

Network Alignment across Social Networks Using Multiple Embedding Techniques
 , , , and
, , , and
Abstract
:1. Introduction
- We propose a network alignment method by using a combination of multiple embedding techniques to improve the accuracy of the MAUIL model. Our method substitutes the embedding of the network structure in MAUIL with a state-of-the-art graph attention network that assigns different attention coefficients for neighborhoods at the aggregation step. By using the GAT, the learned network representation quality can be extremely enhanced and converted into more predictive embedding spaces. Unlike the GAT-based model used in [26], in this study, we combine the GAT-based embedding technique with other embedding techniques to improve the predictive performance of the embeddings and increase the efficiency of the network alignment model.
- We apply graph-drawing embedding techniques in order to embed each network in a representation space by using the known overlapping users between two networks as pivot vertices that represent the network in a common representation space without losing featured information on each network.
- We also apply fuzzy c-mean clustering as an embedding method that preserves the information of the network community, and maximization preserves the original structure of the network.
2. Related Work
3. Problem Formulation
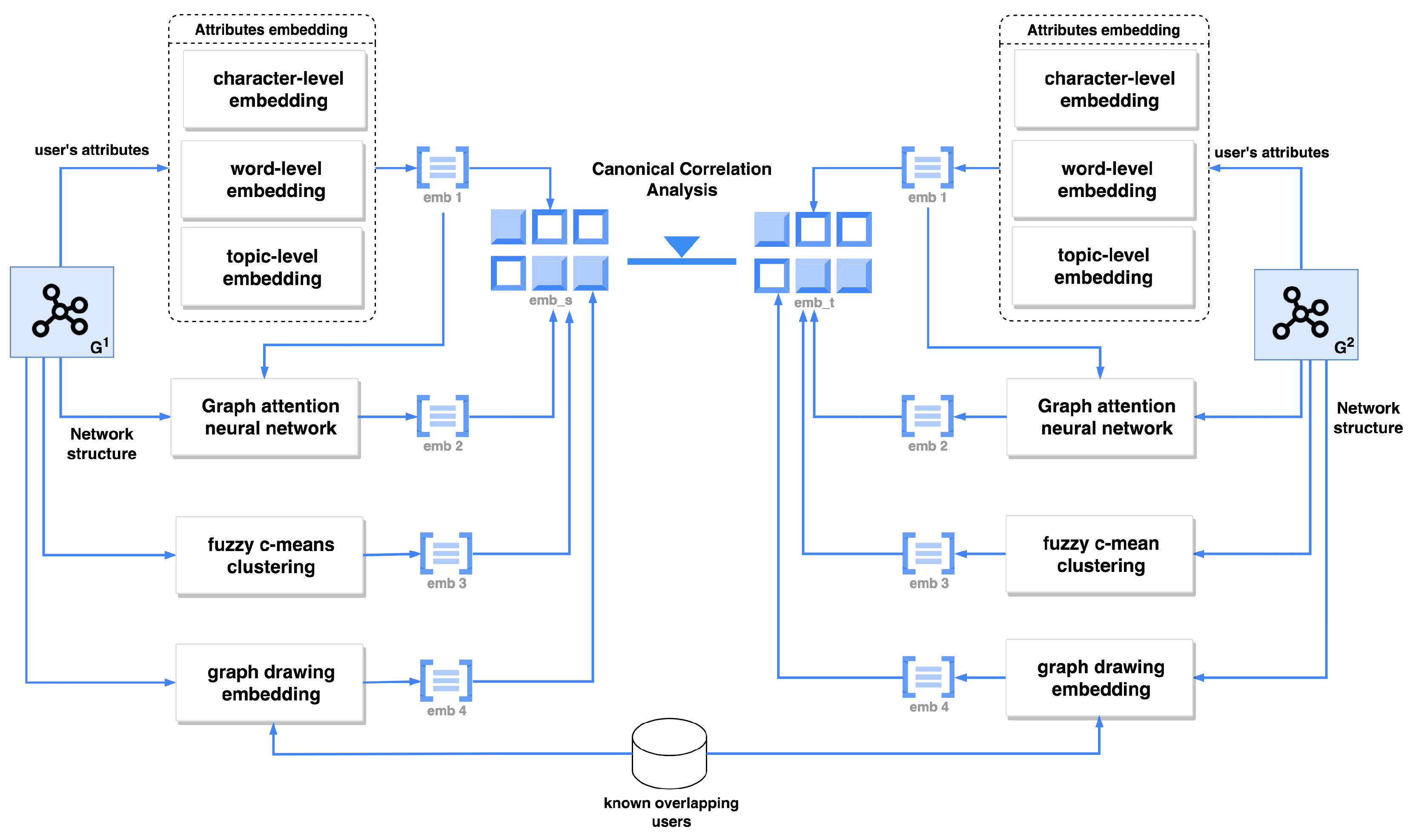
4. Proposed Method
- First, we use a three-level text-based embedding component to embed user attributes, such as the author’s username, the author’s affiliation, and the author’s publications. This process will generate the features of the vertices that represent the user profiles and the user-generated content in each network.
