
Event-Triggered Optimal Consensus of Heterogeneous Nonlinear Multi-Agent Systems

Abstract
:1. Introduction
- Different from the classical time-triggered setting, our proposed event-triggered method is able to significantly reduce the unnecessary control input updates while ensuring the approximate optimal consensus.
- In contrast to the study of first- and second-order multi-agent systems, where external disturbances are assumed to be bounded a priori, we study a more general nonlinear dynamics where uncertainty is allowed to grow arbitrarily as the variation of agent states and higher-order heterogeneous dynamics are involved.
2. Problem Formulation and Preliminaries
2.1. Preliminaries
2.2. Problem Formulation
3. Main Result
3.1. Controller Design
3.2. Stability Analysis
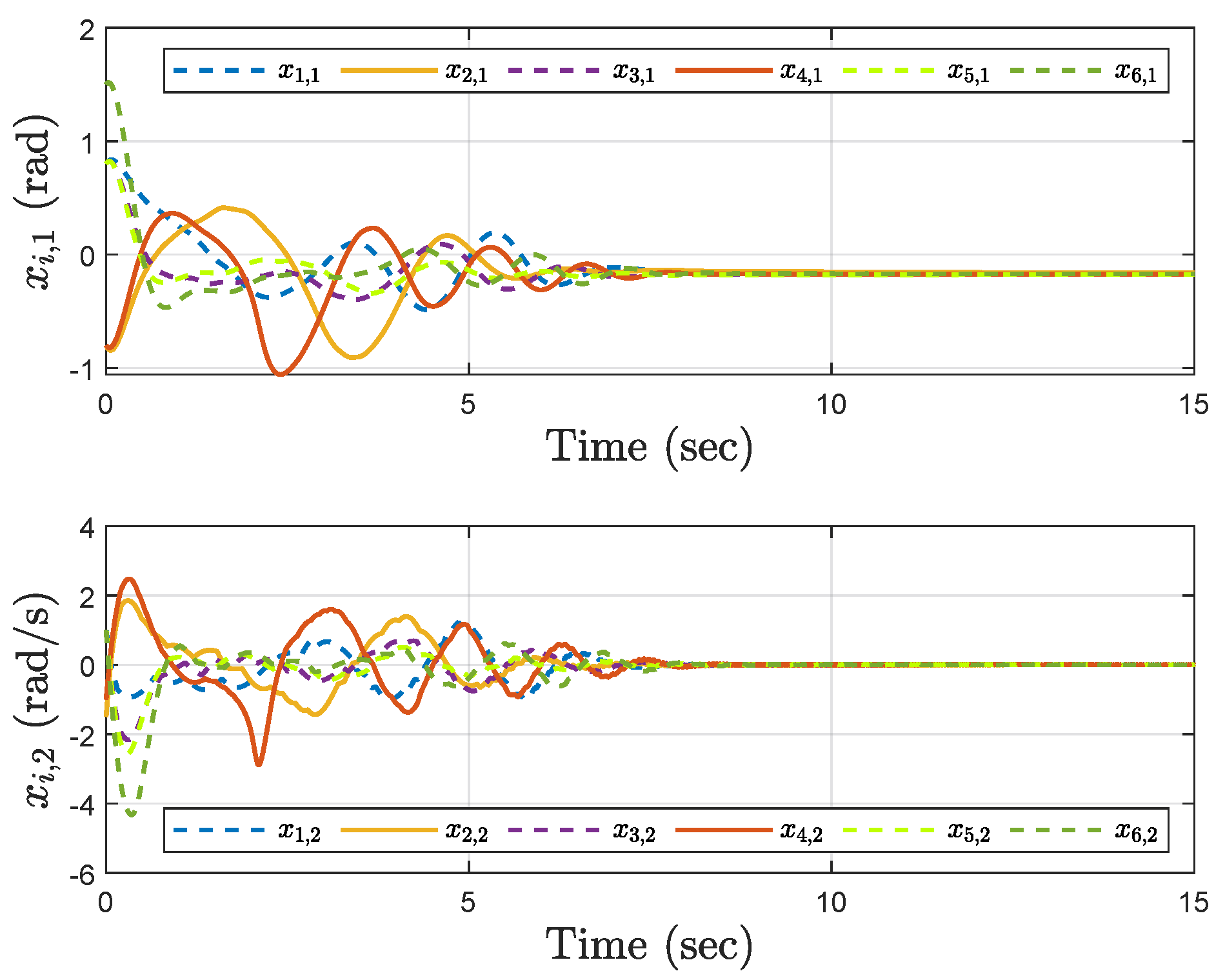
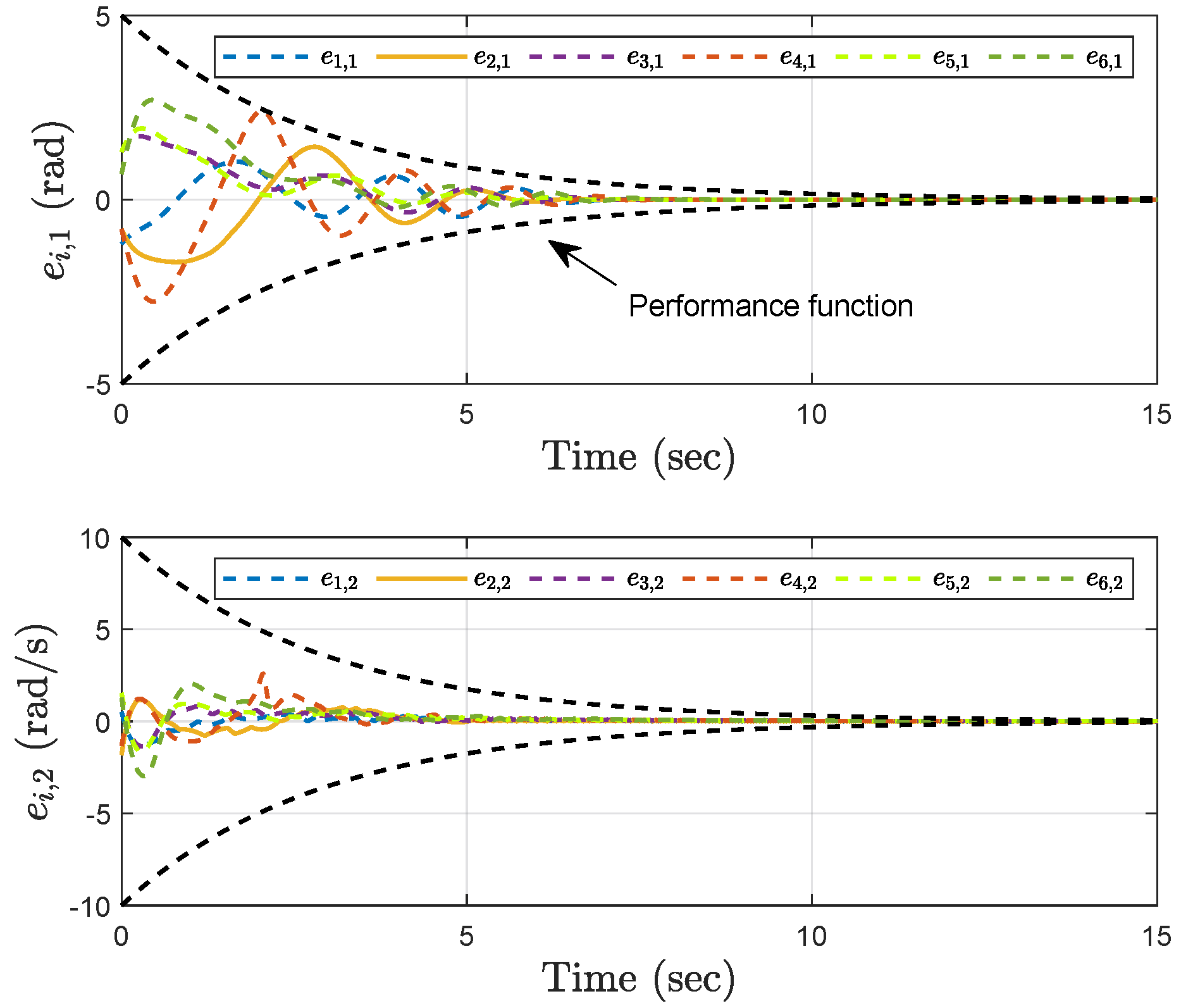
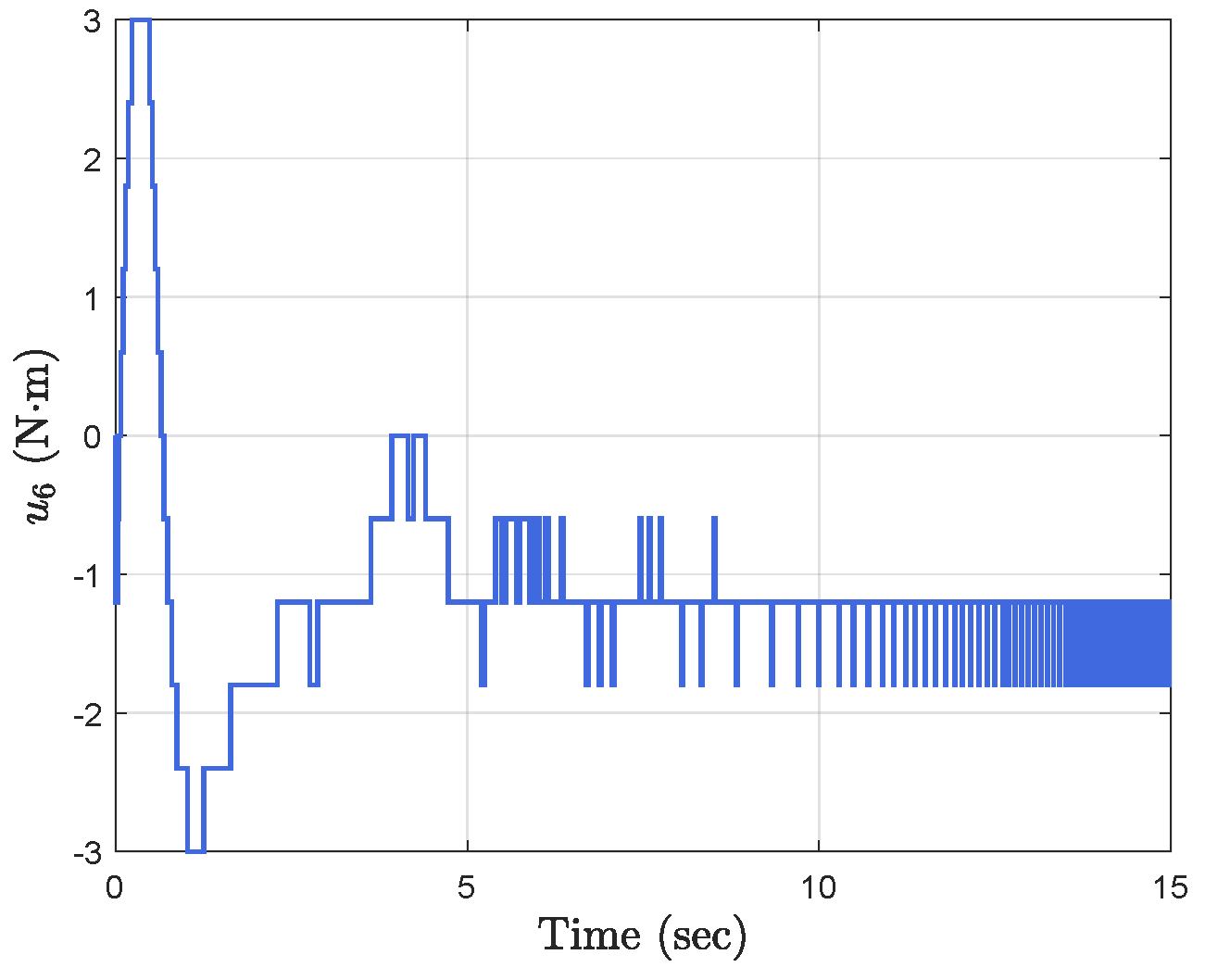
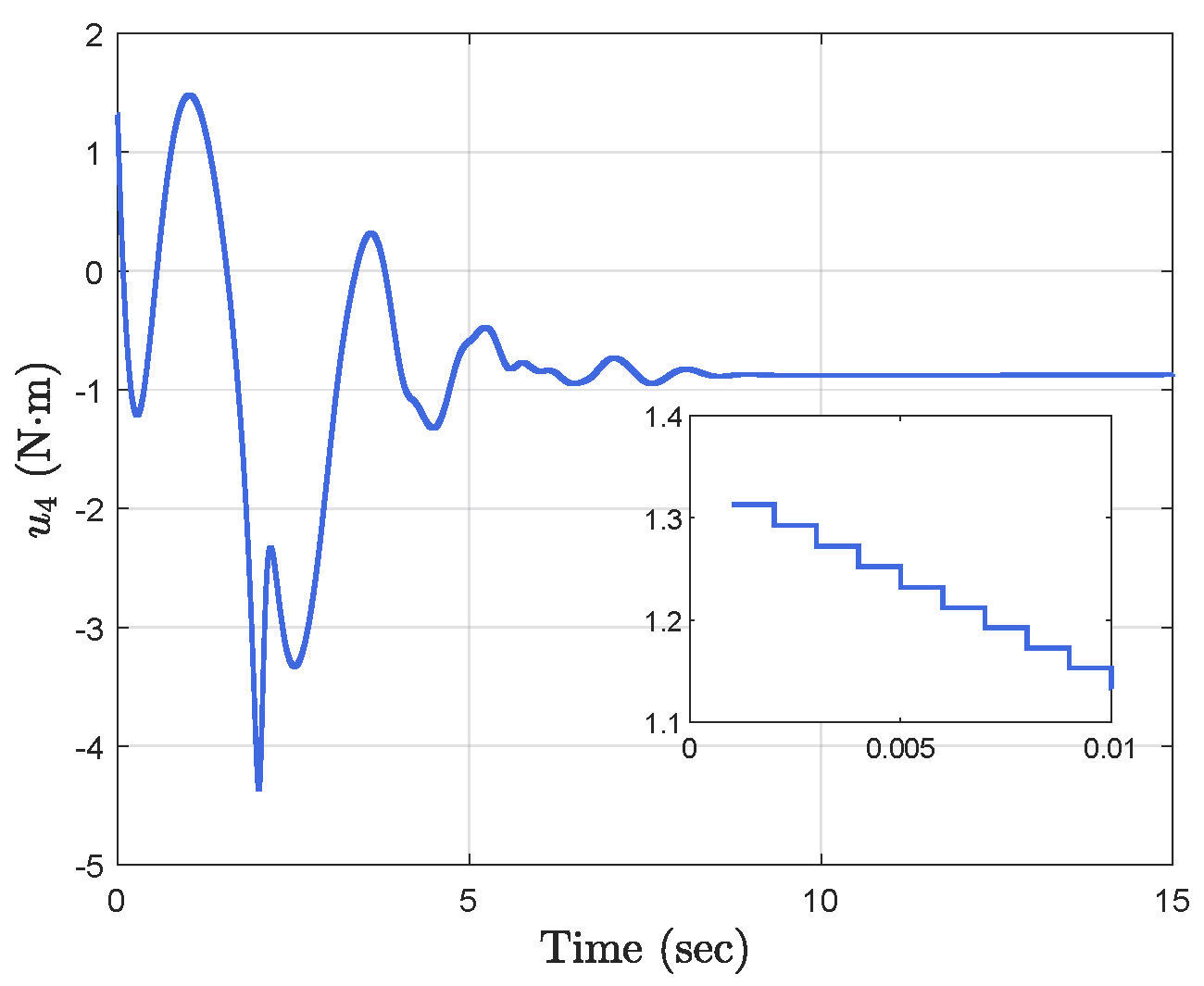
4. Simulation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Psillakis, H.E. Consensus in networks of agents with unknown high-frequency gain signs and switching topology. IEEE Trans. Autom. Control 2017, 62, 3993–3998. [Google Scholar] [CrossRef]
