

Parallel Implementation of a Sensitivity Operator-Based Source Identification Algorithm for Distributed Memory Computers

Abstract
:1. Introduction
2. Materials and Methods
2.1. Inverse Modeling and Data Assimilation Framework
- 1.
- The first group of solvers uses NLOpt package [43] implementations of “derivative-free” minimization algorithms. To use the solvers, it is enough to implement the procedure for solving a direct problem only. Derivative-free and meta-heuristic solvers (a review can be found in [44]) may use the ensembles of direct problem solutions with different input parameters, which can be calculated in parallel. It makes them a good target for parallel implementation (e.g., [45]). We tested this approach in [46] for a Python differential evolution solver in a chemical reaction rate identification problem. Nevertheless, meta-heuristic solvers seem to show relatively slow convergence for high-dimensional inverse problems [47]. To use them for solving large-scale inverse problems, some reduction procedures should be applied in advance.
- 2.
- The second group uses the implementations of gradient algorithms from GSL [48] or NLOpt [43] to address the misfit minimization problems [47,49,50]. The solvers require the procedures for operating both direct and adjoint problems to estimate the gradient of the misfit functional of measured and modeled values. Deriving adjoint problems and implementing their solutions takes additional theoretical and programming effort comparable to the one needed for the direct problem. The task of adjoint code generation can be potentially automatized [51,52,53]. The gradient-based algorithms can be paralleled on the level of direct and adjoint problem solutions.
- 3.
- The third group of solvers is based on the sensitivity operators of inverse problems and refers to the unique features of IMDAF: the inverse problem is reduced to a family of quasi-linear operator equations with sensitivity operators, which are constructed by solving the ensembles of adjoint equations and calculating the corresponding sensitivity functions defined by a set of measurement data aggregation functions. We provide a brief description of the algorithms in Section 2.3; the detailed description can be found in [12,13]. The sensitivity operators can be used for solving and analyzing inverse problems. To realize such options, it is necessary to design the procedures for solving an ensemble of adjoint equations.
2.2. Direct and Inverse Problems
- Let only a given set of species be emitted and for .
- Let the sources be constant in time ().
- The emission rates can be of both signs.
- In the inverse problem, has to be identified from the “measurement data” collected for , see Section 2.5.1.
2.3. Sensitivity Operator-Based Representation of Source Identification Problem
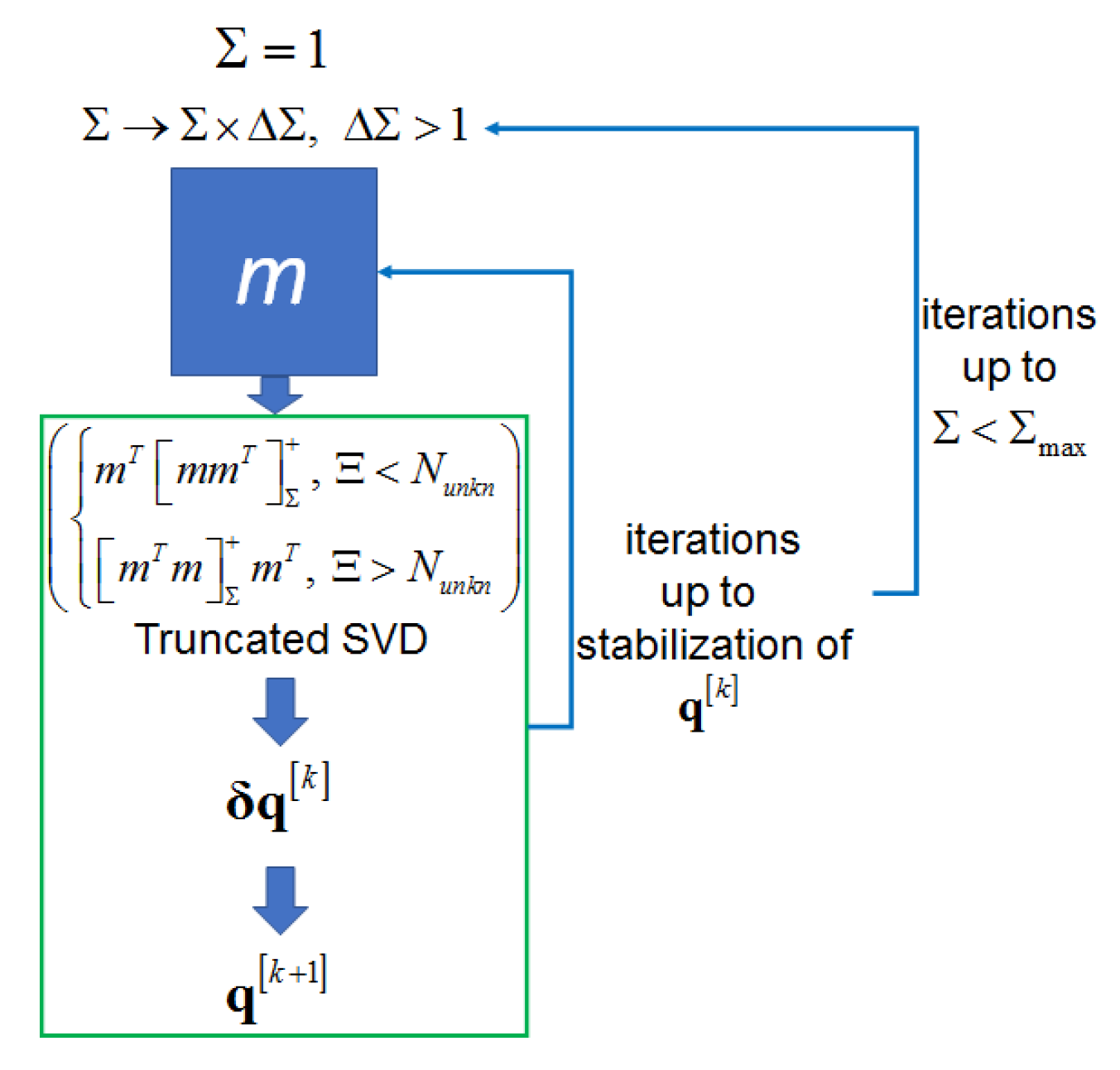
2.4. Parallelization Strategy
- The outer loop increases the sensitivity operator’s matrix inversion regularization parameter ;
- The middle loop performs the Newton-type iterations up to the stabilization with the fixed ;
- The inner loop chooses the step parameter in the Newton-type iterations to provide the monotonic decrease in the data misfit.

