1. Introduction
The National Council of Teachers of Mathematics (NCTM) [
1] reports that teaching with technology to support conceptual development has been a focus of mathematics education for decades. Utilizing multiple technologies to teach mathematics is significantly more difficult than using technology in everyday life. It included teachers’ perspectives, recognizing the significance of technology in teaching mathematics and their confidence in using technology when constructing relevant technology-integrated mathematics classrooms. Therefore, the technology-integrated competency of teachers was defined in this study as the competency to design mathematics lessons that enable students to work on challenging mathematics problems through technology [
2,
3,
4,
5].
To unleash the benefits of technology in the mathematics classroom [
6,
7], teachers require extensive preparation and support. Accordingly, the integration of technology in mathematics education to produce competent prospective mathematics teachers has been incorporated into the most recent mathematics teacher preparation standards [
8]. Utilizing validated classification to evaluate prospective mathematics teachers’ technology-integrated competency provides a solid foundation for entry into the profession [
9,
10].
In recent years, there has been significant interest in the application of data classification approaches to the field of education. Classification is a method for identifying the class of data points provided, referred to as targets/labels or categories. It can be the study of discovering new and potentially helpful information or meaningful outcomes from data. It also seeks to obtain new trends and patterns from datasets by employing various categorization techniques. Particularly, data classification in the education field is now an effective technique for identifying hidden patterns in educational data, predicting students’ academic performance, determining teachers’ competency or enhancing the learning and teaching policy plan. Thus, in this study, we focused on prospective mathematics teachers’ information as our educational data, longitudinally collected over five years, for classification to identify hidden patterns in their technology-integrated competency development.
First of all, we studied the
equilibrium problem (EP), initially introduced by Muu and Oettli [
11]. The EP is to find an element
in a nonempty closed convex subset
C of a real Hilbert space
such that
where
is a bifunction with
for all
, and
is denoted for a solution set of the EP (
1). The EP (
1) generalizes various mathematical problems in optimization analysis such as variational inequalities, minimization problems, linear programming problems, and Nash equilibrium problems, among others, see in [
12,
13,
14,
15].
In 2008, Tran et al. [
16] presented the
two-step extragradient method (TSEM) for solving the EP (
1), which is inspired by the concept of solving the variational inequalities of Korpelevich [
17]. The iterative scheme is formulated as follows:
and
where
is some constant depending on the interval that makes the bifunction
f satisfy the Lipschitz condition. However, as remarked by the authors of [
18], two projections on
C of the two-step extragradient algorithm, which was introduced by Korpelevich [
17], are very difficult to use and can affect the efficiency of the method if
C has a complex structure.
In 2019, Rehman et al. [
19] modified the subgradient explicit iterative algorithm to solve the problem of pseudomonotone equilibrium problems. The weak convergence of these algorithms is well established under stepsize, which are updated at each iteration without the Lipschitz-type condition. The algorithm is generated by arbitrary elements
,
and
,
where
satisfy
with a half-space
and
Very recently, Rehman et al. [
20] focused on improving the stepsize of the subgradient extragradient method to find a solution to the problems of pseudo-monotone equilibrium in a real Hilbert space. The inertial technique term which was first proposed by Polyak [
21] was added to speed up the convergence of the algorithm. The weak convergence of the method is well-established based on the standard assumptions on a bifunction. This algorithm is generated by arbitrary elements
. Choose
,
,
,
and non-decreasing sequence
;
where
satisfy
and construct a half-space
and
Inspired by the above research, we introduce a new modified inertial subgradient extragradient method for obtaining weak convergence to a solution of the set and try to relax the update stepsize that can be chosen in many ways. In applications, we apply our algorithm to solve classification problems in machine learning and show the performance of our algorithm by comparing it with existing algorithms to predict prospective mathematics teachers’ technology-integrated competency.
3. Convergence Theorem
To study the convergence analysis, consider the following conditions.
The solution set is nonempty and f is pseudomonotone on C;
f meets the Lipschitz-like condition on through and ;
is subdifferentiable and convex on for each fixed ;
for each and satisfies .
