
A New Hybrid Based on Long Short-Term Memory Network with Spotted Hyena Optimization Algorithm for Multi-Label Text Classification

 ,
,
Abstract
:1. Introduction
1.1. Motivation
1.2. Main Contributions
- Use the new SHO-LSTM model for MLTC;
- Use SHO to optimize the initial weight matrix of LSTM;
- Because the SHO has a high ability to solve the problem of non-linear optimization, it is a suitable algorithm for the initial weight matrix of the LSTM;
- Evaluate the proposed model based on various factors and compare it with other models.
1.3. Organization of the Paper
2. Previous Studies
2.1. MLTC
2.2. Related Works
3. Foundations
3.1. Spotted Hyena Optimizer
- First, they look about for the prey and follow it;
- Pursuit of prey to make it dull and straightforward to hunt;
- A troop of hyenas encircles the prey to ensure that it is hunted at the appropriate moment;
- The ultimate attack on the prey and its hunting by the hyena.
| Algorithm 1 Pseudo-code of the SHO algorithm |
| 1: procedure SHO 2: Set the parameters h, B, E, and N to their default values. 3: Calculate the fitness of each search agent 4: Ph = the most effective search agent 5: Ch = the collection or cluster of all far-outperforming solutions 6: while (x < Max number of iterations) do 7: for each search agent, do 8: It will be updated position of a current agent by Equation (10) 9: end for 10: Update h, B, E, and N 11: Check if any search agent goes beyond the given search space and then adjust it 12: Determine the fitness of each search agent 13: If there is a better solution than the prior optimal solution, update Ph 14: Update the group Ch w.r.t Ph 15: x = x + 1 16: end while 17: return Ph 18: end procedure |
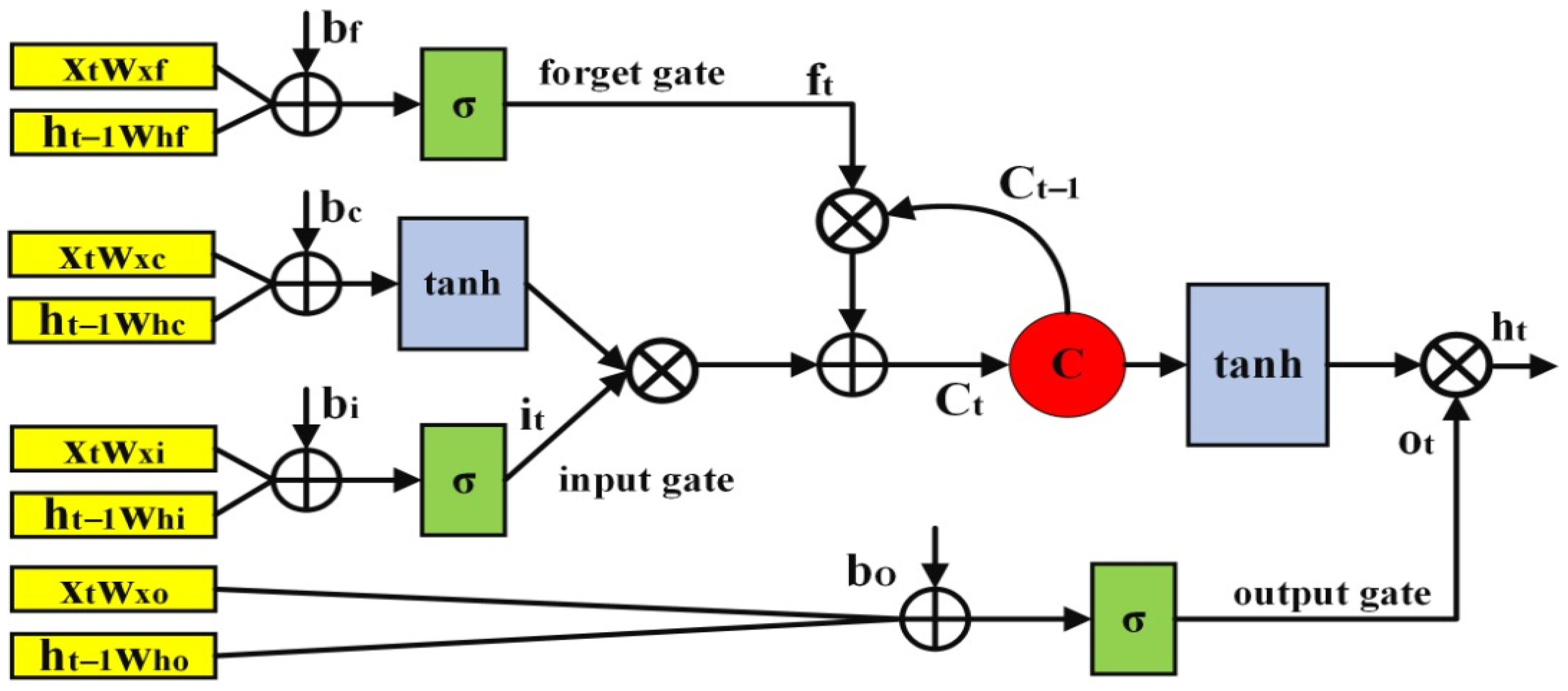
3.2. Long Short-Term Memory (LSTM)
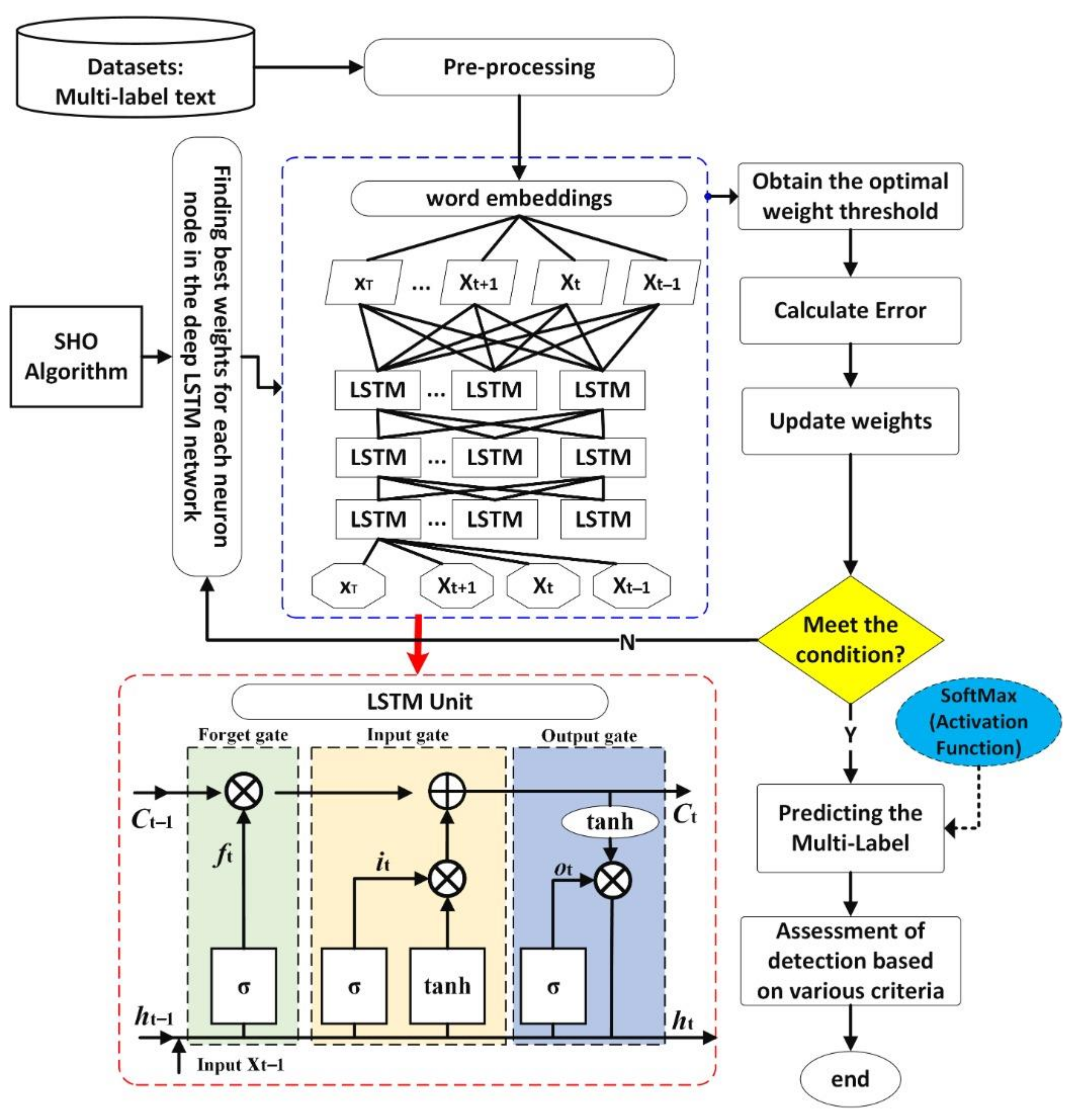
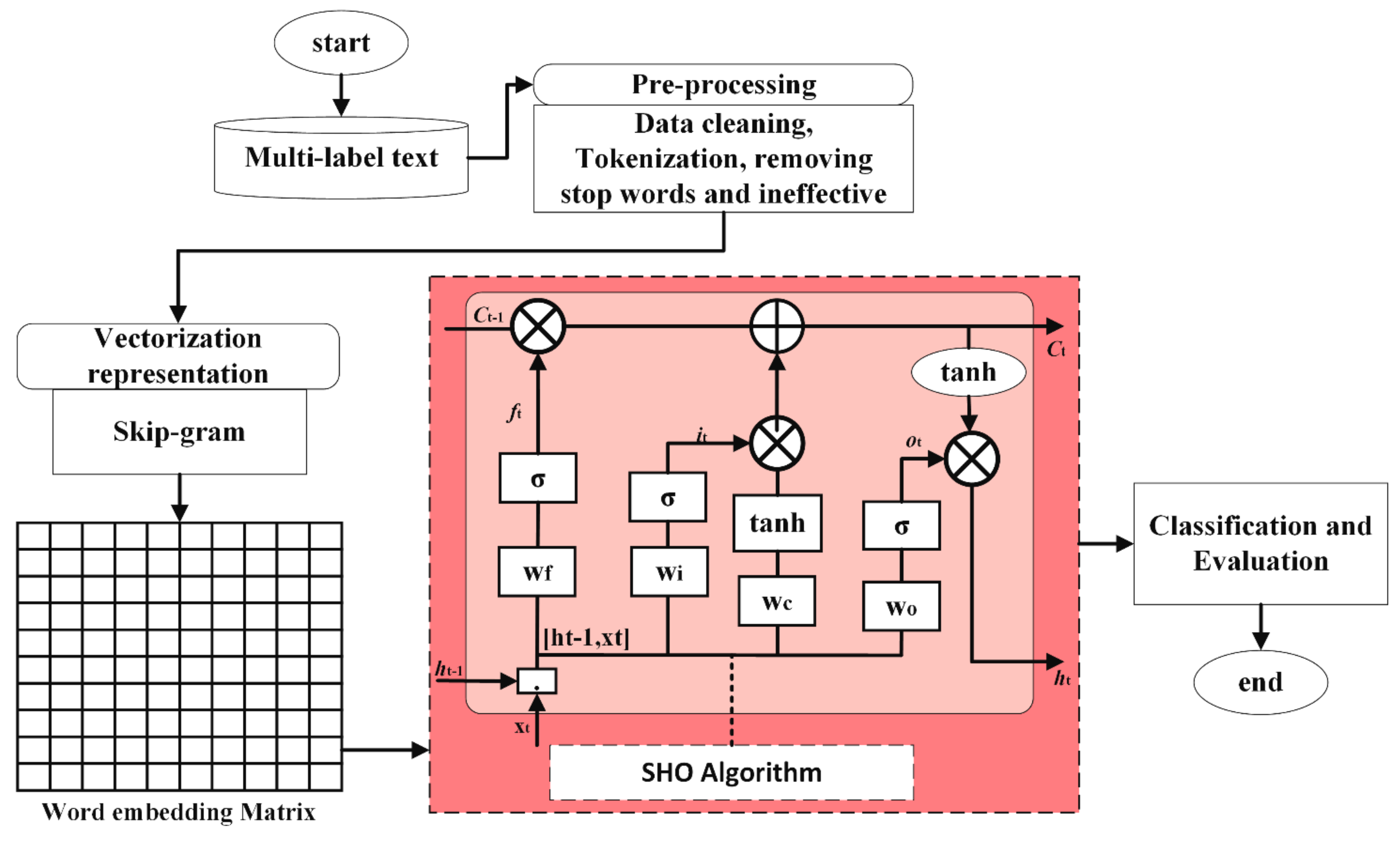
4. Proposed Model
4.1. Pre-Processing
- Convert numbers to words or delete numbers from textual data;
- Clear punctuation marks, accent marks, and diagnostic marks;
- Clear spaces from textual data;
- In the rooting stage, the roots of the words are found, and the words are defined as a base;
- Develop or expand abbreviations;
- Delete ineffective words and particular words;
- Synonymous words are eliminated and replaced by their more general meaning.
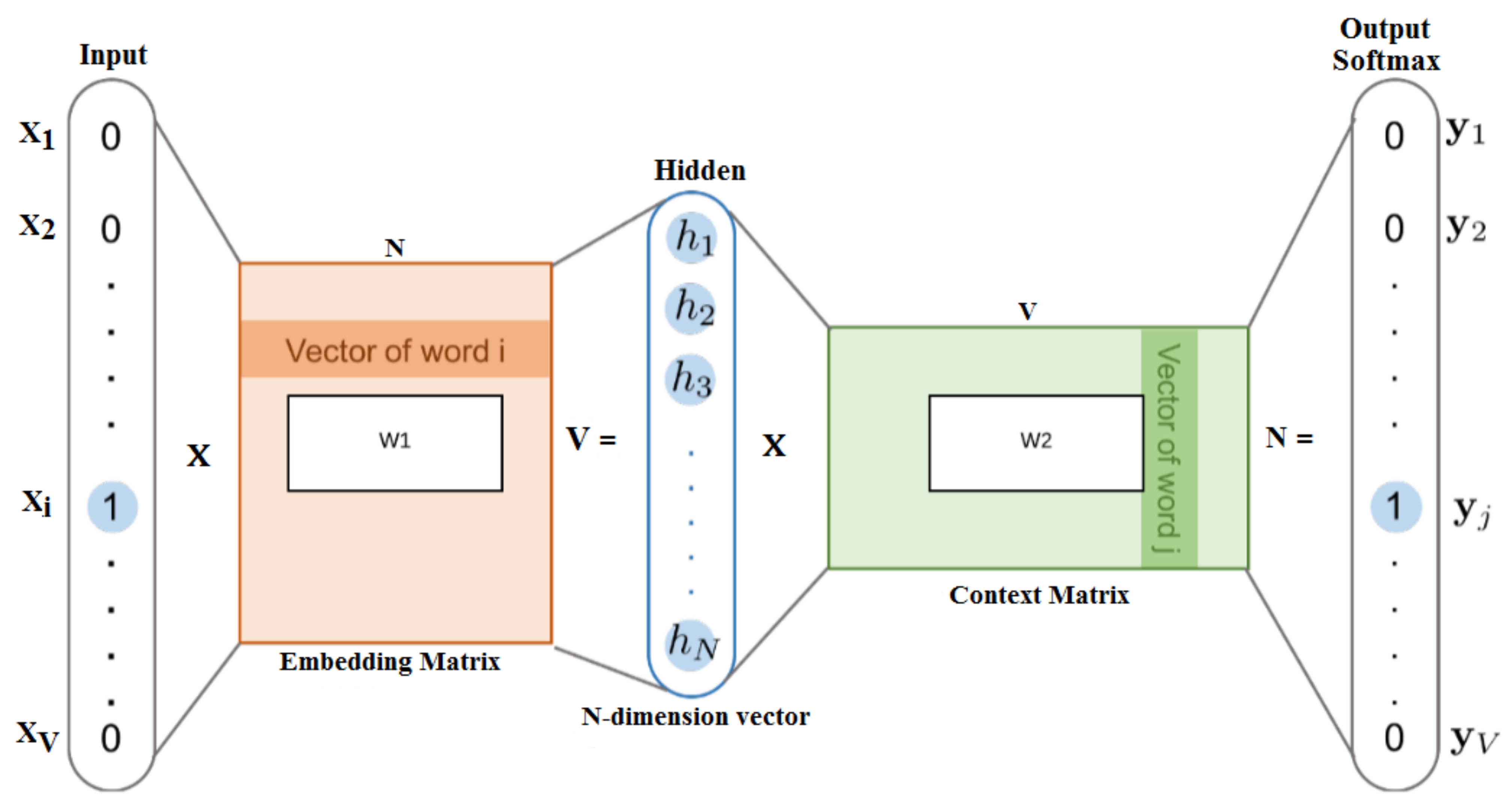
