
Predictive Modeling of Short-Term Rockburst for the Stability of Subsurface Structures Using Machine Learning Approaches: t-SNE, K-Means Clustering and XGBoost



Abstract
:1. Introduction
2. Significance of the Study
- (1)
- To begin, a cutting-edge data depletion process called t-distributed stochastic neighbor embedding (t-SNE) was developed to lessen the magnification of original rockburst database;
- (2)
- Second, an unsupervised machine learning, namely K-means clustering, was used to classify the t-SNE dataset in order to reduce the inconsequential spectral dissimilarity effect in homogeneous localities;
- (3)
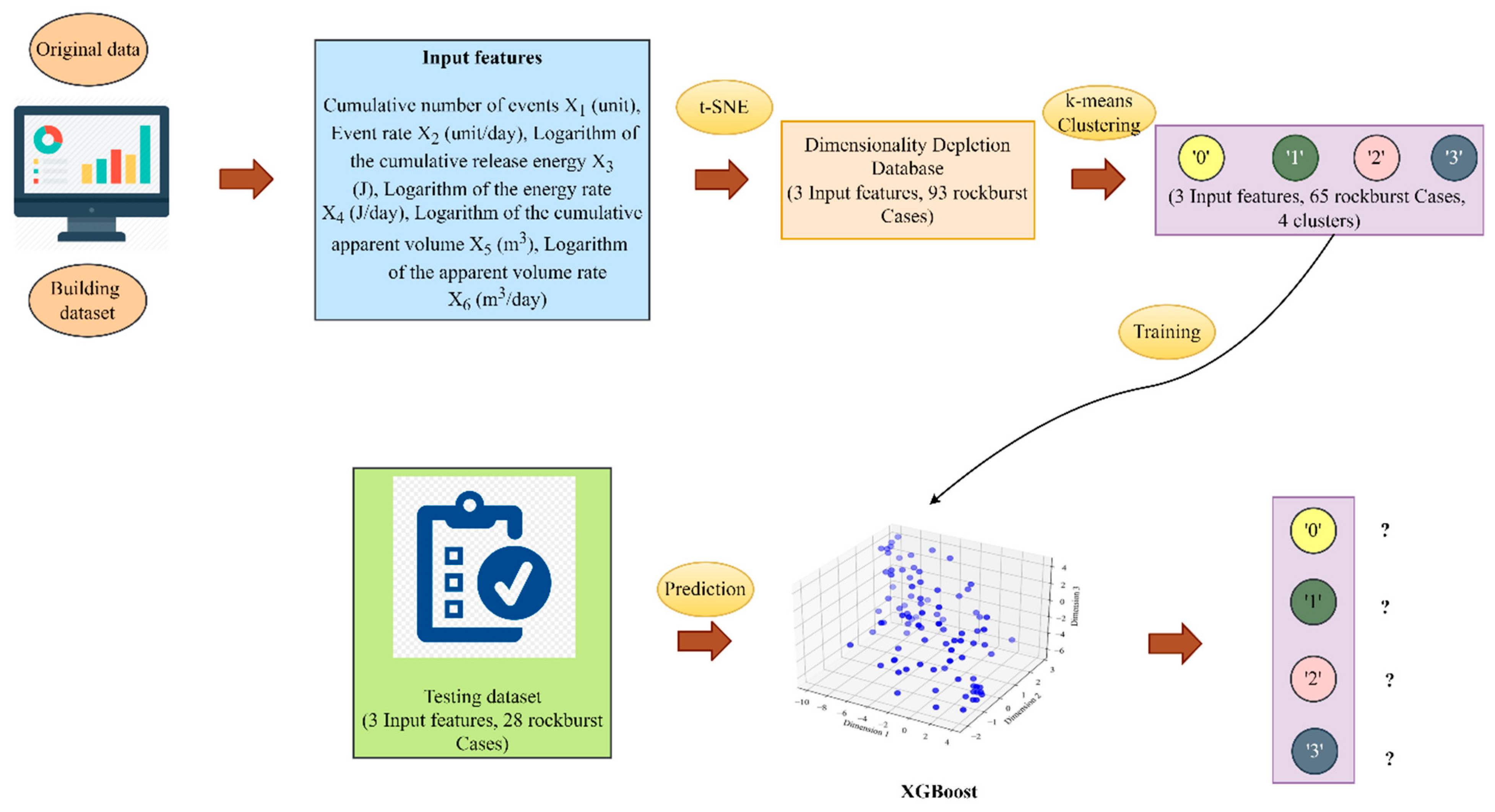
- Finally, XGBoost, a supervised gradient boosting machine learning algorithm, has been developed to forecast various levels of short-term rockburst database. Figure 1 depicts a flowchart of this work.