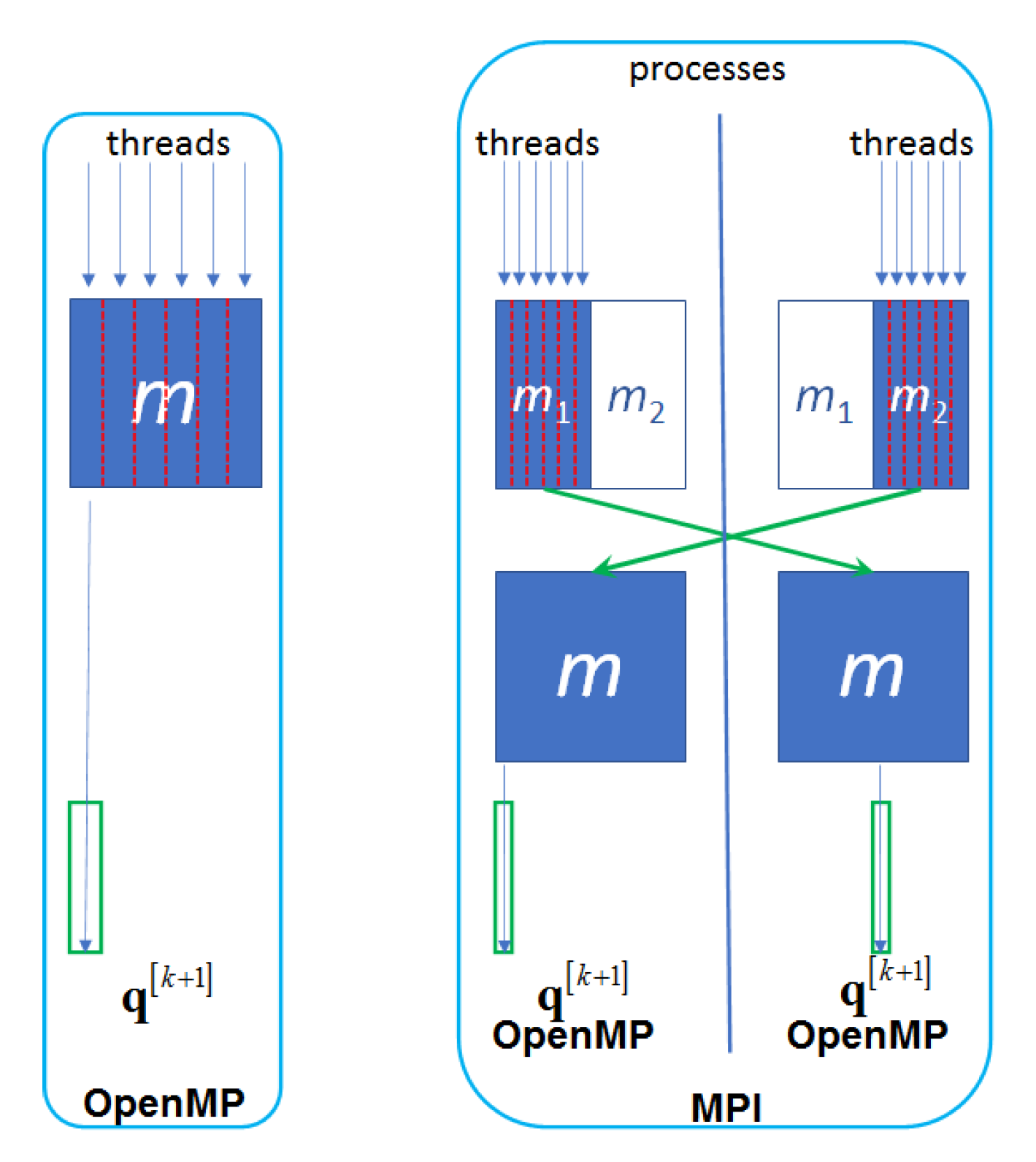
- For single-process execution, we use OpenMP parallelization technology [42]: each OpenMP thread constructs its set of the rows of m; after all rows are constructed and the whole m is built, one (the main) thread executes the sequential part of the iteration, i.e., inverts m and makes an update.
- For multiple-process execution, we use OpenMP for in-process parallelization and MPI for inter-process communications. Each MPI process executes the sequential part of the algorithm. In the parallel part, each process constructs its set of the rows of m; then the processes communicate with each other to form full m on each process.

