
Mining Campus Big Data: Prediction of Career Choice Using Interpretable Machine Learning Method


Abstract
:1. Introduction
- (1)
- We use the supervised machine learning method, specifically XGBoost, to support decision making for HEIs based on real data analysis.
- (2)
- We performed a model optimization process to mitigate classification errors and to make complex ML models understandable.
- (3)
- We further put forward some policy to improve the operations of the education system and better serve students’ career choice.
Contribution
- Proposed a novel framework using interpretable machine learning method to identify the significant factors that affecting the students’ career choice;
- Obtained a real-world educational dataset containing four years of education records of 18,000 undergraduates in a specific college;
- Compared the performance of the proposed framework through state-of-the-art methods to validate the findings and further explored the obtained results to obtain a deep insight for students’ career choice;
- Proposed framework and policy suggestions to help HEIs and their managers for better understand their current world.
2. Literature Review
2.1. Educational Data Mining
2.2. Machine Learning in Educational Area
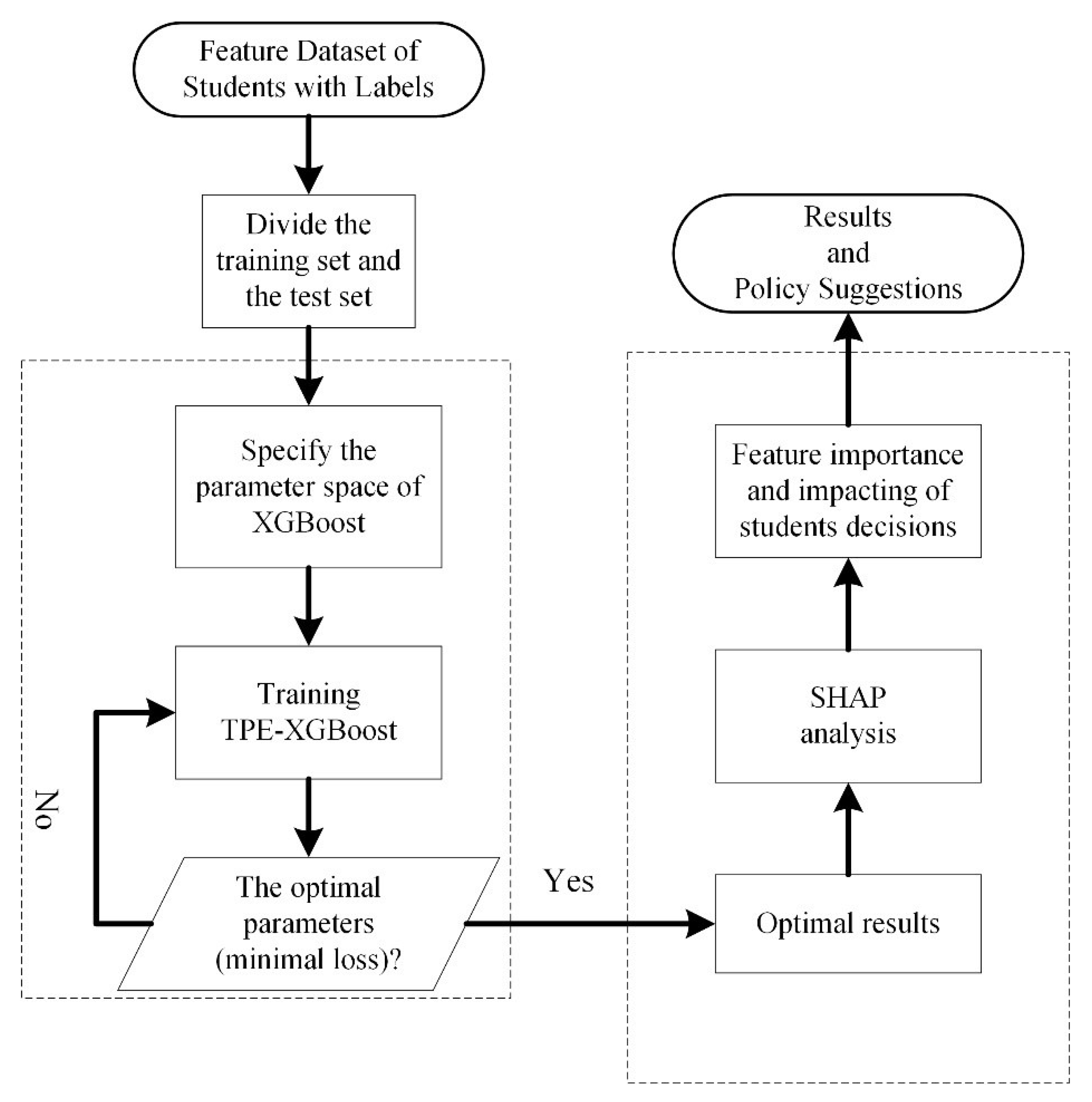
3. Materials and Methods
3.1. XGBoost Algorithm
| Algorithm 1: Exact Greedy Algorithm for Split Finding |
| Input: , instance set of current node |
| Input: feature dimension |
| gain0 |
| G |
| for to m do |
| , |
| for j in sorted (I, by ) do |
| score |
| end |
| end |
| Output: Split with max score |