3. Material and Methods
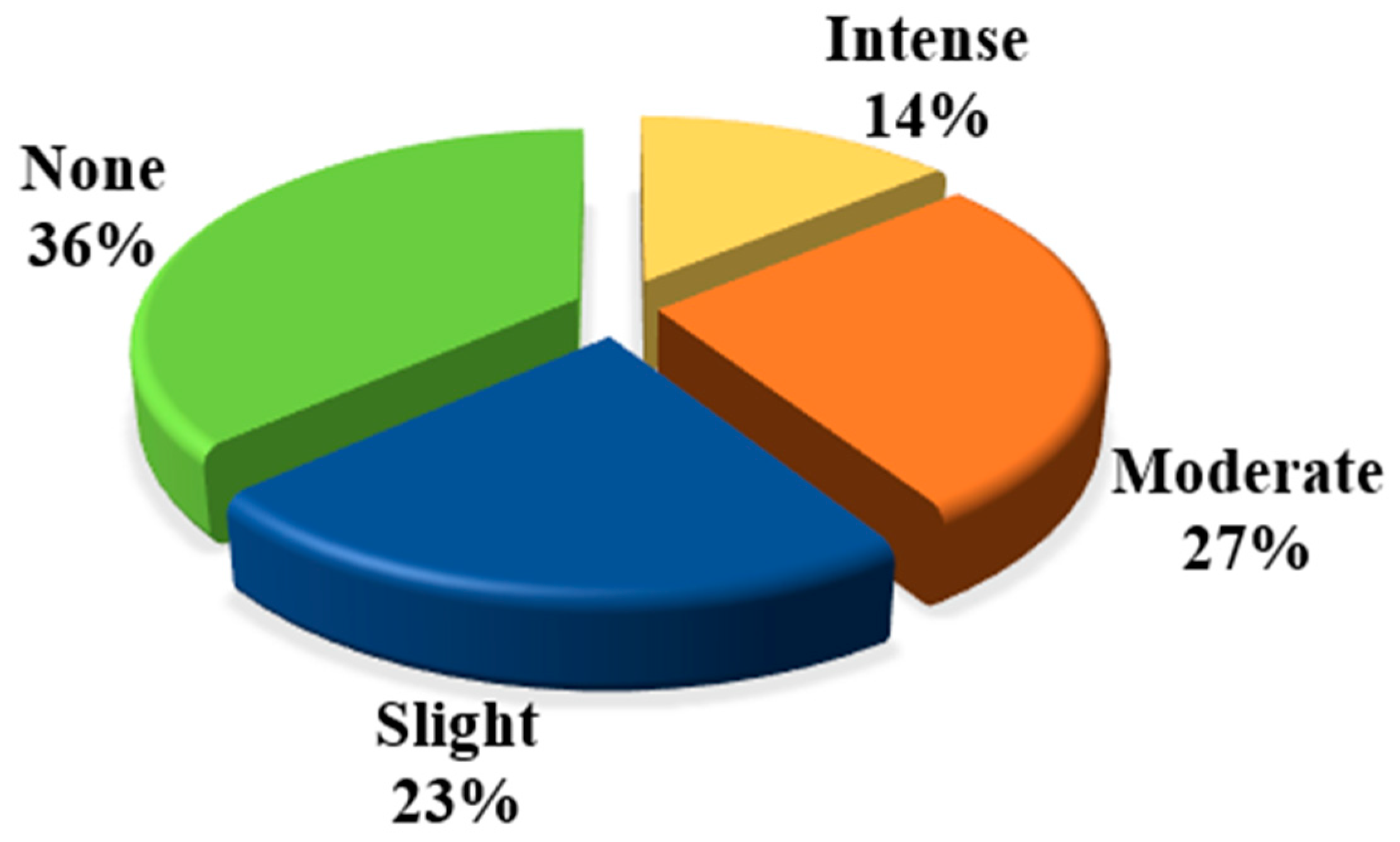
3.1. Data Acquisition
3.2. SNE Based t-SNE Algorithm
3.3. K-Means Clustering
3.4. Extreme Gradient Boosting (XGBoost)
3.5. Hyperparameter Tunning
| Algorithm 1: 5-folds XGBoost cross validation | |
| Input | I(t), I(t1) ∈ I(t): Initial Dataset Extreme Gradient Boosting (XGBoost): Decision Algorithm L: Loss Function 5: Fold Number |
| Step 1 | U1 ⊕ U2 ⊕ ….. T U1 + U2 + ….. T ⇔ Ui ∩ ….. |
| Step 2 | for I from 1 to 10 do |
| Step 3 | Fi = XGBoost(T/Ui) |
| Step 4 | for S(Ai) in Ui do |
| Step 5 | ej = L(Fi, S(Ai) |
| Step 6 | End for |
| Step 7 | End for |
| Step 8 | Returne |
