
Profile and Non-Profile MM Modeling of Cluster Failure Time and Analysis of ADNI Data


Abstract
:1. Introduction
2. The Model and Estimation
2.1. The Model
2.2. An Overview of MM Principle
2.3. Profile MM Estimation Procedure
2.4. Non-Profile MM Estimation Procedure
3. Regularized Estimation Methods via MM Methods
- Step 1.
- Given initial values of , and ;
- Step 2.
- Update the estimate of via (6);
- Step 3.
- For profile MM method, update by maximizingFor non-profile MM method, update by maximizing
- Step 4.
- Step 5.
- Iterate steps 2 to 4 until convergence.
Model Selection
4. Theoretical Properties
5. Numerical Examples
6. Real Data Analysis
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clayton, D.G. A model for association in bivariate life tables and its application in epidemiologic studies of familial tendency in chronic disease incidence. Biometrika 1978, 65, 141–151. [Google Scholar] [CrossRef]
- Clayton, D.G.; Cuzick, J. Multivariate generalizations of the proportional hazards model. J. R. Stat. Soc. Ser. 1985, 148, 82–117. [Google Scholar] [CrossRef]
- Oakes, D. Bivariate survival models induced by frailties. J. Am. Stat. Assoc. 1989, 84, 487–493. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, Q.; Ibrahim, J. Gamma frailty transformation models for multivariate survival times. Biometrika 2009, 96, 277–291. [Google Scholar] [CrossRef] [PubMed]
- Andersen, P.K.; Klein, J.P.; Knudsen, K.M.; Palacios, R.T. Estimation of variance in Cox’s regression model with shared gamma frailties. Biometrics 1997, 53, 1475–1484. [Google Scholar] [CrossRef] [PubMed]
- Cox, D.R. Regression models and life tables (with discussion). J. R. Stat. Soc. Ser. B 1972, 34, 187–220. [Google Scholar]
- Klein, J.P. Semiparametric estimation of random effects using the Cox model based on the EM algorithm. Biometrics 1992, 48, 795–806. [Google Scholar] [CrossRef]
- Nielsen, G.G.; Gill, R.D.; Andersen, P.K.; Sorensen, T.I.A. A counting process approach to maximum likelihood estimation in frailty models. Scand. J. Stat. 1992, 19, 25–43. [Google Scholar]
- Balan, T.A.; Putter, H. A tutorial on frailty models Stat. Methods Med Res. 2020, 29, 3424–3454. [Google Scholar] [CrossRef]
- Do Ha, I.; Lee, Y. A review of h-likelihood for survival analysis. Jpn. J. Stat. Data Sci. 2021, 4, 1157–1178. [Google Scholar]
- Duchateau, L.; Janssen, P. The Frailty Model; Springer Science & Business Media: New York, NY, USA, 2007. [Google Scholar]
- Glidden, D.V.; Vittinghoff, E. Modelling clustered survival data from multicentre clinical trials. Stat. Med. 2004, 23, 369–388. [Google Scholar] [CrossRef] [PubMed]
- Dahlqwist, E.; Pawitan, Y.; Sjölander, A. Regression standardization and attributable fraction estimation with between-within frailty models for clustered survival data. Stat. Methods Med Res. 2019, 28, 462–485. [Google Scholar] [CrossRef] [PubMed]
