
Predicting the 305-Day Milk Yield of Holstein-Friesian Cows Depending on the Conformation Traits and Farm Using Simplified Selective Ensembles




Abstract
:1. Introduction
2. Materials and Methods
2.1. Description of the Analyzed Data
2.2. Modeling Methods
2.2.1. Principal Component Analysis and Exploratory Factor Analysis
2.2.2. CART Ensemble and Bagging (EBag)
2.2.3. Adaptive Resampling and Combining Algorithm (Arcing)
2.2.4. Proposed Simplified Selective Ensemble Algorithm
- Step 1: Calculation of index of agreement (IA), [31], for a selected initial EBag model, , with component trees;
- Step 2: Cycle with the application of a pruning criterion to live-out the j-th component tree for … and calculation of reduced tree ;
- Step 3: Calculation of IA for of all obtained reduced trees, . If , then the tree, , is considered “negative” and subject to possible removal from the ensemble. If the number of negative trees is , we denote their set with , where is the negative tree.
- Step 4: Building simplified selective models by removing cumulative sums from negative trees using the expression:
| Algorithm 1: Simplified selective ensemble |
| Input: dataset E, Tj, tn // E is an ensemble model of weak learners Tj, j = 1,2, …,tn. E is an averaged sum of Tj. Output: SSE, sn // SSE is a vector of indices of the resulting simplified selective ensembles, sn is the number of simplified selective models in SSE. k ← 0; // k is the number of the negative trees (learners). sind ← Ø; // sind is a list or array with the indices of negative trees or learners. dE ← IA(E); // Value of the Index of agreement (IA) of E ([31], see also Equation (5). j ← 1; While j <= tn do  end; s ← k; sn ← tn-s; If [ s = 0 then Break [Algorithm 1]; ]; // in this case, there are not any simplified selective models. j ← 1; SSE ← Ø; While [ j <= (tn-s) do  |
2.2.5. Methodology
- Transformation of 12 independent variables for the external traits using the PCA method and factor analysis and obtaining 11 PCs (factor variables), denoted as PC1, PC2, …, PC11;
- Random splitting of the sample for Milk305 into learning and test datasets at a ratio of 75%:25%; the learning sample is denoted by the variable Milk_miss40, where 25% (40 cases) of the values for milk yield are considered as missing;
- Building and examination of rotation EBag, simplified selective EBag, and rotation ARC regression models with predictors PC1, …, PC11, and Farm to predict Milk_miss40;
- Verification of the condition for diversity and selection of three base models using Wilcoxon signed-rank test (WSRT);
- Determination of the relative importance of predictors in the base models;
- Assessment of models against the initial full-sample Milk305.
- Combination of the selected base models using weights and assessment of the resulting stacked model.
- Assessment of model performance for the 25% holdout test sample.

2.2.6. Evaluation Measures
3. Results and Discussion
3.1. Data Preprocessing
3.2. PCA Results
3.3. Building and Evaluation of Base Models
- (C1)
- different learning datasets for each tree and ensemble derived from the algorithms;
- (C2)
- different methods and hyperparameters to build the ensembles;
- (C3)
- different number of trees in the ensemble models;
- (C4)
- different types of testing or validation.
