
Towards a Highly Available Model for Processing Service Requests Based on Distributed Hash Tables

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- 1.
- The system’s tolerance to individual failures of any of its components, which can be usually obtained by the DHT stabilization mechanisms and by data replication;
- 2.
- The system’s scalability, such that it is still functional if it is exposed to high external stress;
- 3.
- Load balancing, in order to generate as seldom as possible overloading, which in turn could lead to individual node failure.
1.1. State-of-the-Art
1.1.1. Distributing Systems Using Highly Available Data
1.1.2. The Aspect of Storing Data in Decentralized Systems
- 1.
- 2.
- Smart distribution and retrieval techniques for geographically distributed data, a field in which the P2P DHTs [9] have been of great help and have become very popular;
- 3.
1.1.3. Existing Solutions for High Availability of Distributed Services
2. Materials and Methods
2.1. System Load Balancing Based on the Intrinsic Properties of the Chord DHT
2.2. System Scalability Based on the Intrinsic Properties of the Chord DHT
| Algorithm 1 ChordImplicitLoadBalancing. |
|
2.3. The Novel Improved Model of Splitting the Work around the Nodes
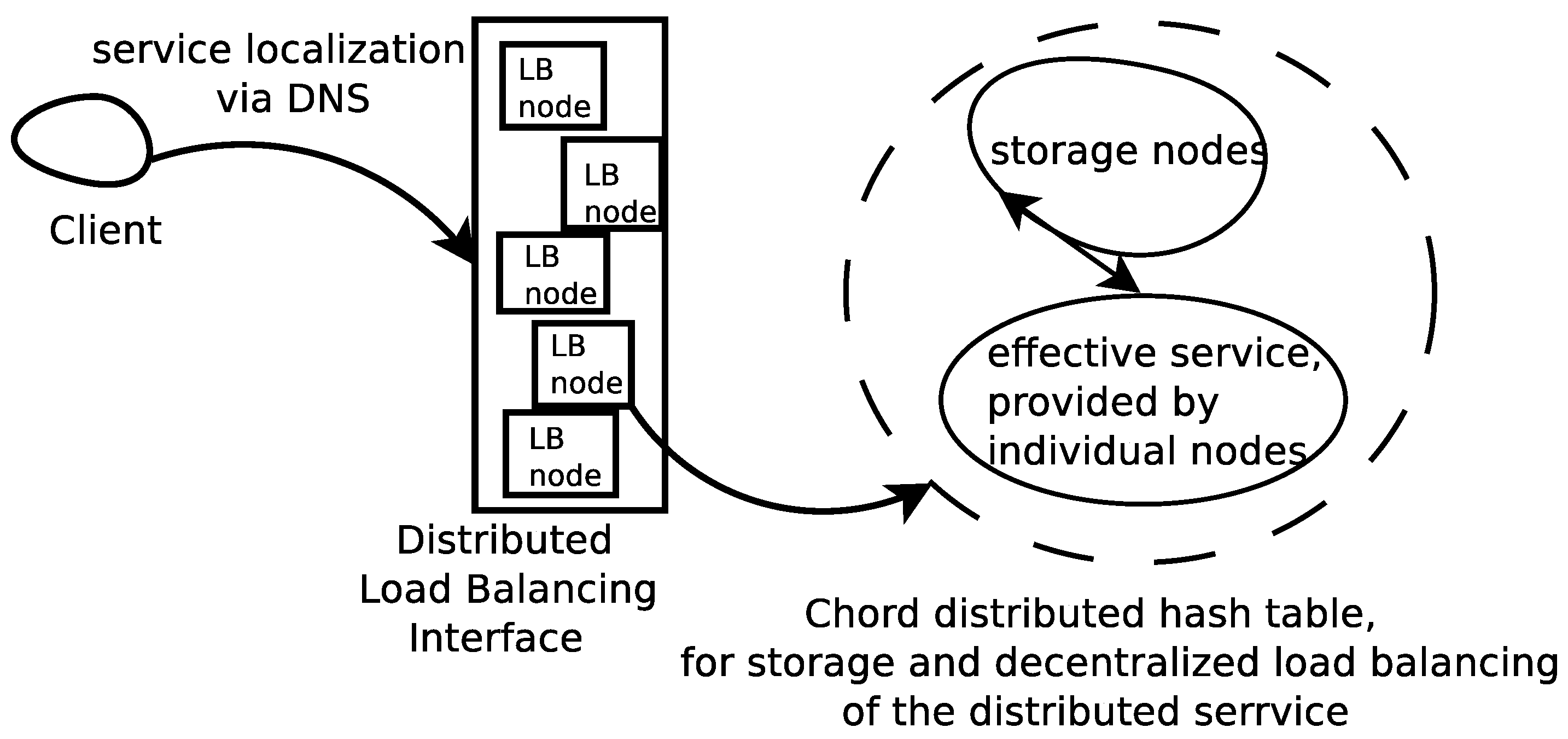