2.5. Experimental Setup
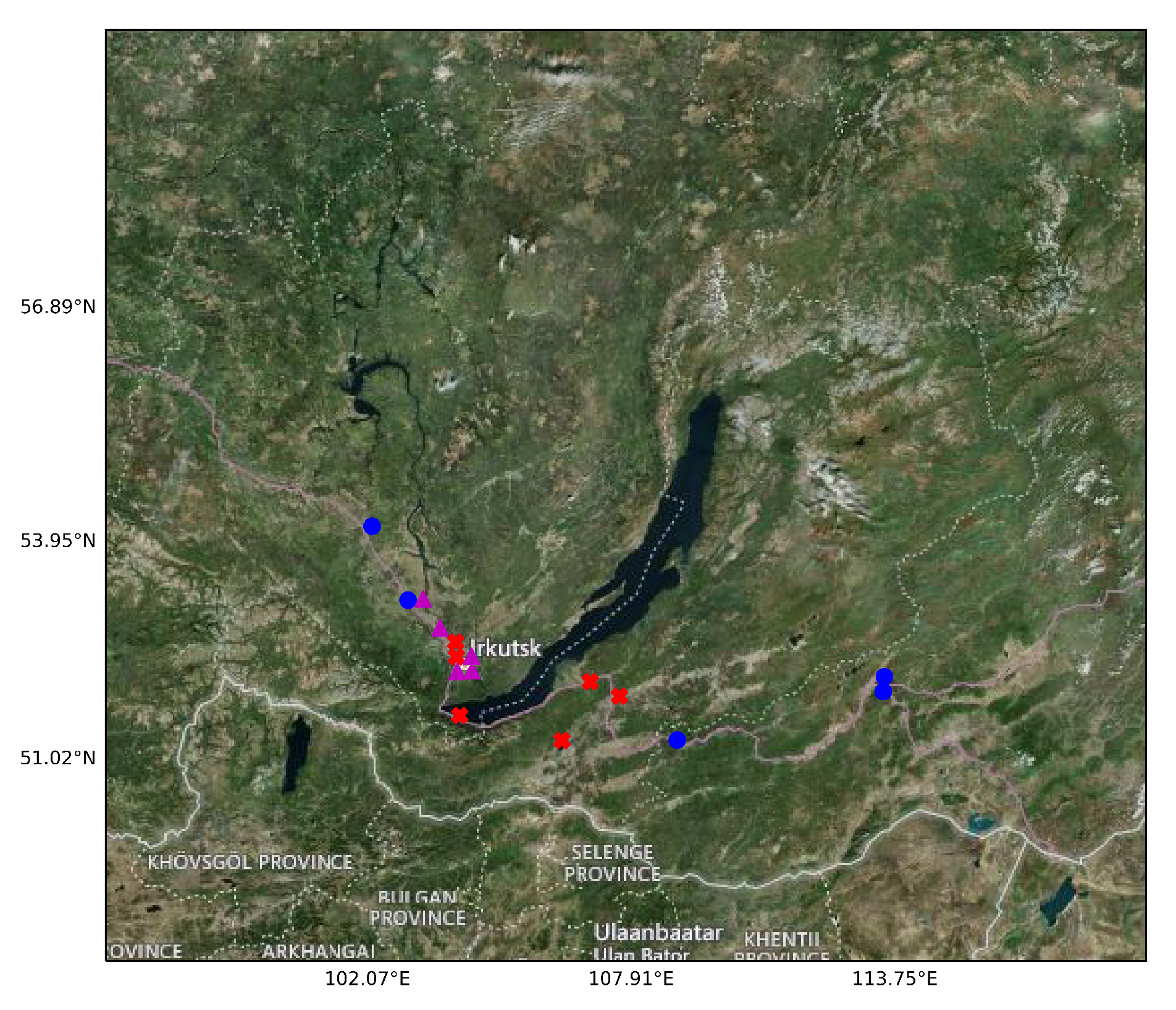
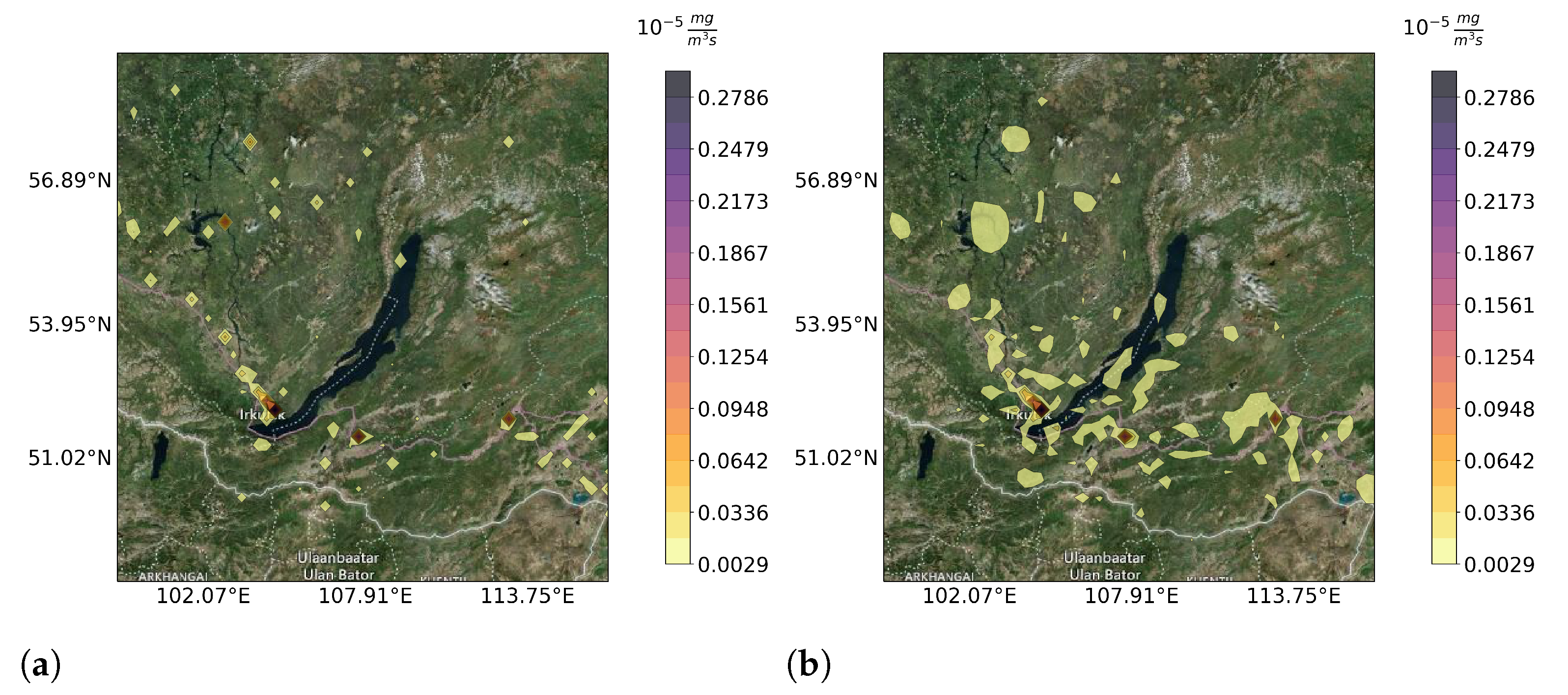
2.5.1. Inverse Modeling Scenario
2.5.2. Hardware Configuration
- Single node with Intel Xeon Phi 7290 (1 CPU × 72 cores × 4 threads, 1.50 GHz, 96 GB RAM). Total number of cores is 72, and the maximum number of processing threads is 288.
