
Enhance Domain-Invariant Transferability of Adversarial Examples via Distance Metric Attack



Abstract
:1. Introduction
- We proposed a novel adversarial attack method, termed as distance metric attack (DMA), which enhances the domain-invariant transferability of the adversarial examples.
- We evaluate the robustness of the latent layers of different models by maximising the feature distance and find that the models with similar structures have consistent robustness at the same layer.
- Empirical results show that the attack success rate of the adversarial examples crafted by DMA is significantly improved on the multiple tasks, including image classification, object detection, and semantic segmentation.
2. Related Work
2.1. Adversarial Attacks on Image Classification
2.2. Adversarial Attacks on Other Vision Tasks
2.3. Adversarial Defences
2.4. Adversarial Attacks on Cross-Task
3. Methodology
3.1. Notation
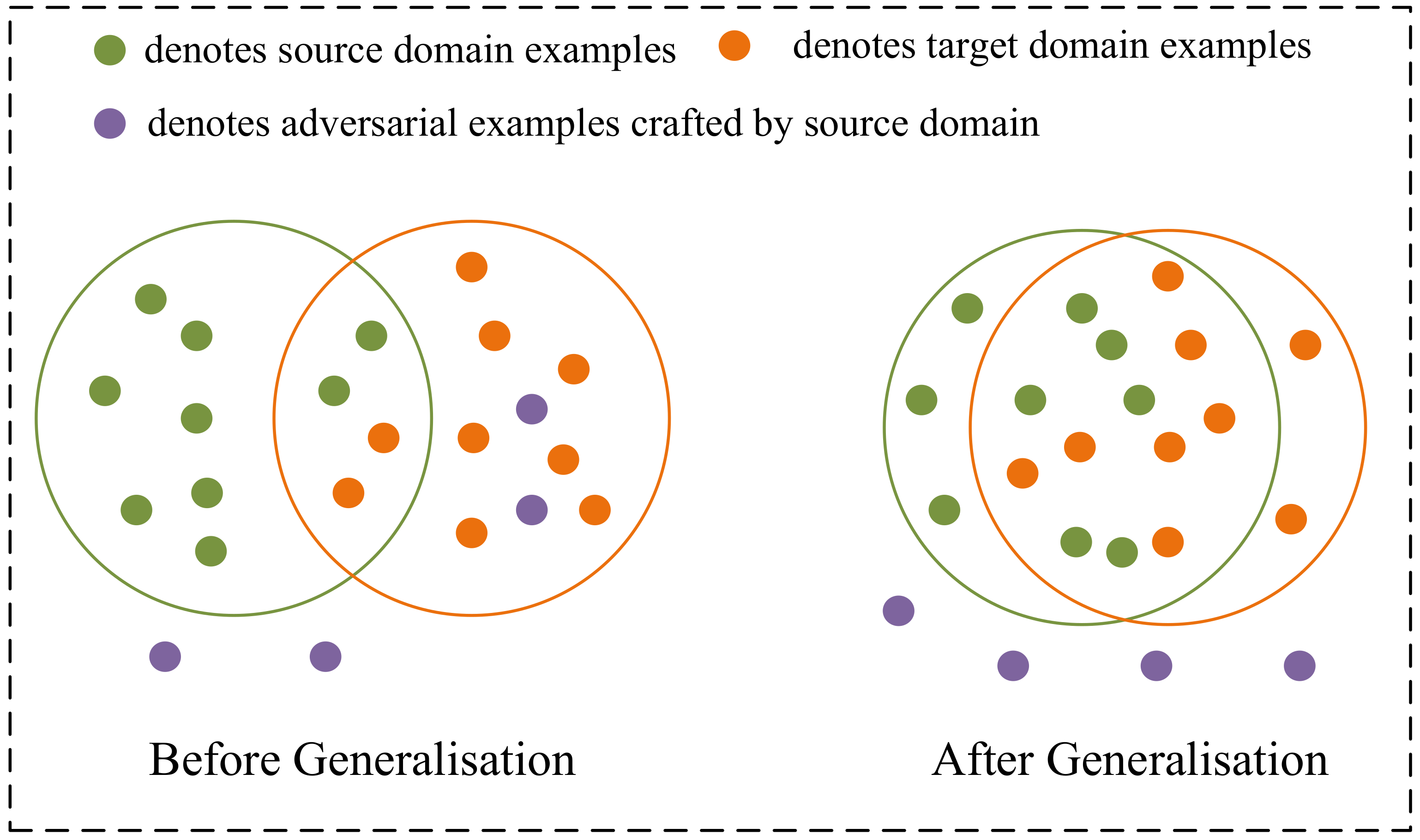
3.2. Motivation
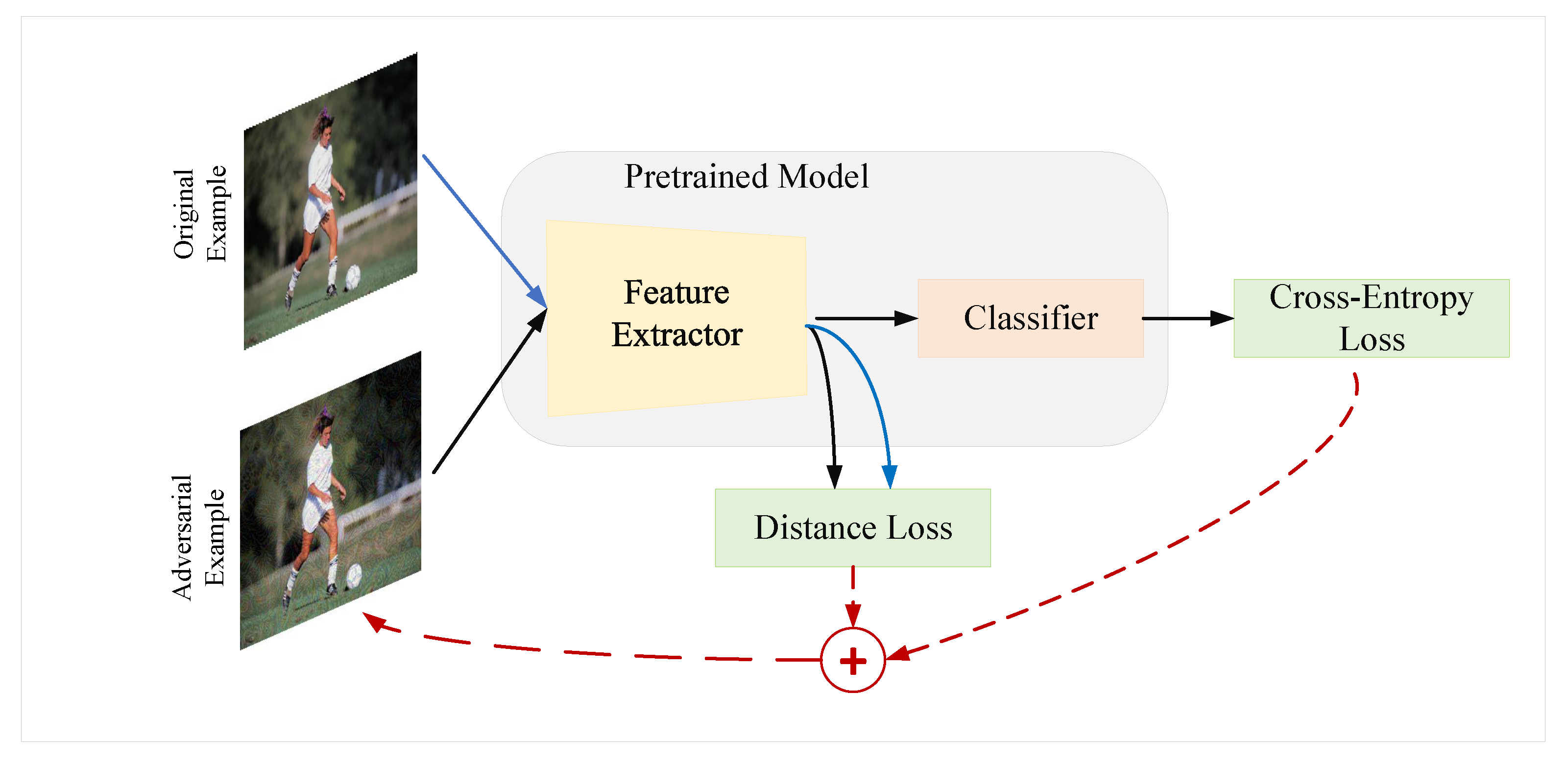
3.3. Distance Metric Attack
| Algorithm 1 Distance Metric Attack |
| Input: A deep model f and the loss function ; the latent layer of the model f; a benign example x and its ground-truth label y. |
| Input: The maximum perturbation , the number of iteration T, the decay factor , and the distance weight . |
| Output: An adversarial example . |
| 1: , , ; |
| 2: for do |
| 3: Get the latent feature of the model by inputting x; Obtain the latent feature of the model by inputting ; |
| 4: Calculate the distance between the latent features |
| 5: Get the softmax cross-entropy loss . |
| 6: Calculate the loss . |
| 7: Calculate the gradient . |
| 8: Update by . |
| 9: Update by |
| 10: end for |
| 11: return ; |
4. Experiments
4.1. Setup
4.1.1. Datasets
4.1.2. Models
4.1.3. Hyper-Parameters
4.2. Ablation Studies
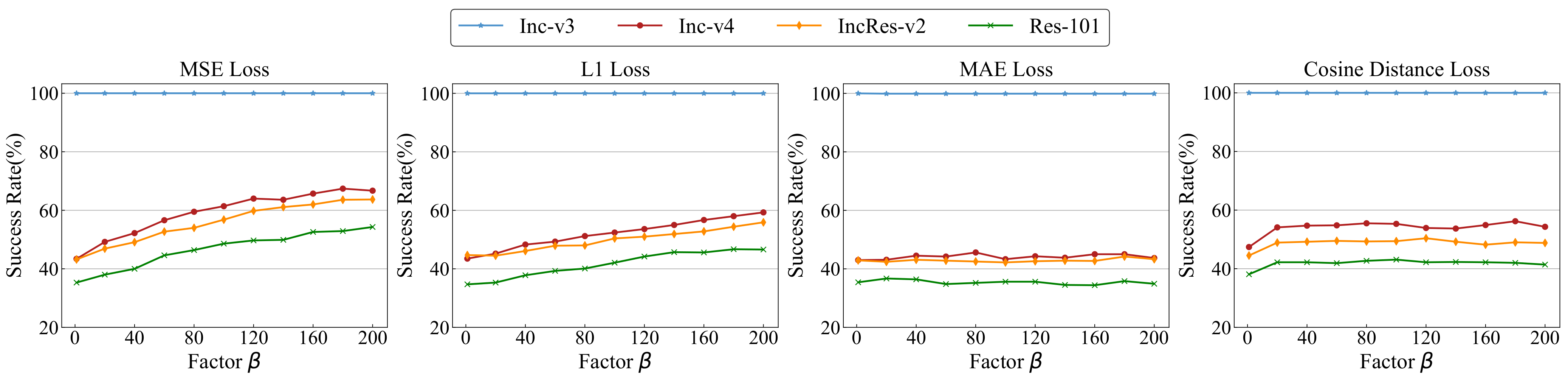
4.2.1. The Effect of the Distance Loss and the Factor
