
Automatic Classification of National Health Service Feedback

 , ,
, ,
Abstract
:1. Introduction
2. Related Work and Theoretical Background
- Tokenizing. This technique splits text into sentences and words to identify parts of speech (POS) such as nouns, verbs and adjectives. This creates options for selective text removal and further processing.
- Stop word removal. This technique removes commonly occurring words which are unlikely to give extra value or meaning to the text. Examples include the words “the”, “and”, “for” and “of”. There are many different open-source, stop word lists [14], which have been used in multiple applications with differing levels of success.
- Stemming or lemmatization. In this technique words are replaced with differing suffixes, whilst maintaining the same common stem. For example, the words “thanking”, “thankful” and “thanks” would all be stemmed to the word “thank”. Some of the most popular stemming algorithms, such as the Porter Stemmer algorithm [15], use a truncation approach, which although fast can often result in mistakes as it is aimed purely at the syntax of the word whilst ignoring the semantics. A slightly more robust, but slower, approach would be lemmatizing, which uses POS to infer context. Thus, it reduces words to a more meaningful root. For example, the words “am”, “are” and “is” would all be lemmatized to the root verb “be”.
- Further cleaning can also occur depending on the raw text data, such as removing URLs, specific unique characters or words identified by POS tagging.
- Term Frequency Inverse Document Frequency (TF-IDF), a measure which scores a word within a document based on the inverse proportion in which it appears in the corpus [16]. Therefore, a word will be assigned a higher score if it is common in the scored document, but rare in all the other documents in the same corpus. The advantage of this measure is that it is quick to calculate. The disadvantage is that synonyms, plurals and misspelled words would all be treated as completely different words.
- TextRank is a graph-based text ranking metric, derived from Google’s PageRank algorithm [17]. When used to identify keywords, each word in a document is deemed to be a vertex in an undirected graph, where an edge exists for each occurrence of a pair of words within a given sentence. Subsequently, each edge in this graph is deemed to be a “vote” for the vertex linked to it. Vertices with higher numbers of votes are deemed to be of higher importance, and the votes which they cast are weighted higher. By iterating through this process, the value for each vertex will converge to a score representing its importance. Note that, in contrast to the TF-IDF, which scores relative to a corpus, TextRank only evaluates the importance of a word within the given document.
- Rapid Automatic Keyword Extraction (RAKE) is an algorithm used to identify keywords and multi-word key-phrases [18]. RAKE was originally designed to work on individual documents focusing on the observation that most keyword-phrases contain multiple words, but very few stop words. Through the combination of a phrase delimiter, word delimiter and stop word list, RAKE identifies the most important keywords/key-phrases in a document and weights them accordingly.
