152 | 0.91 | 0.03 | 0.92 | 0.04 | 0.94 | 0.02 |
| Xception | 0.85 | 0.04 | 0.86 | 0.03 | 0.89 | 0.04 |
| | | | | | | |
| AlexNet | 0.76 | 0.21 | 0.81 | 0.17 | 0.82 | 0.12 |
| ResNet50 | 0.83 | 0.16 | 0.84 | 0.14 | 0.84 | 0.12 |
| ResNet101 | 0.84 | 0.16 | 0.84 | 0.15 | 0.85 | 0.12 |
| ResNet152 | 0.91 | 0.12 | 0.92 | 0.11 | 0.94 | 0.09 |
| Xception | 0.85 | 0.16 | 0.86 | 0.13 | 0.90 | 0.11 |
| | | | | | | |
| AlexNet | 0.76 | 0.20 | 0.79 | 0.19 | 0.80 | 0.13 |
| ResNet50 | 0.83 | 0.16 | 0.85 | 0.13 | 0.84 | 0.14 |
| ResNet101 | 0.84 | 0.16 | 0.84 | 0.14 | 0.92 | 0.10 |
| ResNet152 | 0.90 | 0.15 | 0.92 | 0.11 | 0.94 | 0.06 |
| Xception | 0.85 | 0.14 | 0.86 | 0.13 | 0.89 | 0.11 |
| | | | | | | |
| AlexNet | 0.81 | 0.17 | 0.85 | 0.15 | 0.81 | 0.13 |
| ResNet50 | 0.80 | 0.17 | 0.90 | 0.11 | 0.86 | 0.13 |
| ResNet101 | 0.85 | 0.16 | 0.87 | 0.13 | 0.90 | 0.10 |
| ResNet152 | 0.95 | 0.15 | 0.95 | 0.11 | 0.95 | 0.06 |
| Xception | 0.88 | 0.13 | 0.90 | 0.11 | 0.90 | 0.10 |
| | | | | | | |
| AlexNet | 0.72 | 0.24 | 0.74 | 0.26 | 0.80 | 0.12 |
| ResNet50 | 0.86 | 0.15 | 0.80 | 0.15 | 0.82 | 0.15 |
| ResNet101 | 0.83 | 0.17 | 0.82 | 0.16 | 0.95 | 0.09 |
| ResNet152 | 0.86 | 0.15 | 0.90 | 0.11 | 0.94 | 0.07 |
| Xception | 0.82 | 0.16 | 0.82 | 0.15 | 0.88 | 0.12 |
| | | | | | | |
| AlexNet | 0.81 | 0.17 | 0.85 | 0.15 | 0.81 | 0.13 |
| ResNet50 | 0.80 | 0.17 | 0.90 | 0.11 | 0.86 | 0.13 |
| ResNet101 | 0.85 | 0.16 | 0.87 | 0.13 | 0.90 | 0.10 |
| ResNet152 | 0.95 | 0.15 | 0.95 | 0.11 | 0.95 | 0.06 |
| Xception | 0.88 | 0.13 | 0.90 | 0.11 | 0.90 | 0.10 |
| | | | | | | |
| AlexNet | 0.72 | 0.24 | 0.74 | 0.26 | 0.80 | 0.12 |
| ResNet50 | 0.86 | 0.15 | 0.80 | 0.15 | 0.82 | 0.15 |
| ResNet101 | 0.83 | 0.17 | 0.82 | 0.16 | 0.95 | 0.09 |
| ResNet152 | 0.86 | 0.15 | 0.90 | 0.11 | 0.94 | 0.07 |
| Xception | 0.82 | 0.16 | 0.82 | 0.15 | 0.88 | 0.12 |
Table 6.
Results of models trained with OD-LK/RK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
Table 6.
