
Bayesian Inference for COVID-19 Transmission Dynamics in India Using a Modified SEIR Model
 , , and
, , and
Abstract
:1. Introduction
2. Methodology
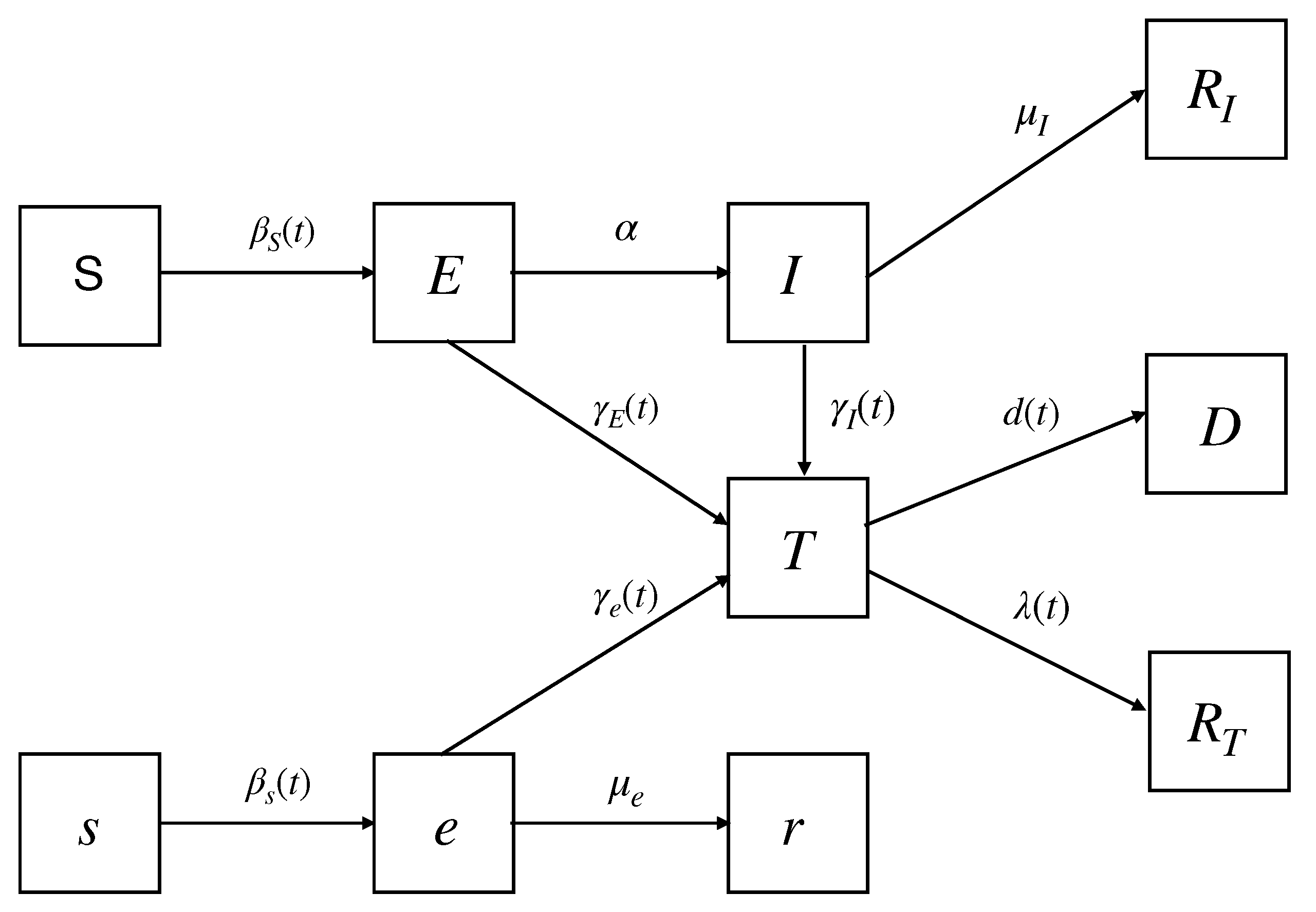
2.1. The Modified SEIR Model
2.2. Data Description
