1. Introduction
The rapidly changing world and the evolving financial industry have led to ease in an individual’s life, especially in the time of COVID19 during which many have shifted to online platforms. Consequently, financial crimes such as credit card fraud have significantly risen. Since 2011, there has been a rapid growth in global losses due to payment fraud as it jumped from USD 9.84 billion in 2011 to USD 32.39 billion in 2020 and it will inevitably be a serious worldwide predicament as it is expected to cost USD 40.62 billion in 2027 [
1]. This problem has captured the concern of governments and financial institutions, not only because of the monetary losses but because these acts can seriously harm a nation’s reputation. Black’s Law Dictionary defines fraud as “A knowing misrepresentation of the truth or concealment of a material fact to induce another to act to his or her detriment” [
2]. There are various types of fraud including but not limited to, tax evasion, insurance fraud, credit card fraud, money laundering and identity theft. Most banks and financial firms use rule-based systems, in which an expert will use historical fraud data to define a set of rules, and a system will raise an alarm if a new transaction matches one of the rules [
3,
4]. The main limitations of this manual process are that it is reactive, lacks flexibility and consistency as well as the fact that it is time-consuming [
5]. Amid these challenges, firms ought to espouse a proactive technology-driven approach for fraud detection, particularly with the new sophisticated criminal techniques that are continually evolving with technological advancements. The era of technology advancement has aided the financial industry in the better detection of these financial crimes by harnessing the power of machine learning techniques that can uncover hidden patterns and, therefore, identify fraudulent financial activities using the realistic dataset to simplify decision-making processes. Furthermore, it helps in keeping up with the ever-changing sophisticated fraud techniques.
Machine learning is the science of getting computers to learn without being explicitly programmed [
6]. It has been commonly used in a wide range of disciplines such as; Chemistry [
7], Bioinformatics [
8], Manufacturing industries [
9], the Medical Field [
10,
11,
12], Biology [
13] and in Finance [
3,
14,
15,
16].
For fraud detection, machine learning is mainly employed to help organizations and financial institutions better detect fraudulent transactions. However, fraud detection can pose a challenge for machine learning for several reasons [
14]:
The distribution of the data is highly imbalanced as the number of fraudulent transactions is very small.
The data is continually evolving over time.
Lack of real-world dataset due to privacy concerns.
As an attempt to overcome these challenges, multiple approaches were proposed in the literature while the main focus was placed on utilizing the idea of a hybrid model.
Several studies on the formation of hybrid models for fraud detection have been reported [
13,
16,
17,
18,
19,
20,
21]. However, these hybrid models only utilized a single model without the consideration of the performance of other models to confirm that the selected model is the optimum choice for the chosen dataset. As such, this has inadvertently led to results inaccuracy and a lack of generalization for the model. The key contribution of this paper is to develop and investigate the use of multiple hybrid models for the same dataset and determine a Champion Hybrid Model based on the evaluation of their performance prediction. We examine the combination of the following eight supervised machine learning algorithms: linear regression (LR), support vector machine (SVM), Naïve Bayes (NB), random forest (RF) decision tree (DT), Light Gradient Boosting Machine (LGBM) and eXtreme Gradient Boosting (XBGOOST) and Adaptive Boosting (Adaboost). The scope of the study is limited to classification supervised machine learning in credit card fraud detection as the nature of most fraud datasets, specifically credit card datasets, is labelled. A real-world dataset was used, and several evaluation metrics were adopted to assess and compare the prediction performance of the proposed hybrid models and the state-of-the-art machine learning algorithms.
The remainder of this paper is organized as follows. The second section provides a brief overview of the hybrid models in the fraud detection domain the literature. The third section discusses in detail the methods and materials including the data collection and preparation. In
Section 4, we discuss the model development using our proposed models and model evaluation. The results and discussion are outlined in
Section 5. Finally, the conclusion and future works are presented in
Section 6.
2. Related Works
Fraud detection has received much attention in the past decade. In this section, hybrid machine learning algorithms used in the credit card fraud domain are reviewed. A growing body of literature has proposed approaches with which to enhance fraud detection.
Combing different approaches together, the authors in [
3] investigated a combination of different approaches together as they proposed a new voting mechanism called OPWEM, standing for; optimistic, pessimistic, and weighted voting in an ensemble of models that can work in tandem with rule-based systems. The authors’ use of OPWEM is fully justified as they suggest that depending on the bank’s strategy for false alarm rates, the bank management should choose one of the voting techniques. For example, pessimistic voting (PES) should be chosen if a bank desires to locate as many fraud cases as possible. On the other hand, a bank that strives for a low false alarm rate should use the optimistic voting (OPT) strategy. Additionally, weighted voting (WGT) discovered more frauds than OPT with a marginal false alarm rate. Therefore, it may be selected as a good alternative to OPT and PES. Additionally, a hybrid framework model was presented based on the combination of unsupervised and supervised learning models by the author in [
17]. The author’s objective was to identify fraudulent transactions at a low cost including the amount of time and effort spent by bank practitioners to reach the necessary level of expertise in machine learning classification methods. The author employed a straightforward approach for one-class classification, with the improvement that the data description boundary is altered based on the account holders’ purchasing behavior. To enhance the model’s output, a post-processing operation was implemented in which rule-based filters are used to pass the flagged accounts. The author concluded that the one-class classification method is highly suitable for complex and large-scale datasets of transaction data as it assists in developing an account group structure that provides personalized models for different types of cardholder behavior. It has been mentioned by the author that the used technique, combined with the post-processing level of the rule-based filters, yields the best results. However, the main limitation of this study is that the experimental findings display that most of the fraudulent cases detected using the hybrid technique are missed by the bank’s rule-based system, and vice versa. This implies that both methods should be used concurrently to gain the optimum results.