3. Research Problem Statement and Input Data
3.1. Research Problem Statement
3.2. Input Data
- The dataset consists of 2307 items. Due to the text or theme being omitted, only 2224 items were deemed viable for classification. This is relatively small compared to most datasets used in text classification.
- The length of each text item is short, the average item contained 49.7 words. The shortest text item is 2 words long and the longest text item is 270 words long.
- The number of themes is large with respect to the size of the dataset. Even if the themes were evenly distributed, this would result in an average of less than 93 text items into each category.
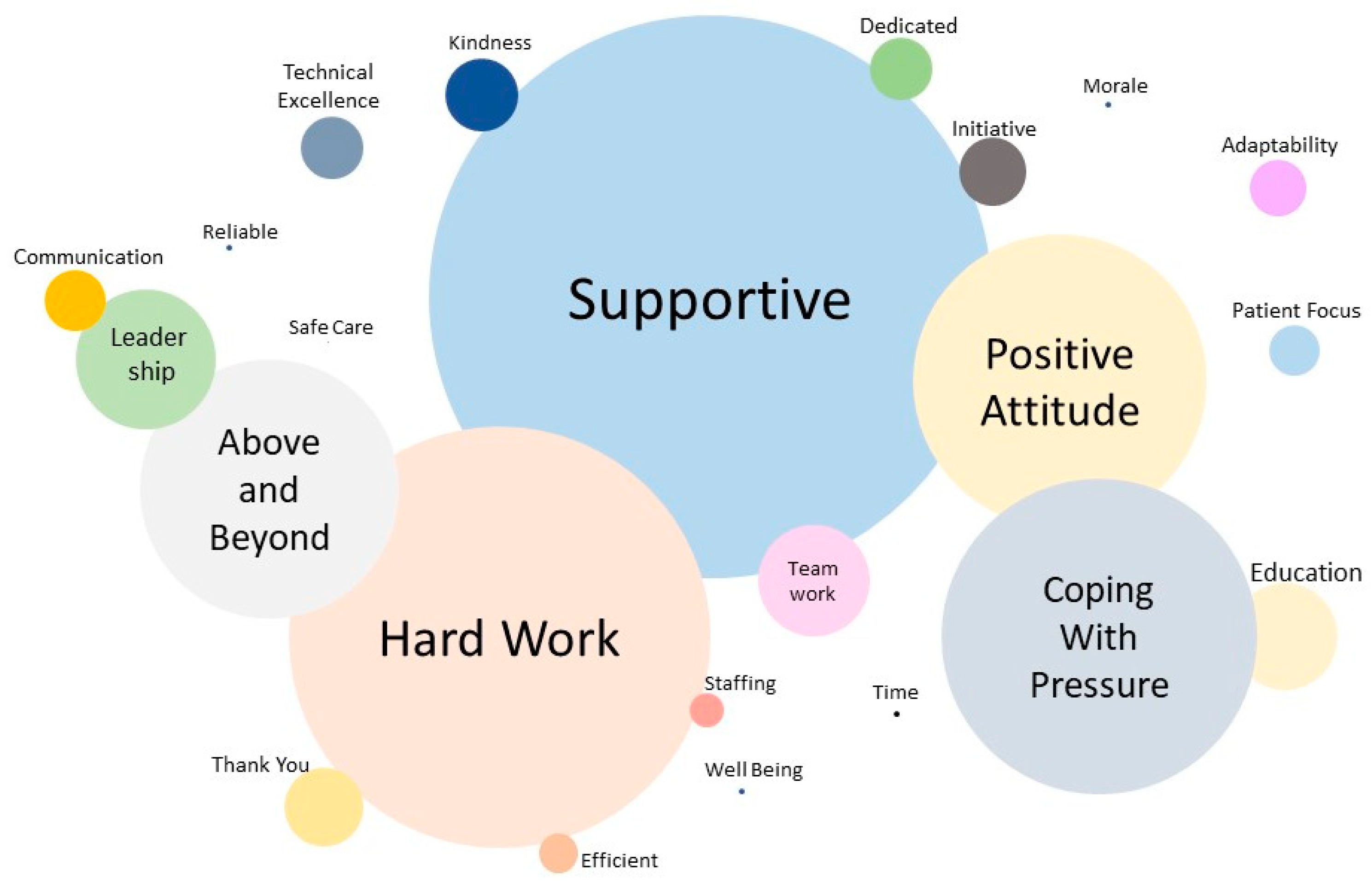
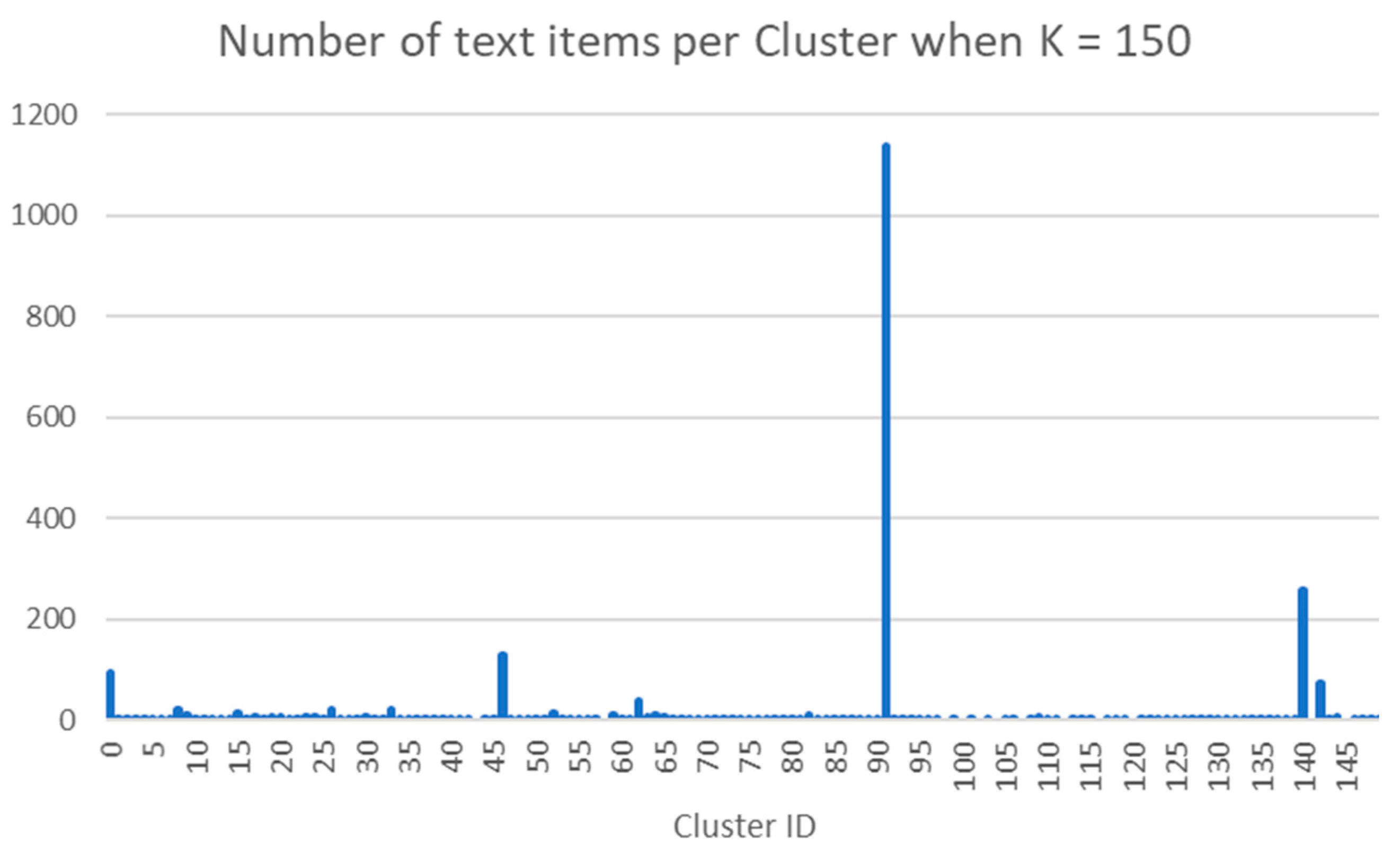
- The distribution of the themes is not balanced. For example, the largest theme “Supportive” is the primary theme for 439 items (19.74%). The smallest theme “Safe Care” is the primary theme for solely 1 item (0.04%). The number of items per category has a standard deviation of 111.23 items. The distribution for the remaining theme categories is also uneven, see Figure 2.
- Since all the text is positive feedback, many of the text items share a similar vocabulary and tone regardless of the theme category to which they belong. For example, the phrase “Thank you” appears in 807 items (36.29%). However, only 61 items (2.74%) belong to the primary theme of “Thank You”.
- The themes are of a subjective nature, dependent on individual interpretation so they could be viewed in different ways. For example, the theme “Teamwork” is not objectively independent of the theme “Leadership”. Thus, there may be some abstract overlap between these themes. Furthermore, there is no definitive measure to determine which theme is more important than another for a given text item, making the choice of the primary theme equally subjective.
- The “Amazon Hierarchical Reviews” dataset is a sample of reviews from different products on Amazon, along with the corresponding product categories. Amazon uses a hierarchical product category model, so that items can be categorized at different levels of granularity. Each item within this dataset is categorized in three levels. For example, at level 1 a product could be in the “toys/games” category. At level 2, it could be in the more specific “games” category. At level 3, it could be in the more specific “jigsaw puzzles” category. This dataset was selected as it provides a direct comparison of classification accuracy, when considering the relative dataset volume compared to the number of categories.
- The “Twitter COVID Sentiment” dataset is a curation of tweets from March and April 2020 which mentioned the words “coronavirus” or “COVID”. This dataset was manually classified within one of the following five sentiments: extremely negative, negative, neutral, positive or extremely positive. The source dataset had been split into a training set and a testing set. As with the Reuters dataset, these two subsets were combined.
- The “Twitter Tweet Genre” dataset is a small selection of tweets which have been manually classified into one of the following four high level genres: sports, entertainment, medical and politics.