- Manda, S.O. A nonparametric frailty model for clustered survival data. Commun. Stat. Methods 2011, 40, 863–875. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic Decomposition by Basis Pursuit. Siam J. Sci. Comput. 1998, 20, 33–61. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Frank, L.E.; Friedman, J.H. A Statistical View of Some Chemometrics Regression Tools. Technometrics 1993, 35, 109–135. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Li, R. Variable Selection via Nonconcave Penalized Likelihood and Its Oracle Properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.-H. Nearly Unbiased Variable Selection Under Minimax Concave Penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef] [Green Version]
- Hunter, D.R.; Lange, K. A tutorial on MM algorithms. Am. Stat. 2004, 58, 30–37. [Google Scholar] [CrossRef]
- Lange, K.; Hunter, D.R.; Yang, I. Optimization transfer using surrogate objective functions (with discussions). J. Comput. Graph. Stat. 2000, 9, 1–20. [Google Scholar]
- Becker, M.P.; Yang, I.; Lange, K. EM algorithms without missing data. Stat. Methods Med. Res. 1997, 6, 38–54. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.F.; Xu, J.F.; Tian, G.L. On profile MM algorithms for gamma frailty survival models. Stat. Sin. 2019, 29, 895–916. [Google Scholar] [CrossRef] [Green Version]
- Lange, K.; Zhou, H. MM algorithms for geometric and signomial programming. Math. Program. Ser. 2014, 143, 339–356. [Google Scholar] [CrossRef] [Green Version]
- Hunter, D.R.; Li, R. Variable selection using MM algorithms. Ann. Stat. 2005, 33, 1617–1642. [Google Scholar] [CrossRef] [Green Version]
- Schwarz, C. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Craven, P.; Wahba, G. Smoothing noisy data with spline functions: Estimating the correct degree of smoothing by the method of generalized cross-validation. Numer. Math. 1979, 31, 377–403. [Google Scholar] [CrossRef]
- Lange, K. Numerical Analysis for Statisticians, 2nd ed.; Statistics and Computing; Springer: New York, NY, USA, 2010. [Google Scholar]
- Varadhan, R.; Roland, C. Simple and globally convergent methods for accelerating the convergence of any EM algorithms. Scand. J. Stat. 2008, 35, 335–353. [Google Scholar] [CrossRef]
- Zhou, H.; Alexander, D.; Lange, K. A quasi-Newton acceleration for high-dimensional optimization algorithms. Stat. Comput. 2011, 21, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Ye, J.P.; Farnum, M.; Yang, E.; Verbeeck, R.; Lobanov, V.; Raghavan, V.; Novak, G.; DiaBernardo, A.; Narayan, V.A. Sparse learning and stability selection for predicting mci to ad conversion using baseline adni data. BMC Neurol. 2012, 12, 46. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Da, X.; Toledo, J.; Toledo, J.; Zee, J.; Wolk, D.A.; Xie, S.X.; Ou, Y.; Shacklett, A.; Parmpi, P.; Shaw, L.; et al. Integration and relative value of biomarkers for prediction of mci to ad progression: Spatial patterns of brain atrophy, cognitive scores, apoe genotype, and csf markers. Neuroimage Clin. 2014, 4, 164–173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kong, D.H.; Ibrahim, J.G.; Lee, E.; Zhu, H.T. Flcrm: Functional linear cox regression model. Biometrics 2018, 74, 109–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zappia, M.; Manna, I.; Serra, P.; Cittadella, R.; Andreoli, V.; La Russa, A.; Annesi, F.; Spadafora, P.; Romeo, N.; Nicoletti, G.; et al. Increased risk for alzheimer disease with the interaction of mpo and a2m polymorphisms. Arch. Neurol. 2004, 61, 341–344. [Google Scholar] [CrossRef] [PubMed] [Green Version]