3.3.1. CART Ensembles and Bagging and Simplified Selective Bagged Ensembles
3.3.2. Arcing and Simplified Selective Arcing Models
3.3.3. Diversity of the Selected Base Models and Their Hyperparameters
- Group A: EB15, EB40, and AR10;
- Group B: SSEB11, SSEB25, and SSAR9.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Model | ||
|---|---|---|---|
| EB15, SSEB11 | EB40, SSEB25 | AR10, SSAR9 | |
| Number of trees in ensemble | 15, 11 | 40, 25 | 10, 9 |
| Minimum cases in parent node | 8 | 8 | 10 |
| Minimum cases in child node | 4 | 4 | 1 |
| Independent variables | Farm, PC1, PC2, …, PC11 | Farm, PC1, PC2, PC4, PC5, PC7, …, PC11 | Farm, PC1, …, PC6, PC9, PC10, PC11 |
| Type of the k-fold cross-validation | 10-fold | 10-fold | 20-fold |
3.3.4. Evaluation Statistics of the Selected Base Models
3.3.5. Relative Importance of the Factors Determining Milk305 Quantity
3.4. Building and Evaluation of the Linear Hybrid Models
3.4.1. Results for Hybrid Models
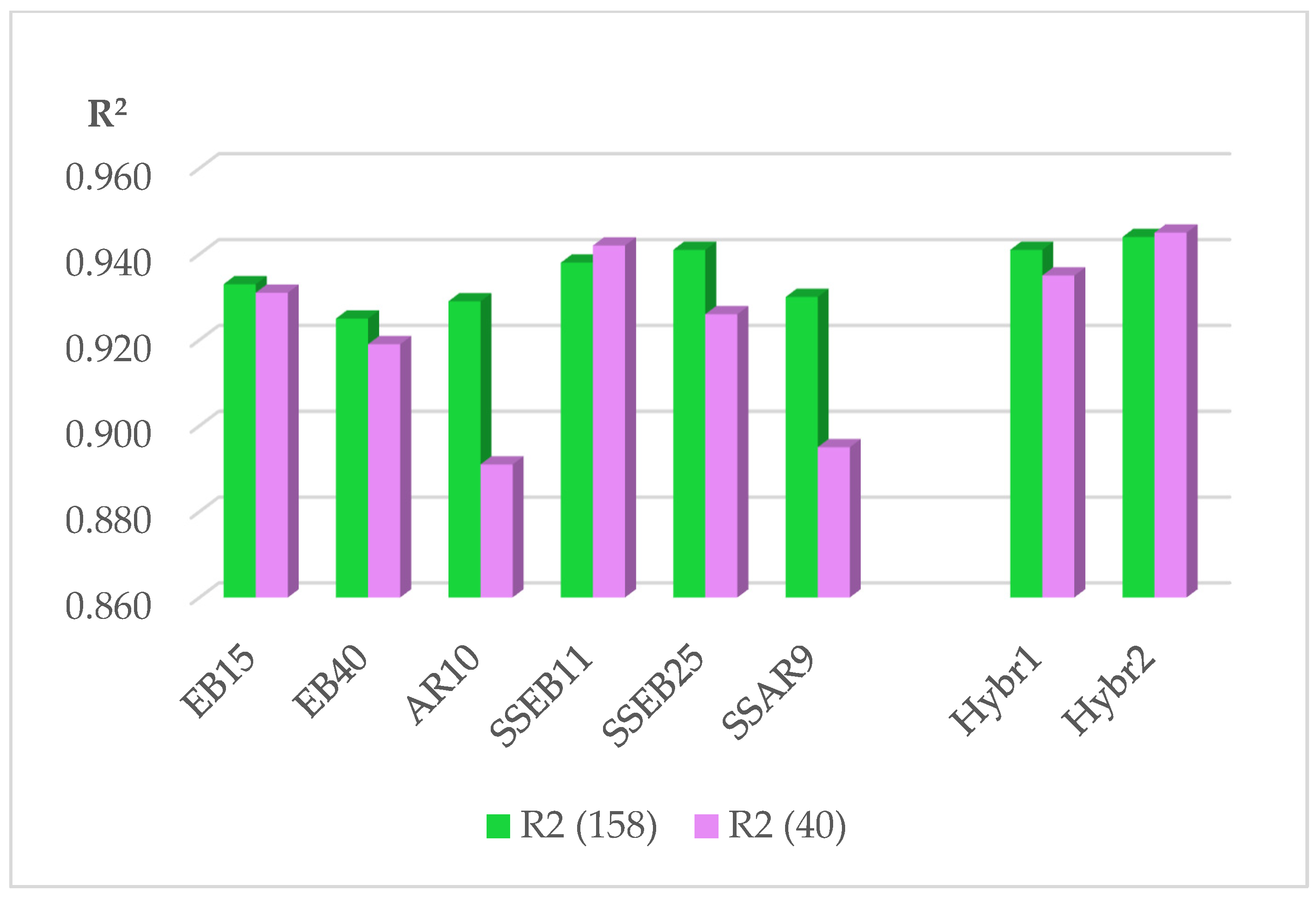
3.4.2. Comparison of Statistics of All Models
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Conflicts of Interest
References
- Berry, D.P.; Buckley, F.; Dillon, P.; Evans, R.D.; Veerkamp, R.F. Genetic Relationships among Linear Type Traits, Milk Yield, Bodyweight, Fertility and Somatic Cell Count in Primiparous Dairy Cows. Irish J. Agric. Food Res. 2004, 43, 161–176. Available online: https://www.jstor.org/stable/25562515 (accessed on 22 February 2022).