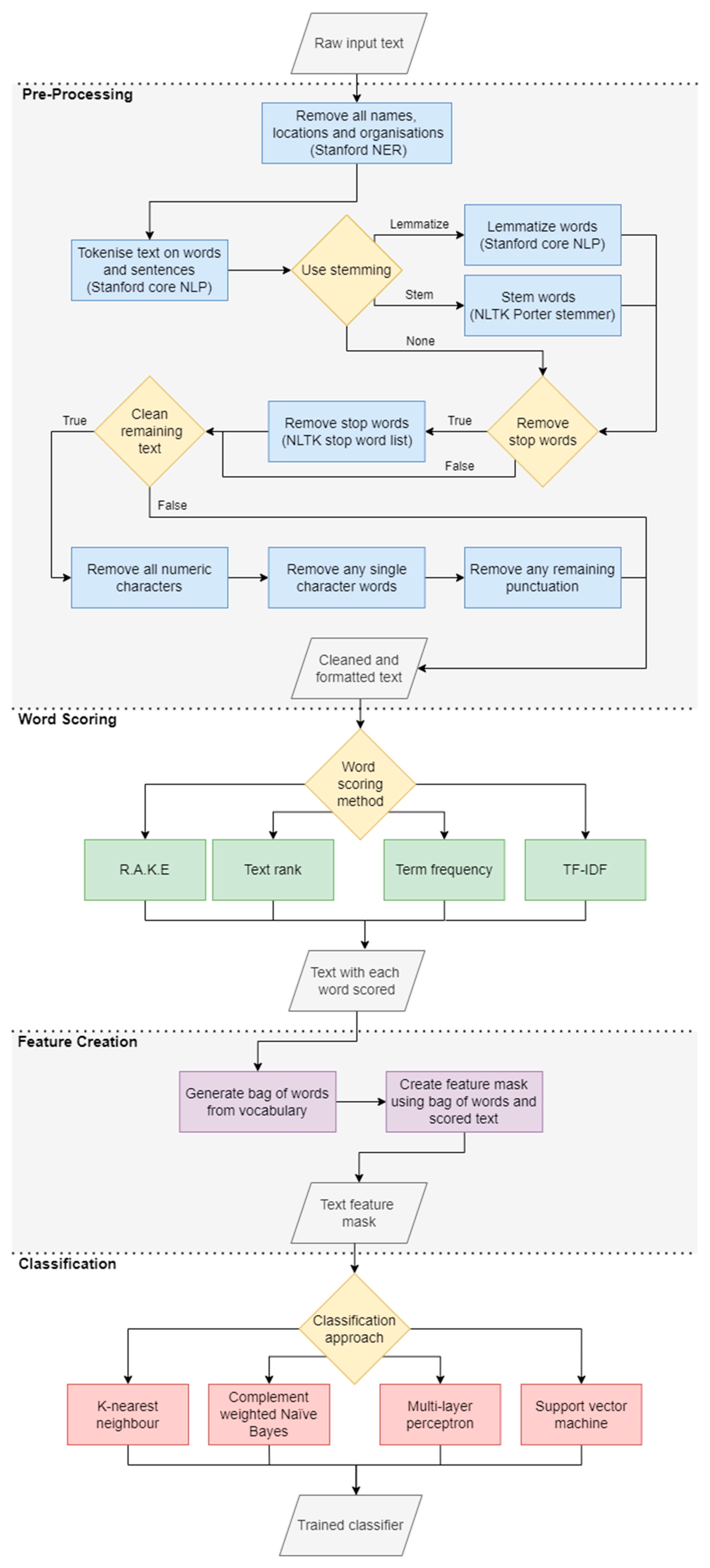
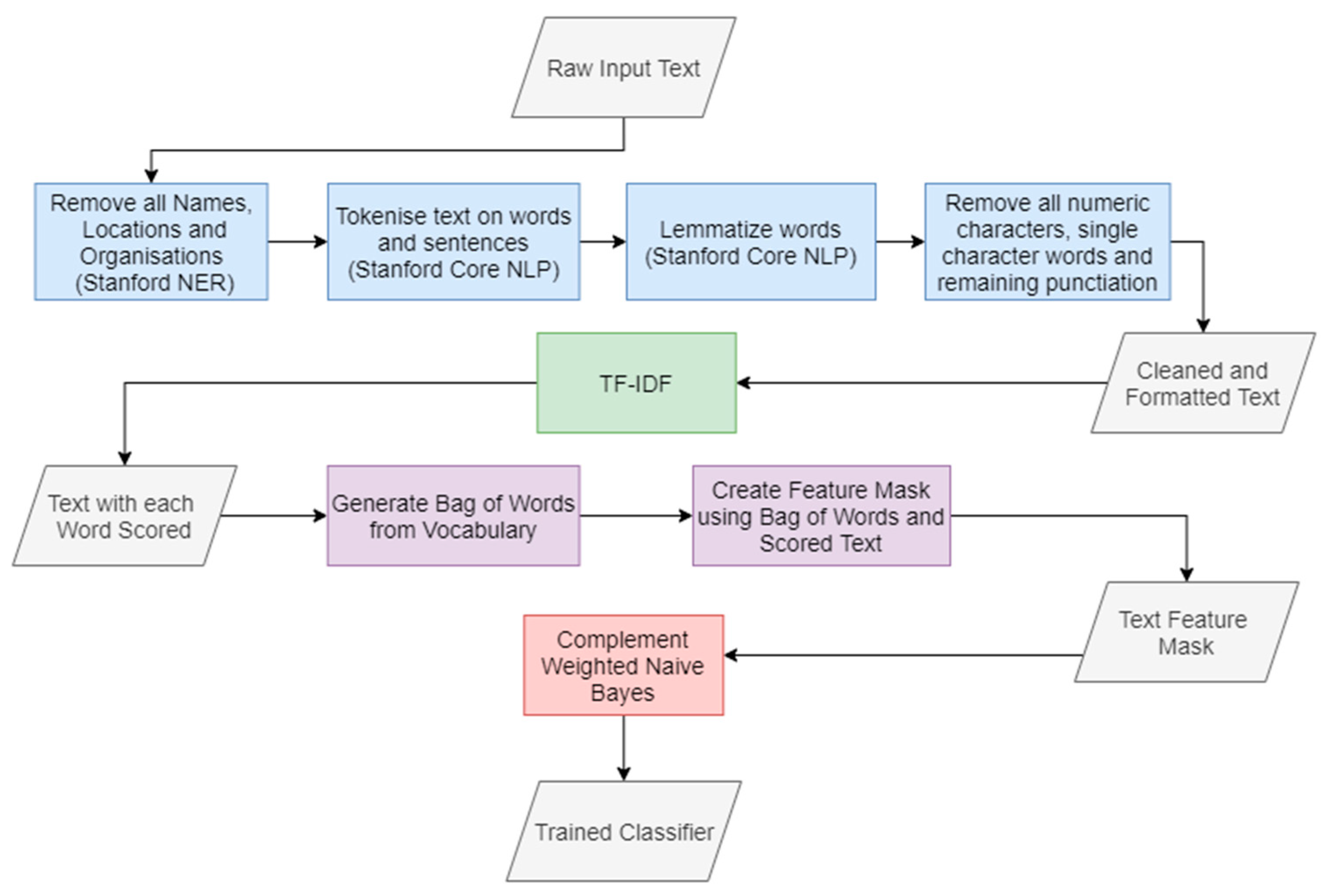
4. Methodology
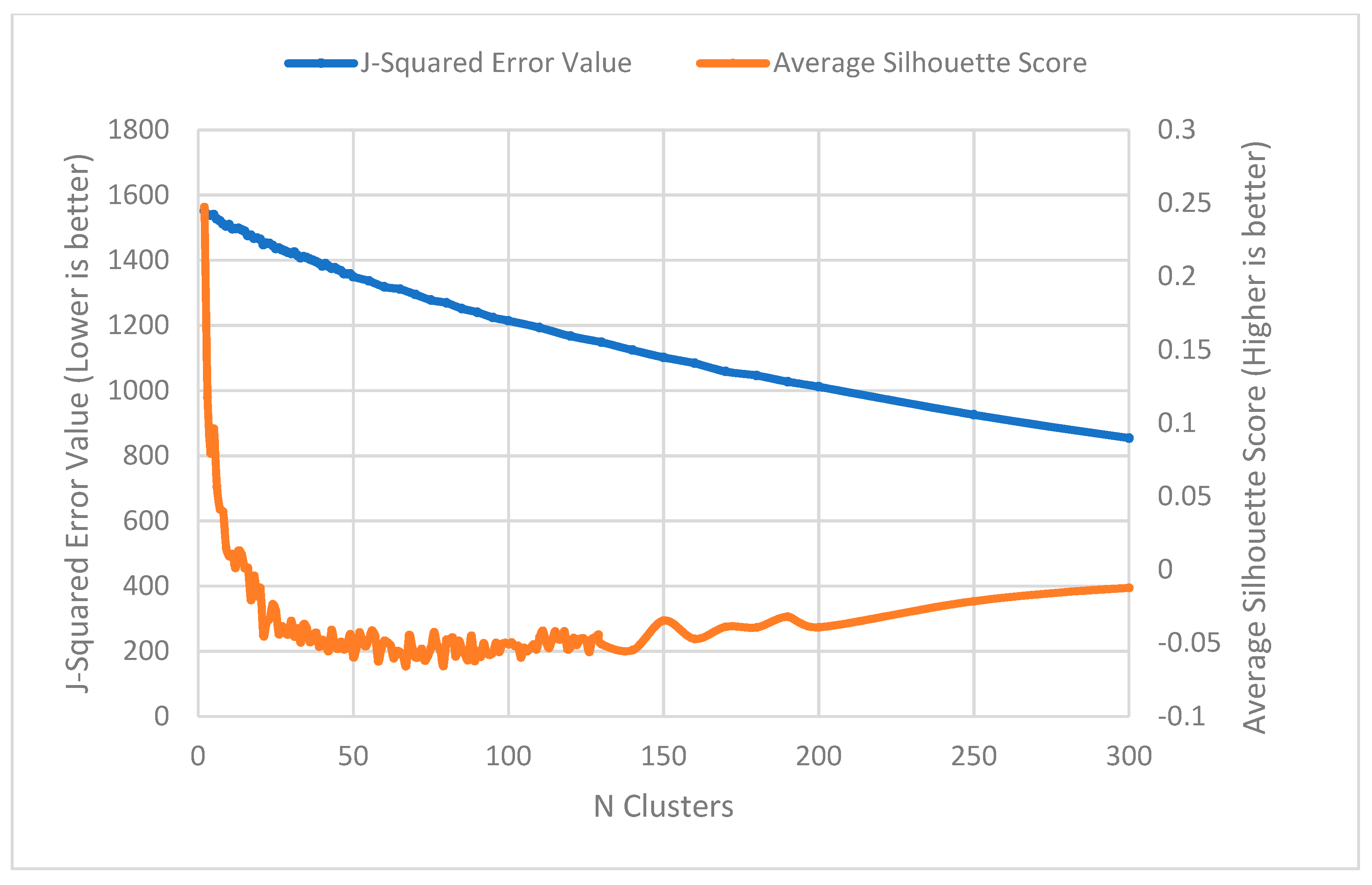
5. Results
6. Discussion
6.1. Practical Implications
- (R1)
- The NHS is likely to adopt our approach to automatically classify feedback. This means we have successfully reduced the workload of NHS staff by providing a tool which can be used in place of manual classification. Therefore, the answer to (R1) is positive. Although our proposed classification pipeline attained a lower micro-averaged F1 score on the LFE dataset compared to the benchmark datasets, given the limitations of the dataset, the NHS has found this better than the alternative of manually classifying future datasets.
- (R2)
- The performance of the classification pipeline published in this paper is evaluated by comparing it against the results of the Reuters dataset with other published work. In this research, a micro-averaged F1 score of 93.30% was achieved. As shown in Table 7, that accuracy outperforms the seminal SVM approaches of Joachims [32], which achieved a micro-averaged breakeven point of 86.40%. Furthermore, the classification pipeline performed in-line with or surpassed more recent approaches [33,34,35]; demonstrating that this classification pipeline produces high accuracy results on other datasets. Therefore, the answer to (R2) is positive.
6.2. Theoretical Implications
- The dataset is relatively small. The overall size of the items in the dataset may have resulted in an advantage to the Reuters and Amazon Hierarchical Reviews results, as it is widely accepted that a larger and more varied dataset will produce better classification results [51,52]. However, the much smaller Twitter Tweet Genre dataset, also achieved a high level of accuracy with a micro-averaged F1 score of 82.80%. Considering the LFE dataset had almost double the number of items, this characteristic alone is unlikely to be the sole cause of the low accuracy results.
- The length of each text item is short. Both Twitter datasets attained vastly different results to the LFE dataset despite the fact they are similarly characterized as being short in length. These Twitter datasets also had considerably shorter average word counts than the LFE dataset and still outperformed it overall. In conclusion, the average length of each text item is unlikely to be a discriminatory characteristic.
- The number of text items per category is small. The average distribution of items per category did not limit performance on the Reuters dataset. However, that could be attributed to the larger overall size, which would have provided more samples for each category in comparison to the LFE dataset.