2.3.1. The Load Balancing Component
| Algorithm 2 DispatcherLoadBalancing. |
|
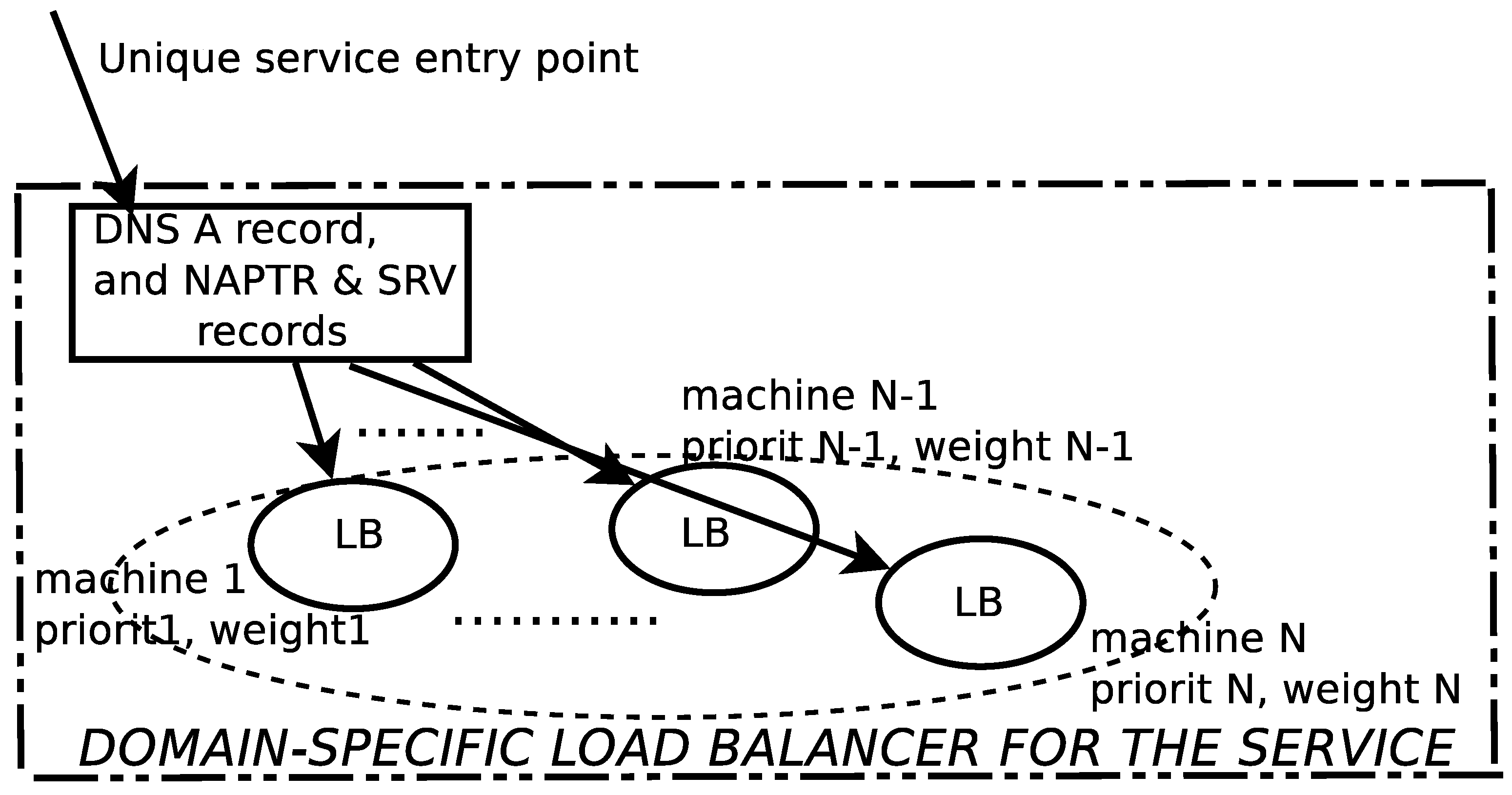
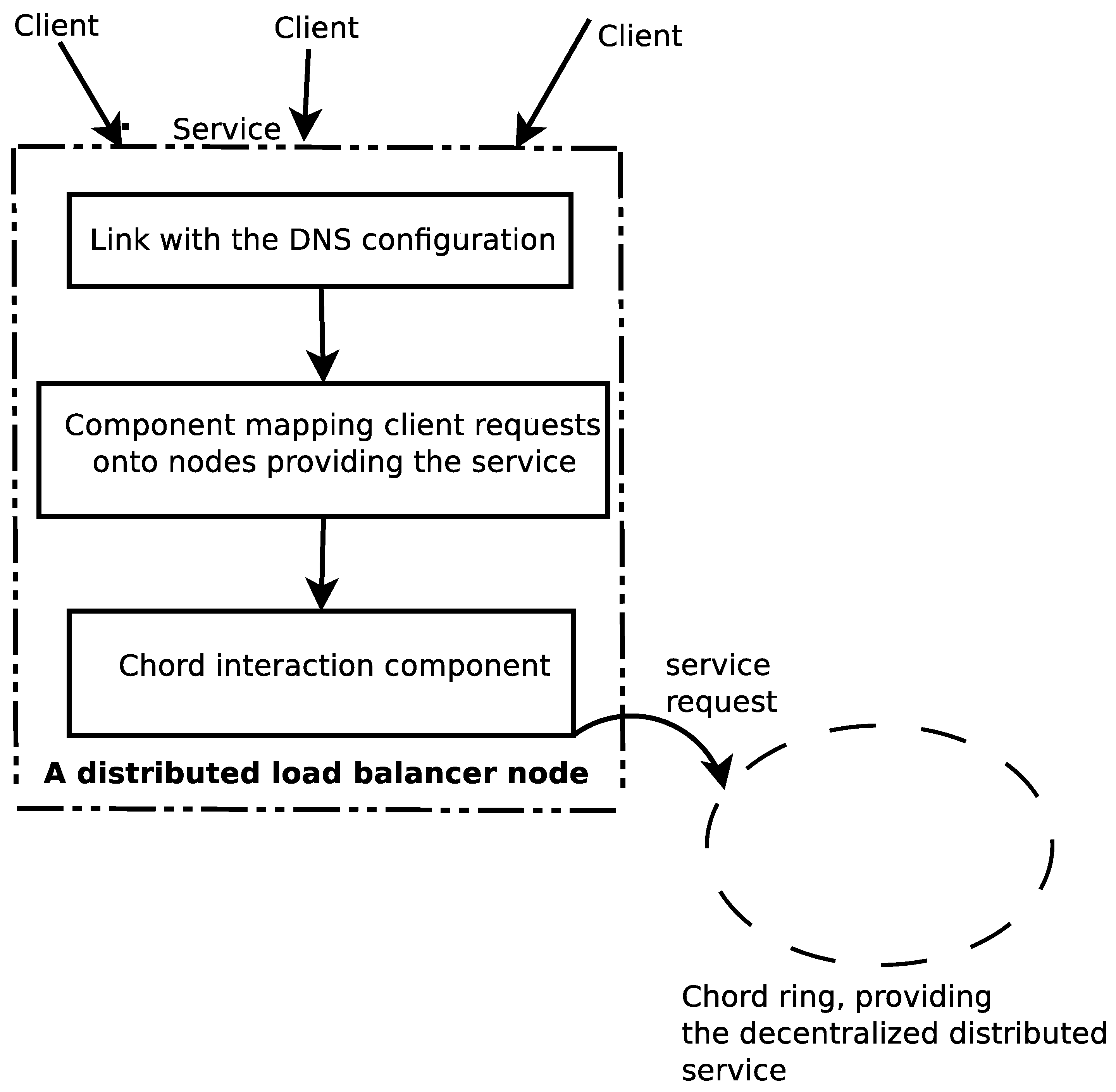
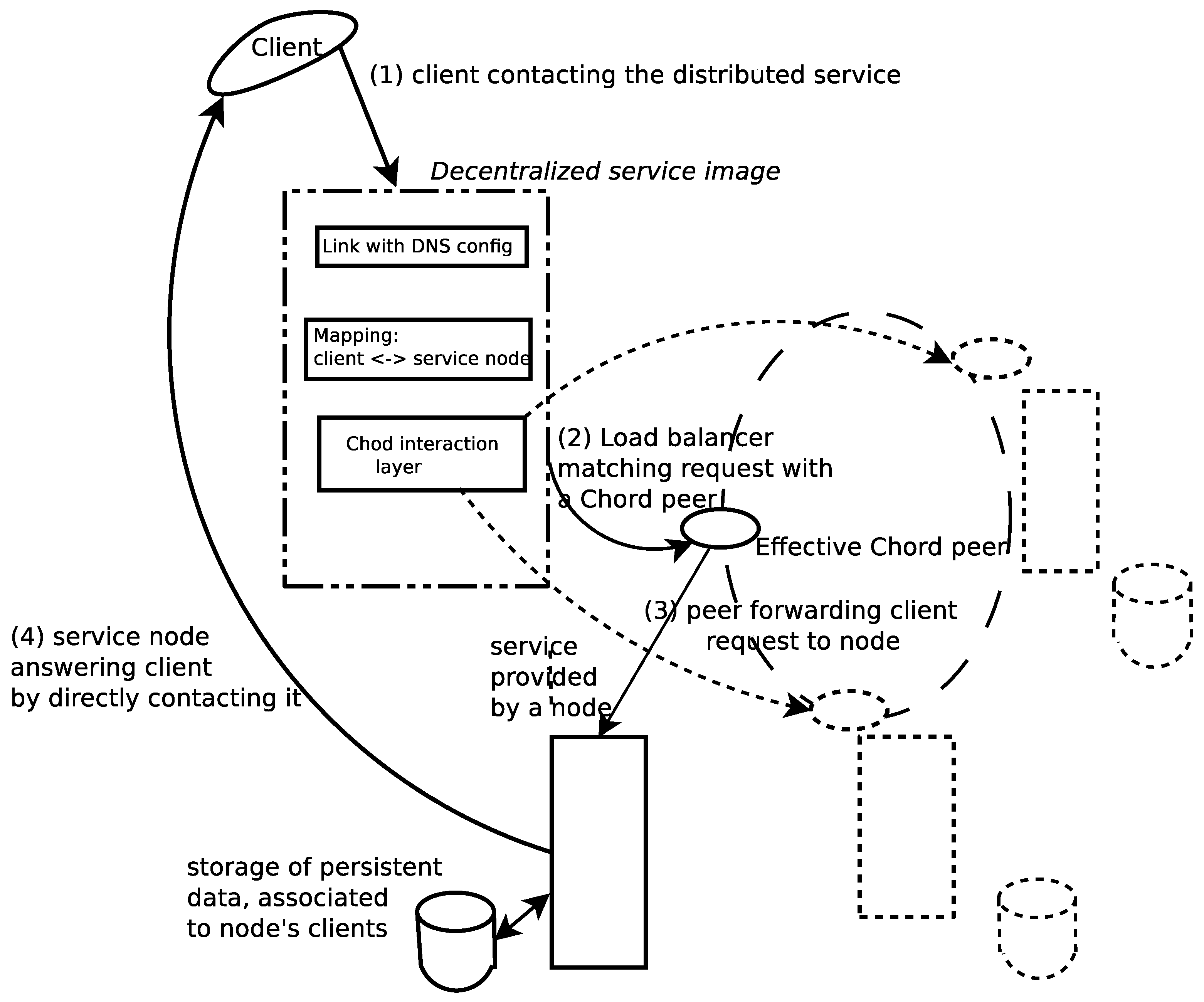
- The link with the DNS configuration for the load balancer renders the “single system image” (SSI) for the distributed service. It defines a standard and easy to use interface, in order to be able to access the service, without overloading the system entry point.
- The component that maps clients onto service nodes has the unique role of computing the Chord key of each client, by using the hash function used within the Chord DHT. Further, this component is the one responsible to construct, from the client’s original message to the service, the message that will be sent to the service node, in the “language” understood by Chord, i.e., to route the message to its destination via the DHT transport layer.
- The Chord component of the load balancer knows that, based on the message the component that maps the clients onto service nodes provides, it should send a request using Chord mechanisms, towards the peer that will have to serve that client. The identification of the service node responsible for the client is made using Chord keys, by computing a hash of the client’s name.
