This section provides the models for workflow and cloud resource, then formulates the multi-objective cloud workflow scheduling problem.
2.1. Workflow Model
Generally, the workflow structure is modeled as a Directed Acyclic Graph (DAG), in which the nodes and directed edges denote the tasks and the data dependencies among the tasks, respectively. In detail, the DAG model of a workflow is formulated as , where is the set of nodes representing the workflow tasks, and is the set of edges representing data dependencies among the tasks. The existence of edge means that the start of task requires the output result of task as input. Then, task is regarded as an immediate predecessor of task , and is regarded as an immediate successor of . For a task , the set of all its immediate predecessors is represented as , while the set of all its immediate successors is represented as .
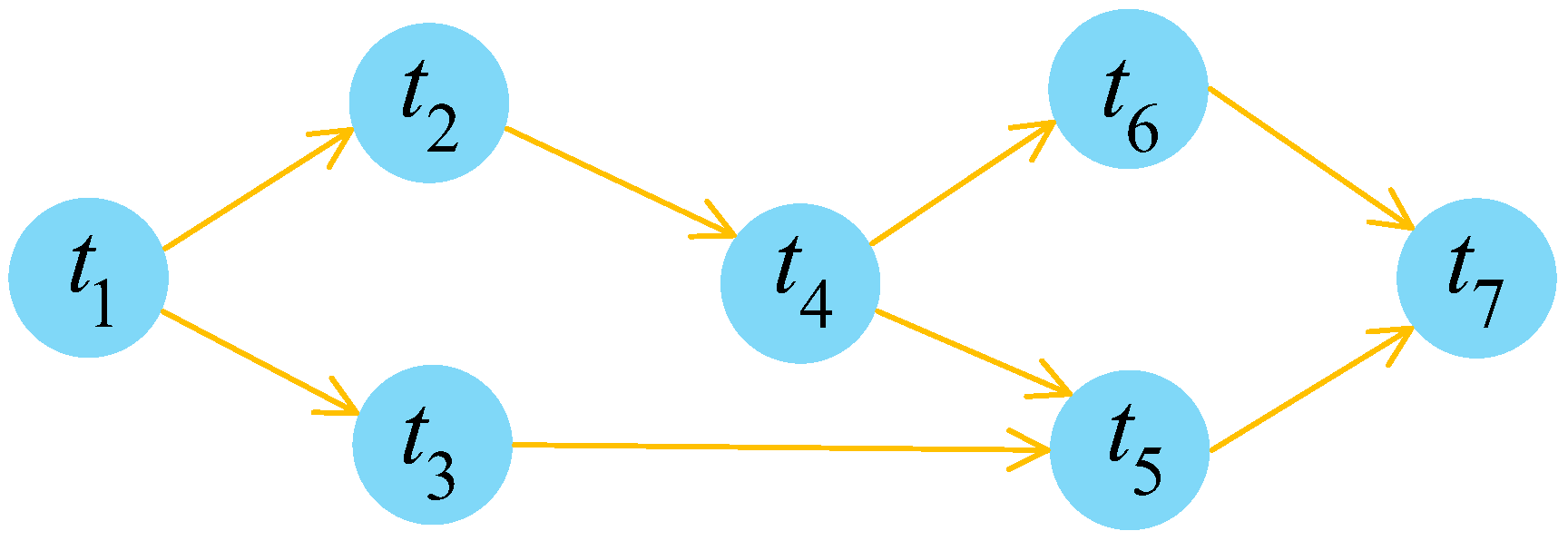
Figure 1 provides an intuitive example of a DAG model for a workflow having seven tasks, i.e.,
. The edge
represents the data dependency between
and
, meaning that the start of task
needs to wait for the output result of task
. As can be seen in
Figure 1, for task
, the set of its immediate predecessors is
, and the set of
’s immediate successors is
.
2.2. Cloud Resource Model
Infrastructure as a Service (IaaS) is one popular cloud paradigm, where cloud providers provide unlimited cloud resources with various types [
31]. Different resource types differ in price and performance configurations, such as CPU frequency, network bandwidth, memory, and storage size. Given that the cloud platform provides
m types of resources, we describe all these resource types as
, where
corresponds to the
-th resource type. For a resource type
, its price and configurations are respectively represented as
and
. Then, a resource instance of type
in a cloud platform can be modeled as
, where
k denotes the index of this resource instance.
