5.2. Design of Primal–Dual Algorithm
The key idea of the primal–dual algorithm proposed in this paper is updating the dual variables to gradually tighten the corresponding dual constraints.
A new instance is constructed form the disk set and TD set U before calculating the feasible solution. First, we guess the disk with the largest radius in the optimal solution and use the full disk construction method in Algorithm 2 to obtain the sets and of TDs directly and indirectly served by . Then, all disks with radii larger than and all disks concentric with (including itself) are removed from , i.e., . Moreover, and are removed from the set U of TDs that are not served, i.e., , and is removed from B, i.e., . Thus, we obtain a new instance. We need to determine whether the new instance has a feasible solution (namely, whether all disks can cover all TDs in the instance and whether the total BS bandwidth capacity satisfies the task demands of all TDs in the instance). If a feasible solution exists, we perform Algorithm 3 on the new instance. For convenience, the TD set, BS set, and disk set in the new instance are still denoted by U, B, and , respectively.
In the process of constructing a feasible solution to dual program DP1, Algorithm 3 obtains the temporarily selected disk set
and the set of TDs served by these disks, allowing the primal-dual algorithm to construct a feasible solution to the primal program LP1. Initially, all TDs are not serviced, all disks are not selected, all dual variables are set to 0, and all flag variables are set to
false and used to determine updates to the dual variables. In each round of the
while loop, lines 3–15 update the dual variables. For each unserved TD
i,
needs to be updated with a step length of
l during each loop. With the repeated execution of the
while loop and the continuous updating of
,
, and
, three types of events corresponding to the three conditional statements occur (lines 16–21), namely, the BS offloading energy consumption in Constraint (8h), the disk coverage energy consumption in Constraint (8i), and the CC offloading energy consumption in Constraint (8j) are tightened. For different events, Algorithm 3 invokes the corresponding procedures. Note that in each round of the
while loop, the three types of events may or may not occur at the same time.
| Algorithm 3 Algorithm for constructing a feasible dual solution of an instance. |
- Input:
TD set U and their tasks , disk set , BS set B and their resources capacity in the instance - Output:
Temporarily selected disks set and set of TDs and they serve directly or indirectly - 1:
Initialize: , ; , ; , , , , ; , , , , , , ; , , , ; - 2:
whiledo - 3:
for each do - 4:
; // l is the step length - 5:
for each do - 6:
if then - 7:
; - 8:
if then - 9:
; - 10:
if then - 11:
; - 12:
if then - 13:
; - 14:
for each do - 15:
; - 16:
if and such that then - 17:
call Algorithm 4; - 18:
if such that then - 19:
call Algorithm 5; - 20:
if and such that then - 21:
call Algorithm 6; - 22:
return and their and .
|
Algorithms 4–6 represent a series of operations corresponding to the three types of events. When the BS offloading energy consumption in Constraint (8h) is tightened, Algorithm 4 follows two cases. (1) If the temporarily selected disk set include a disk centered at
b that covers
i, the algorithm determines whether the remaining resources of
b can satisfy the resource demands of
i. If the CPU and bandwidth requirements of
i are both met,
i is served directly by that temporarily selected disk,
and all
and
stop increasing, and the remaining resource capacity of
b is updated. If one of the resource requirements is not satisfied,
or
of the temporarily selected disks centered at
b that cover
i is increased accordingly. (2) If the temporarily selected disk set does not include a disk centered on
b that covers
i and satisfies
i’s resource requirements, the algorithm attempts to find the disk with the smallest radius centered at
b that covers
i among the unselected disks, and determine whether the remaining resources of
b satisfy the resource requirements of the unserved TDs covered by that disk. If both resource requirements are met,
of the unselected disks centered on
b, which covers
i, increases. If one of the resource requirements is not satisfied,
or
of the unselected disks centered on
b covering
i is increased accordingly.
| Algorithm 4 Algorithm for event 1 |
- 1:
ifthen - 2:
if and then - 3:
, ; - 4:
; - 5:
, , ; - 6:
, ; - 7:
if then - 8:
, ; - 9:
if then - 10:
, ; - 11:
if and then - 12:
if and then - 13:
, ; - 14:
if then - 15:
, ; - 16:
if then - 17:
, ;
|
| Algorithm 5 Algorithm for event 2 |
- 1:
; - 2:
, ; - 3:
; - 4:
, , , ; - 5:
, ;
|
| Algorithm 6 Algorithm for event 3 |
- 1:
ifthen - 2:
if then - 3:
, ; - 4:
; - 5:
, , ; - 6:
; - 7:
else - 8:
, ; - 9:
if and then - 10:
if then - 11:
, ; - 12:
else - 13:
, ;
|
When the coverage energy of the non-temporarily selected disk D in Constraint (8i) is tightened, Algorithm 5 sets D as the temporarily selected disk (line 1). Lines 2–5 classify the TDs contributing to into sets served directly or indirectly by D according to the values of and , stop increasing the of each i in and all and , and update the remaining resource capacity of BS corresponding to the temporarily selected disk D.