2.3.2. The Peer-To-Peer Chord Network
2.4. The Pre-Existent DHT-Based Distributed Database to Reliably and Persistently Store the Data Belonging to a Highly Available Service’s Clients
3. Results
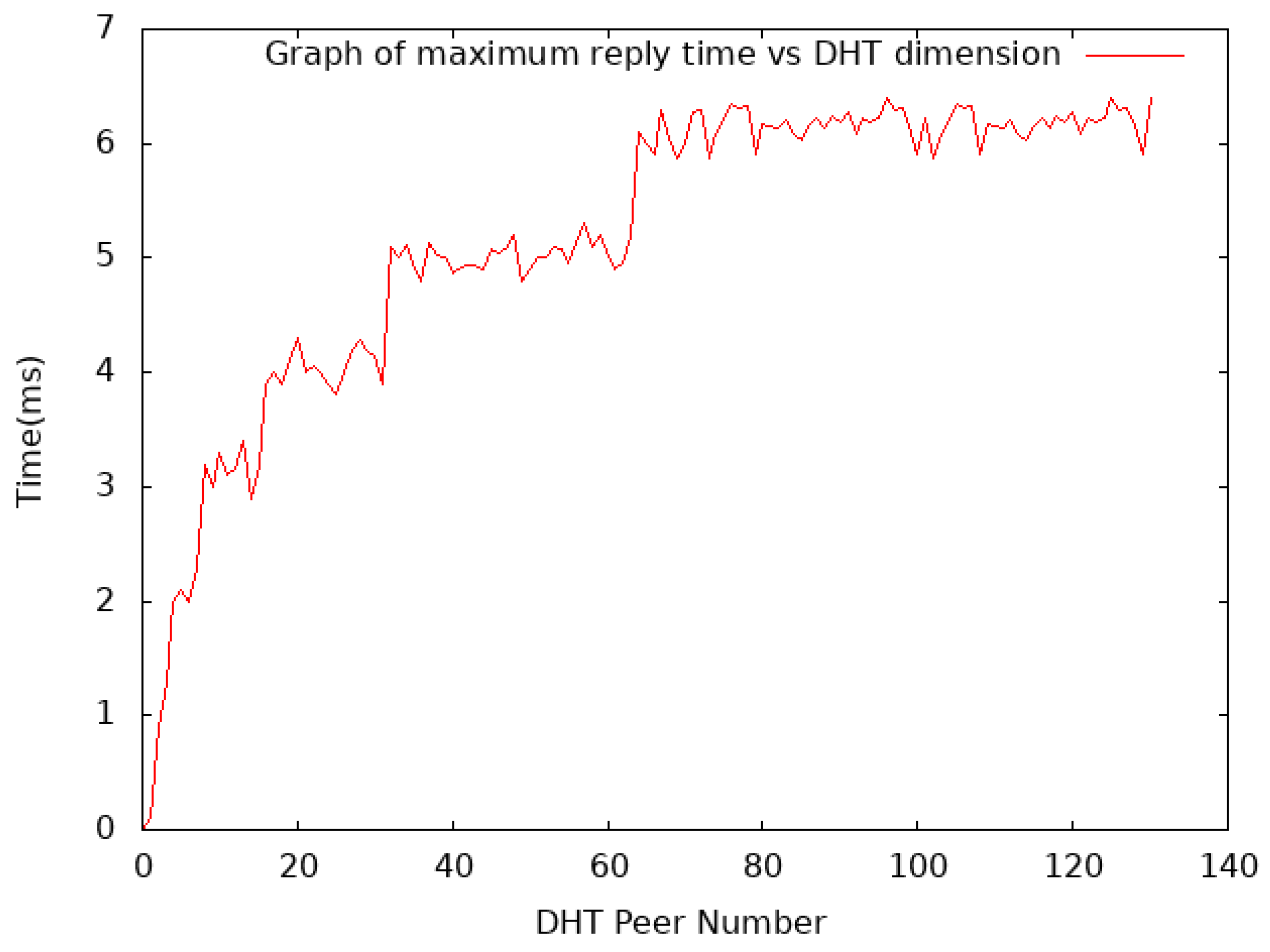
3.1. Practical Evaluating of the System’s Scalability
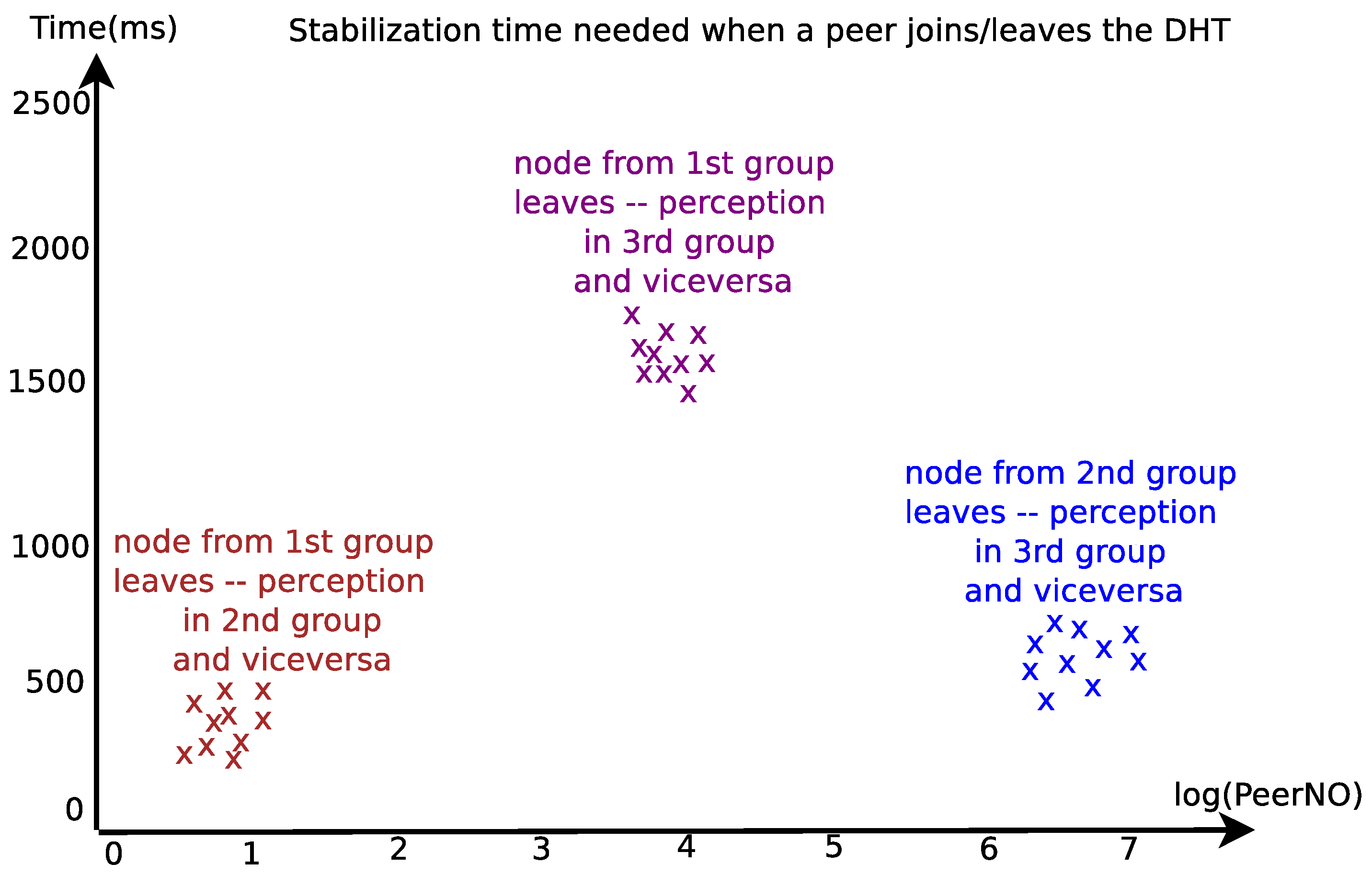
3.2. Practical Evaluating of the System’s Fault Tolerance
3.2.1. The Improvement in Fault Tolerance
3.2.2. The Improvement in Load Balancing
3.3. Evaluation Conclusions
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dabek, F.; Kaashoek, M.F.; Karger, D.; Morris, R.; Stoica, I. Wide-area cooperative storage with CFS. In Proceedings of the 18th ACM Symposium on Operating Systems Principles, Banff, AB, Canada, 21–24 October 2001. [Google Scholar]
- Hassanzadeh-Nazarabadi, Y.; Küpçü, A.; Özkasap, Ö. LightChain: A DHT-based Blockchain for Resource Constrained Environments. arXiv 2019, arXiv:abs/1904.00375. [Google Scholar]
- Matsuoka, K.; Suzuki, T. Blockchain and DHT Based Lookup System Aiming for Alternative DNS. In Proceedings of the 2020 2nd International Conference on Computer Communication and the Internet (ICCCI), Nagoya, Japan, 26–29 June 2020; pp. 98–105. [Google Scholar]