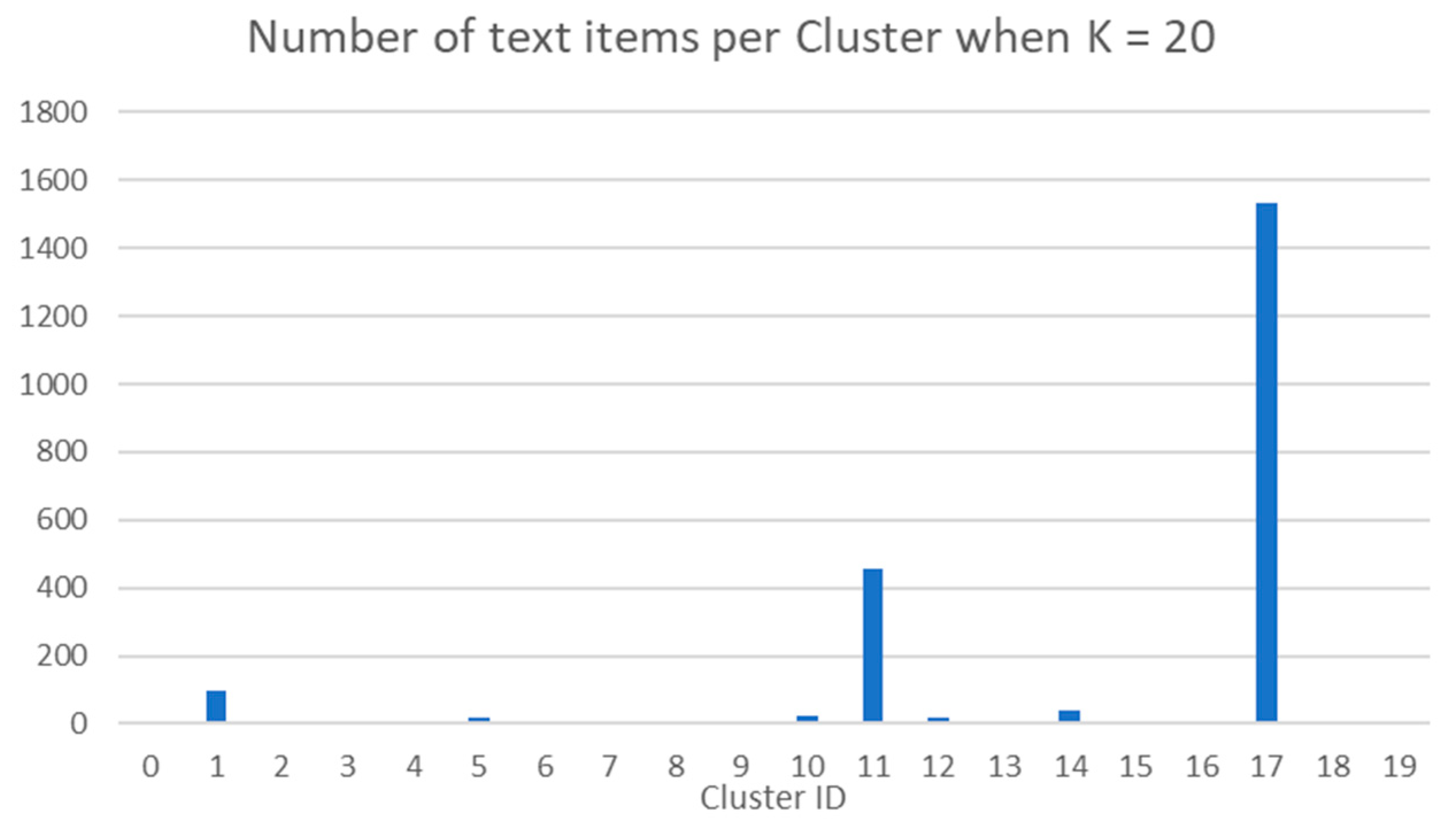
- The distribution of categories is not balanced. In terms of category distribution, all classification techniques for both the Reuters and LFE datasets suffered from the same issue, where the smallest categories were never applied when classifying the test dataset. Specifically, nine of the Reuters categories and five of the LFE categories never appeared in any of the test classifications. Although this did not impact the overall results of the Reuters classification, the percentage of small categories was much greater in the LFE dataset. In the LFE dataset, 25% of categories comprised less than 1% of the dataset compared with 13.8% in the Reuters dataset. These tiny categories are almost certainly a contributing factor to the lower accuracy of the LFE results.
- All the text is positive. The use of common terms across all categories did not have a significantly negative impact on the classification accuracy of the Amazon Hierarchical Reviews dataset. However, the use of common terms did significantly impact the LFE results. This could be attributed to the fact that each Amazon review had an average word count of more than 50% the average LFE item, resulting in a diluting effect of the repeated common words. Due to the overall larger size of the Amazon Hierarchical Reviews dataset, it had a much larger vocabulary in comparison to the LFE dataset, which may explain why TF-IDF was the optimal scoring method for this dataset.
- The categories are subjectively defined. The subjective nature of both the manual classification and the categories themselves are likely to have played a role in the lower scores for accuracy in both the LFE and the Twitter COVID Sentiment datasets. Although, if the accuracy alone is considered, it is not possible to determine a direct link.
- Placement. Cluster ID 5 has a high prevalence of the words: “placement”, “mentor”, “support” and “team”.
- Course Pass. Cluster ID 7 has a high prevalence of the words: “course”, “success”, “level”, “pass”, “hard” and “work”.
- General Support. Cluster ID 3 has a high prevalence of the words: “thank”, “support” and “help”.
- “Thank” appears in 43.44% of items.
- “Support” appears in 32.10% of items.
- “Work” appears in 41.46% of items, “Hard” appears in 15.83% of items.
6.3. Future Research
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Theme | Description |
|---|---|
| Above and Beyond | Performing in excess of the expectations or demands. |
| Adaptability | Being able to adjust to new conditions. |
| Communication | Clearly conveying ideas and tasks to others. |
| Coping with Pressure | Adjusting to unusual demands or stressors. |
| Dedicated | Devoting oneself to a task or purpose. |
| Education | Achieving personal improvement through training/schooling. |
| Efficient | Working in a well-organized and competent way. |
| Hard Work | Working with a great deal of effort or endurance. |
| Initiative | Taking the opportunity to act before others do. |
| Innovative | Introducing new ideas; original and creative in thinking. |
| Kindness | Being friendly and considerate to colleagues and/or patients. |
| Leadership | Influencing others in a group by taking charge of a situation. |
| Morale | Providing confidence and enthusiasm to a group. |
| Patient Focus | Prioritizing patient care above other tasks. |
| Positive Attitude | Showing optimism about situations and interactions. |
| Reliable | Consistently good in quality or performance. |
| Safe Care | Taking all necessary steps to ensure safety protocols are met. |
| Staffing | Covering extra shifts when there is illness/absence. |
| Supportive | Providing encouragement or emotional help. |
| Teamwork | Collaboration with a group to perform well on a given task. |
| Technical Excellence | Producing successful results based on specialist expertise. |
| Time | Devoting additional time to colleagues and/or patients. |
| Thank You | Giving a direct compliment to a member of staff. |
| Well-Being | Making a colleague and/or patient, comfortable and happy. |
Appendix B
- “My food stock is not the only one which is empty…PLEASE, don’t panic, THERE WILL BE ENOUGH FOOD FOR EVERYONE if you do not take more than you need. Stay calm, stay safe.#COVID19france #COVID_19 #COVID19 #coronavirus #confinement #Confinementotal #ConfinementGeneral https://t.co/zrlG0Z520j”—Manually classified as “extremely negative”.
- “Me, ready to go at supermarket during the #COVID19 outbreak. Not because I’m paranoid, but because my food stock is literally empty. The #coronavirus is a serious thing, but please, don’t panic. It causes shortage…#CoronavirusFrance #restezchezvous #StayAtHome #confinement https://t.co/usmuaLq72n”—Manually classified as “positive”.