3.6. Grid Search CV
4. Result and Discussion
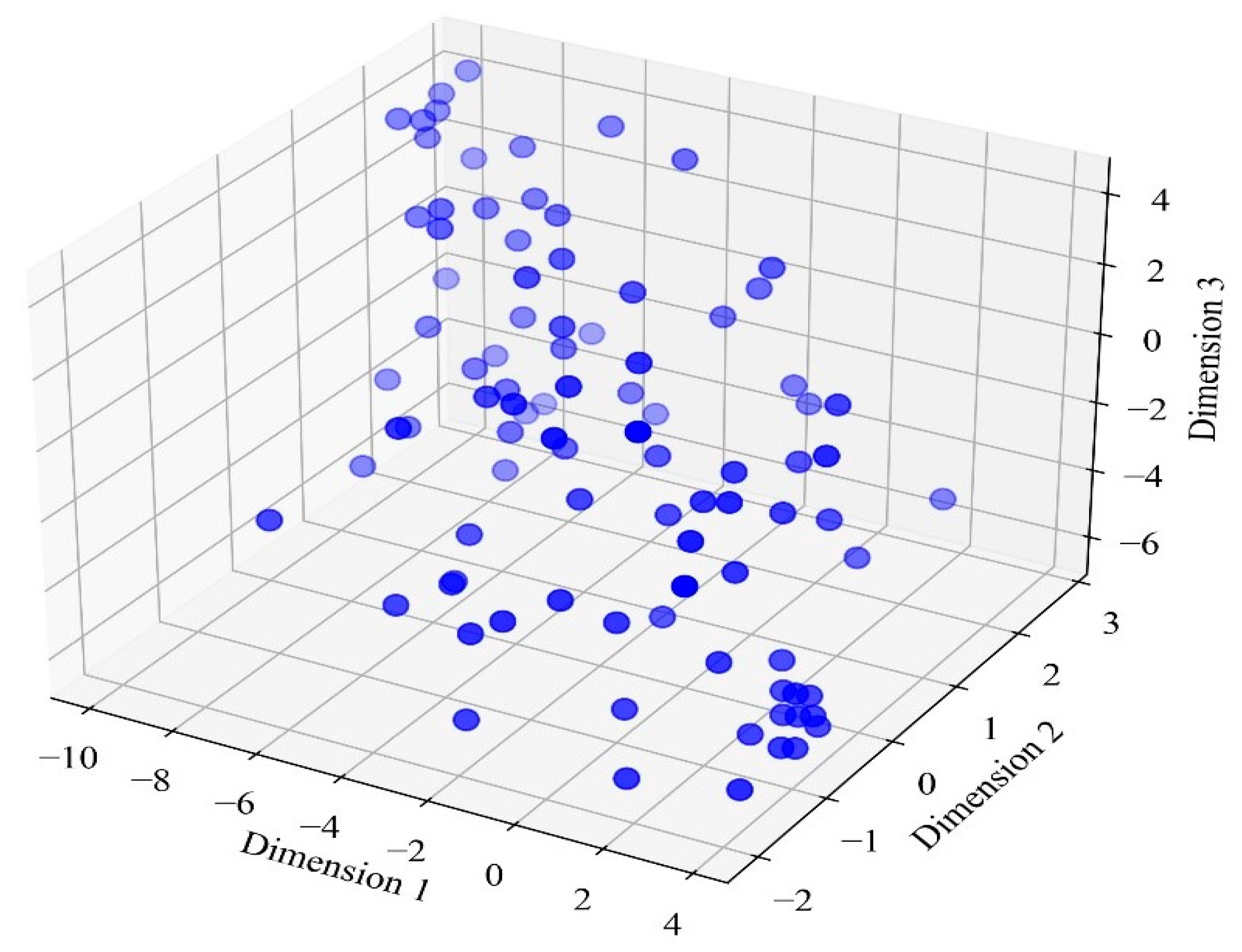
4.1. Rockburst Database Reduction Using t-SNE
- Stage 1: Get data S = , , , …, in high dimension region, and give the dimensionality reduction consequences as , , , …, ;
- Stage 2: Compute perplexity, and assign iteration times , momentum of and learning rate ;
- Stage 3: Calculate as given in Equation (1);
- Stage 4: Estimate as depicted in Equation (7);
- Stage 5: Arbitrarily choose with ;
- Stage 6: Compute as stated in Equation (7), estimate the gradient as stated in Equation (9);
- Stage 7: Finally repeat the stage 6 so that the iteration number is remarkable than .