Results of models trained with OD-LK/RK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
| | | | |
|---|
| | | | | | | |
| AlexNet | 0.81 | 0.10 | 0.84 | 0.08 | 0.86 | 0.07 |
| ResNet50 | 0.90 | 0.03 | 0.91 | 0.03 | 0.92 | 0.04 |
| ResNet101 | 0.91 | 0.04 | 0.92 | 0.03 | 0.94 | 0.02 |
| ResNet152 | 0.92 | 0.02 | 0.92 | 0.01 | 0.94 | 0.01 |
| Xception | 0.92 | 0.05 | 0.93 | 0.03 | 0.93 | 0.02 |
| | | | | | | |
| AlexNet | 0.81 | 0.17 | 0.84 | 0.10 | 0.86 | 0.12 |
| ResNet50 | 0.90 | 0.10 | 0.91 | 0.09 | 0.92 | 0.07 |
| ResNet101 | 0.92 | 0.08 | 0.92 | 0.08 | 0.94 | 0.06 |
| ResNet152 | 0.92 | 0.09 | 0.92 | 0.08 | 0.94 | 0.06 |
| Xception | 0.92 | 0.09 | 0.93 | 0.08 | 0.93 | 0.07 |
| | | | | | | |
| AlexNet | 0.81 | 0.12 | 0.84 | 0.09 | 0.86 | 0.09 |
| ResNet50 | 0.90 | 0.10 | 0.90 | 0.09 | 0.92 | 0.07 |
| ResNet101 | 0.92 | 0.09 | 0.92 | 0.08 | 0.94 | 0.06 |
| ResNet152 | 0.92 | 0.09 | 0.92 | 0.08 | 0.94 | 0.06 |
| Xception | 0.92 | 0.09 | 0.93 | 0.08 | 0.93 | 0.07 |
| | | | | | | |
| AlexNet | 0.82 | 0.12 | 0.86 | 0.09 | 0.88 | 0.10 |
| ResNet50 | 0.91 | 0.09 | 0.88 | 0.10 | 0.95 | 0.06 |
| ResNet101 | 0.93 | 0.10 | 0.92 | 0.08 | 0.96 | 0.04 |
| ResNet152 | 0.94 | 0.08 | 0.93 | 0.07 | 0.95 | 0.05 |
| Xception | 0.93 | 0.09 | 0.95 | 0.08 | 0.93 | 0.07 |
| | | | | | | |
| AlexNet | 0.80 | 0.12 | 0.82 | 0.08 | 0.84 | 0.09 |
| ResNet50 | 0.90 | 0.10 | 0.92 | 0.08 | 0.90 | 0.09 |
| ResNet101 | 0.92 | 0.09 | 0.92 | 0.08 | 0.92 | 0.08 |
| ResNet152 | 0.91 | 0.10 | 0.91 | 0.08 | 0.93 | 0.07 |
| Xception | 0.92 | 0.09 | 0.92 | 0.08 | 0.93 | 0.07 |
| | | | | | | |
| AlexNet | 0.82 | 0.12 | 0.86 | 0.09 | 0.88 | 0.10 |
| ResNet50 | 0.91 | 0.09 | 0.88 | 0.10 | 0.95 | 0.06 |
| ResNet101 | 0.93 | 0.10 | 0.92 | 0.08 | 0.96 | 0.04 |
| ResNet152 | 0.94 | 0.08 | 0.93 | 0.07 | 0.95 | 0.05 |
| Xception | 0.93 | 0.09 | 0.95 | 0.08 | 0.93 | 0.07 |
| | | | | | | |
| AlexNet | 0.80 | 0.12 | 0.82 | 0.08 | 0.84 | 0.09 |
| ResNet50 | 0.90 | 0.10 | 0.92 | 0.08 | 0.90 | 0.09 |
| ResNet101 | 0.92 | 0.09 | 0.92 | 0.08 | 0.92 | 0.08 |
| ResNet152 | 0.91 | 0.10 | 0.91 | 0.08 | 0.93 | 0.07 |
| Xception | 0.92 | 0.09 | 0.92 | 0.08 | 0.93 | 0.07 |
Table 7.
Results of model training for OD-LFK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
Table 7.