Appendix C
| k | F1 Score (Micro) | F1 Score (Macro) |
|---|---|---|
| 9 | 0.205481 | 0.053783 |
| 11 | 0.215820 | 0.053813 |
| 13 | 0.223463 | 0.055129 |
| 15 | 0.223917 | 0.053341 |
| 17 | 0.227964 | 0.054558 |
| 19 | 0.232904 | 0.054457 |
| 21 | 0.230655 | 0.053048 |
| 23 | 0.242796 | 0.055268 |
| 25 | 0.241004 | 0.050718 |
| 27 | 0.238308 | 0.049159 |
| 29 | 0.230211 | 0.047173 |
| 31 | 0.232014 | 0.047116 |
| Weighting Method | F1 Score (Micro) | F1 Score (Macro) |
|---|---|---|
| Uniform | 0.242796 | 0.055268 |
| Distance | 0.236509 | 0.067957 |
| Parameter | Type/Value |
|---|---|
| Activation function | Rectified linear unit function (RELU) |
| Weight optimization algorithm | Adam |
| Max epochs | 200 |
| Batch size | 64 |
| Alpha (regularization term) | 0.0001 |
| Beta (decay rate) | 0.9 |
| Epsilon (numerical stability) | 1 × 10−8 |
| Early stopping tolerance | 1 × 10−4 |
| Early stopping iteration range | 10 |
| Kernel | F1 Score (Micro) | F1 Score (Macro) |
|---|---|---|
| RBF | 0.241 | 0.102515 |
| Polynomial (Degree 3) | 0.118252 | 0.026344 |
| Sigmoid | 0.369148 | 0.207289 |
| Linear | 0.375895 | 0.19138 |

References
- Pong, J.Y.-H.; Kwok, R.C.-W.; Lau, R.Y.-K.; Hao, J.-X.; Wong, P.C.-C. A comparative study of two automatic document classification methods in a library setting. J. Inf. Sci. 2007, 34, 213–230. [Google Scholar] [CrossRef]
- Androutsopoulos, I.; Koutsias, J.; Chandrinos, K.V.; Paliouras, G.; Spyropoulos, C.D. An evaluation of Naive Bayesian anti-spam filtering. In Proceedings of the Workshop on Machine Learning in the New Information Age; Potamias, G., Moustakis, V., van Someren, M., Eds.; Springer: Barcelona, Spain, 2000; pp. 9–17. [Google Scholar]
- Connelly, A.; Kuri, V.; Palomino, M. Lack of consensus among sentiment analysis tools: A suitability study for SME firms. In Proceedings of the 8th Language and Technology Conference, Poznań, Poland, 17–19 November 2017; pp. 54–58. [Google Scholar]
- Meyer, B.J.F. Prose Analysis: Purposes, Procedures, and Problems 1. In Understanding Expository Text; Understanding Expository Text; Routledge: Oxfordshire, England, UK, 2017; pp. 11–64. [Google Scholar]
- Kim, S.-B.; Han, K.-S.; Rim, H.-C.; Myaeng, S.H. Some effective techniques for naive bayes text classification. IEEE Trans. Knowl. Data Eng. 2006, 18, 1457–1466. [Google Scholar]
- Ge, L.; Moh, T.-S. Improving text classification with word embedding. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1796–1805. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding bag-of-words model: A statistical framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, W.; Jiang, C. A survey of word embeddings based on deep learning. Computing 2020, 102, 717–740. [Google Scholar] [CrossRef]
- Manevitz, L.M.; Yousef, M. One-class SVMs for document classification. J. Mach. Learn. Res. 2001, 2, 139–154. [Google Scholar]
- Ting, S.L.; Ip, W.H.; Tsang, A.H.C. Is Naive Bayes a good classifier for document classification. Int. J. Softw. Eng. Its 2011, 5, 37–46. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. Ki Künstliche Intell. 2016, 26, 357–363. [Google Scholar]
- Kannan, S.; Gurusamy, V.; Vijayarani, S.; Ilamathi, J.; Nithya, M. Preprocessing techniques for text mining. Int. J. Comput. Sci. Commun. Netw. 2014, 5, 7–16. [Google Scholar]
- Nothman, J.; Qin, H.; Yurchak, R. Stop word lists in free open-source software packages. In Proceedings of the Workshop for NLP Open Source Software (NLP-OSS), Melbourne, Australia, 20 July 2018; pp. 7–12. [Google Scholar]
- Jivani, A.G. A comparative study of stemming algorithms. Int. J. Comp. Tech. Appl 2011, 2, 1930–1938. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning, Citeseer, Banff, AB, Canada, 27 February–1 March 2011; Volume 242, pp. 29–48. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 2 July 2004; pp. 404–411. [Google Scholar]
- Rose, S.; Engel, D.; Cramer, N.; Cowley, W. Automatic keyword extraction from individual documents. Text. Min. Appl. Theory 2010, 1, 1–20. [Google Scholar]
- Ljungberg, B.F. Dimensionality reduction for bag-of-words models: PCA vs. LSA. Semanticscholar. Org. 2019. Available online: http://cs229.stanford.edu/proj2017/final-reports/5163902.pdf (accessed on 8 February 2022).
