
Bayesian Influence Analysis of the Skew-Normal Spatial Autoregression Models

Abstract
:1. Introduction
2. Models Introduction and MCMC Algorithm
3. Bayesian Local Influence Analysis
3.1. Perturbation Model and Manifold
3.2. Local Influence Measures
4. Bayesian Case Influence Analysis
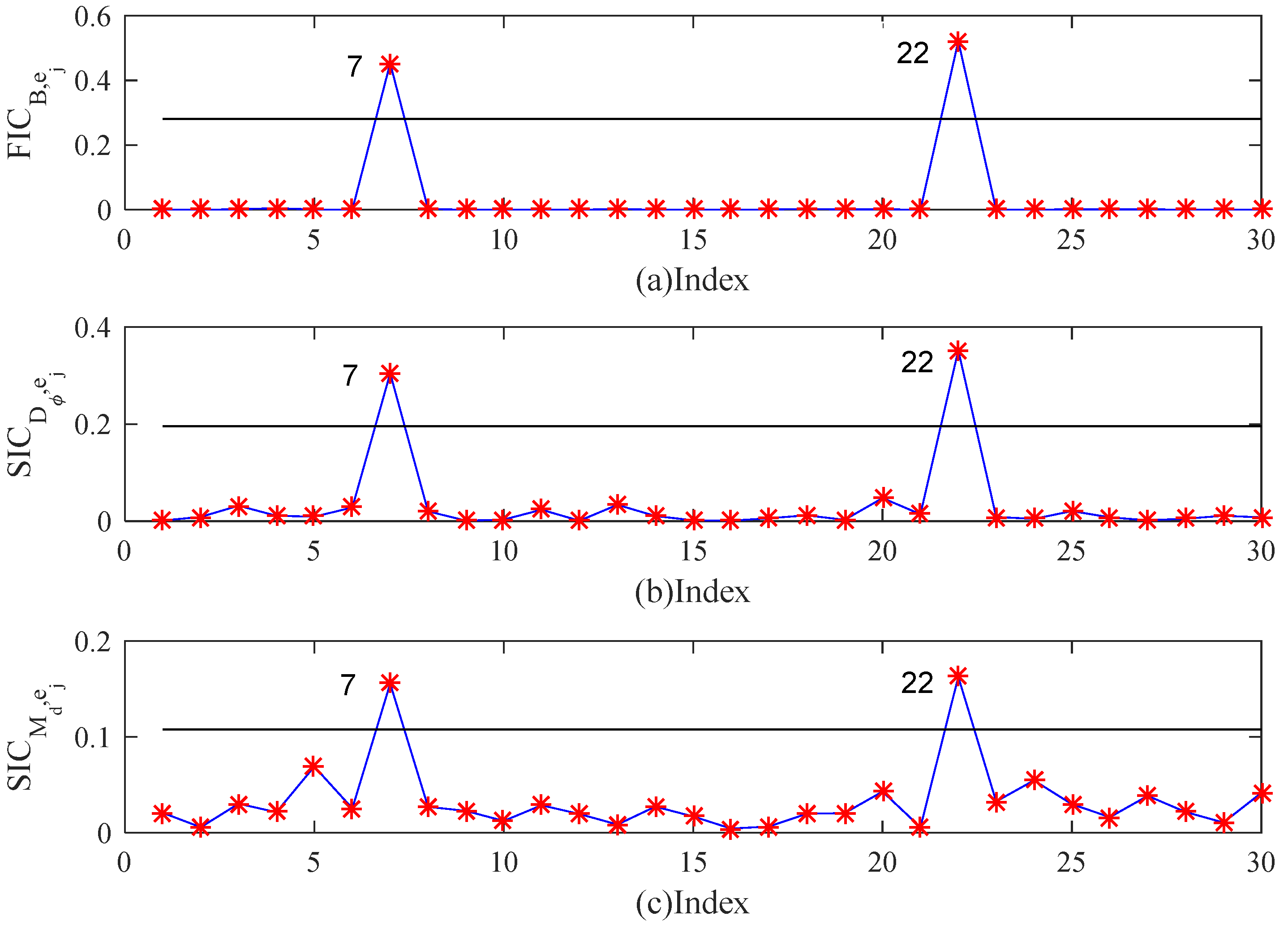
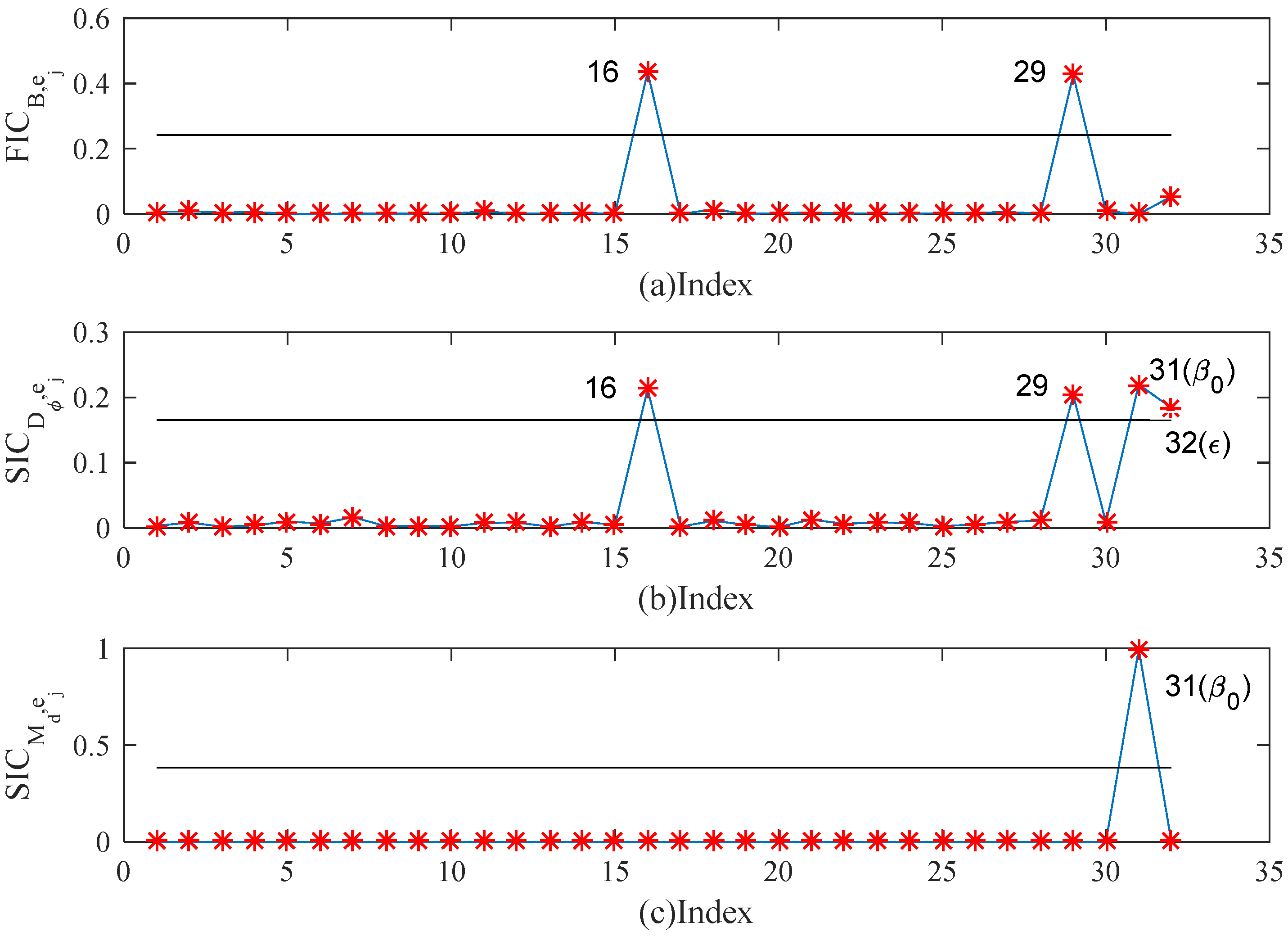
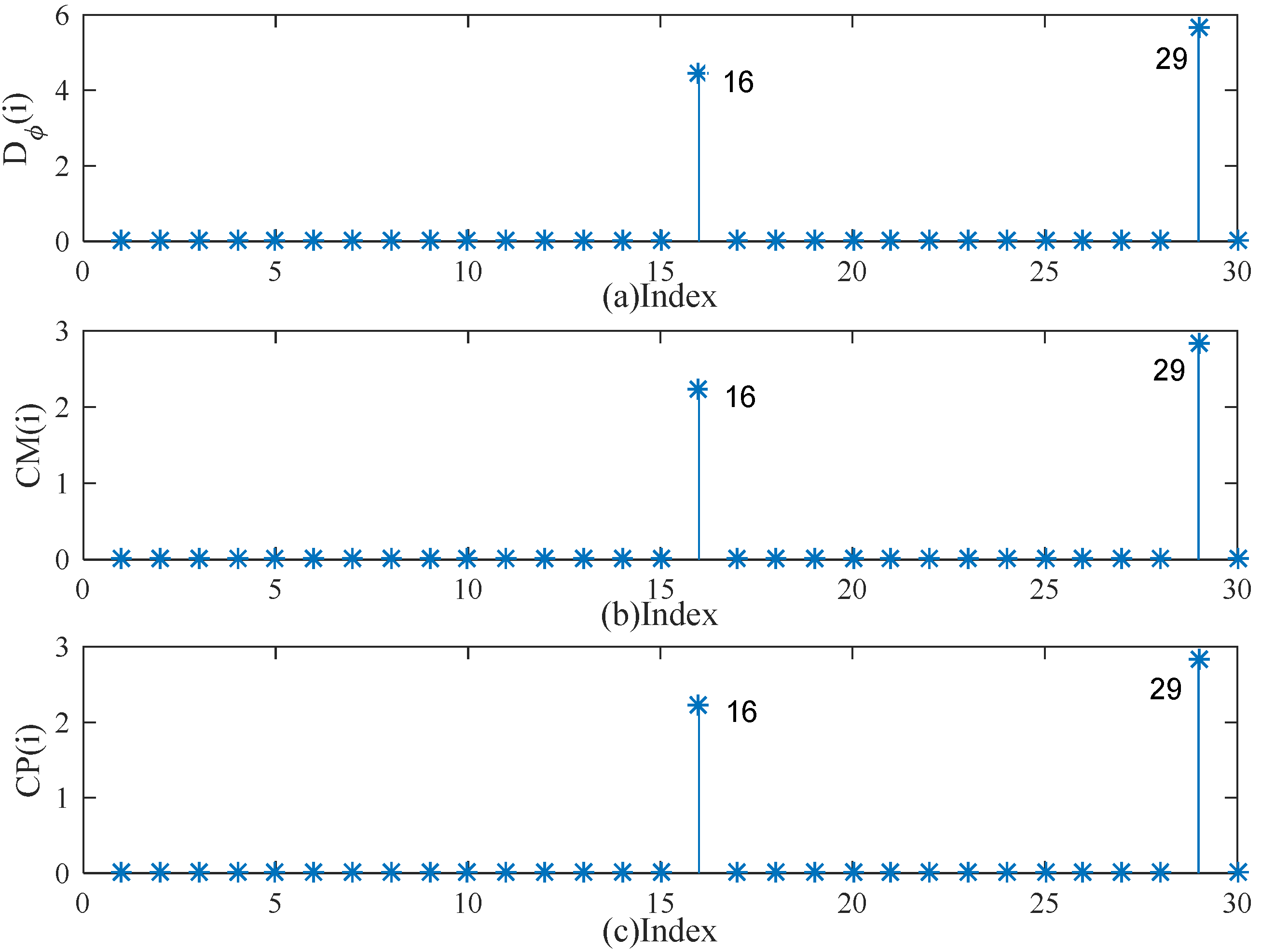
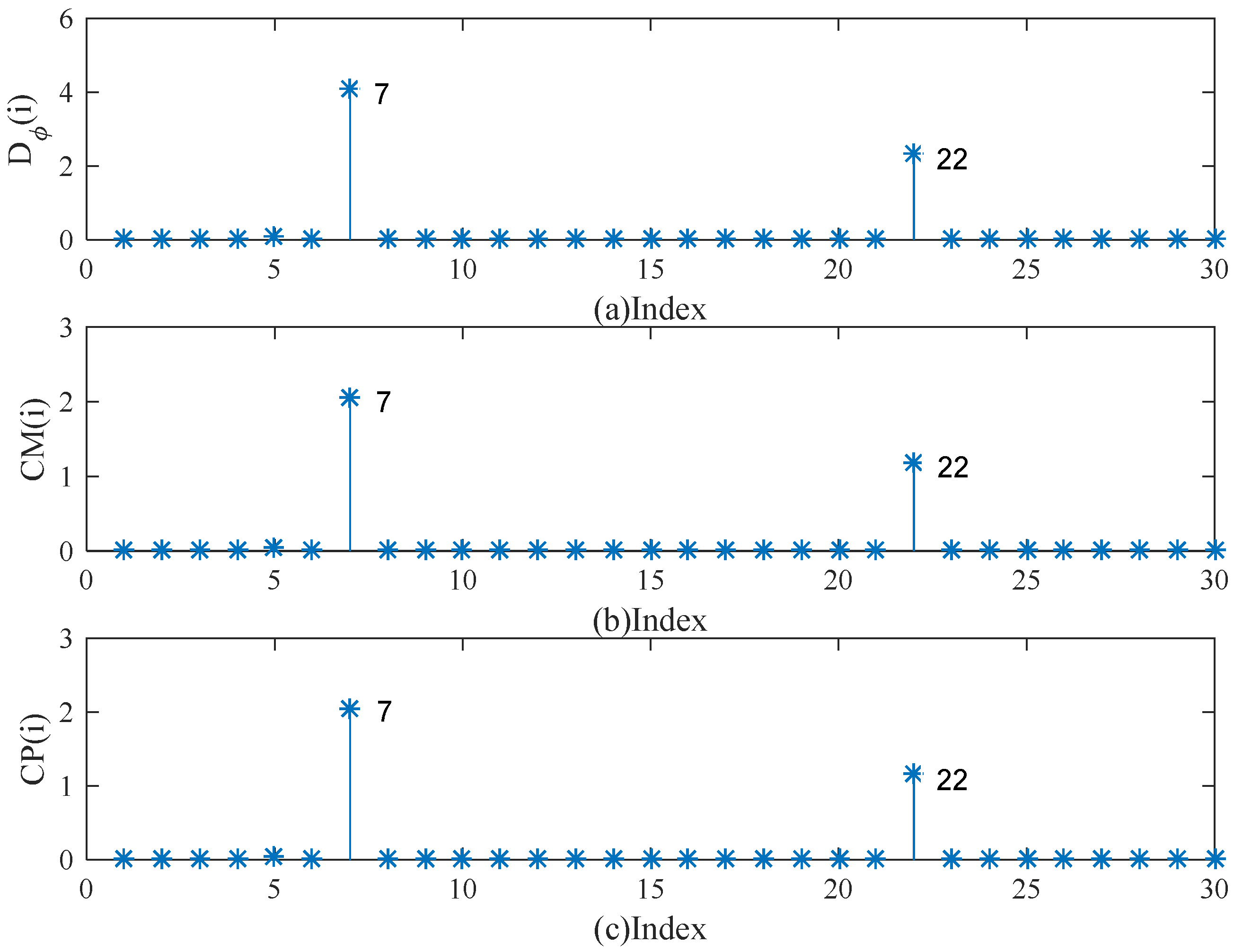
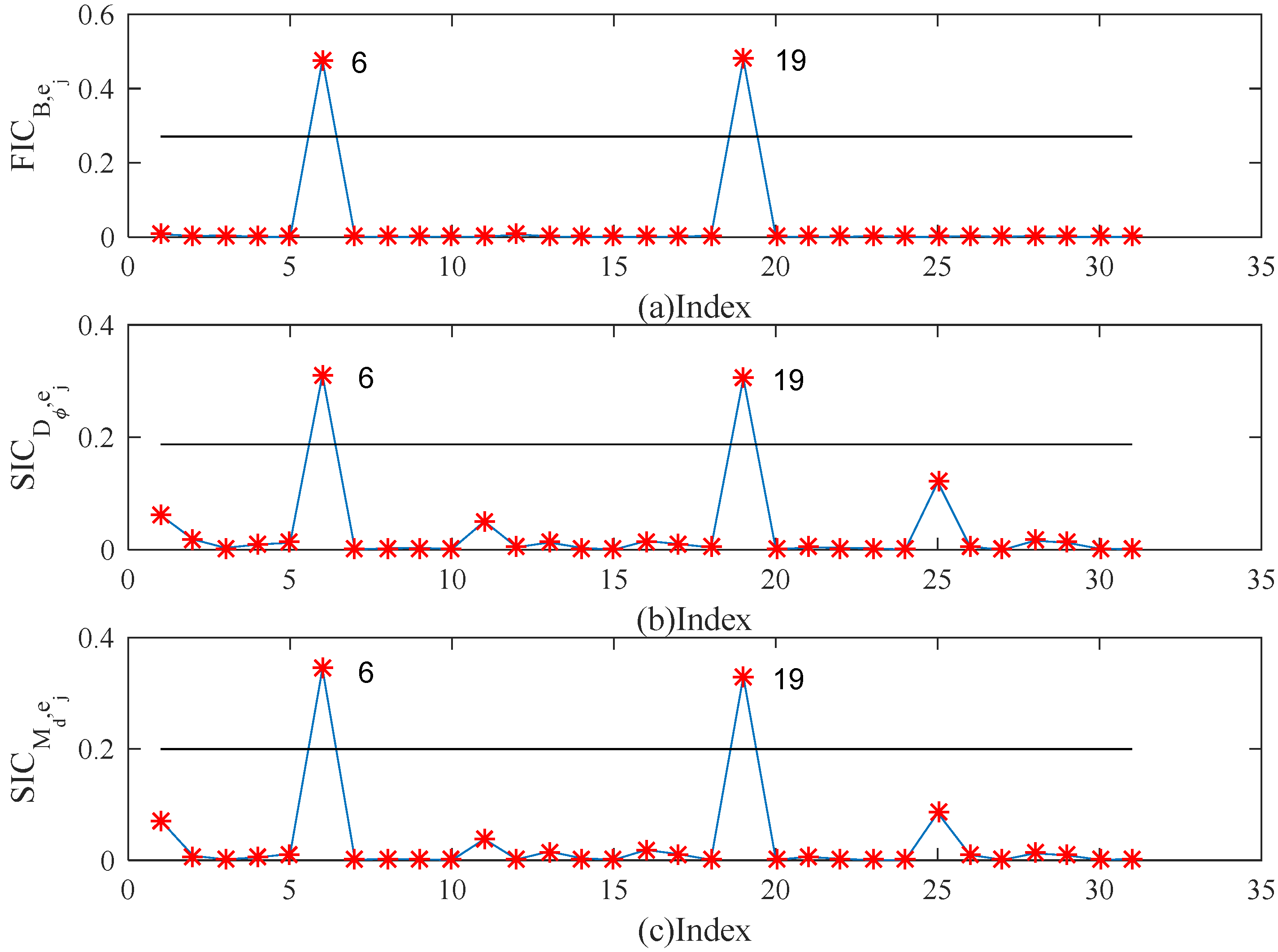
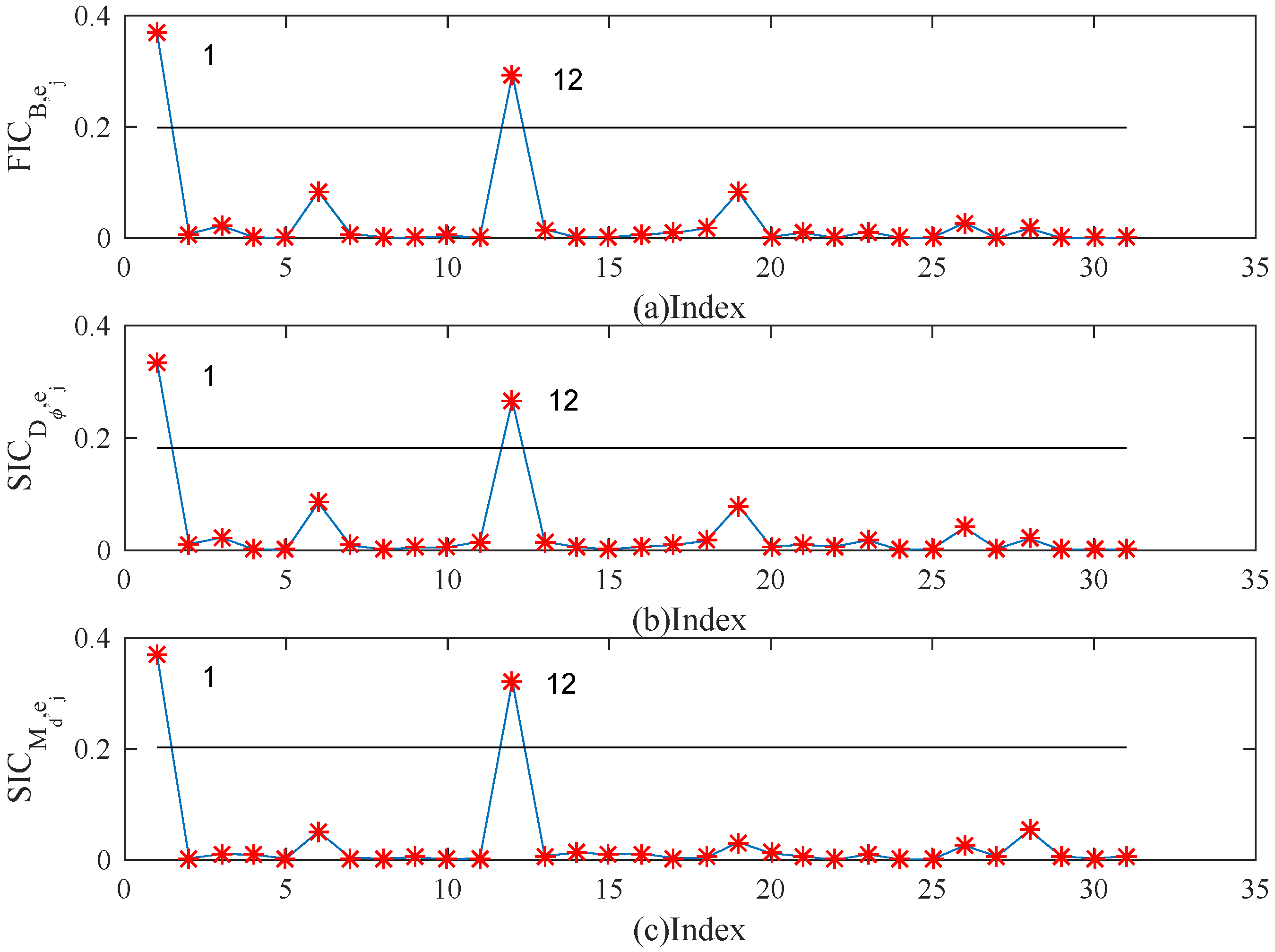
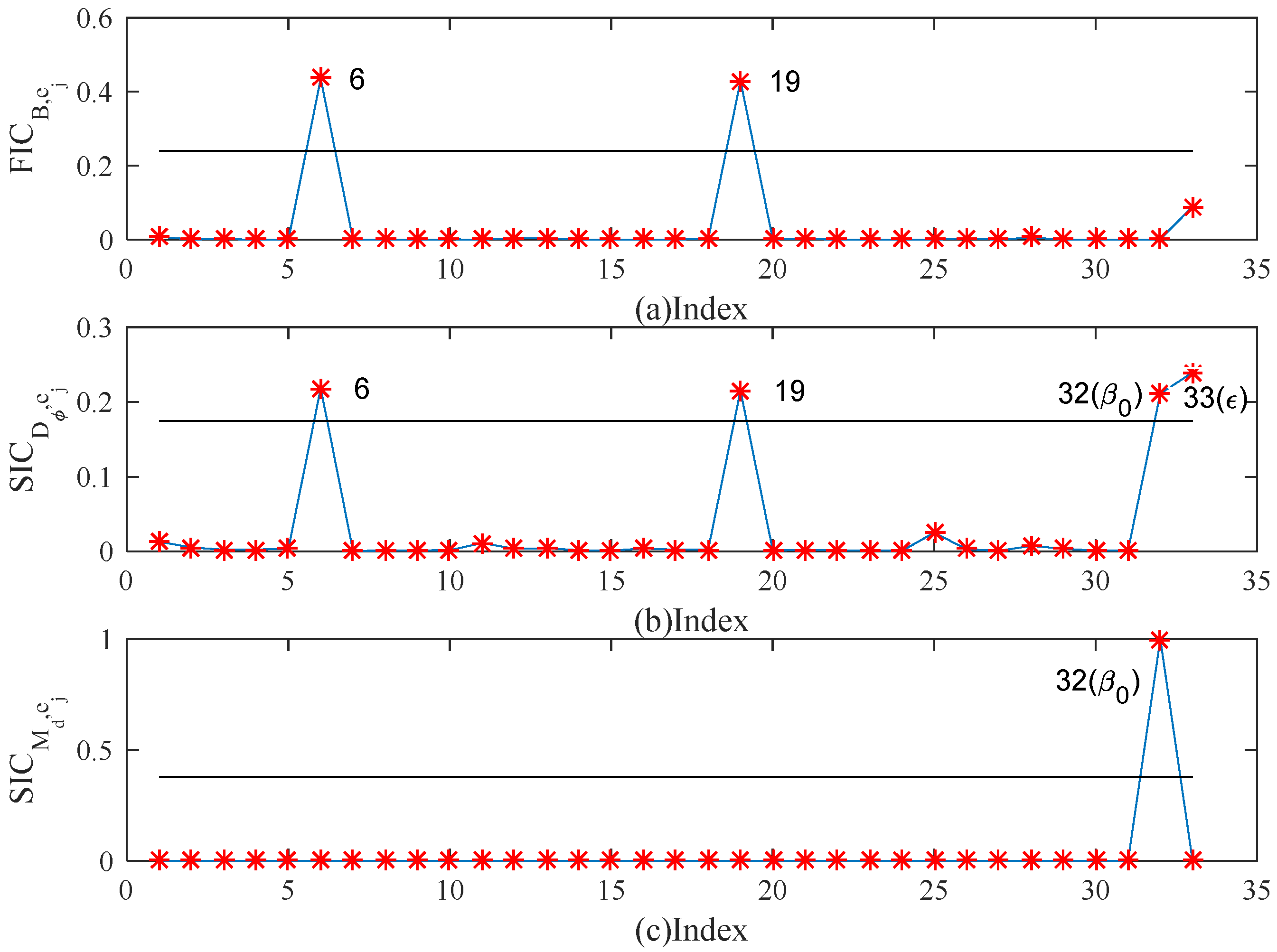
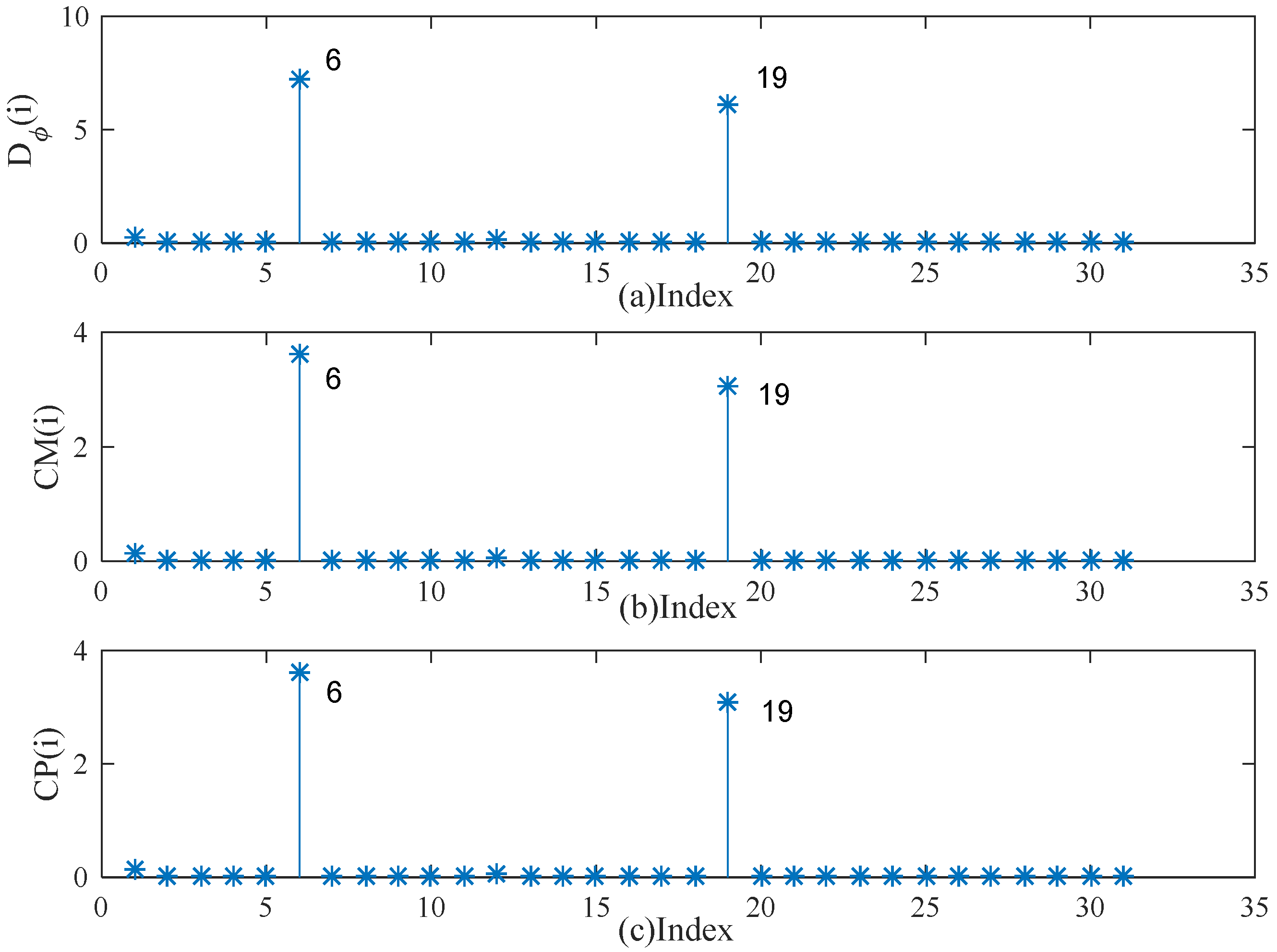
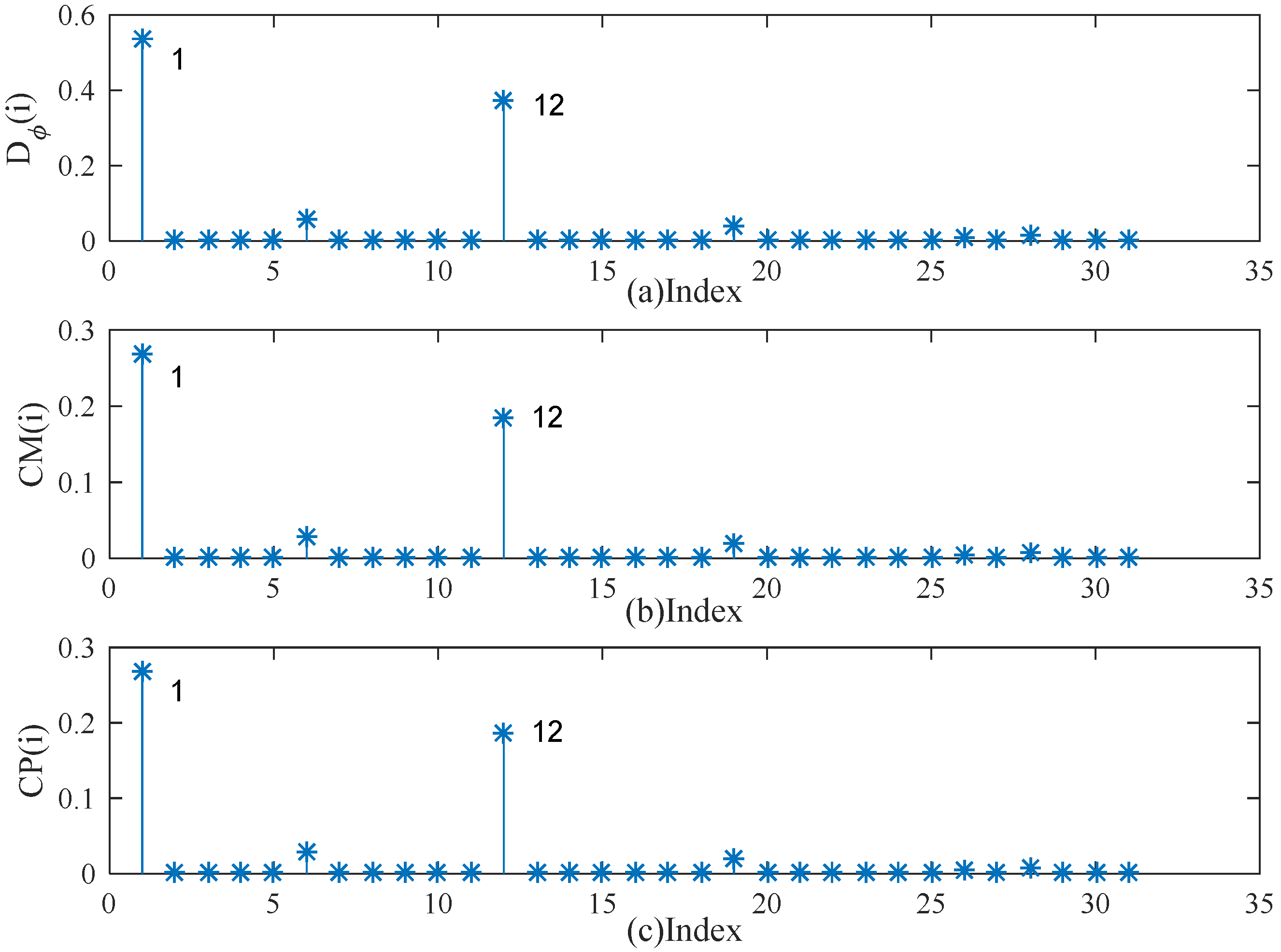
5. Simulation Studies and Real Examples
5.1. Simulation Studies
5.2. Real Example
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- LeSage, J.; Pace, R.K. Introduction to Spatial Econometrics; Chapman and Hall: London, UK, 2009. [Google Scholar]
