1. Introduction
Nowadays, human society is faced with a variety of decision-making problems, which are usually characterized by complexity, diversity and uncertainty. Fortunately, game theory has a powerful ability to handle such complex decision-making problems. Compared with other theories, game theory is prominent in revealing the inherent laws of socio-economic phenomena and the essential characteristics of human behavior. Game theory is a useful tool in studying the interaction between groups, individuals or players [
1]. It has been widely applied in many fields, such as politics [
2], economics [
3], military [
4] and environmental decision-making [
1]. As we all know, to create a game model, some assumptions are required about the type of game, the strategies of players and the payoff values. With the increase in the number of players and strategies, the number of payoff values given by players in a game will increase significantly, which will undoubtedly bring a heavy burden to them [
5]. Moreover, due to the increasing complexity of the game environment and the inevitable uncertainty that arises in the game, finding a suitable method to describe inaccuracy is urgent [
6]. This research focuses on a matrix game with uncertain information.
Generally, there are three commonly-used representations that can depict the inaccuracy of the payoff values in a matrix game model: intervals [
7], fuzzy information [
8,
9,
10,
11,
12,
13,
14,
15,
16] and linguistic information [
5,
6,
17,
18,
19]. Considering the ambiguity of human thinking and the lack of available information, players may prefer to express their opinions with linguistic information rather than interval numbers or fuzzy numbers [
20]. For example, teachers prefer to use linguistic terms (e.g., “medium”, “good” and “excellent”) to evaluate children’s performance in kindergarten. In fact, a single linguistic term is insufficient to perfectly express the decision-makers’ (DMs’) evaluation. To handle this shortcoming, Rodríguez et al. [
21] put forward the concept of the hesitant fuzzy linguistic term set (HFLTS), which can improve the richness and flexibility of linguistic information acquisition. However, HFLTS does not reflect the probability of linguistic terms, which may result in the loss of original information. To overcome this issue, Pang et al. [
22] proposed the concept of the probabilistic linguistic term set (PLTS).A PLTS permits players to select multiple linguistic terms from a linguistic term set (LTS) and assign them with probabilities, which can describe players’ judgments more exactly [
23]. A PLTS combines fuzziness, hesitancy and accurate information in a comprehensive form. Therefore, it is appropriate to use PLTSs to represent the payoff values of a matrix game. PLTS has been widely used by investigators [
24,
25,
26,
27,
28] since it was proposed. However, to the best of our knowledge, probabilistic linguistic information is rarely used to depict the payoff values of matrix games. This is the first of the research gaps intended to be narrowed.
There are many defuzzification techniques which deal with uncertain information in matrix games, such as membership function [
5], membership function and non-membership function [
12], similarity degree [
13], value function and fuzzy function [
14], ranking function [
15], cut sets [
16], etc. For matrix games with linguistic information, the semantics of linguistic terms may be lost by substituting symbolic computation for the operation of membership functions during computation [
5]. The use of membership function is very important in the defuzzification of probabilistic linguistic information [
6], but these methods [
18,
29] integrate the linguistic terms in the game without introducing the membership function. However, as far as we know, there is no research on the trapezoidal membership function of probabilistic linguistic information. This is the second research gap intended to be covered.
Prospect theory (PT) [
30] was used to portray the psychological behavior of DMs under risk. Although the PT has been extended into various fuzzy environments [
31,
32,
33,
34] to solve multi-attribute decision making (MADM) problems, the PT was first studied in [
6] to solve a matrix game under a hesitant fuzzy linguistic environment. However, to the best of our knowledge, there is no research on introducing PT under a probabilistic linguistic environment to solve a matrix game problem. This is the third research gap that needs to be filled.
There are three challenges to overcome in the process of filling the above research gaps: (i) how to build a matrix game model under a probabilistic linguistic environment is the first challenge; (ii) how to defuzzify the probabilistic linguistic information with trapezoidal membership function is the second challenge; (iii) how to introduce the PT to solve a matrix game under probabilistic linguistic environment is the third challenge.
Motivated by the aforesaid analysis, this study aims to propose a probabilistic linguistic matrix game (PLMG) method based on fuzzy envelope and PT, and the effectiveness and practicality of the proposed method is verified by an example from the development strategy of Sanjiangyuan National Nature Reserve (SNNR).It is essential to propose such a method due to the following reasons. Firstly, the study of matrix games under a probabilistic linguistic environment expands the scope of application of game theory. Secondly, the definition of trapezoidal fuzzy envelop for probabilistic linguistic information enriches the defuzzification technology for linguistic information. Moreover, the fusion of PT commendably captures the DMs’ psychological behavior regarding gain and loss, which makes the proposed method more suitable for solving practical decision-making problems. In addition, the proposed method provides feasibility for solving MADM problems without weight information from the perspective of the game between DM and Nature. Finally, the proposed method not only fills the aforementioned research gaps, but has important practical value.
The rest of the paper is organized as follows:
Section 2 briefly recalls the literature review of fuzzy matrix games, PLTSs and prospect theory (PT), and extracts the research gaps dealt with in this paper.
Section 3 provides the essential preliminaries on trapezoidal fuzzy number (TrFN), HFLTS, PLTS, ordered weighted averaging (OWA) operators and PT; a research flow is also provided in this section.
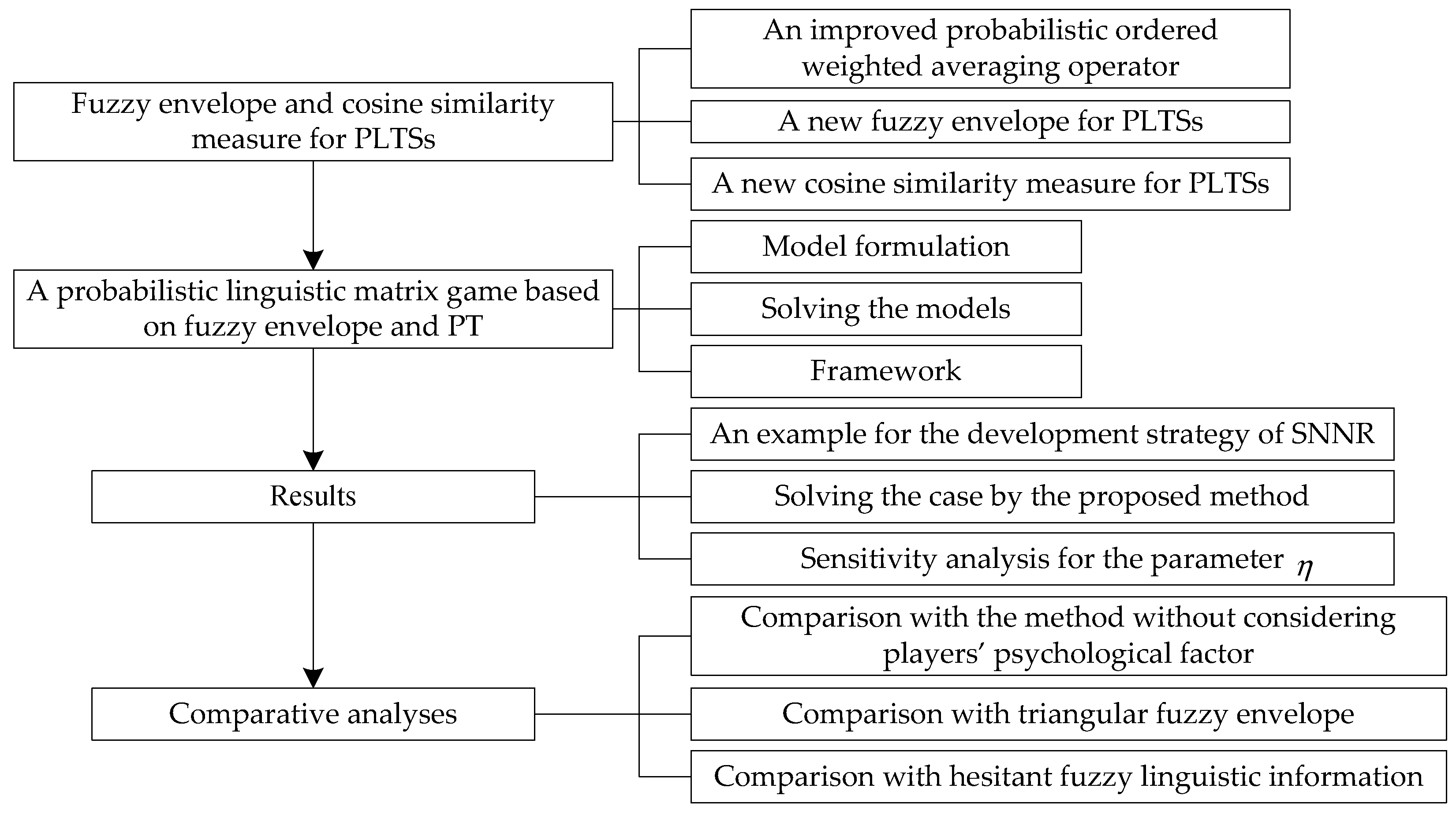
Section 4 gives the definitions of improved probabilistic ordered weighted averaging (POWA) operator, fuzzy envelope and cosine similarity measure for PLTSs, and then their related theorems are analyzed.
Section 5 develops a probabilistic linguistic matrix game method based on fuzzy envelope and PT.
Section 6 deals with an example fromthe development strategy of SNNR.
Section 7 ends this paper with concluding remarks and prospects for the future research.
4. Fuzzy Envelope and Cosine Similarity Measure for PLTSs
In this section, an improved POWA operator is defined. Then, based on the improved POWA operator, an approach is developed to generate a fuzzy envelope for PLTS by using trapezoidal fuzzy membership functions. Ultimately, a cosine similarity measure for PLTSs is put forward.
4.1. An Improved Probabilistic Ordered Weighted Averaging Operator
Based on Definition 5 and inspired by the POWA operator [
42], an improved POWA operator is defined as follows:
Definition 7. Letbe a set of arguments andbe the k-th largest argument among set. An improved POWA operator can be defined aswhere,() is the weight (probability) associated with argument.
In order to apply Equation (5) to aggregate the arguments, the values of
and
should be determined first. Generally, the former can be derived from DMs’ subjective judgments, and the latter can be calculated by using a series of approaches. Since the OWA operator weight-determining approach in [
39] has the powerful ability to identify the pessimistic and optimistic OWA operator weights by orness measure, this paper intends to employ it to determine the OWA operator weights with probability information (called POWA weights hereafter).
For the convenience of the following calculation, denote with and with , where the and are decided by Definition 6.
