
A Dimension Group-Based Comprehensive Elite Learning Swarm Optimizer for Large-Scale Optimization

 , ,
, , 
Abstract
:1. Introduction
- (1)
- A dimension group-based comprehensive elite learning scheme is proposed to guide the update of inferior particles by learning from multiple superior ones. Instead of learning from only at most two exemplars in existing holistic large-scale PSOs [24,25,26,30], the devised learning strategy first randomly divides the dimensions of each inferior particle into several equally sized groups and then employs different superior particles to guide the update of different dimension groups. Moreover, unlike existing elite strategies that only use one elite to direct the evolution of an individual [43,44], it employs a random dimension group-based recombination techniques to try to integrate valuable evolutionary information in multiple elites to guide the update of each non-elite particle. In this way, the learning diversity of particles could be largely promoted, which is beneficial for particles to avoid falling into local traps. Moreover, it is also possible that useful evolutionary information embedded in different superior particles could be integrated to direct the learning of inferior particles, which may be profitable for particles to approach promising areas quickly.
- (2)
- Dynamic adjustment strategies for the control parameters involved in the proposed learning strategy are further designed to cooperate with the learning strategy to help PSO search the large-scale solution space properly. With these dynamic strategies, the developed DGCELSO could appropriately compromise the intensification and diversification of the search process at the swarm level and the particle level.
2. Related Work
2.1. Canonical PSO
2.2. Large-Scale PSO
2.2.1. Cooperative Coevolutionary Large-Scale PSO (CCPSO)
2.2.2. Holistic Large-Scale PSO
3. Dimension Group-Based Comprehensive Elite Learning Swarm Optimizer
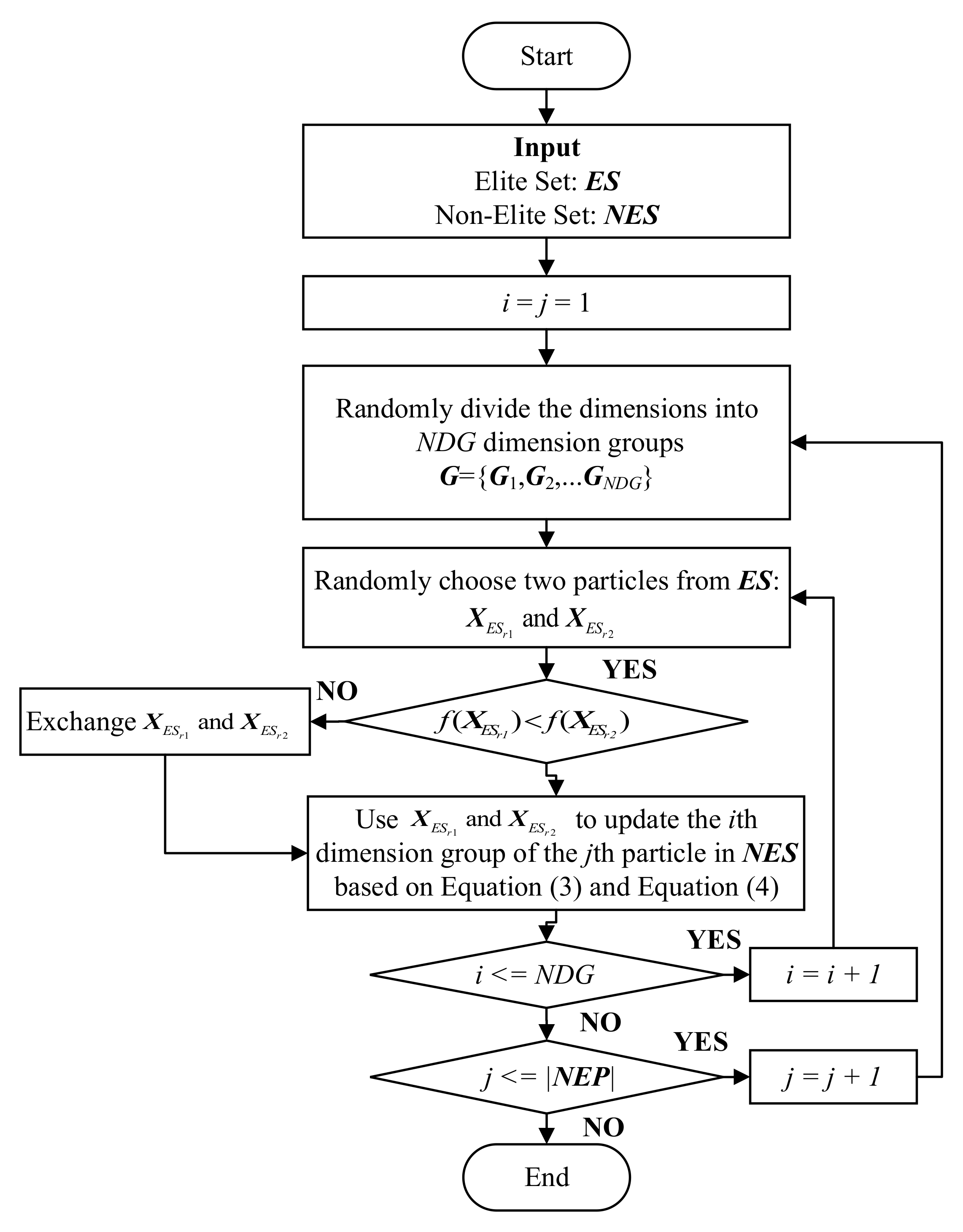
3.1. Dimension Group-Based Comprehensive Elite Learning
- (1)
- As previously mentioned, for each non-elite particle, the dimensions are randomly shuffled. As a result, the partition of dimension groups is different for different non-elite particles.
- (2)
- For each dimension group , two different elite particles and are first randomly selected from ES. Then, the better one between these two elites (suppose it is ) acts as the first exemplar in Equation (4), while the worse one (suppose it is ) acts as the second exemplar to guide the update of the dimension group of the non-elite particle.
- (3)
- The two elite particles guiding the update of each dimension group are both randomly selected. Therefore, they are likely to be different for different dimension groups.
- (1)
- Instead of using historical evolutionary information, such as the historically global best position (gbest), the personal best positions (pbest), and the neighborhood best position (nbest), in traditional PSOs [18,47], the devised DGCEL employs the elite particles in the current swarm to direct the learning of the non-elite particles. In contrast to the historical information, which may remain unchanged for many generations, particles in the swarm are usually updated generation by generation. Therefore, in the proposed DGCEL, the selected two guiding exemplars are not only likely different for different particles but also probably different for the same particle in different generations. This is very beneficial for the promotion of swarm diversity.
- (2)
- Instead of updating each particle with the same exemplars for all dimensions in most existing large-scale PSOs [5,24,25,26,30], the proposed DGCEL updates non-elite particles at the dimension group level. Therefore, for different dimension groups, the two guiding exemplars are likely different. In this way, not only could one non-elite particle learn from multiple different elite ones, but also the useful genes hidden in different elites could be incorporated to direct the evolution of the swarm. As a result, not only the learning diversity of particles could be improved, but also the learning efficiency of particles could be promoted.
- (3)
- In DGCEL, each dimension group of a non-elite particle is guided by two randomly selected elite particles in ES. With the guidance of multiple elites, each non-elite particle is expected to approach promising areas quickly. In addition, since the elite particles in ES are not updated and directly enter the next generation, the useful evolutionary information in the current swarm is protected from being destroyed by uncertain updates. Therefore, the elites in ES become better and better as the evolution iterates, and at last, it is expected that these elites converge to the optimal areas.
Remark
- (1)
- In contrast to the three low-dimensional PSOs [46,47,48], the proposed DGCELSO uses the elite particles in the swarm to comprehensively guide the learning of the non-elite particles at the dimension group level. First, the three low-dimensional PSOs all use the personal best positions (pbests) of particles to construct only one guiding exemplar for each updated particle, whereas DGCELSO leverages the elite particles in the current swarm to construct two different guiding exemplars for each non-elite particle. Second, the three low-dimensional PSOs construct the guiding exemplar dimension by dimension. Nevertheless, DGCELSO constructs the two guiding exemplars group by group. With these two differences, DGCELSO is expected to construct more promising guiding exemplars for the updated particles, and thus the learning effectiveness and efficiency of particles could be largely promoted to explore the large-scale solution space.