Moreover, a hybrid model for improving fraud detection accuracy by combining supervised and unsupervised methods was presented by the authors in [
22]. They displayed several criteria for calculating outlier scores at various levels of granularity (from high granular card-specific outlier scores to low granular global outlier scores). Then, they evaluated their added value in terms of precision once integrated as characteristics in a supervised learning approach. Unfortunately, in terms of local and global methods, the results are unconvincing. However, the model provides a more considerable result in terms of Area Under the Precision–Recall Curve (AUC-PR).
The authors in [
23] applied Bayesian Classification and Association Rule Learning (ARL) to investigate and discover the real transaction signs of fraudulent accounts, and to provide a reference in fraud prevention to the financial industry. Based on these signs, a fraudulent account detection system was developed, and the signs were further investigated by utilizing real-time daily transaction data. They concluded that the proposed method of their study is effective and efficient and can be used by financial institutions to minimize the need for the manual screening of fraudulent accounts. Likewise, an intelligent model for credit card fraud detection to identify fraud in anonymous and heavily skewed credit card datasets was proposed by the authors in [
20]. The authors divided each customer’s transactions into fraudulent and legitimate transactions, then they applied the Apriori algorithm to both sets to determine the patterns for fraudulent and legitimate transactions. Consequently, to detect fraud, they suggested a matching algorithm that searches pattern databases for a match with the incoming transaction. Another important point to note is that to deal with the data’s anonymity each feature was treated equally when looking for patterns and therefore no preference was given to any feature. Finally, the authors suggested running the proposed model at fixed time points occasionally to upgrade the legal and fraud pattern database as a result of customer fraudulent behavior changing slightly over time.
Similarly, the authors in [
21] also presented a hybrid model that combines ARL and process-mining by conducting a process-mining inquiry to collect a number of fraud variables to create some association rules for fraud detection. The aim of process-mining in this context is to inspect skipped tasks, resources, throughput time, and decision points based on simple rules in the Standard operating procedure (SOP). In the first phase, they used a process-mining technique to extract the variables of fraudulent cases from the dataset. Then, an expert determines whether a case contains fraud variables. In the second phase, an Apriori algorithm is used to produce either fraud cases or legal cases. Eventually, as the detection rules, only the association rules with specific consequences such as expert judgement regarding fraudulent status are selected.
Furthermore, a twelve-machine learning algorithm in conjunction with the AdaBoost and majority voting methods using a real credit card dataset obtained from a financial institution has been used to investigate the performance of the used classifiers [
16]. Their result for the highest Matthews correlation coefficient (MCC) score was 0.823, which was obtained by a majority of the votes. However, when using AdaBoost and majority voting procedures, a perfect MCC score of 1 was obtained. To further assess the hybrid models, noise ranging from 10 percent to 30 percent was added to the data samples. When 30 percent noise was added to the data set, the majority voting procedure produced the best MCC score of 0.942. Therefore, the authors reported that the majority vote method performs well in the presence of noise.
More recent research was conducted to develop a hybrid model to detect credit card fraud using credit card datasets and utilizing machine learning classifiers with LR, Gradient Boosting (GB), RF and voting classier [
24]. The author found that RF and GB gave maximum detection rates of 99.99 percent. Although all the aforementioned studies were concerned with fraud detection, different algorithms were used depending on the nature of the dataset. As evident from previous efforts, various approaches were used to detect fraudulent transactions in the financial sector especially the credit card domain either using a single machine learning algorithm or hybrid models. However, these hybrid models only utilized a single model without consideration of the performance of other models to confirm that the selected model is the optimum choice for the chosen dataset. Therefore, this might inadvertently lead to inaccurate results and a lack of generalization for the proposed model. Therefore, a comparison of several hybrid models using the same datasets is still needed to understand the relative performance of the proposed technique. The key contribution of this paper is to develop and investigate the use of multiple hybrid models for the same dataset and determine a champion hybrid model based on the evaluation of their performance prediction.
4. Model Development
Different machine learning classification techniques have been applied to detect fraudulent transactions as discussed earlier. Yet, there is no optimal algorithm for a specific problem [
26]. Therefore, eight different linear and nonlinear algorithms were selected from the literature as they indicated promising performance in the context of fraud detection [
37], including LR, RF, DT, XGBOOST, SVM, NB, Adaboost and LGBM.
In our study, we undertook the methodology suggested by [
38] that has been applied in credit rating, in the credit card fraud detection domain for the first time. Additionally, the majority of the algorithms used in this research were different from the research in [
39]. The development phase of the hybrid models is divided into two phases. In the first phase, a single baseline machine learning classification model was developed using the following eight machine learning algorithms: LR, RF, DT, XGBOOST, SVM, NB, Adaboost and LGBM where their performance was investigated.
Even though algorithm parameter tuning can be useful, a consideration of default parameters is more common in practice. The need for considerable work and time for tuning can dissuade people from implementing the step and could also lead to issues of overfitting for specific datasets [
40]. Appropriately, there were no deliberate efforts to fine-tune the parameters of the methods.