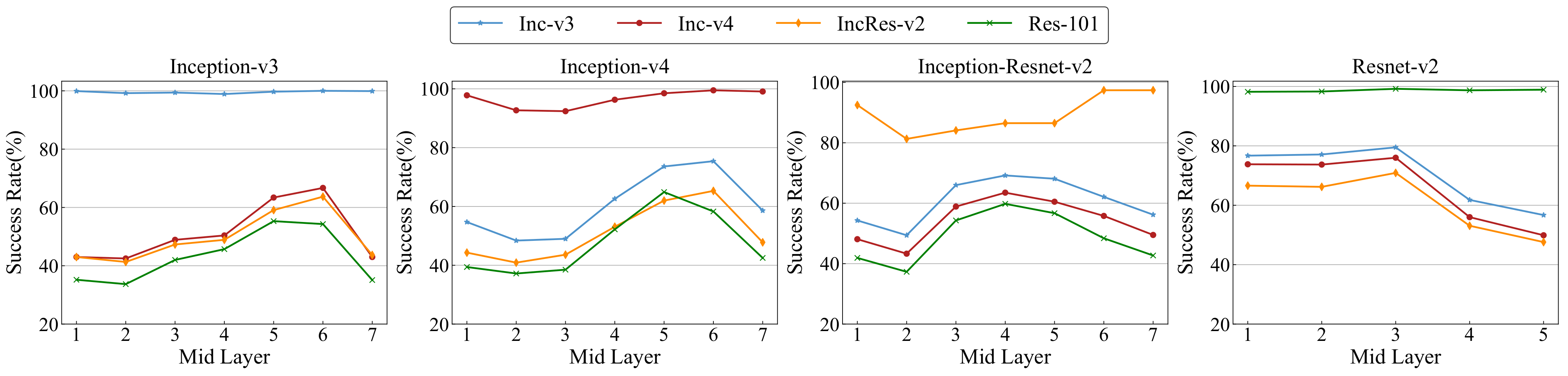
4.2.2. The Performance on Attacking Different Layers
4.3. Adversarial Attack on Image Classification
4.4. Cross-Task Attack on Object Detection
4.5. Cross-Task Attack on Semantic Segmentation
4.6. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into Transferable Adversarial Examples and Black-box Attacks. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing Robust Adversarial Examples. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 284–293. [Google Scholar]
- Yang, P.; Gao, F.; Zhang, H. Multi-Player Evolutionary Game of Network Attack and Defense Based on System Dynamics. Mathematics 2021, 9, 3014. [Google Scholar] [CrossRef]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Xie, C.; Zhang, Z.; Zhou, Y.; Bai, S.; Wang, J.; Ren, Z.; Yuille, A.L. Improving Transferability of Adversarial Examples With Input Diversity. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2730–2739. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading Defenses to Transferable Adversarial Examples by Translation-Invariant Attacks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4312–4321. [Google Scholar]
- Lin, J.; Song, C.; He, K.; Wang, L.; Hopcroft, J.E. Nesterov Accelerated Gradient and Scale Invariance for Adversarial Attacks. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zhou, W.; Hou, X.; Chen, Y.; Tang, M.; Huang, X.; Gan, X.; Yang, Y. Transferable Adversarial Perturbations. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11218, pp. 471–486. [Google Scholar]
- Zhang, Y.; Li, Y.; Liu, T.; Tian, X. Dual-Path Distillation: A Unified Framework to Improve Black-Box Attacks. In Proceedings of the International Conference on Machine Learning (ICML), Virtual Event, 12–18 July 2020; pp. 11163–11172. [Google Scholar]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-box Adversarial Attacks with Limited Queries and Information. In Proceedings of the International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2142–2151. [Google Scholar]