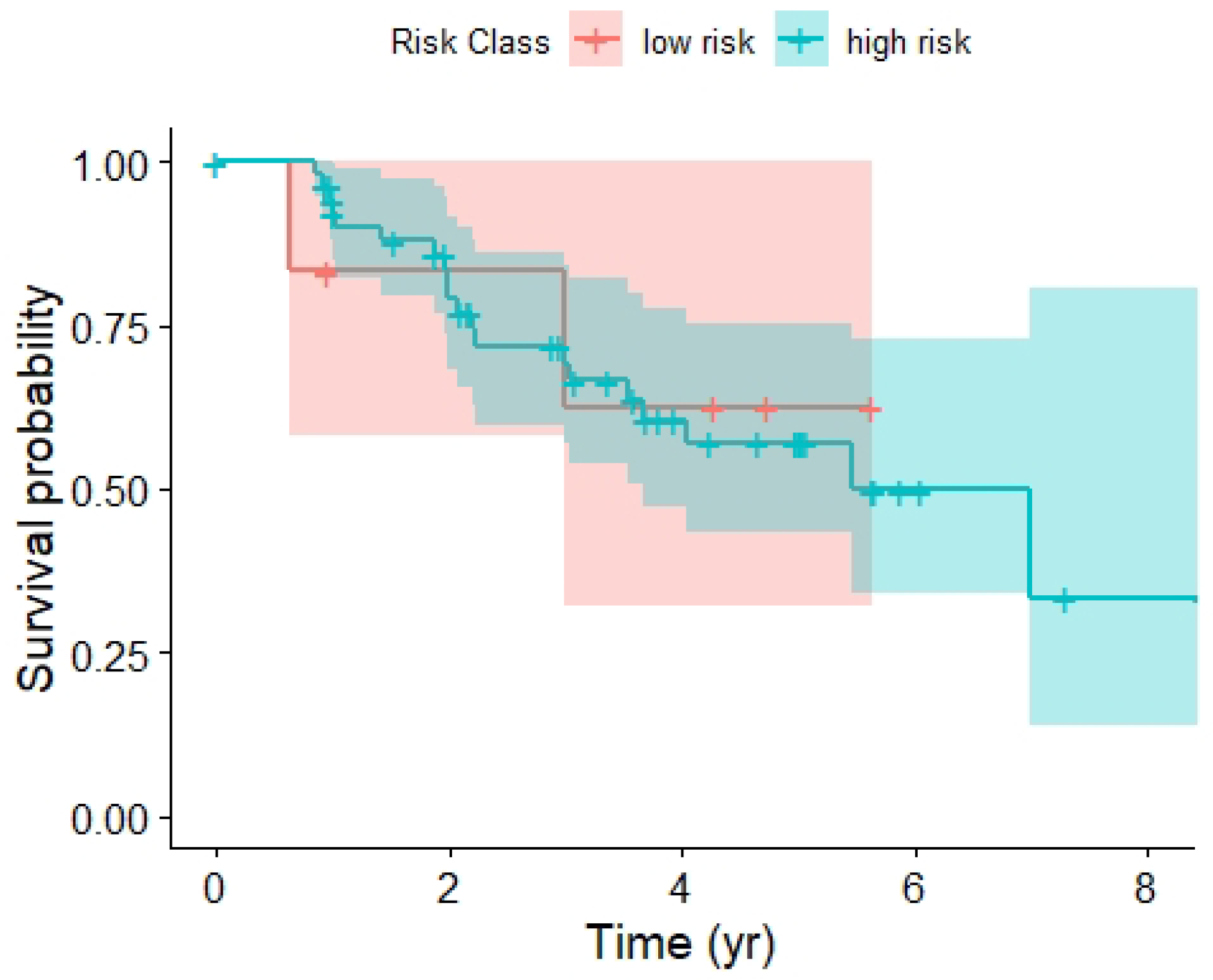{kind=link}
| Par. | Scenario 1: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 8.5716 | 5.7928 | 0.0586 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 0.3438 | 0.0938 | 0.3359 | 0.2925 | 0.0425 | 0.3173 | 0.2955 | 0.0455 | 0.3458 | |
| −2.2157 | −0.2157 | 0.5034 | −2.0969 | -0.0969 | 0.5175 | −2.1697 | −0.1697 | 0.5842 | |
| −2.1316 | −0.1316 | 0.5725 | −2.1392 | -0.1392 | 0.5567 | −2.2005 | −0.2005 | 0.5747 | |
| −1.0976 | −0.0976 | 0.5523 | −1.0863 | −0.0863 | 0.5232 | −1.0854 | −0.0854 | 0.5794 | |
| 1.0720 | 0.0720 | 0.5160 | 1.0126 | 0.0126 | 0.5185 | 1.1232 | 0.1232 | 0.5392 | |
| 2.1871 | 0.1871 | 0.5584 | 2.0966 | 0.0966 | 0.5286 | 2.0560 | 0.0560 | 0.5217 | |
| 3.2619 | 0.2619 | 0.5576 | 3.1412 | 0.1412 | 0.5455 | 3.2396 | 0.2396 | 0.6022 | |
| 3.2156 | 0.2156 | 0.5775 | 3.1507 | 0.1507 | 0.5468 | 3.2781 | 0.2781 | 0.5669 | |
| Par. | Scenario 2: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 5.7458 | 7.5817 | 0.0893 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 0.3222 | 0.0722 | 0.3006 | 0.2520 | 0.0020 | 0.1099 | 0.2813 | 0.0313 | 0.1065 | |
| −2.1110 | −0.1110 | 0.4399 | −2.0930 | −0.0930 | 0.4531 | −2.0783 | −0.0783 | 0.4743 | |
| −2.1236 | −0.1236 | 0.4634 | −2.1208 | −0.1208 | 0.4615 | −2.1232 | −0.1232 | 0.4384 | |
| −1.0788 | −0.0788 | 0.4491 | −1.0528 | −0.0528 | 0.4517 | −1.0598 | −0.0598 | 0.4877 | |
| 1.0507 | 0.0507 | 0.4467 | 0.9944 | −0.0056 | 0.4416 | 1.0457 | 0.0457 | 0.4539 | |
| 2.0663 | 0.0663 | 0.4679 | 2.0421 | 0.0421 | 0.4665 | 2.1415 | 0.1415 | 0.4872 | |
| 3.1734 | 0.1734 | 0.4824 | 3.0586 | 0.0586 | 0.4499 | 3.2054 | 0.2054 | 0.4726 | |
| 3.1833 | 0.1833 | 0.4574 | 3.0666 | 0.0666 | 0.4371 | 3.1279 | 0.1279 | 0.4558 | |
| Par. | Scenario 3: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 6.2193 | 11.4968 | 0.1281 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 0.2683 | 0.0183 | 0.2427 | 0.2478 | −0.0022 | 0.0862 | 0.2866 | 0.0366 | 0.0884 | |
| −2.0630 | −0.0630 | 0.3870 | −2.0491 | −0.0491 | 0.3831 | −2.0548 | −0.0548 | 0.4021 | |
| −2.0668 | −0.0668 | 0.3975 | −2.0430 | −0.0430 | 0.3903 | −2.0340 | −0.0340 | 0.3716 | |
| −1.0286 | −0.0286 | 0.3875 | −1.0327 | −0.0327 | 0.3799 | −1.0583 | −0.0583 | 0.4058 | |
| 1.0613 | 0.0613 | 0.4001 | 1.0131 | 0.0131 | 0.3915 | 1.0136 | 0.0136 | 0.3867 | |
| 2.0946 | 0.0946 | 0.3984 | 2.0315 | 0.0315 | 0.3853 | 2.0697 | 0.0697 | 0.4497 | |
| 3.1535 | 0.1535 | 0.4104 | 3.0739 | 0.0739 | 0.3973 | 3.1178 | 0.1178 | 0.4147 | |
| 3.1266 | 0.1266 | 0.4187 | 3.0378 | 0.0378 | 0.4088 | 3.1216 | 0.1216 | 0.3875 | |