- Cavnar, W.B.; Trenkle, J.M. N-gram-based text categorization. In Proceedings of the SDAIR-94, 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, NV, USA, 1 June 1994; Volume 161175. [Google Scholar]
- Ogada, K.; Mwangi, W.; Cheruiyot, W. N-gram based text categorization method for improved data mining. J. Inf. Eng. Appl. 2015, 5, 35–43. [Google Scholar]
- Schonlau, M.; Guenther, N.; Sucholutsky, I. Text mining with n-gram variables. Stata J. 2017, 17, 866–881. [Google Scholar] [CrossRef]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2016, 23, 155–162. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Han, E.-H.S.; Karypis, G.; Kumar, V. Text categorization using weight adjusted k-nearest neighbor classification. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Hong Kong, China, 16–18 April 2001; pp. 53–65. [Google Scholar]
- Rennie, J.D.; Shih, L.; Teevan, J.; Karger, D.R. Tackling the poor assumptions of naive bayes text classifiers. In Proceedings of the 20th International Conference on Machine Learning (ICML-03), Washington, DC, USA, 21–24 August 2003; pp. 616–623. [Google Scholar]
- Wermter, S. Neural network agents for learning semantic text classification. Inf. Retrieva 2000, 3, 87–103. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, X. A re-examination of text categorization methods. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 42–49. [Google Scholar]
- Frank, E.; Bouckaert, R.R. Naive Bayes for Text Classification with Unbalanced Classes. In Lecture Notes in Computer Science; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; pp. 503–510. [Google Scholar] [CrossRef] [Green Version]
- Liu, B. Sentiment analysis and subjectivity. Handb. Nat. Lang. Process. 2010, 2, 627–666. [Google Scholar]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the European Conference on Machine Learning, Bilbao, Spain, 13–17 September 1998; pp. 137–142. [Google Scholar]
- Banerjee, S.; Majumder, P.; Mitra, M. Re-evaluating the need for modelling term-dependence in text classification problems. arXiv 2017, arXiv:1710.09085. [Google Scholar]
- Ghiassi, M.; Olschimke, M.; Moon, B.; Arnaudo, P. Automated text classification using a dynamic artificial neural network model. Expert Syst. Appl. 2012, 39, 10967–10976. [Google Scholar] [CrossRef]
- Zdrojewska, A.; Dutkiewicz, J.; Jędrzejek, C.; Olejnik, M. Comparison of the Novel Classification Methods on the Reuters-21578 Corpus. In Proceedings of the Multimedia and Network Information Systems: Proceedings of the 11th International Conference MISSI, Wrocław, Poland, 12–14 September 2018; Volume 833, p. 290. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J. Array programming with NumPy. Version 1.19.5. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- McKinney, W. Data structures for statistical computing in python. Version 1.2.3. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 9−15 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C.D. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Stroudsburg, PA, USA, 25–30 June 2005; pp. 363–370. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd annual meeting of the association for computational linguistics: System demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. Version 1.2. arXiv 2003, arXiv:2003.07082. [Google Scholar]
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 3. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; Version 3.5; O’Reilly Media, Inc.: Cambridge, UK, 2009. [Google Scholar]
- Sharma, V.B. Rake-Nltk. Version 1.0.4 Software. Available online: https://pypi.org/project/rake-nltk/ (accessed on 18 March 2021).
- Liang, X. Towards Data Science—Understand TextRank for Keyword Extraction by Python. Available online: https://towardsdatascience.com/textrank-for-keyword-extraction-by-python-c0bae21bcec0 (accessed on 15 April 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python, Version 0.24.1. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tan, S. Neighbor-weighted k-nearest neighbor for unbalanced text corpus. Expert Syst. Appl. 2005, 28, 667–671. [Google Scholar] [CrossRef] [Green Version]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188. [Google Scholar]
- Zhang, W.; Yoshida, T.; Tang, X. Text classification based on multi-word with support vector machine. Knowl.-Based Syst. 2008, 21, 879–886. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 1 January 1967; Volume 1, pp. 281–297. Available online: https://projecteuclid.org/proceedings/berkeley-symposium-on-mathematical-statistics-andprobability/proceedings-of-the-fifth-berkeley-symposium-on-mathematical-statisticsand/Chapter/Some-methods-for-classification-and-analysis-of-multivariateobservations/bsmsp/1200512992 (accessed on 8 February 2022).
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Catal, C.; Diri, B. Investigating the effect of dataset size, metrics sets, and feature selection techniques on software fault prediction problem. Inf. Sci. 2009, 179, 1040–1058. [Google Scholar] [CrossRef]
- Barbedo, J.G.A. Impact of dataset size and variety on the effectiveness of deep learning and transfer learning for plant disease classification. Comput. Electron. Agric. 2018, 153, 46–53. [Google Scholar] [CrossRef]






| Dataset Name and Shared Characteristics | Description | |
|---|---|---|
| Reuters | 3 | There are 9160 documents, classified into one of 65 categories. Average of items per category of 140.90. |
| 4 | The largest category “earn” contains 3923 documents (42.83%). The second largest category “acq” contains 2292 documents (25.02%). The smallest 9 categories only contain 1 document (0.0001%). The number of items per category has a standard deviation of 553.13. | |
| Amazon Hierarchical Reviews | 2 | The average amount of words in a review is 76.5, with the shortest review 1 containing 1 word and the longest containing 1068 words. |
| 3 | Based on level 3 categorizations, there are 39,999 documents, classified into one of 510 categories. Average of items per category of 78.4. | |
| 5 | Since all the text are reviews, there are common words in the vocabulary which have no relation to determining the product category. For example, “great” appears in 9762 reviews (24.41%). However, “great” bears no relation to the product category. | |
| Twitter COVID Sentiment | 2 | The average number of words in a tweet is 27.8, with the shortest 2 containing 1 word and the longest containing 58 words. |