4.2. K-Means Clustering on t-SNE Based Rockburst Database
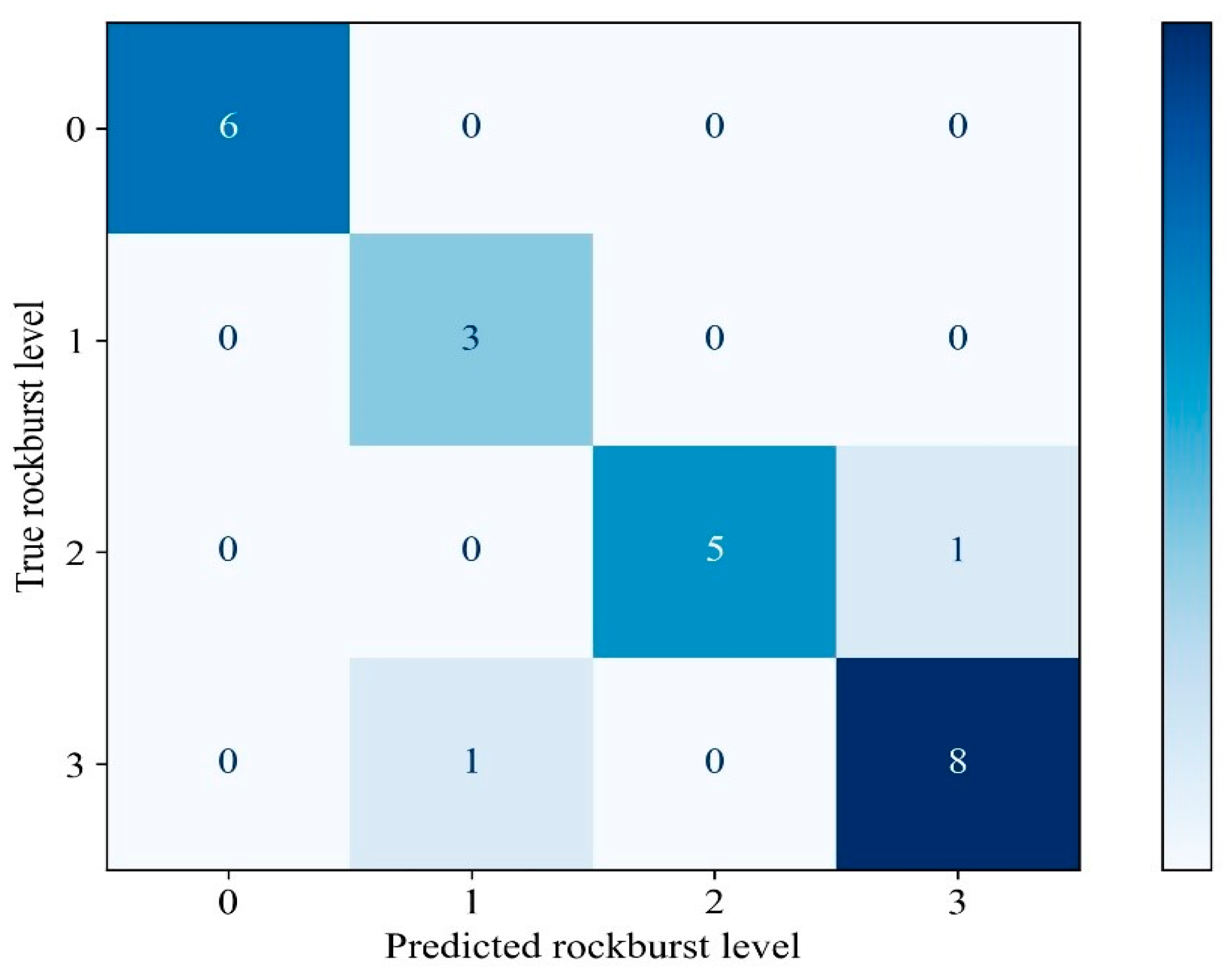
4.3. Extreme Gradient Boosting (XGBoost) Prediction Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, H.; Chen, B.; Zhu, C. Decision Tree Model for Rockburst Prediction Based on Microseismic Monitoring. Adv. Civ. Eng. 2021, 2021, 8818052. [Google Scholar] [CrossRef]
- Feng, X.-T.; Yashun, X.; Guangliang, F. Mechanism, warning and dynamic control of rockburst evolution process. In Proceedings of the ISRM Regional Symposium—7th Asian Rock Mechanics Symposium, Seoul, Korea, 15–19 October 2012. [Google Scholar]
- Sun, Y.; Li, G.; Zhang, J.; Huang, J. Rockburst Intensity Evaluation by a Novel Systematic and Evolved Approach: Machine Learning Booster and Application. Bull. Eng. Geol. Environ. 2021, 80, 8385–8395. [Google Scholar] [CrossRef]
- Cai, M. Principles of Rock Support in Burst-Prone Ground. Tunn. Undergr. Space Technol. 2013, 36, 46–56. [Google Scholar] [CrossRef]
- Cai, X.; Cheng, C.; Zhou, Z.; Konietzky, H.; Song, Z.; Wang, S. Rock Mass Watering for Rock-Burst Prevention: Some Thoughts on the Mechanisms Deduced from Laboratory Results. Bull. Eng. Geol. Environ. 2021, 80, 8725–8743. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Liu, V.; Mitri, H. Machine Learning Methods for Rockburst Prediction-State-of-the-Art Review. Int. J. Min. Sci. Technol. 2019, 29, 565–570. [Google Scholar] [CrossRef]
- Mark, C. Coal Bursts in the Deep Longwall Mines of the United States. Int. J. Coal Sci. Technol. 2016, 3, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Pu, Y.; Apel, D.B.; Wei, C. Applying Machine Learning Approaches to Evaluating Rockburst Liability: A Comparation of Generative and Discriminative Models. Pure Appl. Geophys. 2019, 176, 4503–4517. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, F.; Yang, J.; Bai, W.; Zhang, L. Rockburst Mechanism in Soft Coal Seam within Deep Coal Mines. Int. J. Min. Sci. Technol. 2017, 27, 551–556. [Google Scholar] [CrossRef]
- Zhou, Z.; Cai, X.; Li, X.; Cao, W.; Du, X. Dynamic Response and Energy Evolution of Sandstone Under Coupled Static–Dynamic Compression: Insights from Experimental Study into Deep Rock Engineering Applications. Rock Mech. Rock Eng. 2020, 53, 1305–1331. [Google Scholar] [CrossRef]
- Wang, S.; Tang, Y.; Wang, S. yong Influence of Brittleness and Confining Stress on Rock Cuttability Based on Rock Indentation Tests. J. Cent. South Univ. 2021, 28, 2786–2800. [Google Scholar] [CrossRef]
- Wang, S.; Tang, Y.; Li, X.; Du, K. Analyses and Predictions of Rock Cuttabilities under Different Confining Stresses and Rock Properties Based on Rock Indentation Tests by Conical Pick. Trans. Nonferrous Met. Soc. China (Engl. Ed.) 2021, 31, 1766–1783. [Google Scholar] [CrossRef]
- Li, X.; Gong, F.; Tao, M.; Dong, L.; Du, K.; Ma, C.; Zhou, Z.; Yin, T. Failure Mechanism and Coupled Static-Dynamic Loading Theory in Deep Hard Rock Mining: A Review. J. Rock Mech. Geotech. Eng. 2017, 9, 767–782. [Google Scholar] [CrossRef]
- Lu, C.P.; Dou, L.M.; Liu, B.; Xie, Y.S.; Liu, H.S. Microseismic Low-Frequency Precursor Effect of Bursting Failure of Coal and Rock. J. Appl. Geophys. 2012, 79, 55–63. [Google Scholar] [CrossRef]
- Liu, J.P.; Feng, X.T.; Li, Y.H.; da Xu, S.; Sheng, Y. Studies on Temporal and Spatial Variation of Microseismic Activities in a Deep Metal Mine. Int. J. Rock Mech. Min. Sci. 2013, 60, 171–179. [Google Scholar] [CrossRef]