| Par. | Scenario 1: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 4.8084 | 5.7248 | 0.0541 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 0.2712 | 0.0212 | 0.1446 | 0.2491 | −0.0009 | 0.1434 | 0.3022 | 0.0522 | 0.1507 | |
| −2.2181 | −0.2181 | 0.6137 | −2.1211 | −0.1211 | 0.5712 | −2.1928 | −0.1928 | 0.6084 | |
| −2.1717 | −0.1717 | 0.6270 | −2.1431 | −0.1431 | 0.6230 | −2.2133 | −0.2133 | 0.5920 | |
| −1.1136 | −0.1136 | 0.6001 | −1.0786 | −0.0786 | 0.5881 | −1.0936 | −0.0936 | 0.6158 | |
| 1.0926 | 0.0926 | 0.6117 | 1.0452 | 0.0452 | 0.5603 | 1.0499 | 0.0499 | 0.6049 | |
| 2.2211 | 0.2211 | 0.6234 | 2.0423 | 0.0423 | 0.5667 | 2.2068 | 0.2068 | 0.6567 | |
| 3.2667 | 0.2667 | 0.6156 | 3.1369 | 0.1369 | 0.6192 | 3.2481 | 0.2481 | 0.5558 | |
| 3.2490 | 0.2490 | 0.6192 | 3.1452 | 0.1452 | 0.6355 | 3.2599 | 0.2599 | 0.5502 | |
| Par. | Scenario 2: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 5.56726 | 7.7258 | 0.0818 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 0.3189 | 0.0689 | 0.9271 | 0.2496 | −0.0004 | 0.1150 | 0.2749 | 0.0249 | 0.1077 | |
| −2.0826 | −0.0826 | 0.4974 | −2.0987 | −0.0987 | 0.4898 | −2.0761 | −0.0761 | 0.5023 | |
| −2.1135 | −0.1135 | 0.5391 | −2.0965 | −0.0965 | 0.4950 | −2.0974 | −0.0974 | 0.5200 | |
| −1.0764 | −0.0764 | 0.5065 | −1.0743 | −0.0743 | 0.5180 | −1.0510 | −0.0510 | 0.5055 | |
| 1.0654 | 0.0654 | 0.5137 | 1.0433 | 0.0433 | 0.5028 | 1.0739 | 0.0739 | 0.5766 | |
| 2.1250 | 0.1250 | 0.5033 | 2.0525 | 0.0525 | 0.4933 | 2.1029 | 0.1029 | 0.5137 | |
| 3.1731 | 0.1731 | 0.5236 | 3.0821 | 0.0821 | 0.5105 | 3.1316 | 0.1316 | 0.5783 | |
| 3.1966 | 0.1966 | 0.5207 | 3.0716 | 0.0716 | 0.5034 | 3.2236 | 0.2236 | 0.5268 | |
| Par. | Scenario 3: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 4.7591 | 8.4607 | 0.1188 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 0.2729 | 0.0229 | 0.4236 | 0.2434 | −0.0066 | 0.0865 | 0.2792 | 0.0292 | 0.0966 | |
| −2.0917 | −0.0917 | 0.3814 | −2.0714 | −0.0714 | 0.3741 | −2.1494 | −0.1494 | 0.4376 | |
| −2.0692 | −0.0692 | 0.4076 | −2.0495 | −0.0495 | 0.3990 | −2.0617 | −0.0617 | 0.4617 | |
| −1.0320 | −0.0320 | 0.3822 | −1.0341 | −0.0341 | 0.3725 | −1.0714 | −0.0714 | 0.4174 | |
| 1.0606 | 0.0606 | 0.3928 | 1.0163 | 0.0163 | 0.3843 | 1.0991 | 0.0991 | 0.3947 | |
| 2.0530 | 0.0530 | 0.3851 | 1.9865 | −0.0135 | 0.3773 | 2.0780 | 0.0780 | 0.4779 | |
| 3.1058 | 0.1058 | 0.4000 | 3.0158 | 0.0158 | 0.3855 | 3.1531 | 0.1531 | 0.4395 | |
| 3.1071 | 0.1071 | 0.3849 | 3.0182 | 0.0182 | 0.3752 | 3.1250 | 0.1250 | 0.4593 | |
| Par. | Scenario 1: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 22.3576 | 18.1613 | 0.0846 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 2.0584 | 0.0584 | 0.6494 | 2.1028 | 0.1028 | 0.7066 | 2.1197 | 0.1197 | 0.7023 | |
| −2.1343 | −0.1343 | 0.5452 | −2.1155 | −0.1155 | 0.4974 | −2.1027 | −0.1027 | 0.6415 | |
| −2.1700 | −0.1700 | 0.5426 | −2.1303 | −0.1303 | 0.4923 | −2.1633 | −0.1633 | 0.5354 | |
| −1.0561 | −0.0561 | 0.5395 | −1.0550 | −0.0550 | 0.5505 | −1.0768 | −0.0768 | 0.6086 | |
| 1.0515 | 0.0515 | 0.5749 | 1.0073 | 0.0073 | 0.5046 | 1.0883 | 0.0883 | 0.6006 | |