4.2. Embedding Words
4.3. SHO-LSTM
5. Evaluation and Results
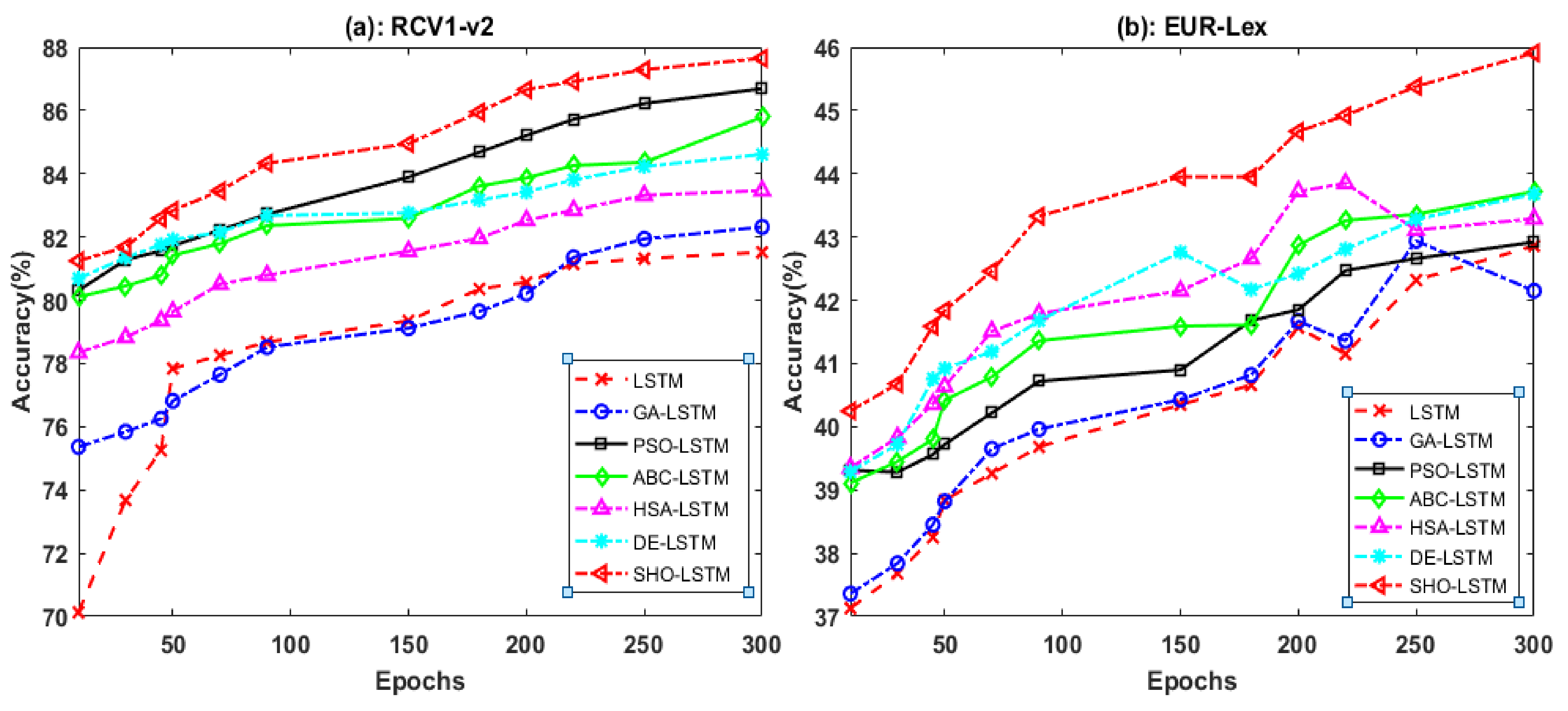
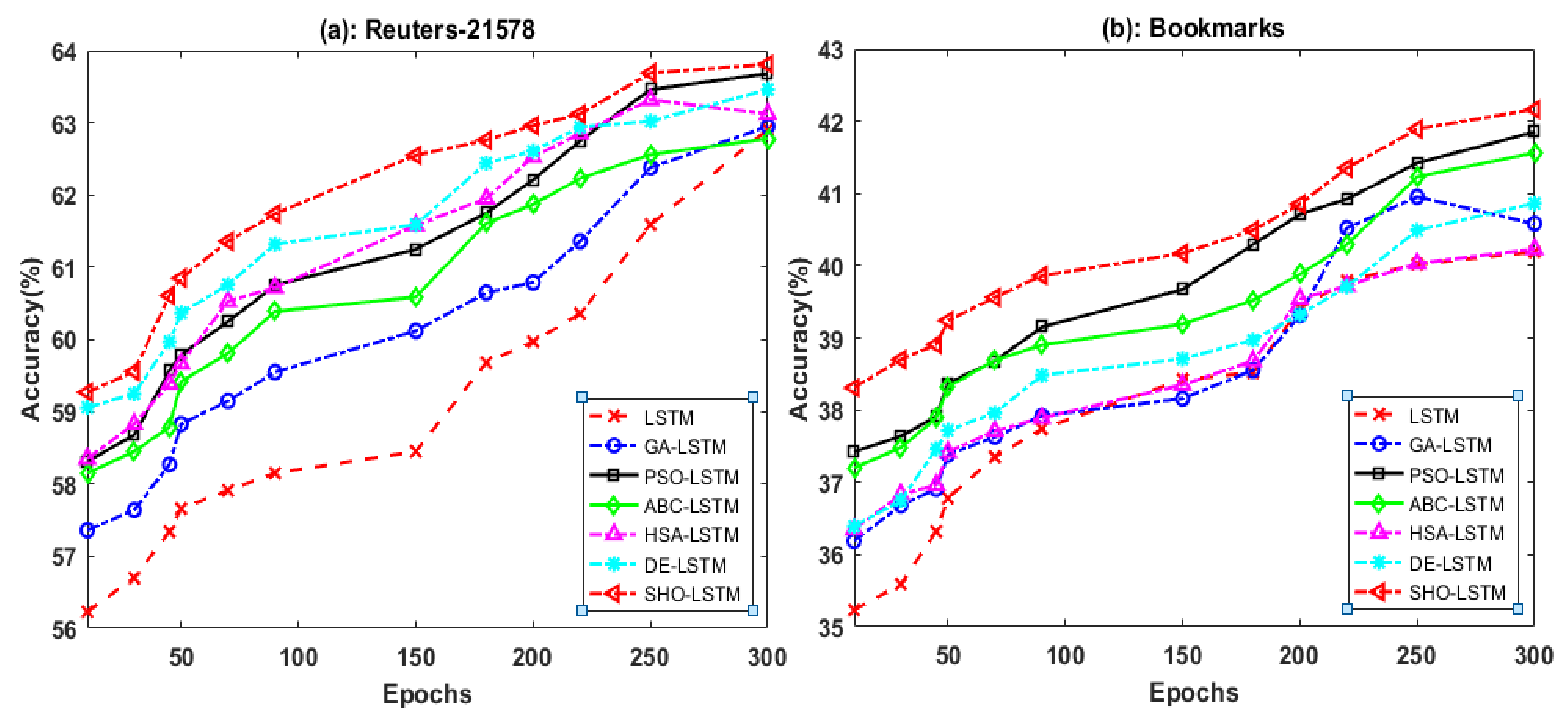
5.1. Evaluation Based on Epochs
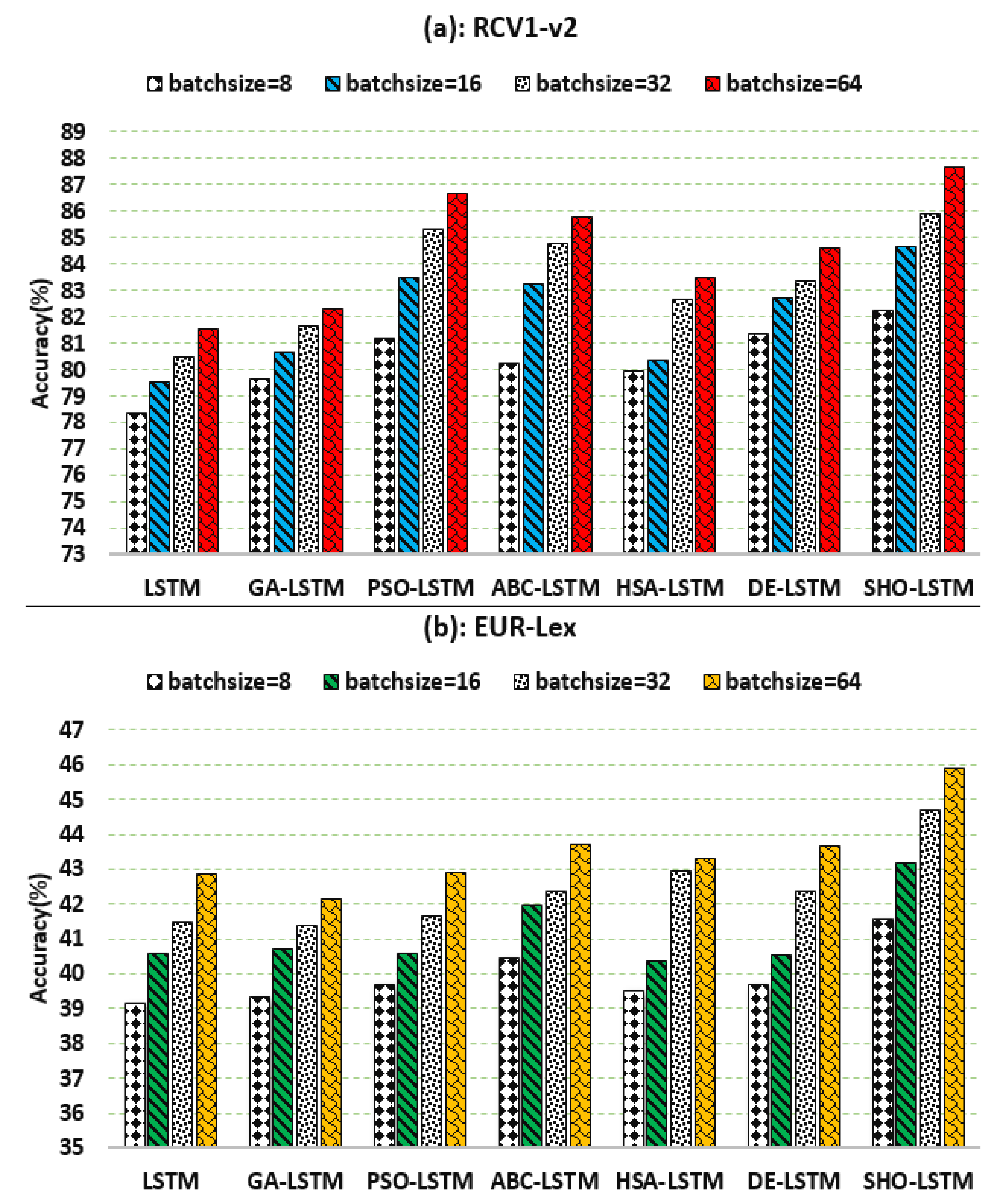
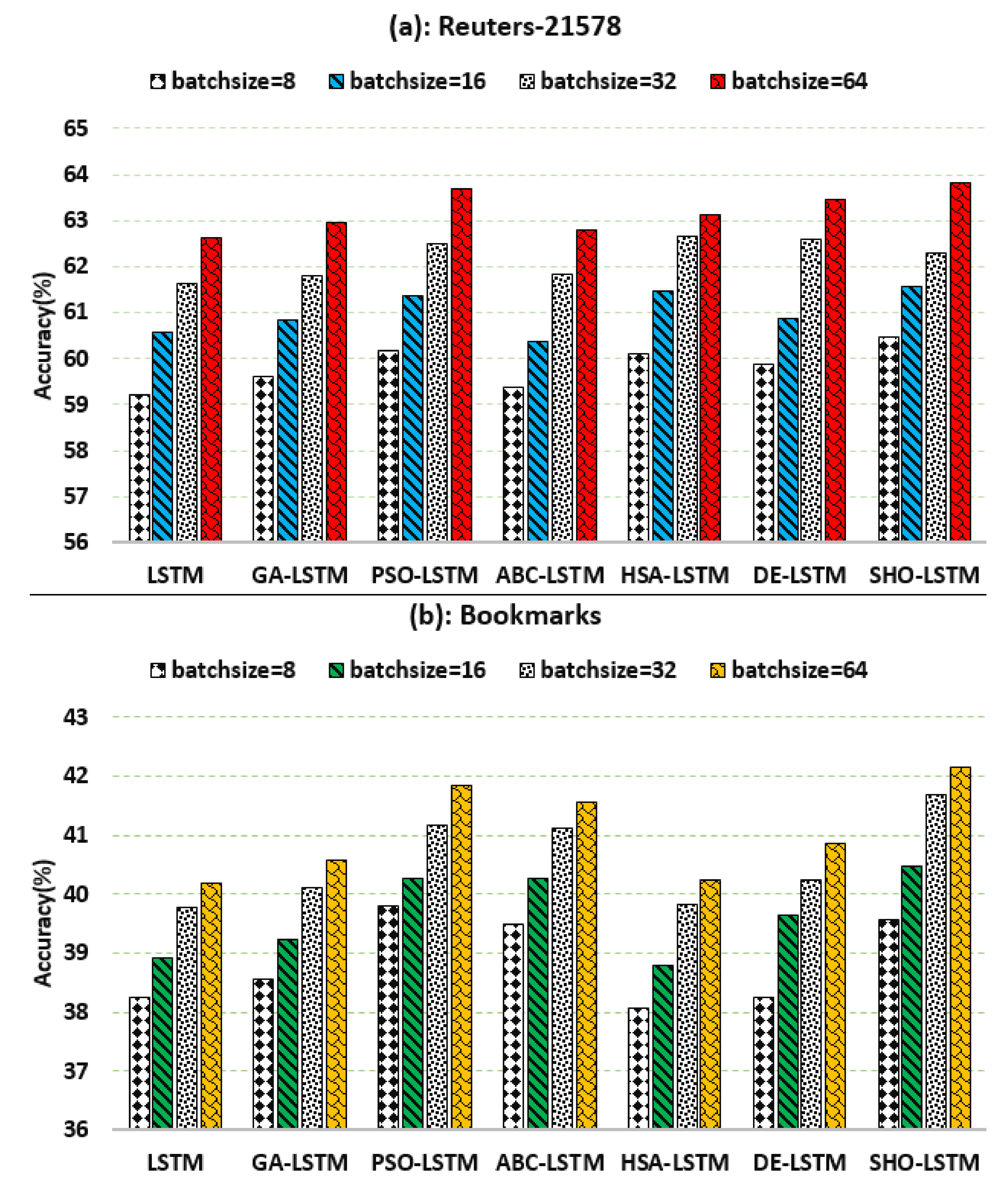
5.2. Evaluation based on Batchsize
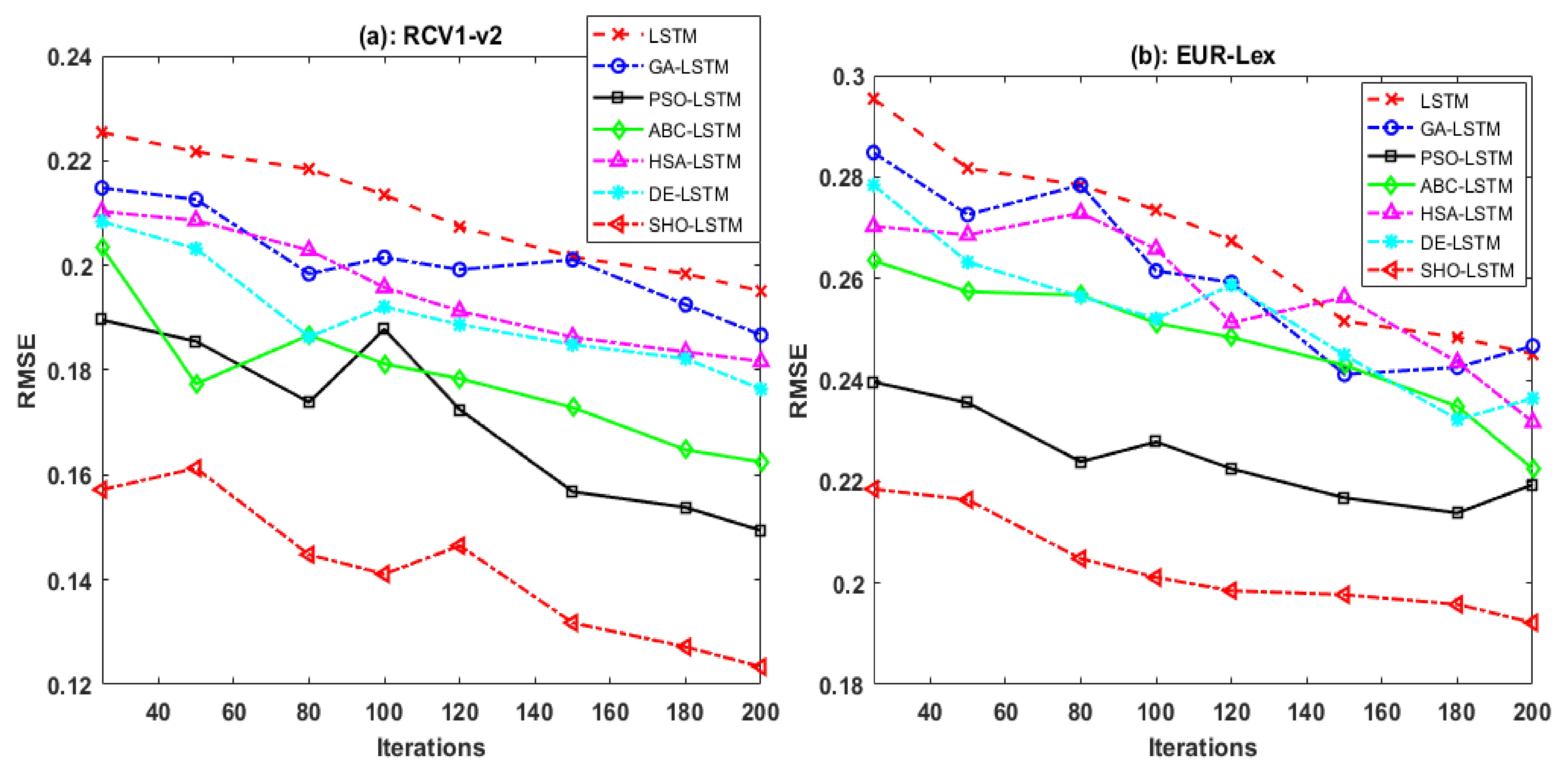
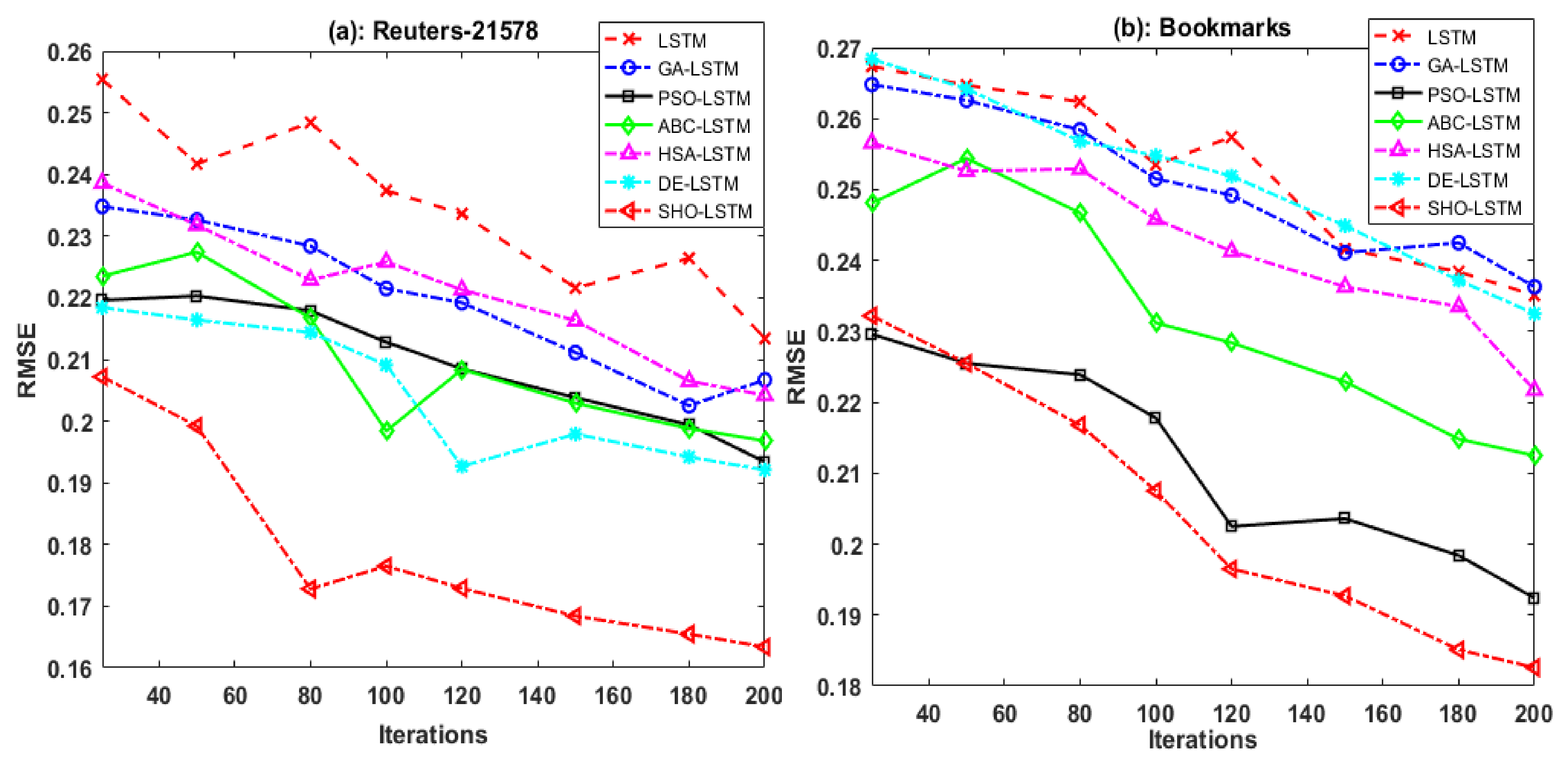
5.3. Evaluation Based on the Number of Iterations
5.4. Comparison and Evaluation
6. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Feremans, L.; Cule, B.; Vens, C.; Goethals, B. Combining instance and feature neighbours for extreme multi-label classification. Int. J. Data Sci. Anal. 2020, 10, 215–231. [Google Scholar] [CrossRef]
- Rubin, T.N.; Chambers, A.; Smyth, P.; Steyvers, M. Statistical topic models for multi-label document classification. Mach. Learn. 2012, 88, 157–208. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Wang, Q.; Ren, J. Label-Embedding Bi-directional Attentive Model for Multi-label Text Classification. Neural Process. Lett. 2021, 53, 375–389. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Khalifelu, Z.A. Analysis and evaluation of unstructured data: Text mining versus natural language processing. In Proceedings of the 2011 5th International Conference on Application of Information and Communication Technologies (AICT), Baku, Azerbaijan, 12–14 October 2011; pp. 1–4. [Google Scholar]
- Mittal, V.; Gangodkar, D.; Pant, B. Deep Graph-Long Short-Term Memory: A Deep Learning Based Approach for Text Classification. Wirel. Pers. Commun. 2021, 119, 2287–2301. [Google Scholar] [CrossRef]
- Liao, W.; Wang, Y.; Yin, Y.; Zhang, X.; Ma, P. Improved sequence generation model for multi-label classification via CNN and initialized fully connection. Neurocomputing 2020, 382, 188–195. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Zhan, H.; Lyu, S.; Lu, Y.; Pal, U. DenseNet-CTC: An end-to-end RNN-free architecture for context-free string recognition. Comput. Vis. Image Underst. 2021, 204, 103168. [Google Scholar] [CrossRef]
- Fasihi, M.; Nadimi-Shahraki, M.H.; Jannesari, A. A Shallow 1-D Convolution Neural Network for Fetal State Assessment Based on Cardiotocogram. SN Comput. Sci. 2021, 2, 287. [Google Scholar] [CrossRef]