- Abdessameud, A.; Tayebi, A. Distributed consensus algorithms for a class of high-order multi-agent systems on directed graphs. IEEE Trans. Autom. Control 2018, 63, 3464–3470. [Google Scholar] [CrossRef]
- Ren, W. On consensus algorithms for double-integrator dynamics. IEEE Trans. Autom. Control 2008, 53, 1503–1509. [Google Scholar] [CrossRef]
- Wang, G. Distributed control of higher-order nonlinear multi-agent systems with unknown non-identical control directions under general directed graphs. Automatica 2019, 110, 108559. [Google Scholar] [CrossRef]
- Wang, G. Consensus control in heterogeneous nonlinear multiagent systems with position feedback and switching topologies. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3546–3557. [Google Scholar] [CrossRef]
- Wang, Q.; Psillakis, H.E.; Sun, C. Cooperative control of multiple agents with unknown high-frequency gain signs under unbalanced and switching topologies. IEEE Trans. Autom. Control 2019, 64, 2495–2501. [Google Scholar] [CrossRef] [Green Version]
- Mei, J.; Ren, W.; Chen, J. Distributed consensus of second-order multi-agent systems with heterogeneous unknown inertias and control gains under a directed graph. IEEE Trans. Autom. Control 2016, 61, 2019–2034. [Google Scholar] [CrossRef]