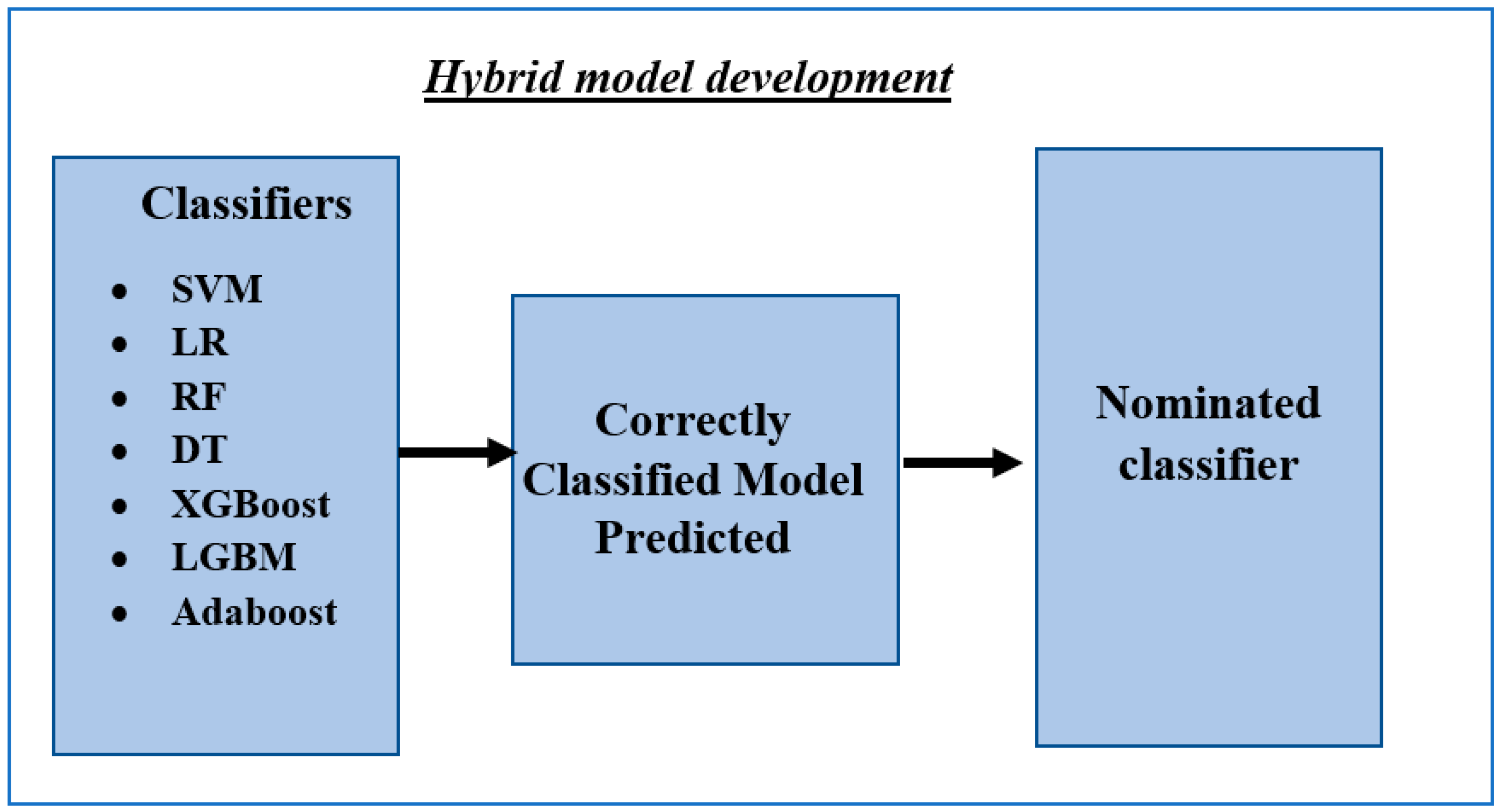
Subsequently, in the second phase of the proposed model, the algorithm with the best performance from the previous experiment based on the highest Area Under the Receiver Operating Characteristic (AUROC) metric served as a baseline model and was used to train the rest of the seven algorithms. The correctly classified data points—true positive (TP) and true negative (TN)—that are generated by the single machine learning algorithm with the highest performance in level one were used to train the hybrid models separately. Consequently, seven hybrid models were constructed and are as follows:
- (1)
The best baseline single model + LR;
- (2)
The best baseline single model + RF;
- (3)
The best baseline single model + DT;
- (4)
The best baseline single model + XGBOOST;
- (5)
The best baseline single model + SVM;
- (6)
The best baseline single model + NB;
- (7)
The best baseline single model + LGBM.
The utilization of the algorithms, which is derived by its score in AUROCmetric for detecting the correct classes, will assist the hybrid models to precisely detect fraudulent and legitimate activities. The proposed hybrid models will be compared with state-of-the-art algorithms to check their effectiveness.
Figure 6 presents the details of the proposed flowchart.
According to the No Free Lunch Theorem, no single model or algorithm can handle all classification problems [
26,
28]. Furthermore, each different algorithm has its advantages and disadvantages as illustrated in
Table 2 [
16,
41,
42,
43,
44]. Consequently, the combination of several algorithms exploits the weaknesses of a single one, such as overfitting. This combination of several algorithms will be beneficial if the algorithms are substantially different from each other. Combining these algorithms together will result in optimal performance and help to overcome the limitation of a single classifier and therefore enhance the detection of fraudulent cases. This distinction could be in the algorithm, or the data used in that algorithm.
5. Model Evaluation
Stratified k-folds validation was applied to measure the efficiency of the proposed model in which it attempts to ensure that both classes (fraud and non-fraud) are roughly evenly distributed in each fold [
27]. In this research, we employed five k, where the validation set is randomly divided into five equal-sized subsets. At each phase of validation, a subset of 25 percent was set aside as the validation dataset to assess the output of the proposed method, while the remaining four subsets that encompass 75 percent were used as a training set.
We employed various performance evaluation metrics that have been widely seen in the literature. It should be noted that the accuracy score is inadequate in the case of a highly imbalanced dataset owing to the overwhelming majority class. Consequently, different criteria are needed to evaluate the model’s performance such as AUROC, AUC-PR, Type-I error, Type-II error F1-measure, recall, precision, misclassification rate and Specificity or True Negative Rate (TNR). The terms used in the applied metrics are defined as follows [
28]:
True positive (TP) implies the number of correctly classified data as fraudulent credit card transactions.
True negative (TN) implies the number of correctly classified data as legitimate credit card transactions.
False positive (FP) denotes the number of legitimate credit card transactions classified as fraudulent.
False Negative (FN) denotes the number of fraudulent credit card transactions classified as legitimate.
Although there is no ultimate individual evaluation metric that can be used to evaluate both negative and positive classes, it was decided that the best overall performance metric for the imbalanced fraud dataset was to use AUROC [
29]. AUROC is an evaluation classification metric that is used to calculate the area under the ROC curve, which gives equal consideration to positive and negative classes. The ROC curve presents a compromise between the true positive rate (TPR) and false-positive rate (FPR) and it is calculated as follows:
The AUROC values vary from 0 to 1 where 1 represents ideal prediction, 0 represents terrible prediction performance and 0.5 represents random performance. The advantage of AUROC is that it does not require a specific cut off value. Additionally, it provides valuable information on whether the model is indeed obtaining knowledge from the data or simply guessing. Additionally, it can be more readily understood compared with the numerical methods due to its visual representation method.