- Bhagoji, A.N.; He, W.; Li, B.; Song, D. Practical Black-Box Attacks on Deep Neural Networks Using Efficient Query Mechanisms. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11216, pp. 158–174. [Google Scholar]
- Li, Y.; Yang, Y.; Zhou, W.; Hospedales, T.M. Feature-Critic Networks for Heterogeneous Domain Generalization. In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 3915–3924. [Google Scholar]
- Peng, W.; Liu, R.; Wang, R.; Cheng, T.; Wu, Z.; Cai, L.; Zhou, W. EnsembleFool: A method to generate adversarial examples based on model fusion strategy. Comput. Secur. 2021, 107, 102317. [Google Scholar] [CrossRef]
- Shang, Y.; Jiang, S.; Ye, D.; Huang, J. Enhancing the Security of Deep Learning Steganography via Adversarial Examples. Mathematics 2020, 8, 1446. [Google Scholar] [CrossRef]
- Lu, Y.; Jia, Y.; Wang, J.; Li, B.; Chai, W.; Carin, L.; Velipasalar, S. Enhancing Cross-Task Black-Box Transferability of Adversarial Examples with Dispersion Reduction. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 937–946. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, À.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Paluzo-Hidalgo, E.; Gonzalez-Diaz, R.; Gutiérrez-Naranjo, M.A.; Heras, J. Simplicial-Map Neural Networks Robust to Adversarial Examples. Mathematics 2021, 9, 169. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D.A. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar]
- Moosavi-Dezfooli, S.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Huang, Q.; Katsman, I.; Gu, Z.; He, H.; Belongie, S.J.; Lim, S. Enhancing Adversarial Example Transferability with an Intermediate Level Attack. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 4732–4741. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A.L. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1378–1387. [Google Scholar]