2.3. Bayesian Model Calibration
3. Numerical Results
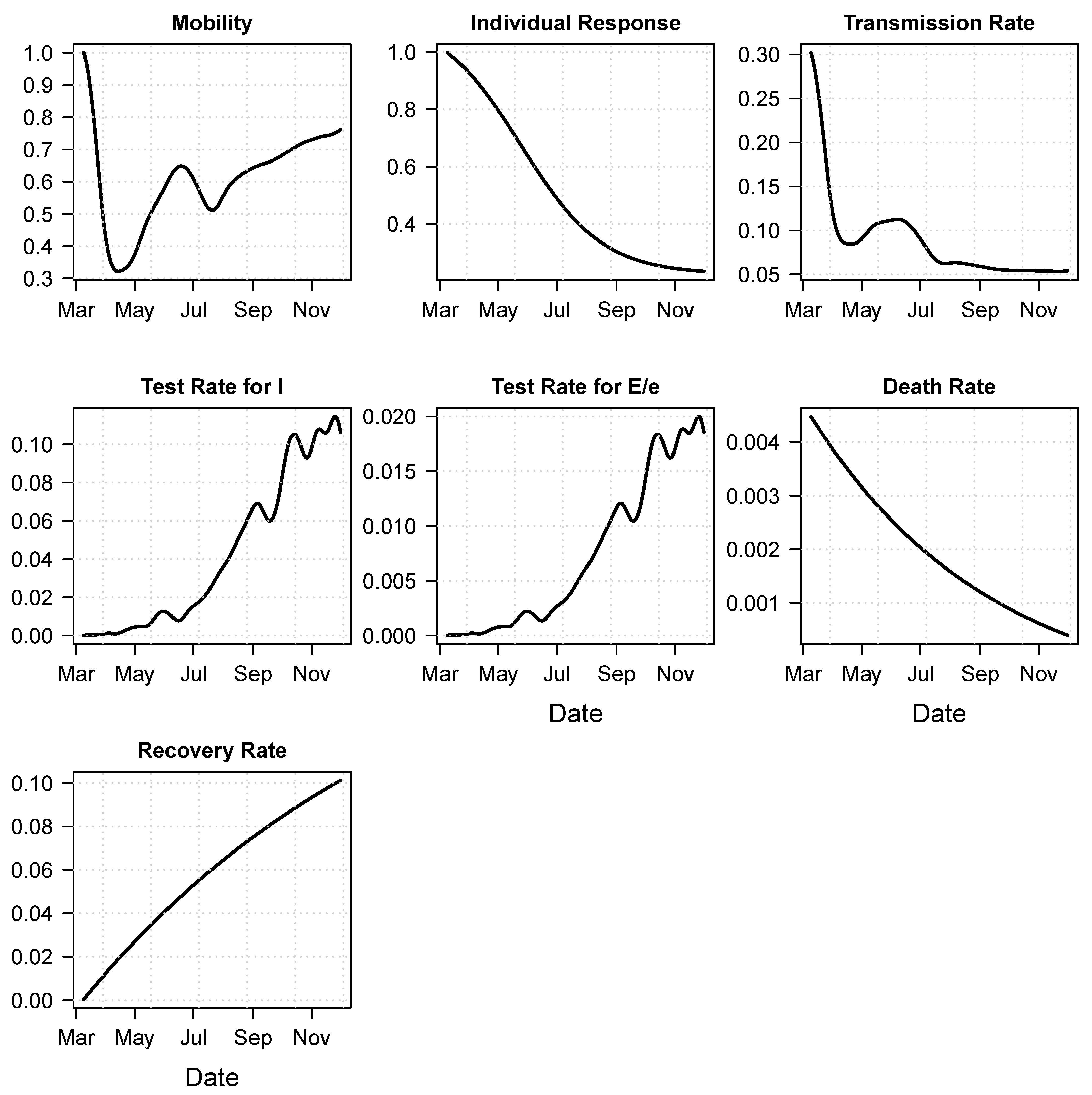
3.1. Calibration Results and Retrospective Analysis
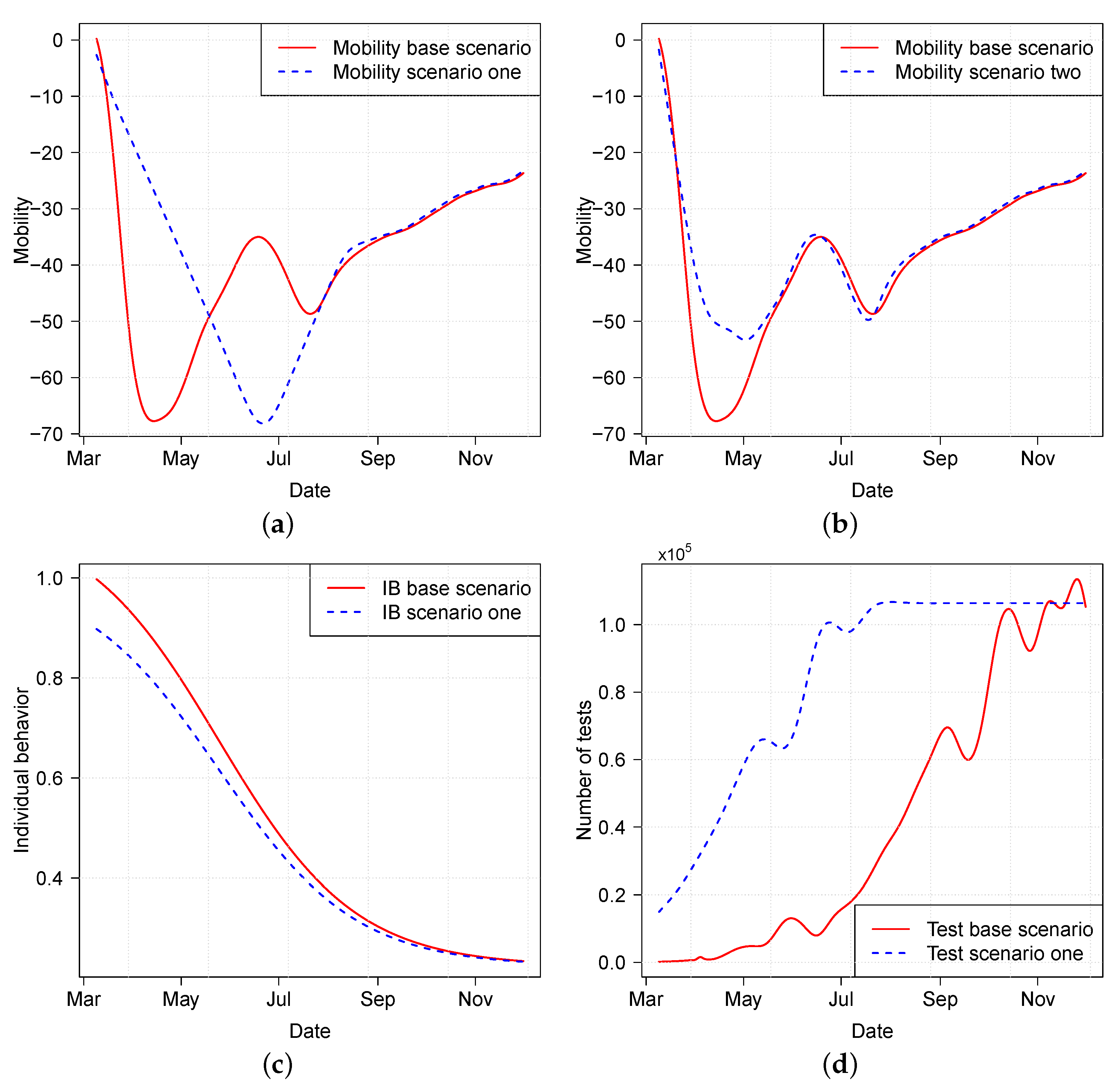
3.2. Effect of Various Intervention Policies
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. Director-General Opening Remarks at the Media Briefing on COVID-19—13 March 2020. Available online: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-mission-briefing-on-covid-19 (accessed on 18 March 2020).