Remark 1. Merigo and Wei [
42]
proposed a POWA operator by introducing . When the probabilities of all arguments are equal, the POWA operator (see Equation (2) in [
42]
) should be reduced into the classical OWA operator (see Equation (3) in Definition 5), namely, for all it holds that if is a non-zero constant. However, it cannot be deduced from , which indicates that Merigo and Wei’s [
42]
POWA operator failed to consider the case that the probabilities of all arguments are equal. Fortunately, the proposed improved POWA operator can tackle this issue perfectly, since can reduce to when all equal a non-zero constant. Remark 2. In the traditional methods [
24,
25,
26,
27,
28]
, the probability information is incomplete (i.e., ), yet it is required to normalize the PLTSs for further calculation. However, in the proposed improved POWA operator, there is no need to normalize the PLTSs in this paper, which can preserve more of the initial information from the DMs. 4.2. A New Fuzzy Envelope for PLTSs
PLTSs have powerful capability to tackle linguistic decision-making problems flexibly. To facilitate the calculation process based on PLTSs, a new fuzzy envelop of PLTS employing trapezoidal fuzzy membership function is proposed. To achieve such a fuzzy representation, the following factors should be considered:
The different probabilities of linguistic terms imply the different importance of such terms.
Trapezoidal fuzzy membership function has strong ability to portray the fuzziness of the comparative linguistic terms.
The parameters of the trapezoidal fuzzy membership function are calculated by an aggregation operator, which can embody the different importance of the linguistic terms in PLTS.
A LTS can be defined as
, where
stands for a possible value for a linguistic variable and
is an even and positive integer. Let
S = {
s0: extremely bad,
s1: very bad,
s2: bad,
s3: medium,
s4: good,
s5: very good,
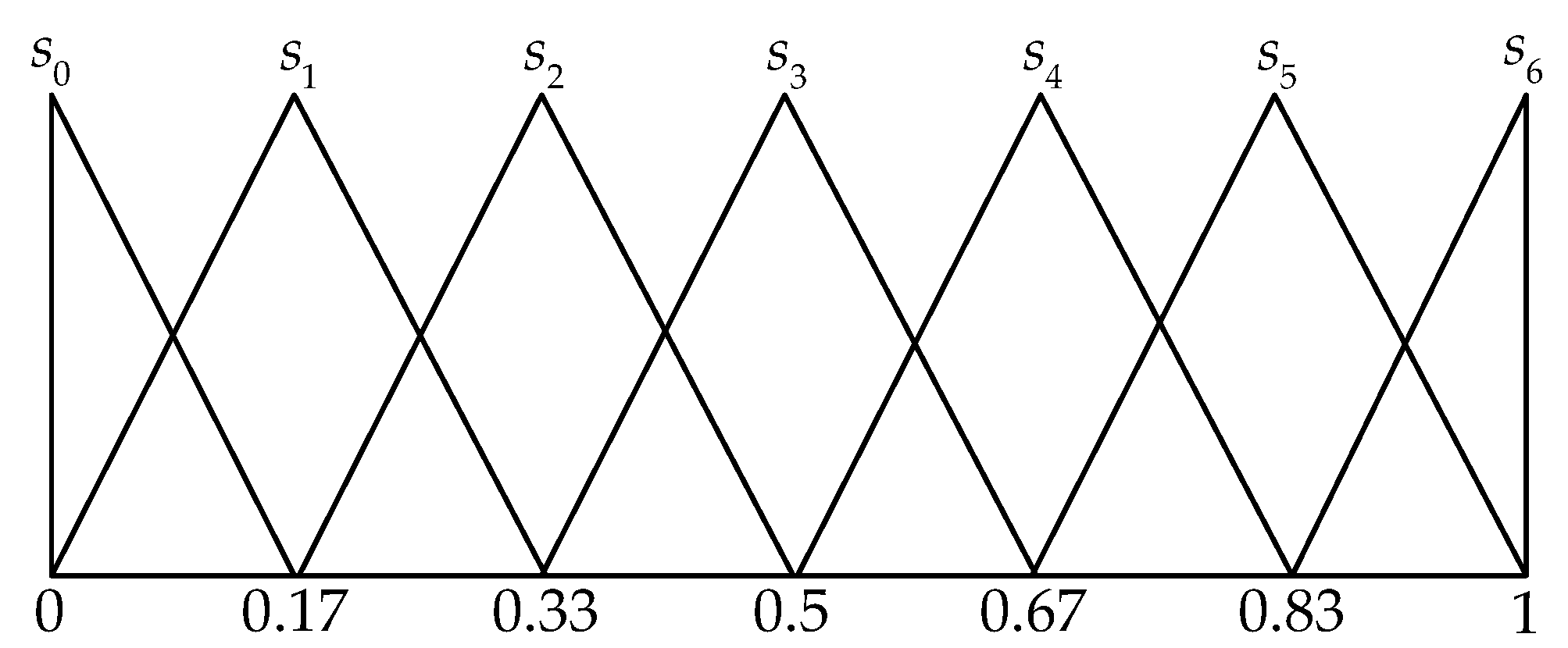
s6: extremely good} be a LTS (i.e.,
). Afterwards,
S with its semantics depicted by triangular fuzzy membership function can be visually displayed in
Figure 2 [
43].
Presume that all the linguistic terms
can be represented as a triangular fuzzy number
(
). Particularly when
, the linguistic terms can be shown in
Figure 2. Hence, PLTS
can be formed as
. The elements contained in
can be further simplified as
due to
. Then, a fuzzy envelope of PLTS based on the proposed improved POWA operator is defined as follows.
Definition 8. For a PLTS, its fuzzy envelopecan be defined as a trapezoidal fuzzy membership function, i.e.,.
In order to obtain the fuzzy envelope , it is required to determine the values of the parameters , , and . Next, the following laws are presented to determine the values of the parameters , , and for different situations.
Fuzzy envelope for . The parameters , , and are determined as ;
Fuzzy envelope for
.
can be transformed into
. The parameters
,
,
and
are determined as
,
and
Herein, . Then, .
Theorem 1. Parameterdetermined by Equation (6) owns the following properties.
;
For fixedand, if the probability ofis closer to 1, thenis closer to; if the probability ofis closer to 1, thenis closer to;
Let, where. For a fixed, if, then; if, then.
Proof of Theorem 1. Since , and is derived by the operator , is between the minimum and maximum aggregated values (i.e., and ).
For convenience, the probability of is denoted by . For a fixed weight vector , the closer the value of is to 1, the larger the value of , which will result in the value of being closer to . Hence, for fixed and , if is closer to 1, then is closer to . It can be deduced that the property “for fixed and , if is closer to 1, then is closer to ” also holds.
Since , where , it holds that . In this case, if , then and , which indicates that . The property “if , then ” can be proven similarly.
This completes the proof of Theorem 1. □
Fuzzy envelope for
.
can be transformed into
. The parameters
,
,
and
are determined as
,
,
Herein,
. Then,
,
,
.
Theorem 2. Parameterdetermined by Equation (7) owns the following properties:
;
For fixedand, if the probability ofis closer to 1, then is closer to ; if the probability of is closer to 1, then is closer to ;
Let, where. For a fixed, if, then; if, then.
Proof of Theorem 2. Since , and is obtained by the operator, is between the minimum and maximum aggregated values.
For convenience, the probability of is denoted by . For a fixed weight vector , the closer the value of is to 1, the larger the value of , which will cause the value of to be closer to . Hence, for fixed and , if is closer to 1, then is closer to . It also can be inferred that the property “for fixed and , if is closer to 1, then is closer to ”.
Since , where , it holds that . In this case, if , then and , which shows that . The property “if , then ” can also be proven.
This completes the proof of Theorem 2. □
Fuzzy envelope of . can be transformed into . The parameters and are determined as and ; For determination for the parameters and , it is required to consider the parity of .
Theorem 3. Parameters and determined by Equation (8) or Equation (9) own the following properties:
;
For fixed,,and, it holds that
- (i)
If the probability of(or) is closer to 1, then is closer to (or );
- (ii)
If the probability ofis closer to 1, then is closer to ;
- (iii)
If the probability of(or) is closer to 1, thenis closer to(or);
- (iv)
If the probability ofis closer to 1, then is closer to ;
For fixedand, if both arguments(or) and arguments(or) have the same probabilities, respectively, then it holds that
- (i)
If, then; if, then(or);
- (ii)
If, then(or); if, then.
Proof of Theorem 3. Since , and is obtained by the operator, is obtained by the operator, and are between the minimum and maximum aggregated values.
For convenience, the probability of (or ) is denoted by . For fixed weight vectors , the closer the value of is to 1, the larger the value of , which will cause the value of (or ) to be closer to (or ). Hence, for fixed , and , if is closer to 1, then is closer to (or ). Similarly, (ii)–(iv) also can be proven.
Since all the arguments have the same probabilities, if , then and , which shows that . If , then , , which indicates that (or ) (or ). (ii) can be also proven similarly.
This completes the proof of Theorem 3. □
In the sequel, a numerical example is given to understand the aforesaid process of obtaining the fuzzy envelope for the PLTSs.