- Liu, X.; Yang, H.; Liu, Z.; Song, L.; Chen, Y.; Li, H. DPATCH: An Adversarial Patch Attack on Object Detectors. In Proceedings of the Workshop on Artificial Intelligence Safety 2019 co-located with the Thirty-Third AAAI Conference on Artificial Intelligence 2019 (AAAI-19), Honolulu, HI, USA, 27 January 2019; Volume 2301. [Google Scholar]
- Thys, S.; Ranst, W.V.; Goedemé, T. Fooling Automated Surveillance Cameras: Adversarial Patches to Attack Person Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 49–55. [Google Scholar]
- Xu, K.; Zhang, G.; Liu, S.; Fan, Q.; Sun, M.; Chen, H.; Chen, P.; Wang, Y.; Lin, X. Adversarial T-Shirt! Evading Person Detectors in a Physical World. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Volume 12350, pp. 665–681. [Google Scholar]
- Xiao, C.; Deng, R.; Li, B.; Yu, F.; Liu, M.; Song, D. Characterizing Adversarial Examples Based on Spatial Consistency Information for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11214, pp. 220–237. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.J.; Boneh, D.; McDaniel, P.D. Ensemble Adversarial Training: Attacks and Defenses. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Song, C.; He, K.; Lin, J.; Wang, L.; Hopcroft, J.E. Robust Local Features for Improving the Generalization of Adversarial Training. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Guo, C.; Rana, M.; Cissé, M.; van der Maaten, L. Countering Adversarial Images using Input Transformations. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Ren, Z.; Yuille, A.L. Mitigating Adversarial Effects Through Randomization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, H.; Pan, S.J.; Wang, S.; Kot, A.C. Domain Generalization With Adversarial Feature Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5400–5409. [Google Scholar]