- Flaxman, S.; Mishra, S.; Gandy, A.; Unwin, H.J.T.; Mellan, T.A.; Coupland, H.; Whittaker, C.; Zhu, H.; Berah, T.; Eaton, J.W.; et al. Estimating the effects of non-pharmaceutical interventions on COVID-19 in Europe. Nature 2020, 584, 257–261. [Google Scholar] [CrossRef] [PubMed]
- Pai, C.; Bhaskar, A.; Rawoot, V. Investigating the dynamics of COVID-19 pandemic in India under lockdown. Chaos Solitons Fractals 2020, 138, 109988. [Google Scholar] [CrossRef] [PubMed]
- Hellewell, J.; Abbott, S.; Gimma, A.; Bosse, N.I.; Jarvis, C.I.; Russell, T.W.; Munday, J.D.; Kucharski, A.J.; Edmunds, W.J.; Sun, F.; et al. Feasibility of controlling COVID-19 outbreaks by isolation of cases and contacts. Lancet Glob. Health 2020, 8, e488–e496. [Google Scholar] [CrossRef] [Green Version]
- Ali, S.T.; Wang, L.; Lau, E.H.; Xu, X.K.; Du, Z.; Wu, Y.; Leung, G.M.; Cowling, B.J. Serial interval of SARS-CoV-2 was shortened over time by nonpharmaceutical interventions. Science 2020, 369, 1106–1109. [Google Scholar] [CrossRef]
- Chu, D.K.; Akl, E.A.; Duda, S.; Solo, K.; Yaacoub, S.; Schünemann, H.J.; El-harakeh, A.; Bognanni, A.; Lotfi, T.; Loeb, M.; et al. Physical distancing, face masks, and eye protection to prevent person-to-person transmission of SARS-CoV-2 and COVID-19: A systematic review and meta-analysis. Lancet 2020, 395, 1973–1987. [Google Scholar] [CrossRef]
- Huang, Q.; Mondal, A.; Jiang, X.; Horn, M.A.; Fan, F.; Fu, P.; Wang, X.; Zhao, H.; Ndeffo-Mbah, M.; Gurarie, D. SARS-CoV-2 transmission and control in a hospital setting: An individual-based modelling study. R. Soc. Open Sci. 2021, 8, 201895. [Google Scholar] [CrossRef]
- Chiu, W.A.; Fischer, R.; Ndeffo-Mbah, M.L. State-level needs for social distancing and contact tracing to contain COVID-19 in the United States. Nat. Hum. Behav. 2020, 4, 1080–1090. [Google Scholar] [CrossRef]
- Godio, A.; Pace, F.; Vergnano, A. SEIR modeling of the Italian epidemic of SARS-CoV-2 using computational swarm intelligence. Int. J. Environ. Res. Public Health 2020, 17, 3535. [Google Scholar] [CrossRef]
- Picchiotti, N.; Salvioli, M.; Zanardini, E.; Missale, F. COVID-19 pandemic: A mobility-dependent SEIR model with undetected cases in Italy, Europe and US. arXiv 2020, arXiv:2005.08882. [Google Scholar]
- Chu, I.Y.H.; Alam, P.; Larson, H.J.; Lin, L. Social consequences of mass quarantine during epidemics: A systematic review with implications for the COVID-19 response. J. Travel Med. 2020, 27, taaa192. [Google Scholar] [CrossRef]
- Joshi, A. COVID-19 pandemic in India: Through psycho-social lens. J. Soc. Econ. Dev. 2021, 23, 414–437. [Google Scholar] [CrossRef] [PubMed]
- Soni, P. Effects of COVID-19 lockdown phases in India: An atmospheric perspective. Environ. Dev. Sustain. 2021, 23, 12044–12055. [Google Scholar] [CrossRef] [PubMed]
- Saikia, D.; Bora, K.; Bora, M.P. COVID-19 outbreak in India: An SEIR model-based analysis. Nonlinear Dyn. 2021, 104, 4727–4751. [Google Scholar] [CrossRef] [PubMed]
- Sarkar, K.; Khajanchi, S.; Nieto, J.J. Modeling and forecasting the COVID-19 pandemic in India. Chaos Solitons Fractals 2020, 139, 110049. [Google Scholar] [CrossRef]