- Almeida, T.P.; Kern, E.L.; Daltro, D.S.; Neto, J.B.; McManus, C.; Neto, A.T.; Cobuci, J.A. Genetic associations between reproductive and linear-type traits of Holstein cows in Brazil. Rev. Bras. Zootecn. 2017, 46, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Schneider, M.P.; Durr, J.W.; Cue, R.I.; Monardes, H.G. Impact of type traits on functional herd life of Quebec Holsteins assessed by survival analysis. J. Dairy Sci. 2003, 86, 4083–4089. [Google Scholar] [CrossRef]
- Cockburn, M. Review: Application and prospective discussion of machine learning for the management of dairy farms. Animals 2020, 10, 1690. [Google Scholar] [CrossRef]
- Dallago, G.M.; Figueiredo, D.M.D.; Andrade, P.C.D.R.; Santos, R.A.D.; Lacroix, R.; Santschi, D.E.; Lefebvre, D.M. Predicting first test day milk yield of dairy heifers. Comput. Electron. Agric. 2019, 166, 105032. [Google Scholar] [CrossRef]
- Murphy, M.D.; O’Mahony, M.J.; Shalloo, L.; French, P.; Upton, J. Comparison of modelling techniques for milk-production forecasting. J. Dairy Sci. 2014, 97, 3352–3363. [Google Scholar] [CrossRef] [Green Version]
- Cak, B.; Keskin, S.; Yilmaz, O. Regression tree analysis for determining of affecting factors to lactation milk yield in brown Swiss cattle. Asian J. Anim. Vet. Adv. 2013, 8, 677–682. [Google Scholar] [CrossRef]
- Celik, S. Comparing predictive performances of tree-based data mining algorithms and MARS algorithm in the prediction of live body weight from body traits in Pakistan goats. Pak. J. Zool. 2019, 51, 1447–1456. [Google Scholar] [CrossRef]
- Eyduran, E.; Yilmaz, I.; Tariq, M.M.; Kaygisiz, A. Estimation of 305-D Milk Yield Using Regression Tree Method in Brown Swiss Cattle. J. Anim. Plant Sci. 2013, 23, 731–735. Available online: https://thejaps.org.pk/docs/v-23-3/08.pdf (accessed on 27 February 2022).
- Fenlon, C.; Dunnion, J.; O’Grady, L.; Doherty, M.; Shalloo, L.; Butler, S. Regression Techniques for Modelling Conception in Seasonally Calving Dairy Vows. In Proceedings of the 16th IEEE International Conference on Data Mining Workshops ICDMW, Barcelona, Spain, 12–15 December 2016; pp. 1191–1196. [Google Scholar] [CrossRef]
- Van der Heide, E.M.M.; Kamphuis, C.; Veerkamp, R.F.; Athanasiadis, I.N.; Azzopardi, G.; van Pelt, M.L.; Ducro, B.J. Improving predictive performance on survival in dairy cattle using an ensemble learning approach. Comput. Electron. Agric. 2020, 177, 105675. [Google Scholar] [CrossRef]
- Weber, V.A.M.; Weber, F.D.L.; Oliveira, A.D.S.; Astolfi, G.; Menezes, G.V.; Porto, J.V.D.A.; Rezende, F.P.C.; de Moraes, P.H.; Matsubara, E.T.; Mateus, R.G.; et al. Cattle weight estimation using active contour models and regression trees Bagging. Comput. Electron. Agric. 2020, 179, 105804. [Google Scholar] [CrossRef]
- Grzesiak, W.; Błaszczyk, P.; Lacroix, R. Methods of predicting milk yield in dairy cows—Predictive capabilities of Wood’s lactation curve and artificial neural networks (ANNs). Comput. Electron. Agric. 2006, 54, 69–83. [Google Scholar] [CrossRef]
- Bhosale, M.D.; Singh, T.P. Comparative study of Feed-Forward Neuro-Computing with Multiple Linear Regression Model for Milk Yield Prediction in Dairy Cattle. Cu. Sci. India 2015, 108, 2257–2261. Available online: https://www.jstor.org/stable/24905663 (accessed on 22 February 2022).