- Srinivasan, C.; Aroras, S.K.; Yajq, R.K. Use of Mining and Seismological Parameters as Premonitors of Rockbursts. Int. J. Rock Mech. Min. Sci. 1997, 34, 1001–1008. [Google Scholar] [CrossRef]
- Ma, X.; Westman, E.; Slaker, B.; Thibodeau, D.; Counter, D. The B-Value Evolution of Mining-Induced Seismicity and Mainshock Occurrences at Hard-Rock Mines. Int. J. Rock Mech. Min. Sci. 2018, 104, 64–70. [Google Scholar] [CrossRef]
- Ma, T.H.; Tang, C.A.; Tang, S.; Kuang, L.; Yu, Q.; Kong, D.Q.; Zhu, X. Rockburst Mechanism and Prediction Based on Microseismic Monitoring. Int. J. Rock Mech. Min. Sci. 2018, 110, 177–188. [Google Scholar] [CrossRef]
- Kidybiiqski, A. Bursting Liability Indices of Coal. Int. J. Rock Mech. Min. Sci. Geomech. Abstr. 1981, 18, 295–304. [Google Scholar] [CrossRef]
- Wattimena, R.K.; Sirait, B.; Widodo, N.P.; Matsui, K. Evaluation of Rockburst Potential in a Cut-and-Fill Mine Using Energy Balance. Int. J. JCRM 2012, 8, 19–23. [Google Scholar]
- Altindag, R. Correlation of Specific Energy with Rock Brittleness Concepts on Rock Cutting. J. S. Afr. Inst. Min. Metall. 2003, 103, 163–171. [Google Scholar]
- Wang, J.-A.; Park, H.D. Comprehensive Prediction of Rockburst Based on Analysis of Strain Energy in Rocks. Tunn. Undergr. Space Technol. 2001, 16, 49–57. [Google Scholar] [CrossRef]
- Cai, M. Prediction and Prevention of Rockburst in Metal Mines—A Case Study of Sanshandao Gold Mine. J. Rock Mech. Geotech. Eng. 2016, 8, 204–211. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Xu, H. Rockburst Prediction in Kimberlite with Unsupervised Learning Method and Support Vector Classifier. Tunn. Undergr. Space Technol. 2019, 90, 12–18. [Google Scholar] [CrossRef]
- Wojtecki, Ł.; Iwaszenko, S.; Apel, D.B.; Cichy, T. An Attempt to Use Machine Learning Algorithms to Estimate the Rockburst Hazard in Underground Excavations of Hard Coal Mine. Energies 2021, 14, 6928. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, B.; Zhang, Q. Data-Driven Model for Rockburst Prediction. Math. Probl. Eng. 2020, 2020, 5735496. [Google Scholar] [CrossRef]
- Afraei, S.; Shahriar, K.; Madani, S.H. Developing Intelligent Classification Models for Rock Burst Prediction after Recognizing Significant Predictor Variables, Section 2: Designing Classifiers. Tunn. Undergr. Space Technol. 2019, 84, 522–537. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Shi, X. Long-Term Prediction Model of Rockburst in Underground Openings Using Heuristic Algorithms and Support Vector Machines. Saf. Sci. 2012, 50, 629–644. [Google Scholar] [CrossRef]
- Xue, Y.; Bai, C.; Qiu, D.; Kong, F.; Li, Z. Predicting Rockburst with Database Using Particle Swarm Optimization and Extreme Learning Machine. Tunn. Undergr. Space Technol. 2020, 98, 103287. [Google Scholar] [CrossRef]
- Li, Y.; Wang, C.; Xu, J.; Zhou, Z.; Xu, J.; Cheng, J. Rockburst Prediction Based on the KPCA-APSO-SVM Model and Its Engineering Application. Shock Vib. 2021, 2021, 7968730. [Google Scholar] [CrossRef]
- Guo, D.; Chen, H.; Tang, L.; Chen, Z.; Samui, P. Assessment of Rockburst Risk Using Multivariate Adaptive Regression Splines and Deep Forest Model. Acta Geotech. 2021, 1–23. [Google Scholar] [CrossRef]
- Zhou, J.; Li, X.; Mitri, H.S. Classification of Rockburst in Underground Projects: Comparison of Ten Supervised Learning Methods. J. Comput. Civ. Eng. 2016, 30, 04016003. [Google Scholar] [CrossRef]