- Stoica, I.; Shenker, S. From Cloud Computing to Sky Computing. In Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS. ’21), Ann Arbor, MI, USA, 31 May–2 June 2021. [Google Scholar]
- Monteiro, A.; Pinto, J.S.; Teixeira, C.J.V.; Batista, T. Sky computing: Exploring the aggregated cloud resources—Part i. In Proceedings of the 16th Iberian Conference on Information Systems and Technologies, Chaves, Portugal, 23–26 June 2021. [Google Scholar]
- Mohammadi, B.; Navimipour, N.J. Data replication mechanisms in the peer-to-peer networks. Int. J. Commun. Syst. 2019, 32, e3996. [Google Scholar] [CrossRef]
- Iancu, V.; Ignat, I. A Decentralized Distributed Database Built on Top of the Chord DHT. In Proceedings of the 8th RoEduNet International Conference, Galati, Romania, 3–4 December 2009; pp. 151–155. [Google Scholar]
- MongoDB. Available online: https://www.mongodb.com/ (accessed on 3 January 2022).
- Stoica, I.; Morris, R.; Karger, D.; Kaashoek, F.; Balakrishnan, H. Chord: A Scalable Peer-To-Peer Lookup Service for Internet Applications. In Proceedings of the 2001 ACM SIGCOMM Conference, San Diego, CA, USA, 1–2 November 2001; pp. 149–160. [Google Scholar]
- Jenkov, T. Chord P2P + DHT Network Algorithm—Tutorials Jenkov. 2021. Available online: http://tutorials.jenkov.com/ (accessed on 3 January 2022).