- Fasihi, M.; Nadimi-Shahraki, M.H.; Jannesari, A. Multi-Class Cardiovascular Diseases Diagnosis from Electrocardiogram Signals using 1-D Convolution Neural Network. In Proceedings of the 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 11–13 August 2020; pp. 372–378. [Google Scholar]
- Lee, T. EMD and LSTM Hybrid Deep Learning Model for Predicting Sunspot Number Time Series with a Cyclic Pattern. Sol. Phys. 2020, 295, 82. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Jain, G.; Sharma, M.; Agarwal, B. Optimizing semantic LSTM for spam detection. Int. J. Inf. Technol. 2019, 11, 239–250. [Google Scholar] [CrossRef]
- Alotaibi, F.M.; Asghar, M.Z.; Ahmad, S. A Hybrid CNN-LSTM Model for Psychopathic Class Detection from Tweeter Users. Cogn. Comput. 2021, 13, 709–723. [Google Scholar] [CrossRef]
- Wang, R.; Peng, C.; Gao, J.; Gao, Z.; Jiang, H. A dilated convolution network-based LSTM model for multi-step prediction of chaotic time series. Comput. Appl. Math. 2019, 39, 30. [Google Scholar] [CrossRef]
- Yang, Z.; Wei, C. Prediction of equipment performance index based on improved chaotic lion swarm optimization–LSTM. Soft Comput. 2020, 24, 9441–9465. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Muhammad Adnan, R. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Li, S.; You, X.; Liu, S. Multiple ant colony optimization using both novel LSTM network and adaptive Tanimoto communication strategy. Appl. Intell. 2021, 51, 5644–5664. [Google Scholar] [CrossRef]
- Gong, C.; Wang, X.; Gani, A.; Qi, H. Enhanced long short-term memory with fireworks algorithm and mutation operator. J. Supercomput. 2021, 77, 12630–12646. [Google Scholar] [CrossRef]
- Goluguri, N.V.R.R.; Devi, K.S.; Srinivasan, P. Rice-net: An efficient artificial fish swarm optimization applied deep convolutional neural network model for identifying the Oryza sativa diseases. Neural Comput. Appl. 2020, 33, 5869–5884. [Google Scholar] [CrossRef]
- Jalali, S.M.J.; Ahmadian, S.; Khodayar, M.; Khosravi, A.; Ghasemi, V.; Shafie-khah, M.; Nahavandi, S.; Catalão, J.P.S. Towards novel deep neuroevolution models: Chaotic levy grasshopper optimization for short-term wind speed forecasting. Eng. Comput. 2021. [Google Scholar] [CrossRef]