- Malavika, B.; Marimuthu, S.; Joy, M.; Nadaraj, A.; Asirvatham, E.S.; Jeyaseelan, L. Forecasting COVID-19 epidemic in India and high incidence states using SIR and logistic growth models. Clin. Epidemiol. Glob. Health 2021, 9, 26–33. [Google Scholar] [CrossRef]
- Singh, B.C.; Alom, Z.; Hu, H.; Rahman, M.M.; Baowaly, M.K.; Aung, Z.; Azim, M.A.; Moni, M.A. COVID-19 Pandemic Outbreak in the Subcontinent: A Data Driven Analysis. J. Pers. Med. 2021, 11, 889. [Google Scholar] [CrossRef]
- Al-Raeei, M.; El-Daher, M.S.; Solieva, O. Applying SEIR model without vaccination for COVID-19 in case of the United States, Russia, the United Kingdom, Brazil, France, and India. Epidemiol. Methods 2021, 10, 20200036. [Google Scholar] [CrossRef]
- Poonia, R.C.; Saudagar, A.K.J.; Altameem, A.; Alkhathami, M.; Khan, M.B.; Hasanat, M.H.A. An Enhanced SEIR Model for Prediction of COVID-19 with Vaccination Effect. Life 2022, 12, 647. [Google Scholar] [CrossRef]
- Calvetti, D.; Hoover, A.; Rose, J.; Somersalo, E. Bayesian dynamical estimation of the parameters of an SE(A)IR COVID-19 spread model. arXiv 2020, arXiv:2005.04365. [Google Scholar]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis, 2nd ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2004. [Google Scholar]
- Mahajan, A.; Solanki, R.; Sivadas, N. Estimation of undetected symptomatic and asymptomatic cases of COVID-19 infection and prediction of its spread in the USA. J. Med. Virol. 2021, 93, 3202–3210. [Google Scholar] [CrossRef]
- COVID-19 Community Mobility Reports. Available online: https://www.google.com/covid19/mobility/ (accessed on 20 January 2021).
- India COVID-19 Tracker. 2020. Available online: https://www.covid19india.org/ (accessed on 20 January 2021).
- Haario, H.; Saksman, E.; Tamminen, J. An adaptive Metropolis algorithm. Bernoulli 2001, 7, 223–242. [Google Scholar] [CrossRef] [Green Version]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Soetaert, K.; Petzoldt, T.; Setzer, R.W. Solving Differential Equations in R: Package deSolve. J. Stat. Softw. 2010, 33, 1–25. [Google Scholar] [CrossRef]
- Lauer, S.A.; Grantz, K.H.; Bi, Q.; Jones, F.K.; Zheng, Q.; Meredith, H.R.; Azman, A.S.; Reich, N.G.; Lessler, J. The incubation period of coronavirus disease 2019 (COVID-19) from publicly reported confirmed cases: Estimation and application. Ann. Intern. Med. 2020, 172, 577–582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bartolomeo, N.; Trerotoli, P.; Serio, G. Short-term forecast in the early stage of the COVID-19 outbreak in Italy. Application of a weighted and cumulative average daily growth rate to an exponential decay model. Infect. Dis. Model. 2021, 6, 212–221. [Google Scholar] [CrossRef]
- Pelinovsky, E.; Kokoulina, M.; Epifanova, A.; Kurkin, A.; Kurkina, O.; Tang, M.; Macau, E.; Kirillin, M. Gompertz model in COVID-19 spreading simulation. Chaos Solitons Fractals 2022, 154, 111699. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| q | Fraction of population through symptomatic pathway |
| Initial normal transmission rate | |
| Slope rate of sigmoid function | |
| x | First reflection point of sigmoid function |
| b | Lower bound of |
| Average duration (in days) of asymptomatic | |
| Average duration (in days) of infectious period | |
| Average duration (in days) of latent period | |
| Pr(a particular person in I is tested)/Pr(a random person is tested) | |