- Yang, F.; Yu, Z.; Huang, D.; Jiang, H. Distributed optimization for second-order multi-agent systems over directed networks. Mathematics 2022, 10, 3803. [Google Scholar] [CrossRef]
- Gharesifard, B.; Cortés, J. Distributed continuous-time convex optimization on weight-balanced digraphs. IEEE Trans. Autom. Control 2014, 59, 781–786. [Google Scholar] [CrossRef] [Green Version]
- Zanella, F.; Varagnolo, D.; Cenedese, A.; Pillonetto, G.; Schenato, L. Newton-Raphson consensus for distributed convex optimization. In Proceedings of the 2011 50th IEEE Conference on Decision and Control and European Control Conference, Orlando, FL, USA, 12–15 December 2011; pp. 5917–5922. [Google Scholar]
- Kia, S.S.; Cortés, J.; Martínez, S. Distributed convex optimization via continuous-time coordination algorithms with discrete-time communication. Automatica 2015, 55, 254–264. [Google Scholar] [CrossRef]
- Wang, X.; Yi, P.; Hong, Y. Dynamic optimization for multi-agent systems with external disturbances. Control Theory Technol. 2014, 12, 132–138. [Google Scholar] [CrossRef]
- Wang, X.; Li, S.; Wang, G. Distributed optimization for disturbed second-order multiagent systems based on active antidisturbance control. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2104–2117. [Google Scholar] [CrossRef] [PubMed]