- Ghulanavar, R.; Dama, K.K.; Jagadeesh, A. Diagnosis of faulty gears by modified AlexNet and improved grasshopper optimization algorithm (IGOA). J. Mech. Sci. Technol. 2020, 34, 4173–4182. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, R.; Zhang, J. Optimization scheme of wind energy prediction based on artificial intelligence. Environ. Sci. Pollut. Res. 2021, 28, 39966–39981. [Google Scholar] [CrossRef] [PubMed]
- Rajeev, R.; Samath, J.A.; Karthikeyan, N.K. An Intelligent Recurrent Neural Network with Long Short-Term Memory (LSTM) BASED Batch Normalization for Medical Image Denoising. J. Med. Syst. 2019, 43, 234. [Google Scholar] [CrossRef] [PubMed]
- Vijayaprabakaran, K.; Sathiyamurthy, K. Neuroevolution based hierarchical activation function for long short-term model network. J. Ambient Intell. Humaniz. Comput. 2021, 12, 10757–10768. [Google Scholar] [CrossRef]
- Sikkandar, H.; Thiyagarajan, R. Deep learning based facial expression recognition using improved Cat Swarm Optimization. J. Ambient Intell. Humaniz. Comput. 2021, 12, 3037–3053. [Google Scholar] [CrossRef]
- Lan, K.; Liu, L.; Li, T.; Chen, Y.; Fong, S.; Marques, J.A.L.; Wong, R.K.; Tang, R. Multi-view convolutional neural network with leader and long-tail particle swarm optimizer for enhancing heart disease and breast cancer detection. Neural Comput. Appl. 2020, 32, 15469–15488. [Google Scholar] [CrossRef]
- Nandhini, S.; Ashokkumar, K. Improved crossover based monarch butterfly optimization for tomato leaf disease classification using convolutional neural network. Multimed. Tools Appl. 2021, 80, 18583–18610. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Spotted hyena optimizer: A novel bio-inspired based metaheuristic technique for engineering applications. Adv. Eng. Softw. 2017, 114, 48–70. [Google Scholar] [CrossRef]
- Wang, R.; Ridley, R.; Su, X.; Qu, W.; Dai, X. A novel reasoning mechanism for multi-label text classification. Inf. Process. Manag. 2021, 58, 102441. [Google Scholar] [CrossRef]
- Omar, A.; Mahmoud, T.M.; Abd-El-Hafeez, T.; Mahfouz, A. Multi-label Arabic text classification in Online Social Networks. Inf. Syst. 2021, 100, 101785. [Google Scholar] [CrossRef]
- Udandarao, V.; Agarwal, A.; Gupta, A.; Chakraborty, T. InPHYNet: Leveraging attention-based multitask recurrent networks for multi-label physics text classification. Knowl.-Based Syst. 2021, 211, 106487. [Google Scholar] [CrossRef]
- Ciarelli, P.M.; Oliveira, E.; Salles, E.O.T. Multi-label incremental learning applied to web page categorization. Neural Comput. Appl. 2014, 24, 1403–1419. [Google Scholar] [CrossRef]