- (2)
- In contrast to the large-scale PSO, namely SPLSO [30], DGCELSO uses two different elite particles to direct the update of each dimension group of each non-elite particle. First, the partition of the swarm in DGCELSO is very different from the one in SPLSO. In DGCELSO, the swarm is divided into two exclusive sets according to the fitness of particles, with the best es particles entering ES and the rest entering NES. However, in SPLSO, particles in the swarm are paired together and each paired two particles compete with each other, with the winner entering the relatively good set and the loser entering the relatively poor set. Second, for each non-elite particle, DGCELSO adopts two random elites in ES to guide the update of each dimension group, whereas in SPLSO, each dimension group of a loser is updated by only one random relatively good particle with the other exemplar being the mean position of the relatively good set, which is shared by all updated particles. Therefore, it is expected that the learning effectiveness and efficiency of particles in DGCELSO are higher than in SPLSO. Hence, DGCELSO is expected to explore and exploit the large-scale solution space more appropriately than SPLSO.
3.2. Adaptive Strategies for Control Parameters
3.2.1. Dynamic Adjustment for tp
3.2.2. Dynamic Adjustment for NDG
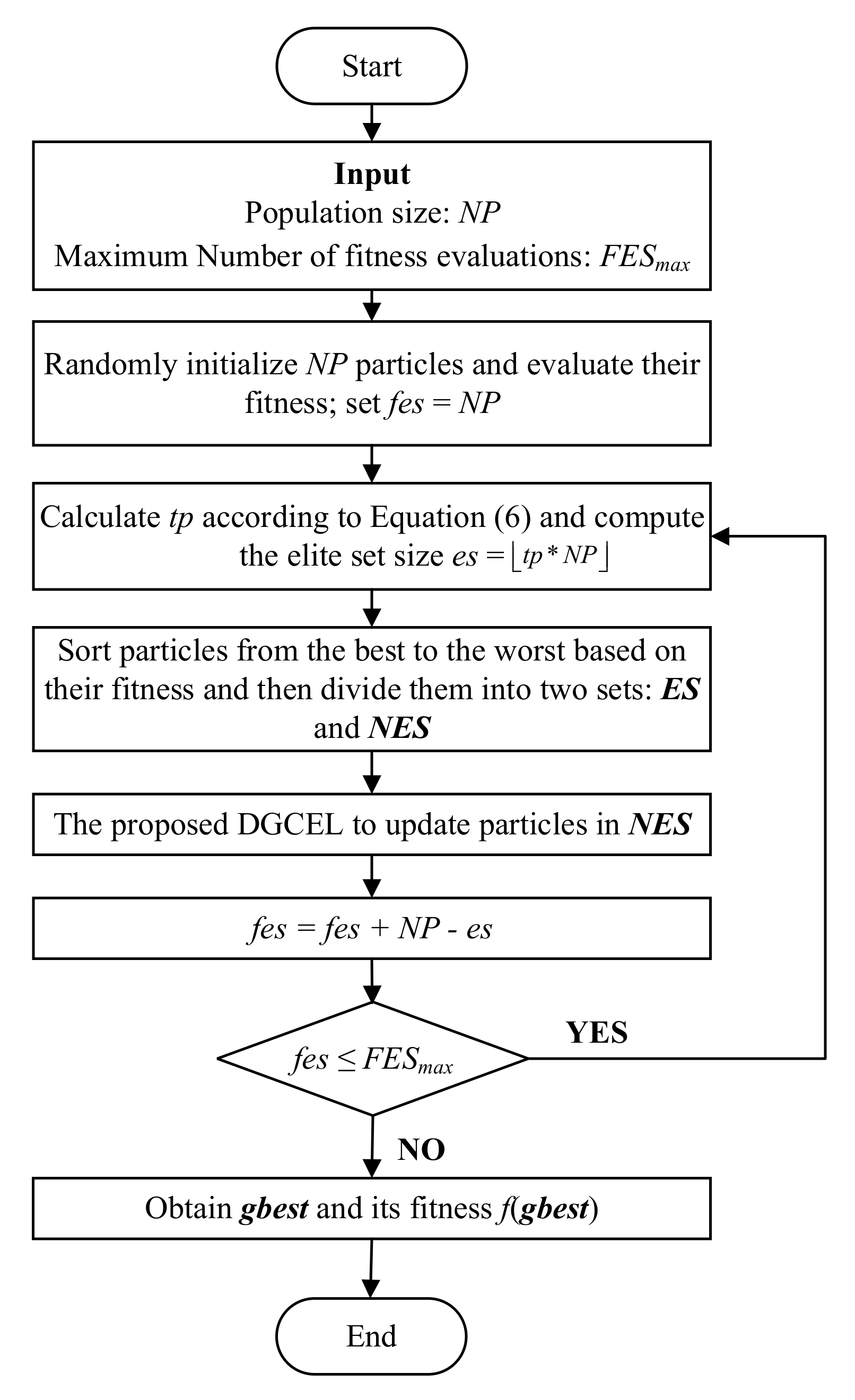
3.3. Overall Procedure of DGCELSO
| Algorithm 1: The Pseudocode of DGCELSO. | |
| Input: | Population size NP, Maximum number of fitness evaluations FESmax, Control parameter ; |
| 1: | Initialize NP particles randomly and calculate their fitness; fes = NP; |
| 2: | While (fes ≤ FESmax) do |
| 3: | Calculate tp according to Equation (6) and obtain the elite set size es = ; |
| 4: | Sort particles based on their fitness and divide them into two sets, namely ES and NES; |
| 5: | For each non-elite particle in NES do |
| 6: | Generate based on Equation (7); |
| 7: | Random shuffle the dimensions and then split the dimensions into groups; |
| 8: | For each dimension group do |
| 9: | Randomly select two different elite particles from ES: ; |
| 10: | If (f() < f()) then |
| 11: | Swap ESr1 and ESr2; |
| 12: | End If |
| 13: | Update the dimension group of according to Equations (3) and (4); |
| 14: | End For |
| 15: | Calculate the fitness of the updated , and fes ++; |
| 16: | End For |
| 17: | End While |
| 18: | Obtain the best solution in the swarm gbest and its fitness f(gbest) |
| Output: f(gbest) and gbest | |
4. Experimental Section
4.1. Parameter Setting
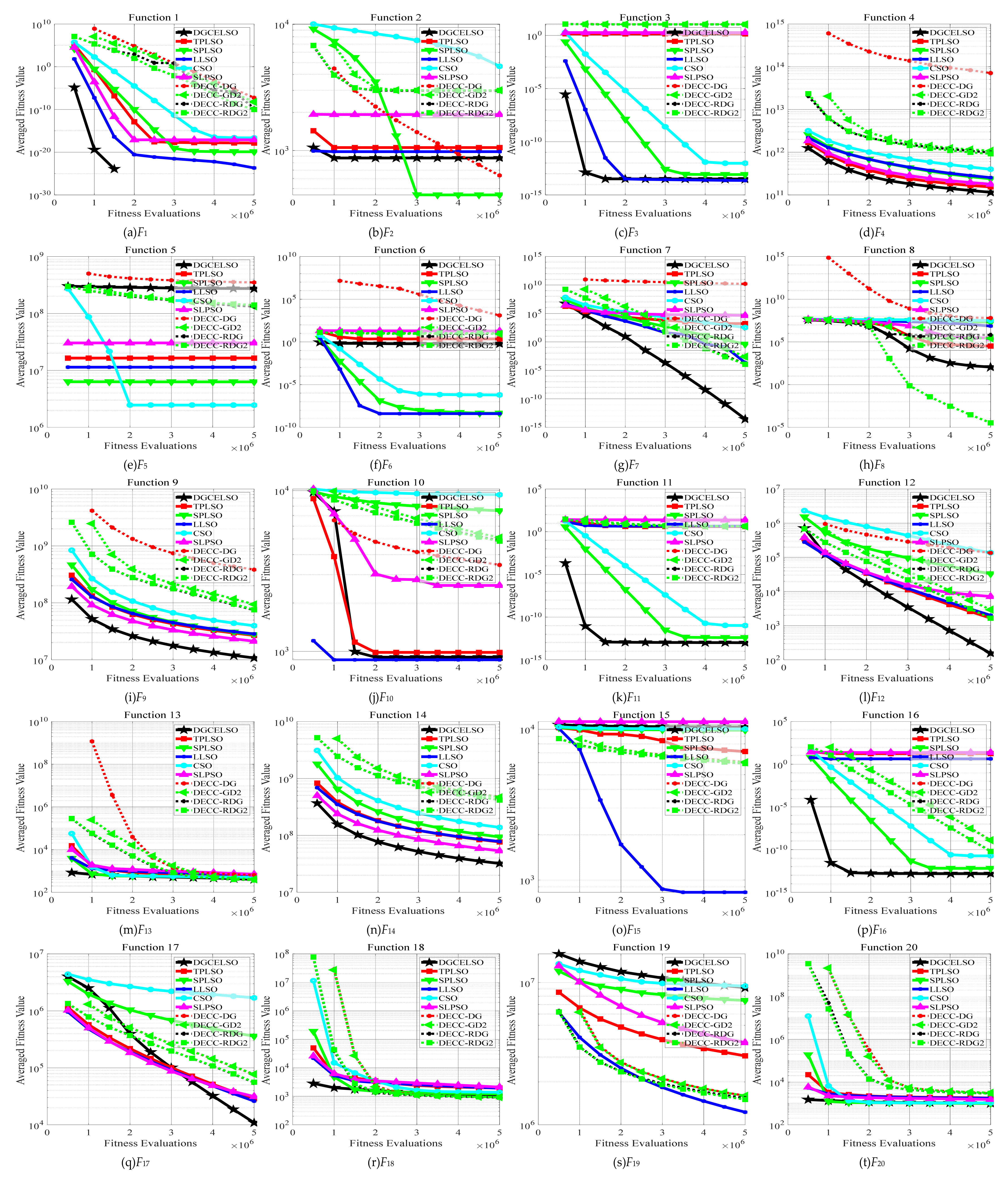
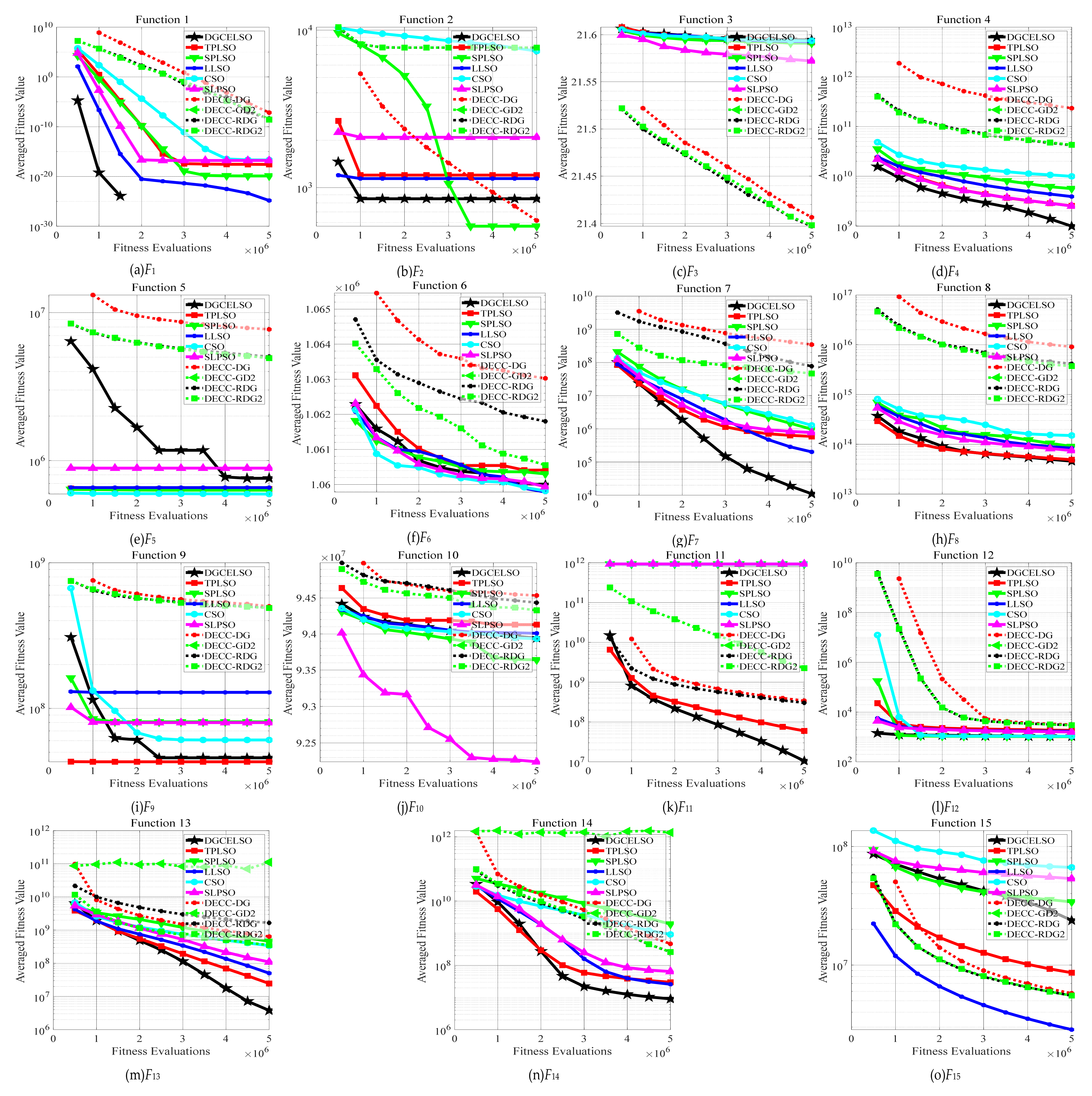
4.2. Comparisons with State-of-the-Art Methods
4.3. Deep Investigation on DGCELSO
4.3.1. Effectiveness of the Proposed DGCEL
4.3.2. Effectiveness of the Proposed Dynamic Adjustment Schemes for Parameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jia, Y.H.; Mei, Y.; Zhang, M. A Two-Stage Swarm Optimizer with Local Search for Water Distribution Network Optimization. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Cao, K.; Cui, Y.; Liu, Z.; Tan, W.; Weng, J. Edge Intelligent Joint Optimization for Lifetime and Latency in Large-Scale Cyber-Physical Systems. IEEE Internet Things J. 2021. [Google Scholar] [CrossRef]
- Chen, W.N.; Tan, D.Z.; Yang, Q.; Gu, T.; Zhang, J. Ant Colony Optimization for the Control of Pollutant Spreading on Social Networks. IEEE Trans. Cybern. 2020, 50, 4053–4065. [Google Scholar] [CrossRef]
- Zuo, T.; Zhang, Y.; Meng, K.; Tong, Z.; Dong, Z.Y.; Fu, Y. A Two-Layer Hybrid Optimization Approach for Large-Scale Offshore Wind Farm Collector System Planning. IEEE Trans. Ind. Inform. 2021, 17, 7433–7444. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Gu, T.; Jin, H.; Mao, W.; Zhang, J. An Adaptive Stochastic Dominant Learning Swarm Optimizer for High-Dimensional Optimization. IEEE Trans. Cybern. 2020, 52, 1960–1976. [Google Scholar] [CrossRef]
- Omidvar, M.N.; Li, X.; Mei, Y.; Yao, X. Cooperative Co-Evolution with Differential Grouping for Large Scale Optimization. IEEE Trans. Evol. Comput. 2014, 18, 378–393. [Google Scholar] [CrossRef] [Green Version]
- Tang, K.; Li, X.; Suganthan, P.; Yang, Z.; Weise, T. Benchmark Functions for the CEC 2010 Special Session and Competition on Large-Scale Global Optimization; Nature Inspired Computation and Applications Laboratory, University of Science and Technology of China: Hefei, China, 2009. [Google Scholar]
- Li, X.; Tang, K.; Omidvar, M.N.; Yang, Z.; Qin, K.; China, H. Benchmark Functions for the CEC 2013 Special Session and Competition on Large-Scale Global Optimization; Technical Report; Evolutionary Computation and Machine Learning Group, RMIT University: Melbourne, Australia, 2013. [Google Scholar]
- Yang, Q.; Li, Y.; Gao, X.-D.; Ma, Y.-Y.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. An Adaptive Covariance Scaling Estimation of Distribution Algorithm. Mathematics 2021, 9, 3207. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.N.; Gu, T.; Zhang, H.; Yuan, H.; Kwong, S.; Zhang, J. A Distributed Swarm Optimizer with Adaptive Communication for Large-Scale Optimization. IEEE Trans. Cybern. 2020, 50, 3393–3408. [Google Scholar] [CrossRef]
- Omidvar, M.N.; Li, X.; Yao, X. A Review of Population-Based Metaheuristics for Large-Scale Black-Box Global Optimization: Part A. IEEE Trans. Evol. Comput. 2021. in press. Available online: https://ieeexplore.ieee.org/document/9627116 (accessed on 1 January 2022).
- Omidvar, M.N.; Li, X.; Yao, X. A Review of Population-Based Metaheuristics for Large-Scale Black-Box Global Optimization: Part B. IEEE Trans. Evol. Comput. 2021. in press. Available online: https://ieeexplore.ieee.org/document/9627138 (accessed on 1 January 2022).