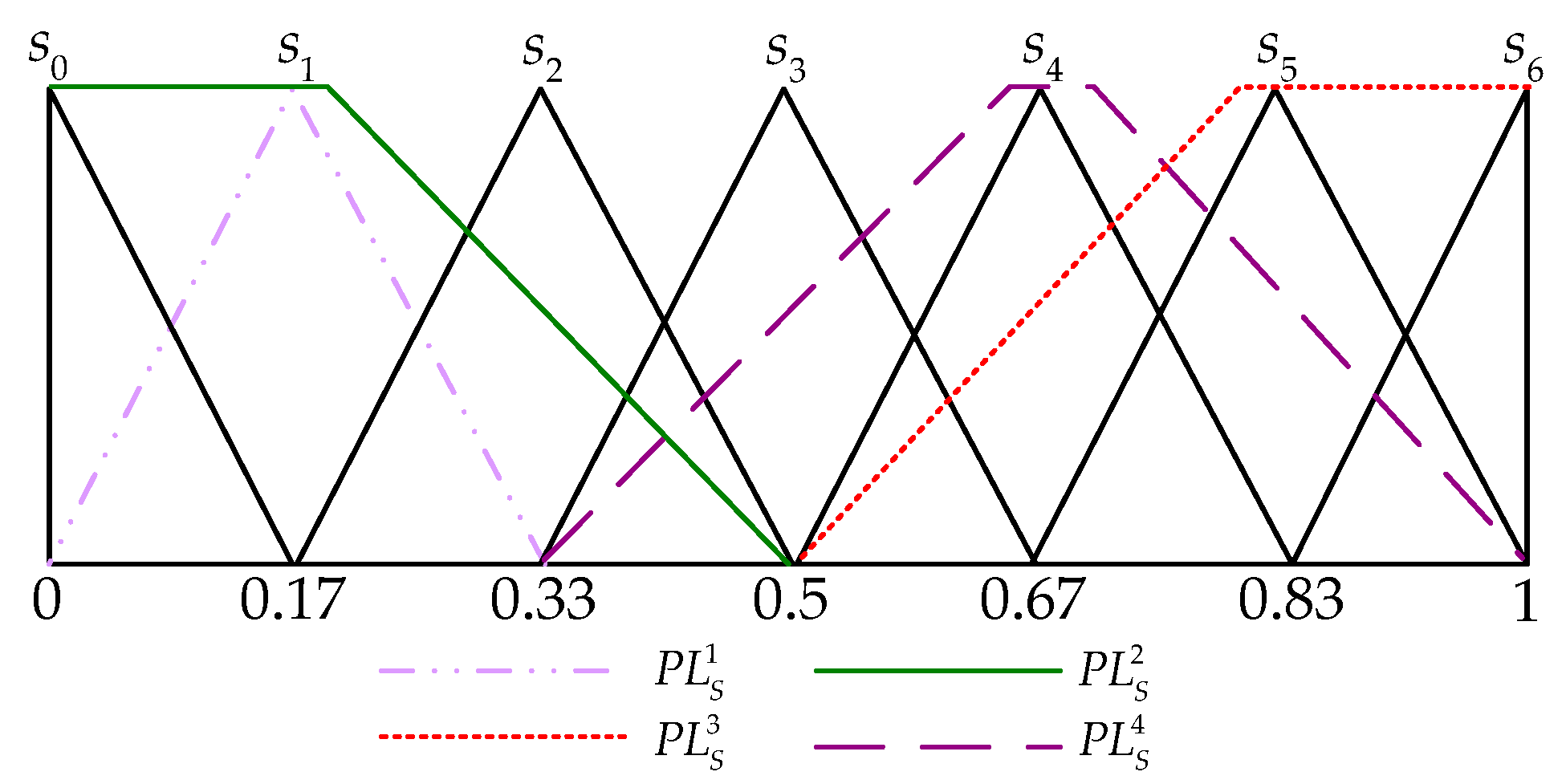
Example 2. Letbe a linguistic term set with its triangular fuzzy membership function shown in Figure 2. In order to grasp the proposed fuzzy envelope determining approach, an example is conducted as follows: Fuzzy envelope for PLTScan be obtained as.
Fuzzy envelope for PLTSis obtained as follows:
,. Since, according to [
43]
, , thenTherefore, .
Fuzzy envelope for PLTSis obtained as follows:
,. Since, according to [
43]
, , thenThus, .
Fuzzy envelope for PLTSis obtained as follows:
,. Sinceand, according to [
43]
, (for determining ) and (for determining ), then and .
Thus,.
The fuzzy envelopes obtained above are shown inFigure 3.
When the probabilities of all linguistic terms in
are equal and continue, then
can be regarded as the hesitant fuzzy linguistic term sets (HFLTSs). In this case, the fuzzy envelopes for
are exactly the same as those presented in [
43], namely,
,
and
.
Hence, the approach to determining the fuzzy envelope for PLTS proposed by this paper can generalize that proposed by [
43], which shows the effectiveness and flexibility of the proposed approach.
4.3. A New Cosine Similarity Measure for PLTSs
Currently, the cosine similarity measure has received popular attention in retrieving information and collecting data. Liao and Xu [
44] defined a cosine similarity measure for HFLTSs, as shown in Definition 9.
Definition 9 ([
44])
. Let be a subscript-symmetric linguistic term set. Given any two HFLTSs , the cosine similarity measure between them is formulated aswhere . If , should be converted to a new one with the same length as by adding the smallest ones in and the probabilities of them are zero. Inspired by Definition 9 and according to the fuzzy envelopes for PLTSs, the cosine similarity measure for PLTSs is defined as follows.
Definition 10. Letbe any two PLTSs andbe their fuzzy envelopes. The cosine similarity measure betweenandis formulated as According to the relationship between distance and similarity measure mentioned in [
44]
, the corresponding cosine distance measure can be defined as The above Equations (11) and (12) satisfy boundness (i.e., ) and reflexivity (i.e., ). Generally, the greater the cosine similarity measure between two PLTSs, the more analogous they are, and the smaller the distance.
Based on the relative repetition degree and the diversity degree of probabilities for linguistic terms, Xian et al. [
25] proposed a similarity measure for PLTSs. In order to compare with the similarity measure defined in [
25], a numerical example is given as follows.
Example 3. Let,andbe three PLTSs. Their fuzzy envelopes can be calculated as,and. Then, in the light of Equation (11), the cosine similarity measures between them can be computed asand. By using the formula of Xian et al. [
24]
, it can be calculated that .
Due to the fact that
is closer to
than
, it is more in line with humanintuition that the similarity between
and
is higher than that between
and
. In addition, it was mentioned that there is no need to normalize the PLTSs when determining their fuzzy envelopes. Thus, the proposed similarity measure has strong ability to preserve more initial information from the PLTSs. Nevertheless, it is necessary to normalize the PLTSs when using the similarity measure of Xian et al. [
25]. Hence, the similarity measure proposed in this paper is more reasonable than the one proposed in [
25].
5. A Probabilistic Linguistic Matrix Game Based on Fuzzy Envelope and PT
In this section, a probabilistic linguistic matrix game (PLMG) is formulated. Afterwards, based on fuzzy envelope and considering the player’s psychological behavior, an effective method is developed to solve the PLMG. The framework of the proposed method is also presented.
5.1. Model Formulation
Due to the fact that PLTSs have the strong ability to describe uncertain and imprecise payoff values, the formal description of the PLMG is given to construct the programming models. In this PLMG, the pure strategy spaces of players
and
are denoted as
and
, respectively. The vectors
and
are the mixed strategies of players
and
, where the
and
are the probabilities for players
and
that choose pure strategies
and
, separately. The mixed strategy spaces for player
is
and the mixed strategy spaces for player
is
. Suppose that the player
takes the pure strategy
to maximize his/her benefit, and the player
selects the pure strategy
to minimize his/her loss (i.e., at situation
), the profit of player
is
, where
is a PLTS defined in Definition 4. Let
be a linguistic term set. For simplicity, the payoff matrix of PLMG is denoted as
, which can be described as
Hereinafter, the PLMG with mixed strategies is abbreviated as .
If players and take any mixed strategies and , then the expected payoff of player is , where is the length of .
Let be the maximize player, be the minimize player. From the perspective of gain-floor and loss-ceiling, the goals of players and can be constructed as follows, respectively.
Player : and player : .
Let
represent the minimal fuzzy payoff value of player
and
represent the maximal fuzzy payoff value of player
[
5]. The goals of players can be transformed as
for each strategy
and
for each strategy
. The symbols “
” and “
” are the probabilistic linguistic version of the crisp order relation, meaning “essentially not less than” and “essentially not larger than”, respectively. Now, to get the maximin strategy
and the minimax strategy
, the following two fuzzy programming models have to be solved.
and
5.2. Solving the Models
Since the payoff values
in the payoff matrix
are expressed by PLTSs, the traditional method failed to address the aforesaid game models. In this paper, a new method is developed to find the optimal solution for the mathematical models. Firstly, by using the approach presented in
Section 4.2, all elements in the probabilistic linguistic payoff matrix are represented by trapezoidal fuzzy membership function and a fuzzy envelope-based payoff matrix is formed. Then, considering DMs’ psychological behavior, the fuzzy envelope-based payoff matrix is transformed into an overall prospect payoff matrix through applying PT. Finally, based on the prospect payoff matrix, two linear programming models are constructed and solved.
Now, the specific and detailed processes for seeking the maximin and the minimax strategies are profiled as follows:
Step 1. Convert the probabilistic linguistic payoff matrix into the fuzzy envelope-based payoff matrix , where .
By using the technique presented in
Section 4.2, the entire elements in the probabilistic linguistic payoff matrix can be represented by their trapezoidal fuzzy membership functions. As a result, the fuzzy envelope-based payoff matrix
can be obtained.
Step 2. Transform the fuzzy envelope-based payoff matrix into a prospect payoff matrix through the application of PT.
- (i)
Define the reference point
The choice of reference point is the key and also the core of PT. When making a decision, the DM will measure the gain or loss on the basis of the reference point. The selection of the preference point is frequently dependent on the risk attitude and psychological behavior of DMs [
34]. In this paper, the positive ideal point and the negative ideal point are taken as the double reference points. Suppose that the positive and negative ideal PLTSs are
and
, respectively.
- (ii)
Calculate the gain and loss of on the negative and positive ideal PLTS
To characterize the “utility value” that the player perceives in gain and the “regret value” that the player perceives in loss, the cosine distance between and the negative ideal PLTS is deemed as the gain and the cosine distance between and the positive ideal PLTS is viewed as the loss.
According to Definition 10, the gain of
on the negative ideal PLTS
is given as
Similarity, the loss of
on the positive ideal PLTS
is given as
- (iii)
Compute the overall prospect value of payoff value at situation given by player
In the view of Equation (4), the negative and positive prospect value of payoff value at situation
given by player
on
and
can be obtained as
Therefore, the overall prospect value of payoff value at situation
given by player
can be obtained as
where the risk attitude parameter
indicates the different importance degrees of the positive and negative ideal PLTSs.
Step 3. The acquired overall prospect payoff matrix
is considered as the crisp equivalent of the given payoff matrix
. Now Equations (13) and (14) are turned into the following two crisp linear programming models, respectively.
where
and
represent the crisp equivalents of gain-floor and loss-ceiling for players, respectively.
Step 4. Via solving the aforementioned two linear programming modelswith the ordinary simplex method, the maximin strategy for player and the minimax strategy for player can be acquired. In addition, the optimal crisp equivalent of the gain-floor and loss-ceiling for players and are evaluated here, respectively.
Step 5. The aggregated expected payoff for player
can be calculated by employing the basic operations of PLTS introduced in [
22].
5.3. Framework
Up to now, this paper has completed the method of solving the matrix game with probabilistic linguistic information. The framework (
Figure 4) is described below to clearly explain the logic and organizational structure of the proposed method.
6. Results
This section provides an example from the development strategy of SNNR to illustrate the applicability of the proposed method. Then, sensitivity analysis and comparative analyses are conducted to show the flexibility and superiorities of the proposed method.
