
Dynamic ILC for Linear Repetitive Processes Based on Different Relative Degrees


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Problem Description
- (1)
- if and the row is full of rank, then ;
- (2)
- if the system meets the following conditions:
- (a)
- for all , there are and ;
- (b)
- and the row is full of rank.
3. Iterative Learning Control for Linear Repetitive Processes
4. Design of a Dynamic Iterative Learning Control System
4.1. Zero Relativity ()
4.2. Higher Order Relativity ()
| Algorithm 1 Linear repetitive process dynamic ILC law calculation |
|
| Algorithm 2 Dynamic ILC for linear repetitive process algorithm |
|
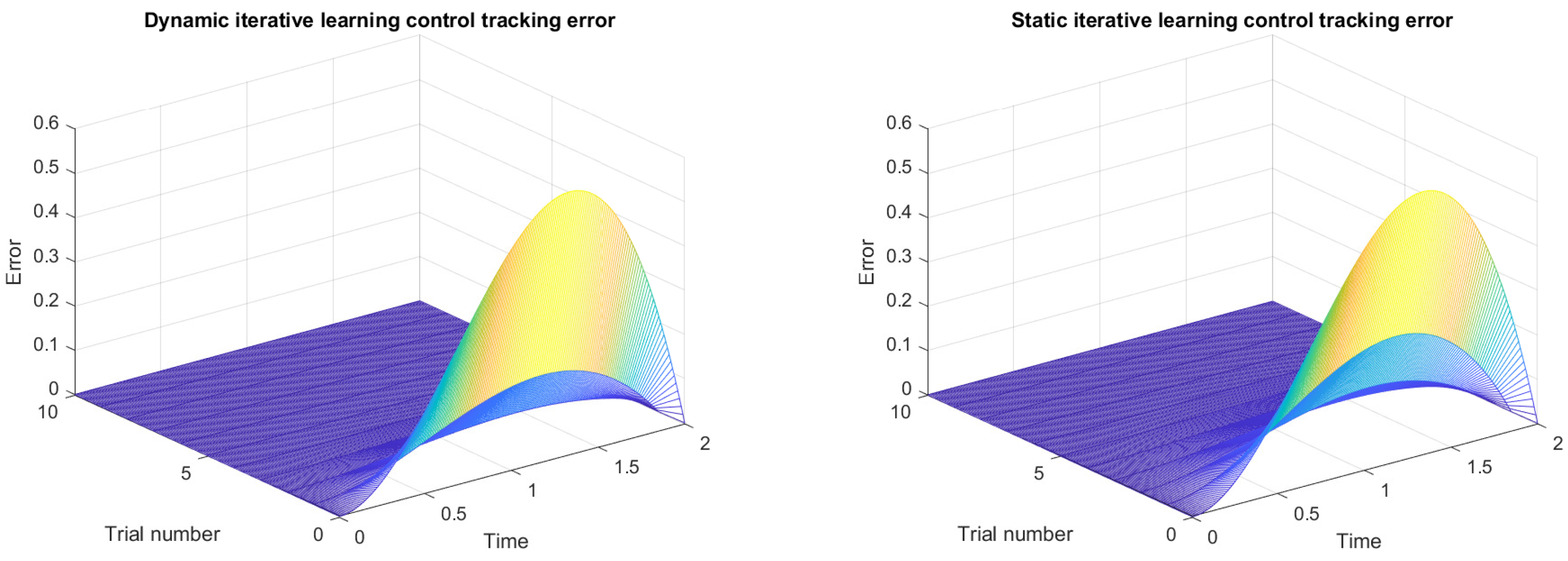
5. Simulation Results
5.1. Condition 1: Relativity
5.2. Condition 2: Relativity
5.3. Condition 3: Relativity
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Chu, B.; Freeman, C.T. Iterative Learning Control for Robotic Path Following With Trial-Varying Motion Profiles. IEEE/ASME Trans. Mechatron. 2022, 27, 4697–4706. [Google Scholar] [CrossRef]
- Yan, Q.; Cai, J.; Ma, Y.; Yu, Y. Robust Learning Control for Robot Manipulators with Random Initial Errors and Iteration-Varying Reference Trajectories. IEEE Access 2019, 7, 32628–32643. [Google Scholar] [CrossRef]
- Bouakrif, F. Iterative learning control for MIMO nonlinear systems with arbitrary relative degree and no states measurement. Complexity 2013, 19, 37–45. [Google Scholar] [CrossRef]
- Fu, Q.; Du, L.; Xu, G.; Wu, J.; Yu, P. PD-type iterative learning control for linear continuous systems with arbitrary relative degree. Trans. Inst. Meas. Control 2018, 41, 2555–2562. [Google Scholar] [CrossRef]
- Cao, W.; Sun, M. Iterative learning based fault diagnosis for discrete linear uncertain systems. J. Syst. Eng. Electron. 2014, 25, 496–501. [Google Scholar] [CrossRef]
- Li, Z.; Hu, Y.; Li, D. Robust design of feedback feed-forward iterative learning control based on 2D system theory for linear uncertain systems. Int. J. Syst. Sci. 2015, 47, 2620–2631. [Google Scholar] [CrossRef]
- Wang, X.; Wang, J.; Shen, D.; Zhou, Y. Convergence analysis for iterative learning control of conformable fractional differential equations. Math. Methods Appl. Sci. 2018, 41, 8315–8328. [Google Scholar] [CrossRef]
- Tao, H.; Paszke, W.; Rogers, E.; Yang, H.; Gałkowski, K. Finite frequency range iterative learning fault-tolerant control for discrete time-delay uncertain systems with actuator faults. ISA Trans. 2019, 95, 152–163. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Chu, B.; Freeman, C.T.; Liu, Y. Generalized iterative learning control with mixed system constraints: A gantry robot based verification. Control Eng. Pract. 2020, 95, 104260. [Google Scholar] [CrossRef]
- Pakshin, P.V.; Emelianova, J.P.; Emelianov, M.A. Iterative Learning Control Design for Multiagent Systems Based on 2D Models. Autom. Remote Control 2018, 79, 1040–1056. [Google Scholar] [CrossRef]
- Wang, L.; Dong, W. Optimal Iterative Learning Fault-Tolerant Guaranteed Cost Control for Batch Processes in the 2D-FM Model. Abstr. Appl. D 2012, 2012, 748981. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Yu, J.; Wang, L. 2D Terminal Constrained Model Predictive Iterative Learning Control of Batch Processes With Time Delay. IEEE Access 2019, 7, 126842–126856. [Google Scholar] [CrossRef]