- Yang, Q.; Xie, H.; Chen, W.; Zhang, J. Multiple Parents Guided Differential Evolution for Large Scale Optimization. In Proceedings of the IEEE Congress on Evolutionary Computation, Vancouver, BC, Canada, 24–29 July 2016; pp. 3549–3556. [Google Scholar]
- Yang, Q.; Chen, W.N.; Li, Y.; Chen, C.L.P.; Xu, X.M.; Zhang, J. Multimodal Estimation of Distribution Algorithms. IEEE Trans. Cybern. 2017, 47, 636–650. [Google Scholar] [CrossRef] [Green Version]
- Eberhart, R.; Kennedy, J. A New Optimizer Using Particle Swarm Theory. In Proceedings of the International Symposium on Micro Machine and Human Science, Nagoya, Japan, 4–6 October 1995; pp. 39–43. [Google Scholar]
- Shi, Y.; Eberhart, R. A Modified Particle Swarm Optimizer. In Proceedings of the IEEE International Conference on Evolutionary Computation Proceedings: IEEE World Congress on Computational Intelligence, Anchorage, AK, USA, 4–9 May 1998; pp. 69–73. [Google Scholar]
- Tang, J.; Liu, G.; Pan, Q. A Review on Representative Swarm Intelligence Algorithms for Solving Optimization Problems: Applications and Trends. IEEE/CAA J. Autom. Sin. 2021, 8, 1627–1643. [Google Scholar] [CrossRef]
- Ren, Z.; Zhang, A.; Wen, C.; Feng, Z. A Scatter Learning Particle Swarm Optimization Algorithm for Multimodal Problems. IEEE Trans. Cybern. 2014, 44, 1127–1140. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, Y.; Che, L.; Zhou, M. Moving-Distance-Minimized PSO for Mobile Robot Swarm. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef]
- Villalón, C.L.C.; Dorigo, M.; Stützle, T. PSO-X: A Component-Based Framework for the Automatic Design of Particle Swarm Optimization Algorithms. IEEE Trans. Evol. Comput. 2021. [Google Scholar] [CrossRef]
- Ding, W.; Lin, C.T.; Cao, Z. Deep Neuro-Cognitive Co-Evolution for Fuzzy Attribute Reduction by Quantum Leaping PSO with Nearest-Neighbor Memeplexes. IEEE Trans. Cybern. 2019, 49, 2744–2757. [Google Scholar] [CrossRef]
- Yang, Q.; Hua, L.; Gao, X.; Xu, D.; Lu, Z.; Jeon, S.-W.; Zhang, J. Stochastic Cognitive Dominance Leading Particle Swarm Optimization for Multimodal Problems. Mathematics 2022, 10, 761. [Google Scholar] [CrossRef]
- Bonavolontà, F.; Noia, L.P.D.; Liccardo, A.; Tessitore, S.; Lauria, D. A PSO-MMA Method for the Parameters Estimation of Interarea Oscillations in Electrical Grids. IEEE Trans. Instrum. Meas. 2020, 69, 8853–8865. [Google Scholar] [CrossRef]
- Lan, R.; Zhu, Y.; Lu, H.; Liu, Z.; Luo, X. A Two-Phase Learning-Based Swarm Optimizer for Large-Scale Optimization. IEEE Trans. Cybern. 2020, 51, 6284–6293. [Google Scholar] [CrossRef]
- Yang, Q.; Chen, W.; Deng, J.D.; Li, Y.; Gu, T.; Zhang, J. A Level-Based Learning Swarm Optimizer for Large-Scale Optimization. IEEE Trans. Evol. Comput. 2018, 22, 578–594. [Google Scholar] [CrossRef]
- Cheng, R.; Jin, Y. A Competitive Swarm Optimizer for Large Scale Optimization. IEEE Trans. Cybern. 2015, 45, 191–204. [Google Scholar] [CrossRef]
- Mahdavi, S.; Shiri, M.E.; Rahnamayan, S. Metaheuristics in Large-Scale Global Continues Optimization: A Survey. Inf. Sci. 2015, 295, 407–428. [Google Scholar] [CrossRef]
- Ma, X.; Li, X.; Zhang, Q.; Tang, K.; Liang, Z.; Xie, W.; Zhu, Z. A Survey on Cooperative Co-Evolutionary Algorithms. IEEE Trans. Evol. Comput. 2018, 23, 421–441. [Google Scholar] [CrossRef]
- Li, X.; Yao, X. Cooperatively Coevolving Particle Swarms for Large Scale Optimization. IEEE Trans. Evol. Comput. 2011, 16, 210–224. [Google Scholar]
- Yang, Q.; Chen, W.; Gu, T.; Zhang, H.; Deng, J.D.; Li, Y.; Zhang, J. Segment-Based Predominant Learning Swarm Optimizer for Large-Scale Optimization. IEEE Trans. Cybern. 2017, 47, 2896–2910. [Google Scholar] [CrossRef] [Green Version]
- Xie, H.Y.; Yang, Q.; Hu, X.M.; Chen, W.N. Cross-Generation Elites Guided Particle Swarm Optimization for Large Scale Optimization. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Song, G.W.; Yang, Q.; Gao, X.D.; Ma, Y.Y.; Lu, Z.Y.; Zhang, J. An Adaptive Level-Based Learning Swarm Optimizer for Large-Scale Optimization. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Melbourne, Australia, 17–20 October 2021; pp. 152–159. [Google Scholar]
- Potter, M.A.; De Jong, K.A. A Cooperative Co-Evolutionary Approach to Function Optimization. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Berlin, Germany, 22–26 September 1994; pp. 249–257. [Google Scholar]
- Yang, Q.; Chen, W.N.; Zhang, J. Evolution Consistency Based Decomposition for Cooperative Coevolution. IEEE Access 2018, 6, 51084–51097. [Google Scholar] [CrossRef]
- Omidvar, M.N.; Yang, M.; Mei, Y.; Li, X.; Yao, X. DG2: A Faster and More Accurate Differential Grouping for Large-Scale Black-Box Optimization. IEEE Trans. Evol. Comput. 2017, 21, 929–942. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Kirley, M.; Halgamuge, S.K. Extended Differential Grouping for Large Scale Global Optimization with Direct and Indirect Variable Interactions. In Proceedings of the Annual Conference on Genetic and Evolutionary Computation, Madrid, Spain, 11–15 July 2015; pp. 313–320. [Google Scholar]
- Sun, Y.; Kirley, M.; Halgamuge, S.K. A Recursive Decomposition Method for Large Scale Continuous Optimization. IEEE Trans. Evol. Comput. 2017, 22, 647–661. [Google Scholar] [CrossRef]
- Song, A.; Chen, W.N.; Gong, Y.J.; Luo, X.; Zhang, J. A Divide-and-Conquer Evolutionary Algorithm for Large-Scale Virtual Network Embedding. IEEE Trans. Evol. Comput. 2020, 24, 566–580. [Google Scholar] [CrossRef]
- Deng, H.; Peng, L.; Zhang, H.; Yang, B.; Chen, Z. Ranking-Based Biased Learning Swarm Optimizer for Large-Scale Optimization. Inf. Sci. 2019, 493, 120–137. [Google Scholar] [CrossRef]
- Wang, H.; Liang, M.; Sun, C.; Zhang, G.; Xie, L. Multiple-Strategy Learning Particle Swarm Optimization for Large-Scale Optimization Problems. Complex Intell. Syst. 2021, 7, 1–16. [Google Scholar] [CrossRef]
- Jian, J.R.; Chen, Z.G.; Zhan, Z.H.; Zhang, J. Region Encoding Helps Evolutionary Computation Evolve Faster: A New Solution Encoding Scheme in Particle Swarm for Large-Scale Optimization. IEEE Trans. Evol. Comput. 2021, 25, 779–793. [Google Scholar] [CrossRef]
- Kampourakis, K. Understanding Evolution; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Ju, X.; Liu, F. Wind Farm Layout Optimization Using Self-Informed Genetic Algorithm with Information Guided Exploitation. Appl. Energy 2019, 248, 429–445. [Google Scholar] [CrossRef]
- Ju, X.; Liu, F.; Wang, L.; Lee, W.-J. Wind Farm Layout Optimization Based on Support Vector Regression Guided Genetic Algorithm with Consideration of Participation among Landowners. Energy Convers. Manag. 2019, 196, 1267–1281. [Google Scholar] [CrossRef]
- Xia, X.; Gui, L.; Yu, F.; Wu, H.; Wei, B.; Zhang, Y.L.; Zhan, Z.H. Triple Archives Particle Swarm Optimization. IEEE Trans. Cybern. 2020, 50, 4862–4875. [Google Scholar] [CrossRef]
- Liang, J.J.; Qin, A.K.; Suganthan, P.N.; Baskar, S. Comprehensive Learning Particle Swarm Optimizer for Global Optimization of Multimodal Functions. IEEE Trans. Evol. Comput. 2006, 10, 281–295. [Google Scholar] [CrossRef]
- Gong, Y.; Li, J.; Zhou, Y.; Li, Y.; Chung, H.S.; Shi, Y.; Zhang, J. Genetic Learning Particle Swarm Optimization. IEEE Trans. Cybern. 2016, 46, 2277–2290. [Google Scholar] [CrossRef] [Green Version]
- Zhan, Z.; Zhang, J.; Li, Y.; Shi, Y. Orthogonal Learning Particle Swarm Optimization. IEEE Trans. Evol. Comput. 2011, 15, 832–847. [Google Scholar] [CrossRef] [Green Version]
- Van den Bergh, F.; Engelbrecht, A.P. A Cooperative Approach to Particle Swarm Optimization. IEEE Trans. Evol. Comput. 2004, 8, 225–239. [Google Scholar] [CrossRef]
- Mei, Y.; Omidvar, M.N.; Li, X.; Yao, X. A Competitive Divide-and-Conquer Algorithm for Unconstrained Large-Scale Black-Box Optimization. ACM Trans. Math. Softw. 2016, 42, 1–24. [Google Scholar] [CrossRef]
- Yang, M.; Zhou, A.; Li, C.; Yao, X. An Efficient Recursive Differential Grouping for Large-Scale Continuous Problems. IEEE Trans. Evol. Comput. 2021, 25, 159–171. [Google Scholar] [CrossRef]
- Sun, Y.; Omidvar, M.N.; Kirley, M.; Li, X. Adaptive Threshold Parameter Estimation with Recursive Differential Grouping for Problem Decomposition. In Proceedings of the Genetic and Evolutionary Computation Conference, Kyoto, Japan, 15–19 July 2018. [Google Scholar]
- Ma, X.; Huang, Z.; Li, X.; Wang, L.; Qi, Y.; Zhu, Z. Merged Differential Grouping for Large-scale Global Optimization. IEEE Trans. Evol. Comput. 2022, in press. [Google Scholar] [CrossRef]
- Liu, H.; Wang, Y.; Fan, N. A Hybrid Deep Grouping Algorithm for Large Scale Global Optimization. IEEE Trans. Evol. Comput. 2020, 24, 1112–1124. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Gong, Y.J.; Lin, Y.; Zhang, J.; Kwong, S.; Zhang, J. Dynamic Cooperative Coevolution for Large Scale Optimization. IEEE Trans. Evol. Comput. 2019, 23, 935–948. [Google Scholar] [CrossRef]
- Neshat, M.; Mirjalili, S.; Sergiienko, N.Y.; Esmaeilzadeh, S.; Amini, E.; Heydari, A.; Garcia, D.A. Layout Optimisation of Offshore Wave Energy Converters Using a Novel Multi-swarm Cooperative Algorithm with Backtracking Strategy: A Case Study from Coasts of Australia. Energy 2022, 239, 122463. [Google Scholar] [CrossRef]