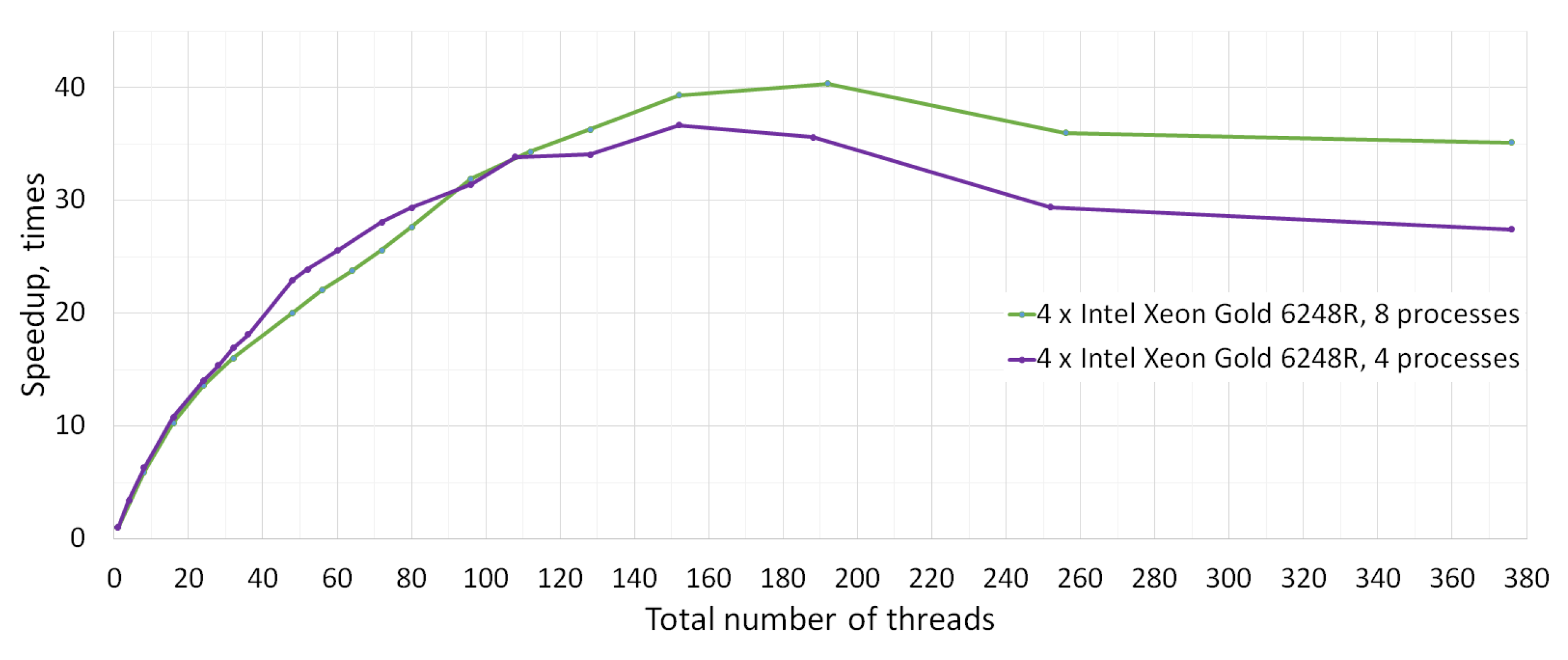
- Total of 1, 2, 3, and 4 nodes with Intel Xeon Gold 6248R (2 CPU × 24 cores × 2 threads, 3.00 GHz, 384 GB RAM) connected with Cluster Interconnect Omni-Path 100 Gbps. Total number of cores/threads is 48/96, 96/192, 144/288, and 192/384, correspondingly. For each number of nodes, we tested:
- −
- “Single process per node” execution,
- −
- “Two processes per node” execution with each process running on separate CPU.
In multiple-process execution, all the processes launch an equal number of OpenMP threads, so the total number of threads is a multiple of the number of processes.