| 6 | Sentiment analysis in general has a subjective nature to the classifications given [31]. This dataset also has some specific cases where two very similar tweets have been given opposing sentiments, an example can be found in Appendix B. | |
| Twitter Tweet Genre | 1 | This dataset consists of only 1161 documents. |
| 2 | The average amount of words in a tweet is 16 with the shortest 2 containing 1 word and the longest containing 27 words. | |
| Dataset Name | Items | Categories | Avg. Word Count | Avg. Character Count | Avg. Items per Category 1 |
|---|---|---|---|---|---|
| LFE | 2307 | 24 | 49.6 | 290.4 | 96 |
| Reuters | 9160 | 65 | 104.4 | 643.1 | 140 |
| Amazon Hierarchical Reviews | 39,999 | 6/64/510 2 | 76.5 | 424.1 | 6666/624/78 2 |
| Twitter COVID Sentiment | 44,955 | 5 | 27.8 | 176.4 | 8950 |
| Twitter Tweet Genre | 1161 | 4 | 16.0 | 101.9 | 290 |
| Dataset Name | Pre-Processing | F1 Score (Micro) | F1 Score (Macro) |
|---|---|---|---|
| LFE | None | 0.358 | 0.133 |
| Stop Word Removal | 0.334 | 0.151 | |
| Word Lemmatizing | 0.351 | 0.136 | |
| Both | 0.323 | 0.153 | |
| Reuters | None | 0.870 | 0.477 |
| Stop Word Removal | 0.890 | 0.526 | |
| Word Lemmatizing | 0.858 | 0.446 | |
| Both | 0.886 | 0.505 | |
| Amazon Hierarchical Reviews | None | 0.829 | 0.826 |
| Stop Word Removal | 0.834 | 0.832 | |
| Word Lemmatizing | 0.827 | 0.825 | |
| Both | 0.837 | 0.833 | |
| Twitter COVID Sentiment | None | 0.439 | 0.445 |
| Stop Word Removal | 0.431 | 0.438 | |
| Word Lemmatizing | 0.434 | 0.438 | |
| Both | 0.427 | 0.434 | |
| Twitter Tweet Genre | None | 0.800 | 0.801 |
| Stop Word Removal | 0.786 | 0.787 | |
| Word Lemmatizing | 0.807 | 0.808 | |
| Both | 0.791 | 0.791 |
| Dataset Name | Word Scoring Method | F1 Score (Micro) | F1 Score (Macro) |
|---|---|---|---|
| LFE | RAKE | 0.152 | 0.089 |
| TextRank | 0.174 | 0.045 | |
| Term Frequency | 0.342 | 0.154 | |
| TF-IDF | 0.323 | 0.153 | |
| Reuters | RAKE | 0.461 | 0.348 |
| TextRank | 0.597 | 0.100 | |
| Term Frequency | 0.898 | 0.552 | |
| TF-IDF | 0.886 | 0.505 | |
| Amazon Hierarchical Reviews | RAKE | 0.381 | 0.268 |
| TextRank | 0.605 | 0.573 | |
| Term Frequency | 0.834 | 0.832 | |
| TF-IDF | 0.837 | 0.833 | |
| Twitter COVID Sentiment | RAKE | 0.213 | 0.192 |
| TextRank | 0.385 | 0.364 | |
| Term Frequency | 0.435 | 0.441 | |
| TF-IDF | 0.427 | 0.434 | |
| Twitter Tweet Genre | RAKE | 0.427 | 0.422 |
| TextRank | 0.658 | 0.608 | |
| Term Frequency | 0.826 | 0.827 | |
| TF-IDF | 0.791 | 0.791 |
| Dataset Name | Classifier | F1 Score (Micro) | F1 Score (Macro) | Fit Time | Score Time |
|---|---|---|---|---|---|
| LFE | KNN | 0.224 | 0.053 | 0.039 | 0.0758 |
| CNB | 0.323 | 0.153 | 0.050 | 0.0077 | |
| MLP | 0.329 | 0.099 | 49.029 | 0.0327 | |
| SVM | 0.241 | 0.102 | 12.865 | 2.2606 | |
| Reuters | KNN | 0.624 | 0.297 | 9.618 | 132.67 |
| CNB | 0.886 | 0.505 | 33.872 | 2.526 | |
| MLP | 0.928 | 0.656 | 46,840.85 | 31.941 | |
| SVM | 0.771 | 0.561 | 49,310.23 | 35.715 | |
| Amazon Hierarchical Reviews | KNN | 0.652 | 0.624 | 10.831 | 145.69 |
| CNB | 0.834 | 0.832 | 35.250 | 2.724 | |
| MLP | 0.841 | 0.839 | 50,840.12 | 35.769 | |
| SVM | 0.822 | 0.817 | 56,527.68 | 39.935 | |
| Twitter COVID Sentiment | KNN | 0.313 | 0.302 | 7.787 | 149.136 |
| CNB | 0.424 | 0.431 | 42.274 | 2.497 | |
| MLP | 0.387 | 0.384 | 48,257.21 | 30.676 | |
| SVM | 0.395 | 0.407 | 51,774.16 | 35.027 | |
| Twitter Tweet Genre | KNN | 0.478 | 0.405 | 0.021 | 0.031 |
| CNB | 0.791 | 0.791 | 0.026 | 0.004 | |
| MLP | 0.748 | 0.748 | 15.946 | 0.012 | |
| SVM | 0.761 | 0.765 | 2.095 | 0.605 |
| Dataset Name | Pre-Processing | Word Scoring Method | Classifier | F1 Score (Micro) |
|---|---|---|---|---|
| LFE | None | Term Frequency | CNB | 0.358 |
| Reuters | Stop Word Removal | Term Frequency | MLP | 0.933 |
| Amazon Hierarchical Reviews | Both | TF-IDF | MLP | 0.841 |
| Twitter COVID Sentiment | None | Term Frequency | CNB | 0.440 |
| Twitter Tweet Genre | Word Lemmatizing | Term Frequency | CNB | 0.828 |
| Automatic Text Classification Approach | Overall Accuracy (Micro-Averaged) |
|---|---|
| Joachims, T. SVM [32] | 0.864 |
| Banerjee, S. et al. SVC [33] | 0.870 |
| Ghiassi, M. et al. “DAN2” MLP 1 [34] | 0.910 |
| Zdrojewska A. et al. Feed-forward MLP with ADAM [35] | 0.924 |
| Haynes, C. et al. Novel Pipeline MLP | 0.933 |
| Overall | Cluster ID 0 | Cluster ID 1 | Cluster ID 3 | Cluster ID 5 | Cluster ID 7 | |
|---|---|---|---|---|---|---|
| Word/Size | 2307 | 9 | 1853 | 319 | 11 | 29 |
| Thank | 43.44% | 100.00% | 39.50% | 70.22% | 0.00% | 3.45% |
| Mentor | 1.66% | 0.00% | 0.81% | 6.27% | 18.18% | 0.00% |
| Placement | 1.57% | 0.00% | 0.49% | 6.58% | 45.45% | 0.00% |
| Support | 32.10% | 0.00% | 29.25% | 52.04% | 36.36% | 3.45% |
| SAU | 0.90% | 0.00% | 0.27% | 4.70% | 0.00% | 0.00% |
| Work | 41.46% | 100.00% | 43.82% | 26.33% | 9.09% | 55.17% |
| Hard | 15.83% | 0.00% | 17.00% | 7.21% | 0.00% | 48.28% |
| Help | 31.79% | 22.22% | 29.30% | 50.47% | 0.00% | 3.45% |
| Team | 32.87% | 0.00% | 36.97% | 13.79% | 18.18% | 0.00% |
| Staff | 22.84% | 0.00% | 25.74% | 9.72% | 0.00% | 0.00% |
| Course | 2.52% | 0.00% | 1.35% | 2.19% | 0.00% | 86.21% |
| Success | 3.33% | 100.00% | 2.10% | 1.88% | 0.00% | 68.97% |
| Level | 4.90% | 0.00% | 2.10% | 1.88% | 0.00% | 58.62% |
| Pass | 5.94% | 0.00% | 6.58% | 1.25% | 0.00% | 20.69% |
| Patient | 37.54% | 0.00% | 42.31% | 15.67% | 9.09% | 0.00% |
| Fantastic | 5.98% | 100.00% | 5.45% | 3.45% | 81.82% | 10.34% |
| Congratulation | 1.39% | 0.00% | 0.38% | 0.31% | 0.00% | 79.31% |
| Ward | 14.12% | 0.00% | 14.25% | 14.11% | 27.27% | 6.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haynes, C.; Palomino, M.A.; Stuart, L.; Viira, D.; Hannon, F.; Crossingham, G.; Tantam, K. Automatic Classification of National Health Service Feedback. Mathematics 2022, 10, 983. https://doi.org/10.3390/math10060983
Haynes C, Palomino MA, Stuart L, Viira D, Hannon F, Crossingham G, Tantam K. Automatic Classification of National Health Service Feedback. Mathematics. 2022; 10(6):983. https://doi.org/10.3390/math10060983
Chicago/Turabian StyleHaynes, Christopher, Marco A. Palomino, Liz Stuart, David Viira, Frances Hannon, Gemma Crossingham, and Kate Tantam. 2022. "Automatic Classification of National Health Service Feedback" Mathematics 10, no. 6: 983. https://doi.org/10.3390/math10060983