- Pan, Q.K.; Gao, L.; Wang, L. An Effective Cooperative Co-Evolutionary Algorithm for Distributed Flowshop Group Scheduling Problems. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef]
- Neshat, M.; Alexander, B.; Wagner, M. A Hybrid Cooperative Co-Evolution Algorithm Framework for Optimising Power Take off and Placements of Wave Energy Converters. Inf. Sci. 2020, 534, 218–244. [Google Scholar] [CrossRef]
- Liang, M.; Wang, W.; Dong, C.; Zhao, D. A Cooperative Coevolutionary Optimization Design of Urban Transit Network and Operating Frequencies. Expert Syst. Appl. 2020, 160, 113736. [Google Scholar] [CrossRef]
- Zhao, S.-Z.; Liang, J.J.; Suganthan, P.N.; Tasgetiren, M.F. Dynamic Multi-Swarm Particle Swarm Optimizer with Local Search for Large Scale Global Optimization. In Proceedings of the IEEE Congress on Evolutionary Computation, Hong Kong, China, 1–6 June 2008; pp. 3845–3852. [Google Scholar]
- Cheng, R. A Social Learning Particle Swarm Optimization Algorithm for Scalable Optimization. Inf. Sci. 2015, 291, 43–60. [Google Scholar] [CrossRef]
- Mohapatra, P.; Das, K.N.; Roy, S. A Modified Competitive Swarm Optimizer for Large Scale Optimization Problems. Appl. Soft Comput. 2017, 59, 340–362. [Google Scholar] [CrossRef]
- Li, D.; Guo, W.; Lerch, A.; Li, Y.; Wang, L.; Wu, Q. An Adaptive Particle Swarm Optimizer with Decoupled Exploration and Exploitation for Large Scale Optimization. Swarm Evol. Comput. 2021, 60, 100789. [Google Scholar] [CrossRef]
- Lan, R.; Zhang, L.; Tang, Z.; Liu, Z.; Luo, X. A Hierarchical Sorting Swarm Optimizer for Large-Scale Optimization. IEEE Access 2019, 7, 40625–40635. [Google Scholar] [CrossRef]
- Kong, F.; Jiang, J.; Huang, Y. An Adaptive Multi-Swarm Competition Particle Swarm Optimizer for Large-Scale Optimization. Mathematics 2019, 7, 521. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Lv, L.; Ye, S.; Hao, Z. Particle Swarm Optimization with Convergence Speed Controller for Large-Scale Numerical Optimization. Soft Comput. 2019, 23, 4421–4437. [Google Scholar] [CrossRef]
- LaTorre, A.; Muelas, S.; Peña, J.-M. A Comprehensive Comparison of Large Scale Global Optimizers. Inf. Sci. 2015, 316, 517–549. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| F | NP = 100 | NP = 200 | ||||||||||||||||
| ϕ = 0.1 | ϕ = 0.2 | ϕ = 0.3 | ϕ = 0.4 | ϕ = 0.5 | ϕ = 0.6 | ϕ = 0.7 | ϕ = 0.8 | ϕ = 0.9 | ϕ = 0.1 | ϕ = 0.2 | ϕ = 0.3 | ϕ = 0.4 | ϕ = 0.5 | ϕ = 0.6 | ϕ = 0.7 | ϕ = 0.8 | ϕ = 0.9 | |
| F1 | 3.31 × 102 | 5.18 × 107 | 8.23 × 107 | 1.34 × 107 | 1.12 × 103 | 2.92 × 10−23 | 9.51 × 10−20 | 5.27 × 105 | 1.01 × 108 | 5.12 × 10−26 | 6.22 × 10−29 | 5.73 × 10−27 | 0.00 × 100 | 1.10 × 10−26 | 2.11 × 10−22 | 9.04 × 102 | 5.08 × 107 | 1.22 × 109 |
| F2 | 2.93 × 103 | 3.58 × 103 | 3.64 × 103 | 3.22 × 103 | 2.50 × 103 | 1.62 × 103 | 1.12 × 103 | 9.12 × 103 | 1.13 × 104 | 1.16 × 103 | 1.61 × 103 | 1.69 × 103 | 1.40 × 103 | 8.84 × 102 | 2.95 × 103 | 1.07 × 104 | 1.14 × 104 | 1.19 × 104 |
| F3 | 5.74 × 100 | 1.13 × 101 | 1.14 × 101 | 8.23 × 100 | 3.24 × 100 | 2.18 × 10−1 | 6.43 × 10−14 | 3.89 × 10−1 | 1.36 × 101 | 3.47 × 10−14 | 2.90 × 10−2 | 1.19 × 10−1 | 3.42 × 10−14 | 3.81 × 10−14 | 4.88 × 10−14 | 3.63 × 10−1 | 1.27 × 101 | 1.71 × 101 |
| F4 | 4.77 × 1011 | 5.57 × 1012 | 5.93 × 1012 | 2.88 × 1012 | 1.66 × 1011 | 1.14 × 1011 | 1.53 × 1011 | 2.90 × 1011 | 7.08 × 1011 | 1.74 × 1011 | 1.96 × 1011 | 4.21 × 1011 | 1.28 × 1011 | 1.25 × 1011 | 1.67 × 1011 | 2.48 × 1011 | 6.04 × 1011 | 2.14 × 1013 |
| F5 | 2.96 × 107 | 3.16 × 107 | 3.01 × 107 | 3.54 × 107 | 1.30 × 108 | 2.75 × 108 | 2.86 × 108 | 2.96 × 108 | 3.05 × 108 | 2.81 × 108 | 2.36 × 108 | 2.24 × 108 | 2.55 × 108 | 2.77 × 108 | 2.84 × 108 | 2.91 × 108 | 3.04 × 108 | 3.09 × 108 |
| F6 | 1.99 × 101 | 2.02 × 101 | 2.02 × 101 | 2.01 × 101 | 1.99 × 101 | 2.01 × 101 | 2.15 × 101 | 2.15 × 101 | 2.03 × 101 | 1.94 × 101 | 1.97 × 101 | 1.97 × 101 | 1.98 × 101 | 1.96 × 101 | 4.00 × 10−9 | 3.82 × 10−1 | 1.34 × 101 | 1.78 × 101 |
| F7 | 2.94 × 106 | 9.82 × 108 | 1.28 × 109 | 3.37 × 108 | 7.90 × 105 | 7.40 × 105 | 1.17 × 105 | 8.40 × 104 | 7.80 × 105 | 3.34 × 10−6 | 3.70 × 104 | 1.75 × 106 | 1.40 × 103 | 8.73 × 10−6 | 3.14 × 10−1 | 2.51 × 104 | 5.02 × 105 | 1.76 × 107 |
| F8 | 3.39 × 107 | 4.89 × 107 | 4.72 × 107 | 4.42 × 107 | 1.67 × 105 | 6.68 × 104 | 1.58 × 107 | 4.17 × 107 | 4.89 × 107 | 3.33 × 105 | 5.47 × 106 | 2.47 × 107 | 1.86 × 103 | 3.95 × 103 | 1.73 × 107 | 3.97 × 107 | 4.52 × 107 | 4.62 × 107 |
| F9 | 8.72 × 107 | 1.03 × 109 | 1.17 × 109 | 6.34 × 108 | 2.80 × 107 | 1.75 × 107 | 4.08 × 107 | 4.70 × 108 | 1.36 × 1010 | 1.97 × 107 | 3.44 × 107 | 6.48 × 107 | 1.98 × 107 | 1.47 × 107 | 4.03 × 107 | 3.65 × 109 | 2.29 × 1010 | 4.11 × 1010 |
| F10 | 3.14 × 103 | 3.85 × 103 | 3.97 × 103 | 3.43 × 103 | 2.65 × 103 | 1.69 × 103 | 2.66 × 103 | 1.09 × 104 | 1.16 × 104 | 1.20 × 103 | 1.76 × 103 | 1.82 × 103 | 1.48 × 103 | 9.59 × 102 | 1.01 × 104 | 1.08 × 104 | 1.14 × 104 | 1.20 × 104 |
| F11 | 7.08 × 101 | 9.71 × 101 | 9.38 × 101 | 8.60 × 101 | 5.22 × 101 | 3.03 × 101 | 2.47 × 101 | 2.53 × 101 | 6.32 × 101 | 1.57 × 101 | 2.00 × 101 | 2.03 × 101 | 2.00 × 101 | 1.09 × 101 | 1.85 × 10−13 | 1.38 × 100 | 5.04 × 101 | 1.41 × 102 |
| F12 | 9.54 × 104 | 1.03 × 106 | 1.13 × 106 | 6.89 × 105 | 4.82 × 103 | 8.18 × 102 | 6.14 × 104 | 5.07 × 106 | 6.64 × 106 | 2.35 × 103 | 1.71 × 104 | 7.25 × 104 | 1.72 × 103 | 1.92 × 103 | 2.36 × 106 | 5.14 × 106 | 6.61 × 106 | 7.97 × 106 |
| F13 | 5.89 × 103 | 3.83 × 106 | 4.40 × 106 | 9.77 × 105 | 5.29 × 103 | 3.06 × 103 | 2.35 × 103 | 6.58 × 104 | 1.36 × 108 | 6.55 × 102 | 8.02 × 102 | 1.02 × 103 | 5.58 × 102 | 4.97 × 102 | 5.48 × 102 | 2.96 × 103 | 3.95 × 107 | 9.38 × 109 |
| F14 | 2.68 × 108 | 2.11 × 109 | 2.30 × 109 | 1.45 × 109 | 8.31 × 107 | 4.56 × 107 | 1.39 × 108 | 3.47 × 109 | 3.23 × 1010 | 5.82 × 107 | 1.12 × 108 | 2.20 × 108 | 6.07 × 107 | 4.61 × 107 | 2.11 × 108 | 2.02 × 1010 | 5.18 × 1010 | 7.58 × 1010 |
| F15 | 3.33 × 103 | 4.07 × 103 | 4.13 × 103 | 3.53 × 103 | 2.81 × 103 | 1.11 × 104 | 1.09 × 104 | 1.12 × 104 | 1.17 × 104 | 1.07 × 104 | 3.71 × 103 | 3.33 × 103 | 1.07 × 104 | 1.05 × 104 | 1.05 × 104 | 1.08 × 104 | 1.14 × 104 | 1.21 × 104 |
| F16 | 1.89 × 102 | 2.56 × 102 | 2.56 × 102 | 2.22 × 102 | 1.47 × 102 | 8.35 × 101 | 5.10 × 101 | 6.61 × 101 | 2.58 × 102 | 6.10 × 10−1 | 1.60 × 101 | 2.71 × 101 | 6.75 × 100 | 3.42 × 10−2 | 2.93 × 10−13 | 1.35 × 101 | 2.52 × 102 | 3.39 × 102 |
| F17 | 3.02 × 105 | 1.61 × 106 | 1.71 × 106 | 1.27 × 106 | 3.52 × 104 | 1.06 × 104 | 2.08 × 106 | 9.92 × 106 | 1.40 × 107 | 4.93 × 104 | 9.98 × 104 | 2.77 × 105 | 2.24 × 104 | 1.18 × 105 | 6.85 × 106 | 1.08 × 107 | 1.47 × 107 | 1.80 × 107 |
| F18 | 1.70 × 104 | 7.87 × 108 | 1.16 × 109 | 3.75 × 107 | 2.67 × 103 | 1.71 × 103 | 2.72 × 103 | 6.17 × 106 | 4.49 × 1010 | 1.95 × 103 | 2.54 × 103 | 3.90 × 103 | 1.66 × 103 | 1.30 × 103 | 1.59 × 103 | 1.71 × 107 | 2.95 × 1010 | 1.40 × 1011 |
| F19 | 2.34 × 106 | 4.66 × 106 | 4.74 × 106 | 3.92 × 106 | 1.72 × 106 | 6.52 × 106 | 1.48 × 107 | 2.01 × 107 | 2.49 × 107 | 9.10 × 106 | 2.46 × 106 | 2.41 × 106 | 5.98 × 106 | 1.09 × 107 | 1.60 × 107 | 2.09 × 107 | 2.58 × 107 | 3.04 × 107 |
| F20 | 8.41 × 103 | 1.01 × 109 | 1.39 × 109 | 4.32 × 107 | 2.93 × 103 | 1.29 × 103 | 1.25 × 103 | 7.61 × 106 | 4.93 × 1010 | 1.41 × 103 | 2.13 × 103 | 2.72 × 103 | 1.51 × 103 | 1.10 × 103 | 1.02 × 103 | 2.27 × 107 | 3.25 × 1010 | 1.47 × 1011 |
| Rank | 3.75 | 6.35 | 7.05 | 5.30 | 2.80 | 2.45 | 3.25 | 5.75 | 8.30 | 3.25 | 4.25 | 5.25 | 3.15 | 2.45 | 3.95 | 6.25 | 7.70 | 8.75 |
| F | NP = 300 | NP = 400 | ||||||||||||||||
| ϕ = 0.1 | ϕ = 0.2 | ϕ = 0.3 | ϕ = 0.4 | ϕ = 0.5 | ϕ = 0.6 | ϕ = 0.7 | ϕ = 0.8 | ϕ = 0.9 | ϕ = 0.1 | ϕ = 0.2 | ϕ = 0.3 | ϕ = 0.4 | ϕ = 0.5 | ϕ = 0.6 | ϕ = 0.7 | ϕ = 0.8 | ϕ = 0.9 | |
| F1 | 9.78 × 10−27 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 7.97 × 10−10 | 5.83 × 105 | 1.86 × 108 | 2.23 × 109 | 6.50 × 10−24 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 8.36 × 10−24 | 4.18 × 10−3 | 3.39 × 106 | 3.30 × 108 | 3.01 × 109 |
| F2 | 6.93 × 102 | 1.06 × 103 | 1.15 × 103 | 8.88 × 102 | 5.90 × 102 | 1.04 × 104 | 1.09 × 104 | 1.15 × 104 | 1.21 × 104 | 5.75 × 102 | 8.12 × 102 | 8.78 × 102 | 6.57 × 102 | 9.82 × 103 | 1.05 × 104 | 1.10 × 104 | 1.16 × 104 | 1.22 × 104 |
| F3 | 3.36 × 10−14 | 3.05 × 10−14 | 3.15 × 10−14 | 3.18 × 10−14 | 3.88 × 10−14 | 1.15 × 10−7 | 5.14 × 100 | 1.47 × 101 | 1.77 × 101 | 3.51 × 10−14 | 2.99 × 10−14 | 2.98 × 10−14 | 3.15 × 10−14 | 3.98 × 10−14 | 3.29 × 10−4 | 7.64 × 100 | 1.54 × 101 | 1.79 × 101 |
| F4 | 2.22 × 1011 | 2.13 × 1011 | 2.00 × 1011 | 1.60 × 1011 | 1.57 × 1011 | 2.06 × 1011 | 3.80 × 1011 | 1.31 × 1012 | 6.16 × 1013 | 2.88 × 1011 | 2.60 × 1011 | 2.27 × 1011 | 1.96 × 1011 | 1.82 × 1011 | 2.48 × 1011 | 5.19 × 1011 | 3.12 × 1012 | 1.09 × 1014 |
| F5 | 2.83 × 108 | 2.81 × 108 | 2.76 × 108 | 2.80 × 108 | 2.82 × 108 | 2.86 × 108 | 2.93 × 108 | 3.02 × 108 | 3.18 × 108 | 2.82 × 108 | 2.82 × 108 | 2.81 × 108 | 2.78 × 108 | 2.83 × 108 | 2.89 × 108 | 2.94 × 108 | 3.06 × 108 | 3.16 × 108 |
| F6 | 4.00 × 10−9 | 6.18 × 100 | 1.86 × 101 | 4.00 × 10−9 | 4.00 × 10−9 | 2.08 × 10−7 | 5.36 × 100 | 1.54 × 101 | 1.84 × 101 | 4.00 × 10−9 | 3.88 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.72 × 10−4 | 8.08 × 100 | 1.61 × 101 | 1.86 × 101 |