- Ghasemi, E.; Gholizadeh, H.; Adoko, A.C. Evaluation of Rockburst Occurrence and Intensity in Underground Structures Using Decision Tree Approach. Eng. Comput. 2020, 36, 213–225. [Google Scholar] [CrossRef]
- Wang, Y. Prediction of Rockburst Risk in Coal Mines Based on a Locally Weighted C4.5 Algorithm. IEEE Access 2021, 9, 15149–15155. [Google Scholar] [CrossRef]
- Ahmad, M.; Hu, J.L.; Hadzima-Nyarko, M.; Ahmad, F.; Tang, X.W.; Rahman, Z.U.; Nawaz, A.; Abrar, M. Rockburst Hazard Prediction in Underground Projects Using Two Intelligent Classification Techniques: A Comparative Study. Symmetry 2021, 13, 632. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, J.; Li, C.; Armaghani, D.J.; Li, X.; Mitri, H.S. Rockburst Prediction in Hard Rock Mines Developing Bagging and Boosting Tree-Based Ensemble Techniques. J. Cent. South Univ. 2021, 28, 527–542. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Wang, C.; Wilson, B. Evaluation of Burst Liability in Kimberlite Using Support Vector Machine. Acta Geophys. 2018, 66, 973–982. [Google Scholar] [CrossRef]
- Liang, W.; Sari, A.; Zhao, G.; McKinnon, S.D.; Wu, H. Short-Term Rockburst Risk Prediction Using Ensemble Learning Methods. Nat. Hazards 2020, 104, 1923–1946. [Google Scholar] [CrossRef]
- Zhou, J.; Shi, X.Z.; Huang, R.D.; Qiu, X.Y.; Chen, C. Feasibility of Stochastic Gradient Boosting Approach for Predicting Rockburst Damage in Burst-Prone Mines. Trans. Nonferrous Met. Soc. China (Engl. Ed.) 2016, 26, 1938–1945. [Google Scholar] [CrossRef]
- Feng, G.; Xia, G.; Chen, B.; Xiao, Y.; Zhou, R. A Method for Rockburst Prediction in the Deep Tunnels of Hydropower Stations Based on the Monitored Microseismicity and an Optimized Probabilistic Neural Network Model. Sustainability 2019, 11, 3212. [Google Scholar] [CrossRef] [Green Version]
- Ji, B.; Xie, F.; Wang, X.; He, S.; Song, D. Investigate Contribution of Multi-Microseismic Data to Rockburst Risk Prediction Using Support Vector Machine with Genetic Algorithm. IEEE Access 2020, 8, 58817–58828. [Google Scholar] [CrossRef]
- Li, N.; Jimenez, R. A Logistic Regression Classifier for Long-Term Probabilistic Prediction of Rock Burst Hazard. Nat. Hazards 2018, 90, 197–215. [Google Scholar] [CrossRef]
- Afraei, S.; Shahriar, K.; Madani, S.H. Statistical Assessment of Rock Burst Potential and Contributions of Considered Predictor Variables in the Task. Tunn. Undergr. Space Technol. 2018, 72, 250–271. [Google Scholar] [CrossRef]
- Faradonbeh, R.S.; Taheri, A. Long-Term Prediction of Rockburst Hazard in Deep Underground Openings Using Three Robust Data Mining Techniques. Eng. Comput. 2019, 35, 659–675. [Google Scholar] [CrossRef]
- Pu, Y.; Apel, D.B.; Lingga, B. Rockburst Prediction in Kimberlite Using Decision Tree with Incomplete Data. J. Sustain. Min. 2018, 17, 158–165. [Google Scholar] [CrossRef]
- Adoko, A.C.; Gokceoglu, C.; Wu, L.; Zuo, Q.J. Knowledge-Based and Data-Driven Fuzzy Modeling for Rockburst Prediction. Int. J. Rock Mech. Min. Sci. 2013, 61, 86–95. [Google Scholar] [CrossRef]
- Feng, X.T.; Chen, B.R.; Zhang, C.Q.; Li, S.J.; Wu, S.Y. Mechanism, Warning and Dynamic Control of Rockburst Development Processes; Science Press: Beijing, China, 2013. (In Chinese) [Google Scholar]