3.2. Tree-Structured Parzen Estimator for Model Optimization
3.3. Shapley Additivity exPlanation
3.4. Data and Preprocess Methods
3.4.1. Data Source
3.4.2. Data Description
4. Results and Discussion
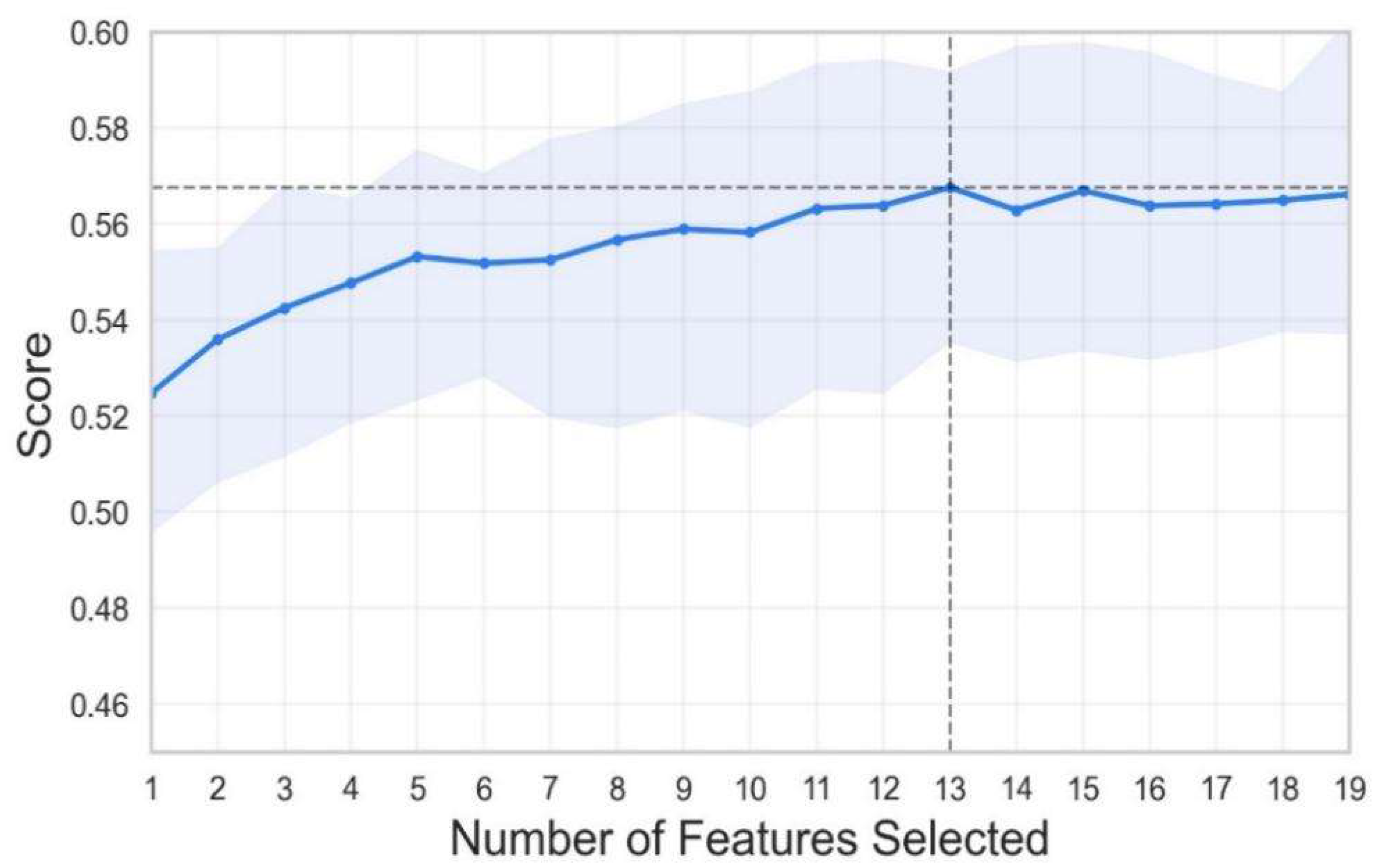
4.1. Feature Selection
4.2. Evaluation Metrics
4.3. Comparison of Model’s Performance
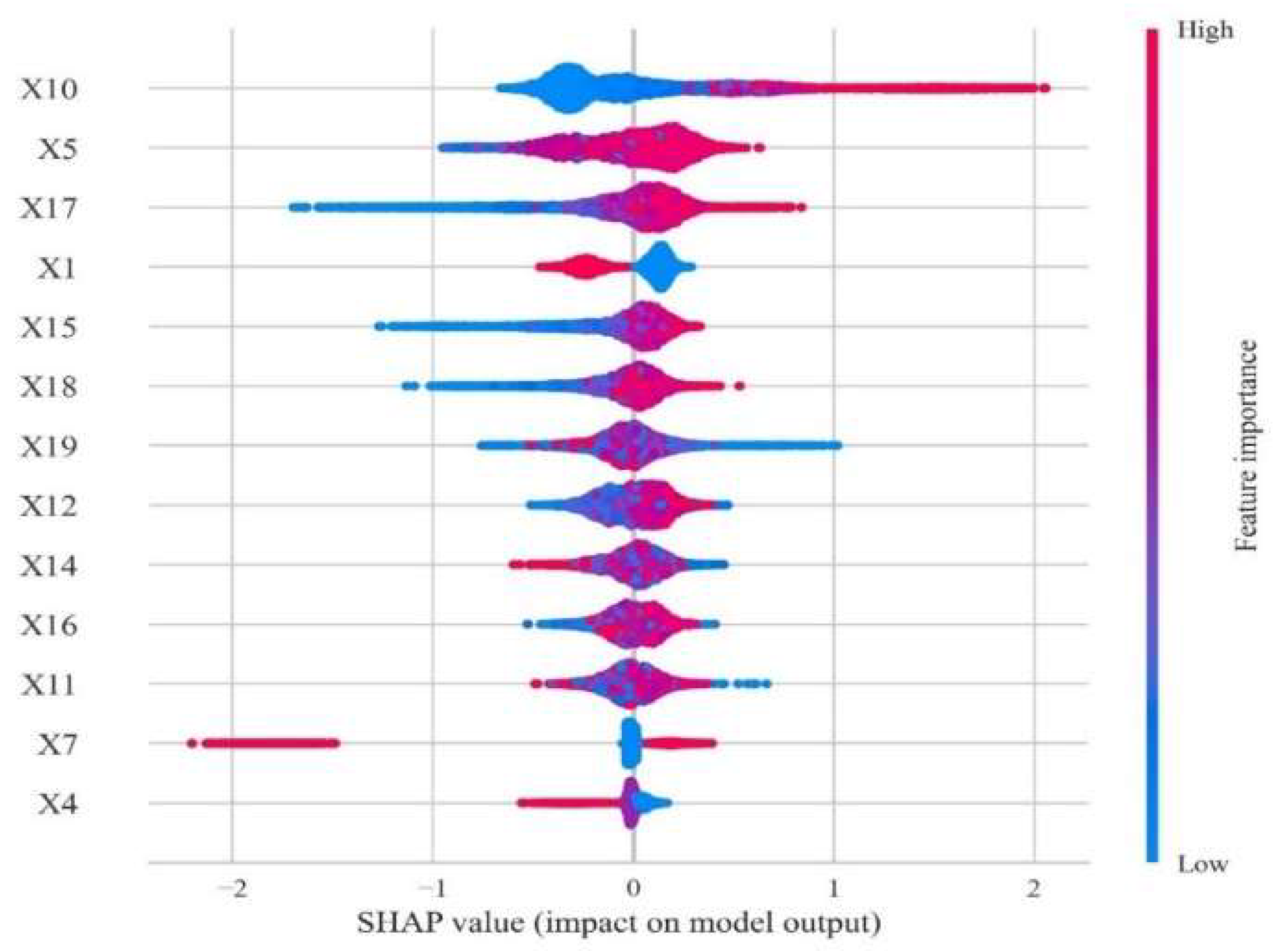
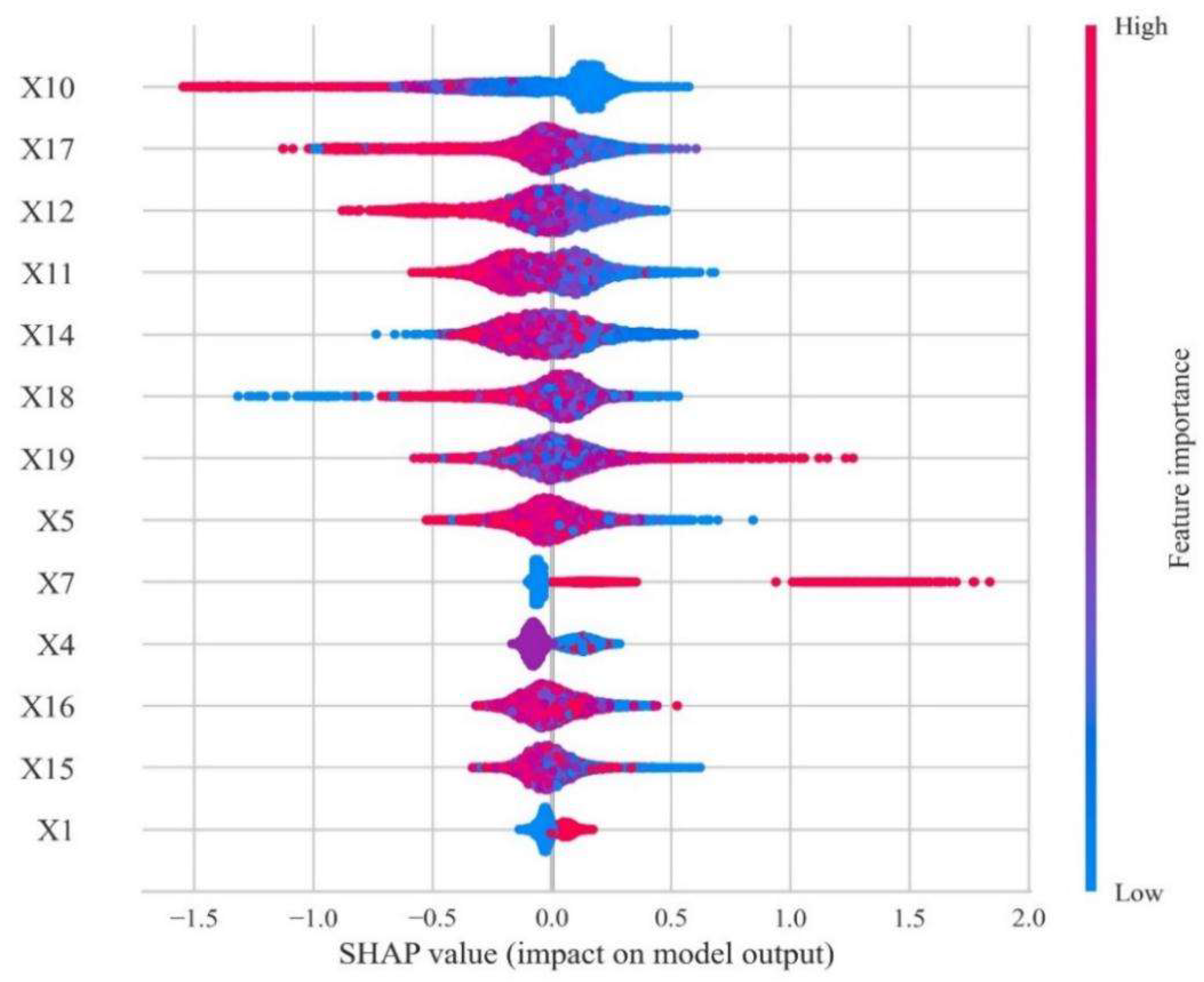
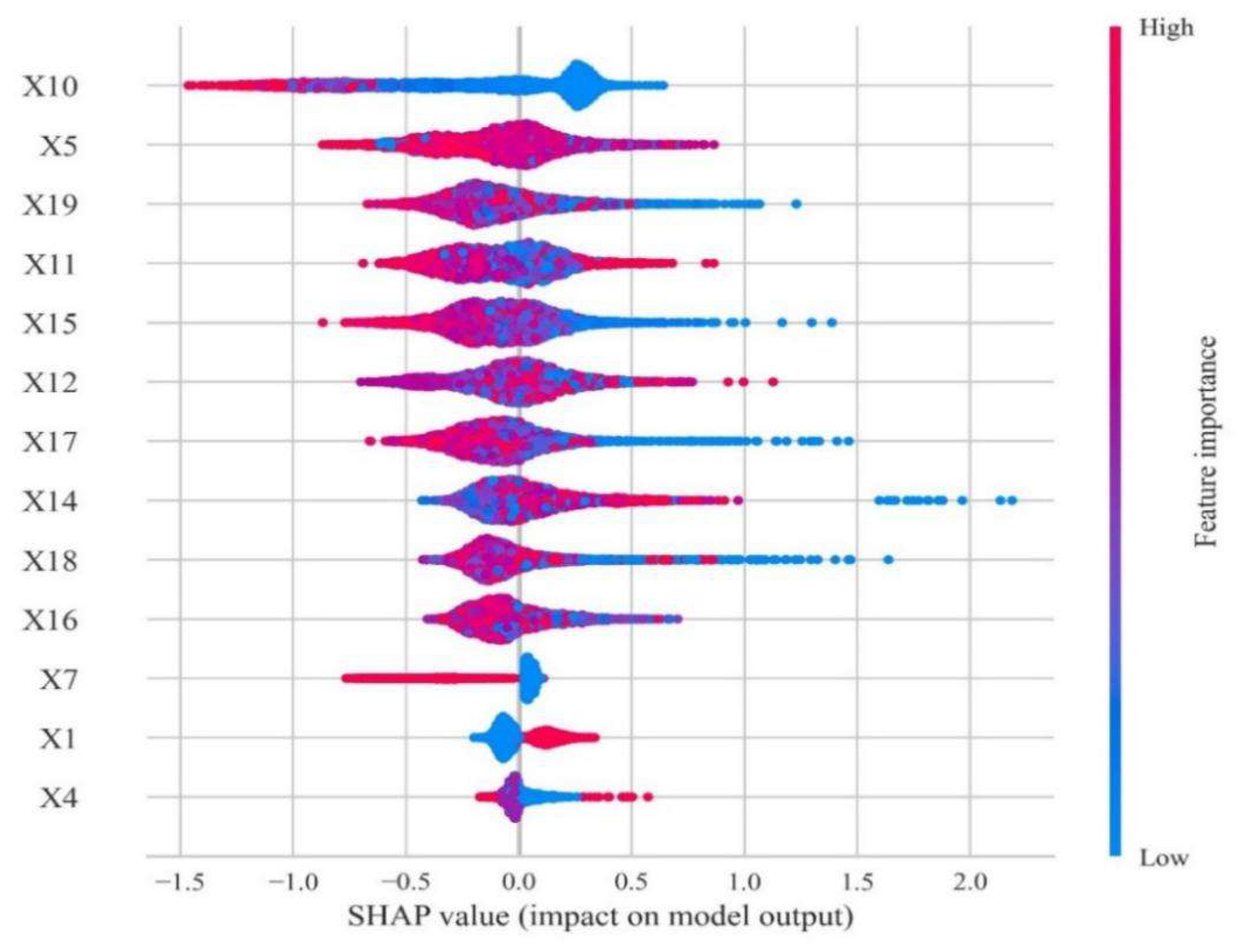
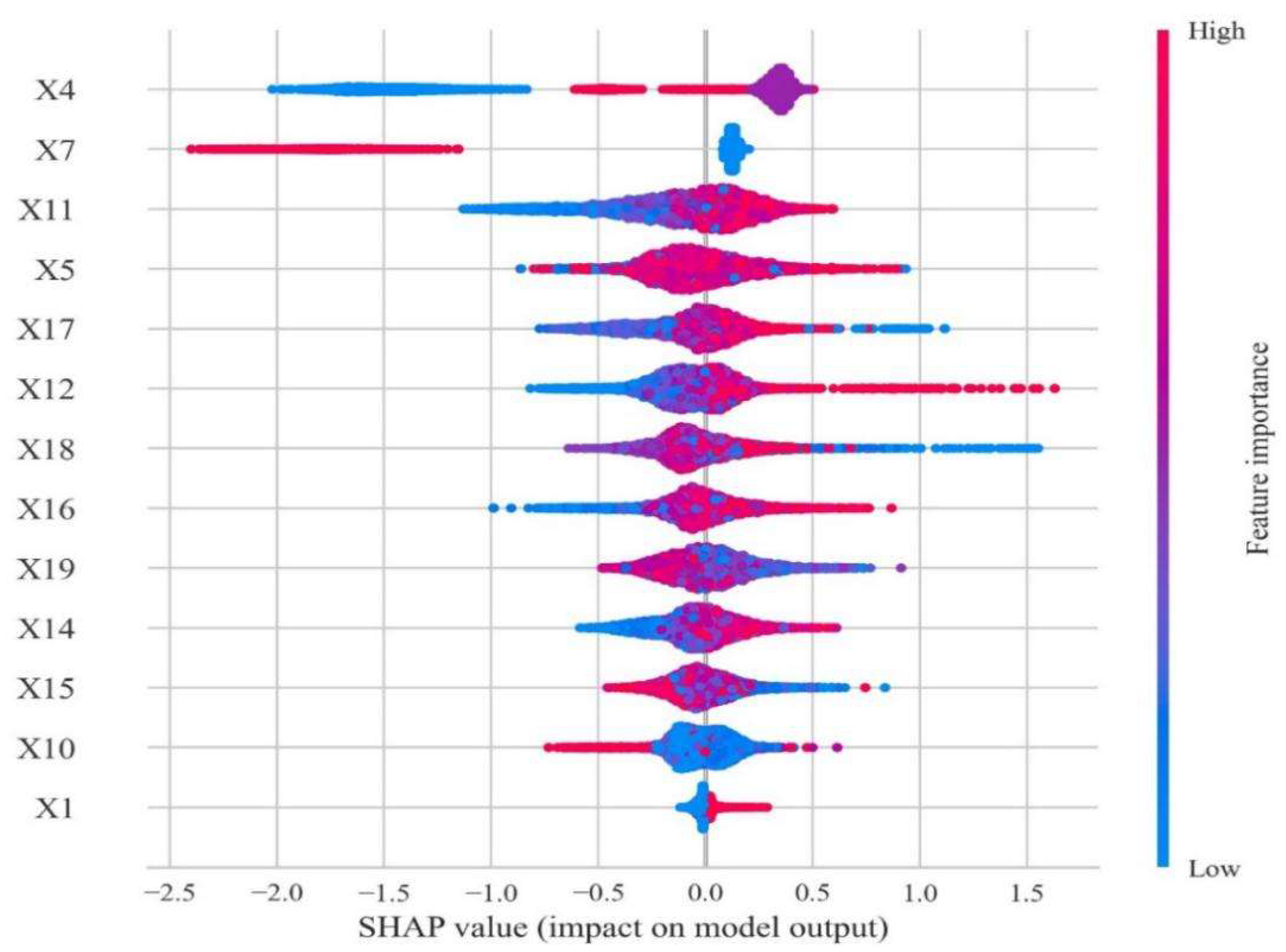
4.4. SHAP Approach for Results Interpretation
5. Conclusions
- (1)
- Within students’ basic information, the score of college entrance examination plays an important role in predicting graduates’ career choice. The results of empirical analysis show that students with high scores tend to choose further education in China, and the higher their scores, the less likely they are to face employment and graduation problems. However, it is worth noting that more students with an intermediate score suffer in employment and graduation compared with those students achieving low scores.