Algorithm 6 also considers two cases when the CC offloading energy consumption in Constraint (8j) is tightened. In this case, only the bandwidth limitation of the BSs is involved, and the algorithm process is similar to that of Algorithm 4; thus, the explanation is not repeated.
When all TDs are provisionally served, Algorithm 7 constructs the final selected disk set
according to the provisionally selected disk set
. First, the temporarily selected disks are sorted in decreasing order according to their radii, and each temporarily selected disk is examined in turn. If there is a disk
D in the final selected disk set that is concentric with the temporarily selected disk
that is being examined,
D acts as the service provider for the TDs served by
, and the algorithm examines the next temporarily selected disk; otherwise,
is marked as the final selected disk.
| Algorithm 7 Algorithm for constructing a feasible primal solution of an instance |
- Input:
Temporarily selected disk set and their and - Output:
Final selected disk set and their and - 1:
Initialize: ; - 2:
Sort all disks in in descending order according to their radii; - 3:
for each do - 4:
if and then - 5:
, ; - 6:
else - 7:
; - 8:
return and their and .
|
Finally, we obtain a feasible solution to the primal problem LP1 by merging of the instance and . After at most guesses, the scheme with the smallest objective function value is selected, which is the approximate optimal solution obtained by the primal–dual algorithm for LP1.
5.3. An Illustrative Example of the Primal–Dual Algorithm
We use the same data as in the greedy algorithm example to explain the execution of the primal–dual algorithm. In this example, at most 4 × 10 guesses are required to find the
that minimizes energy consumption. According to the experimental results presented in
Section 6, we use only a disk with a radius between the average radii of the disks selected by the optimal solution (31.3 m) and its value plus 25 m (56.3 m) as
. Therefore, 13 instances are constructed. When
is taken as
, the total energy consumption is the lowest, with a value of 5894.5 J. The following specifically describes the algorithm process when
is selected as
. First, the TDs that are directly or indirectly served by
are obtained by constructing the full disks, namely,
and
. Then, all disks centered on BS
and disks with radii greater than
are removed from the set of 40 disks, and
are removed from the 10 TDs, yielding a new instance:
,
,
,
,
,
,
,
,
,
,
,
,
. This instance has a feasible solution. In the execution of the primal–dual algorithm, events 1 and 3 occur first; thus, the dual variables
,
,
,
,
,
,
,
,
, and
start to gradually increase. Then, event 2 occurs, and the coverage energy consumption of
,
,
, and
are tightened successively. The four disks are provisionally selected and serve the TDs in
U, namely,
,
,
, and
. Among the three temporarily selected disks centered on BS
, we finally choose
, which has the largest radius. The coverage of the selected three disks
,
, and
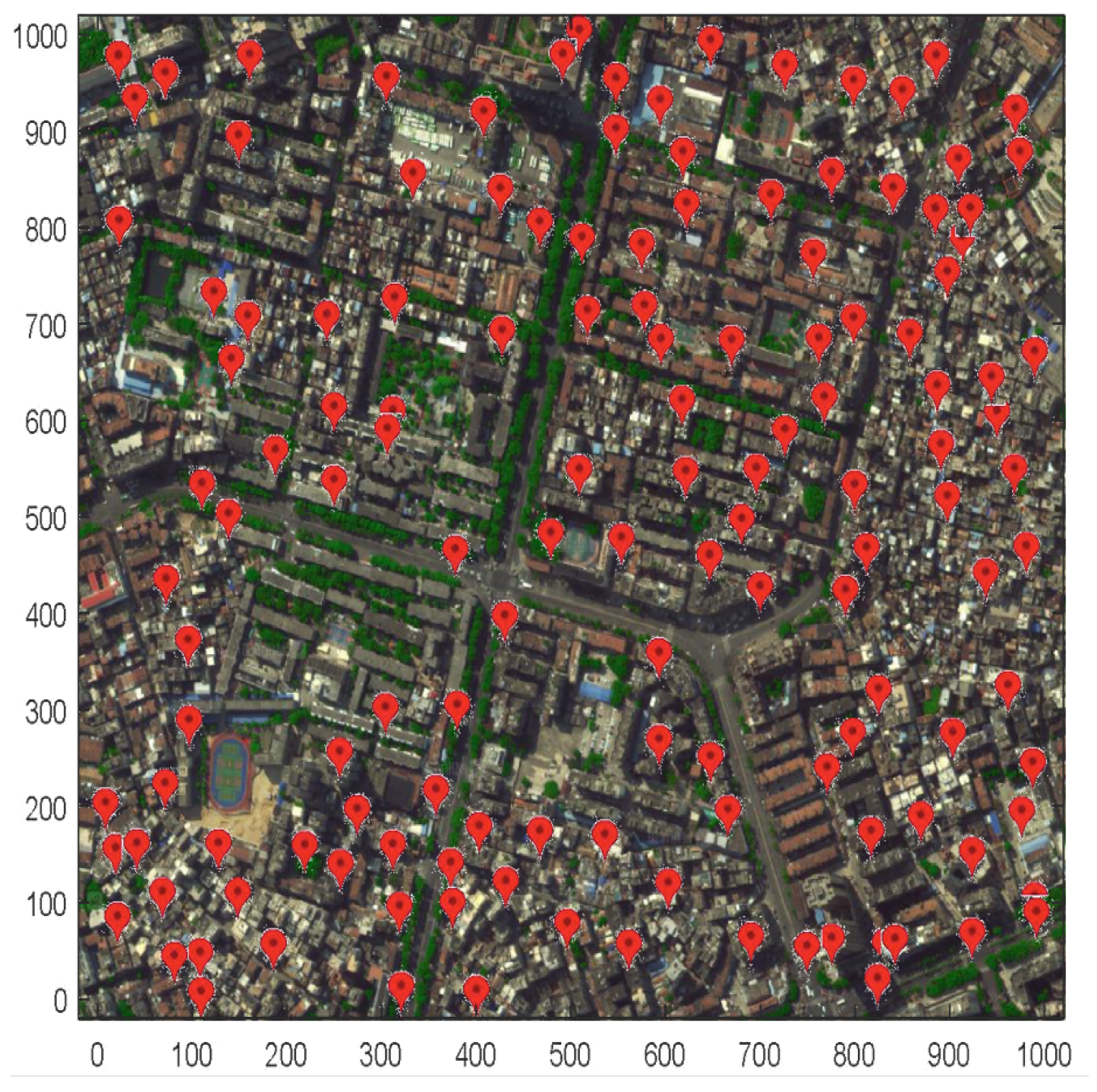
and the offloading of the TDs are shown in
Figure 4. Compared with the optimal solution and the greedy algorithm, the coverage radius of BS
is reduced, the coverage radius of BS
is increased, and TD 5’s task is directly served by BS
. Although the average radius of the selected BS increases, the coverage of the TDs is more balanced.
5.4. Analysis of Algorithm Correctness and Time Complexity