- Li, Y.; Tian, X.; Gong, M.; Liu, Y.; Liu, T.; Zhang, K.; Tao, D. Deep Domain Generalization via Conditional Invariant Adversarial Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11219, pp. 647–663. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Volume 9908, pp. 630–645. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-level Feature. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 13039–13048. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection With Learnable Proposals. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric Non-Local Neural Networks for Semantic Segmentation. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 593–602. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Volume 12351, pp. 173–190. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- MMSegmentation Contributors. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 20 April 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Attack | Inc-v3 | Inc-v4 | IncRes-v2 | Res-101 | Inc-v | Inc-v | IncRes-v |
|---|---|---|---|---|---|---|---|---|
| Inc-v3 | MI-FGSM | 99.9 * | 43.8 | 43.6 | 33.7 | 12.2 | 9.9 | 5.6 |
| ILA | 99.9 * | 48.4 | 40.3 | 33.5 | 6.3 | 5.6 | 3.5 | |
| DMA | 100.0 * | 66.7 | 63.7 | 54.3 | 15.9 | 13.6 | 7.2 | |
| Inc-v4 | MI-FGSM | 56.3 | 99.9 * | 46.1 | 40.5 | 13.7 | 11.1 | 7.1 |
| ILA | 58.5 | 99.6 * | 43.2 | 36.2 | 8.0 | 5.6 | 5.2 | |
| DMA | 75.4 | 99.5 * | 65.3 | 58.3 | 17.6 | 15.5 | 7.7 | |
| IncRes-v2 | MI-FGSM | 57.0 | 50.1 | 97.3 * | 43.0 | 18.1 | 15.6 | 10.5 |
| ILA | 71.5 | 64.3 | 97.8 * | 56.5 | 21.2 | 15.1 | 12.3 | |
| DMA | 62.1 | 55.8 | 97.4 * | 48.4 | 19.8 | 16.6 | 11.7 | |
| Res-101 | MI-FGSM | 55.9 | 50.2 | 48.5 | 99.4 * | 22.7 | 19.5 | 11.5 |
| ILA | 66.9 | 63.3 | 55.1 | 99.4 * | 18.5 | 13.3 | 9.1 | |
| DMA | 79.5 | 76.0 | 70.9 | 99.2 * | 31.9 | 27.4 | 15.8 |
| Model | Attack | Inc-v3 | Inc-v4 | IncRes-v2 | Res-101 | Inc-v | Inc-v | IncRes-v |
|---|---|---|---|---|---|---|---|---|
| Inc-v3 | TI-DIM | 98.8 * | 65.8 | 62.1 | 54.9 | 35.2 | 32.2 | 20.9 |
| ILA | 99.7 * | 51.0 | 46.1 | 36.0 | 9.2 | 7.9 | 4.8 | |
| TI-DI-DMA | 99.6 * | 84.0 | 79.8 | 68.0 | 42.5 | 38.6 | 23.9 | |