| c | The odd ratio for an individual from compartment getting |
| tested against one from compartment I | |
| Asymptotic cure rate | |
| Slope in the cure rate function | |
| Asymptotic death rate | |
| Difference between initial death rate and the asymptotic death rate | |
| Slope in the death rate function |
| State/Parameters | q | ||||
|---|---|---|---|---|---|
| Maharashtra | 0.7314 | 0.3740 | 0.0215 | 95 | 0.1 |
| [0.6116, 0.8517] | [0.3125, 0.4355] | [0.0171, 0.0239] | [79.3739, 110.6261] | [0.1172, 0.163] | |
| Karnataka | 0.6865 | 0.3026 | 0.0235 | 77 | 0.2242 |
| [0.5756, 0.7995] | [0.2528, 0.3524] | [0.0196, 0.0274] | [64.3346, 89.6654] | [0.1873, 0.2611] | |
| Andhra Pradesh | 0.6988 | 0.2711 | 0.0112 | 70 | 0.2235 |
| [0.5853, 0.8138] | [0.2265, 0.3157] | [0.0094, 0.013] | [58.486, 81.514] | [0.1867, 0.2603] | |
| Kerala | 0.6924 | 0.1839 | 0.0104 | 69 | 0.2223 |
| [0.5802, 0.8064] | [0.1537, 0.2141] | [0.0087, 0.0121] | [57.6505, 80.3495] | [0.1857, 0.2589] | |
| West Bengal | 0.6883 | 0.4723 | 0.0647 | 41 | 0.1575 |
| [0.577, 0.8016] | [0.3946, 0.55] | [0.0541, 0.0753] | [34.2561, 47.7439] | [0.1316, 0.1834] | |
| Prior support | [0.5, 1] | [0.1, 2] | [0.001, 1] | [1, 150] | [0.1, 0.5] |
| State/Parameters | c | ||||
| Maharashtra | 21 | 7 | 39 | 0.4243 | |
| [17.5458, 24.4542] | [5.8486, 8.1514] | [32.5851, 45.4149] | [0.3545, 0.4941] | ||
| Karnataka | 23 | 6 | 70 | 0.17442 | |
| [19.2166, 26.7778] | [5.0131, 6.9869] | [58.486, 81.514] | [0.1457, 0.2031] | ||
| Andhra Pradesh | 21 | 6.5 | 69 | 0.4974 | |
| [17.5458, 24.4542] | [5.4308, 7.5692] | [57.6505, 80.3495] | [0.4156, 0.5792] | ||
| Kerala | 17 | 5 | 10 | 0.3903 | |
| [14.207, 19.7964] | [4.5953, 6.4047] | [10.0627, 11.96] | [0.3261, 0.4545] | ||
| West Bengal | 19 | 5.5 | 71 | 0.4505 | |
| [15.875, 22.1252] | [4.1776, 5.8224] | [59.3215, 82.6785] | [0.3764, 0.5246] | ||
| Prior support | [11, 31] | [2, 14] | [10, 200] | [0.001, 1] |
| Scenarios | Cumulative Infected | Cumulative Death | Peak Infected | Peak Death |
|---|---|---|---|---|
| M0PB0T0 | 883,632 | 11,219 | 10,037 | 138 |
| M1PB0T0 | 7,033,837 | 127,646 | 90,784 | 1505 |
| M1PB0T1 | 1,307,246 | 42,159 | 19,911 | 644 |
| M1PB1T0 | 1,077,677 | 15,627 | 11,445 | 162 |
| M1PB1T1 | 110,325 | 3901 | 1702 | 59 |
| M2PB0T0 | 5,163,521 | 73,859 | 67,834 | 989 |
| M2PB0T1 | 338,997 | 7731 | 4035 | 101 |
| M2PB1T0 | 558,504 | 7277 | 6163 | 87 |
| M2PB1T1 | 27,777 | 728 | 335 | 9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, K.; Mondal, A.; Ndeffo-Mbah, M.; Banerjee, P.; Huang, Q.; Gurarie, D. Bayesian Inference for COVID-19 Transmission Dynamics in India Using a Modified SEIR Model. Mathematics 2022, 10, 4037. https://doi.org/10.3390/math10214037
Yin K, Mondal A, Ndeffo-Mbah M, Banerjee P, Huang Q, Gurarie D. Bayesian Inference for COVID-19 Transmission Dynamics in India Using a Modified SEIR Model. Mathematics. 2022; 10(21):4037. https://doi.org/10.3390/math10214037
Chicago/Turabian StyleYin, Kai, Anirban Mondal, Martial Ndeffo-Mbah, Paromita Banerjee, Qimin Huang, and David Gurarie. 2022. "Bayesian Inference for COVID-19 Transmission Dynamics in India Using a Modified SEIR Model" Mathematics 10, no. 21: 4037. https://doi.org/10.3390/math10214037