6.1. An Example from the Development Strategy of SNNR
The Sanjiangyuan region (the headwater region of the Yangtze, Yellow and Lantsang rivers) is located in the hinterland of the Qinghai-Tibet Plateau, south of Qinghai Province. The region is called the “Water tower of China” and has an important water storage function [
45]. The region is essential not only for ecological water supply and regulation services, but also for ecological services of biodiversity conservation [
46]. However, the ecosystem in this region is fragile and the impact of climate change (especially global warming) on this region is particularly obvious [
47]. Rapid population growth, unconstrained economic development and extensive human activities have enormously exacerbated the deterioration of the ecological environment, including the degradation of grassland, soil erosion and the loss of biodiversity [
48]. In order to strengthen the ecological and environmental protection of this region, the Chinese government established the Sanjiangyuan National Nature Reserve (SNNR) in 2000 and launched the Sanjiangyuan ecological project in 2005 [
49]. SNNR is the largest nature reserve in China covering an area of 363,000 square kilometers. The establishment of the nature reserve aims to safeguard and preserve the biodiversity and natural ecological balance of the region.
Nevertheless, as an underdeveloped region in China, the Sanjiangyuan region is facing a series of problems under the combined effects of global climate change and increasingly frequent human economic activities: the uncoordinated contradiction between humans and Nature is gradually becoming prominent; the ecological environment is deteriorating; the number of ecological refugees is increasing year by year; the contradiction between population, resources, environment and development is becoming more and more serious; the situation for ecological environment protection and natural resource development and utilization are becoming increasingly grim [
50]. How to sustainably develop the economy and steadily improve peoples’ lives without destroying the local ecological environment is a difficult and urgent matter. Thus, it has highly significant academic value and practical application to research the interaction between economy and ecology in the Sanjiangyuan region, and formulate a development strategy for SNNR. In order to explore the balance between economic development and ecological protection, Xue et al. [
6] have used a hesitant fuzzy matrix game method to study the development strategy of SNNR, considering that PLTSs have more powerful and flexible capabilities than HFLTSs in disposing of uncertain information, which is also more in line with human thinking. Therefore, this paper intends to apply the PLMG method to solve the development strategy of SNNR.
In fact, different development goals may conflict with each other when formulating the development strategy of SNNR. Compared with other objectives such as biodiversity, water storage capacity and conserving wetland areas, the management department that formulates the development strategy (hereinafter referred to as management department) of SNNR may pay more attention to the goal of economic return. However, Nature and the management department are contradictory in terms of economic returns. Thus, two competitors are formed–the management department and Nature. In this paper, the management department that formulates the development strategy of SNNR is regarded as player and Nature as player . : Forestry, : Manufacturing, : Tourism, : Planting and : Livestock farming are five economic development schemes devised by the management department for the economic development of SNNR. The five different schemes can be viewed as the five strategies of player in the game. In a similar way, : Economic benefit, : Biological diversity, : Capacity of water storage and : Lakes and wetland area are four objectives considered by Nature for the coordinated development of ecology and economy for SNNR. These four different objectives can be viewed as the four strategies of player in the game.