- Piribauer, P.; Cuaresma, J.C. Bayesian variable selection in spatial autoregressive models. Spat. Econ. Anal. 2016, 11, 457–479. [Google Scholar] [CrossRef]
- Xie, T.F.; Cao, R.Y.; Du, J. Variable selection for spatial autoregressive models with a diverging number of parameters. Stat. Pap. 2018, 61, 1125–1145. [Google Scholar] [CrossRef]
- Du, J.; Sun, X.Q.; Cao, R.Y.; Zhang, Z.Z. Statistical inference for partially linear additive spatial autoregressive models. Spat. Stat.-Neth. 2018, 25, 52–67. [Google Scholar] [CrossRef]
- Xie, L.; Wang, X.R.; Cheng, W.H.; Tang, T. Variable selection for spatial autoregressive models. Commun. Stat.-Theor. Methods 2019, 50, 1325–1340. [Google Scholar] [CrossRef]
- Jay, M.; Ver, H.; Erin, E.; Peterson, M.B.; Hooten, E.M.; Hanks, M.J.F. Spatial autoregressive models for statistical inference from ecological data. Ecol. Monogr. 2018, 88, 36–59. [Google Scholar]
- Anik, A.; Bambang, W.O.; Purhadi, P.; Sutikno, S. Lagrange multiplier test for spatial autoregressive model with latent variables. Symmetry 2020, 12, 1375. [Google Scholar]
- Song, Y.Q.; Liang, X.J.; Zhu, Y.J.; Lin, L. Robust variable selection with exponential squared loss for the spatial autoregressive model. Comput. Stat. Data Anal. 2021, 155. [Google Scholar] [CrossRef]
- Pereira, M.A.A.; Russo, C.M. Nonlinear mixed-effects models with scale mixture of skew-normal distributions. J. Appl. Stat. 2019, 46, 1602–1620. [Google Scholar] [CrossRef]
- Yin, J.H.; Wu, L.C.; Dai, L. Variable selection in finite mixture of regression models using the skew-normal distribution. J. Appl. Stat. 2020, 47, 2941–2960. [Google Scholar] [CrossRef]