- Second, we feed the feature vector generated in the previous step and the network structure into the graph attention neural network to generate the second network embedding. This process takes advantage of the neighboring vertices in the aggregation step by assigning different attention coefficients to each neighbor.
- Third, we use the network structure along with known overlapping users between two networks as the input for the graph-drawing embedding technique to generate the third network embedding. This process utilizes the known alignment to represent each vertex in the network by the anchor vertices. By representing every vertex in the network based on anchor vertices, two network representations can be aligned in a common space.
- Fourth, we use fuzzy c-mean clustering to generate the fourth network embedding. This technique will enhance the embedding process by preserving the network community properties.
- Finally, we project the embedding of two networks into a common embedding space using the canonical correlation analysis technique. Then, we calculate the similarity matrix between them using the distance between two vertices in the first and second networks.
4.1. Feature Extraction
4.1.1. Character-Level Feature Extraction
4.1.2. Word-Level Feature Extraction
4.1.3. Topic-Level Feature Extraction
4.2. Graph Attention Network
4.3. Fuzzy C-Mean Clustering Technique
4.4. Graph-Drawing Embedding Technique
4.5. Canonical Correlation Analysis
5. Experiments
5.1. Datasets
- Weibo vs. Douban: This dataset was collected from two popular Chinese social networks, Weibo and Douban. First, the authors collected a list of seed users on the Douban network who had published their Weibo accounts on their profiles. These seed users on the Weibo platform and corresponding users on the Douban platform can be seen as known overlapping users between two networks in the alignment task. Second, the authors used these seed users to grow the network by crawling for user attributes, such as age, sex, address, friends, and posts.
- DBLP17 vs. DBLP19. This dataset was collected from a computer science bibliography website. In this study, the authors collected two instances of the DBLP network in two different periods. The known overlapping users between two networks were determined from the authors who had the same identity in two different instances of a network.