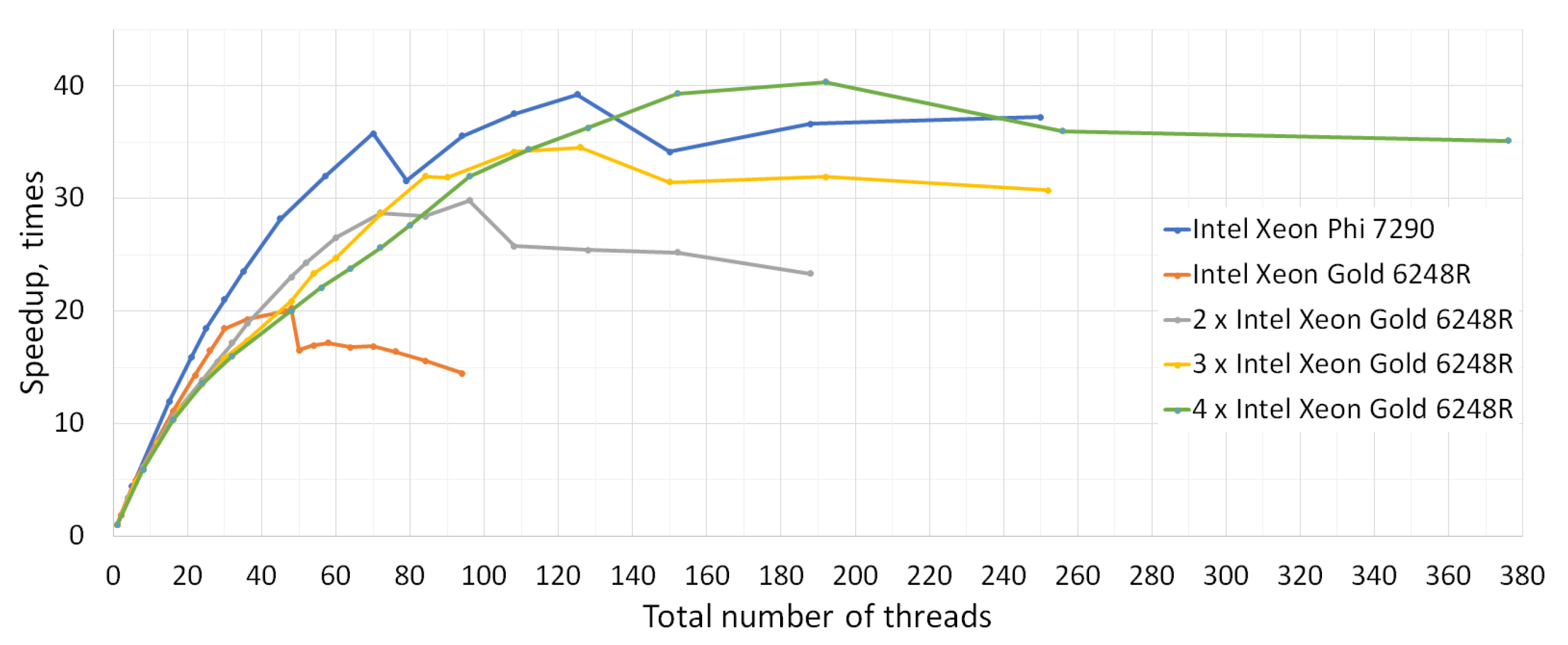
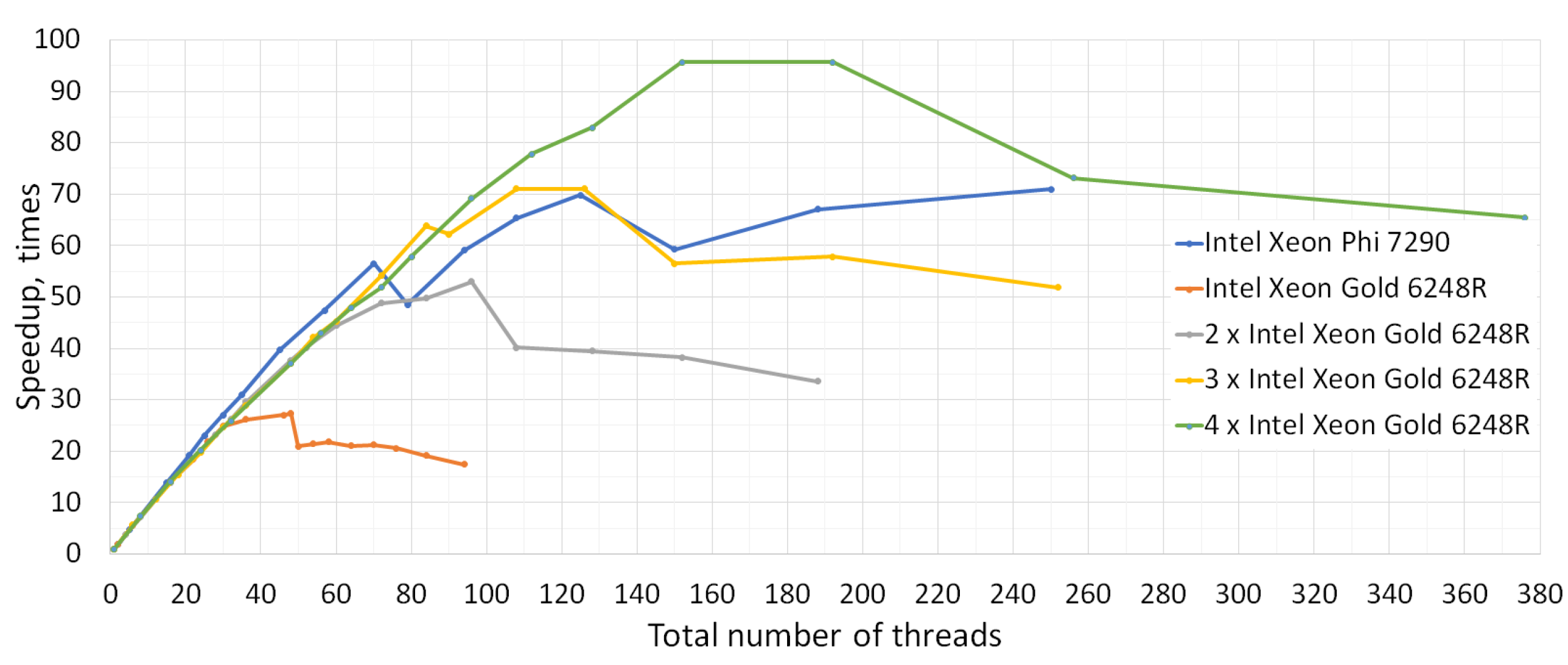
3. Results




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | , sec | , sec | , % | , sec | , % | |||
|---|---|---|---|---|---|---|---|---|
| 1 × Intel Xeon Phi 7290 | 461,257 | 11,758 | 39.23 | 125 | 125 | 31.4 | 6336 | 53.9 |
| 1 × Intel Xeon Gold 6248R | 84,928 | 4195 | 20.25 | 48 | 48 | 42.2 | 3003 | 71.6 |
| 2 × Intel Xeon Gold 6248R | 84,928 | 2847 | 29.83 | 96 | 48 | 31.1 | 1551 | 54.5 |
| 3 × Intel Xeon Gold 6248R | 84,928 | 2460 | 34.52 | 126 | 42 | 27.4 | 1155 | 47.0 |
| 4 × Intel Xeon Gold 6248R | 84,928 | 2105 | 40.35 | 192 | 48 | 21.0 | 858 | 40.8 |
4. Discussion
- The OpenMP threads 1–24 are executed by one CPU of Intel Xeon Gold and the threads 25–48, by another;
- The memory allocated by a thread is taken from the local memory of the CPU running the thread;
- CPU accesses its own local memory faster than non-local memory.