| 2.1385 | 0.1385 | 0.542 | 2.1311 | 0.1311 | 0.5639 | 2.1685 | 0.1685 | 0.5608 | |
| 3.1702 | 0.1702 | 0.5815 | 3.1928 | 0.1928 | 0.5893 | 3.2140 | 0.2140 | 0.5916 | |
| 3.2185 | 0.2185 | 0.5623 | 3.1268 | 0.1268 | 0.6005 | 3.2433 | 0.2433 | 0.6320 | |
| Par. | Scenario 2: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 23.2786 | 41.7191 | 0.1438 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 2.0934 | 0.0934 | 0.4866 | 2.0270 | 0.0270 | 0.4817 | 2.151 | 0.1510 | 0.6232 | |
| −2.1266 | −0.1266 | 0.4648 | −2.1027 | −0.1027 | 0.4600 | −2.1189 | −0.1189 | 0.5060 | |
| −2.1197 | −0.1197 | 0.4763 | −2.0886 | −0.0886 | 0.4549 | −2.1842 | −0.1842 | 0.4881 | |
| −1.0328 | −0.0328 | 0.4703 | −1.0685 | −0.0685 | 0.4789 | −1.0671 | −0.0671 | 0.4818 | |
| 1.0604 | 0.0604 | 0.4871 | 1.0212 | 0.0212 | 0.4847 | 1.0956 | 0.0956 | 0.4446 | |
| 2.1313 | 0.1313 | 0.4696 | 2.0185 | 0.0185 | 0.4745 | 2.0961 | 0.0961 | 0.4848 | |
| 3.1788 | 0.1788 | 0.4695 | 3.0747 | 0.0747 | 0.4954 | 3.1749 | 0.1749 | 0.4888 | |
| 3.1934 | 0.1934 | 0.5120 | 3.1287 | 0.1287 | 0.4953 | 3.1908 | 0.1908 | 0.5070 | |
| Par. | Scenario 3: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 27.4950 | 47.8408 | 0.2415 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 2.0792 | 0.0792 | 0.4091 | 2.0268 | 0.0268 | 0.3890 | 2.0905 | 0.0905 | 0.4287 | |
| −2.0896 | −0.0896 | 0.4017 | −2.0466 | −0.0466 | 0.4406 | −2.1372 | −0.1372 | 0.4366 | |
| −2.0619 | −0.0619 | 0.4060 | −2.0388 | −0.0388 | 0.4199 | −2.1541 | −0.1541 | 0.463 | |
| −1.0431 | −0.0431 | 0.4186 | −1.0190 | −0.0190 | 0.4047 | −1.0672 | −0.0672 | 0.4016 | |
| 1.0739 | 0.0739 | 0.4190 | 1.0363 | 0.0363 | 0.4025 | 1.0006 | 0.0006 | 0.4269 | |
| 2.0655 | 0.0655 | 0.4141 | 2.0694 | 0.0694 | 0.4272 | 2.0781 | 0.0781 | 0.4213 | |
| 3.1542 | 0.1542 | 0.3919 | 3.0680 | 0.0680 | 0.4461 | 3.1171 | 0.1171 | 0.4331 | |
| 3.1085 | 0.1085 | 0.4201 | 3.0707 | 0.0707 | 0.4800 | 3.1198 | 0.1198 | 0.4200 | |
| Par. | Scenario 1: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 18.1609 | 27.0720 | 0.0601 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 2.0325 | 0.0325 | 0.8620 | 2.0844 | 0.0844 | 0.7522 | 2.0332 | 0.0332 | 0.6807 | |
| −1.9628 | 0.0372 | 0.8105 | −2.2108 | −0.2108 | 0.6094 | −2.1984 | −0.1984 | 0.5954 | |
| −1.9076 | 0.0924 | 0.8051 | −2.1330 | −0.1330 | 0.5744 | −2.1072 | −0.1072 | 0.6045 | |
| −1.0357 | −0.0357 | 0.5701 | −1.0732 | −0.0732 | 0.5423 | −1.1172 | −0.1172 | 0.5989 | |
| 0.9478 | −0.0522 | 0.6464 | 1.0731 | 0.0731 | 0.5596 | 1.0585 | 0.0585 | 0.5717 | |
| 1.9482 | −0.0518 | 0.7783 | 2.0924 | 0.0924 | 0.5450 | 2.1451 | 0.1451 | 0.6499 | |
| 2.9937 | −0.0063 | 1.0379 | 3.1667 | 0.1667 | 0.6197 | 3.2788 | 0.2788 | 0.5763 | |
| 2.9867 | −0.0133 | 1.0485 | 3.2437 | 0.2437 | 0.6203 | 3.2631 | 0.2631 | 0.5981 | |
| Par. | Scenario 2: | ||||||||
| Profile MM approach | Non-Profile MM Approach | Coxph | |||||||
| T | 16.7308 | 30.7202 | 0.0995 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 2.0880 | 0.0880 | 0.5207 | 2.0962 | 0.0962 | 0.4792 | 2.1913 | 0.1913 | 0.6610 | |