In addition, recall and precision were also suitable to evaluate the predictive model to check if it is capable to identify fraudulent transactions accurately. A recall which is equivalent to TPR and sensitivity is the proportion of real credit card transactions predicted correctly by the model as fraudulent cases. On the other hand, precision is the proportion of predicted observations such as fraudulent credit card transactions predicted by the model that are accurate [
11]. If the recall is equal to 1, it indicates that all the credit card transactions are classified as fraudulent. Conversely, precision will be low as many non-fraudulent credit card transactions will be falsely classified as fraud. Thus, performance measurements such as the F1-measure give equal consideration to precision and recall. Moreover, the misclassification rate or error rate will be used which determines the percentage of misclassified observations by the model [
30]. These measures were defined as follows.
False cases that are predicted as possible fraud are costly in fraud detection, as they are taken for further investigation. The precise detection of cases of fraud helps to avoid costs resulting from missing a fraudulent activity (Type-I error), which is usually greater than falsely alleging fraud (Type-II error). Therefore, a Type-I error and Type-II error were used. FP provides the total of nonfraudulent firms that are mistakenly labeled as fraudulent, whereas Type-II error (false negative) indicates the sum of nonfraudulent firms that are incorrectly labeled as fraudulent [
45,
46].
The experiments were carried out on a Windows 10 computer with an Intel Core i7—10750H CPU (2.60 GHz 6 cores) and 16 GB RAM, using the Jupyter Notebook environment in an Anaconda Navigator platform.