- Hinton, G.; Roweis, S. Stochastic Neighbor Embedding; Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2002; pp. 833–840. [Google Scholar]
- Liu, H.; Yang, J.; Ye, M.; James, S.C.; Tang, Z.; Dong, J.; Xing, T. Using T-Distributed Stochastic Neighbor Embedding (t-SNE) for Cluster Analysis and Spatial Zone Delineation of Groundwater Geochemistry Data. J. Hydrol. 2021, 597, 126146. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Zhu, X.; Jin, X.; Jia, D.; Sun, N.; Wang, P. Application of Data Mining in an Intelligent Early Warning System for Rock Bursts. Processes 2019, 7, 55. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Song, J. GDILC: A Grid-Based Density-Isoline Clustering Algorithm. In Proceedings of the 2001 International Conferences on Info-Tech and Info-Net. Proceedings (Cat. No.01EX479), Beijing, China, 29 October–1 November 2001. [Google Scholar]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The Global K-Means Clustering Algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Schapire, R.E. The Boosting Approach to Machine Learning: An Overview. In Nonlinear Estimation and Classification. Lecture Notes in Statistics; Denison, D.D., Hansen, M.H., Holmes, C.C., Mallick, B., Yu, B., Eds.; Springer: New York, NY, USA, 2003; Volume 171. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A Working Guide to Boosted Regression Trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic Gradient Boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. Available online: http://www.elsevier.com/locate/csda (accessed on 25 November 2021). [CrossRef]
- Wang, Z.; Monteiro, C.D.; Jagodnik, K.M.; Fernandez, N.F.; Gundersen, G.W.; Rouillard, A.D.; Jenkins, S.L.; Feldmann, A.S.; Hu, K.S.; McDermott, M.G.; et al. Extraction and Analysis of Signatures from the Gene Expression Omnibus by the Crowd. Nat. Commun. 2016, 7, 12846. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choubineh, A.; Helalizadeh, A.; Wood, D.A. Estimation of Minimum Miscibility Pressure of Varied Gas Compositions and Reservoir Crude Oil over a Wide Range of Conditions Using an Artificial Neural Network Model. Adv. Geo-Energy Res. 2019, 3, 52–66. [Google Scholar] [CrossRef]
- Bergstra, J.; Ca, J.B.; Ca, Y.B. Random Search for Hyper-Parameter Optimization Yoshua Bengio. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Kamran, M. A State of the Art Catboost-Based T-Distributed Stochastic Neighbor Embedding Technique to Predict Back-Break at Dewan Cement Limestone Quarry. J. Min. Environ. JME 2021, 12, 679–691. [Google Scholar] [CrossRef]
- van Der Maaten, L.; Hinton, G. Visualizing Data Using T-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Shi, N.; Liu, X.; Guan, Y. Research on K-Means Clustering Algorithm: An Improved k-Means Clustering Algorithm. In Proceedings of the 3rd International Symposium on Intelligent Information Technology and Security Informatics (IITSI 2010), Jian, China, 2–4 April 2010; pp. 63–67. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.W.; Gil, J.M. Research Paper Classification Systems Based on TF-IDF and LDA Schemes. Hum.-Cent. Comput. Inf. Sci. 2019, 9, 30. [Google Scholar] [CrossRef]
- Sarno Riyanarto, G.H.; Pamungkas, E.W.; Sunaryono, D. Clustering of ERP Business Process Fragments. In Proceedings of the 2013 International Conference on Computer, Control, Informatics and Its Applications (IC3INA), Jakarta, Indonesia, 19–21 November 2013. [Google Scholar]