| Inc-v4 | TI-DIM | 72.9 | 97.8 * | 64.3 | 55.4 | 34.9 | 31.5 | 23.5 |
| ILA | 61.7 | 99.0 * | 49.1 | 38.3 | 10.7 | 9.6 | 5.3 | |
| TI-DI-DMA | 83.2 | 97.7 * | 71.0 | 64.5 | 41.6 | 36.5 | 25.1 | |
| IncRes-v2 | TI-DIM | 68.1 | 65.6 | 91.9 * | 59.2 | 43.0 | 37.3 | 35.1 |
| ILA | 74.5 | 67.5 | 95.2 * | 59.6 | 26.8 | 19.3 | 18.2 | |
| TI-DI-DMA | 70.7 | 70.1 | 92.0 * | 62.5 | 45.1 | 39.9 | 36.8 | |
| Res-101 | TI-DIM | 75.0 | 70.6 | 69.3 | 99.2 * | 54.3 | 50.2 | 40.0 |
| ILA | 72.7 | 68.4 | 64.4 | 99.3 * | 22.9 | 19.2 | 12.4 | |
| TI-DI-DMA | 80.6 | 78.6 | 76.8 | 98.5 * | 54.1 | 49.0 | 41.0 |
| Model | Attack | Inc-v3 | Inc-v4 | IncRes-v2 | Res-101 | Inc-v | Inc-v | IncRes-v |
|---|---|---|---|---|---|---|---|---|
| Inc-v3 | DR | 96.3 * | 14.1 | 14.4 | 16.2 | 4.9 | 3.9 | 3.1 |
| DMA | 100.0 * | 66.7 | 63.7 | 54.3 | 15.9 | 13.6 | 7.2 | |
| Inc-v4 | DR | 21.7 | 76.0 * | 14.8 | 14.3 | 5.7 | 4.9 | 3.4 |
| DMA | 75.4 | 99.5 * | 65.3 | 58.3 | 17.6 | 15.5 | 7.7 | |
| IncRes-v2 | DR | 32.5 | 24.3 | 63.3 * | 25.8 | 12.3 | 10.4 | 7.0 |
| DMA | 62.1 | 55.8 | 97.4 * | 48.4 | 19.8 | 16.6 | 11.7 | |
| Res-101 | DR | 35.6 | 30.0 | 27.8 | 98.1 * | 8.8 | 7.6 | 5.8 |
| DMA | 79.5 | 76.0 | 70.9 | 99.2 * | 31.9 | 27.4 | 15.8 |
| Model | Attack | Faster RCNN ResNet101 | Retinanet ResNet101 | Yolov3 DarkNet53 | YoloF ResNet50 | Sparse RCNN ResNet101 |
|---|---|---|---|---|---|---|
| clean | 50.5 | 48.1 | 46.8 | 47.1 | 55.2 | |
| Inc-v3 | MI-FGSM | 33.1 | 32.3 | 31.4 | 30.6 | 39.2 |
| TI-DIM | 31.7 | 30.9 | 29.2 | 26.9 | 37.3 | |
| DR | 30.9 | 30.8 | 28.1 | 27.7 | 37.2 | |
| DMA | 28.6 | 28.2 | 26.0 | 25.3 | 34.4 | |
| Inc-v4 | MI-FGSM | 30.6 | 29.9 | 28.2 | 27.0 | 36.3 |
| TI-DIM | 29.1 | 28.3 | 26.5 | 24.8 | 35.1 | |
| DR | 30.0 | 30.2 | 27.7 | 27.4 | 36.0 | |
| DMA | 25.0 | 24.6 | 22.3 | 22.0 | 29.4 | |
| IncRes-v2 | MI-FGSM | 29.5 | 29.8 | 28.1 | 28.0 | 35.3 |
| TI-DIM | 28.3 | 28.5 | 26.9 | 24.6 | 34.4 | |