- Mathapo, M.C.; Tyasi, T.L. Prediction of body weight of yearling boer goats from morphometric traits using classification and regression tree. Am. J. Anim. Vet. Sci. 2021, 16, 130–135. [Google Scholar] [CrossRef]
- Yordanova, A.P.; Kulina, H.N. Random forest models of 305-days milk yield for Holstein Cows in Bulgaria. AIP Conf. Proc. 2020, 2302, 060020. [Google Scholar] [CrossRef]
- Balhara, S.; Singh, R.P.; Ruhil, A.P. Data mining and decision support systems for efficient dairy production. Vet. World 2021, 14, 1258–1262. [Google Scholar] [CrossRef]
- Tamon, C.; Xiang, J. On the boosting pruning problem. In Proceedings of the 11th European Conference on Machine Learning, ECML 2000, Barcelona, Spain, 31 May–2 June 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 404–412. [Google Scholar]
- Zhou, Z.-H.; Wu, J.; Tang, W. Ensembling neural networks: Many could be better than all. Artif. Intel. 2002, 137, 239–263. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.-H.; Tang, W. Selective ensemble of decision trees. In Proceedings of the International Workshop on Rough Sets, Fuzzy Sets, Data Mining, and Granular-Soft Computing, RSFDGrC 2003, Lecture Notes in Computer Science, Chongqing, China, 26–29 May 2003; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2639, pp. 476–483. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Kuncheva, L. Combining Pattern Classifiers: Methods and Algorithms, 2nd ed.; Wiley and Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Mendes-Moreira, J.; Soares, C.; Jorge, A.M.; De Sousa, J.F. Ensemble approaches for regression: A survey. ACM Comput. Surv. 2012, 45, 10. [Google Scholar] [CrossRef]
- Margineantu, D.D.; Dietterich, T.G. Pruning adaptive boosting. In Proceedings of the 14th International Conference on Machine Learning ICML’97, San Francisco, CA, USA, 8–12 July 1997; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; pp. 211–218. [Google Scholar]
- Zhu, X.; Ni, Z.; Cheng, M.; Jin, F.; Li, J.; Weckman, G. Selective ensemble based on extreme learning machine and improved discrete artificial fish swarm algorithm for haze forecast. Appl. Intell. 2017, 48, 1757–1775. [Google Scholar] [CrossRef]
- Wei, L.; Wan, S.; Guo, J.; Wong, K.K. A novel hierarchical selective ensemble classifier with bioinformatics application. Artif. Intel. Med. 2017, 83, 82–90. [Google Scholar] [CrossRef]
- ICAR. International Agreement of Recording Practices. Conformation Recording of Dairy Cattle. 2012. Available online: https://aberdeenangus.ro/wp-content/uploads/2014/03/ICAR.pdf (accessed on 22 February 2022).