Let
S = {
s0: extremely poor (EP),
s1: very poor (VP),
s2: poor (P),
s3: medium (M),
s4: good (G),
s5: very good (VG),
s6: extremely good (EG)}be a LTS. The payoff matrix values with probabilistic linguistic information are shown in
Table 1. These evaluation values in the payoff matrix are given by the invited team of senior experts after field research, consulting relevant historical materials and combining the current national policies.
The evaluation information in
Table 1 can be described in the forms of PLTSs in the probabilistic linguistic payoff matrix
.
6.2. Solving the Case by the Proposed Method
Step 1. Take the trapezoidal fuzzymembership function to represent the entire elements in probabilistic linguistic payoff matrix
. Then, a fuzzy envelope-based payoff matrix
can be obtained through the approach introduced in
Section 4.2.
Step 2. Determine the reference point.
Let and be the positive ideal PLTS and the negative ideal PLTS, respectively.
Step 3. The gain
and loss
can be computed by using Equations (15) and (16). Afterwards, the obtained calculation results can form two cosine distance matrices, separately.
and
Step 4. Based on Equations (17) and (18), the negative prospect value
and positive prospect value
can be computed. After that, the negative and the positive prospect matrices can be formed, respectively.
and
Step 5. Set the risk attitude parameter
; the overall prospect value
can be obtained by Equation (19). Then, all the acquired overall prospect value can constitute an overall prospect matrix.
Step 6. Now, to obtain the maximin strategy
and the crisp equivalent of the gain-floor
for player
, a crisp linear programming model can be constructed as follows in the light of Equation (20).
Solving the above linear programming model, the maximin strategy and the crisp equivalent of the gain-floor of player (i.e., management department) are obtained as and .
Step 7. To obtain the minimax strategy
and the crisp equivalent of the loss-ceiling
for player
, a crisp linear programming model can be established by utilizing Equation (21).
Solving the above linear programming model, the minimax strategy and the crisp equivalent of the loss-ceiling of player (i.e., Nature) are obtained as and .
Step 8. Calculate the expected payoff of player .
By employing the normalized method and the basic operations of PLTSs (see [
22]), the expected payoff is calculated as follows:
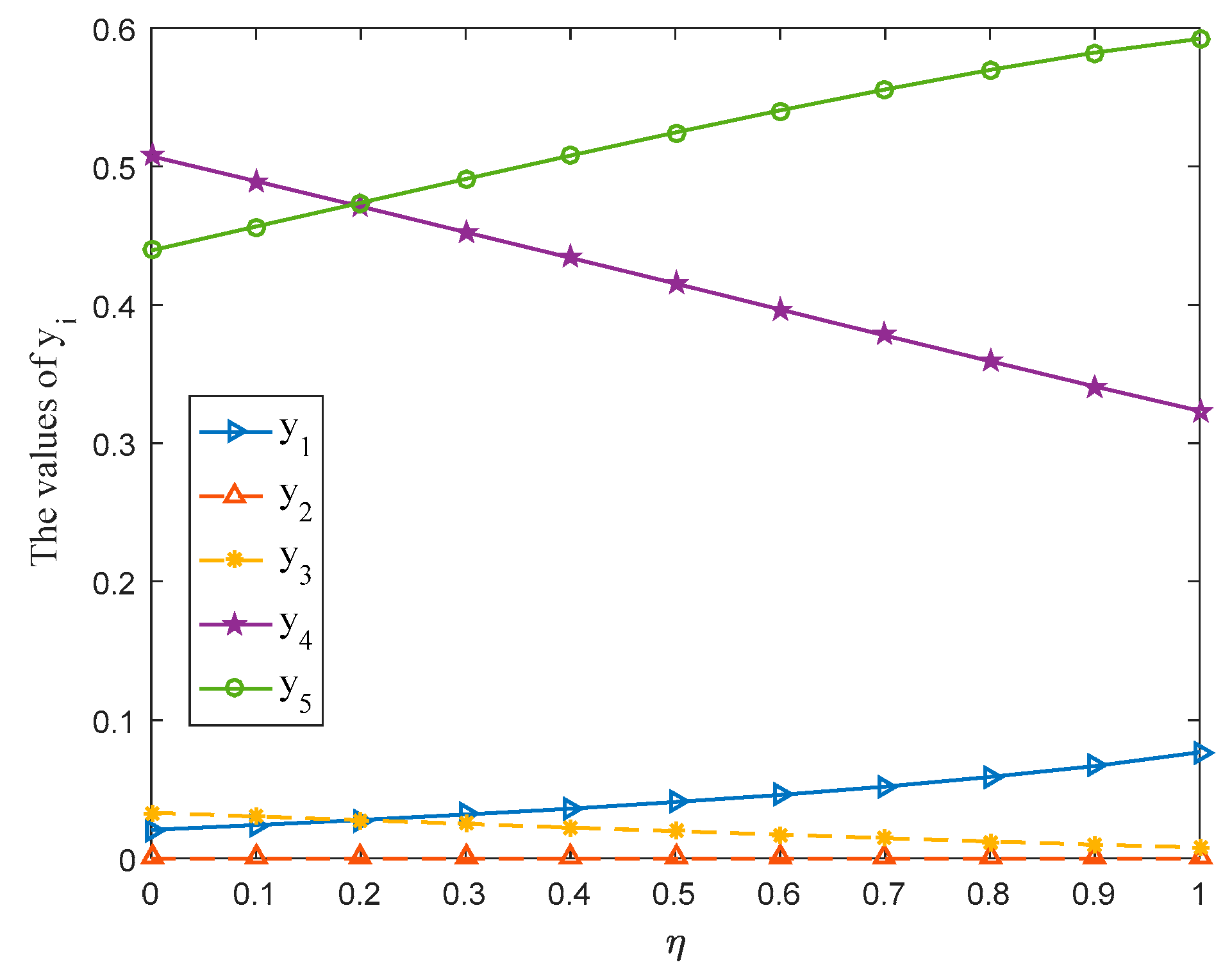
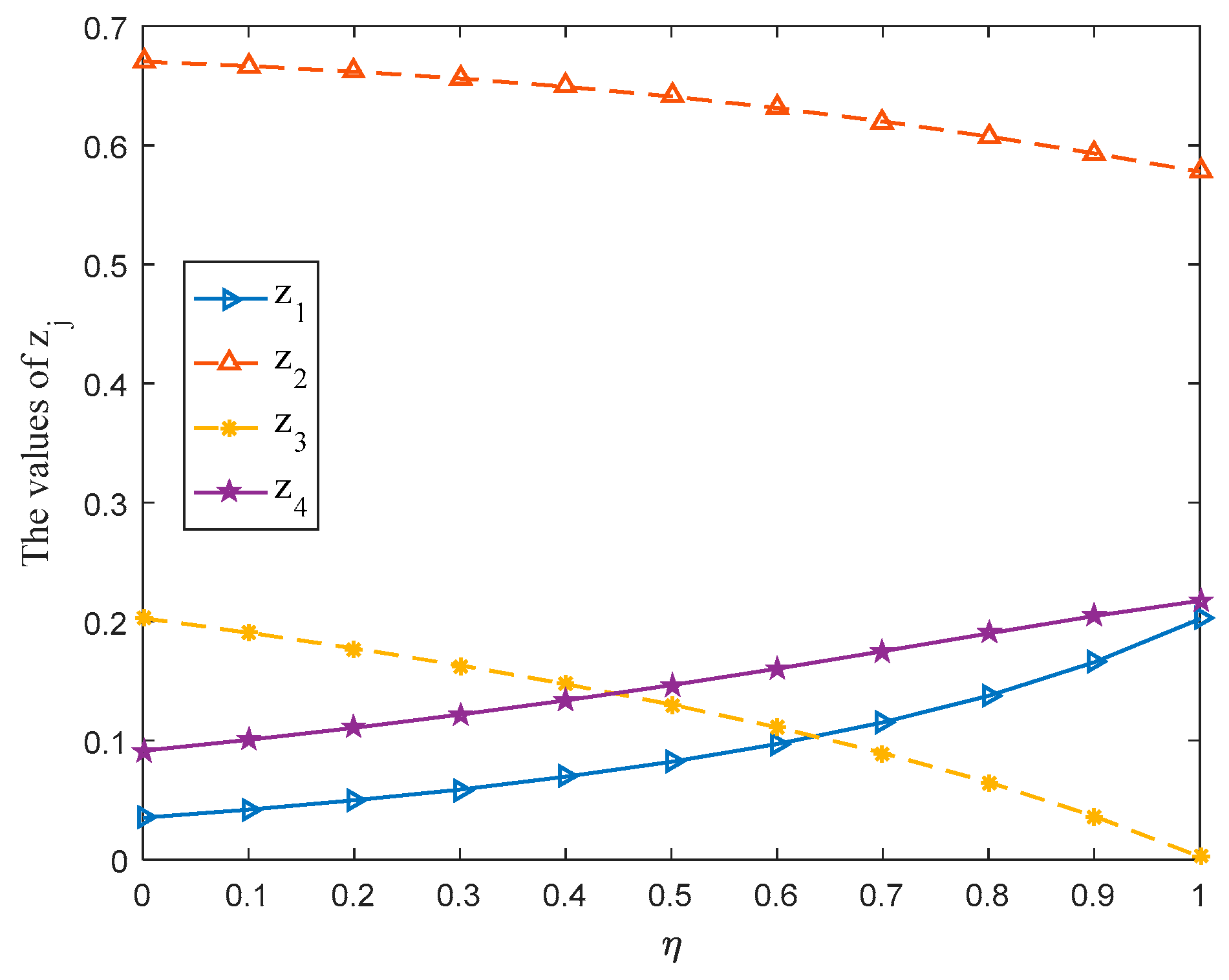
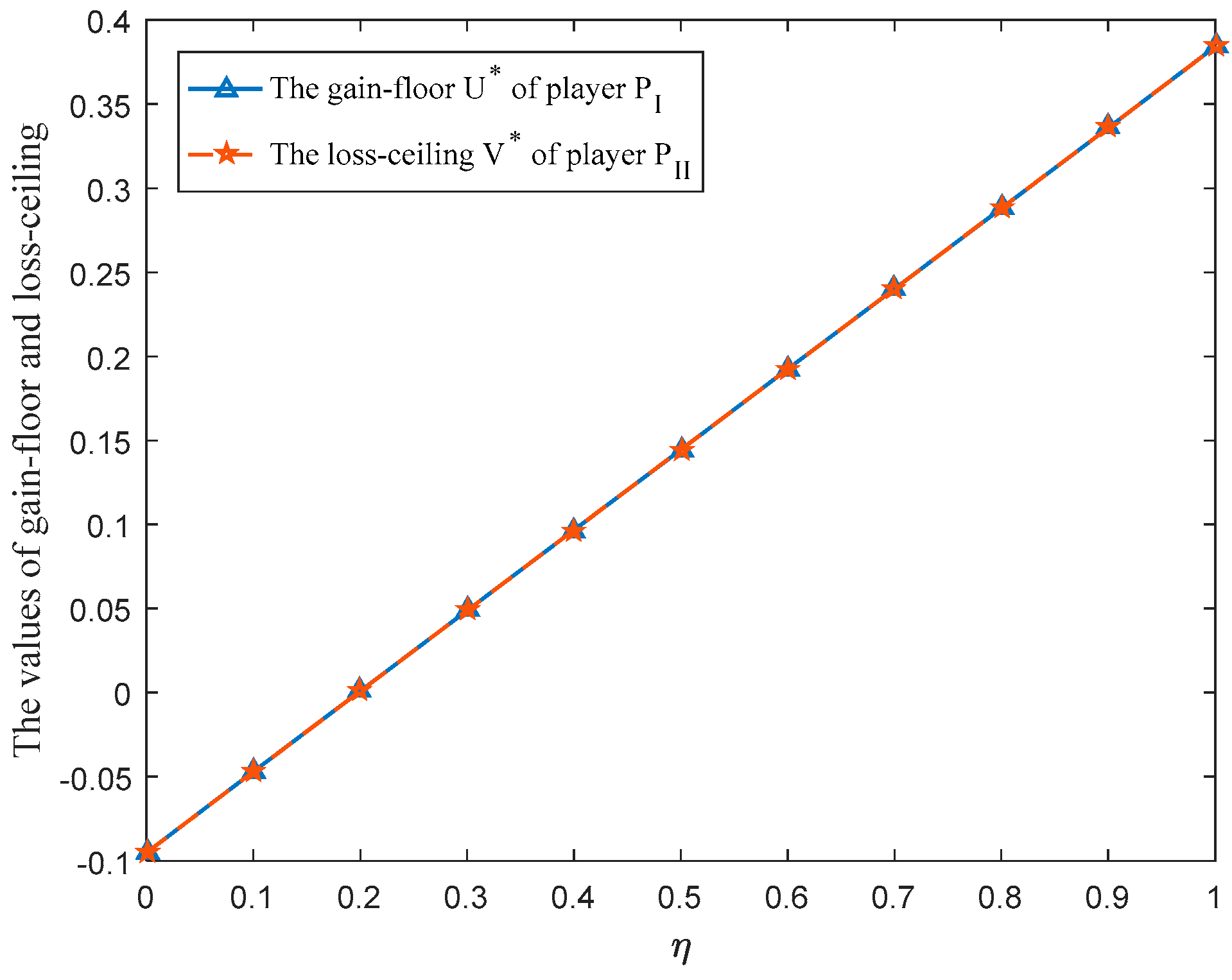
6.3. Sensitivity Analysis for the Parameter
In Equation (19), the parameter
(
) is considered in the overall prospect value of payoff value at situation
given by player
. Then, this subsection adopts different values of parameter
to solve the aforementioned case. The corresponding game results are shown in
Table 2. Meanwhile, the optimal strategy
and
of players
(management department) and
(Nature) along with the variation tendencies of gain-floor and loss-ceiling of players
and
are drawn in
Figure 5,
Figure 6 and
Figure 7 with
varying from 0 to 1 at the interval 0.1.
- (i)
The mixed strategies, gain-floor and loss-ceiling for players will change with the change of the parameter , which reflects the flexibility of the proposed method.
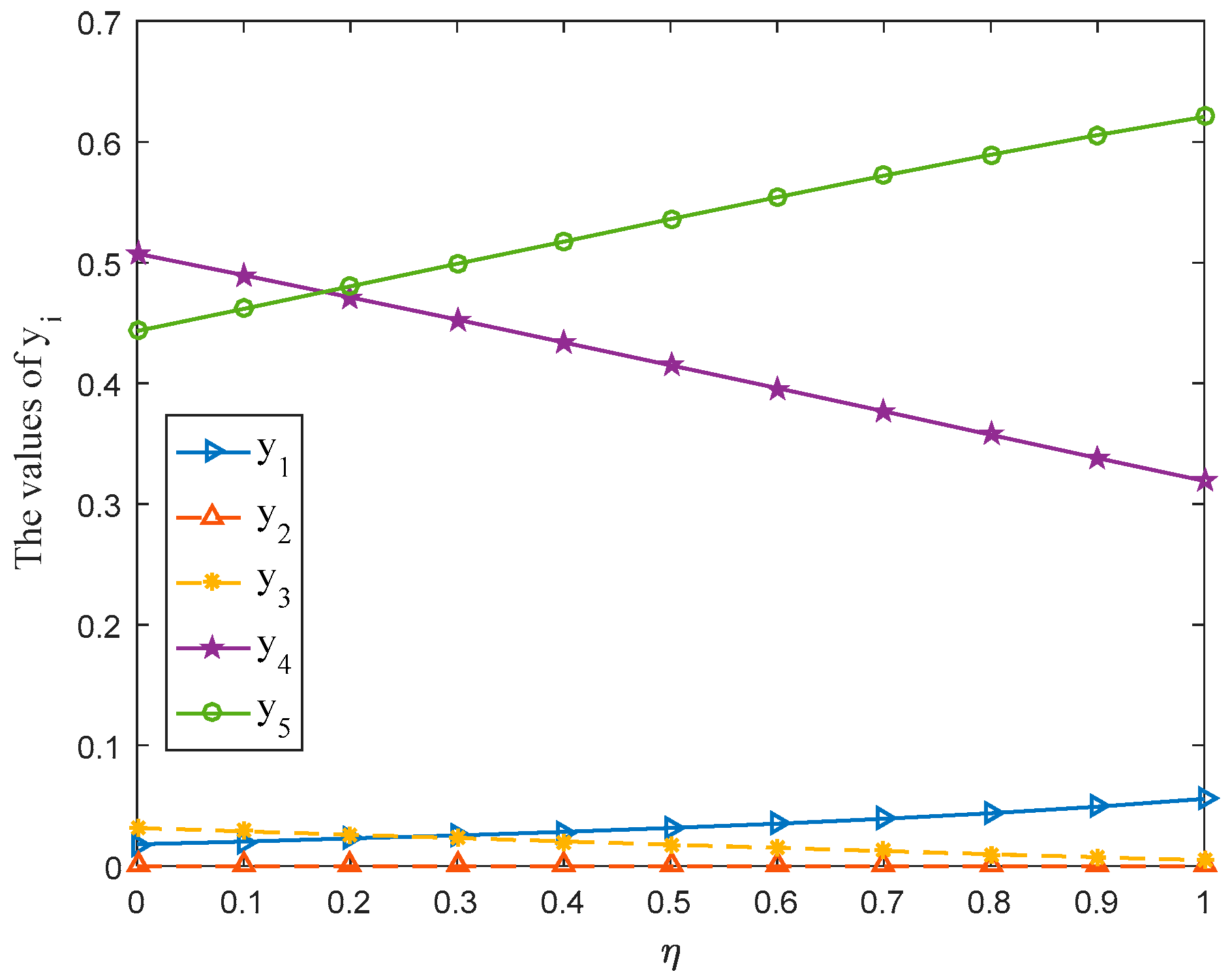
- (ii)
For the management department, when takes a value between 0.3 and 1, the probability ranking of each strategy in the selected mixed strategy keeps constant totally, that is, . The stability of the probability ranking shows that the management department should put : Livestock farming in the first place and : Manufacturing should be the last consideration when formulating the development strategy for SNNR.