6. Results and Discussion
This section presents the results and discussion from our proposed approach and compares the performance of developed hybrid models to the state-of-the-art machine learning algorithms, namely LR, RF, DT, XGBOOST, SVM, NB, Adaboost and LGBM. The single algorithms were compared in terms of prediction performance using their AUROC score to find which ones perform the best in this dataset and therefore are most suited for use as the first algorithm for the proposed hybrid models.
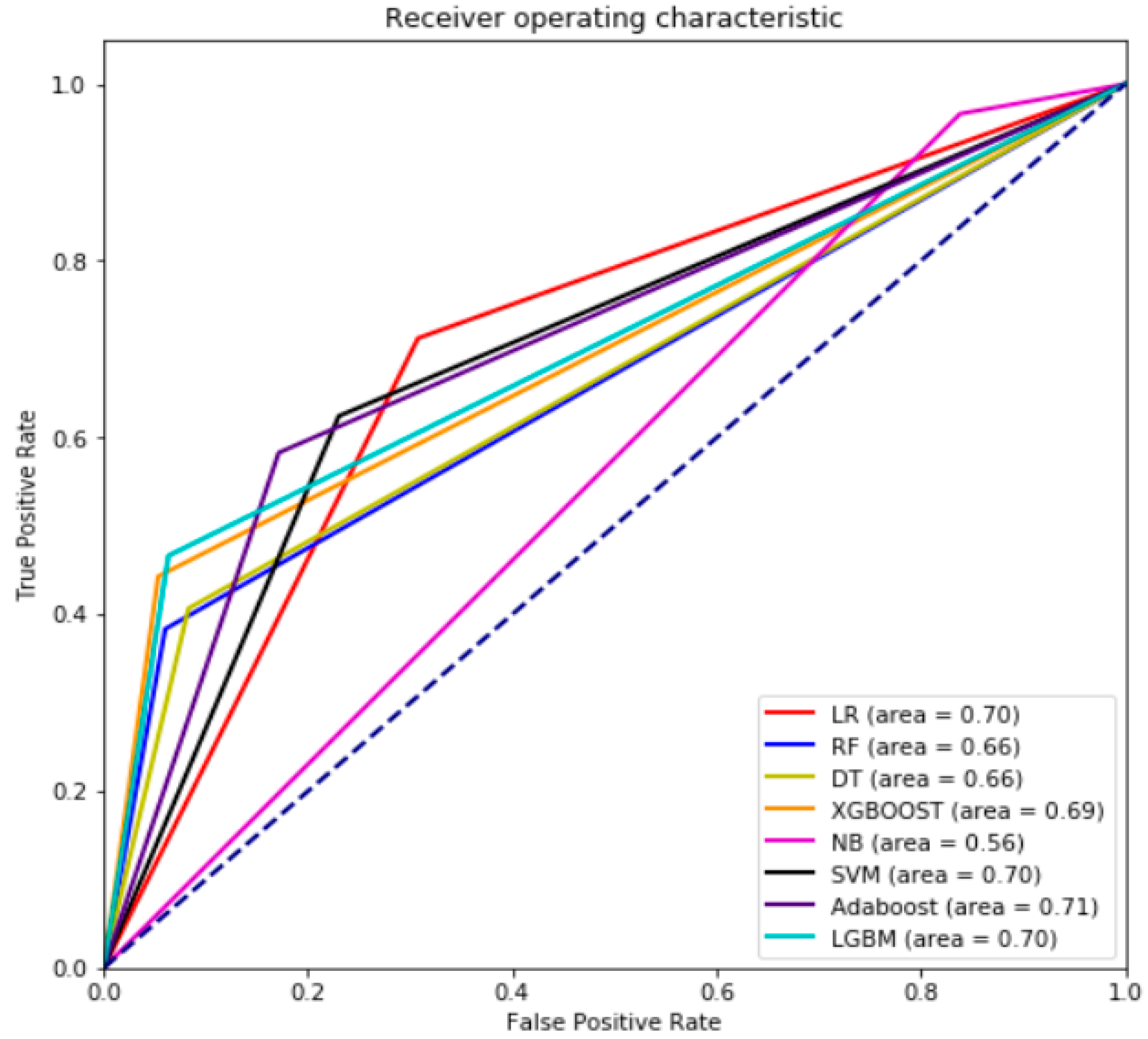
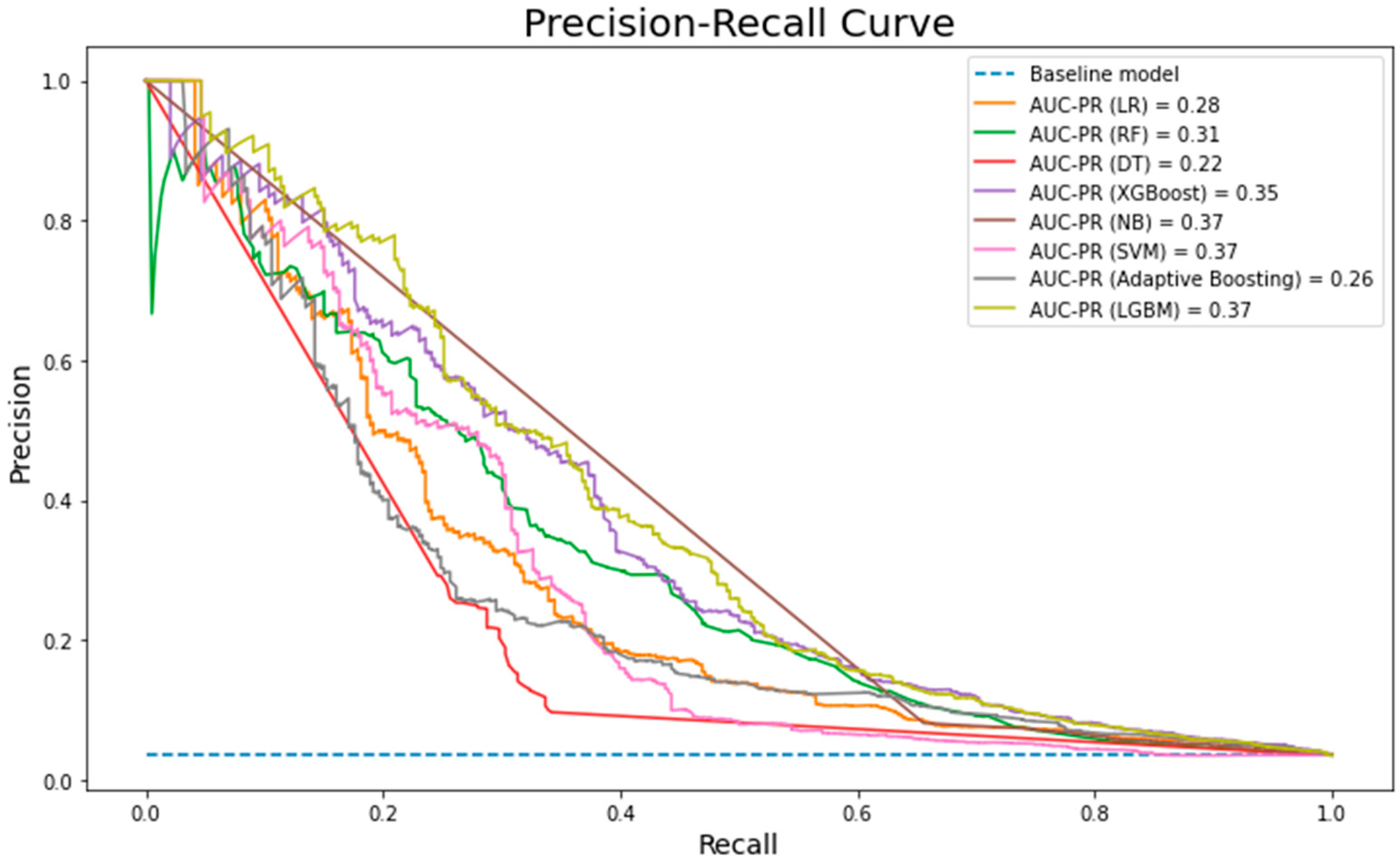
Figure 7 illustrates that generally, all the single models (other than NB) gave relatively similar performance values (0.66–0.71). Adaboost achieved the highest score (0.71) in the first phase. The decision was made based on the highest TPR and lowest FPR achieved by Adaboost, while NB gives the worst performance with an AUROC score of 0.56. The low performance of NB relies completely on the independence assumptions, whereas the used dataset might have some dependence features. However, it demonstrated one of the highest performance rates in the AUC-PR (
Figure 8) alongside SVM and LGBM. One the other hand, DT and LR has shown the worst performance with 0.22 and 0.28 AUC-PR measure, respectively.
As a result of the superior performance of Adaboost in terms of its AUCROC measurement, it was selected as the optimum single baseline model and was be combined with the rest of the algorithms to determine the best hybrid model. The Adaboost algorithm was able to correctly classify 9023 credit card transactions as shown in
Table 3. Next, to establish the correctly classified dataset, TP was added to TN to train and validate the hybrid models.