| F7 | 3.43 × 10−3 | 1.20 × 10−3 | 3.63 × 10−2 | 2.15 × 10−5 | 2.54 × 10−3 | 3.60 × 102 | 1.83 × 105 | 9.66 × 105 | 4.68 × 108 | 8.32 × 10−1 | 3.50 × 10−2 | 3.16 × 10−2 | 7.06 × 10−3 | 1.03 × 100 | 7.18 × 103 | 3.40 × 105 | 5.23 × 106 | 1.55 × 109 |
| F8 | 1.37 × 107 | 3.51 × 105 | 3.72 × 104 | 4.36 × 103 | 9.82 × 105 | 3.01 × 107 | 4.30 × 107 | 4.58 × 107 | 4.65 × 107 | 2.23 × 107 | 1.00 × 107 | 3.36 × 106 | 6.67 × 105 | 1.33 × 107 | 3.52 × 107 | 4.41 × 107 | 4.61 × 107 | 4.67 × 107 |
| F9 | 2.47 × 107 | 2.28 × 107 | 2.49 × 107 | 1.77 × 107 | 2.14 × 107 | 1.69 × 108 | 1.40 × 1010 | 3.19 × 1010 | 5.08 × 1010 | 3.12 × 107 | 2.42 × 107 | 2.41 × 107 | 2.01 × 107 | 3.01 × 107 | 1.36 × 109 | 1.92 × 1010 | 3.70 × 1010 | 5.55 × 1010 |
| F10 | 8.49 × 102 | 1.13 × 103 | 1.22 × 103 | 9.23 × 102 | 9.75 × 103 | 1.05 × 104 | 1.09 × 104 | 1.15 × 104 | 1.22 × 104 | 9.74 × 103 | 8.59 × 102 | 9.25 × 102 | 1.11 × 103 | 1.02 × 104 | 1.05 × 104 | 1.10 × 104 | 1.16 × 104 | 1.22 × 104 |
| F11 | 1.25 × 10−13 | 2.23 × 10−1 | 6.68 × 100 | 1.10 × 10−13 | 1.17 × 10−13 | 3.45 × 10−7 | 8.82 × 100 | 7.59 × 101 | 1.59 × 102 | 1.30 × 10−13 | 1.11 × 10−13 | 1.05 × 10−13 | 1.06 × 10−13 | 1.31 × 10−13 | 7.60 × 10−4 | 1.51 × 101 | 9.53 × 101 | 1.67 × 102 |
| F12 | 2.50 × 104 | 4.39 × 103 | 5.55 × 103 | 2.55 × 103 | 8.74 × 104 | 4.13 × 106 | 5.75 × 106 | 7.14 × 106 | 8.45 × 106 | 1.71 × 105 | 9.83 × 103 | 7.41 × 103 | 1.18 × 104 | 2.03 × 106 | 4.62 × 106 | 6.16 × 106 | 7.49 × 106 | 8.77 × 106 |
| F13 | 5.69 × 102 | 5.35 × 102 | 5.91 × 102 | 5.15 × 102 | 4.69 × 102 | 4.85 × 102 | 1.08 × 105 | 5.63 × 108 | 1.67 × 1010 | 5.31 × 102 | 5.36 × 102 | 5.46 × 102 | 4.93 × 102 | 4.50 × 102 | 4.80 × 102 | 3.72 × 105 | 1.46 × 109 | 2.23 × 1010 |
| F14 | 7.79 × 107 | 6.96 × 107 | 7.62 × 107 | 5.17 × 107 | 7.69 × 107 | 5.73 × 109 | 3.85 × 1010 | 6.50 × 1010 | 8.96 × 1010 | 1.14 × 108 | 7.11 × 107 | 7.20 × 107 | 6.01 × 107 | 1.43 × 108 | 1.68 × 1010 | 4.63 × 1010 | 7.22 × 1010 | 9.64 × 1010 |
| F15 | 1.04 × 104 | 1.05 × 104 | 1.05 × 104 | 1.04 × 104 | 1.03 × 104 | 1.06 × 104 | 1.10 × 104 | 1.16 × 104 | 1.22 × 104 | 1.04 × 104 | 1.03 × 104 | 1.04 × 104 | 1.03 × 104 | 1.03 × 104 | 1.06 × 104 | 1.11 × 104 | 1.17 × 104 | 1.23 × 104 |
| F16 | 2.15 × 10−13 | 5.86 × 10−2 | 9.78 × 10−2 | 1.55 × 10−13 | 2.01 × 10−13 | 2.36 × 10−6 | 1.02 × 102 | 2.92 × 102 | 3.52 × 102 | 2.39 × 10−13 | 1.61 × 10−13 | 1.53 × 10−13 | 1.60 × 10−13 | 2.44 × 10−13 | 7.14 × 10−3 | 1.52 × 102 | 3.07 × 102 | 3.57 × 102 |
| F17 | 1.53 × 106 | 5.71 × 104 | 5.65 × 104 | 6.57 × 104 | 4.44 × 106 | 8.75 × 106 | 1.28 × 107 | 1.65 × 107 | 1.98 × 107 | 4.81 × 106 | 1.72 × 105 | 1.03 × 105 | 7.07 × 105 | 6.20 × 106 | 1.02 × 107 | 1.37 × 107 | 1.72 × 107 | 2.06 × 107 |
| F18 | 1.56 × 103 | 1.65 × 103 | 1.56 × 103 | 1.31 × 103 | 1.13 × 103 | 1.26 × 103 | 1.57 × 109 | 5.42 × 1010 | 1.76 × 1011 | 1.31 × 103 | 1.31 × 103 | 1.33 × 103 | 1.25 × 103 | 1.12 × 103 | 3.88 × 103 | 4.92 × 109 | 6.87 × 1010 | 1.94 × 1011 |
| F19 | 1.33 × 107 | 8.92 × 106 | 8.14 × 106 | 1.02 × 107 | 1.43 × 107 | 1.88 × 107 | 2.25 × 107 | 2.75 × 107 | 3.21 × 107 | 1.45 × 107 | 1.09 × 107 | 1.02 × 107 | 1.21 × 107 | 1.53 × 107 | 1.94 × 107 | 2.47 × 107 | 2.87 × 107 | 3.36 × 107 |
| F20 | 1.12 × 103 | 1.32 × 103 | 1.40 × 103 | 1.08 × 103 | 9.79 × 102 | 1.00 × 103 | 1.88 × 109 | 5.74 × 1010 | 1.82 × 1011 | 9.89 × 102 | 1.15 × 103 | 1.10 × 103 | 9.85 × 102 | 9.82 × 102 | 1.72 × 103 | 5.69 × 109 | 7.40 × 1010 | 2.03 × 1011 |
| Rank | 3.80 | 3.48 | 4.03 | 2.03 | 2.88 | 5.00 | 6.90 | 7.95 | 8.95 | 3.90 | 2.90 | 2.50 | 2.05 | 3.95 | 5.70 | 7.00 | 8.00 | 9.00 |
| F | NP = 500 | NP = 600 | ||||||||||||||||
| ϕ = 0.1 | ϕ = 0.2 | ϕ = 0.3 | ϕ = 0.4 | ϕ = 0.5 | ϕ = 0.6 | ϕ = 0.7 | ϕ = 0.8 | ϕ = 0.9 | ϕ = 0.1 | ϕ = 0.2 | ϕ = 0.3 | ϕ = 0.4 | ϕ = 0.5 | ϕ = 0.6 | ϕ = 0.7 | ϕ = 0.8 | ϕ = 0.9 | |
| F1 | 8.02 × 10−22 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 6.91 × 10−21 | 4.51 × 100 | 8.52 × 106 | 4.72 × 108 | 3.65 × 109 | 2.72 × 10−19 | 2.86 × 10−26 | 0.00 × 100 | 5.33 × 10−26 | 9.43 × 10−16 | 1.90 × 102 | 1.57 × 107 | 6.02 × 108 | 4.18 × 109 |
| F2 | 8.73 × 103 | 6.81 × 102 | 7.34 × 102 | 5.74 × 102 | 1.01 × 104 | 1.06 × 104 | 1.11 × 104 | 1.16 × 104 | 1.23 × 104 | 9.87 × 103 | 6.03 × 102 | 6.59 × 102 | 4.15 × 103 | 1.02 × 104 | 1.06 × 104 | 1.11 × 104 | 1.17 × 104 | 1.23 × 104 |
| F3 | 3.92 × 10−14 | 2.96 × 10−14 | 2.90 × 10−14 | 3.12 × 10−14 | 8.55 × 10−14 | 1.24 × 10−2 | 9.15 × 100 | 1.58 × 101 | 1.80 × 101 | 8.00 × 10−13 | 2.97 × 10−14 | 2.90 × 10−14 | 3.16 × 10−14 | 6.07 × 10−11 | 1.06 × 10−1 | 1.02 × 101 | 1.61 × 101 | 1.82 × 101 |
| F4 | 3.35 × 1011 | 3.11 × 1011 | 2.86 × 1011 | 2.49 × 1011 | 2.16 × 1011 | 3.21 × 1011 | 6.31 × 1011 | 1.05 × 1013 | 1.22 × 1014 | 4.16 × 1011 | 3.83 × 1011 | 3.30 × 1011 | 2.84 × 1011 | 2.67 × 1011 | 3.79 × 1011 | 7.59 × 1011 | 1.73 × 1013 | 1.39 × 1014 |
| F5 | 2.80 × 108 | 2.76 × 108 | 2.78 × 108 | 2.77 × 108 | 2.77 × 108 | 2.90 × 108 | 2.95 × 108 | 3.06 × 108 | 3.20 × 108 | 2.80 × 108 | 2.79 × 108 | 2.76 × 108 | 2.79 × 108 | 2.84 × 108 | 2.87 × 108 | 2.99 × 108 | 3.03 × 108 | 3.18 × 108 |
| F6 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 1.69 × 10−2 | 9.72 × 100 | 1.66 × 101 | 1.88 × 101 | 4.09 × 10−9 | 3.88 × 10−9 | 3.88 × 10−9 | 4.00 × 10−9 | 6.07 × 10−9 | 1.45 × 10−1 | 1.08 × 101 | 1.68 × 101 | 1.89 × 101 |
| F7 | 2.61 × 101 | 1.21 × 100 | 7.81 × 10−1 | 4.75 × 10−1 | 3.43 × 101 | 3.08 × 104 | 4.80 × 105 | 3.01 × 107 | 2.65 × 109 | 2.63 × 102 | 1.79 × 101 | 1.21 × 101 | 8.88 × 100 | 3.52 × 102 | 7.34 × 104 | 6.46 × 105 | 1.15 × 108 | 3.95 × 109 |
| F8 | 2.74 × 107 | 1.73 × 107 | 1.16 × 107 | 9.50 × 106 | 2.05 × 107 | 3.79 × 107 | 4.47 × 107 | 4.63 × 107 | 4.68 × 107 | 3.08 × 107 | 2.23 × 107 | 1.74 × 107 | 1.59 × 107 | 2.52 × 107 | 3.96 × 107 | 4.50 × 107 | 4.64 × 107 | 4.69 × 107 |
| F9 | 3.94 × 107 | 2.71 × 107 | 2.62 × 107 | 2.33 × 107 | 4.11 × 107 | 4.17 × 109 | 2.23 × 1010 | 4.01 × 1010 | 5.87 × 1010 | 4.84 × 107 | 3.01 × 107 | 2.85 × 107 | 2.62 × 107 | 5.78 × 107 | 6.49 × 109 | 2.49 × 1010 | 4.26 × 1010 | 6.14 × 1010 |
| F10 | 1.00 × 104 | 1.35 × 103 | 7.94 × 102 | 9.73 × 103 | 1.02 × 104 | 1.06 × 104 | 1.11 × 104 | 1.17 × 104 | 1.23 × 104 | 1.02 × 104 | 9.45 × 103 | 6.43 × 103 | 9.99 × 103 | 1.03 × 104 | 1.06 × 104 | 1.11 × 104 | 1.17 × 104 | 1.24 × 104 |
| F11 | 1.67 × 10−13 | 1.11 × 10−13 | 1.04 × 10−13 | 1.10 × 10−13 | 5.51 × 10−13 | 2.59 × 10−2 | 1.94 × 101 | 1.08 × 102 | 1.72 × 102 | 6.69 × 10−12 | 1.12 × 10−13 | 1.05 × 10−13 | 1.13 × 10−13 | 4.00 × 10−10 | 1.90 × 10−1 | 2.66 × 101 | 1.17 × 102 | 1.75 × 102 |
| F12 | 1.54 × 106 | 2.34 × 104 | 1.47 × 104 | 4.12 × 104 | 3.02 × 106 | 4.87 × 106 | 6.37 × 106 | 7.75 × 106 | 9.01 × 106 | 2.65 × 106 | 4.99 × 104 | 2.82 × 104 | 1.18 × 105 | 3.37 × 106 | 5.07 × 106 | 6.50 × 106 | 7.83 × 106 | 9.11 × 106 |
| F13 | 5.27 × 102 | 4.92 × 102 | 4.67 × 102 | 4.65 × 102 | 4.69 × 102 | 4.80 × 102 | 1.08 × 106 | 2.45 × 109 | 2.62 × 1010 | 4.82 × 102 | 5.44 × 102 | 5.20 × 102 | 4.56 × 102 | 4.42 × 102 | 5.63 × 102 | 3.15 × 106 | 3.37 × 109 | 2.90 × 1010 |
| F14 | 1.66 × 108 | 8.14 × 107 | 7.67 × 107 | 7.21 × 107 | 3.28 × 108 | 2.36 × 1010 | 5.14 × 1010 | 7.78 × 1010 | 1.30 × 1011 | 2.61 × 108 | 9.02 × 107 | 8.54 × 107 | 8.71 × 107 | 8.67 × 108 | 2.77 × 1010 | 5.44 × 1010 | 7.81 × 1010 | 1.03 × 1011 |
| F15 | 1.03 × 104 | 1.03 × 104 | 1.03 × 104 | 1.03 × 104 | 1.03 × 104 | 1.07 × 104 | 1.11 × 104 | 1.17 × 104 | 1.24 × 104 | 1.03 × 104 | 1.03 × 104 | 1.03 × 104 | 1.03 × 104 | 1.03 × 104 | 1.07 × 104 | 1.12 × 104 | 1.17 × 104 | 1.24 × 104 |
| F16 | 2.83 × 10−13 | 1.65 × 10−13 | 1.55 × 10−13 | 1.66 × 10−13 | 1.34 × 10−12 | 2.74 × 10−1 | 1.83 × 102 | 3.16 × 102 | 3.61 × 102 | 1.54 × 10−11 | 1.74 × 10−13 | 1.58 × 10−13 | 1.80 × 10−13 | 1.18 × 10−9 | 2.41 × 100 | 2.05 × 102 | 3.22 × 102 | 3.63 × 102 |
| F17 | 5.98 × 106 | 7.91 × 105 | 2.80 × 105 | 3.07 × 106 | 7.05 × 106 | 1.07 × 107 | 1.43 × 107 | 1.76 × 107 | 2.10 × 107 | 6.68 × 106 | 2.56 × 106 | 1.14 × 106 | 4.24 × 106 | 7.51 × 106 | 1.11 × 107 | 1.44 × 107 | 1.81 × 107 | 2.12 × 107 |
| F18 | 1.18 × 103 | 1.26 × 103 | 1.18 × 103 | 1.13 × 103 | 1.00 × 103 | 1.10 × 105 | 8.30 × 109 | 7.98 × 1010 | 2.08 × 1011 | 1.08 × 103 | 1.22 × 103 | 1.22 × 103 | 1.05 × 103 | 9.59 × 102 | 1.41 × 106 | 1.12 × 1010 | 8.67 × 1010 | 2.19 × 1011 |
| F19 | 1.55 × 107 | 1.23 × 107 | 1.15 × 107 | 1.31 × 107 | 1.64 × 107 | 2.02 × 107 | 2.50 × 107 | 2.92 × 107 | 3.32 × 107 | 1.62 × 107 | 1.31 × 107 | 1.23 × 107 | 1.40 × 107 | 1.72 × 107 | 2.06 × 107 | 2.48 × 107 | 2.97 × 107 | 3.49 × 107 |
| F20 | 9.94 × 102 | 1.02 × 103 | 1.06 × 103 | 9.70 × 102 | 9.78 × 102 | 1.10 × 10 | 9.17 × 109 | 8.52 × 1010 | 2.20 × 1011 | 9.91 × 102 | 9.85 × 102 | 9.94 × 102 | 9.77 × 102 | 9.86 × 102 | 1.53 × 106 | 1.28 × 1010 | 9.33 × 1010 | 2.30 × 1011 |
| Rank | 4.25 | 2.75 | 2.00 | 2.00 | 4.15 | 5.85 | 7.00 | 8.00 | 9.00 | 4.10 | 2.65 | 1.85 | 2.30 | 4.20 | 5.90 | 7.00 | 8.00 | 9.00 |
| F | Quality | DGCELSO | TPLSO | SPLSO | LLSO | CSO | SLPSO | DECC-GDG | DECC-DG2 | DECC-RDG | DECC-RDG2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Median | 0.00 × 100 | 1.98 × 10−18 | 7.70 × 10−20 | 2.97 × 10−22 | 4.64 × 10−12 | 7.65 × 10−18 | 6.53 × 100 | 1.95 × 10−1 | 2.60 × 10−3 | 1.05 × 10−3 |