Lemma 4. Let in Algorithm 1, then .
| Algorithm 1 Modified inertial subgradient extragradient Mann Algorithm 1 |
Initialization: Select arbitrary elements . Iterative Steps: Construct by using the following steps: Step 1. Set , where , and compute
where . If , then stop. Otherwise, Step 2. Compute
where satisfying and construct a half-space
Step 3. Compute
where . Replace n with and then repeat Step 1.
|
Proof. By the definition of
with Lemma 1, we have
Thus, we can write
, where
and
. Due to
implies that
. Thus, we have
for all
. By
implies
for all
and through above expression, we obtain
for all
. Due to
and using the subdifferential definition, we obtain
for all
. From the inequalities (
6) and (
7) with
implies that
for all
, that is,
. □
Lemma 5. Suppose that meet the items , we havefor all . Proof. Let
, then by using Lemma 1, we have
Thus, we can write
, where
and
. This implies that
for all
. Given that
then
for all
. Therefore, we have
for all
. Since
, we have
for all
. From (
9) and (
10), we obtain
for all
. Substituting
in (
9), we obtain
Given
imply that
and owing to the item
gives that
. Thus, we obtain
Following the condition
, we have
Combining (
13) and (
14), we obtain
By using the half-space definition, we have
, which implies that
Since
, we obtain
for all
. By replacing
, we obtain
It follows from inequalities (
16) and (
17) that
From (
15) and (
18), we have
Now, we obtain the following equalities:
and
Combining the above equalities with expression (
19) finalizes the proof. □
Lemma 6. Assume that the items hold. If there is a subsequence of such that andthen . Proof. From
,
and
, we get
. This follows from
that the subsequence
is bounded. For any
, using (
11), (
14) and (
18), we have
This implies by (
20) and the boundedness of
that the right hand side tends to zero. Due to
, the condition
, and
, we obtain
for all
. Since
, we get
for all
, that is,
. □
With the above results, we are now ready for the main convergence theorem.
Theorem 1. Suppose that and the items are satisfied. Then, the sequence generated due to Algorithm 1 converges weakly to a point in .
Proof. Let
. Since
with expression (
8) implies that
By the definition of
and
, we get
Next, from the definitions of
and
, and using (
21), the following relation is obtained:
Applying this to
with Lemma 2, we can conclude that the sequence
converges. It follows from (
22) and (
23) that
Next, applying the definition of
with (
5) and (
21), we have
which means that
It is implied by expression (
24) and
that
By the inequality (
8), we obtain
for some
. Using (
25) with (
26) and
, we infer that
Finally, let
such that
as
for some subsequence
of
. By (
22), we get
as
. Then, Lemma 6 together with (
25) and (
27) implies that
. Using Opial’s lemma (Lemma 3), we can conclude that
converges weakly to a point in
. □
We next show that we can construct stepsizes under the Lipschitz-like condition of the parameter
for obtaining new algorithms in many ways. This means that our algorithm is flexible to use. Inspired by the stepsize idea of Rehman et al. [
19,
20], we can modify stepsizes
for our Algorithm 1 which satisfy the condition that
; then, we obtain the following algorithms.
4. Application to Data Classification Problem of Educational Dataset
The educational dataset shown in this classification is prospective mathematics teachers’ technology-integrated competency level identified as A, B, C, and D. According to Niess et al. [
25], the levels to which prospective mathematics teachers integrate technology into their teaching were classified in this study: Exploring (A), Adapting (B), Accepting (C), and Recognizing (D).
At level D, prospective mathematics teachers recognize technology usage in the classroom as distinct from pedagogical content knowledge. At level C, prospective mathematics teachers desire to integrate technology into their classrooms but may struggle to find ways to connect it to specific topics. At level B, to determine the use of technology in their classrooms, prospective mathematics teachers begin to make noticeably different adjustments in their pedagogy. Lastly, at level A, prospective mathematics teachers begin seeking more ways to integrate technology throughout the curriculum as another learning tool.
This study is a part of a longitudinal study; the research team planned the research design before collecting the data, according to the educational theory of mathematics education. The observation and analysis were validated by three experts in mathematics education and were proved reliable by three researchers to find consensus from all experts and researchers.