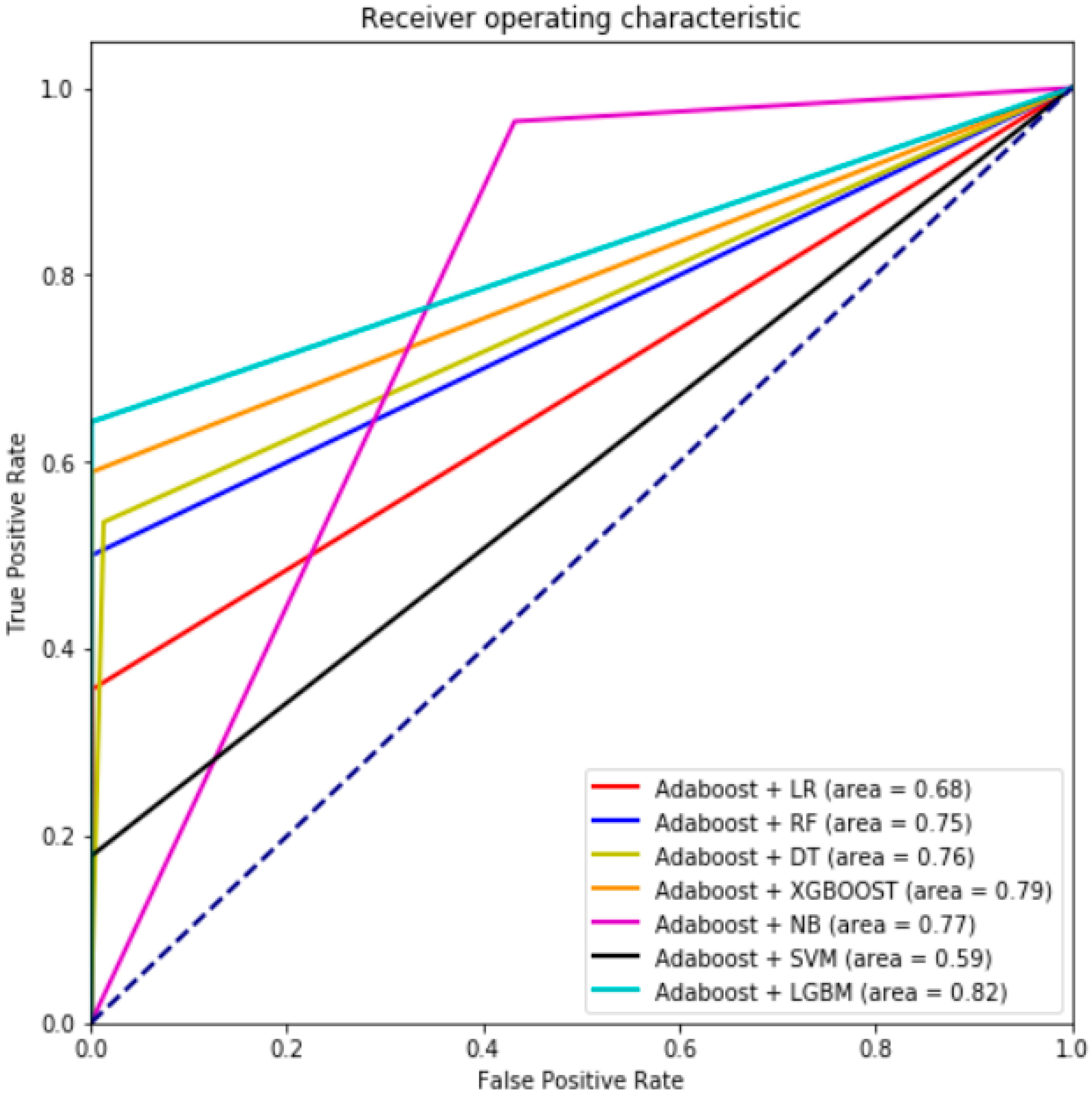
In the second phase, seven hybrid machine learning models were developed (
Figure 9). The predictive performance of the hybrid models has shown that the performance of the hybrid model Adaboost + LGBM excels in terms of its AUROC measure when utilizing real-world dataset (IEEE– CIS). As displayed in
Table 4, the experimental results show that most of our proposed approaches outperformed the state-of-the-art machine learning algorithms in terms of AUROC, Type-I error, Type-II error, F1-measure, precision, misclassification rate and TNR, although some of the hybrid models (Adaboost +LR, Adaboost + NB and Adaboost + SVM) had a higher Type-II error than the state-of-the-art algorithms. However, this will not be a server issue as Type-I error is more costly and being able to lower such an error will have a good impact on the bank system. Additionally, all the proposed hybrid models were able to detect the non-fraudulent cases that were identified as non-fraud at a rate of almost 0.99 percent.
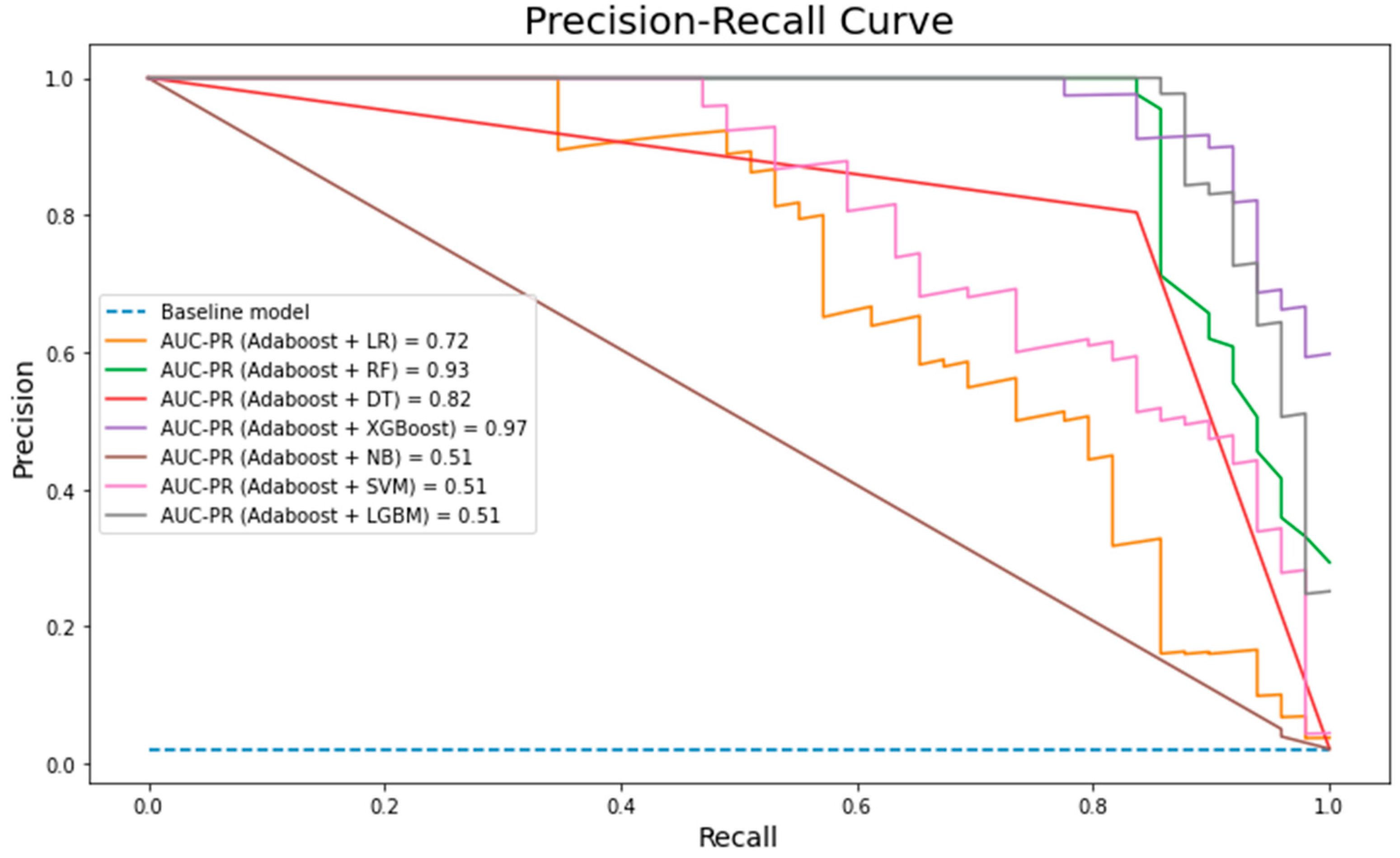
It is reflected in the AUC-PR (
Figure 10) that the combination of Adaboost + XGBOOST outperforms the other six machine learning algorithms. Furthermore, Adaboost + XGBOOST and Adaboost + LGBM have a high capability of accurately identifying fraudulent activities as they have the lowest misclassification error rate (0.002) of AUROC. Utilizing Adaboost as a preprocessing step yields a cleaner dataset, which is expected to result in a