| −2.1346 | −0.1346 | 0.5360 | −2.1102 | −0.1102 | 0.4817 | −2.1127 | −0.1127 | 0.5501 | |
| −2.0743 | −0.0743 | 0.5299 | −2.1301 | −0.1301 | 0.5327 | −2.0796 | −0.0796 | 0.5362 | |
| −1.0846 | −0.0846 | 0.5289 | −1.0862 | −0.0862 | 0.5136 | −1.0690 | −0.0690 | 0.4962 | |
| 1.0980 | 0.0980 | 0.5242 | 1.0001 | 0.0001 | 0.5169 | 1.0932 | 0.0932 | 0.5306 | |
| 2.1329 | 0.1329 | 0.5216 | 2.0354 | 0.0354 | 0.5278 | 2.1117 | 0.1117 | 0.5432 | |
| 3.2089 | 0.2089 | 0.5183 | 3.1365 | 0.1365 | 0.5155 | 3.2383 | 0.2383 | 0.5587 | |
| 3.1702 | 0.1702 | 0.5345 | 3.1695 | 0.1695 | 0.5495 | 3.2301 | 0.2301 | 0.5380 | |
| Par. | Scenario 3: | ||||||||
| Profile MM Approach | Non-Profile MM Approach | Coxph | |||||||
| T | 16.3097 | 29.1778 | 0.1647 | ||||||
| MLE | Bias | SD | MLE | Bias | SD | MLE | Bias | SD | |
| 2.0999 | 0.0999 | 0.4480 | 2.0462 | 0.0462 | 0.3831 | 2.0948 | 0.0948 | 0.3700 | |
| −2.1151 | −0.1151 | 0.4605 | −2.0508 | −0.0508 | 0.4187 | −2.1324 | −0.1324 | 0.4554 | |
| −2.0767 | −0.0767 | 0.4197 | −2.0876 | −0.0876 | 0.4615 | −2.1001 | −0.1001 | 0.4394 | |
| −1.0963 | −0.0963 | 0.4629 | −1.0712 | −0.0712 | 0.4393 | −1.0513 | −0.0513 | 0.4306 | |
| 1.0443 | 0.0443 | 0.4313 | 0.9910 | −0.0090 | 0.4234 | 2.0347 | 0.0347 | 0.4476 | |
| 2.0813 | 0.0813 | 0.4775 | 2.0330 | 0.0330 | 0.4630 | 2.1039 | 0.1039 | 0.4538 | |
| 3.1089 | 0.1089 | 0.4848 | 3.0978 | 0.0978 | 0.4660 | 3.1829 | 0.1829 | 0.4484 | |
| 3.1216 | 0.1216 | 0.4805 | 3.1462 | 0.1462 | 0.5005 | 3.1834 | 0.1834 | 0.5308 | |
| Par. | Scenario 1: | |||||
| Profile MM Approach | Non-Profile MM Approach | |||||
| T | 3.0369 | 7.9534 | ||||
| MLE | Bias | SD | MLE | Bias | SD | |
| 0.7060 | −0.2940 | 0.6920 | 0.7130 | −0.2870 | 0.6511 | |
| −2.1516 | −0.1516 | 0.5664 | −2.1002 | −0.1002 | 0.4646 | |
| −2.1783 | −0.1783 | 0.5366 | −2.1062 | −0.1062 | 0.5173 | |
| −1.1028 | −0.1028 | 0.5526 | −1.0881 | −0.0881 | 0.4719 | |
| 1.1284 | 0.1284 | 0.5523 | 0.9661 | −0.0339 | 0.5069 | |
| 2.2162 | 0.2162 | 0.5225 | 1.9742 | −0.0258 | 0.4936 | |
| 3.2591 | 0.2591 | 0.5269 | 2.9877 | −0.0123 | 0.5332 | |
| 3.2139 | 0.2139 | 0.5553 | 3.0247 | 0.0247 | 0.5250 | |
| Par. | Scenario 2: | |||||
| Profile MM Approach | Non-Profile MM Approach | |||||
| T | 5.2872 | 27.2494 | ||||
| MLE | Bias | SD | MLE | Bias | SD | |
| 0.7537 | −0.2463 | 0.5623 | 0.9178 | −0.0822 | 0.4438 | |
| −2.1515 | −0.1515 | 0.4592 | −2.1441 | −0.1441 | 0.4455 | |
| −2.1300 | −0.1300 | 0.4646 | −2.1146 | −0.1146 | 0.4907 | |
| −1.0873 | −0.0873 | 0.4743 | −1.0830 | −0.0830 | 0.4316 | |
| 1.0681 | 0.0681 | 0.4755 | 1.0223 | 0.0223 | 0.4445 | |
| 2.1454 | 0.1454 | 0.4600 | 2.0591 | 0.0591 | 0.4625 | |
| 3.2323 | 0.2323 | 0.4972 | 3.1031 | 0.1031 | 0.4807 | |
| 3.2223 | 0.2223 | 0.4698 | 3.0855 | 0.0855 | 0.4907 | |
| Par. | Scenario 3: | |||||
| Profile MM Approach | Non-Profile MM Approach | |||||
| T | 54.9905 | 36.7796 | ||||
| MLE | Bias | SD | MLE | Bias | SD | |
| 0.8461 | −0.1539 | 0.4143 | 0.9724 | −0.0276 | 0.3678 | |
| −2.0933 | −0.0933 | 0.4056 | −2.0688 | −0.0688 | 0.4135 | |