- Yao, L.; Sheng, Q.Z.; Ngu, A.H.H.; Gao, B.J.; Li, X.; Wang, S. Multi-label classification via learning a unified object-label graph with sparse representation. World Wide Web. 2016, 19, 1125–1149. [Google Scholar] [CrossRef]
- Ghiandoni, G.M.; Bodkin, M.J.; Chen, B.; Hristozov, D.; Wallace, J.E.A.; Webster, J.; Gillet, V.J. Enhancing reaction-based de novo design using a multi-label reaction class recommender. J. Comput.-Aided Mol. Des. 2020, 34, 783–803. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laghmari, K.; Marsala, C.; Ramdani, M. An adapted incremental graded multi-label classification model for recommendation systems. Prog. Artif. Intell. 2018, 7, 15–29. [Google Scholar] [CrossRef]
- Zou, Y.-p.; Ouyang, J.-h.; Li, X.-m. Supervised topic models with weighted words: Multi-label document classification. Front. Inf. Technol. Electron. Eng. 2018, 19, 513–523. [Google Scholar] [CrossRef]
- Li, X.; Ouyang, J.; Zhou, X. Labelset topic model for multi-label document classification. J. Intell. Inf. Syst. 2016, 46, 83–97. [Google Scholar] [CrossRef]
- Wang, B.; Hu, X.; Li, P.; Yu, P.S. Cognitive structure learning model for hierarchical multi-label text classification. Knowl.-Based Syst. 2021, 218, 106876. [Google Scholar] [CrossRef]
- Neshat, M.; Nezhad, M.M.; Abbasnejad, E.; Mirjalili, S.; Tjernberg, L.B.; Astiaso Garcia, D.; Alexander, B.; Wagner, M. A deep learning-based evolutionary model for short-term wind speed forecasting: A case study of the Lillgrund offshore wind farm. Energy Convers. Manag. 2021, 236, 114002. [Google Scholar] [CrossRef]
- Kwon, D.-H.; Kim, J.-B.; Heo, J.-S.; Kim, C.-M.; Han, Y.-H. Time Series Classification of Cryptocurrency Price Trend Based on a Recurrent LSTM Neural Network. J. Inf. Process. Syst. 2019, 15, 694–706. [Google Scholar]
- Koutsoukas, A.; Monaghan, K.J.; Li, X.; Huan, J. Deep-learning: Investigating deep neural networks hyper-parameters and comparison of performance to shallow methods for modeling bioactivity data. J. Cheminform. 2017, 9, 42. [Google Scholar] [CrossRef] [PubMed]
- Pareek, V.; Chaudhury, S. Deep learning-based gas identification and quantification with auto-tuning of hyper-parameters. Soft Comput. 2021, 25, 14155–14170. [Google Scholar] [CrossRef]