- Wang, L.; Yu, J.; Li, P.; Li, H.; Zhang, R. A 2D-FM model-based robust iterative learning model predictive control for batch processes. ISA Trans. 2021, 110, 271–282. [Google Scholar] [CrossRef] [PubMed]
- Yu, M.; Chai, S. Adaptive iterative learning control for discrete-time nonlinear systems with multiple iteration-varying high-order internal models. Int. J. Robust Nonlinear Control 2021, 31, 7390–7408. [Google Scholar] [CrossRef]
- Yu, M.; Chai, S. A Survey on High-Order Internal Model Based Iterative Learning Control. IEEE Access 2019, 7, 127024–127031. [Google Scholar] [CrossRef]
- Zou, W.; Shen, Y.; Paszke, W.; Tao, H. Robust feedback feed-forward PD-type iterative learning control for uncertain discrete systems over finite frequency ranges. Trans. Inst. Meas. Control 2022, 44, 2850–2862. [Google Scholar] [CrossRef]
- Asl, R.M.; Madady, A. Stabilization of two-dimensional mixed continuous-discrete-time systems via dynamic output feedback with application to iterative learning control design. Trans. Inst. Meas. Control 2021, 44, 172–187. [Google Scholar] [CrossRef]
- Wei, Y.S.; Li, X.D. Iterative learning control for linear discrete-time systems with high relative degree under initial state vibration. IET Control Theory Ampmathsemicolon Appl. 2016, 10, 1115–1126. [Google Scholar] [CrossRef]
- Liu, Y.; Ruan, X.; Li, X. Optimized Iterative Learning Control for Linear Discrete-Time-Invariant Systems. IEEE Access 2019, 7, 75378–75388. [Google Scholar] [CrossRef]
- Hladowski, L.; Galkowski, K.; Rogers, E. Dynamic Output-Only Iterative Learning Control Design. IEEE Access 2021, 9, 147072–147081. [Google Scholar] [CrossRef]
- Li, X.; Xu, J.X.; Huang, D. Iterative learning control for nonlinear dynamic systems with randomly varying trial lengths. Int. J. Adapt. Control Signal Process. 2015, 29, 1341–1353. [Google Scholar] [CrossRef]
- Wu, S.; Zhang, R. A two-dimensional design of model predictive control for batch processes with two-dimensional (2D) dynamics using extended non-minimal state space structure. J. Process. Control 2019, 81, 172–189. [Google Scholar] [CrossRef]
- Wan, K.; Wei, Y.S. Adaptive ILC of Tracking Nonrepetitive Trajectory for Two-dimensional Nonlinear Discrete Time-varying Fornasini-Marchesini Systems with Iteration-varying Boundary States. Int. J. Control Autom. Syst. 2020, 19, 417–425. [Google Scholar] [CrossRef]
- Li, X. Robot target localization and interactive multi-mode motion trajectory tracking based on adaptive iterative learning. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 6271–6282. [Google Scholar] [CrossRef]
- Zhao, X.; Geng, Y.; Yuan, C.; Wu, B. An Unscented Kalman Filter–based iterative learning controller for multibody rotating scan optical spacecraft. Trans. Inst. Meas. Control 2022, 44, 2418–2433. [Google Scholar] [CrossRef]
- Bifaretti, S.; Tomei, P.; Verrelli, C.M. A global robust iterative learning position control for current-fed permanent magnet step motors. Automatica 2011, 47, 227–234. [Google Scholar] [CrossRef]