| Mean | 0.00 × 100 | 1.93 × 10−18 | 7.73 × 10−20 | 3.13 × 10−22 | 4.75 × 10−12 | 7.73 × 10−18 | 6.54 × 100 | 7.34 × 10−1 | 6.42 × 100 | 8.08 × 10−3 | |
| Std | 0.00 × 100 | 3.04 × 10−19 | 6.95 × 10−21 | 6.93 × 10−23 | 7.77 × 10−13 | 8.84 × 10−19 | 9.35 × 10−1 | 1.61 × 100 | 3.41 × 101 | 3.28 × 10−2 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F2 | Median | 8.85 × 102 | 1.13 × 103 | 4.45 × 102 | 9.71 × 102 | 7.52 × 103 | 1.94 × 103 | 1.40 × 103 | 3.00 × 103 | 2.98 × 103 | 2.99 × 103 |
| Mean | 8.88 × 102 | 1.11 × 103 | 4.45 × 102 | 9.78 × 102 | 7.48 × 103 | 1.93 × 103 | 1.40 × 103 | 3.00 × 103 | 2.98 × 103 | 3.00 × 103 | |
| Std | 4.13 × 101 | 8.28 × 101 | 1.63 × 101 | 5.17 × 101 | 2.60 × 102 | 8.05 × 101 | 2.67 × 101 | 1.34 × 102 | 1.16 × 102 | 1.35 × 102 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8− | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F3 | Median | 3.24 × 10−14 | 1.44 × 100 | 2.56 × 10−13 | 2.89 × 10−14 | 2.56 × 10−9 | 1.88 × 100 | 1.12 × 101 | 1.08 × 101 | 1.12 × 101 | 1.11 × 101 |
| Mean | 3.18 × 10−14 | 1.45 × 100 | 2.52 × 10−13 | 2.76 × 10−14 | 2.57 × 10−9 | 1.84 × 100 | 1.11 × 101 | 1.09 × 101 | 1.11 × 101 | 1.10 × 101 | |
| Std | 1.32 × 10−15 | 1.34 × 10−1 | 1.86 × 10−14 | 2.16 × 10−15 | 1.82 × 10−10 | 2.62 × 10−1 | 5.69 × 10−1 | 6.40 × 10−1 | 6.46 × 10−1 | 6.88 × 10−1 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8− | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F4 | Median | 1.58 × 1011 | 2.77 × 1011 | 4.36 × 1011 | 4.48 × 1011 | 6.92 × 1011 | 2.68 × 1011 | 1.37 × 1014 | 1.44 × 1012 | 1.39 × 1012 | 1.37 × 1012 |
| Mean | 1.60 × 1011 | 2.89 × 1011 | 4.30 × 1011 | 4.54 × 1011 | 6.87 × 1011 | 2.83 × 1011 | 1.38 × 1014 | 1.69 × 1012 | 1.49 × 1012 | 1.44 × 1012 | |
| Std | 3.72 × 1010 | 9.22 × 1010 | 8.17 × 1010 | 1.29 × 1011 | 1.76 × 1011 | 8.77 × 1010 | 2.68 × 1013 | 6.16 × 1011 | 6.33 × 1011 | 5.35 × 1011 | |
| p-value | - | 1.00 × 100= | 3.49 × 10−3+ | 4.32 × 10−8+ | 1.02 × 10−3+ | 3.19 × 10−7+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 3.19 × 10−7+ | |
| F5 | Median | 2.82 × 108 | 1.63 × 107 | 5.97 × 106 | 1.09 × 107 | 2.00 × 106 | 2.89 × 107 | 3.84 × 108 | 1.72 × 108 | 1.75 × 108 | 1.72 × 108 |
| Mean | 2.80 × 108 | 1.59 × 107 | 6.30 × 106 | 1.16 × 107 | 2.46 × 106 | 3.04 × 107 | 3.82 × 108 | 1.75 × 108 | 1.71 × 108 | 1.73 × 108 | |
| Std | 9.11 × 106 | 4.51 × 106 | 1.73 × 106 | 2.93 × 106 | 1.33 × 106 | 8.42 × 106 | 1.54 × 107 | 1.84 × 107 | 1.84 × 107 | 1.50 × 107 | |
| p-value | - | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8+ | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | |
| F6 | Median | 4.00 × 10−9 | 2.08 × 100 | 1.00 × 10−8 | 4.00 × 10−9 | 8.18 × 10−7 | 2.14 × 101 | 3.51 × 105 | 8.81 × 100 | 1.07 × 101 | 1.06 × 101 |
| Mean | 4.00 × 10−9 | 2.20 × 100 | 9.44 × 10−9 | 4.00 × 10−9 | 8.16 × 10−7 | 1.95 × 101 | 3.58 × 105 | 8.90 × 100 | 1.05 × 101 | 1.05 × 101 | |
| Std | 3.73 × 10−15 | 3.74 × 10−1 | 1.18 × 10−9 | 8.27 × 10−25 | 2.57 × 10−8 | 4.13 × 100 | 4.27 × 104 | 6.50 × 10−1 | 7.02 × 10−1 | 6.84 × 10−1 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8− | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F7 | Median | 1.89 × 10−5 | 9.21 × 102 | 4.51 × 102 | 6.58 × 100 | 2.13 × 104 | 6.26 × 104 | 2.98 × 1010 | 1.80 × 103 | 4.86 × 101 | 5.18 × 101 |
| Mean | 2.15 × 10−5 | 5.86 × 103 | 4.76 × 102 | 2.31 × 101 | 2.13 × 104 | 6.49 × 104 | 3.10 × 1010 | 1.98 × 103 | 6.40 × 101 | 5.87 × 101 | |
| Std | 1.55 × 10−5 | 1.03 × 104 | 1.29 × 102 | 7.45 × 101 | 4.53 × 103 | 3.81 × 104 | 4.19 × 109 | 9.49 × 102 | 4.67 × 101 | 3.71 × 101 | |
| p-value | - | 2.07 × 10−6+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F8 | Median | 4.28 × 103 | 4.78 × 105 | 3.11 × 107 | 2.33 × 107 | 3.86 × 107 | 7.51 × 106 | 6.78 × 108 | 6.05 × 102 | 6.57 × 10−1 | 3.68 × 10−1 |
| Mean | 4.36 × 103 | 4.98 × 105 | 3.11 × 107 | 2.33 × 107 | 3.87 × 107 | 7.57 × 106 | 8.05 × 108 | 2.71 × 105 | 6.65 × 105 | 7.43 × 10−1 | |
| Std | 4.17 × 102 | 1.43 × 105 | 9.43 × 104 | 2.96 × 105 | 8.47 × 104 | 2.44 × 106 | 4.70 × 108 | 9.94 × 105 | 1.49 × 106 | 1.24 × 100 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F9 | Median | 1.76 × 107 | 4.25 × 107 | 4.57 × 107 | 4.64 × 107 | 6.65 × 107 | 3.31 × 107 | 7.45 × 108 | 2.15 × 108 | 1.76 × 108 | 1.77 × 108 |
| Mean | 1.77 × 107 | 4.32 × 107 | 4.59 × 107 | 4.48 × 107 | 6.68 × 107 | 3.35 × 107 | 7.43 × 108 | 2.18 × 108 | 1.73 × 108 | 1.77 × 108 | |
| Std | 1.69 × 106 | 4.10 × 106 | 2.99 × 106 | 4.16 × 106 | 4.38 × 106 | 3.63 × 106 | 3.71 × 107 | 1.73 × 107 | 1.22 × 107 | 1.66 × 107 | |
| p-value | - | 4.32 × 10−8+ | 1.00 × 100= | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F10 | Median | 9.18 × 102 | 9.67 × 102 | 7.99 × 103 | 8.87 × 102 | 9.58 × 103 | 2.59 × 103 | 4.16 × 103 | 6.73 × 103 | 6.32 × 103 | 6.27 × 103 |
| Mean | 9.23 × 102 | 9.84 × 102 | 7.99 × 103 | 8.88 × 102 | 9.58 × 103 | 2.79 × 103 | 4.15 × 103 | 6.72 × 103 | 6.32 × 103 | 6.27 × 103 | |
| Std | 3.82 × 101 | 8.52 × 101 | 1.25 × 102 | 3.50 × 101 | 6.49 × 101 | 1.28 × 103 | 5.70 × 101 | 9.30 × 101 | 1.12 × 102 | 1.09 × 102 | |
| p-value | - | 1.06 × 10−2+ | 4.32 × 10−8+ | 4.32 × 10−8− | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F11 | Median | 1.11 × 10−13 | 3.48 × 100 | 3.02 × 10−12 | 2.90 × 100 | 3.98 × 10−8 | 2.37 × 101 | 5.58 × 100 | 5.39 × 100 | 4.76 × 100 | 4.86 × 100 |
| Mean | 1.10 × 10−13 | 3.50 × 100 | 3.05 × 10−12 | 5.51 × 100 | 3.98 × 10−8 | 2.42 × 101 | 5.53 × 100 | 5.59 × 100 | 4.75 × 100 | 4.86 × 100 | |
| Std | 2.36 × 10−15 | 1.30 × 100 | 2.84 × 10−13 | 5.43 × 100 | 3.19 × 10−9 | 3.03 × 100 | 5.49 × 10−1 | 6.12 × 10−1 | 4.79 × 10−1 | 3.88 × 10−1 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F12 | Median | 2.55 × 103 | 1.23 × 104 | 9.39 × 104 | 1.24 × 104 | 4.25 × 105 | 1.30 × 104 | 2.87 × 105 | 3.99 × 104 | 2.22 × 104 | 2.21 × 104 |
| Mean | 2.55 × 103 | 1.23 × 104 | 9.53 × 104 | 1.23 × 104 | 4.37 × 105 | 1.54 × 104 | 2.87 × 105 | 3.94 × 104 | 2.21 × 104 | 2.19 × 104 | |
| Std | 2.13 × 102 | 1.30 × 103 | 6.64 × 103 | 1.32 × 103 | 6.49 × 104 | 7.06 × 103 | 1.10 × 104 | 2.17 × 103 | 1.28 × 103 | 1.45 × 103 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 3.19 × 10−7+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F13 | Median | 4.64 × 102 | 7.29 × 102 | 4.50 × 102 | 7.82 × 102 | 4.68 × 102 | 8.87 × 102 | 1.39 × 103 | 1.65 × 103 | 8.25 × 102 | 8.17 × 102 |
| Mean | 5.15 × 102 | 7.54 × 102 | 5.48 × 102 | 7.91 × 102 | 5.53 × 102 | 9.81 × 102 | 1.42 × 103 | 1.77 × 103 | 8.24 × 102 | 8.40 × 102 | |
| Std | 1.49 × 102 | 1.07 × 102 | 1.66 × 102 | 2.37 × 102 | 1.75 × 102 | 3.86 × 102 | 3.40 × 102 | 5.06 × 102 | 1.35 × 102 | 1.98 × 102 | |
| p-value | - | 5.90 × 10−5+ | 3.49 × 10−3+ | 4.32 × 10−8+ | 2.73 × 10−1= | 2.85 × 10−2+ | 3.49 × 10−3+ | 5.90 × 10−5+ | 1.18 × 10−5+ | 2.07 × 10−6+ | |
| F14 | Median | 5.10 × 107 | 1.29 × 108 | 1.61 × 108 | 1.23 × 108 | 2.46 × 108 | 8.61 × 107 | 8.59 × 108 | 8.71 × 108 | 7.19 × 108 | 7.18 × 108 |
| Mean | 5.17 × 107 | 1.32 × 108 | 1.60 × 108 | 1.22 × 108 | 2.46 × 108 | 8.55 × 107 | 8.64 × 108 | 8.60 × 108 | 7.23 × 108 | 7.25 × 108 | |
| Std | 2.76 × 106 | 9.33 × 106 | 8.42 × 106 | 6.41 × 106 | 1.29 × 107 | 7.57 × 106 | 3.30 × 107 | 4.17 × 107 | 3.65 × 107 | 3.44 × 107 | |
| p-value | - | 4.32 × 10−8+ | 2.07 × 10−6+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F15 | Median | 1.04 × 104 | 1.04 × 104 | 9.92 × 103 | 8.30 × 102 | 1.01 × 104 | 1.12 × 104 | 6.75 × 103 | 6.73 × 103 | 6.55 × 103 | 6.56 × 103 |
| Mean | 1.04 × 104 | 8.88 × 103 | 9.91 × 103 | 8.97 × 102 | 1.01 × 104 | 1.12 × 104 | 6.76 × 103 | 6.73 × 103 | 6.55 × 103 | 6.55 × 103 | |
| Std | 6.65 × 101 | 3.41 × 103 | 6.31 × 101 | 3.47 × 102 | 6.48 × 101 | 1.19 × 102 | 8.82 × 101 | 7.27 × 101 | 8.86 × 101 | 8.39 × 101 | |
| p-value | - | 1.44 × 10−1= | 4.32 × 10−8− | 4.32 × 10−8− | 1.06 × 10−2− | 4.32 × 10−8+ | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | |
| F16 | Median | 1.55 × 10−13 | 1.78 × 101 | 4.66 × 10−12 | 4.40 × 100 | 5.64 × 10−8 | 2.12 × 101 | 3.98 × 10−4 | 3.89 × 10−4 | 1.92 × 10−5 | 1.88 × 10−5 |
| Mean | 1.55 × 10−13 | 1.89 × 101 | 4.68 × 10−12 | 4.33 × 100 | 5.68 × 10−8 | 2.36 × 101 | 3.97 × 10−4 | 3.90 × 10−4 | 1.93 × 10−5 | 1.89 × 10−5 | |
| Std | 2.66 × 10−15 | 7.46 × 100 | 4.41 × 10−13 | 2.50 × 100 | 6.21 × 10−9 | 1.11 × 101 | 1.44 × 10−5 | 1.33 × 10−5 | 8.87 × 10−7 | 8.30 × 10−7 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F17 | Median | 6.70 × 104 | 9.65 × 104 | 6.90 × 105 | 9.17 × 104 | 2.19 × 106 | 8.64 × 104 | 2.64 × 105 | 2.64 × 105 | 1.99 × 105 | 1.97 × 105 |
| Mean | 6.57 × 104 | 9.83 × 104 | 6.84 × 105 | 9.12 × 104 | 2.21 × 106 | 8.74 × 104 | 2.65 × 105 | 2.63 × 105 | 1.98 × 105 | 1.98 × 105 | |
| Std | 7.55 × 103 | 9.90 × 103 | 3.57 × 104 | 5.43 × 103 | 2.07 × 105 | 1.39 × 104 | 7.79 × 103 | 7.33 × 103 | 8.75 × 103 | 9.45 × 103 | |
| p-value | - | 4.32 × 10−8+ | 7.15 × 10−2+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F18 | Median | 1.25 × 103 | 2.29 × 103 | 1.25 × 103 | 2.49 × 103 | 1.38 × 103 | 2.95 × 103 | 1.15 × 103 | 1.14 × 103 | 1.08 × 103 | 1.11 × 103 |
| Mean | 1.31 × 103 | 2.36 × 103 | 1.35 × 103 | 2.51 × 103 | 1.64 × 103 | 2.92 × 103 | 1.16 × 103 | 1.13 × 103 | 1.07 × 103 | 1.10 × 103 | |