Theorem 3. The primal–dual algorithm can obtain a feasible solution for LP1 in polynomial time.
Proof. (1) Correctness. In the three events in the primal–dual algorithm, the TDs can be served directly or indirectly only when their resource demands are satisfied by BSs corresponding to the temporarily selected disk covering the TDs (lines 1–4 in Algorithm 4, lines 1–3 in Algorithm 5, and lines 1–4 in Algorithm 6). Lines 3–5 in Algorithm 7 indicate that when a disk is finally selected, the service objects of other temporarily selected disks that are concentric with this disk and have smaller radii are served by that disk. Therefore, Constraints (6b)–(6e) of LP1 hold. The feasibility judgment before Algorithm 3 and the while loop ensure that Constraint (6a) holds. Lines 3–7 in Algorithm 7 ensure that at most one concentric disk is selected; thus, Constraint (6f) holds. Therefore, the primal–dual algorithm guarantees that the constraints of LP1 are valid in this instance. In addition, the construction process of the instance shows that and the set of TDs served by it, as well as the deleted disks, also satisfy the constraints of LP1. Therefore, the primal–dual algorithm can obtain a feasible solution for LP1.
(2) Polynomial time complexity. In Algorithm 7, line 1 takes time for initialization. Line 2 takes at most time to sort all temporarily selected disks in descending order according to their radii. Lines 3–7 take at most time to obtain the final selected disk set. Therefore, the time complexity of Algorithm 7 is at most .
Next, we investigate whether Algorithm 3 can run in polynomial time. The TDs are served in the following three cases. In the first case, when event 1 occurs, there is a temporarily selected disk centered at b that covers i, and the two types of remaining resources for this disk satisfy i’s task demands (lines 1–4 in Algorithm 4). In the second case, when event 2 occurs, there are unserved TDs that contribute to the selection of D, i.e., or and (lines 1–3 in Algorithm 5). In the third case, when event 3 occurs, there is a temporarily selected disk centered at b that covers i, and its remaining bandwidth satisfies i’s task requirements (lines 1–4 in Algorithm 6). Thus, we investigate the loop rounds during which these three cases occur. Suppose that one of the above three cases is executed during the -th loop, and let and be the set of TDs served and the set of temporarily selected disks, respectively, at the end of the -th loop. Then, we examine the next loop , during which is served, and we consider three cases.
Case 1 In event 1, some TD is serviced in the next loop, denoted as . For and , if exists and and , then .
Case 2 In event 2, some TD is serviced in the next loop, denoted as . We solve the following equation related to t-th loop: , . For each , the solution to the above equation can be obtained in polynomial time when and or , where represents the disk with the smallest radius among the temporarily unselected disks centered at . Thus, can be obtained.
Case 3 In event 3, some TD is serviced in the next loop, denoted as . For and , if exists and , then . Thus, the above analysis shows that the next time is served occurs during the -th loop. , and can be obtained in polynomial time; therefore, the loop can be completed in polynomial time.
In addition, the construction of a new instance takes at most time. Thus, the primal–dual algorithm has polynomial time complexity. □






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}