| −2.1509 | −0.1509 | 0.4375 | −2.0664 | −0.0664 | 0.4318 | |
| −1.0878 | −0.0878 | 0.3992 | −1.0790 | −0.0790 | 0.3824 | |
| 1.0437 | 0.0437 | 0.4217 | 0.9728 | −0.0272 | 0.4111 | |
| 2.1137 | 0.1137 | 0.4077 | 2.0257 | 0.0257 | 0.4005 | |
| 3.1511 | 0.1511 | 0.4311 | 3.0709 | 0.0709 | 0.4129 | |
| 3.1846 | 0.1846 | 0.4137 | 3.0540 | 0.0540 | 0.4219 | |
| Par. | Scenario 1: | |||||
| Profile MM Approach | Non-Profile MM Approach | |||||
| T | 9.7444 | 16.1049 | ||||
| MLE | Bias | SD | MLE | Bias | SD | |
| 0.5343 | −0.4657 | 0.6665 | 0.7017 | −0.2983 | 0.6431 | |
| −2.1693 | −0.1693 | 0.6153 | −2.1795 | −0.1795 | 0.6054 | |
| −2.2288 | −0.2288 | 0.5688 | −2.1677 | −0.1677 | 0.6601 | |
| −1.0228 | −0.0228 | 0.5690 | −1.1006 | −0.1006 | 0.5843 | |
| 1.1635 | 0.1635 | 0.5542 | 1.0577 | 0.0577 | 0.6157 | |
| 2.2779 | 0.2779 | 0.6479 | 2.0902 | 0.0902 | 0.6168 | |
| 3.2790 | 0.2790 | 0.6760 | 3.1711 | 0.1711 | 0.6672 | |
| 3.3969 | 0.3969 | 0.6867 | 3.1939 | 0.1939 | 0.6412 | |
| Par. | Scenario 2: | |||||
| Profile MM Approach | Non-Profile MM Approach | |||||
| T | 22.7787 | 22.0124 | ||||
| MLE | Bias | SD | MLE | Bias | SD | |
| 0.6564 | −0.3436 | 0.5263 | 1.0203 | 0.0203 | 0.5297 | |
| −2.1801 | −0.1801 | 0.5395 | −2.1915 | −0.1915 | 0.4992 | |
| −2.0213 | −0.0213 | 0.4727 | −2.1508 | −0.1508 | 0.5142 | |
| −1.1390 | −0.1390 | 0.5202 | −1.0678 | −0.0678 | 0.5140 | |
| 1.0824 | 0.0824 | 0.5276 | 0.9845 | −0.0155 | 0.5005 | |
| 2.1354 | 0.1354 | 0.4639 | 2.0252 | 0.0252 | 0.5088 | |
| 3.1809 | 0.1809 | 0.6421 | 3.1362 | 0.1362 | 0.5233 | |
| 3.2375 | 0.2375 | 0.5542 | 3.0828 | 0.0828 | 0.5183 | |
| Par. | Scenario 3: | |||||
| Profile MM Approach | Non-Profile MM Approach | |||||
| T | 20.9400 | 32.6620 | ||||
| MLE | Bias | SD | MLE | Bias | SD | |
| 0.8502 | −0.1498 | 0.3856 | 0.9809 | −0.0191 | 0.3556 | |
| −2.1046 | −0.1046 | 0.4252 | −2.0688 | −0.0688 | 0.4124 | |
| −2.1536 | −0.1536 | 0.4224 | −2.1123 | −0.1123 | 0.4065 | |
| −1.0597 | −0.0597 | 0.3893 | −1.0542 | −0.0542 | 0.3806 | |
| 1.0692 | 0.0692 | 0.3973 | 1.0067 | 0.0067 | 0.3841 | |
| 2.1129 | 0.1129 | 0.4162 | 2.0184 | 0.0184 | 0.4005 | |
| 3.1770 | 0.1770 | 0.4159 | 3.0489 | 0.0489 | 0.4005 | |
| 3.2102 | 0.2102 | 0.4277 | 3.0832 | 0.0832 | 0.4120 | |
| MRME | Zeros | MRME | Zeros | |||
|---|---|---|---|---|---|---|
| Correct | Incorrect | Correct | Incorrect | |||
| Penalty | ||||||
| Profile MM method | ||||||
| 0.159 | 45.775 | 0 | 0.163 | 44.39 | 0 | |
| MCP () | 0.091 | 46 | 0 | 0.066 | 46 | 0 |
| SCAD () | 0.143 | 45.915 | 0 | 0.101 | 45.965 | 0 |
| Non-profile MM method | ||||||
| 0.089 | 45.74 | 0 | 0.188 | 44.225 | 0 | |
| MCP () | 0.051 | 46 | 0 | 0.085 | 46 | 0 |
| SCAD () | 0.077 | 45.885 | 0 | 0.106 | 45.88 | 0 |
| Penalty | Par. | Profile MM Approach | Non-Profile MM Approach | ||||
|---|---|---|---|---|---|---|---|
| MLE | Bias | SD | MLE | Bias | SD | ||
| MCP (ϱ = 0.25) | 0.4835 | 0.1120 | 0.4820 | 0.1398 | |||
| 0.0950 | 0.9988 | 0.1028 | |||||
| 0.1984 | 2.9856 | 0.1971 | |||||
| 0.1513 | 1.9791 | 0.1512 | |||||