In the very first phase of this research, only four attributes were considered as factors. However, other unobserved factors emerged. Those factors were analyzed to determine whether they affected the competency by statistical analysis and affirmed by inspecting pieces of literature. This analysis was provided in another part of the research and was in-proceeding in other contributions. Moreover, all inputs (prospective mathematics teachers) entered the program under the same selective examination and were controlled by the exit examination.
Consequently, in data training, 954 instances were used, containing ten attributes, including major, gender, GPA, IT for learning competency, innovative skill, technology knowledge for a specific subject, number of supplementation, curriculum pattern, selective technology courses and competency level. The statistical overview of the data is illustrated in
Table 1.
Denoted CV as coefficient of variation (%) and SD as standard deviation.
Before starting our work, we will provide a brief concept of an extreme learning machine (ELM) [
26] for data classification problems. Let
,
be a training set of
N distinct samples where
is input training data and
is a target. The output function of ELM for single-hidden layer feed forward neural networks (SLFNs) with
H hidden nodes and activation function
is
where
and
are parameters of weight and finally the bias, respectively. To find the optimal output weight
at the
i-th hidden node, then the hidden layer output matrix
is generated as follows:
To solve ELM is to find optimal output weight such that , where is the training target data. The least square problem is considered for finding the solution in the cases of the Moore–Penrose generalized inverse of and may be difficult to find when the matrix does not exist.
To avoid overfitting in machine learning, we use least square regularization. This problem can be determined as the following convex minimization problem:
where
is a regularization parameter. This problem is called the least absolute shrinkage and selection operator (LASSO) [
27]. For applying our algorithms we set the bifunction
for all
We use four evaluation metrics:
Accuracy,
Precision,
Recall, and
F1-score [
28] as explained below for comparing the performance of the classification algorithms.
where these matrices gave True Negative (
), False Positive (
), False Negative (
), and True Positive (
) results. The multi-class cross entropy loss is used in multi-class classification by the form:
where
is 0 or 1, indicating whether class label
k is the correct classification and
is a probability of class
and
N is the number of scalar values in the model output.
To start our computation, we set the activation function as sigmoid, hidden nodes
, and regularization parameter
. Setting
and
for Algorithms 1–3,
for Algorithm 2 and
for Algorithm 3. The stopping criteria is the best accuracy of the training process (81.06%). The comparison of all algorithms with different parameters
of Algorithm 1 and
of Algorithms 2 and 3 is presented in
Table 2:
Where
, we can see that
of Algorithms 1–3 receives less training time and iteration number. This means that it highly improves the performance of the algorithm. Next, we consider the differences of the parameters
and
of Algorithms 1–3 in
Table 3 and
Table 4, respectively, when
. Setting
, then we obtain the following numerical results of different parameters
.
Using the best parameter
for Algorithms 1 and 2 and
for Algorithm 3 in
Table 3 and setting
,
, we obtain the following numerical results of different parameters
.
| Algorithm 2 Modified inertial subgradient extragradient Mann Algorithm 2 |
Initialization: Select arbitrary elements , and . Iterative Steps: Construct by using the following steps: Step 1. Set , where , and compute
If , then stop. Otherwise Step 2. Compute
where satisfying and construct a half-space
Step 3. Compute
where and . Replace n with and then repeat Step 1.
|
| Algorithm 3 Modified inertial subgradient extragradient Mann Algorithm 3 |
Initialization: Select arbitrary elements , and . Iterative Steps: Construct by using the following steps: Step 1. Set , where , and compute
If , then stop. Otherwise, Step 2. Compute
where satisfy and construct a half-space
Step 3. Compute
where and . Replace n by and then repeat Step 1.
|
From
Table 4, we see that
highly improves the performance of the Algorithms 1 and 2 and
highly improves the performance of Algorithm 3. We next show the performance of our Algorithms 1–3 compared with the other existing Algorithms (
2)–(
4).