- (2)
- Total amount of scholarships has an important impact on the final academic direction. Students with a higher amount tend to choose domestic postgraduate education rather than employment because they have better learning ability and make clear academic plans. At the same time, it should be noted that the evaluation of scholarship is based on the comprehensive achievements rather than GPA solely, so it is necessary to remind students of the importance of comprehensive development in their lower grade.
- (3)
- In terms of academic data, GPA in the first semester has a vital impact on students’ future choice, which is quite obvious among students taking up further education. Most students with low GPA in the first semester will not consider studying abroad or further education in China. Most of them go to job market directly, or some of them face problems in employment or graduation.
Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Data Information

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Attributes and Characteristics (2014–2018, 2015–2019, 2016–2020) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| New State Attribute | Comprehensive Quality | Scientific Research | Academic Achievement | Grant | Attribute of Employment Status | ||||||
| Initial Data at the Beginning of Enrollment | Student Cadre Position | Situation of Winning Awards | Outstanding Graduate of Beijing | Participation in Innovation Credits | Participation in the Scientific research “Meng Ya” | GPA Throughout College | Scholars-hip Award | Awards obtained during university | Grants received during university | Repayment of National Student Loans | Graduation Information |
| Sex | Organization Name | Time | Yes | Participate in or Not | Level | First Term | Time | Time | Time | On Time | Graduating Year |
| Political Status | Position | Category | No | Win an Award or Not | Rank | Second Term | Name and Level | Name and Level | Name and Level | Over Time | Political Status |
| Nation | Time | Third Term | Total | Total | Type of Registration Card Issued | ||||||
| Students Birth Place | Fourth Term | Reasons for not Being Employed | |||||||||
| School | Fifth Term | Job Category | |||||||||
| Major | Sixth Term | Graduated or Not | |||||||||
| Examinee Category | Seven Term | Implementation Channels | |||||||||
| Subject | Eighth Term | Graduate Destination | |||||||||
| College Entrance Examination Results | Overall GPA | Forms of Employment | |||||||||
| Date of Birth | Total Credits | Channel and Time | |||||||||
| Grade | Category of Difficult Students | ||||||||||
Appendix A.2. Data Processing and Coding
| Features | Gender | Coding |
|---|---|---|
| Gender | Male | 0 |
| Female | 1 | |
| National | Han | 0 |
| Ethnic Minorities | 1 | |
| Political Landscape | Masses | 0 |
| The Communist Youth League | 1 | |
| Probationary Party Member | 2 | |
| Examinee Category | Rural Fresh Graduates | 0 |
| Urban Fresh Graduates | 1 | |
| Former Rural Graduates | 2 | |
| Former Urban Graduates | 3 | |
| Rural to Urban Fresh Graduates | 4 | |
| Note | No | 0 |
| Highest Score in the Major | 1 | |
| Special Talents in Arts | 2 | |
| High Level Athletes | 3 | |
| Directed student | 4 | |
| Poverty Alleviation Program | 5 | |
| Independent Recruitment | 6 | |
| Difficult Students | Non-Difficult Students | 0 |
| Family Difficulties and Physical Disability | 1 | |
| Former Urban Graduates | 2 | |
| Provincial and Municipal Outstanding Graduates or Not | No | 0 |
| Yes | 1 | |
| Awarded at the School Level above or Not | No | 0 |
| Yes | 1 | |
| Total Amount of Scholarships Awarded during University | Total Amount of Scholarships Awarded during University | Total Amount of Scholarships Awarded during University |
References
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2008, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Olaya, D.; Vásquez, J.; Maldonado, S.; Miranda, J.; Verbeke, W. Uplift Modeling for preventing student dropout in higher education. Decis. Support Syst. 2020, 134, 113320. [Google Scholar] [CrossRef]
- Maldonado, S.; Miranda, J.; Olaya, D.; Vásquez, J.; Verbeke, W. Redefining profit metrics for boosting student retention in higher education. Decis. Support Syst. 2021, 143, 113493. [Google Scholar] [CrossRef]
- Nauman, M.; Akhtar, N.; Alhudhaif, A.; Alothaim, A. Guaranteeing correctness of machine learning based decision making at higher educational institutions. IEEE Access 2021, 9, 92864–92880. [Google Scholar] [CrossRef]
- Erikson, E.H. Identity: Youth and Crisis; WW Norton & Company: Manhattan, NY, USA, 1994; pp. 176–200. [Google Scholar]