5. Conclusions
- Increasing overall efficiency of IMDAF code at micro (loop vectorization, memory access optimization) and macro (using highly optimized libraries, decreasing memory footprint) levels;
- Introducing parallelism into the “sequential” part of the program;
- Analyzing and mitigating the factors limiting the speedup of sensitivity operator matrix construction;
- Testing more realistic and time-consuming models and scenarios (including more complicated chemistry model and 3D space modeling);
- Using the software in the thematic services for air quality studies.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CTM | chemical transport model |
| HPC | high performance computing |
| IMDAF | inverse modeling and data assimilation framework |
| MPI | message passing interface |
| NUMA | non-uniform memory access |
| SVD | singular value decomposition |
Appendix A
| Algorithm A1 Newton–Kantorovich-type Algorithm [13] |
|
References
- Brunet, G. Seamless Prediction of the Earth System: From Minutes to Months; World Meteorological Organization: Geneva, Switzerland, 2015. [Google Scholar]
- World Meteorological Organization. Guide to Instruments and Methods of Observation; Volume I –Measurement of Meteorological Variables, Chapter Measurement of Atmospheric Composition; WMO: Geneva, Switzerland, 2018; pp. 506–541. [Google Scholar]
- Sokhi, R.S.; Moussiopoulos, N.; Baklanov, A.; Bartzis, J.; Coll, I.; Finardi, S.; Friedrich, R.; Geels, C.; Grönholm, T.; Halenka, T.; et al. Advances in air quality research—current and emerging challenges. Atmos. Chem. Phys. 2022, 22, 4615–4703. [Google Scholar] [CrossRef]
- Bocquet, M.; Elbern, H.; Eskes, H.; Hirtl, M.; Žabkar, R.; Carmichael, G.R.; Flemming, J.; Inness, A.; Pagowski, M.; Camaño, J.L.P.; et al. Data assimilation in atmospheric chemistry models: Current status and future prospects for coupled chemistry meteorology models. Atmos. Chem. Phys. Discuss. 2014, 14, 32233–32323. [Google Scholar] [CrossRef] [Green Version]
- Carrassi, A.; Bocquet, M.; Bertino, L.; Evensen, G. Data assimilation in the geosciences: An overview of methods, issues, and perspectives. Wiley Interdiscip. Rev. Clim. Chang. 2018, 9, e535. [Google Scholar] [CrossRef] [Green Version]
- Elbern, H.; Strunk, A.; Schmidt, H.; Talagrand, O. Emission rate and chemical state estimation by 4-dimensional variational inversion. Atmos. Chem. Phys. Discuss. 2007, 7, 1725–1783. [Google Scholar] [CrossRef] [Green Version]
- Holnicki, P.; Nahorski, Z. Emission Data Uncertainty in Urban Air Quality Modeling—Case Study. Environ. Model. Assess. 2015, 20, 583–597. [Google Scholar] [CrossRef] [Green Version]
- Markakis, K.; Valari, M.; Perrussel, O.; Sanchez, O.; Honore, C. Climate-forced air-quality modeling at the urban scale: Sensitivity to model resolution, emissions and meteorology. Atmos. Chem. Phys. 2015, 15, 7703–7723. [Google Scholar] [CrossRef] [Green Version]
- Zlatev, Z. Computer Treatment of Large Air Pollution Models; Springer: Dordrecht, The Netherlands, 1995. [Google Scholar] [CrossRef]
- Baklanov, A.; Alexander, M.; Sokhi, R. (Eds.) Integrated Systems of Meso—Meteorological and Chemical Transport Models; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Cullen, M.; Freitag, M.A.; Kindermann, S.; Scheichl, R. (Eds.) Large Scale Inverse Problems; DE GRUYTER: Berlin, Germany; Boston, MA, USA, 2013. [Google Scholar] [CrossRef] [Green Version]
- Penenko, A. Convergence analysis of the adjoint ensemble method in inverse source problems for advection-diffusion-reaction models with image-type measurements. Inverse Probl. Imaging 2020, 14, 757–782. [Google Scholar] [CrossRef]
- Penenko, A.; Penenko, V.; Tsvetova, E.; Gochakov, A.; Pyanova, E.; Konopleva, V. Sensitivity Operator Framework for Analyzing Heterogeneous Air Quality Monitoring Systems. Atmosphere 2021, 12, 1697. [Google Scholar] [CrossRef]
- Penenko, A.; Zubairova, U.; Mukatova, Z.; Nikolaev, S. Numerical algorithm for morphogen synthesis region identification with indirect image-type measurement data. J. Bioinform. Comput. Biol. 2019, 17, 1940002-1–1940002-18. [Google Scholar] [CrossRef]
- Marchuk, G.I. Formulation of some converse problems. Sov. Math. Dokl. 1964, 5, 675–678. [Google Scholar]
- Penenko, V. Methods for Numerical Simulation of Atmospheric Processes; Hydrometeoizdat: Leningrad, Russia, 1981. (In Russian) [Google Scholar]
- Murio, D.A. The Mollification Method and the Numerical Solution of Ill-Posed Problems; John Wiley & Sons, Inc.: New York, NY, USA, 1993. [Google Scholar] [CrossRef]
- Dimet, F.X.L.; Souopgui, I.; Titaud, O.; Shutyaev, V.; Hussaini, M.Y. Toward the assimilation of images. Nonlinear Process. Geophys. 2015, 22, 15–32. [Google Scholar] [CrossRef] [Green Version]
- Anderson, J.L.; Collins, N. Scalable Implementations of Ensemble Filter Algorithms for Data Assimilation. J. Atmos. Ocean. Technol. 2007, 24, 1452–1463. [Google Scholar] [CrossRef]
- Li, X.; Lu, W. Particle network EnKF for large-scale data assimilation. Front. Phys. 2022, 10, 850. [Google Scholar] [CrossRef]
