
Bayes in Wonderland! Predictive Supervised Classification Inference Hits Unpredictability


Abstract
:1. Introduction
2. Partition Exchangeability
2.1. Parameter Estimation
2.2. Hypothesis Testing
3. Supervised Classifiers under PE
Algorithms for the Predictive Classifiers
- 1
- Set an initial with the marginal classifier algorithm .
- 2
- Until S remains unchanged between iteration, do for each test item :
4. Numerical Illustrations Underlying Convergence
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PE | Partition Exchangeability |
| mBpc | marginal Bayesian predictive classifiers |
| sBpc | simultaneous Bayesian predictive classifiers |
| LRT | Likelihood Ratio Test |
| MLE | Maximum Likelihood Estimate |
| PD | Poisson–Dirichlet |
| i.i.d. | Independent and Identically Distributed |
Appendix A. Maximum Likelihood Estimate
Appendix B. Lagrange Multiplier Test
Appendix C. A Note on Two-Parameter PD
References
- Solomonoff, R. A formal theory of inductive inference. Inf. Ctrl. 1964, 7, 1–22. [Google Scholar]
- Falco, I.D.; Cioppa, A.D.; Maisto, D.; Tarantino, E. A genetic programming approach to Solomonoff’s probabilistic induction. In European Conference on Genetic Programming; Springer: Berlin/Heidelberg, Germany, 2006; pp. 24–35. [Google Scholar]
- Hand, D.J.; Yu, K. Idiot’s Bayes: Not so stupid after all? Int. Stat. Rev. 2001, 69, 385. [Google Scholar]
- Bryant, P.; Williamson, J.A. Asymptotic behaviour of classification maximum likelihood estimates. Biometrika 1978, 65, 273–281. [Google Scholar] [CrossRef]
- Corer, J.; Cui, Y.; Koski, T.; Siren, J. Have I seen you before? Principles of Bayesian predictive classification revisited. Springer Stat. Comput. 2011, 23, 59–73. [Google Scholar]
- Quintana, F.A. A predictive view of Bayesian clustering. J. Stat. Plan. Inference 2006, 136, 2407–2429. [Google Scholar] [CrossRef]
- Bassetti, F.; Ladelli, L. Mixture of Species Sampling Models. Mathematics 2021, 9, 3127. [Google Scholar] [CrossRef]
- Barlow, R.E. Introduction to de Finetti (1937) foresight: Its logical laws, its subjective sources. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 127–133. [Google Scholar]
- Kingman, J.F.C. Random partitions in population genetics. Proc. R. Soc. A Math Phys. Eng. Sci. 1978, 361, 1–20. [Google Scholar]
- Zabell, S.L. Predicting the unpredictable. Harv. Bus. Rev. 1992, 90, 205–232. [Google Scholar] [CrossRef]
- Hansen, B.; Pitman, J. Prediction rules for exchangeable sequences related to species sampling. Stat. Probab. Lett. 2000, 46, 251–256. [Google Scholar] [CrossRef]
- Bassetti, F.; Ladelli, L. Asymptotic number of clusters for species sampling sequences with non-diffuse base measure. Stat. Probab.-Lett. 2020, 162, 108749. [Google Scholar] [CrossRef]