- Marinov, I. Linear Type Traits and Their Relationship with Productive, Reproductive and Health Traits in Black-and-White Cows. Ph.D. Thesis, Trakia University, Stara Zagora, Bulgaria, 2015. (In Bulgarian). [Google Scholar]
- Penev, T.; Marinov, I.; Gergovska, Z.; Mitev, J.; Miteva, T.; Dimov, D.; Binev, R. Linear Type Traits for Feet and Legs, Their Relation to Health Traits Connected with Them, and with Productive and Reproductive Traits in Dairy Cows. Bulg. J. Agric. Sci. 2017, 23, 467–475. Available online: https://www.agrojournal.org/23/03-17.pdf (accessed on 22 February 2022).
- Fuerst-Walt, B.; Sölkner, J.; Essl, A.; Hoeschele, I.; Fuerst, C. Non-linearity in the genetic relationship between milk yield and type traits in Holstein cattle. Livest. Prod. Sci. 1998, 57, 41–47. [Google Scholar] [CrossRef]
- Willmott, C. On the validation of models. Phys. Geogr. 1981, 2, 184–194. [Google Scholar] [CrossRef]
- Ren, Y.; Zhang, L.; Suganthan, P.N. Ensemble classification and regression-recent developments, applications and future directions. IEEE Comput. Intell. Mag. 2016, 11, 41–53. [Google Scholar] [CrossRef]
- Izenman, A. Modern Multivariate Statistical Techniques; Springer: New York, NY, USA, 2008. [Google Scholar]
- Török, E.; Komlósi, I.; Béri, B.; Füller, I.; Vágó, B.; Posta, J. Principal component analysis of conformation traits in Hungarian Simmental cows. Czech J. Anim. Sci. 2021, 66, 39–45. [Google Scholar] [CrossRef]
- Mello, R.R.C.; Sinedino, L.D.-P.; Ferreira, J.E.; De Sousa, S.L.G.; De Mello, M.R.B. Principal component and cluster analyses of production and fertility traits in Red Sindhi dairy cattle breed in Brazil. Trop. Anim. Health Prod. 2020, 52, 273–281. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadsworth Advanced Books and Software: Belmont, CA, USA, 1984. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- SPM—Salford Predictive Modeler. 2021. Available online: https://www.minitab.com/enus/products/spm (accessed on 22 February 2022).
- Breiman, L. Arcing Classifiers. Ann. Stat. 1998, 26, 801–824. Available online: https://www.jstor.org/stable/120055 (accessed on 22 February 2022).
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comp. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Gocheva-Ilieva, S.; Ivanov, A.; Stoimenova-Minova, M. Prediction of daily mean PM10 concentrations using random forest, CART Ensemble and Bagging Stacked by MARS. Sustainability 2022, 14, 798. [Google Scholar] [CrossRef]
- Wolfram Mathematica. Available online: https://www.wolfram.com/mathematica (accessed on 22 February 2022).
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–260. [Google Scholar] [CrossRef]
- Flores, B.E. The utilization of the wilcoxon test to compare forecasting methods: A note. Int. J. Forecast. 1989, 5, 529–535. [Google Scholar] [CrossRef]