- Hao, S.; Liu, T.; Paszke, W.; Galkowski, K. Robust iterative learning control for batch processes with input delay subject to time-varying uncertainties. IET Control Theory Ampmathsemicolon Appl. 2016, 10, 1904–1915. [Google Scholar] [CrossRef]
- Wang, L.; Shen, Y.; Yu, J.; Li, P.; Zhang, R.; Gao, F. Robust iterative learning control for multi-phase batch processes: An average dwell-time method with 2D convergence indexes. Int. J. Syst. Sci. 2017, 49, 324–343. [Google Scholar] [CrossRef]
- Hladowski, L.; Galkowski, K.; Rogers, E. Further results on dynamic iterative learning control law design using repetitive process stability theory. In Proceedings of the 2017 Tenth International Workshop on Multidimensional (nD) Systems (nDS), Zielona Góra, Poland, 13–15 September 2017. [Google Scholar] [CrossRef]
- Qiao, J.Z.; Wu, H.; Zhu, Y.; Xu, J.; Li, W. Anti-disturbance iterative learning tracking control for space manipulators with repetitive reference trajectory. Assem. Autom. 2019, 39, 401–409. [Google Scholar] [CrossRef]
- Meng, D.; Jia, Y.; Du, J.; Yu, F. Data-Driven Control for Relative Degree Systems via Iterative Learning. IEEE Trans. Neural Netw. 2011, 22, 2213–2225. [Google Scholar] [CrossRef]
- Rogers, E.; Galkowski, K.; Owens, D.H. Control Systems Theory and Applications for Linear Repetitive Processes; Springer: Berlin/Heidelberg, Germany, 2007; Volume 349, p. 32. [Google Scholar] [CrossRef] [Green Version]
- Rantzer, A. On the Kalman—Yakubovich—Popov lemma. Syst. Ampmathsemicolon Control Lett. 1996, 28, 7–10. [Google Scholar] [CrossRef]
- Gahinet, P.; Apkarian, P. A linear matrix inequality approach to H∞ control. Int. J. Robust Nonlinear Control 1994, 4, 421–448. [Google Scholar] [CrossRef]
- Shi, J.; Gao, F.; Wu, T.J. Robust design of integrated feedback and iterative learning control of a batch process based on a 2D Roesser system. J. Process. Control 2005, 15, 907–924. [Google Scholar] [CrossRef]
- Geng, Y.; Ruan, X.; Zhou, Q.; Yang, X. Robust adaptive iterative learning control for nonrepetitive systems with iteration-varying parameters and initial state. Int. J. Mach. Learn. Cybern. 2021, 12, 2327–2337. [Google Scholar] [CrossRef]
- Ayatinia, M.; Forouzanfar, M.; Ramezani, A. An LMI Approach to Robust Iterative Learning Control for Linear Discrete-time Systems. Int. J. Control Autom. Syst. 2022, 20, 2391–2401. [Google Scholar] [CrossRef]
- Tao, H.; Li, J.; Chen, Y.; Stojanovic, V.; Yang, H. Robust point-to-point iterative learning control with trial-varying initial conditions. IET Control Theory Appl. 2020, 14, 3344–3350. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Dong, L.; Yang, R.; Chen, Y. Dynamic ILC for Linear Repetitive Processes Based on Different Relative Degrees. Mathematics 2022, 10, 4824. https://doi.org/10.3390/math10244824
Wang L, Dong L, Yang R, Chen Y. Dynamic ILC for Linear Repetitive Processes Based on Different Relative Degrees. Mathematics. 2022; 10(24):4824. https://doi.org/10.3390/math10244824
Chicago/Turabian StyleWang, Lei, Liangxin Dong, Ruitian Yang, and Yiyang Chen. 2022. "Dynamic ILC for Linear Repetitive Processes Based on Different Relative Degrees" Mathematics 10, no. 24: 4824. https://doi.org/10.3390/math10244824