- Marcia, J.E.; Waterman, A.S.; Matteson, D.R.; Archer, S.L. Ego Identity: A Handbook for Psychosocial Research; Springer Science and Business Media: New York, NY, USA, 2012. [Google Scholar]
- Chrysafiadi, K.; Virvou, M. Student modeling approaches: A literature review for the last decade. Expert Syst. Appl. 2013, 40, 4715–4729. [Google Scholar] [CrossRef]
- Wan, S.; Niu, Z. An e-learning recommendation approach based on the self-organization of learning resource. Knowl.-Based Syst. 2018, 160, 71–87. [Google Scholar] [CrossRef]
- Hsia, T.C.; Shie, A.J.; Chen, L.C. Course planning of extension education to meet market demand by using data mining techniques—An example of Chinkuo technology university in Taiwan. Expert Syst. Appl. 2008, 34, 596–602. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Systematic ensemble model selection approach for educational data mining. Knowl.-Based Syst. 2020, 200, 105992. [Google Scholar] [CrossRef]
- Alam, T.M.; Shaukat, K.; Hameed, I.A.; Khan, W.A.; Sarwar, M.U.; Iqbal, F.; Luo, S. A novel framework for prognostic factors identification of malignant mesothelioma through association rule mining. Biomed. Signal Process. Control 2021, 68, 102726. [Google Scholar] [CrossRef]
- Shuhidan, S.M.; Nori, W.M. Accounting information system and decision useful information fit towards cost conscious strategy in Malaysian higher education institutions. Procedia Econ. Financ. 2015, 31, 885–895. [Google Scholar] [CrossRef]
- Noaman, A.Y.; Ahmed, F.F. ERP systems functionalities in higher education. Procedia Comput. Sci. 2015, 65, 385–395. [Google Scholar] [CrossRef] [Green Version]
- Wen, Z.; Qiang, W.; Ye, Y.; Yoshida, T. A 2020 perspective on “DeRec: A data-driven approach to accurate recommendation with deep learning and weighted loss function”. Electron. Commer. Res. Appl. 2021, 48, 101064. [Google Scholar]
- Anastasios, T.; Cleo, S.; Effie, P.; Olivier, T.; George, M. Institutional research management using an integrated information system. Procedia-Soc. Behav. Sci. 2013, 73, 518–525. [Google Scholar] [CrossRef]
- Wen, Z.; Shaoshan, Y.; Jian, L.; Xin, T.; Yoshida, T. Credit risk prediction of SMEs in supply chain finance by fusing demographic and behavioral data. Transp. Res. Part E, 2022; in press. [Google Scholar]
- Wen, Z.; Wang, Q.; Yoshida, T.; Jian, L. RP-LGMC: Rating prediction based on local and global information with matrix clustering. Comput. Oper. Res. 2021, 129, 105228. [Google Scholar]
- Wen, Z.; Li, X.; Li, J.; Yang, Y. Two-stage Rating Prediction Approach Based on Matrix Clustering on Implicit Information. IEEE Trans. Comput. Soc. Syst. 2020, 7, 517–535. [Google Scholar]
- Shaukat, K.; Nawaz, I.; Aslam, S.; Zaheer, S.; Shaukat, U. Student’s performance in the context of data mining. In Proceedings of the 2016 19th International Multi-Topic Conference (INMIC), Islamabad, Pakistan, 1–8 December 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Shaukat, K.; Nawaz, I.; Aslam, S.; Zaheer, S.; Shaukat, U. Student’s Performance: A Data Mining Perspective; LAP Lambert Academic Publishing: Saarbrücken, Germany, 2017. [Google Scholar]
- Alam, T.M.; Mushtaq, M.; Shaukat, K.; Hameed, I.A.; Sarwar, M.U.; Luo, S. A Novel Method for Performance Measurement of Public Educational Institutions Using Machine Learning Models. Appl. Sci. 2021, 11, 9296. [Google Scholar] [CrossRef]
- Amez, S.; Baert, S. Smartphone use and academic performance: A literature review. Int. J. Educ. Res. 2020, 103, 101618. [Google Scholar] [CrossRef]
- Nieto, Y.; Gacía-Díaz, V.; Montenegro, C.; González, C.C.; Crespo, R.G. Usage of machine learning for strategic decision making at higher educational institutions. IEEE Access 2019, 7, 75007–75017. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 24–27 August 2016; pp. 785–794. [Google Scholar]
- Yang, L.; Zhao, Y.; Niu, X.; Song, Z.; Gao, Q.; Wu, J. Municipal Solid Waste Forecasting in China Based on Machine Learning Models. Front. Energy Res. 2021, 9, 763977. [Google Scholar] [CrossRef]
- Jabeur, S.B.; Mefteh-Wali, S.; Viviani, J.L. Forecasting gold price with the XGBoost algorithm and SHAP interaction values. Ann. Oper. Res. 2021, 1–21. [Google Scholar] [CrossRef]
- Varshney, K.R.; Alemzadeh, H. On the safety of machine learning: Cyber-physical systems, decision sciences, and data products. Big Data 2017, 5, 246–255. [Google Scholar] [CrossRef] [PubMed]
- De Clercq, D.; Wen, Z.; Fei, F.; Caicedo, L.; Yuan, K.; Shang, R. Interpretable machine learning for predicting biomethane production in industrial-scale anaerobic co-digestion. Sci. Total Environ. 2020, 712, 134574. [Google Scholar] [CrossRef] [PubMed]