- Tatsuya, K.; Strawderman, W.E.; Ryota, Y. Shrinkage estimation of location parameters in a multivariate skew-normal distribution. Commun. Stat.-Theor. Methods 2020, 49, 2008–2024. [Google Scholar]
- Liu, Y.H.; Mao, G.; Leiva, V.; Liu, S.Z.; Alejandra, T. Diagnostic analytics for an autoregressive model under the skew-normal distribution. Mathematics 2020, 8, 693. [Google Scholar] [CrossRef]
- Teimouri, M. EM algorithm for mixture of skew-normal distributions fitted to grouped data. J. Appl. Stat. 2021, 48, 1154–1179. [Google Scholar] [CrossRef]
- Zhu, H.T.; Ibrahim, J.G.; Tang, N.S. Bayesian influence analysis: A geometric approach. Biometrika 2011, 98, 307–323. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.Q.; Tang, N.S. Bayesian local influence analysis of general estimating equations with nonignorable missing data. Comput. Stat. Data Anal. 2017, 105, 184–200. [Google Scholar] [CrossRef]
- Ouyang, M.; Yan, X.D.; Chen, J.; Tang, N.S.; Song, X.Y. Bayesian local influence of semiparametric structural equation models. Comput. Stat. Data Anal. 2017, 111, 102–115. [Google Scholar] [CrossRef]
- Dai, X.W.; Jin, L.B.; Tian, M.Z.; Shi, L. Bayesian local influence for spatial autoregressive models with heteroscedasticity. Stat. Pap. 2019, 60, 1423–1446. [Google Scholar] [CrossRef]
- Ju, Y.Y.; Tang, N.S.; Li, X.X. Bayesian local influence analysis of skew-normal spatial dynamic panel data models. J. Stat. Comput. Sim. 2018, 88, 2342–2364. [Google Scholar] [CrossRef]
- Vicente, G.; Cancho, D.K.D.; Victor, H.; Lachos, M.G.A. Bayesian nonlinear regression models with scale mixtures of skew-normal distributions: Estimation and case influence diagnostics. Comput. Stat. Data Anal. 2010, 55, 588–602. [Google Scholar]