- (iii)
For Nature, no matter how the parameter changes, Nature should put : Biological diversity in first place since the probability of strategy : Biological diversity in the selected mixed strategy is always greater than 0.5.
- (iv)
The gain-floor and loss-ceiling for players are equal, whichis consistent with the results obtained in [
13], and the values of these increase with the increase of the parameter
.
Strategic interventions
In response to the development strategy of SNNR, it is recommended that the management department adopts a mixed strategy instead of a pure strategy. The management department is not to maximize short-term interests, but to pursue the sustainable development of human needs and Nature in the long term. Thus, it is impossible to reach the goal by relying on a single strategy. Using the information in the payoff matrix , if the players believe that the positive ideal PLTS and negative ideal PLTS are of equal importance, then the management department is recommended to adopt a mixed strategy, namely, 4.06% Forestry, 1.96% Tourism, 41.53% Planting and 52.45% Livestock farming. If players believe that the importance of positive ideal PLTS and negative ideal PLTS is not equal, then the recommended strategy will be different. Besides, if the payoff matrix given by player changes, the optimal strategy obtained may also be different.
6.4. Comparative Analyses
6.4.1. Comparison with the Method without Considering Players’ Psychological Factor
This subsection compares the proposed method with the method [
13] regardless of the players’ psychological behavior, which adopts the notion of composite relative similarity degree to the positive ideal fuzzy solution. To make the comparison fair, we implement the solution steps introduced in [
13] on the basis of the trapezoidal fuzzy envelope matrix
, and the similarity degree adopts the cosine similarity degree defined in this paper. After a series of calculations, the final composite matrix
, which is regarded as the crisp equivalent of the payoff matrix
, is shown below.
Based on the composite matrix
, Equations (20) and (21), two linear programming models can be constructed as follows:
and
By solving the above two models, the optimal solution can be obtained as: , , .
To stress the virtues of considering the psychological behavior of players, the results obtained by the proposed method (see
Table 2 and
Figure 5,
Figure 6 and
Figure 7) are compared with those obtained by the method [
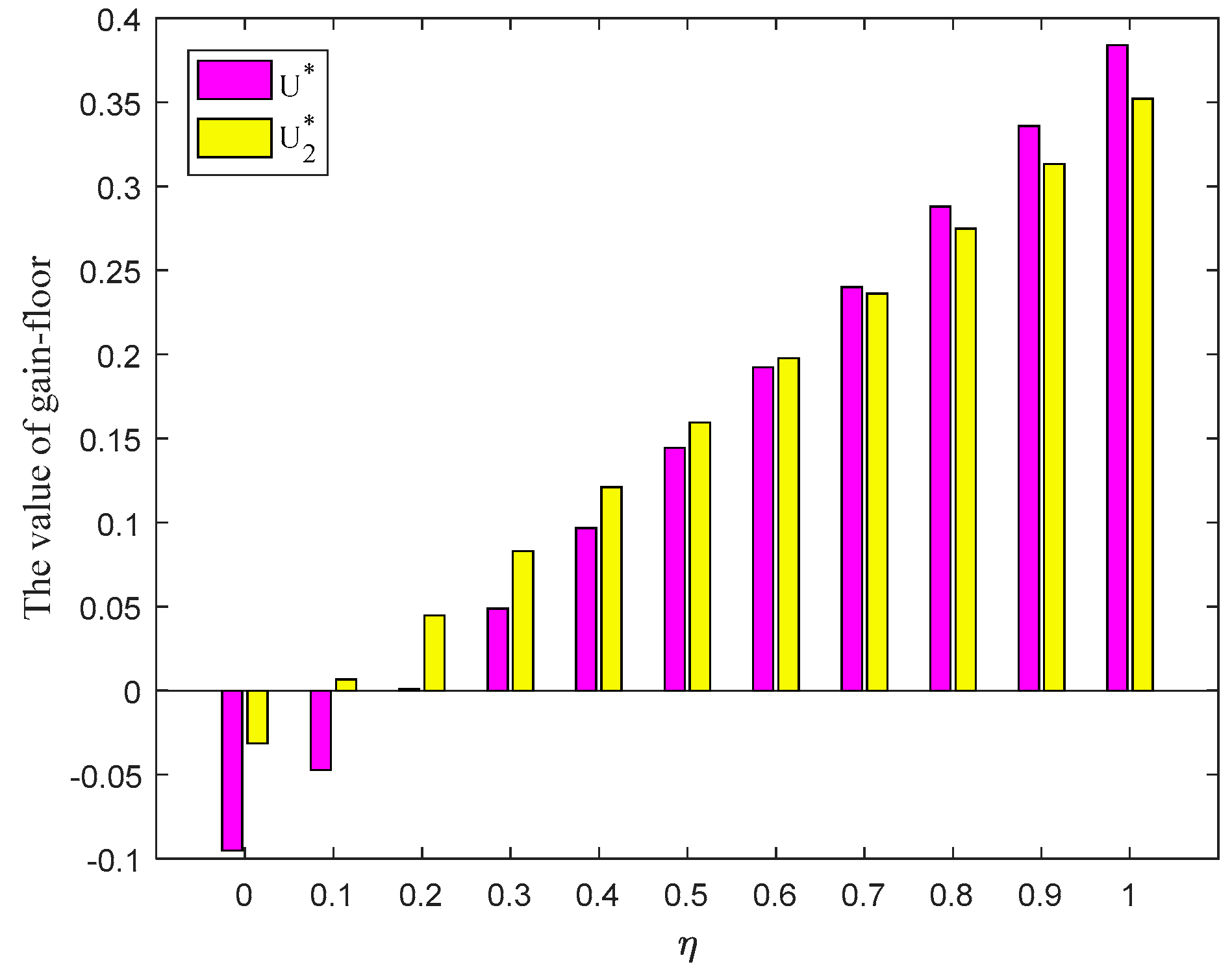
13]. The conclusions are summarized as follows:
For player
, the probability ranking of each pure strategy in the selected mixed strategy
obtained by the method [
13] is
, which is totally different from the probability ranking obtained by the proposed method (see
Table 2 and
Figure 5). That is to say, the probability ranking seems to change markedly if the game process does not include the psychological behavior of players. In addition, the probability of
: Livestock farming is largest when formulating the development strategy for SNNR, which is more in line with reality.
For player
, the probability ranking of each pure strategy in the selected mixed strategy
obtained by the method [
13] is
, which is slightly different from the probability ranking obtained by the proposed method (see
Table 2 and
Figure 6). Although the pure strategies with the largest probability obtained by the two methods are the same (i.e.,
: Biological diversity), if the psychological behavior of the players without considering in the game process, the ranking of probability will change.
According to
Table 2 and
Figure 7, the obtained gain-floor of player
and the loss-ceiling of player
by the method [
13] are less than those that acquired by the proposed method when the parameter
is not smaller than 0.8. Besides, the proposed method is also more flexible due to the consideration of players’ risk attitude.
Therefore, players’ psychological behavior will indeed have an impact on their optimal strategies. Specifically, players’ psychological behavior will change the ranking of the probability in the selected mixed strategy, resulting in different game results. This phenomenon is consistent with reality. Each player has different perception of gain and loss as a result of their psychological behavior, which will eventually change the game results. Thus, it is reasonable and necessary to incorporate players’ psychological behavior into the actual game process.
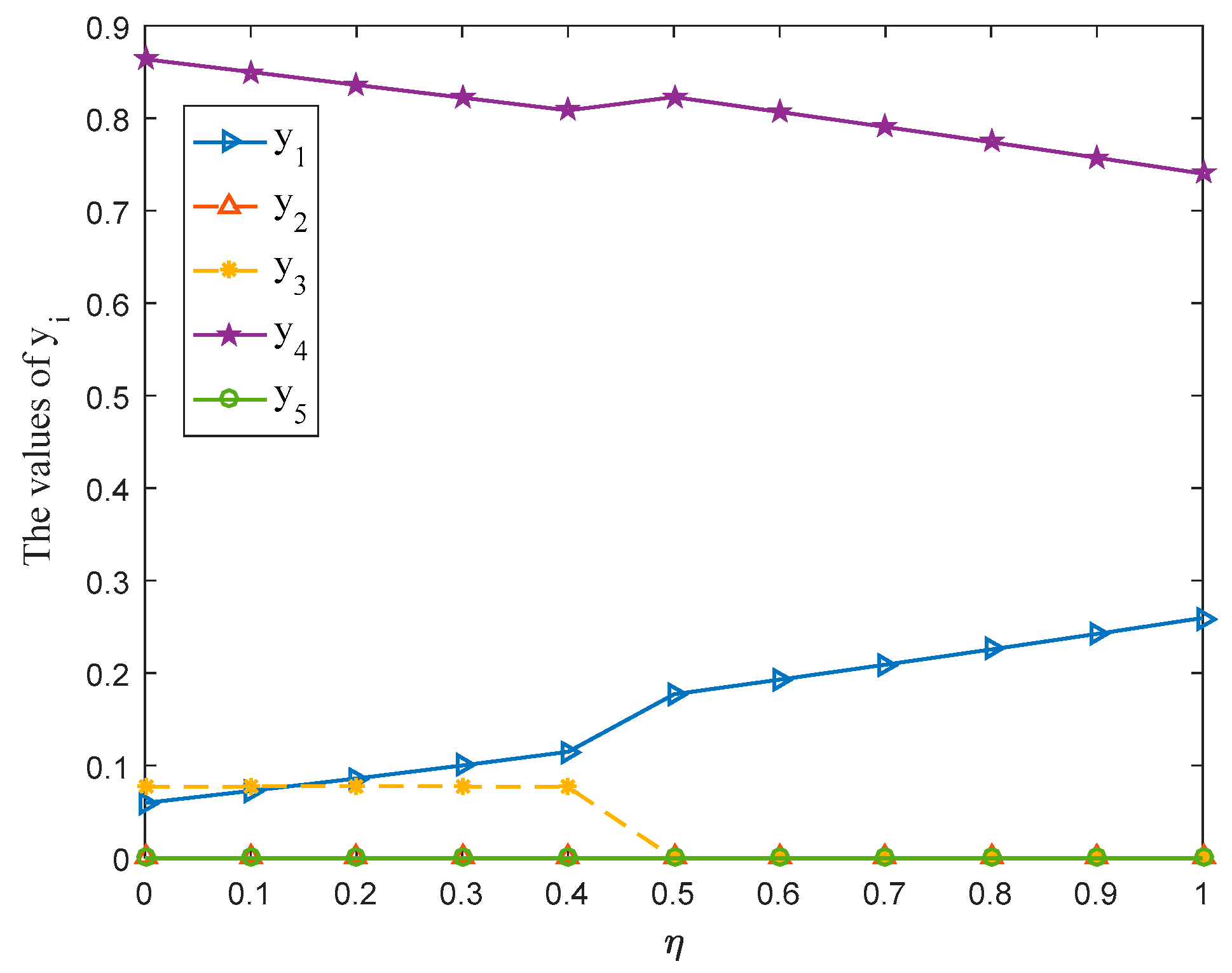
6.4.2. Comparison with Triangular Fuzzy Envelope
In order to highlight the advantages of trapezoidal fuzzy envelope used in this paper, this subsection first replaces the trapezoidal fuzzy membership function with the triangular membership function for PLTSs proposed by Mi et al. [
5]. Then the proposed method is used to solve the aforesaid development strategy of SNNR. The calculation results are shown in
Table 3. Simultaneously, the optimal strategies
and
of players
and
with
varying from 0 to 1 at the interval 0.1 are shown in
Figure 8 and
Figure 9, separately. Since the gain-floor of player
and the loss-ceiling of player
are equal invariably, the gain-floor
and
of player
obtained by triangular fuzzy envelope and trapezoidal fuzzy envelope is plotted in
Figure 10 only.