- Breiman, L. Stacked regressions. Mach. Learn. 1996, 24, 49–64. [Google Scholar] [CrossRef] [Green Version]






| Variable | Description | Type | Measure |
|---|---|---|---|
| Milk305 | 305-day milk yield | Scale | kg |
| Stature | Stature | Ordinal | 1, 2, …, 9; Short—Tall |
| ChestW | Chest width | Ordinal | 1, 2, …, 9; Narrow—Wide |
| RumpW | Rump width | Ordinal | 1, 2, …, 9; Narrow—Wide |
| RLRV | Rear legs (rear view) | Ordinal | 1, 2, …, 9; Hock in-Parallel |
| RLSV | Rear leg set (side view) | Ordinal | 1, 2, …, 5 (Transformed); Strait/Sickled—Ideal |
| HockD | Hock development | Ordinal | 1, 2, …, 9; Filled—Dry |
| Bone | Bone structure | Ordinal | 1, 2, …, 9; Coarse—Fine and thin |
| FootA | Foot angle | Ordinal | 1, 2, …, 5 (Transformed); Low/Steep—Ideal |
| FootD | Foot depth | Ordinal | 1, 2, …, 9; Short—Tall |
| UdderW | Udder width | Ordinal | 1, 2, …, 9; Narrow—Wide |
| Locom | Locomotion | Ordinal | 1, 2, …, 9; Severe abduction— No abduction |
| Lameness | Lameness | Ordinal | 1, 2, 3; Walks unevenly—Very lame |
| Farm | Farm number | Nominal | 1, 2, 3, 4 |
| Notation | Description | Type |
|---|---|---|
| ARC | Arcing | method |
| CART | Classification and regression trees | method |
| CV | Cross-validation | out-of-sample testing |
| EBag | CART ensembles and bagging | method |
| PCA | Principal component analysis | method |
| IA, d | Index of agreement [31] | statistic |
| WSRT | Wilcoxon signed rank test | statistical test |
| RT | Reduced tree | list of trees |
| AR9, AR10 | Arcing model (predicted values) | variable |
| EB, EB15, EB40 | EBag model (predicted values) | variable |
| Hybr1, Hybr2 | Stacked linear model (predicted values) | variable |
| PC1, PC2, … | Principal component, factor variable | variable |
| SSAR9 | Simplified selective ARC model (predicted values) | variable |
| SSEB, SSEB11, SSEB25 | Simplified selective EBag model (predicted values) | variable |
| Variable | Mean | 5% Lower Bound of Mean | 5% Upper Bound of Mean | Median | Std. Dev. | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
| Milk305, kg | 6812.16 | 6451.67 | 7172.66 | 6784.25 | 2294.12 | 0.282 | −0.866 |
| Milk_miss40, kg | 6789.32 | 6359.29 | 7226.36 | 6041.00 | 2397.14 | 0.310 | −0.896 |
| Milk_40, kg | 6879.54 | 6244.59 | 7514.49 | 6743.19 | 1985.37 | 0.182 | −0.960 |
| Stature | 4.68 | 4.39 | 4.96 | 5.00 | 1.83 | −0.228 | −0.558 |
| ChestW | 6.51 | 6.25 | 6.77 | 7.00 | 1.65 | −0.358 | −0.569 |
| RumpW | 6.09 | 5.91 | 6.28 | 6.00 | 1.18 | 0.241 | −0.687 |
| RLRV | 4.91 | 4.68 | 5.14 | 5.00 | 1.45 | 0.054 | 0.291 |
| RLSV | 3.95 | 3.79 | 4.11 | 4.00 | 1.01 | −0.577 | −0.631 |
| HockD | 5.29 | 5.06 | 5.52 | 5.00 | 1.48 | 0.038 | −0.170 |
| Bone | 6.13 | 5.89 | 6.37 | 6.00 | 1.53 | −0.260 | −0.477 |
| FootA | 4.51 | 4.42 | 4.61 | 5.00 | 0.59 | −0.786 | −0.349 |
| FootD | 6.42 | 6.24 | 6.59 | 7.00 | 1.10 | −0.310 | −1.434 |
| UdderW | 5.72 | 5.42 | 6.02 | 6.00 | 1.92 | −0.368 | −0.484 |