We refer to well-known cloud providers, e.g., Amazon EC2 and Alibaba Cloud ECS, and follow their resource charging mode of pay-as-you-use. This way, each user can rent cloud instances on-demand and pay for the used instances based on the real usage time. Generally, the cloud providers charge for resource instances according to the number of charging periods and round up the partial time of a period to one more period. If the period length is one hour, the number of charging periods for 60.5 min is two.
The network structure among resource instances in clouds is often heterogeneous and intricate. Since this paper focuses on scheduling workflow tasks, we simplify the underlying network structure and assume that all resource instances are interconnected. The symbol
is employed to denote the communication bandwidth between resource instance
and
. When two data-dependent tasks are executed on the same resource instance, they will use the same storage space, and there is no data transmission through the network. Then, the data transmission overhead between these two tasks can be negligible [
9,
32].
2.3. Multi-Objective Scheduling Cloud Workflows
Since cloud resource instances are elastic, we construct a resource pool based on the workflow’s most used resource instances. We use
p to represent the maximum parallelism of the workflow, and then the resource pool contains
p instances of each type. That is to say, the resource pool can be detailed as
This paper defines the decision vector as the mappings from workflow tasks to resource instances, where the i-th decision variable corresponds to the i-th workflow task and its value indicates the index of this task mapping resource instance. Then, the value of each decision variable is one of the elements of the set .
For a decision vector, we assume that the workflow task is mapped to resource instance . This task’s start time is the maximum time to collect the output results from all its predecessors and the available mapped resource instance.
On resource instance
, the task set ahead of task
is described as:
where
denotes the order number of task
on the resource instance
.
Then, the start time
of workflow task
on the mapped resource instance
is calculated as follows:
where
denotes the finish time of task
on resource instance
,
denotes the finish time of task
on its mapped resource instance, and
denotes the data transmission time from
to
.
Before scheduling, the execution time
of workflow task
on resource instance
can be estimated by the computation amount of the task and the performance configuration of the resource instance. Then, the relationships among
,
, and
can be described as follows:
The data dependencies among workflow tasks mean that a task
cannot start execution before receiving the output data from all its predecessors, which creates the following constraint:
where
is an indicator function. If
and
are mapped to different resources,
is 1; otherwise, it is 0. The indicator function is employed to reflect the fact that once two dependent tasks are executed by the same resource, the data transmission overhead between these two tasks is negligible and assumed to be zero.
denotes the bandwidth.
Given a decision vector, the set of all tasks mapped to resource instance
can be described as:
With the mapped task set
, the startup time
and shutdown time
of resource instance
can be calculated as follows:
With the formulation above, we formulate the first optimization objective, i.e., minimizing the economic cost, as follows:
where
C denotes the length of charging period for resource instances.