- Ratnasamy, S.; Francis, P.; Handley, M.; Karp, R.; Schenker, S. A scalable content-addressable network. In Proceedings of the Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM ’01, San Diego, CA, USA, 1–2 November 2001; Volume 31, pp. 161–172. [Google Scholar]
- Rowstron, A.; Druschel, P. Pastry: Scalable, decentralized object location and routing for large-scale peer-to-peer systems. In Proceedings of the IFIP/ACM International Conference on Distributed Systems Platforms (Middleware), Beijing, China, 9–13 December 2001; pp. 329–350. [Google Scholar]
- Souto, P.F. Name Resolution in Flat Name Spaces Distributed Hash Tables (DHTs). 2021. Available online: https://web.fe.up.pt/~pfs/aulas/sd2021/at/9dhts.pdf (accessed on 3 January 2022).
- The Blockchain Technology. Available online: https://www.ibm.com/topics/what-is-blockchain/ (accessed on 3 January 2022).
- Kunz, T.; Echegini, S.; Esfandiari, B. A P2P Approach to Routing in Hierarchical MANETs. Commun. Netw. 2020, 12, 99–121. [Google Scholar] [CrossRef]
- Iancu, V.; Ignat, I. A Distributed Database With Self-Extending Capabilities, to Compensate Exclusion of Malicious Nodes. In Proceedings of the 9th RoEduNet International Conference, Sibiu, Romania, 24–26 June 2010; pp. 240–245. [Google Scholar]
- Iancu, V.; Ignat, I. A Peer-to-Peer Consensus Algorithm to Enable Storage Reliability for a Decentralized Distributed Database. In Proceedings of the 2010 IEEE AQTR Conference, Cluj, Romania, 28–30 May 2010; pp. 1–6. [Google Scholar]
- Antoniu, G.; Bougé, L.; Jan, M. JuxMem: An Adaptive Supportive Platform for Data Sharing on the Grid. Scalable Comput. Pract. Exp. 2005, 6, 45–55. [Google Scholar]
- Kubiatowicz, J.; Bindel, D.; Chen, Y.; Czerwinski, S.; Eaton, P.; Geels, D.; Gummadi, R.; Rhea, S.; Weatherspoon, H.; Weimer, W.; et al. OceanStore: An architecture for global-scale persistent storage. SIGPLAN Not. 2000, 35, 190–201. [Google Scholar] [CrossRef]
- SPARK. Available online: http://spark.apache.org/ (accessed on 3 January 2022).
- HADOOP. Available online: http://hadoop.apache.org/ (accessed on 3 January 2022).
- Davies, A.; Fisk, H. MySQL Clustering; MySQL Press, 2006. Available online: https://www.bookdepository.com/publishers/Mysql-Press (accessed on 3 January 2022).
- Map-Reduce Processing Pattern. Available online: https://en.wikipedia.org/wiki/MapReduce (accessed on 3 January 2022).
- The Network Filesystem. Available online: https://en.wikipedia.org/wiki/Network_File_System (accessed on 3 January 2022).
- Nicolae, B.; Antoniu, G.; Bougé, L.; Moise, D.; Carpen-Amarie, A. Blobseer: Next-generation data management for large scale infrastructures. J. Parallel Distrib. Comput. 2011, 71, 169–184. [Google Scholar] [CrossRef] [Green Version]
- Mor, N.; Allman, E.; Pratt, R.; Lutz, K.; Kubiatowicz, J. An Architecture for a Widely Distributed Storage and Communication Infrastructure. 2018. Available online: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2018/EECS-2018-130.html (accessed on 3 January 2022).