| Locom | 5.32 | 5.11 | 5.53 | 5.00 | 1.34 | −0.092 | −0.530 |
| Lameness | 1.65 | 1.55 | 1.76 | 2.00 | 0.67 | 0.535 | −0.713 |
| Initial Variable | Principal Components (Factor Variables) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PC1 | PC2 | PC3 | PC4 | PC5 | PC6 | PC7 | PC8 | PC9 | PC10 | PC11 | |
| Locom | 0.978 | −0.009 | −0.001 | 0.007 | 0.000 | 0.016 | 0.028 | 0.011 | 0.025 | 0.002 | −0.032 |
| Lameness | −0.976 | −0.009 | −0.001 | 0.007 | 0.000 | 0.016 | 0.028 | 0.011 | 0.025 | 0.002 | −0.032 |
| RumpW | 0.000 | 0.998 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 | 0.000 | 0.001 | 0.002 |
| ChestW | 0.000 | 0.000 | 0.998 | 0.001 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.001 | 0.001 |
| UdderW | 0.000 | 0.000 | 0.001 | 0.995 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.002 | 0.006 |
| RLRV | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| FootD | 0.000 | .001 | 0.000 | 0.000 | 0.000 | 0.999 | −0.001 | 0.000 | −0.001 | 0.001 | 0.001 |
| RLSV | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | −0.001 | 1.000 | −0.001 | −0.001 | 0.000 | 0.002 |
| FootA | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | −0.001 | 1.000 | −0.001 | 0.000 | 0.001 |
| HockD | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | −0.001 | −0.001 | −0.001 | 1.000 | 0.000 | 0.002 |
| Bone | 0.000 | 0.002 | 0.002 | 0.002 | 0.001 | 0.001 | 0.000 | 0.000 | 0.000 | 0.995 | 0.003 |
| Stature | 0.000 | 0.006 | 0.003 | 0.011 | 0.000 | 0.001 | 0.002 | 0.001 | 0.002 | 0.004 | 0.986 |
| Statistics | Models | |||||
|---|---|---|---|---|---|---|
| EB15-EB40 | EB15-AR10 | AR10-EB40 | SSEB11-SSEB25 | SSEB11- SSAR9 | SSEB25- SSAR9 | |
| Z | −3.440 b | −3.475 b | −2.006 b | −2.360 b | −3.480 b | −2.332 b |
| Asymp. Sig. (2-tailed) | 0.001 | 0.001 | 0.045 | 0.018 | 0.001 | 0.020 |
| Measure | Base Model Group A | Base Model Group B | Linear Combinations | |||||
|---|---|---|---|---|---|---|---|---|
| EB15 | EB40 | AR10 | SSEB11 | SSEB25 | SSAR9 | Hybr1 | Hybr2 | |
| Mean, 158 | 6739.11 | 6797.17 | 6872.41 | 6747.79 | 6790.98 | 6871.63 | 6787.81 | 6778.75 |
| Mean, 118 | 6755.05 | 6810.56 | 6836.70 | 6758.16 | 6811.57 | 6844.17 | 6787.88 | 6779.66 |
| Mean, 40 | 6692.06 | 6757.64 | 6977.76 | 6717.18 | 6730.25 | 6952.66 | 6787.61 | 6776.05 |
| Std. Dev., 158 | 2086.27 | 2119.82 | 2029.76 | 2118.99 | 2143.82 | 2081.68 | 2062.66 | 2100.91 |
| Std. Dev., 118 | 2163.54 | 2187.59 | 2077.31 | 2191.88 | 2225.50 | 2131.27 | 2132.25 | 2169.99 |
| Std. Dev., 40 | 1864.37 | 1931.58 | 1903.79 | 1913.43 | 1907.36 | 1951.61 | 1867.60 | 1908.38 |
| 0.933 | 0.925 | 0.929 | 0.938 | 0.941 | 0.930 | 0.941 | 0.944 | |
| 0.934 | 0.928 | 0.941 | 0.939 | 0.947 | 0.940 | 0.943 | 0.945 | |
| 0.931 | 0.919 | 0.891 | 0.942 | 0.926 | 0.895 | 0.935 | 0.945 | |
| RMSE, 158 | 611.791 | 632.277 | 632.855 | 580.404 | 560.473 | 620.607 | 579.461 | 556.051 |