- Ghorbanidehno, H.; Kokkinaki, A.; Lee, J.; Darve, E. Recent developments in fast and scalable inverse modeling and data assimilation methods in hydrology. J. Hydrol. 2020, 591, 125266. [Google Scholar] [CrossRef]
- Todaro, V.; D’Oria, M.; Tanda, M.G.; Gómez-Hernández, J.J. genES-MDA: A generic open-source software package to solve inverse problems via the Ensemble Smoother with Multiple Data Assimilation. Comput. Geosci. 2022, 167, 105210. [Google Scholar] [CrossRef]
- Anderson, J.; Hoar, T.; Raeder, K.; Liu, H.; Collins, N.; Torn, R.; Avellano, A. The Data Assimilation Research Testbed: A Community Facility. Bull. Am. Meteorol. Soc. 2009, 90, 1283–1296. [Google Scholar] [CrossRef] [Green Version]
- Nerger, L.; Hiller, W. Software for ensemble-based data assimilation systems—Implementation strategies and scalability. Comput. Geosci. 2013, 55, 110–118. [Google Scholar] [CrossRef]
- Nerger, L.; Tang, Q.; Mu, L. Efficient ensemble data assimilation for coupled models with the Parallel Data Assimilation Framework: Example of AWI-CM (AWI-CM-PDAF 1.0). Geosci. Model Dev. 2020, 13, 4305–4321. [Google Scholar] [CrossRef]
- Browne, P.; Wilson, S. A simple method for integrating a complex model into an ensemble data assimilation system using MPI. Environ. Model. Softw. 2015, 68, 122–128. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.Z.; Huang, J.; Reich, S.; Stuart, A.M. Efficient derivative-free Bayesian inference for large-scale inverse problems. Inverse Probl. 2022, 38, 125006. [Google Scholar] [CrossRef]
- Cho, T.; Chung, J.; Miller, S.M.; Saibaba, A.K. Computationally efficient methods for large-scale atmospheric inverse modeling. Geosci. Model Dev. 2022, 15, 5547–5565. [Google Scholar] [CrossRef]
- Pandey, S.; Houweling, S.; Segers, A. Order of magnitude wall time improvement of variational methane inversions by physical parallelization: A demonstration using TM5-4DVAR. Geosci. Model Dev. 2022, 15, 4555–4567. [Google Scholar] [CrossRef]
- D’Amore, L.; Constantinescu, E.; Carracciuolo, L. A Scalable Space-Time Domain Decomposition Approach for Solving Large Scale Nonlinear Regularized Inverse Ill Posed Problems in 4D Variational Data Assimilation. J. Sci. Comput. 2022, 91, 59. [Google Scholar] [CrossRef]
- Hamill, T.M.; Snyder, C. A Hybrid Ensemble Kalman Filter–3D Variational Analysis Scheme. Mon. Weather. Rev. 2000, 128, 2905–2919. [Google Scholar] [CrossRef]
- Pisso, I.; Sollum, E.; Grythe, H.; Kristiansen, N.I.; Cassiani, M.; Eckhardt, S.; Arnold, D.; Morton, D.; Thompson, R.L.; Zwaaftink, C.D.G.; et al. The Lagrangian particle dispersion model FLEXPART version 10.4. Geosci. Model Dev. 2019, 12, 4955–4997. [Google Scholar] [CrossRef] [Green Version]
- Bergamaschi, P.; Segers, A.; Brunner, D.; Haussaire, J.M.; Henne, S.; Ramonet, M.; Arnold, T.; Biermann, T.; Chen, H.; Conil, S.; et al. High-resolution inverse modelling of European CH4 emissions using the novel FLEXPART-COSMO TM5 4DVAR inverse modelling system. Atmos. Chem. Phys. 2022, 22, 13243–13268. [Google Scholar] [CrossRef]
- Leeuwen, P.J.; Kunsch, H.R.; Nerger, L.; Potthast, R.; Reich, S. Particle filters for high-dimensional geoscience applications: A review. Q. J. R. Meteorol. Soc. 2019, 145, 2335–2365. [Google Scholar] [CrossRef] [PubMed]
- Penny, S.G.; Smith, T.A.; Chen, T.C.; Platt, J.A.; Lin, H.Y.; Goodliff, M.; Abarbanel, H.D.I. Integrating Recurrent Neural Networks With Data Assimilation for Scalable Data-Driven State Estimation. J. Adv. Model. Earth Syst. 2022, 14, e2021MS002843. [Google Scholar] [CrossRef]
- Biondi, E.; Barnier, G.; Clapp, R.G.; Picetti, F.; Farris, S. An object-oriented optimization framework for large-scale inverse problems. Comput. Geosci. 2021, 154, 104790. [Google Scholar] [CrossRef]
- Villa, U.; Petra, N.; Ghattas, O. hIPPYlib An Extensible Software Framework for Large-Scale Inverse Problems Governed by PDEs: Part I: Deterministic Inversion and Linearized Bayesian Inference. ACM Trans. Math. Softw. 2021, 47, 1–34. [Google Scholar] [CrossRef]
- Issartel, J.P. Emergence of a tracer source from air concentration measurements, a new strategy for linear assimilation. Atmos. Chem. Phys. 2005, 5, 249–273. [Google Scholar] [CrossRef] [Green Version]
- Mamonov, A.V.; Tsai, Y.H.R. Point source identification in nonlinear advection-diffusion-reaction systems. Inverse Probl. 2013, 29, 035009. [Google Scholar] [CrossRef] [Green Version]
- Bieringer, P.E.; Young, G.S.; Rodriguez, L.M.; Annunzio, A.J.; Vandenberghe, F.; Haupt, S.E. Paradigms and commonalities in atmospheric source term estimation methods. Atmos. Environ. 2017, 156, 102–112. [Google Scholar] [CrossRef] [Green Version]
- Panasenko, E.A.; Starchenko, A.V. Determination of urban district atmospheric air pollution in accordance with observational data. Atmos. Ocean. Opt. 2009, 22, 186–191. [Google Scholar] [CrossRef]
- Penenko, A.; Gochakov, A. Parallel speedup analysis of an adjoint ensemble-based source identification algorithm. J. Phys. Conf. Ser. 2021, 1715, 012072-1–012072-6. [Google Scholar] [CrossRef]
- Johnson, S.G. The NLopt Nonlinear-Optimization Package. Available online: http://github.com/stevengj/nlopt (accessed on 31 October 2022).