Results of model training for OD-LFK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
| | | | |
|---|
| | | | | | | |
| AlexNet | 0.82 | 0.06 | 0.83 | 0.05 | 0.83 | 0.06 |
| ResNet50 | 0.91 | 0.02 | 0.92 | 0.01 | 0.91 | 0.01 |
| ResNet101 | 0.92 | 0.03 | 0.92 | 0.01 | 0.93 | 0.01 |
| ResNet152 | 0.94 | 0.02 | 0.95 | 0.01 | 0.95 | 0.01 |
| Xception | 0.96 | 0.02 | 0.95 | 0.01 | 0.96 | 0.01 |
| | | | | | | |
| AlexNet | 0.83 | 0.11 | 0.83 | 0.12 | 0.83 | 0.09 |
| ResNet50 | 0.91 | 0.07 | 0.92 | 0.08 | 0.91 | 0.08 |
| ResNet101 | 0.92 | 0.08 | 0.92 | 0.06 | 0.95 | 0.06 |
| ResNet152 | 0.95 | 0.05 | 0.95 | 0.05 | 0.96 | 0.06 |
| Xception | 0.96 | 0.04 | 0.95 | 0.05 | 0.96 | 0.05 |
| | | | | | | |
| AlexNet | 0.82 | 0.09 | 0.82 | 0.10 | 0.83 | 0.10 |
| ResNet50 | 0.92 | 0.08 | 0.92 | 0.07 | 0.91 | 0.08 |
| ResNet101 | 0.92 | 0.08 | 0.92 | 0.06 | 0.93 | 0.07 |
| ResNet152 | 0.94 | 0.06 | 0.95 | 0.05 | 0.95 | 0.06 |
| Xception | 0.96 | 0.05 | 0.95 | 0.05 | 0.96 | 0.06 |
| | | | | | | |
| AlexNet | 0.80 | 0.07 | 0.81 | 0.09 | 0.80 | 0.14 |
| ResNet50 | 0.93 | 0.07 | 0.93 | 0.06 | 0.92 | 0.08 |
| ResNet101 | 0.92 | 0.07 | 0.92 | 0.07 | 0.93 | 0.06 |
| ResNet152 | 0.96 | 0.05 | 0.96 | 0.05 | 0.97 | 0.05 |
| Xception | 0.97 | 0.04 | 0.96 | 0.05 | 0.97 | 0.05 |
| | | | | | | |
| AlexNet | 0.85 | 0.12 | 0.84 | 0.12 | 0.87 | 0.07 |
| ResNet50 | 0.91 | 0.09 | 0.92 | 0.08 | 0.90 | 0.09 |
| ResNet101 | 0.92 | 0.08 | 0.92 | 0.06 | 0.93 | 0.07 |
| ResNet152 | 0.92 | 0.08 | 0.94 | 0.06 | 0.94 | 0.06 |
| Xception | 0.95 | 0.06 | 0.95 | 0.05 | 0.95 | 0.06 |
| | | | | | | |
| AlexNet | 0.80 | 0.07 | 0.81 | 0.09 | 0.80 | 0.14 |
| ResNet50 | 0.93 | 0.07 | 0.93 | 0.06 | 0.92 | 0.08 |
| ResNet101 | 0.92 | 0.07 | 0.92 | 0.07 | 0.93 | 0.06 |
| ResNet152 | 0.96 | 0.05 | 0.96 | 0.05 | 0.97 | 0.05 |
| Xception | 0.97 | 0.04 | 0.96 | 0.05 | 0.97 | 0.05 |
| | | | | | | |
| AlexNet | 0.85 | 0.12 | 0.84 | 0.12 | 0.87 | 0.07 |
| ResNet50 | 0.91 | 0.09 | 0.92 | 0.08 | 0.90 | 0.09 |
| ResNet101 | 0.92 | 0.08 | 0.92 | 0.06 | 0.93 | 0.07 |
| ResNet152 | 0.92 | 0.08 | 0.94 | 0.06 | 0.94 | 0.06 |
| Xception | 0.95 | 0.06 | 0.95 | 0.05 | 0.95 | 0.06 |
Table 8.
Results of model training for OD-RFK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
Table 8.