| RMSE, 118 | 631.401 | 651.280 | 632.878 | 605.778 | 562.188 | 612.666 | 601.317 | 581.328 |
| RMSE, 40 | 549.885 | 572.555 | 656.169 | 498.077 | 555.382 | 643.463 | 509.555 | 473.690 |
| MAPE, 158 (%) | 6.63 | 6.94 | 8.36 | 6.40 | 6.51 | 7.68 | 6.45 | 6.23 |
| MAPE, 118 (%) | 6.87 | 7.03 | 8.59 | 6.65 | 6.42 | 7.66 | 6.75 | 6.51 |
| MAPE, 40 (%) | 5.93 | 6.68 | 7.68 | 5.65 | 6.76 | 7.33 | 5.55 | 5.44 |
| d, 158 | 0.9801 | 9.9790 | 0.9777 | 0.9824 | 0.9837 | 0.9795 | 0.9820 | 0.9837 |
| d, 118 | 0.9804 | 0.9794 | 0.9796 | 0.9822 | 0.9849 | 0.9813 | 0.9820 | 0.9835 |
| d, 40 | 0.9788 | 0.9777 | 0.9703 | 0.9831 | 0.9788 | 0.9722 | 0.9818 | 0.9847 |
| Predictor Variable | Model | |||||
|---|---|---|---|---|---|---|
| EB15 | SSEB11 | EB40 | SSEB25 | AR10 | SSAR9 | |
| Farm | 100.0 | 100.0 | 100.0 | 100.0 | 98.1 | 100.0 |
| PC4 (UdderW) | 67.6 | 67.7 | 64.5 | 66.3 | 64.2 | 60.2 |
| PC3 (ChestW) | 44.8 | 46.0 | - | - | 57.7 | 57.6 |
| PC11 (Stature) | 34.7 | 35.5 | 30.6 | 30.8 | 22.1 | 18.7 |
| PC10 (Bone) | 22.8 | 22.6 | 23.4 | 26.4 | 19.0 | 20.2 |
| PC1 (Locom & Lameness) | 13.5 | 14.5 | 17.1 | 19.8 | 28.5 | 30.0 |
| PC9 (HockD) | 6.6 | 6.7 | 12.4 | 14.4 | 36.2 | 38.0 |
| PC5 (RLRV) | 12.8 | 12.1 | 15.5 | 15.7 | 19.5 | 16.6 |
| PC6 (FootD) | 10.7 | 11.5 | - | - | 26.3 | 25.1 |
| PC2 (RumpW) | 9.7 | 10.3 | 11.0 | 11.9 | 30.4 | 30.8 |
| PC8 (FootA) | 7.8 | 8.0 | 12.3 | 14.0 | - | - |
| PC7 (RLSV) | 6.6 | 8.2 | 10.5 | 11.1 | - | - |
| Error, Improvement | Base Model Group A | Base Model Group B | Linear Combinations | |||||
|---|---|---|---|---|---|---|---|---|
| EB15 | EB40 | AR10 | SSEB11 | SSEB25 | SSAR9 | Hybr1 | Hybr2 | |
| RMSE, 40 | 549.885 | 572.555 | 656.169 | 498.077 | 555.382 | 643.463 | 509.555 | 473.690 |
| Improvement by Hybr2 | 7.3% | 11.0% | 22.3% | 4.9% | 14.7% | 26.4% | 7.0% | - |
| MSE, 40 | 302,373.5 | 327,819.2 | 430,557.8 | 248,080.7 | 308,449.2 | 414,044.6 | 259,646.3 | 224,382.22 |
| Improvement by Hybr2 | 14.1% | 20.8% | 39.7% | 9.6% | 27.3% | 45.8% | 13.6% | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gocheva-Ilieva, S.; Yordanova, A.; Kulina, H. Predicting the 305-Day Milk Yield of Holstein-Friesian Cows Depending on the Conformation Traits and Farm Using Simplified Selective Ensembles. Mathematics 2022, 10, 1254. https://doi.org/10.3390/math10081254
Gocheva-Ilieva S, Yordanova A, Kulina H. Predicting the 305-Day Milk Yield of Holstein-Friesian Cows Depending on the Conformation Traits and Farm Using Simplified Selective Ensembles. Mathematics. 2022; 10(8):1254. https://doi.org/10.3390/math10081254
Chicago/Turabian StyleGocheva-Ilieva, Snezhana, Antoaneta Yordanova, and Hristina Kulina. 2022. "Predicting the 305-Day Milk Yield of Holstein-Friesian Cows Depending on the Conformation Traits and Farm Using Simplified Selective Ensembles" Mathematics 10, no. 8: 1254. https://doi.org/10.3390/math10081254