- Ibrahim, M.A.; Ghani Khan, M.U.; Mehmood, F.; Asim, M.N.; Mahmood, W. GHS-NET a generic hybridized shallow neural network for multi-label biomedical text classification. J. Biomed. Inform. 2021, 116, 103699. [Google Scholar] [CrossRef] [PubMed]
- Duan, X.; Ying, S.; Cheng, H.; Yuan, W.; Yin, X. OILog: An online incremental log keyword extraction approach based on MDP-LSTM neural network. Inf. Syst. 2021, 95, 101618. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-series well performance prediction based on Long Short-Term Memory (LSTM) neural network model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Das Chakladar, D.; Dey, S.; Roy, P.P.; Dogra, D.P. EEG-based mental workload estimation using deep BLSTM-LSTM network and evolutionary algorithm. Biomed. Signal Process. Control 2020, 60, 101989. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. A novel genetic LSTM model for wind power forecast. Energy 2021, 223, 120069. [Google Scholar] [CrossRef]
- Memarzadeh, G.; Keynia, F. A new short-term wind speed forecasting method based on fine-tuned LSTM neural network and optimal input sets. Energy Convers. Manag. 2020, 213, 112824. [Google Scholar] [CrossRef]
- Ding, N.; Li, H.; Yin, Z.; Zhong, N.; Zhang, L. Journal bearing seizure degradation assessment and remaining useful life prediction based on long short-term memory neural network. Measurement 2020, 166, 108215. [Google Scholar] [CrossRef]
- Huang, Y.-F.; Chen, P.-H. Fake news detection using an ensemble learning model based on Self-Adaptive Harmony Search algorithms. Expert Syst. Appl. 2020, 159, 113584. [Google Scholar] [CrossRef]
- Prasanth, S.; Singh, U.; Kumar, A.; Tikkiwal, V.A.; Chong, P.H.J. Forecasting spread of COVID-19 using google trends: A hybrid GWO-deep learning approach. Chaos Solitons Fractals 2021, 142, 110336. [Google Scholar] [CrossRef]
- Liang, J.; Yang, H.; Gao, J.; Yue, C.; Ge, S.; Qu, B. MOPSO-Based CNN for Keyword Selection on Google Ads. IEEE Access 2019, 7, 125387–125400. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Alazab, M.; Kaluri, R.; Maddikunta, P.K.R.; Bhattacharya, S.; Lakshmanna, K.; Parimala, M. Hand gesture classification using a novel CNN-crow search algorithm. Complex Intell. Syst. 2021, 7, 1855–1868. [Google Scholar] [CrossRef]
- Kumar, K.; Haider, M.T.U. Enhanced Prediction of Intra-day Stock Market Using Metaheuristic Optimization on RNN–LSTM Network. New Gener. Comput. 2021, 39, 231–272. [Google Scholar] [CrossRef]