- Amiryousefi, A. Asymptotic Supervised Predictive Classifiers under Partition Exchangeability. arXiv 2021, arXiv:2101.10950. [Google Scholar]
- Kingman, J.F.C. The population structure associated with the Ewens sampling formula. Theor. Popul. Biol. 1977, 11, 274–283. [Google Scholar] [CrossRef]
- Ewens, W. The Sampling Theory of Selectively Neutral Alleles. Theor. Popul. Biol. 1972, 3, 87–112. [Google Scholar] [CrossRef]
- Crane, H. The Ubiquitous Ewens Sampling Formula. Stat. Sci. 2016, 31, 1–19. [Google Scholar] [CrossRef]
- Radhakrishna Rao, C. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. Math. Proc. Camb. Philos. Soc. 1948, 44, 50–57. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the problem of the most efficient tests of statistical hypotheses. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. Math. Phys. Character 1933, 231, 289–337. [Google Scholar] [CrossRef] [Green Version]
- Hoppe, F.M. Polya-like urns and the Ewens sampling formula. J. Math. Biol. 1984, 20, 91–94. [Google Scholar] [CrossRef] [Green Version]
- Karlin, S.; McGregor, J. Addendum to a paper of Ewens. Theor. Popul. Biol. 1972, 3, 113–116. [Google Scholar] [CrossRef]
- Corer, J.; Gyllenberg, M.; Koski, T. Random partition models and exchangeability for Bayesian identification of population structure. Bull. Math. Biol. 2007, 69, 797–815. [Google Scholar]
- Fortini, S.; Ladelli, L.; Regazzini, E. A Central Limit Problem for Partially Exchangeable Random Variables. Theory Probab. Its Appl. 1997, 41, 224–246. [Google Scholar] [CrossRef] [Green Version]
- Pitman, J.; Yor, M. The two-parameter Poisson-Dirichlet distribution derived from a stable subordinator. Ann. Probab. 1997, 25, 855–900. [Google Scholar] [CrossRef]


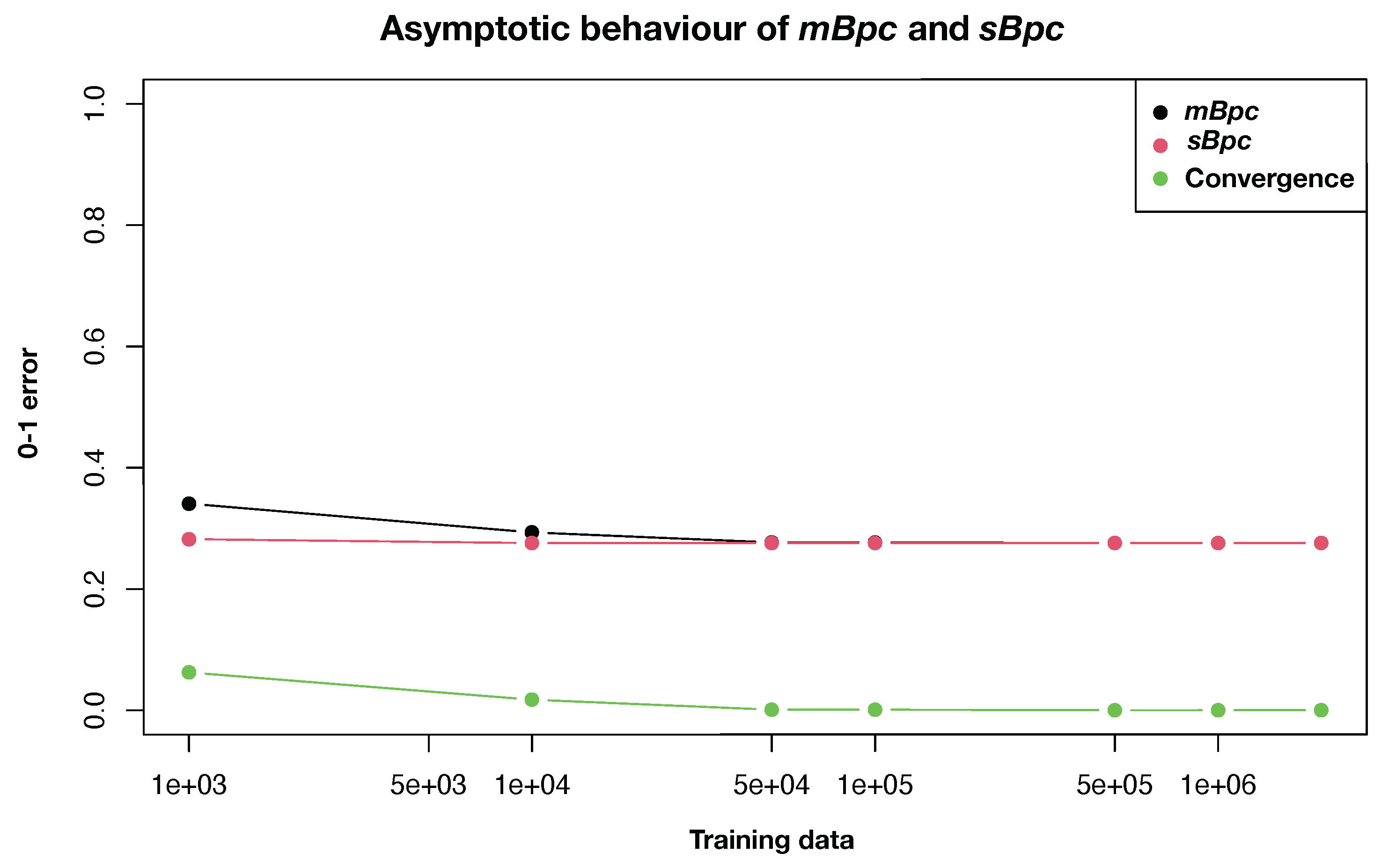{kind=link}
| Training (m) | Test (n) | No. Clusters (k) | Dispersion () | |||
|---|---|---|---|---|---|---|
| 2 | 1, 2 | 0.491 | 0.491 | 0 | ||
| 3 | 1, 10, 50 | 0.3408 | 0.2823 | 0.0626 | ||
| 3 | 1, 10, 50 | 0.2768 | 0.2758 | 0.0010 | ||
| 5 | 1, 100, | 0.7535 | 0.5865 | 0.167 | ||
| 5 | 1, 100, | 0.434 | 0.364 | 0.115 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amiryousefi, A.; Kinnula, V.; Tang, J. Bayes in Wonderland! Predictive Supervised Classification Inference Hits Unpredictability. Mathematics 2022, 10, 828. https://doi.org/10.3390/math10050828
Amiryousefi A, Kinnula V, Tang J. Bayes in Wonderland! Predictive Supervised Classification Inference Hits Unpredictability. Mathematics. 2022; 10(5):828. https://doi.org/10.3390/math10050828
Chicago/Turabian StyleAmiryousefi, Ali, Ville Kinnula, and Jing Tang. 2022. "Bayes in Wonderland! Predictive Supervised Classification Inference Hits Unpredictability" Mathematics 10, no. 5: 828. https://doi.org/10.3390/math10050828