- Rani Usha, S.S. Comparison of Clustering Techniques for Measuring Similarity in Articles. In Proceedings of the 3rd IEEE International Conference on Computational Intelligence and Communication Technology, Ghaziabad, India, 9–10 February 2017. [Google Scholar]
- Ma, Y.; Peng, M.; Xue, W.; Ji, X. A Dynamic Affinity Propagation Clustering Algorithm for Cell Outage Detection in Self-Healing Networks. In Proceedings of the 2013 IEEE Wireless Communications and Networking Conference (WCNC), Shanghai, China, 7–10 April 2013; pp. 2266–2270. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.No | References | Machine Learning Models | Dataset Size | Year |
|---|---|---|---|---|
| 1 | Zhou et al. [32] | KNN | 246 | 2016 |
| 2 | Li et al. [42] | LR | 135 | 2017 |
| 3 | Afraei et al. [43] | LR | 188 | 2018 |
| 4 | Faradonbeh et al. [44] | DT | 134 | 2019 |
| 5 | Pu et al. [45] | DT | 132 | 2018 |
| 6 | Ghasemi et al. [33] | DT | 174 | 2020 |
| 7 | Faradonbeh et al. [44] | ANN | 134 | 2019 |
| 8 | Adoko et al. [46] | ANFIS | 174 | 2013 |
| 9 | Zhou et al. [32] | SVM | 246 | 2016 |
| 10 | Guo et al. [31] | MARS | 344 | 2021 |
| Descriptive Statistics | Cumulative Number of Events (Unit) | Event Rate (Unit/Day) | Logarithm of the Cumulative Release Energy (J) | Logarithm of the Energy Rate (J/Day) | Logarithm of the Cumulative Apparent Volume (m3) | Logarithm of the Apparent Volume Rate (m3/Day) |
|---|---|---|---|---|---|---|
| Mean | 13.011 | 1.735 | 4.389 | 3.562 | 4.150 | 3.334 |
| Standard deviation | 13.690 | 1.738 | 1.441 | 1.332 | 0.660 | 0.558 |
| Minimum | 1 | 0.111 | 0.780 | 0.178 | 2.511 | 1.666 |
| Maximum | 70 | 12.250 | 7.094 | 5.890 | 5.168 | 4.393 |
| Samples | Dimension 1 | Dimension 2 | Dimension 3 |
|---|---|---|---|
| 1 | −9.1895 | 1.876923 | 3.533078 |
| 2 | −5.25797 | 1.386265 | 2.998773 |
| 3 | −6.33402 | 0.83398 | −0.95647 |
| 4 | −6.6661 | 1.667999 | 1.523691 |
| 5 | −3.36939 | 0.296317 | 1.838995 |
| ….. | ….. | ….. | |
| 88 | −8.27044 | 1.192174 | 2.389334 |
| 89 | −8.87826 | 1.073105 | −2.3535 |
| 91 | −2.44182 | −0.94443 | 1.698488 |
| 92 | −5.97327 | 1.043975 | −4.14844 |
| 93 | −0.7725 | −1.40264 | 1.910676 |
| Class | XGBoost Model | ||
|---|---|---|---|
| Precision % | Recall % | f1-Score % | |
| No rockburst | 100 | 86 | 92 |
| Slight rockburst | 60 | 100 | 75 |
| Moderate rockburst | 100 | 83 | 91 |
| Violent rockburst | 88 | 88 | 88 |
| Accuracy | 88 | ||
| macro avg | 87 | 89 | 66 |
| Weighted avg | 91 | 88 | 88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, B.; Kamran, M.; Rui, Y. Predictive Modeling of Short-Term Rockburst for the Stability of Subsurface Structures Using Machine Learning Approaches: t-SNE, K-Means Clustering and XGBoost. Mathematics 2022, 10, 449. https://doi.org/10.3390/math10030449
Ullah B, Kamran M, Rui Y. Predictive Modeling of Short-Term Rockburst for the Stability of Subsurface Structures Using Machine Learning Approaches: t-SNE, K-Means Clustering and XGBoost. Mathematics. 2022; 10(3):449. https://doi.org/10.3390/math10030449
Chicago/Turabian StyleUllah, Barkat, Muhammad Kamran, and Yichao Rui. 2022. "Predictive Modeling of Short-Term Rockburst for the Stability of Subsurface Structures Using Machine Learning Approaches: t-SNE, K-Means Clustering and XGBoost" Mathematics 10, no. 3: 449. https://doi.org/10.3390/math10030449