more accurate and robust model that gives rise to a positive impact on the dataset via lowering the error rate for all the used algorithms. However, Adaboost + LGBM indicated a noticeable performance as it reached 0.82. On the contrary, LR and SVM showed decreasing performance for AUROC measures when hybridization with Adaboost took place. This indicates that hybridization between machine learning algorithms does not necessarily lead to higher performance. Additionally, looking into details for Adaboost + LGBM, a precision value of 0.97 indicates that when the model predicted a positive result it was correct 97 percent of the time and a recall value of 0.64 indicates that the model was able to identify 64 percent of all positive values correctly. In terms of the tradeoff between both measures, an F1-measure of 77 percent gives an equal consideration of both values. Having such a high result compared with other hybrid models in terms of its precision, ROC, F-measure, and misclassification rate, we conclude that Adaboost + LGBM is the best hybrid model for the given dataset in this study.
7. Conclusions
Credit card fraud has recently become a major concern worldwide, especially for financial institutions. Various approaches have been previously used to detect fraudulent activities; however, the need to investigate different reliable methods still exists to detect fraudulent credit card transactions, as was the aim in this work for a single case study. In this research, several hybrid machine learning models were developed and investigated based on the combination of supervised machine learning techniques as a part of a credit card fraud detection study. The hybridization of different models was found to have the ability to yield a major advantage over the state-of-the-art models. However, not all hybrid models worked well with the given dataset. Several experiments need to be conducted to examine various types of models to define which works the best. Comparing the performance of the hybrid model to the state-of-the-art and itself, we conclude that Adaboost + LGBM is the champion model for this dataset. The result also illustrates that the use of hybrid methods has lowered the error rate. For future work, the hybrid models used in this study will be extended to other datasets in the credit card fraud detection domain.
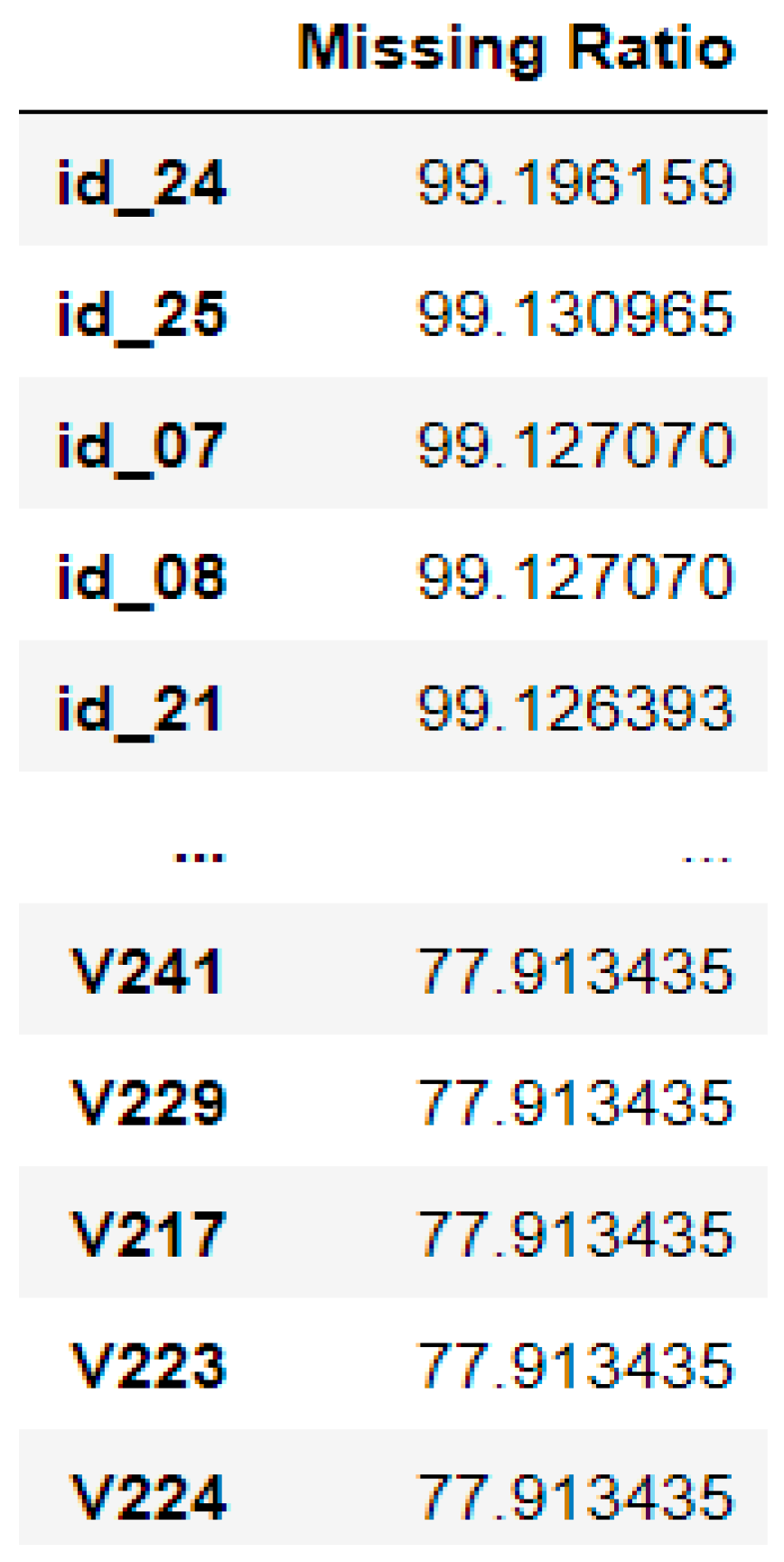
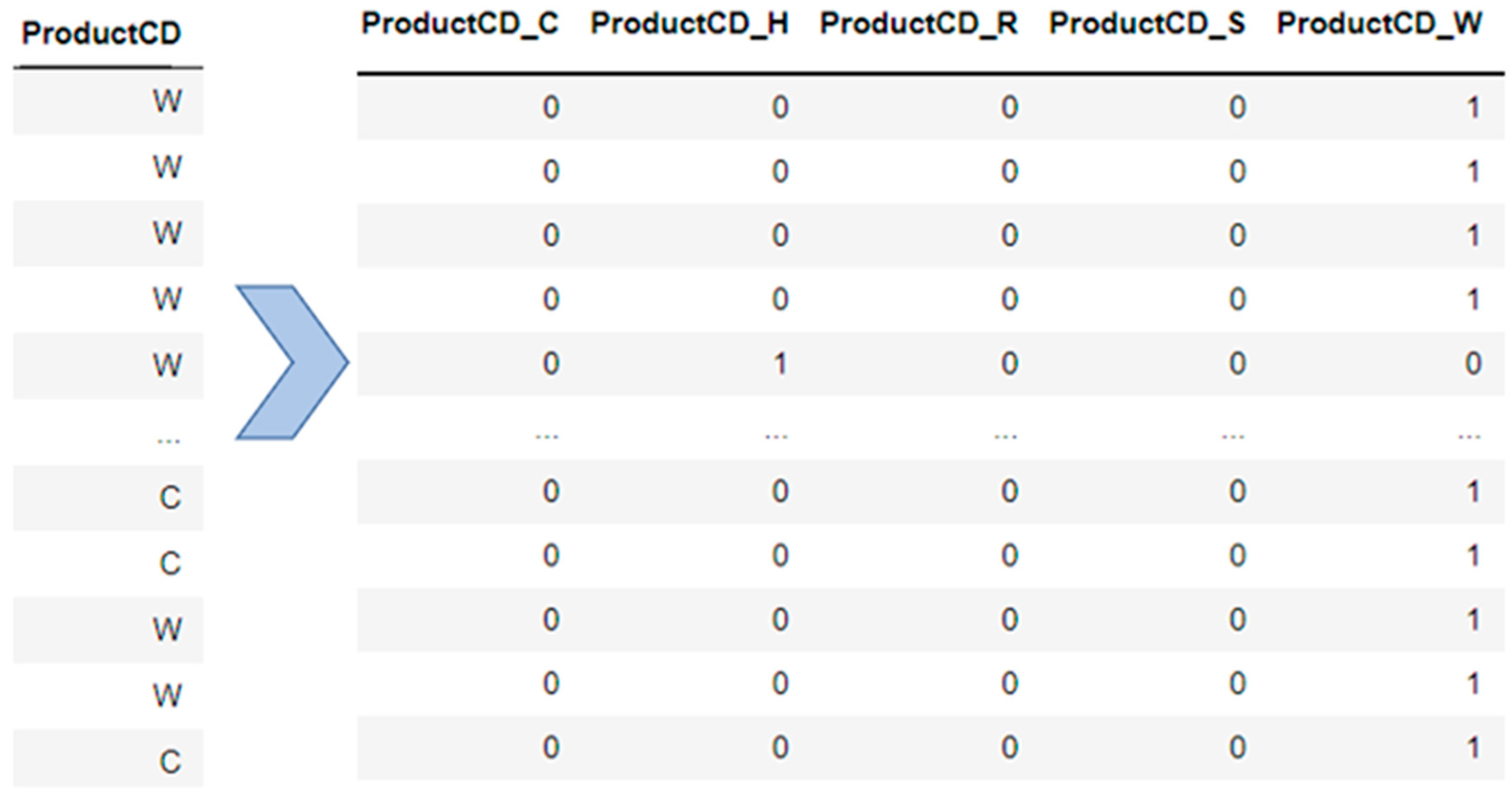
Future work may focus on different areas, starting by proposing data preprocessing techniques to overcome the drawback of the missing values. Additionally, different methods of feature selection and extraction should be investigated in the credit card domain and to determine its impact on prediction accuracy. An investigation of the most appropriate hybrid model among the state-of-the-art machine learning algorithms to determine the most accurate hybridized model in the previously mentioned domain should be the main concern for future studies.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}