| DR | 26.2 | 26.1 | 24.6 | 24.6 | 30.3 | |
| DMA | 29.1 | 28.6 | 27.9 | 27.3 | 34.6 | |
| Res-101 | MI-FGSM | 30.8 | 30.8 | 29.2 | 29.0 | 35.7 |
| TI-DIM | 30.1 | 30.0 | 28.2 | 27.5 | 35.4 | |
| DR | 25.7 | 25.9 | 23.2 | 23.1 | 31.2 | |
| DMA | 21.8 | 22.6 | 19.3 | 20.2 | 25.8 |
| Model | Attack | deeplabv3 ResNet50 | ANN ResNet50 | FCN ResNet50 | OCRNet HRNetV2p | GCNet ResNet101 |
|---|---|---|---|---|---|---|
| clean | 66.8 | 66.3 | 58.8 | 64.6 | 67.1 | |
| Inc-v3 | MI-FGSM | 53.0 | 52.0 | 42.8 | 52.1 | 55.2 |
| TI-DIM | 51.6 | 50.5 | 41.7 | 50.1 | 55.8 | |
| DR | 50.7 | 50.0 | 40.9 | 51.4 | 53.7 | |
| DMA | 44.3 | 43.1 | 35.2 | 40.7 | 47.3 | |
| Inc-v4 | MI-FGSM | 48.8 | 48.6 | 39.9 | 49.9 | 53.8 |
| TI-DIM | 50.4 | 48.9 | 39.4 | 49.8 | 54.1 | |
| DR | 44.0 | 42.4 | 34.3 | 45.3 | 48.0 | |
| DMA | 39.2 | 38.8 | 31.5 | 38.4 | 42.8 | |
| IncRes-v2 | MI-FGSM | 49.2 | 48.6 | 38.5 | 48.4 | 51.3 |
| TI-DIM | 47.8 | 47.1 | 38.2 | 47.9 | 51.5 | |
| DR | 44.4 | 43.6 | 33.3 | 42.0 | 47.4 | |
| DMA | 47.4 | 47.3 | 37.9 | 47.5 | 50.0 | |
| Res-101 | MI-FGSM | 48.8 | 48.7 | 39.1 | 48.7 | 52.2 |
| TI-DIM | 50.5 | 48.9 | 39.5 | 48.8 | 53.7 | |
| DR | 42.2 | 41.2 | 32.1 | 41.6 | 46.3 | |
| DMA | 32.0 | 31.5 | 26.0 | 28.0 | 33.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Peng, W.; Wang, R.; Lin, Y.; Zhou, W.; Lan, G. Enhance Domain-Invariant Transferability of Adversarial Examples via Distance Metric Attack. Mathematics 2022, 10, 1249. https://doi.org/10.3390/math10081249
Zhang J, Peng W, Wang R, Lin Y, Zhou W, Lan G. Enhance Domain-Invariant Transferability of Adversarial Examples via Distance Metric Attack. Mathematics. 2022; 10(8):1249. https://doi.org/10.3390/math10081249
Chicago/Turabian StyleZhang, Jin, Wenyu Peng, Ruxin Wang, Yu Lin, Wei Zhou, and Ge Lan. 2022. "Enhance Domain-Invariant Transferability of Adversarial Examples via Distance Metric Attack" Mathematics 10, no. 8: 1249. https://doi.org/10.3390/math10081249