Results of model training for OD-RFK approach, for each used architecture and image size, expressed as average metrics (AUC, Accuracy, F1, Recall, Precision, Sensitivity, Specificity) and standard errors.
| | | | |
|---|
| | | | | | | |
| AlexNet | 0.83 | 0.06 | 0.83 | 0.05 | 0.82 | 0.06 |
| ResNet50 | 0.92 | 0.01 | 0.92 | 0.02 | 0.93 | 0.01 |
| ResNet101 | 0.92 | 0.02 | 0.93 | 0.01 | 0.92 | 0.01 |
| ResNet152 | 0.84 | 0.01 | 0.94 | 0.01 | 0.95 | 0.01 |
| Xception | 0.97 | 0.01 | 0.97 | 0.02 | 0.97 | 0.01 |
| | | | | | | |
| AlexNet | 0.85 | 0.12 | 0.83 | 0.09 | 0.82 | 0.10 |
| ResNet50 | 0.93 | 0.07 | 0.92 | 0.06 | 0.93 | 0.06 |
| ResNet101 | 0.92 | 0.08 | 0.93 | 0.05 | 0.92 | 0.07 |
| ResNet152 | 0.84 | 0.13 | 0.94 | 0.05 | 0.95 | 0.06 |
| Xception | 0.97 | 0.05 | 0.97 | 0.04 | 0.97 | 0.03 |
| | | | | | | |
| AlexNet | 0.83 | 0.11 | 0.83 | 0.14 | 0.82 | 0.09 |
| ResNet50 | 0.92 | 0.07 | 0.92 | 0.06 | 0.93 | 0.06 |
| ResNet101 | 0.92 | 0.07 | 0.94 | 0.05 | 0.92 | 0.07 |
| ResNet152 | 0.84 | 0.13 | 0.95 | 0.05 | 0.95 | 0.06 |
| Xception | 0.97 | 0.05 | 0.97 | 0.05 | 0.97 | 0.03 |
| | | | | | | |
| AlexNet | 0.81 | 0.15 | 0.80 | 0.14 | 0.81 | 0.13 |
| ResNet50 | 0.93 | 0.06 | 0.93 | 0.06 | 0.95 | 0.06 |
| ResNet101 | 0.92 | 0.07 | 0.95 | 0.05 | 0.94 | 0.06 |
| ResNet152 | 0.84 | 0.12 | 0.95 | 0.05 | 0.94 | 0.06 |
| Xception | 0.99 | 0.04 | 0.98 | 0.05 | 0.99 | 0.02 |
| | | | | | | |
| AlexNet | 0.86 | 0.08 | 0.86 | 0.13 | 0.83 | 0.07 |
| ResNet50 | 0.91 | 0.07 | 0.92 | 0.05 | 0.92 | 0.06 |
| ResNet101 | 0.92 | 0.08 | 0.94 | 0.06 | 0.91 | 0.08 |
| ResNet152 | 0.84 | 0.14 | 0.95 | 0.05 | 0.96 | 0.05 |
| Xception | 0.95 | 0.06 | 0.96 | 0.05 | 0.95 | 0.05 |
| | | | | | | |
| AlexNet | 0.81 | 0.15 | 0.80 | 0.14 | 0.81 | 0.13 |
| ResNet50 | 0.93 | 0.06 | 0.93 | 0.06 | 0.95 | 0.06 |
| ResNet101 | 0.92 | 0.07 | 0.95 | 0.05 | 0.94 | 0.06 |
| ResNet152 | 0.84 | 0.12 | 0.95 | 0.05 | 0.94 | 0.06 |
| Xception | 0.99 | 0.04 | 0.98 | 0.05 | 0.99 | 0.02 |
| | | | | | | |
| AlexNet | 0.86 | 0.08 | 0.86 | 0.13 | 0.83 | 0.07 |
| ResNet50 | 0.91 | 0.07 | 0.92 | 0.05 | 0.92 | 0.06 |
| ResNet101 | 0.92 | 0.08 | 0.94 | 0.06 | 0.91 | 0.08 |
| ResNet152 | 0.84 | 0.14 | 0.95 | 0.05 | 0.96 | 0.05 |
| Xception | 0.95 | 0.06 | 0.96 | 0.05 | 0.95 | 0.05 |



 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}