- de Jongh, J. Shared Scheduling in Distributed Systems. Ph.D. Thesis, Technische Universiteit Delft, Delft, The Netherlands, 2002. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. In Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012. [Google Scholar]
- Ananthanarayanan, G.; Ghodsi, A.; Wang, A.; Borthakur, D.; Kandula, S.; Shenker, S.; Stoica, I. PACMan: Coordinated Memory Caching for Parallel Jobs. In Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012. [Google Scholar]
- Fan, B.; Lim, H.; Andersen, D.G.; Kaminsky, M. Small Cache, Big Effect: Provable Load Balancing for Randomly Partitioned Cluster Services. In Proceedings of the ACM Symposium on Cloud Computing in Conjunction with SOSP, Cascais, Portugal, 27–28 October 2011. [Google Scholar]
- Cai, Q.; Guo, W.; Zhang, H.; Agrawal, D.; Ooi, G.C.B.C.; Tan, K.L.; Teo, Y.M.; Wang, S. Efficient Distributed Memory Management with RDMA and Caching. VLDB Endowment 2018, 11, 1604–1617. [Google Scholar] [CrossRef] [Green Version]
- Matri, P.; Alforov, Y.; Brandon, A.; Pérez, M.; Costan, A.; Antoniu, G.; Kuhn, M.; Carns, P.; Ludwig, T. Mission Possible: Unify HPC and Big Data Stacks Towards Application-Defined Blobs at the Storage Layer. Future Gener. Comput. Syst. 2020, 109, 668–677. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.Y.; Huang, L.; Stribling, J.; Rhea, S.C.; Joseph, A.D.; Kubiatowicz, J.D. Tapestry: A Resilient Global-scale Overlay for Service Deployment. IEEE J. Sel. Areas Commun. 2004, 22, 41–53. [Google Scholar] [CrossRef] [Green Version]
- RFC 3768 (Draft Standard); Virtual Router Redundancy Protocol (VRRP). Hinden, R. (Ed.) Nokia: Espoo, Finland, 2004.
- RFC 2915 (Proposed Standard); The Naming Authority Pointer (NAPTR) DNS Resource Record. Mealling, M.; Daniel, R. (Eds.) The Internet Society: Reston, VA, USA, 2000; Obsoleted by RFCs 3401, 3402, 3403, 3404.
- RFC 2782 (Proposed Standard); A DNS RR for specifying the location of services (DNS SRV). Gulbrandsen, A.; Vixie, P.; Esibov, L. (Eds.) The Internet Society: Reston, VA, USA, 2000.
- Andreica, M.I.; Tîrşa, E.D.; Ţăpuş, N. A Peer-to-Peer Architecture for Multi-Path Data Transfer Optimization using Local Decisions. In Proceedings of the Fourth EuroSys Conference 2009, Nuremberg, Germany, 31 March 2009. [Google Scholar]
- SHA-1—Secure Hash Standard. Available online: http://www.itl.nist.gov/fipspubs/fip180-1.htm (accessed on 3 January 2022).
- Rivest, R.L. The MD5 Message-Digest Algorithm. RFC 1321. 1992. Available online: https://www.rfc-editor.org/info/rfc1321 (accessed on 3 January 2022).
- RFC 1035 (Standard); Domain Names—Implementation and Specification. Mockapetris, P. (Ed.) Information Sciences Institute: Marina del Rey, CA, USA, 1987; Updated by RFCs 1101, 1183, 1348, 1876, 1982, 1995, 1996, 2065, 2136, 2181, 2137, 2308, 2535, 2845, 3425, 3658, 4033, 4034, 4035, 4343.
- Iancu, V.; Ignat, I. A Scalable Solution for Balancing the Peer Load in a Chord DHT. In Proceedings of the 2010 IEEE ICCP Conference, Cambridge, MA, USA, 29–30 March 2010; pp. 297–304. [Google Scholar]
- Iancu, V.; Ignat, I. A self-adapting peer-to-peer logical infrastructure, to increase storage reliability on top of the physical infrastructure. In Proceedings of the 2009 IEEE ICCP Conference, San Francisco, CA, USA, 16–17 April 2009; pp. 259–266. [Google Scholar]
- Napster File-Sharing System. Available online: http://www.napster.com/ (accessed on 3 January 2022).
- KaZaA Peer-to-Peer Storage System. Available online: http://www.kazaa.com/ (accessed on 3 January 2022).
- Skype Peer-to-Peer VoIP System. Available online: http://www.skype.com/ (accessed on 3 January 2022).
- What Is Overlay Networking (SDN Overlay)? Available online: https://www.sdxcentral.com/networking/sdn/definitions/what-is-overlay-networking/ (accessed on 3 January 2022).
- Introduction to VRRP and Its Configurations. Available online: https://www.geeksforgeeks.org/introduction-of-virtual-router-redundancy-protocol-vrrp-and-its-configuration/ (accessed on 3 January 2022).






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iancu, V.; Ţăpuş, N. Towards a Highly Available Model for Processing Service Requests Based on Distributed Hash Tables. Mathematics 2022, 10, 831. https://doi.org/10.3390/math10050831
Iancu V, Ţăpuş N. Towards a Highly Available Model for Processing Service Requests Based on Distributed Hash Tables. Mathematics. 2022; 10(5):831. https://doi.org/10.3390/math10050831
Chicago/Turabian StyleIancu, Voichiţa, and Nicolae Ţăpuş. 2022. "Towards a Highly Available Model for Processing Service Requests Based on Distributed Hash Tables" Mathematics 10, no. 5: 831. https://doi.org/10.3390/math10050831