- Gkesoulis, A.K.; Psillakis, H.E.; Lagos, A.R. Optimal consensus via OCPI regulation for unknown pure-feedback agents with disturbances and state-delays. IEEE Trans. Autom. Control 2022, 67, 4338–4345. [Google Scholar] [CrossRef]
- Xing, L.; Wen, C.; Liu, Z.; Su, H.; Cai, J. Event-triggered adaptive control for a class of uncertain nonlinear systems. IEEE Trans. Autom. Control 2017, 62, 2071–2076. [Google Scholar] [CrossRef]
- Zhuang, J.; Li, Z.; Hou, Z.; Yang, C. Event-triggered consensus control of nonlinear strict feedback multi-agent systems. Mathematics 2022, 10, 1596. [Google Scholar] [CrossRef]
- Bai, H.; Arcak, M. Instability mechanisms in cooperative control. IEEE Trans. Autom. Control 2009, 55, 258–263. [Google Scholar] [CrossRef]
- Wang, G.; Wang, C.; Ding, Z.; Ji, Y. Distributed consensus of nonlinear multi-agent systems with mismatched uncertainties and unknown high-frequency gains. IEEE Trans. Circuits Syst. II Express Briefs 2021, 68, 938–942. [Google Scholar] [CrossRef]
- Bechlioulis, C.P.; Rovithakis, G.A. A low-complexity global approximation-free control scheme with prescribed performance for unknown pure feedback systems. Automatica 2014, 50, 1217–1226. [Google Scholar] [CrossRef]