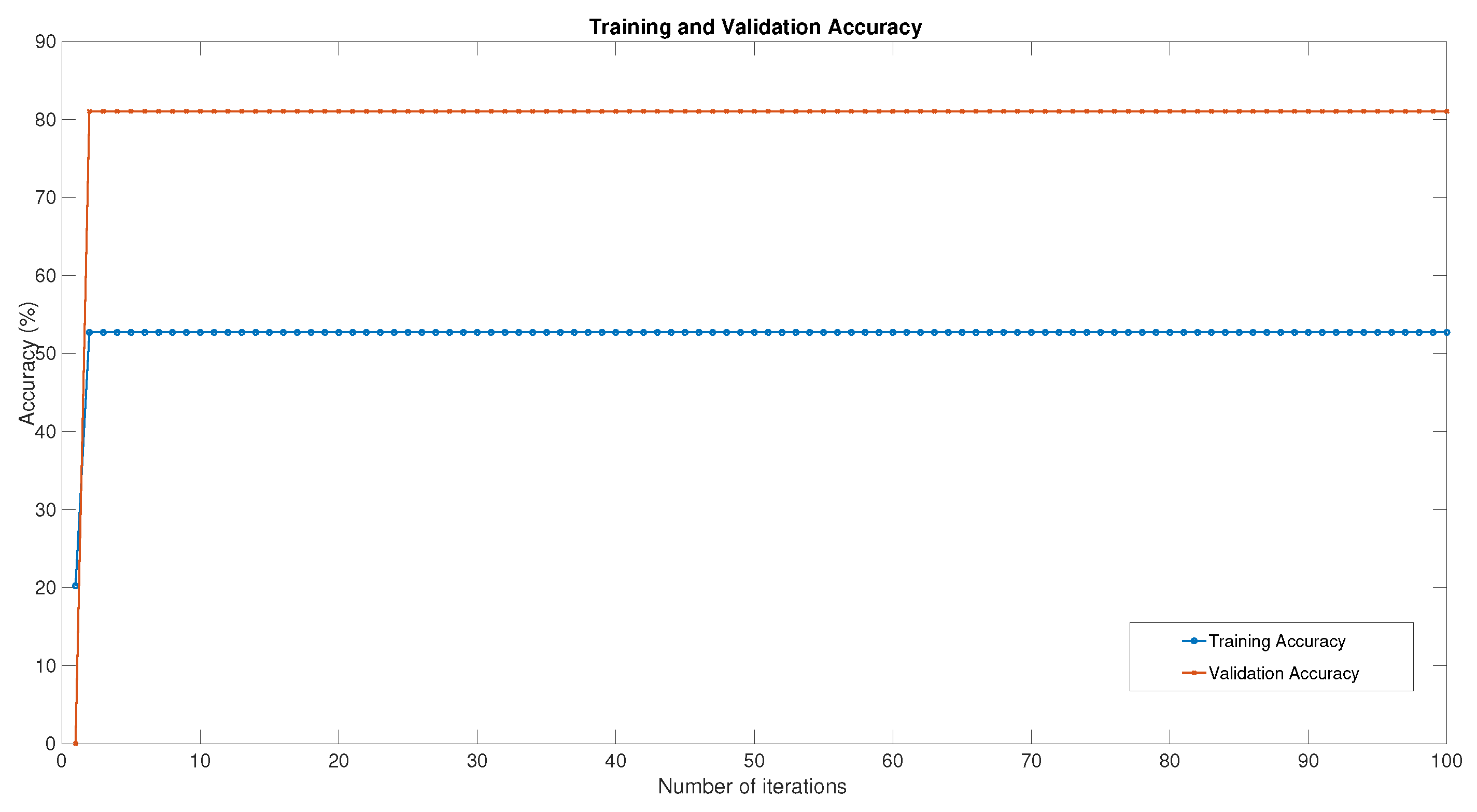
Table 5 demonstrates that our algorithm is among those with the highest precision, recall, F1-score, and accuracy efficiency. Additionally, it has the lowest number of iterations. Although it may slightly reduce training time, compared to previous examinations, it has the best probability of correctly categorizing prospective mathematics teachers’ technology-integrated competency level. Moreover, we deliver the training and validation loss with the accuracy of training to show that our algorithm has no overfitting in the training dataset.
From
Figure 1 and
Figure 2, we see that our model from Algorithm 3 with the suitable parameters in
Table 2,
Table 3 and
Table 4 obtains a good fitting model that is the measure of a machine learning model and generalizes well to similar data. Based on
Figure 1 and
Figure 2, the over fitting problem can be controlled by finding the best parameters of our algorithms to solve the least square regularization problem (
28).