- Gundu, V.; Simon, S.P. PSO–LSTM for short term forecast of heterogeneous time series electricity price signals. J. Ambient Intell. Humaniz. Comput. 2021, 12, 2375–2385. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, Q.; Lv, S.-X.; Wang, L. Effective long short-term memory with fruit fly optimization algorithm for time series forecasting. Soft Comput. 2020, 24, 15059–15079. [Google Scholar] [CrossRef]
- Rashid, N.A.; Abdul Aziz, I.; Hasan, M.H.B. Machine Failure Prediction Technique Using Recurrent Neural Network Long Short-Term Memory-Particle Swarm Optimization Algorithm. In Artificial Intelligence Methods in Intelligent Algorithms; Springer: Cham, Switzerland, 2019; pp. 243–252. [Google Scholar]
- Singh, P.; Sehgal, P. G.V Black dental caries classification and preparation technique using optimal CNN-LSTM classifier. Multimed. Tools Appl. 2021, 80, 5255–5272. [Google Scholar] [CrossRef]
- Wang, T.; Liu, L.; Liu, N.; Zhang, H.; Zhang, L.; Feng, S. A multi-label text classification method via dynamic semantic representation model and deep neural network. Appl. Intell. 2020, 50, 2339–2351. [Google Scholar] [CrossRef]
- Benites, F.; Sapozhnikova, E. HARAM: A Hierarchical ARAM Neural Network for Large-Scale Text Classification. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 847–854. [Google Scholar]
- Chen, Z.; Ren, J. Multi-label text classification with latent word-wise label information. Appl. Intell. 2021, 51, 966–979. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Gholizadeh, H. A comprehensive survey: Whale Optimization Algorithm and its applications. Swarm Evol. Comput. 2019, 48, 1–24. [Google Scholar] [CrossRef]
- Shayanfar, H.; Gharehchopogh, F.S. Farmland fertility: A new metaheuristic algorithm for solving continuous optimization problems. Appl. Soft Comput. 2018, 71, 728–746. [Google Scholar] [CrossRef]
- Ghafori, S.; Gharehchopogh, F.S. Advances in spotted hyena optimizer: A comprehensive survey. Arch. Comput. Methods Eng. 2021, 1–22. [Google Scholar] [CrossRef]
- Kuang, S.; Davison, B.D. Learning class-specific word embeddings. J. Supercomput. 2020, 76, 8265–8292. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the Proceedings of ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 1944, pp. 1942–1948.