| 0.2498 | 3.9868 | 0.2566 | |||||
| SCAD (ϱ = 0.25) | 0.4967 | 0.1267 | 0.4800 | 0.1335 | |||
| 1.0133 | 0.0133 | 0.0960 | 0.9864 | 0.0975 | |||
| 3.0167 | 0.0167 | 0.2023 | 2.9467 | 0.1644 | |||
| 2.0183 | 0.0183 | 0.1417 | 1.9816 | 0.1255 | |||
| 4.0315 | 0.0315 | 0.2657 | 3.9300 | 0.2334 | |||
| MCP (ϱ = 0.75) | 0.4886 | 0.1258 | 0.4842 | 0.1480 | |||
| 0.9774 | 0.1331 | 1.0071 | 0.0071 | 0.1369 | |||
| 3.0252 | 0.0252 | 0.2020 | 2.9743 | 0.2570 | |||
| 2.0083 | 0.0083 | 0.1831 | 1.9857 | 0.2203 | |||
| 4.0134 | 0.0134 | 0.2606 | 4.0026 | 0.0026 | 0.3055 | ||
| SCAD (ϱ = 0.75) | 0.4869 | 0.1277 | 0.4839 | 0.1341 | |||
| 1.0119 | 0.0119 | 0.1364 | 1.0152 | 0.0152 | 0.1560 | ||
| 2.9815 | 0.2063 | 3.0035 | 0.0035 | 0.2422 | |||
| 2.0012 | 0.0012 | 0.2238 | 1.9984 | 0.2052 | |||
| 4.0119 | 0.0119 | 0.2633 | 4.0021 | 0.0021 | 0.2855 | ||
| Patient ID | From CN to MCI | ||||
| First Observation Date of State CN | Date of Transition to MCI | Last Date of Observation | (yr) | ||
| 011_S_0002 | 8 September 2005 | 26 September 2012 | 18 October 2017 | 7.05 | 1 |
| 011_S_0021 | 24 October 2005 | - | 27 November 2017 | 12.10 | 0 |
| 100_S_0035 | 8 November 2005 | 8 December 2010 | 8 December 2010 | 5.08 | 1 |
| 131_S_0123 | 7 February 2006 | 23 February 2012 | 10 February 2016 | 6.05 | 1 |
| 127_S_0259 | 28 March 2006 | 9 April 2014 | 22 September 2017 | 8.04 | 1 |
| Patient ID | From MCI to Dementia | ||||
| First Observation Date of State MCI | Date of Transition to Dementia | Last Date of Observation | (yr) | ||
| 011_S_0002 | 26 September 2012 | - | 18 October 2017 | 5.06 | 0 |
| 011_S_0021 | - | - | - | - | - |
| 100_S_0035 | 8 December 2010 | - | 8 December 2010 | 0.00 | 0 |
| 131_S_0123 | 23 February 2012 | 12 February 2014 | 10 February 2016 | 1.97 | 1 |
| 127_S_0259 | 9 April 2014 | 10 April 2015 | 22 September 2017 | 1.00 | 1 |
| Profile MM | Non-Profile MM | |||
|---|---|---|---|---|
| Penalty | BIC | No. of Non-Zero | BIC | No. of Non-Zero |
| MCP | 1154.70 | 70 | 1154.75 | 70 |
| SCAD | 1150.59 | 69 | 1150.82 | 69 |
| Profile MM | Non-Profile MM | |||
|---|---|---|---|---|
| Penalty | BIC | No. of Non-Zero | BIC | No. of Non-Zero |
| MCP | 1198.76 | 27 | 1198.82 | 27 |
| SCAD | 1203.97 | 27 | 1204.50 | 27 |
| Profile MM | Non-Profile MM | |||
|---|---|---|---|---|
| Penalty | BIC | No. of Non-Zero | BIC | No. of Non-Zero |
| MCP | 1149.10 | 71 | 1148.86 | 72 |
| SCAD | 1149.10 | 71 | 1148.86 | 71 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Xu, J.; Zhou, Y. Profile and Non-Profile MM Modeling of Cluster Failure Time and Analysis of ADNI Data. Mathematics 2022, 10, 538. https://doi.org/10.3390/math10040538
Huang X, Xu J, Zhou Y. Profile and Non-Profile MM Modeling of Cluster Failure Time and Analysis of ADNI Data. Mathematics. 2022; 10(4):538. https://doi.org/10.3390/math10040538
Chicago/Turabian StyleHuang, Xifen, Jinfeng Xu, and Yunpeng Zhou. 2022. "Profile and Non-Profile MM Modeling of Cluster Failure Time and Analysis of ADNI Data" Mathematics 10, no. 4: 538. https://doi.org/10.3390/math10040538