By comparing the results obtained by triangular fuzzy envelope method and trapezoidal fuzzy envelope method, the conclusions are summarized as follows:
It can be seen from
Table 3 and
Figure 8 that the probability ranking obtained by the triangular fuzzy envelope method is completely different from that obtained by trapezoidal fuzzy envelope method. Moreover, the pure strategy with the highest probability is
: Planting, and the probabilities of selecting pure strategies
: Manufacturing and
: Livestock farming are equal to 0. The probability of
: Tourism is also equal to 0 when the parameter
, which appears to be inconsistent with reality.
According to
Table 3 and
Figure 9, the probability ranking of each pure strategy in the selected mixed strategy
is
when
. The probability ranking is
when
. The pure strategies with the largest probability obtained by the two methods are
: Biological diversity, which is in line with the concept of sustainable development. However, as shown in
Figure 9, the probability of selecting pure strategy
: Capacity of water storage is always equal to 0 no matter how the parameter
changes, and the probability of
: Lakes and wetland area is also equal to 0 when
, which does not conform to the actual situation evidently.
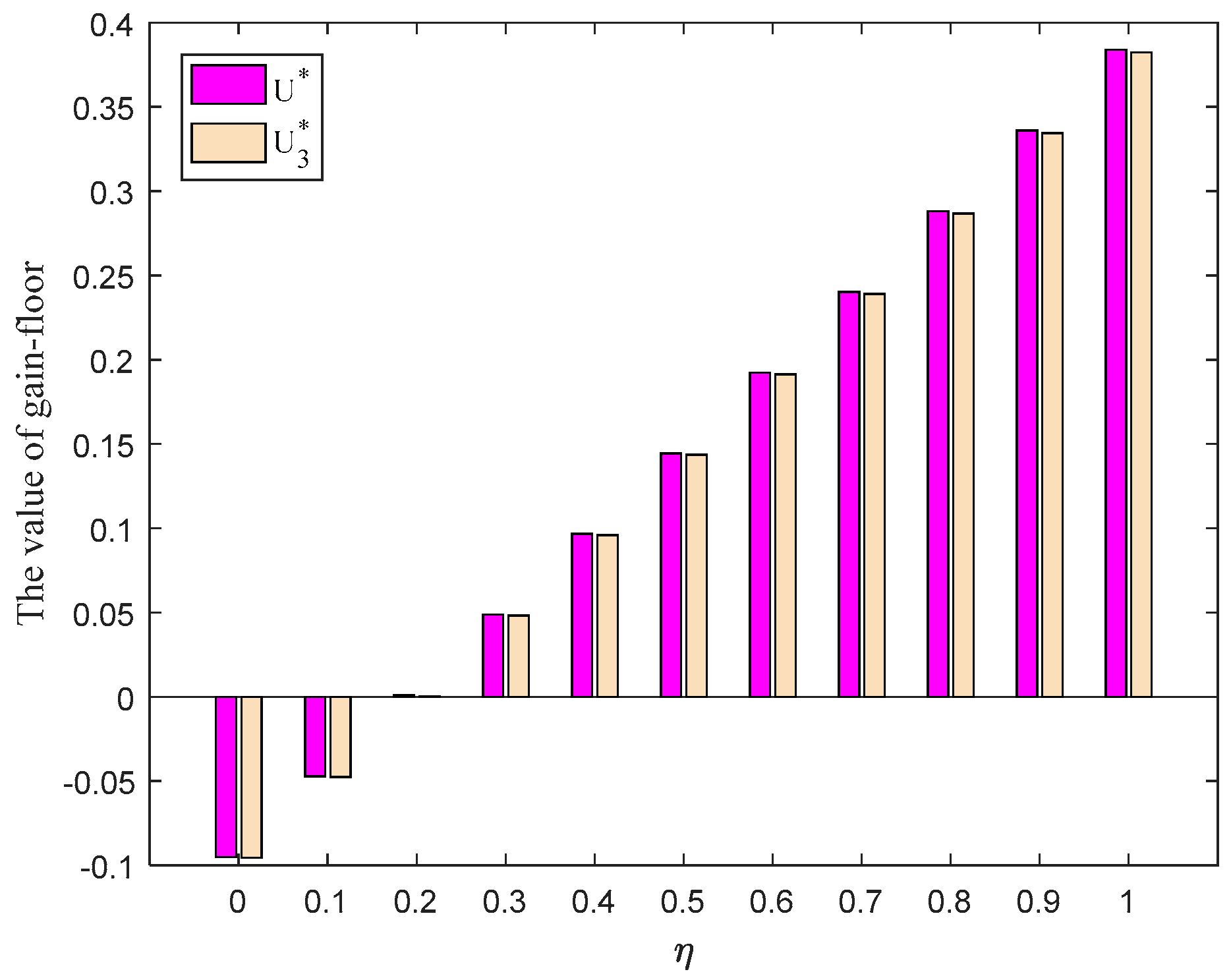
In the light of
Table 3 and
Figure 10, we can find that when
varies from 0 to 1, the variation tendency of the gain-floor
of player
obtained by the triangular fuzzy envelope method [
5] is consistent with that obtained by the proposed method in this paper. However, when
, the gain-floor
(loss-ceiling
) is smaller than the gain-floor
(loss-ceiling
). When
, the gain-floor
is greater than the gain-floor
. As mentioned earlier, the larger the value of the parameter
, the more optimistic the player, the better the result will be, that is, the greater the gain-floor and loss-ceiling. In reality, most players usually tend to ponder and solve the problem with an optimistic attitude. Hence, the greater the value of
, the higher the importance of the negative ideal PLTS, and the result obtained by the proposed method is better than the triangular fuzzy envelope method. The proposed method is more applicable for a situation in which the players are optimistic.
Thus, compared with triangular fuzzy envelope, the trapezoidal fuzzy envelope can grasp players’ evaluation information more comprehensively, and describe players’ judgments more accurately. The trapezoidal fuzzy envelope is used to flexibly deal with the linguistic information, which can make the game results more reliable.
6.4.3. Comparison with Hesitant Fuzzy Linguistic Information
If we get rid of the probabilities from PLTSs, then the PLTSs are transformed into the HFLTSs. In order to emphasize the merits of using probabilistic linguistic information in this paper, this subsection first directly removes the probabilities behind all linguistic terms in the payoff matrix
, and then the HFLTSs are represented by their fuzzy envelope by using the method proposed in [
43]; the subsequent solution steps are the same as those developed in this paper. The results are shown in
Table 4. Furthermore, the optimal strategy
and
of players
and
with
varying from 0 to 1 are shown in
Figure 11 and
Figure 12, separately. The gain-floor
and
of player
obtained by HFLTSs and PLTSs are plotted in
Figure 13.
By comparing the results obtained by HFLTSs and PLTSs, the conclusions are summarized as follows:
From
Table 4,
Figure 11 and
Figure 12, the probability rankings of each pure strategy in the selected mixed strategies for player
obtained by the HFLTSs and PLTSs are almost the same. The probability rankings of each pure strategy in the selected mixed strategies for player
obtained by the HFLTSs and PLTSs are exactly the same. This seems to indicate the effectiveness of the proposed method in this paper.
According to
Table 4 and
Figure 13, it is not hard to discover that the variation tendency of the gain-floor
of player
obtained by the HFLTSs with the parameter
varying from 0 to 1 is also consistent with that obtained by the proposed method in this paper. However, the gain-floor
(loss-ceiling
) is always larger than the gain-floor
(loss-ceiling
), which reveals the superiority of the method proposed in this paper.
PLTS is a general concept to extend HFLTS via adding probabilities without losing any original linguistic information offered by players [
22]. Consequently, it is more scientific to combine probability information with linguistic information. Probabilistic linguistic information has the following three merits: (i) better handling of the uncertainty and ambiguity in the game process; (ii) more accurate and comprehensive expression of players’ judgment; (iii) reduction in the burden and difficulty for players when giving the payoff values. Therefore, probabilistic linguistic information is more suitable for solving the actual game problem in this paper than hesitant fuzzy linguistic information.
7. Conclusions
This paper proposes a probabilistic linguistic matrix game method based on fuzzy envelope and PT, which can accept incomplete linguistic information as input. An example of a development strategy for SNNR is offered to demonstrate the effectiveness of the proposed method. The main advantages and contributions of the proposed method can be summarized as follows:
From the perspective of decision-maker and Nature, we propose a new PLMG method to solve decision-making problems. In order to defuzzify the probabilistic linguistic information, this paper proposes a fuzzy envelope of PLTS by using a trapezoidal fuzzy membership function. The parameters of the trapezoidal fuzzy membership function are decided by applying the improved POWA operator. The proposal of the improved POWA operator makes it unnecessary to normalize the PLTS in advance when determining the fuzzy envelope of the PLTS. Therefore, the new fuzzy envelope has a strong ability in polymerizing the original linguistic terms and avoiding the loss of the initial information.
Since each player has a different perception of gain and loss, for depicting the psychological behavior of decision-makers regarding losses and gains, the PT is creatively introduced into the PLMG method based on the predefined cosine distance measure. By comparing with the method without considering psychological factors, it is confirmed that the player’s psychological behavior does lead to different game results, which is consistent with reality. Thus, it is necessary to incorporate the psychological behavior of players into the actual game process.
The sensitivity analysis and comparative analyses with other methods indicate the flexibility and superiority of the proposed method. A DSS is developed based on the proposed method to illustrate its practical value.