- Zhu, H.T.; Joseph, G.I.; Cho, Y.; Tang, N.S. Bayesian case influence measures for statistical models with missing data. J. Comput. Graph. Stat. 2012, 21, 253–271. [Google Scholar] [CrossRef] [Green Version]
- Tang, N.S.; Duan, X.D. Bayesian influence analysis of generalized partial linear mixed models for longitudinal data. J. Multivar. Anal. 2014, 126, 86–99. [Google Scholar] [CrossRef]
- Hao, H.X.; Lin, J.G.; Wang, H.X.; Huang, X.F. Bayesian case influence analysis for GARCH models based on Kullback–Leibler divergence. J. Korean Stat. Soc. 2016, 45, 595–609. [Google Scholar] [CrossRef]
- Duan, X.D.; Fung, W.F.; Tang, N.S. Bayesian semiparametric reproductive dispersion mixed models for non-normal longitudinal data: Estimation and case influence analysis. J. Stat. Comput. Sim. 2017, 87, 1925–1939. [Google Scholar] [CrossRef]
- Arellano-Valle, R.B.; Bolfarine, H.; Lachos, V.H. Bayesian inference for skew-normal linear mixed models. J. Appl. Stat. 2007, 34, 663–682. [Google Scholar] [CrossRef]
- Poon, W.Y.; Poon, Y.S. Conformal normal curvature and assessment of Local Influence. J. R. Stat. Soc. B 1999, 61, 51–61. [Google Scholar] [CrossRef]
- Cook, R.D.; Weisberg, S. Residuals and influence regression. Biometrics 1982, 39, 413–415. [Google Scholar]
- Weiss, R.E.; Cook, R.D. A graphical case statistic for assessing posterior influence. Biometrika 1992, 79, 51–55. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Par. | With | Without | ||
|---|---|---|---|---|
| Est. | SD. | Est. | SD. | |
| 1.1988 | 0.0315 | 1.3440 | 0.0311 | |
| 1.9275 | 0.0320 | 2.1451 | 0.0315 | |
| 1.1440 | 0.0315 | 1.2767 | 0.0313 | |
| 0.1795 | 0.1348 | 0.4755 | 0.2005 | |
| 1.0437 | 0.1023 | 1.3488 | 0.1430 | |
| 0.0979 | 0.0076 | 0.0000 | 0.0000 | |
| Par. | With | Without | ||
|---|---|---|---|---|
| Est. | SD. | Est. | SD. | |
| 1.1988 | 0.0315 | 0.9898 | 0.0316 | |
| 1.9275 | 0.0320 | 1.5838 | 0.0314 | |
| 1.1440 | 0.0315 | 0.9491 | 0.0315 | |
| 0.1795 | 0.1348 | 0.2086 | 0.1701 | |
| 1.0437 | 0.1023 | 3.2987 | 0.7886 | |
| 0.0979 | 0.0076 | 0.1989 | 0.0019 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, Y.; Yang, Y.; Hu, M.; Dai, L.; Wu, L. Bayesian Influence Analysis of the Skew-Normal Spatial Autoregression Models. Mathematics 2022, 10, 1306. https://doi.org/10.3390/math10081306
Ju Y, Yang Y, Hu M, Dai L, Wu L. Bayesian Influence Analysis of the Skew-Normal Spatial Autoregression Models. Mathematics. 2022; 10(8):1306. https://doi.org/10.3390/math10081306
Chicago/Turabian StyleJu, Yuanyuan, Yan Yang, Mingxing Hu, Lin Dai, and Liucang Wu. 2022. "Bayesian Influence Analysis of the Skew-Normal Spatial Autoregression Models" Mathematics 10, no. 8: 1306. https://doi.org/10.3390/math10081306