The second optimization objective is to minimize the makespan of the workflow, which refers to the maximum finish time of all the workflow tasks. We formulate this optimization objective as follows:
To summarize, the model for multi-objective scheduling cloud workflows can be formulated as follows:
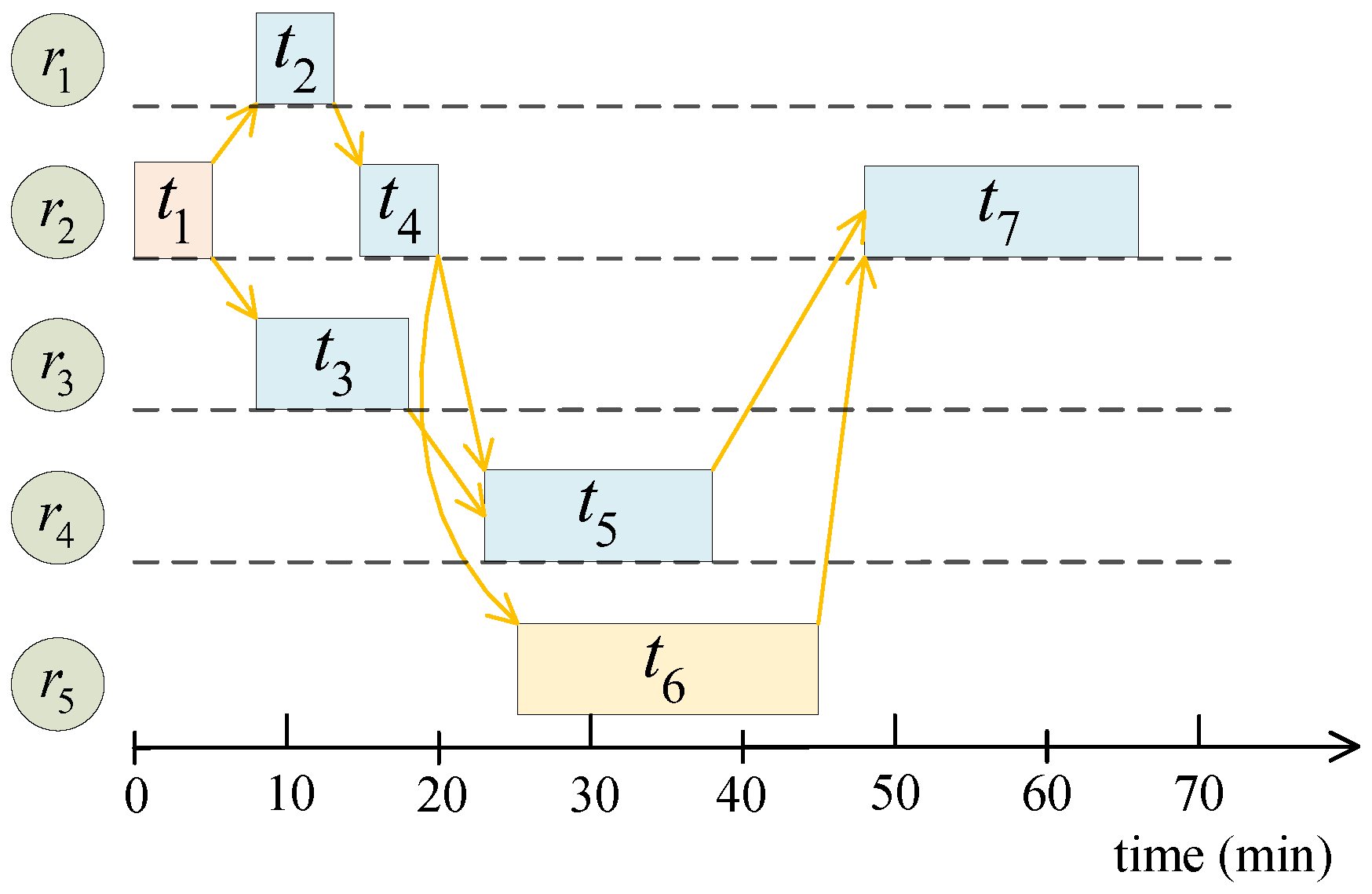
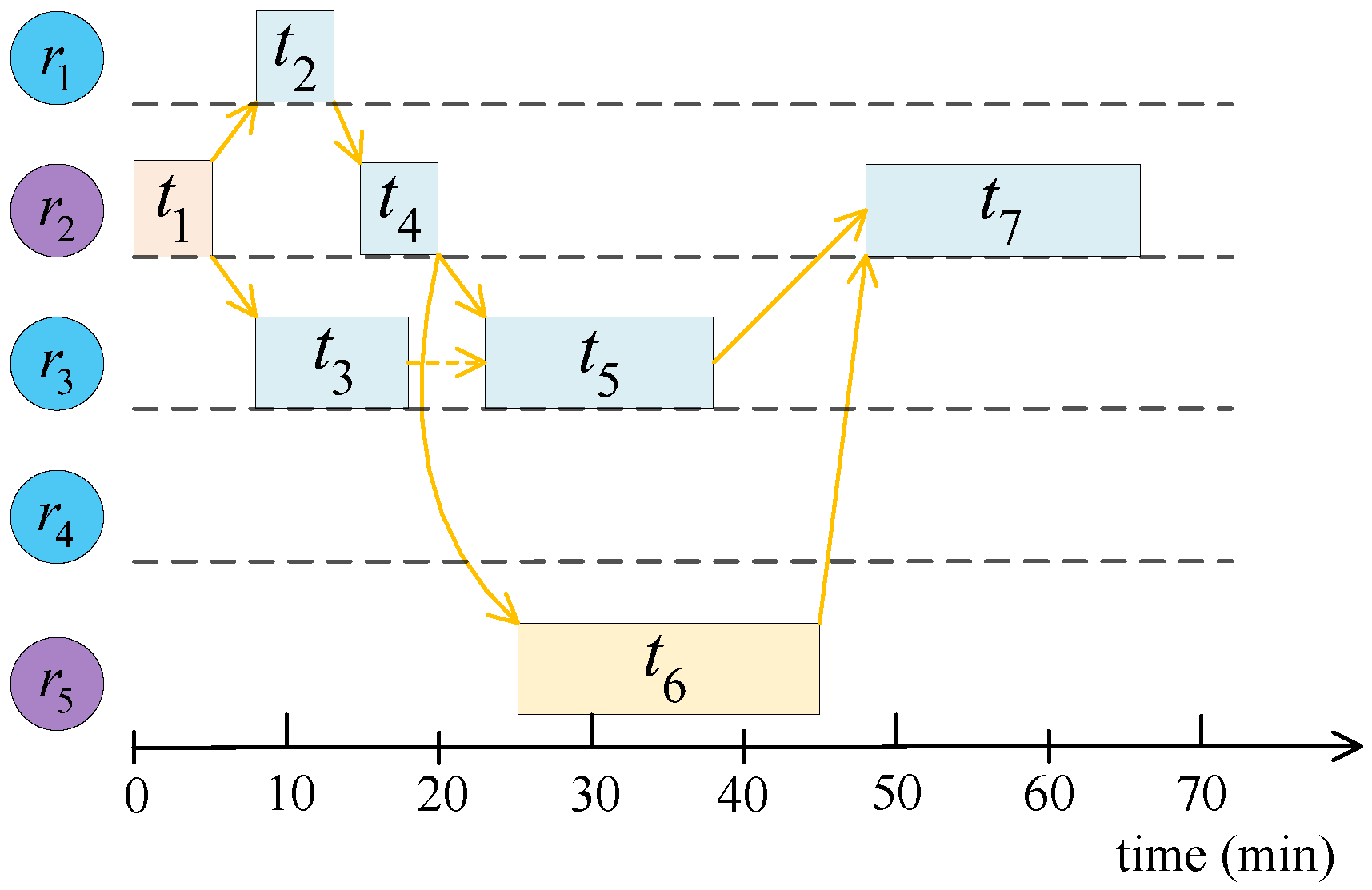
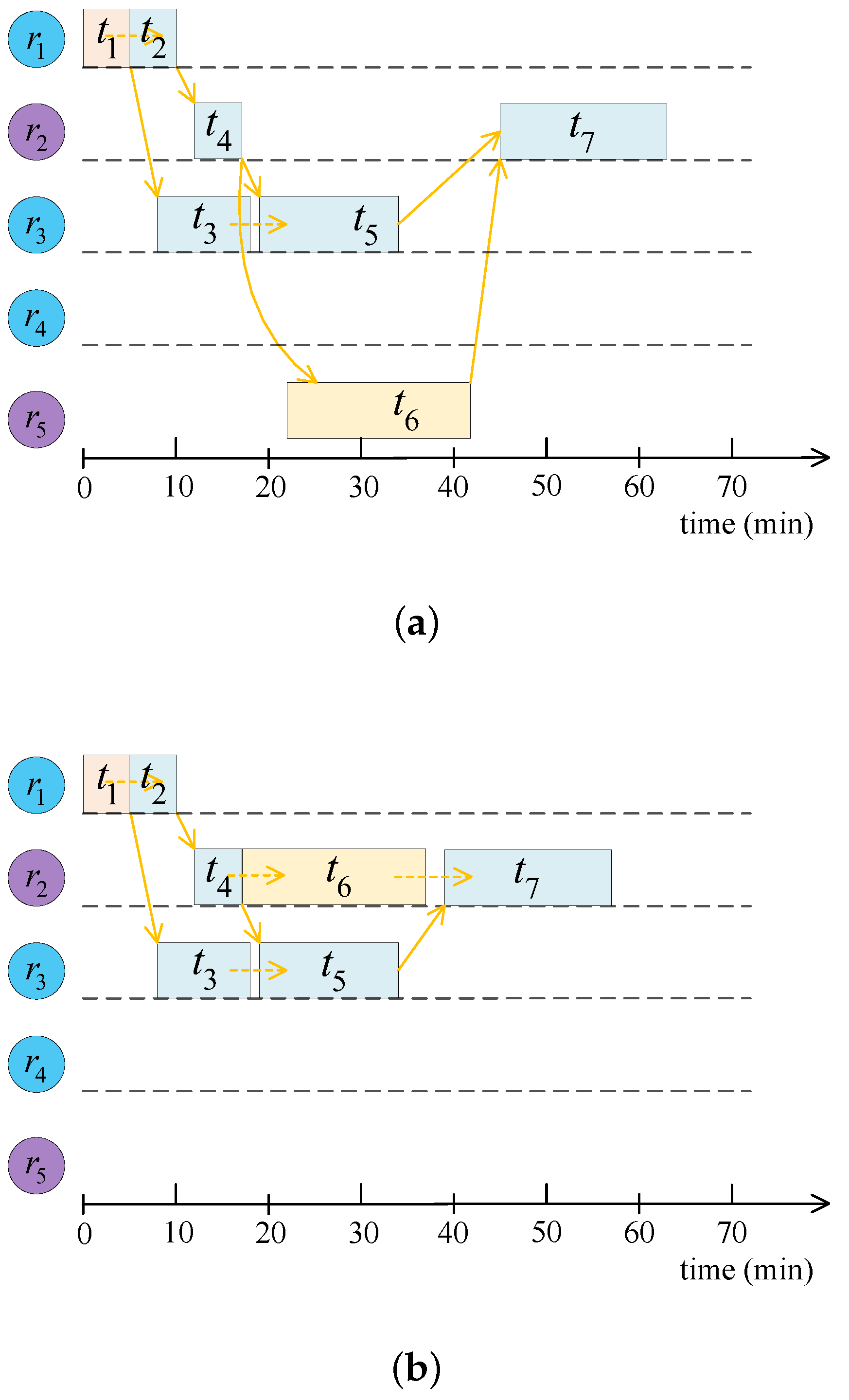
To improve readability, we take the workflow in
Figure 1 as an example to visually illustrate the decision variable and the calculation of the corresponding objective vector. Assuming that the resource set is
, one decision variable of the workflow with seven tasks in
Figure 1 is