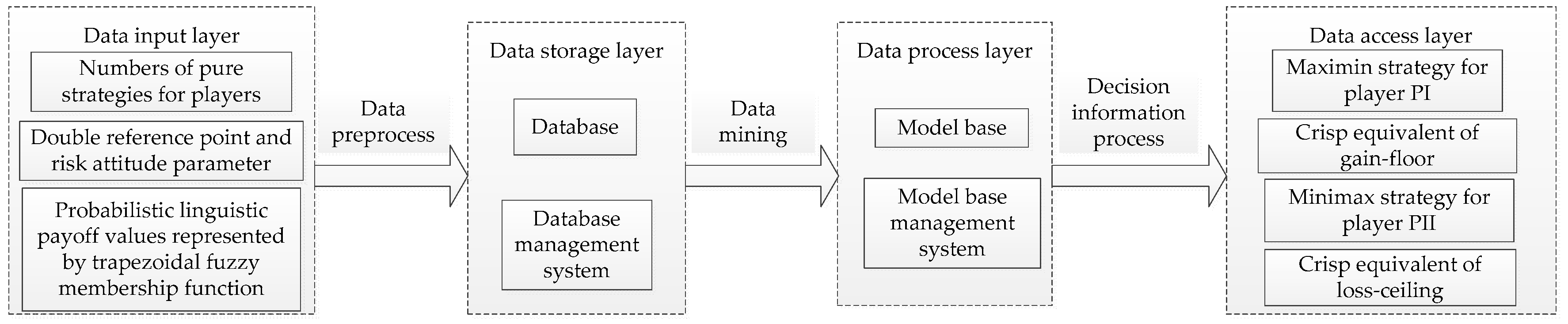
In order to show the practical value of the proposed method, a decision support system (DSS) is designed, which is based on the platform of Windows 11 by combining Microsoft SQL Server 2015 with Java.
Figure 14 displays the framework of DSS based on the proposed method.
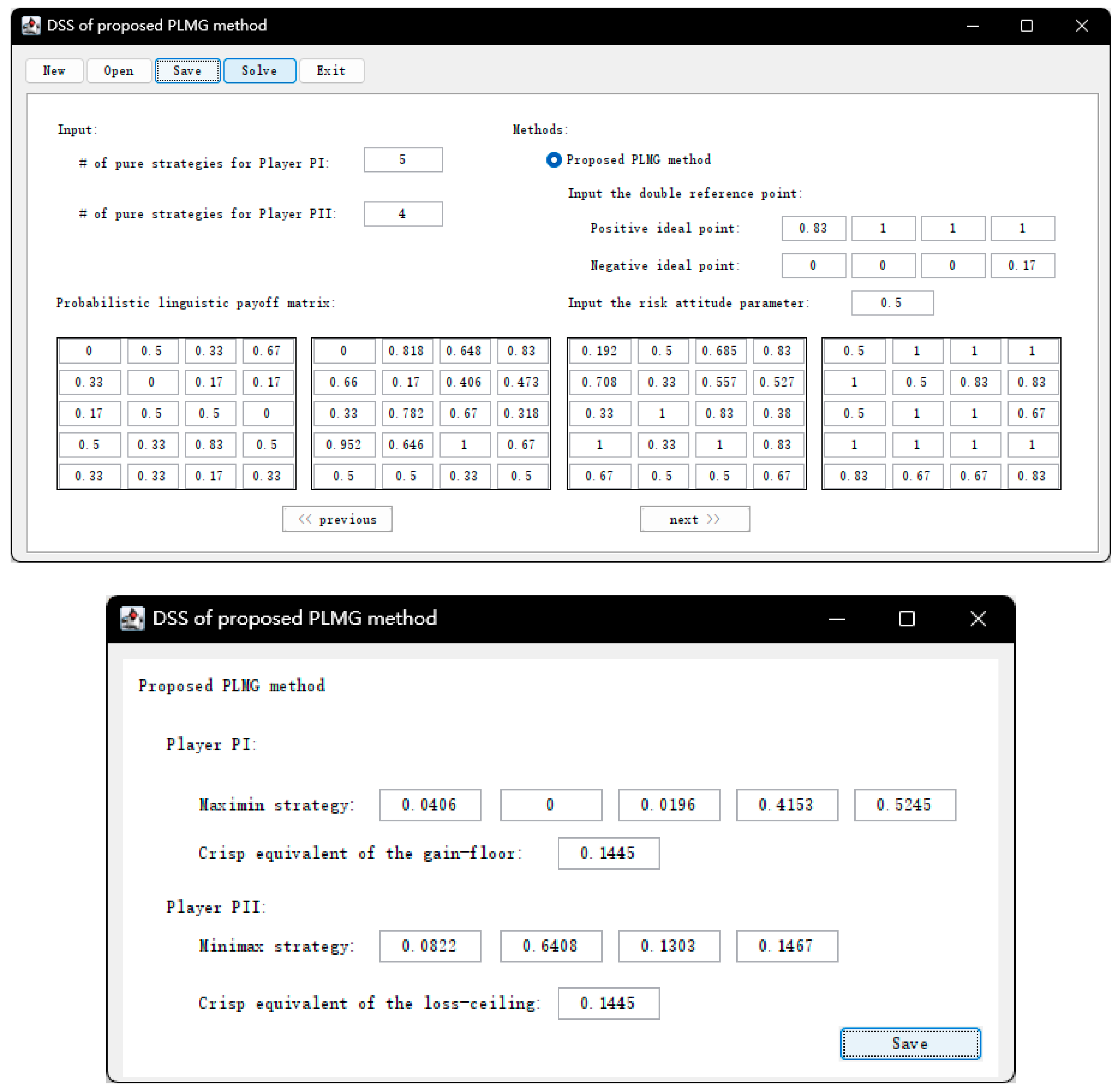
To further explain the practicality of the proposed method, the main interfaces are shown as the following
Figure 15 when using the developed DSS to solve the development strategy of SNNR in
Section 6.1. In real world decision-making, the DMs only input four matrices and other parameters, then run the DSS, which can output the decision results.
Remark 3. According to the DSS designed above, the decision-maker can quickly obtain the optimal strategy only by inputting the numbers of pure strategies for players, the payoff values expressed by trapezoidal membership function, double reference points and the risk attitude parameter. Thus, the process of the proposed method can be simplified by using the DSS.
The proposed method not only narrows the theoretical gap of matrix games in the context of probabilistic linguistic, but also has important practical value. Different from other matrix game methods, the proposed method aims to realize the long-term harmonious development of man and Nature. In addition, it is more practical for decision makers to choose a mixed strategy rather than a single pure strategy. The limitation of this study is that the developed method fails to investigate the multi-objective problems under a probabilistic linguistic environment, which is a deserving and interesting topic for the future. Besides, how to integrate other theories (e.g., regret theory and evidential theory) into game theory to solve practical problems is another challenging research direction. Moreover, the evolutionary game with natural language information is also a fascinating research field.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
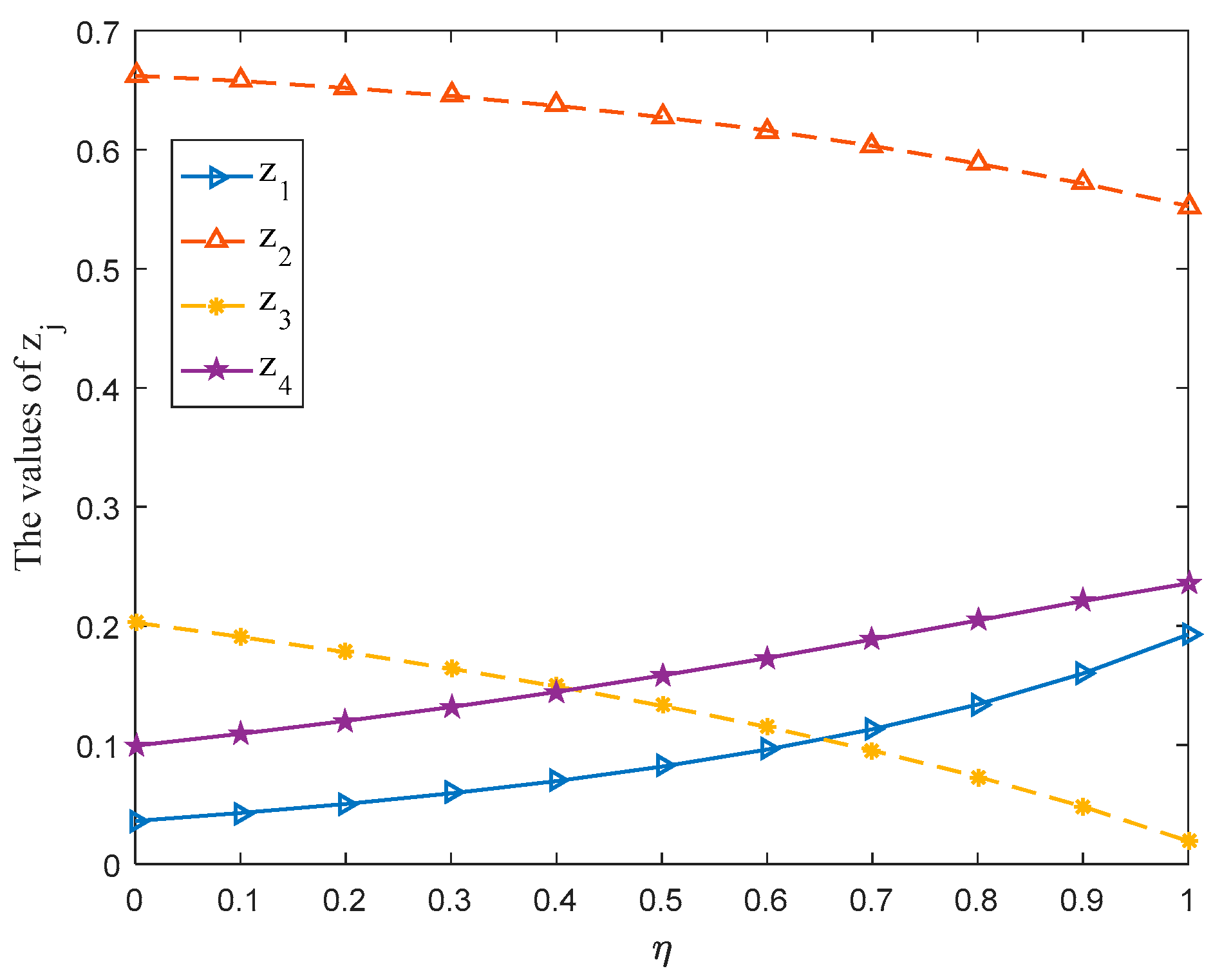{kind=link}
{kind=link}
{kind=link}
{kind=link}