- Bechlioulis, C.P.; Rovithakis, G.A. Robust adaptive control of feedback linearizable MIMO nonlinear systems with prescribed performance. IEEE Trans. Autom. Control 2008, 53, 2090–2099. [Google Scholar] [CrossRef]
- Spong, M.W.; Hutchinson, S.; Vidyasagar, M. Robot Modeling and Control; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Manipulator 1 | Manipulator 2 | Manipulator 3 | |
| Event-triggered control | 1130 | 716 | 630 |
| Periodic time-triggered control | 15,000 | 15,000 | 15,000 |
| Manipulator 4 | Manipulator 5 | Manipulator 6 | |
| Event-triggered control | 949 | 551 | 171 |
| Periodic time-triggered control | 15,000 | 15,000 | 15,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Y.; Wang, G.; Li, Q.; Wang, C. Event-Triggered Optimal Consensus of Heterogeneous Nonlinear Multi-Agent Systems. Mathematics 2022, 10, 4622. https://doi.org/10.3390/math10234622
Ji Y, Wang G, Li Q, Wang C. Event-Triggered Optimal Consensus of Heterogeneous Nonlinear Multi-Agent Systems. Mathematics. 2022; 10(23):4622. https://doi.org/10.3390/math10234622
Chicago/Turabian StyleJi, Yunfeng, Gang Wang, Qingdu Li, and Chaoli Wang. 2022. "Event-Triggered Optimal Consensus of Heterogeneous Nonlinear Multi-Agent Systems" Mathematics 10, no. 23: 4622. https://doi.org/10.3390/math10234622