. The configurations of the five cloud resources and the execution time from tasks to resources are summarized in
Table 1. The data transmission time among workflow tasks is given in
Table 2. Based on the above assumptions,
Figure 2 illustrates the Gantt chart of the schedule. Then, we can calculate each workflow task’s start and finish time, which is given in
Table 3.
According to the charging mode of cloud resources, i.e., the partial time of a charging period is rounded up to one, the charging periods of the five resources are 1, 2, 1, 1, and 1, respectively. Then, the execution cost of the workflow is dollars, which corresponds to the first optimization objective. Besides, the makespan of a workflow refers to the maximum finish time of all the tasks. We can obtain this optimization objective as min.
Pareto dominance is commonly used to compare solutions with multiple conflicting objectives [
33,
34].
Pareto-Dominance: Suppose and are two feasible solutions for the cloud workflow scheduling. is regarded to Pareto dominate (expressed as ) if and only if the two objectives of is no larger than that of (i.e., ) and is less than on at least one objective (i.e., ).
Pareto-optimal Solution: A solution is generally defined as Pareto-optimal when there exists no feasible solution dominating it.
Pareto-optimal Set/Front: All the Pareto-optimal solutions are defined as Pareto-Set (PS) in the decision space and Pareto-Front (PF) in the objective space.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}