| Std | 2.94 × 102 | 4.19 × 102 | 3.81 × 102 | 7.42 × 102 | 8.13 × 102 | 8.08 × 102 | 1.31 × 102 | 1.29 × 102 | 1.08 × 102 | 1.02 × 102 | |
| p-value | - | 5.90 × 10−5+ | 3.49 × 10−3+ | 2.61 × 10−4+ | 2.73 × 10−1= | 2.85 × 10−2+ | 3.19 × 10−7− | 3.19 × 10−7− | 3.19 × 10−7− | 4.32 × 10−8− | |
| F19 | Median | 1.02 × 107 | 3.94 × 106 | 8.19 × 106 | 1.85 × 106 | 9.78 × 106 | 5.20 × 106 | 2.11 × 106 | 2.09 × 106 | 1.96 × 106 | 1.93 × 106 |
| Mean | 1.02 × 107 | 3.89 × 106 | 8.20 × 106 | 1.82 × 106 | 9.86 × 106 | 5.23 × 106 | 2.12 × 106 | 2.10 × 106 | 1.95 × 106 | 1.92 × 106 | |
| Std | 7.69 × 105 | 2.64 × 105 | 4.61 × 105 | 9.22 × 104 | 5.07 × 105 | 9.15 × 105 | 8.77 × 104 | 9.92 × 104 | 7.80 × 104 | 1.05 × 105 | |
| p-value | - | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | |
| F20 | Median | 1.06 × 103 | 2.04 × 103 | 9.79 × 102 | 1.88 × 103 | 9.87 × 102 | 1.73 × 103 | 5.43 × 103 | 5.33 × 103 | 4.32 × 103 | 4.25 × 103 |
| Mean | 1.08 × 103 | 2.08 × 103 | 1.06 × 103 | 1.92 × 103 | 1.07 × 103 | 1.73 × 103 | 5.45 × 103 | 5.46 × 103 | 4.28 × 103 | 4.34 × 103 | |
| Std | 7.30 × 101 | 2.00 × 102 | 1.75 × 102 | 3.00 × 102 | 1.70 × 102 | 1.53 × 102 | 3.32 × 102 | 3.37 × 102 | 2.29 × 102 | 3.20 × 102 | |
| p-value | - | 4.32 × 10−8+ | 5.90 × 10−5− | 4.32 × 10−8+ | 5.90 × 10−5− | 1.18 × 10−5+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| w/t/l | 16/2/2 | 14/1/5 | 15/0/5 | 15/2/3 | 18/0/2 | 17/0/3 | 16/0/4 | 16/0/4 | 16/0/4 | ||
| Rank | 2.75 | 4.80 | 4.65 | 3.70 | 6.25 | 6.05 | 8.20 | 7.10 | 5.85 | 5.65 | |
| F | Quality | DGCELSO | TPLSO | SPLSO | LLSO | CSO | SLPSO | DECC-GDG | DECC-DG2 | DECC-RDG | DECC-RDG2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Median | 0.00 × 100 | 3.21 × 10−18 | 1.17 × 10−19 | 4.02 × 10−22 | 7.92 × 10−12 | 1.03 × 10−17 | 7.06 × 100 | 3.46 × 100 | 2.04 × 10−2 | 2.96 × 10−2 |
| Mean | 0.00 × 100 | 3.81 × 10−18 | 1.18 × 10−19 | 4.28 × 10−22 | 7.88 × 10−12 | 1.65 × 10−17 | 7.43 × 100 | 6.31 × 100 | 3.51 × 10−2 | 1.08 × 10−1 | |
| Std | 0.00 × 100 | 1.57 × 10−18 | 1.04 × 10−20 | 1.29 × 10−22 | 1.19 × 10−12 | 3.25 × 10−17 | 9.38 × 10−1 | 7.78 × 100 | 3.88 × 10−2 | 2.08 × 10−1 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 9.63 × 10−7+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F2 | Median | 8.61 × 102 | 1.30 × 103 | 9.64 × 102 | 1.14 × 103 | 8.58 × 103 | 2.09 × 103 | 1.43 × 103 | 7.81 × 103 | 7.81 × 103 | 7.69 × 103 |
| Mean | 8.77 × 102 | 1.34 × 103 | 1.06 × 103 | 1.14 × 103 | 8.58 × 103 | 2.10 × 103 | 1.43 × 103 | 7.88 × 103 | 7.74 × 103 | 7.74 × 103 | |
| Std | 4.28 × 101 | 1.75 × 102 | 4.38 × 102 | 5.00 × 101 | 1.76 × 102 | 1.61 × 102 | 2.43 × 101 | 4.07 × 102 | 3.47 × 102 | 3.56 × 102 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F3 | Median | 2.16 × 101 | 2.22 × 101 | 2.16 × 101 | 2.16 × 101 | 2.16 × 101 | 2.16 × 101 | 2.15 × 101 | 2.15 × 101 | 2.14 × 101 | 2.15 × 101 |
| Mean | 2.16 × 101 | 2.31 × 101 | 2.16 × 101 | 2.16 × 101 | 2.16 × 101 | 2.16 × 101 | 2.15 × 101 | 2.15 × 101 | 2.14 × 101 | 2.15 × 101 | |
| Std | 6.26 × 10−3 | 1.72 × 100 | 7.11 × 10−15 | 7.11 × 10−15 | 7.11 × 10−15 | 2.37 × 10−1 | 3.00 × 10−2 | 4.23 × 10−2 | 4.82 × 10−2 | 4.90 × 10−2 | |
| p-value | - | 3.49 × 10−3+ | 2.61 × 10−4− | 2.61 × 10−4− | 2.07 × 10−6− | 7.15 × 10−1= | 4.65 × 10−1= | 4.65 × 10−1= | 7.15 × 10−1= | 7.15 × 10−1= | |
| F4 | Median | 2.55 × 109 | 4.23 × 109 | 9.14 × 109 | 6.40 × 109 | 1.22 × 1010 | 4.28 × 109 | 4.15 × 1011 | 8.12 × 1010 | 7.45 × 1010 | 6.10 × 1010 |
| Mean | 2.52 × 109 | 4.27 × 109 | 9.41 × 109 | 6.55 × 109 | 1.35 × 1010 | 4.33 × 109 | 4.20 × 1011 | 7.79 × 1010 | 7.16 × 1010 | 6.78 × 1010 | |
| Std | 6.55 × 108 | 1.03 × 109 | 1.86 × 109 | 1.40 × 109 | 3.12 × 109 | 9.91 × 108 | 7.75 × 1010 | 2.19 × 1010 | 1.92 × 1010 | 2.32 × 1010 | |
| p-value | - | 1.44 × 10−1= | 1.02 × 10−3+ | 1.06 × 10−2+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F5 | Median | 7.83 × 105 | 6.80 × 105 | 6.43 × 105 | 6.51 × 105 | 5.90 × 105 | 8.89 × 105 | 8.62 × 106 | 6.10 × 106 | 5.81 × 106 | 5.72 × 106 |
| Mean | 7.91 × 105 | 6.79 × 105 | 6.30 × 105 | 6.56 × 105 | 5.97 × 105 | 8.90 × 105 | 8.66 × 106 | 6.06 × 106 | 5.72 × 106 | 5.67 × 106 | |
| Std | 1.03 × 105 | 1.10 × 105 | 1.00 × 105 | 1.01 × 105 | 1.03 × 105 | 1.31 × 105 | 2.80 × 105 | 2.40 × 105 | 4.24 × 105 | 3.61 × 105 | |
| p-value | - | 1.06 × 10−2− | 1.18 × 10−5− | 3.49 × 10−3− | 2.61 × 10−4− | 2.85 × 10−2+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F6 | Median | 1.06 × 106 | 1.17 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 |
| Mean | 1.06 × 106 | 1.22 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | 1.06 × 106 | |
| Std | 1.27 × 103 | 1.61 × 105 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 3.00 × 103 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | |
| p-value | - | 5.90 × 10−5+ | 4.65 × 10−1= | 1.18 × 10−5− | 2.73 × 10−1= | 2.61 × 10−4− | 4.65 × 10−1= | 1.44 × 10−1= | 2.73 × 10−1= | 2.85 × 10−2− | |
| F7 | Median | 7.93 × 104 | 1.22 × 106 | 5.42 × 106 | 1.70 × 106 | 5.45 × 106 | 1.47 × 106 | 7.45 × 108 | 7.36 × 107 | 2.84 × 108 | 8.36 × 107 |
| Mean | 9.71 × 104 | 1.24 × 106 | 5.50 × 106 | 1.87 × 106 | 5.81 × 106 | 1.58 × 106 | 7.67 × 108 | 7.79 × 107 | 3.65 × 108 | 8.25 × 107 | |
| Std | 5.54 × 104 | 5.05 × 105 | 2.23 × 106 | 1.08 × 106 | 3.04 × 106 | 7.53 × 105 | 1.32 × 108 | 2.73 × 107 | 2.63 × 108 | 2.06 × 107 | |
| p-value | - | 1.18 × 10−5+ | 1.18 × 10−5+ | 4.32 × 10−8+ | 2.61 × 10−4+ | 3.19 × 10−7+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F8 | Median | 5.58 × 1013 | 7.07 × 1013 | 1.56 × 1014 | 1.37 × 1014 | 2.43 × 1014 | 9.65 × 1013 | 1.70 × 1016 | 9.35 × 1015 | 6.96 × 1015 | 5.83 × 1015 |
| Mean | 6.15 × 1013 | 7.28 × 1013 | 1.55 × 1014 | 1.36 × 1014 | 2.46 × 1014 | 1.09 × 1014 | 1.65 × 1016 | 9.32 × 1015 | 6.95 × 1015 | 6.38 × 1015 | |
| Std | 2.08 × 1013 | 4.02 × 1013 | 2.92 × 1013 | 3.39 × 1013 | 8.71 × 1013 | 5.44 × 1013 | 4.49 × 1015 | 2.71 × 1015 | 1.64 × 1015 | 1.99 × 1015 | |
| p-value | - | 5.90 × 10−5+ | 1.44 × 10−1= | 2.85 × 10−2− | 1.18 × 10−5− | 3.49 × 10−3− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | |
| F9 | Median | 4.67 × 107 | 4.52 × 107 | 7.23 × 107 | 1.11 × 108 | 5.94 × 107 | 8.05 × 107 | 5.62 × 108 | 5.55 × 108 | 5.40 × 108 | 5.32 × 108 |
| Mean | 4.47 × 107 | 4.28 × 107 | 8.08 × 107 | 1.29 × 108 | 6.08 × 107 | 7.99 × 107 | 5.61 × 108 | 5.59 × 108 | 5.38 × 108 | 5.31 × 108 | |
| Std | 1.37 × 107 | 7.49 × 106 | 2.21 × 107 | 8.85 × 107 | 1.29 × 107 | 1.18 × 107 | 3.24 × 107 | 2.93 × 107 | 3.03 × 107 | 2.33 × 107 | |
| p-value | - | 4.65 × 10−1= | 3.19 × 10−7+ | 4.32 × 10−8+ | 2.61 × 10−4+ | 3.19 × 10−7+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F10 | Median | 9.40 × 107 | 9.44 × 107 | 9.40 × 107 | 9.41 × 107 | 9.41 × 107 | 9.37 × 107 | 9.46 × 107 | 9.46 × 107 | 9.46 × 107 | 9.45 × 107 |
| Mean | 9.40 × 107 | 9.52 × 107 | 9.39 × 107 | 9.41 × 107 | 9.40 × 107 | 9.27 × 107 | 9.46 × 107 | 9.46 × 107 | 9.46 × 107 | 9.45 × 107 | |
| Std | 2.95 × 105 | 1.70 × 106 | 2.18 × 105 | 2.23 × 105 | 2.14 × 105 | 1.99 × 106 | 2.57 × 105 | 2.51 × 105 | 1.98 × 105 | 2.78 × 105 | |
| p-value | - | 1.02 × 10−3+ | 6.79 × 10−2= | 1.18 × 10−5+ | 2.07 × 10−6+ | 1.02 × 10−3− | 3.19 × 10−7+ | 3.19 × 10−7+ | 4.32 × 10−8+ | 2.07 × 10−6+ | |
| F11 | Median | 6.44 × 107 | 1.88 × 108 | 9.22 × 1011 | 9.23 × 1011 | 9.26 × 1011 | 9.38 × 1011 | 6.80 × 108 | 1.99 × 1010 | 5.75 × 108 | 1.33 × 1010 |
| Mean | 7.14 × 107 | 1.83 × 108 | 9.27 × 1011 | 9.28 × 1011 | 9.29 × 1011 | 9.34 × 1011 | 6.84 × 108 | 2.52 × 1010 | 5.68 × 108 | 1.49 × 1010 | |
| Std | 2.45 × 107 | 5.62 × 107 | 9.35 × 109 | 9.68 × 109 | 9.63 × 109 | 8.96 × 109 | 1.09 × 108 | 1.38 × 1010 | 9.23 × 107 | 7.57 × 109 | |
| p-value | - | 3.49 × 10−3+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 2.61 × 10−4+ | 4.32 × 10−8+ | 3.49 × 10−3+ | 4.32 × 10−8+ | |
| F12 | Median | 1.12 × 103 | 2.19 × 103 | 1.03 × 103 | 1.80 × 103 | 1.04 × 103 | 1.76 × 103 | 5.54 × 103 | 5.42 × 103 | 4.28 × 103 | 4.25 × 103 |
| Mean | 1.14 × 103 | 2.13 × 103 | 1.05 × 103 | 1.82 × 103 | 1.08 × 103 | 1.77 × 103 | 5.51 × 103 | 5.59 × 103 | 4.34 × 103 | 4.30 × 103 | |
| Std | 9.96 × 101 | 2.72 × 102 | 5.45 × 101 | 1.52 × 102 | 7.45 × 101 | 1.69 × 102 | 3.67 × 102 | 7.64 × 102 | 3.24 × 102 | 2.48 × 102 | |
| p-value | - | 4.32 × 10−8+ | 2.85 × 10−2− | 4.32 × 10−8+ | 1.00 × 100= | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | |
| F13 | Median | 4.89 × 107 | 2.01 × 108 | 1.20 × 109 | 2.98 × 108 | 7.08 × 108 | 4.01 × 108 | 1.56 × 109 | 1.43 × 109 | 2.87 × 109 | 7.08 × 108 |
| Mean | 6.40 × 107 | 2.21 × 108 | 1.20 × 109 | 3.42 × 108 | 7.48 × 108 | 5.20 × 108 | 1.50 × 109 | 1.47 × 109 | 2.98 × 109 | 7.17 × 108 | |
| Std | 5.35 × 107 | 1.24 × 108 | 4.91 × 108 | 1.42 × 108 | 2.85 × 108 | 4.85 × 108 | 3.35 × 108 | 3.46 × 108 | 7.23 × 108 | 1.57 × 108 | |
| p-value | - | 3.19 × 10−7+ | 1.00 × 100= | 4.32 × 10−8+ | 1.02 × 10−3+ | 4.32 × 10−8+ | 1.44 × 10−1= | 2.73 × 10−1= | 4.32 × 10−8+ | 3.49 × 10−3+ | |
| F14 | Median | 1.77 × 107 | 5.86 × 107 | 5.19 × 109 | 8.06 × 107 | 2.90 × 109 | 1.51 × 108 | 4.45 × 109 | 4.54 × 109 | 2.23 × 109 | 2.50 × 109 |