- Boussaid, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Biscani, F.; Izzo, D. A parallel global multiobjective framework for optimization: Pagmo. J. Open Source Softw. 2020, 5, 2338. [Google Scholar] [CrossRef]
- Penenko, A.V.; Konopleva, V.S.; Penenko, V.V. Inverse modeling of atmospheric chemistry with a differential evolution solver: Inverse problem and Data assimilation. IOP Conf. Ser. Earth Environ. Sci. 2022, 1023, 012015. [Google Scholar] [CrossRef]
- Penenko, A.; Konopleva, V.; Bobrovskikh, A. Numerical Comparison of the Adjoint Problem-based and Derivative-free Algorithms on the Coefficient Identification Problem for a Production-Loss Model. In Proceedings of the 2021 17th International Asian School-Seminar Optimization Problems of Complex Systems (OPCS), Novosibirsk, Russia, 13–17 September 2021. [Google Scholar] [CrossRef]
- Galassi, M. GNU Scientific Library Reference Manual-Third Edition; Network Theory Ltd., 2009; ISBN 0954612078. Available online: https://dl.acm.org/doi/10.5555/1538674 (accessed on 31 October 2022).
- Penenko, A.; Nikolaev, S.; Golushko, S.; Romashenko, A.; Kirilova, I. Numerical Algorithms for Diffusion Coefficient Identification in Problems of Tissue Engineering. Math. Biol. Bioinform. 2016, 11, 426–444. [Google Scholar] [CrossRef] [Green Version]
- Penenko, A. A Newton-Kantorovich Method in Inverse Source Problems for Production-Destruction Models with Time Series-Type Measurement Data. Numer. Anal. Appl. 2019, 12, 51–69. [Google Scholar] [CrossRef]
- Heimbach, P.; Hill, C.; Giering, R. An efficient exact adjoint of the parallel MIT General Circulation Model, generated via automatic differentiation. Future Gener. Comput. Syst. 2005, 21, 1356–1371. [Google Scholar] [CrossRef]
- Vlasenko, A.; Kohl, A.; Stammer, D. The efficiency of geophysical adjoint codes generated by automatic differentiation tools. Comput. Phys. Commun. 2016, 199, 22–28. [Google Scholar] [CrossRef] [Green Version]
- Naumann, U. Adjoint Code Design Patterns. ACM Trans. Math. Softw. 2019, 45, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Rew, R.; Davis, G. NetCDF: An interface for scientific data access. IEEE Comput. Graph. Appl. 1990, 10, 76–82. [Google Scholar] [CrossRef]
- Ortega, J.M.; Rheinboldt, W.C. Iterative Solution of Nonlinear Equations in Several Variables; Academic Press: New York, NY, USA, 1970. [Google Scholar]
- UNESCO. Lake Baikal. Available online: https://whc.unesco.org/en/list/754/ (accessed on 1 December 2021).
- Roshydromet. Unified Information System for Monitoring Atmospheric Air Pollution. Available online: http://www.feerc.ru/uisem/portal/ad/irkutsk (accessed on 1 November 2021). (In Russian).
- Hundsdorfer, W.; Verwer, J.G. Numerical Solution of Time-Dependent Advection-Diffusion-Reaction Equations; Springer Series in Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Baldauf, M.; Seifert, A.; Forstner, J.; Majewski, D.; Raschendorfer, M.; Reinhardt, T. Operational Convective-Scale Numerical Weather Prediction with the COSMO Model: Description and Sensitivities. Mon. Weather. Rev. 2011, 139, 3887–3905. [Google Scholar] [CrossRef]
- Cheverda, V.A.; Kostin, V.I. R-pseudoinverses for compact operators in Hilbert spaces: Existence and stability. J. Inverse Ill-Posed Probl. 1995, 3, 131–148. [Google Scholar] [CrossRef]
- Guennebaud, G.; Jacob, B. Eigen v3. 2010. Available online: http://eigen.tuxfamily.org (accessed on 31 October 2022).


| Hardware | , sec | , sec | , % |
|---|---|---|---|
| Intel Xeon Phi 7290 | 461,257 | 442,233 | 95.9 |
| Intel Xeon Gold 6248R | 84,928 | 82,101 | 96.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Penenko, A.; Rusin, E. Parallel Implementation of a Sensitivity Operator-Based Source Identification Algorithm for Distributed Memory Computers. Mathematics 2022, 10, 4522. https://doi.org/10.3390/math10234522
Penenko A, Rusin E. Parallel Implementation of a Sensitivity Operator-Based Source Identification Algorithm for Distributed Memory Computers. Mathematics. 2022; 10(23):4522. https://doi.org/10.3390/math10234522
Chicago/Turabian StylePenenko, Alexey, and Evgeny Rusin. 2022. "Parallel Implementation of a Sensitivity Operator-Based Source Identification Algorithm for Distributed Memory Computers" Mathematics 10, no. 23: 4522. https://doi.org/10.3390/math10234522