We implemented an inertial subgradient extragradient method for the equilibrium problem on an educational dataset of 954 instances containing ten attributes, including major, gender, GPA, IT for learning competency, innovative skill, technology knowledge for a specific subject, number of supplementation, curriculum pattern, selective technology courses and competency level. The accuracy of classification achieved by the proposed machine learning algorithm was evaluated and 81.06% of the dataset was classified accurately with fewer iterations compared to other methods.
5. Conclusions and Discussion
This study proposes a new method based on machine learning algorithms to predict the technology-integrated competency level of prospective mathematics teachers, taking their data related to different aspects as the source data. Performances of an extragradient method for equilibrium problem were calculated and compared to predict the technology-integrated competency. This study emphasized two focuses. The first one was the prediction of competency based on the skills and knowledge developed throughout teacher education programs. The second focus was the comparison of the performances of machine learning algorithm.
The results show that the proposed method achieved a classification accuracy of 81.06%. Accordingly, it can be said that major, gender, GPA, IT for learning competency, innovative skill, technology knowledge for a specific subject, number of supplementation, curriculum pattern, and selective technology courses are significant predictors to be used for predicting their technology-integrated competency.
Even though this study focused on technology-integrated competency in mathematics classrooms, it was noticed that the major of prospective teachers was one of the predictors. Because there is a large number of prospective teachers in Thailand who may teach out of their field upon entering the profession [
29], the major of teacher education programs was also analyzed to determine if their technology-integrated competency differs when they are required to teach mathematics in the future [
30].
Comparing the results of this study to other studies on technology integration by mathematics teachers, it was discovered that gender is one of the best predictors of teachers’ intentions to implement technology in their classes [
31,
32]. In addition, general technological skills and knowledge, such as IT for learning competency and innovative skill, are without a doubt effective predictors of technology-integrated competency [
25,
33,
34]. Additionally, the integration of technology knowledge and content knowledge, also known as Technological Content Knowledge (TCK), was represented by the attribute of technology knowledge for a specific subject, which is a predictor for predicting technology-integrated competency [
25,
34,
35].
The curriculum pattern, according to the educational dataset analyzed in this study, is the new finding that distinguishes this study from others. Since Pattern 1, Pattern 2, and Pattern 3 are included in this study—the attributes of the curriculum pattern—there are three sorts of pattern. The patterns that prospective teachers study the most in courses of pedagogical knowledge, content knowledge, and technological knowledge are Pattern 1, Pattern 2, and Pattern 3, respectively. This finding indicates that when prospective teachers were trained in a variety of knowledge patterns, their technology-integrated competency also performed differently [
36,
37].
Using this approach, it is possible to anticipate future technology-integrated competency based on these findings. By projecting prospective teachers’ technology-integrated competency in the future, pre-service teachers can examine and improve their working techniques and proficiency. Given that there are about four years between teacher education programs, it is easier to comprehend the significance of the proposed strategy.
The practical achievement of this study is a curriculum revision policy for university-level mathematics education programs. Particularly, the program should offer additional TCK courses, and the redesigned curriculum should place a greater emphasis on technology knowledge for mathematics. In addition, the result specifies the concept of the required curriculum pattern in terms of weighing pedagogical knowledge, content knowledge, and technology knowledge courses.
In the comparison of performances of a machine learning algorithm with other methods, it was found that our Algorithm 3 uses fewer iterations than the existing algorithms with the same highest precision, recall, F1-score, and accuracy efficiency and has the same number of iterations compared with Algorithm 3, although it takes slightly less time to train the data. This means that we can choose to use both algorithms to work with these data.
The results demonstrate that machine learning techniques can be used to predict the technology-integrated competency of prospective mathematics teachers. The results of this study can assist educators in identifying pre-service teachers with below or above average technology integration. In addition, such data driven studies are very significant for establishing a prospective teacher competency analysis framework in teacher education and contributing to decision-making for policy design.
Future research can be undertaken by incorporating additional input attributes and machine learning methods into the modeling procedure. In addition, it is crucial to leverage the efficacy of an extra gradient method in order to analyze the learning patterns of individuals, address their issues, enhance the educational environment, and enable data driven decision-making for the policy design of teacher education in Thailand.







{kind=link}
{kind=link}