- Karaboga, D. An Idea Based on Honey Bee Swarm For Numerical Optimization; Erciyes University, Engineering Faculty, Computer Engineering Department: Kayseri, Turkey, 2005. [Google Scholar]
- Dubey, M.; Kumar, V.; Kaur, M.; Dao, T.-P. A Systematic Review on Harmony Search Algorithm: Theory, Literature, and Applications. Math. Probl. Eng. 2021, 2021, 5594267. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution—A Simple and Efficient Heuristic for global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Luo, Q.; Li, J.; Zhou, Y.; Liao, L. Using spotted hyena optimizer for training feedforward neural networks. Cogn. Syst. Res. 2021, 65, 1–16. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Words | Size of the Vocabulary | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 0 | 0 | V | |
| Social | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| media | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| are | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| interactive | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| networks | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| that | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| allow | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | . | 0 | 0 |
| the | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | . | 0 | 0 |
| creation | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | . | 0 | 0 |
| or | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | . | 0 | 0 |
| sharing | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | . | 1 | 1 |
| Datasets | Number of Total Texts | Number of Labels | Size of Total Features | Average Number of Labels per Text | Number of Train Texts | Number of Test Texts |
|---|---|---|---|---|---|---|
| RCV1-v2 | 804,414 | 103 | 47,236 | 3.24 | 723,531 | 160,883 |
| EUR-Lex | 19,348 | 3993 | 26,575 | 5.32 | 15,478 | 3870 |
| Reuters-21578 | 10,789 | 90 | 18,637 | 1.13 | 8631 | 2158 |
| Bookmarks | 87,856 | 208 | 2150 | 2.03 | 70,285 | 17,571 |
| Algorithm | Parameters | Value |
|---|---|---|
| SHO | search agents | 30 |
| control parameter () | (5,0) | |
| constant | (0.5,1) | |
| number of iterations | 200 | |
| LSTM | word embedding size | (256–512) |
| number of hidden layers | (5–20) | |
| learning rate | 0.001 | |
| batch size | 64 | |
| unit number of LSTM | 15 | |
| epochs | (1300) | |
| gate activation function | Sigmoid | |
| state activation function | tanh |
| Datasets | Models | Accuracy | Precision | Recall | F-Measure |
|---|---|---|---|---|---|
| RCV1-v2 | LSTM | 81.52 | 80.27 | 81.94 | 81.10 |
| GA-LSTM | 82.32 | 83.17 | 82.57 | 82.87 | |
| PSO-LSTM | 86.69 | 87.29 | 86.38 | 86.83 | |
| ABC-LSTM | 85.79 | 85.17 | 85.39 | 85.28 | |
| HSA-LSTM | 83.47 | 84.22 | 83.61 | 83.91 | |
| DE-LSTM | 84.61 | 84.57 | 83.72 | 84.14 | |
| SHO-LSTM | 87.65 | 89.74 | 86.24 | 87.96 | |
| EUR-Lex | LSTM | 42.86 | 42.52 | 43.68 | 43.19 |
| GA-LSTM | 42.15 | 42.37 | 42.15 | 42.26 | |
| PSO-LSTM | 42.92 | 42.65 | 42.28 | 42.46 | |
| ABC-LSTM | 43.72 | 43.96 | 42.87 | 43.41 | |
| HSA-LSTM | 43.29 | 43.58 | 43.65 | 43.61 | |
| DE-LSTM | 43.68 | 43.27 | 43.31 | 43.29 | |
| SHO-LSTM | 45.91 | 46.43 | 46.15 | 46.29 | |
| Reuters-21578 | LSTM | 62.61 | 61.19 | 61.82 | 61.50 |
| GA-LSTM | 62.95 | 62.82 | 62.42 | 62.62 | |
| PSO-LSTM | 63.68 | 63.78 | 63.27 | 63.52 | |
| ABC-LSTM | 62.78 | 62.64 | 62.19 | 62.41 | |
| HSA-LSTM | 63.12 | 63.25 | 63.08 | 63.16 | |
| DE-LSTM | 63.46 | 63.58 | 62.91 | 63.24 | |
| SHO-LSTM | 63.81 | 64.27 | 63.94 | 64.10 | |
| Bookmarks | LSTM | 40.19 | 40.48 | 41.57 | 41.02 |
| GA-LSTM | 40.58 | 40.82 | 40.63 | 40.72 | |
| PSO-LSTM | 41.85 | 41.66 | 41.20 | 41.34 | |
| ABC-LSTM | 41.56 | 41.79 | 41.17 | 41.52 | |
| HSA-LSTM | 40.23 | 40.15 | 40.02 | 40.08 | |
| DE-LSTM | 40.86 | 41.03 | 42.65 | 41.82 | |
| SHO-LSTM | 42.16 | 42.51 | 42.32 | 42.40 |
| Datasets | Models | Refs. | Precision | Recall | F-Measure |
|---|---|---|---|---|---|
| RCV1-v2 | ML-DT | [60] | 0.3961 | 0.5626 | 0.4649 |
| ML-KNN | 0.5741 | 0.5676 | 0.5708 | ||
| BR | 0.7946 | 0.6237 | 0.6989 | ||
| CC | 0.7682 | 0.6449 | 0.7012 | ||
| HARAM | 0.7756 | 0.5693 | 0.6566 | ||
| BP-MLL | 0.4385 | 0.5803 | 0.4995 | ||
| CNN-RNN | 0.8034 | 0.6465 | 0.7165 | ||
| HLSE | 0.7825 | 0.5876 | 0.6712 | ||
| SERL | 0.8015 | 0.6215 | 0.7001 | ||
| DSRM-DNN-1 | 0.8164 | 0.6413 | 0.7183 | ||
| DSRM-DNN-2 | 0.8326 | 0.6395 | 0.7234 | ||
| ML-Reasoner | [30] | 0.9120 | 0.8470 | 0.8780 | |
| ML-Reasoner-LSTM | 0.8970 | 0.8450 | 0.8700 | ||
| ML-Reasoner-BERT | 0.8900 | 0.8520 | 0.8710 | ||
| CNN-RNN | [62] | 0.8890 | 0.8250 | 0.8560 | |
| MLC-LWL | 0.9100 | 0.8540 | 0.8810 | ||
| H-AGCRNN | [39] | 0.7960 | 0.7610 | 0.7780 | |
| HAGTP-GCN | 0.8710 | 0.8090 | 0.8390 | ||
| HCSM | 0.8940 | 0.8250 | 0.8580 | ||
| SHO-LSTM | - | 0.8974 | 0.8624 | 0.8796 | |
| EUR-Lex | ML-DT | [60] | 0.1567 | 0.2254 | 0.1849 |
| ML-KNN | 0.5141 | 0.2318 | 0.3195 | ||
| BR | 0.4260 | 0.3643 | 0.3927 | ||
| CC | 0.2618 | 0.3012 | 0.2801 | ||
| HARAM | 0.4158 | 0.3271 | 0.3662 | ||
| BP-MLL | 0.2331 | 0.3063 | 0.2647 | ||
| CNN-RNN | 0.3727 | 0.3103 | 0.3387 | ||
| HLSE | 0.3854 | 0.3942 | 0.3898 | ||
| SERL | 0.4085 | 0.3853 | 0.3966 | ||
| DSRM-DNN-1 | 0.4298 | 0.3932 | 0.4109 | ||
| DSRM-DNN-2 | 0.4315 | 0.4107 | 0.4208 | ||
| SHO-LSTM | - | 46.43 | 46.15 | 46.29 | |
| Reuters-21578 | ML-DT | [60] | 0.3510 | 0.2806 | 0.3119 |
| ML-KNN | 0.3422 | 0.2056 | 0.2569 | ||
| BR | 0.4645 | 0.3507 | 0.3997 | ||
| CC | 0.4706 | 0.3613 | 0.4088 | ||
| HARAM | 0.2981 | 0.2424 | 0.2674 | ||
| BP-MLL | 0.4809 | 0.4761 | 0.4785 | ||
| CNN-RNN | 0.3697 | 0.2875 | 0.3235 | ||
| HLSE | 0.4582 | 0.3974 | 0.4256 | ||
| SERL | 0.4796 | 0.4520 | 0.4654 | ||
| DSRM-DNN-1 | 0.4913 | 0.4831 | 0.4872 | ||
| DSRM-DNN-2 | 0.6147 | 0.4785 | 0.5381 | ||
| SHO-LSTM | - | 64.27 | 63.94 | 64.10 | |
| Bookmarks | ML-DT | [60] | 0.1324 | 0.1458 | 0.1388 |
| ML-KNN | 0.2514 | 0.2780 | 0.2640 | ||
| BR | 0.1950 | 0.1880 | 0.1914 | ||
| CC | 0.1642 | 0.3104 | 0.2148 | ||
| HARAM | 0.3614 | 0.3409 | 0.3509 | ||
| BP-MLL | 0.1115 | 0.2743 | 0.1586 | ||
| CNN-RNN | 0.2257 | 0.3321 | 0.2688 | ||
| HLSE | 0.3472 | 0.3274 | 0.3370 | ||
| SERL | 0.3715 | 0.3603 | 0.3658 | ||
| DSRM-DNN-1 | 0.3841 | 0.3596 | 0.3714 | ||
| DSRM-DNN-2 | 0.4018 | 0.3702 | 0.3854 | ||
| SHO-LSTM | - | 42.51 | 42.32 | 42.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khataei Maragheh, H.; Gharehchopogh, F.S.; Majidzadeh, K.; Sangar, A.B. A New Hybrid Based on Long Short-Term Memory Network with Spotted Hyena Optimization Algorithm for Multi-Label Text Classification. Mathematics 2022, 10, 488. https://doi.org/10.3390/math10030488
Khataei Maragheh H, Gharehchopogh FS, Majidzadeh K, Sangar AB. A New Hybrid Based on Long Short-Term Memory Network with Spotted Hyena Optimization Algorithm for Multi-Label Text Classification. Mathematics. 2022; 10(3):488. https://doi.org/10.3390/math10030488
Chicago/Turabian StyleKhataei Maragheh, Hamed, Farhad Soleimanian Gharehchopogh, Kambiz Majidzadeh, and Amin Babazadeh Sangar. 2022. "A New Hybrid Based on Long Short-Term Memory Network with Spotted Hyena Optimization Algorithm for Multi-Label Text Classification" Mathematics 10, no. 3: 488. https://doi.org/10.3390/math10030488