- Jiang, C.; Wang, Z.; Zhao, H. A prediction-driven mixture cure model and its application in credit scoring. Eur. J. Oper. Res. 2019, 277, 20–31. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems 2017, Los Angeles, CA, USA, 4–7 December 2017; pp. 4768–4777. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Ayoub, J.; Yang, X.J.; Zhou, F. Combat COVID-19 infodemic using explainable natural language processing models. Inf. Processing Manag. 2021, 58, 102569. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Xu, M. A survey on machine learning techniques for cyber security in the last decade. IEEE Access 2020, 8, 222310–222354. [Google Scholar] [CrossRef]
- Shieh, M.D.; Yang, C.C. Multiclass SVM-RFE for product form feature selection. Expert Syst. Appl. 2008, 35, 531–541. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Varadharajan, V.; Hameed, I.A.; Chen, S.; Liu, D.; Li, J. Performance comparison and current challenges of using machine learning techniques in cybersecurity. Energies 2020, 13, 2509. [Google Scholar] [CrossRef]
- Shaukat, K.; Luo, S.; Chen, S.; Liu, D. Cyber threat detection using machine learning techniques: A performance evaluation perspective. In Proceedings of the 2020 International Conference on Cyber Warfare and Security (ICCWS), Norfolk, VA, USA, 1–6 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Kim, T.K. T-test as a parametric statistic. Korean J. Anesthesiol. 2015, 68, 540. [Google Scholar] [CrossRef] [Green Version]
- Nie, M.; Xiong, Z.; Zhong, R.; Deng, W.; Yang, G. Career Choice Prediction Based on Campus Big Data—Mining the Potential Behavior of College Students. Appl. Sci. 2020, 10, 2841. [Google Scholar] [CrossRef] [Green Version]







| Classification | Description | Symbol | |
|---|---|---|---|
| Input | Essential Data | Gender | X1 |
| National | X2 | ||
| Political Landscape | X3 | ||
| Examinee Category | X4 | ||
| Score of college entrance examination | X5 | ||
| Note | X6 | ||
| Category of students with difficulty | X7 | ||
| Honors | Scholarship awarded by university | X8 | |
| Scholarship awarded by provincial | X9 | ||
| Total amount of money | X10 | ||
| GPA Data | GPA of First Term | X11 | |
| GPA of Second Term | X12 | ||
| GPA of Third Term | X13 | ||
| GPA of Fourth Term | X14 | ||
| GPA of Fifth Term | X15 | ||
| GPA of Sixth Term | X16 | ||
| GPA of Seventh Term | X17 | ||
| GPA of Eighth Term | X18 | ||
| Overall GPA | X19 | ||
| Output | Destination | Final Employment | Y |
| Classification | Content | Alphabetize | Population |
|---|---|---|---|
| Further Study in China | Master’s | Y1 | 4264 |
| Doctorate | |||
| Preparing for the Entrance Exam | |||
| Second Bachelor’s Degree | |||
| Employment | Sign Labor Contract | Y2 | 4372 |
| Sign an Employment Agreement | |||
| Certificate of Employment | |||
| Self-employed | |||
| Freelance Work | |||
| Joined the Army | |||
| Volunteer in the West | |||
| Difficulties in Employment | Waiting for Employment in Beijing | Y3 | 617 |
| Return to Hometown for Employment | |||
| Apply for Non-Employment | |||
| Delay | |||
| Study Abroad | Has Gone Abroad | Y4 | 1038 |
| Plans to Go Abroad |
| Hyperparameters | Value | Meaning |
|---|---|---|
| n_estimators | 331 | Number of trees |
| subsample | 0.4494 | Percentage of random sample |
| max_depth | 10 | Maximum depth of each tree |
| colsample_bytree | 0.5294 | Random sampling characteristics |
| gamma | 3 | Penalty term for complexity |
| learning_rate | 0.1533 | Learning rate |
| Model | p | R | F1 | Performance Comparison (%) |
|---|---|---|---|---|
| Decision Tree | 0.803 | 0.812 | 0.807 | −7.454% ** (0.035) |
| SVM | 0.791 | 0.788 | 0.789 | −9.518% * (0.072) |
| Random Forest | 0.847 | 0.824 | 0.835 | −4.243% *** (0.001) |
| Light GBM | 0.889 | 0.846 | 0.866 | −0.689% (0.301) |
| XGBoost | 0.891 | 0.854 | 0.872 | / |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Yang, L.; Wu, J.; Song, Z.; Shi, L. Mining Campus Big Data: Prediction of Career Choice Using Interpretable Machine Learning Method. Mathematics 2022, 10, 1289. https://doi.org/10.3390/math10081289
Wang Y, Yang L, Wu J, Song Z, Shi L. Mining Campus Big Data: Prediction of Career Choice Using Interpretable Machine Learning Method. Mathematics. 2022; 10(8):1289. https://doi.org/10.3390/math10081289
Chicago/Turabian StyleWang, Yuan, Liping Yang, Jun Wu, Zisheng Song, and Li Shi. 2022. "Mining Campus Big Data: Prediction of Career Choice Using Interpretable Machine Learning Method" Mathematics 10, no. 8: 1289. https://doi.org/10.3390/math10081289