| Mean | 1.78 × 107 | 6.05 × 107 | 8.31 × 109 | 1.59 × 108 | 3.67 × 109 | 2.51 × 108 | 5.28 × 109 | 4.58 × 109 | 2.78 × 109 | 3.33 × 109 | |
| Std | 2.62 × 106 | 1.34 × 107 | 6.56 × 109 | 2.27 × 108 | 3.32 × 109 | 2.25 × 108 | 3.84 × 109 | 1.83 × 109 | 1.85 × 109 | 2.09 × 109 | |
| p-value | - | 4.32 × 10−8+ | 4.32 × 10−8+ | 4.32 × 10−8+ | 2.07 × 10−6+ | 3.19 × 10−7+ | 2.85 × 10−2+ | 6.79 × 10−2= | 1.00 × 100= | 6.79 × 10−2= | |
| F15 | Median | 3.53 × 107 | 1.29 × 107 | 4.13 × 107 | 4.58 × 106 | 7.60 × 107 | 5.99 × 107 | 8.60 × 106 | 8.82 × 106 | 7.75 × 106 | 8.04 × 106 |
| Mean | 3.54 × 107 | 1.26 × 107 | 4.13 × 107 | 4.59 × 106 | 7.61 × 107 | 6.03 × 107 | 8.98 × 106 | 8.95 × 106 | 7.96 × 106 | 8.07 × 106 | |
| Std | 7.60 × 106 | 1.36 × 106 | 3.05 × 106 | 3.22 × 105 | 6.14 × 106 | 6.54 × 106 | 8.90 × 105 | 9.38 × 105 | 9.30 × 105 | 9.78 × 105 | |
| p-value | - | 4.32 × 10−8− | 4.32 × 10−8+ | 4.32 × 10−8+ | 1.18 × 10−5+ | 4.65 × 10−1= | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | 4.32 × 10−8− | |
| w/t/l | 11/2/2 | 8/4/3 | 12/0/3 | 11/2/2 | 11/2/2 | 11/3/1 | 10/4/1 | 11/3/1 | 11/2/2 | ||
| Rank | 2.73 | 4.47 | 4.87 | 4.13 | 5.80 | 5.00 | 8.13 | 7.40 | 6.47 | 6.00 | |
| F | DGCELSO | DGCELSO-1 | DGCELSO-1000 | DGCELSO-SPL |
|---|---|---|---|---|
| F1 | 0.00 × 100 | 3.85 × 10−26 | 0.00 × 100 | 1.81 × 103 |
| F2 | 8.88 × 102 | 1.98 × 103 | 8.70 × 102 | 1.54 × 103 |
| F3 | 3.18 × 10−14 | 1.08 × 100 | 3.16 × 10−14 | 1.97 × 10−2 |
| F4 | 1.60 × 1011 | 2.15 × 1011 | 1.56 × 1011 | 9.44 × 1011 |
| F5 | 2.80 × 108 | 6.93 × 107 | 2.79 × 108 | 1.07 × 107 |
| F6 | 4.00 × 10−9 | 1.96 × 101 | 4.00 × 10−9 | 3.74 × 10−1 |
| F7 | 2.15 × 10−5 | 4.01 × 103 | 2.17 × 10−5 | 6.15 × 106 |
| F8 | 4.36 × 103 | 6.84 × 105 | 4.26 × 103 | 3.27 × 107 |
| F9 | 1.77 × 107 | 3.28 × 107 | 1.77 × 107 | 1.05 × 108 |
| F10 | 9.23 × 102 | 2.02 × 103 | 9.34 × 102 | 3.63 × 103 |
| F11 | 1.10 × 10−13 | 2.08 × 101 | 1.10 × 10−13 | 6.66 × 10−1 |
| F12 | 2.55 × 103 | 4.60 × 103 | 2.63 × 103 | 1.99 × 105 |
| F13 | 5.15 × 102 | 7.69 × 102 | 4.87 × 102 | 1.42 × 103 |
| F14 | 5.17 × 107 | 9.78 × 107 | 5.13 × 107 | 3.42 × 108 |
| F15 | 1.04 × 104 | 2.04 × 103 | 1.05 × 104 | 1.00 × 104 |
| F16 | 1.55 × 10−13 | 2.92 × 101 | 2.93 × 10−2 | 5.72 × 10−1 |
| F17 | 6.57 × 104 | 4.30 × 104 | 7.12 × 104 | 7.10 × 105 |
| F18 | 1.31 × 103 | 2.30 × 103 | 1.33 × 103 | 2.38 × 104 |
| F19 | 1.02 × 107 | 1.33 × 106 | 1.06 × 107 | 6.52 × 106 |
| F20 | 1.08 × 103 | 1.98 × 103 | 1.08 × 103 | 2.11 × 104 |
| Rank | 1.80 | 2.90 | 1.90 | 3.40 |
| F | tp = 0.1 | tp = 0.2 | tp = 0.3 | tp = 0.4 | tp = 0.5 | tp = 0.6 | tp = 0.7 | tp = 0.8 | tp = 0.9 | Dynamic |
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | 9.55 × 10−3 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 3.31 × 10−26 | 0.00 × 100 |
| F2 | 2.33 × 103 | 1.38 × 103 | 1.05 × 103 | 8.21 × 102 | 6.71 × 102 | 1.03 × 103 | 9.26 × 103 | 9.83 × 103 | 1.00 × 104 | 8.88 × 102 |
| F3 | 1.41 × 100 | 3.30 × 10−14 | 3.17 × 10−14 | 3.14 × 10−14 | 2.98 × 10−14 | 2.96 × 10−14 | 2.99 × 10−14 | 2.93 × 10−14 | 2.98 × 10−14 | 3.18 × 10−14 |
| F4 | 6.60 × 1011 | 1.64 × 1011 | 1.80 × 1011 | 1.89 × 1011 | 2.01 × 1011 | 2.24 × 1011 | 2.28 × 1011 | 2.52 × 1011 | 2.53 × 1011 | 1.60 × 1011 |
| F5 | 5.90 × 107 | 2.64 × 108 | 2.75 × 108 | 2.76 × 108 | 2.83 × 108 | 2.79 × 108 | 2.81 × 108 | 2.82 × 108 | 2.83 × 108 | 2.80 × 108 |
| F6 | 1.99 × 101 | 2.00 × 101 | 1.98 × 101 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 3.88 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 |
| F7 | 1.15 × 106 | 9.66 × 10−8 | 5.36 × 10−5 | 8.46 × 10−3 | 3.32 × 10−1 | 2.98 × 100 | 1.56 × 101 | 8.23 × 101 | 3.67 × 102 | 2.15 × 10−5 |
| F8 | 4.15 × 107 | 1.10 × 103 | 7.82 × 103 | 1.19 × 105 | 2.07 × 106 | 6.99 × 106 | 1.07 × 107 | 1.36 × 107 | 1.57 × 107 | 4.36 × 103 |
| F9 | 1.21 × 108 | 1.93 × 107 | 1.85 × 107 | 1.78 × 107 | 2.05 × 107 | 2.03 × 107 | 2.21 × 107 | 2.17 × 107 | 2.34 × 107 | 1.77 × 107 |
| F10 | 2.44 × 103 | 1.53 × 103 | 1.06 × 103 | 2.19 × 103 | 9.48 × 103 | 9.80 × 103 | 1.01 × 104 | 1.02 × 104 | 1.02 × 104 | 9.23 × 102 |
| F11 | 2.86 × 101 | 2.04 × 101 | 1.05 × 101 | 1.11 × 10−13 | 1.09 × 10−13 | 1.11 × 10−13 | 1.11 × 10−13 | 1.13 × 10−13 | 1.15 × 10−13 | 1.10 × 10−13 |
| F12 | 1.68 × 105 | 1.12 × 103 | 2.48 × 103 | 7.33 × 103 | 2.81 × 104 | 1.16 × 105 | 5.74 × 105 | 1.53 × 106 | 2.08 × 106 | 2.55 × 103 |
| F13 | 1.68 × 103 | 4.27 × 102 | 5.13 × 102 | 4.12 × 102 | 6.18 × 102 | 4.30 × 102 | 4.50 × 102 | 4.88 × 102 | 5.19 × 102 | 5.15 × 102 |
| F14 | 3.74 × 108 | 5.88 × 107 | 5.39 × 107 | 5.68 × 107 | 5.82 × 107 | 6.54 × 107 | 6.97 × 107 | 8.12 × 107 | 8.92 × 107 | 5.17 × 107 |
| F15 | 2.66 × 103 | 1.08 × 104 | 1.05 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 |
| F16 | 7.57 × 101 | 5.55 × 100 | 1.62 × 10−13 | 1.64 × 10−13 | 1.68 × 10−13 | 1.76 × 10−13 | 1.79 × 10−13 | 1.87 × 10−13 | 1.94 × 10−13 | 1.55 × 10−13 |
| F17 | 5.02 × 105 | 2.01 × 104 | 5.70 × 104 | 1.86 × 106 | 3.51 × 106 | 4.29 × 106 | 4.92 × 106 | 5.16 × 106 | 5.46 × 106 | 6.57 × 104 |
| F18 | 4.17 × 103 | 1.45 × 103 | 1.35 × 103 | 1.45 × 103 | 1.09 × 103 | 1.43 × 103 | 1.16 × 103 | 1.12 × 103 | 1.16 × 103 | 1.31 × 103 |
| F19 | 2.18 × 106 | 6.26 × 106 | 1.05 × 107 | 1.20 × 107 | 1.32 × 107 | 1.39 × 107 | 1.42 × 107 | 1.50 × 107 | 1.53 × 107 | 1.02 × 107 |
| F20 | 3.09 × 103 | 1.30 × 103 | 1.19 × 103 | 1.10 × 103 | 1.06 × 103 | 1.03 × 103 | 1.02 × 103 | 9.94 × 102 | 9.86 × 102 | 1.08 × 103 |
| Rank | 7.75 | 4.98 | 4.53 | 4.23 | 4.85 | 5.35 | 5.9 | 6.28 | 7.73 | 3.43 |
| F | NDG = 20 | NDG = 30 | NDG = 40 | NDG = 50 | NDG = 60 | NDG = 70 | NDG = 80 | NDG = 90 | NDG = 100 | Dynamic |
|---|---|---|---|---|---|---|---|---|---|---|
| F1 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 | 0.00 × 100 |
| F2 | 8.46 × 102 | 8.56 × 102 | 8.49 × 102 | 8.41 × 102 | 8.53 × 102 | 8.48 × 102 | 8.52 × 102 | 8.51 × 102 | 8.44 × 102 | 8.88 × 102 |
| F3 | 3.18 × 10−14 | 3.18 × 10−14 | 3.19 × 10−14 | 3.22 × 10−14 | 3.21 × 10−14 | 3.24 × 10−14 | 3.19 × 10−14 | 3.21 × 10−14 | 3.19 × 10−14 | 3.18 × 10−14 |
| F4 | 1.69 × 1011 | 1.69 × 1011 | 1.68 × 1011 | 1.65 × 1011 | 1.54 × 1011 | 1.56 × 1011 | 1.65 × 1011 | 1.58 × 1011 | 1.65 × 1011 | 1.60 × 1011 |
| F5 | 2.78 × 108 | 2.79 × 108 | 2.80 × 108 | 2.78 × 108 | 2.78 × 108 | 2.78 × 108 | 2.79 × 108 | 2.78 × 108 | 2.79 × 108 | 2.80 × 108 |
| F6 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 4.00 × 10−9 | 3.88 × 10−9 | 4.00 × 10−9 |
| F7 | 2.36 × 10−5 | 3.22 × 10−5 | 2.64 × 10−5 | 2.58 × 10−5 | 2.18 × 10−5 | 1.92 × 10−5 | 2.22 × 10−5 | 2.00 × 10−5 | 2.93 × 10−5 | 2.15 × 10−5 |
| F8 | 5.49 × 103 | 5.20 × 103 | 5.15 × 103 | 5.12 × 103 | 5.14 × 103 | 4.98 × 103 | 5.07 × 103 | 5.01 × 103 | 5.07 × 103 | 4.36 × 103 |
| F9 | 1.80 × 107 | 1.78 × 107 | 1.73 × 107 | 1.81 × 107 | 1.74 × 107 | 1.76 × 107 | 1.78 × 107 | 1.74 × 107 | 1.82 × 107 | 1.77 × 107 |
| F10 | 8.97 × 102 | 8.94 × 102 | 8.94 × 102 | 8.94 × 102 | 8.92 × 102 | 8.92 × 102 | 9.02 × 102 | 9.14 × 102 | 8.89 × 102 | 9.23 × 102 |
| F11 | 1.11 × 10−13 | 1.11 × 10−13 | 1.11 × 10−13 | 1.11 × 10−13 | 1.11 × 10−13 | 1.10 × 10−13 | 1.10 × 10−13 | 1.11 × 10−13 | 1.11 × 10−13 | 1.10 × 10−13 |
| F12 | 3.13 × 103 | 3.13 × 103 | 3.24 × 103 | 3.18 × 103 | 3.24 × 103 | 3.21 × 103 | 3.11 × 103 | 3.14 × 103 | 3.28 × 103 | 2.55 × 103 |
| F13 | 4.48 × 102 | 5.03 × 102 | 5.13 × 102 | 4.83 × 102 | 5.30 × 102 | 5.09 × 102 | 4.51 × 102 | 4.64 × 102 | 4.82 × 102 | 5.15 × 102 |
| F14 | 5.26 × 107 | 5.26 × 107 | 5.24 × 107 | 5.16 × 107 | 5.16 × 107 | 5.07 × 107 | 5.23 × 107 | 5.18 × 107 | 5.24 × 107 | 5.17 × 107 |
| F15 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 | 1.04 × 104 |
| F16 | 1.59 × 10−13 | 1.57 × 10−13 | 1.58 × 10−13 | 1.58 × 10−13 | 3.85 × 10−2 | 1.58 × 10−13 | 2.93 × 10−2 | 1.59 × 10−13 | 1.59 × 10−13 | 1.55 × 10−13 |
| F17 | 1.19 × 105 | 1.20 × 105 | 1.19 × 105 | 1.20 × 105 | 1.28 × 105 | 1.22 × 105 | 1.28 × 105 | 1.34 × 105 | 1.35 × 105 | 6.57 × 104 |
| F18 | 1.19 × 103 | 1.21 × 103 | 1.28 × 103 | 1.31 × 103 | 1.24 × 103 | 1.18 × 103 | 1.31 × 103 | 1.31 × 103 | 1.28 × 103 | 1.31 × 103 |
| F19 | 1.10 × 107 | 1.09 × 107 | 1.12 × 107 | 1.10 × 107 | 1.12 × 107 | 1.13 × 107 | 1.12 × 107 | 1.12 × 107 | 1.11 × 107 | 1.02 × 107 |
| F20 | 1.12 × 103 | 1.11 × 103 | 1.09 × 103 | 1.11 × 103 | 1.08 × 103 | 1.11 × 103 | 1.09 × 103 | 1.08 × 103 | 1.10 × 103 | 1.08 × 103 |
| Rank | 6.05 | 6.05 | 6.18 | 5.33 | 5.78 | 4.70 | 5.50 | 5.18 | 6.00 | 4.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Q.; Zhang, K.-X.; Gao, X.-D.; Xu, D.-D.; Lu, Z.-Y.; Jeon, S.-W.; Zhang, J. A Dimension Group-Based Comprehensive Elite Learning Swarm Optimizer for Large-Scale Optimization. Mathematics 2022, 10, 1072. https://doi.org/10.3390/math10071072
Yang Q, Zhang K-X, Gao X-D, Xu D-D, Lu Z-Y, Jeon S-W, Zhang J. A Dimension Group-Based Comprehensive Elite Learning Swarm Optimizer for Large-Scale Optimization. Mathematics. 2022; 10(7):1072. https://doi.org/10.3390/math10071072
Chicago/Turabian StyleYang, Qiang, Kai-Xuan Zhang, Xu-Dong Gao, Dong-Dong Xu, Zhen-Yu Lu, Sang-Woon Jeon, and Jun Zhang. 2022. "A Dimension Group-Based Comprehensive Elite Learning Swarm Optimizer for Large-Scale Optimization" Mathematics 10, no. 7: 1072. https://doi.org/10.3390/math10071072