5.2. Evaluation Metrics
5.3. Baselines
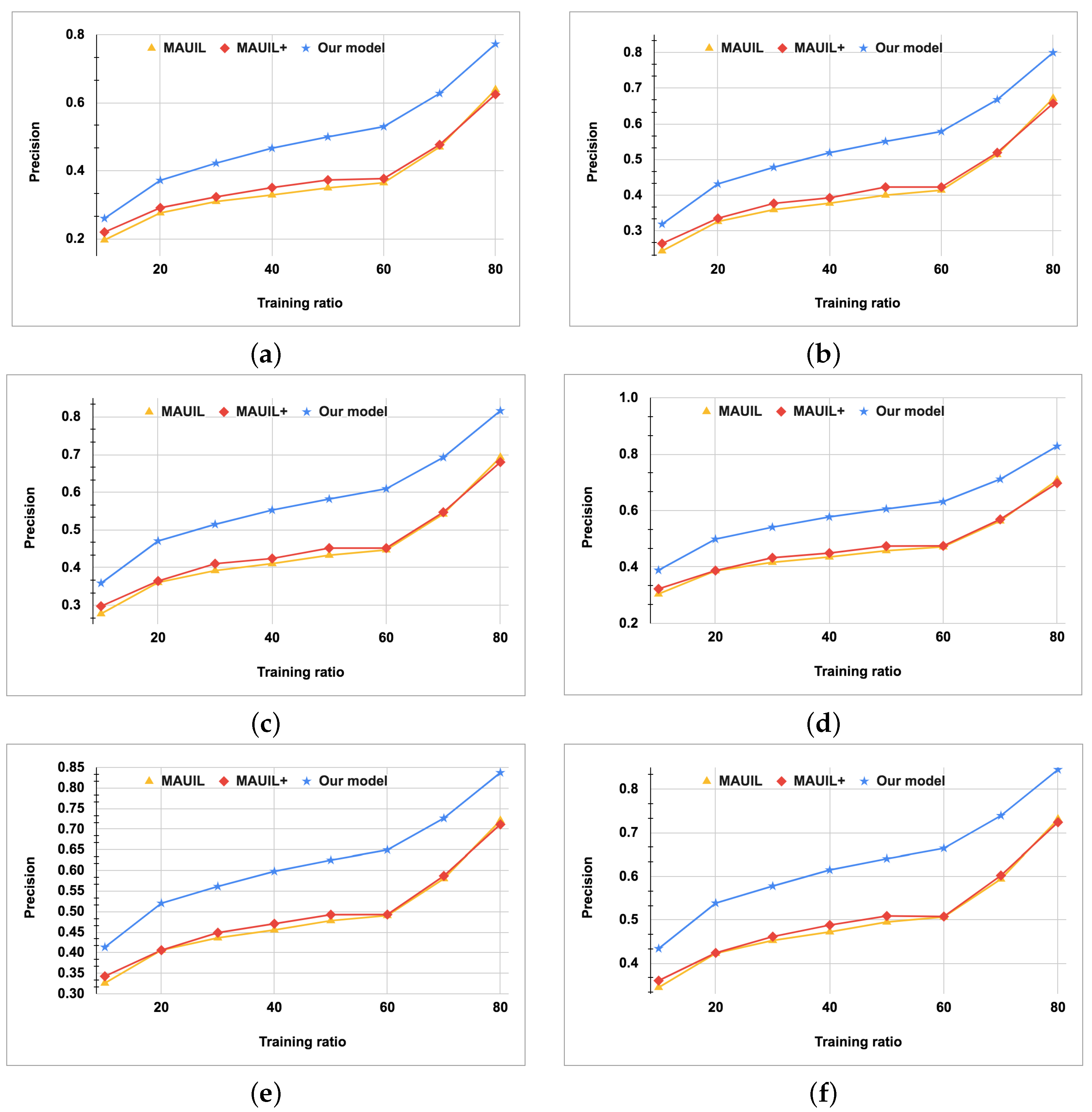
- MAUIL [27] includes three components: multilevel attribute embedding (character-level, word-level, and topic-level), network embedding, and regularized canonical correlation analysis (RCCA)-based linear projection.
- MAUIL+ [43] is an extension of the MAUIL model by substituting the LINE method [44] in MAUIL with the graph attention neural network. This method includes multilevel text-based embedding to extract user features, network structure embedding, graph attention neural network embedding, and regularized canonical correlation analysis to project the network embedding of each network into a common representation space.
- Our model is an another extension of the MAUIL model that adds more embedding layers, including the graph attention neural network, graph-drawing embedding technique, and fuzzy c-mean clustering technique.
5.4. Performance Comparison
5.5. Ablation Test
- Our-1: We combined MAUIL with only GAT-based embedding.
- Our-2: We combined MAUIL with only FCM embedding.
- Our-3: We combined MAUIL with only graph-drawing embedding.
5.6. Discussion
- Most network alignment models are based on representation learning. Generally speaking, it follows that a specific representation technique will be used to represent nodes in an information network. This technique must be optimized to preserve the maximum amount of information about the structure and properties of the network. The embeddings of these vertices are then trained by a machine learning model using known overlapping users as a training dataset to perform the alignment. Although there are many studies on the prediction of overlapping users and the achievement of a certain result, most of these works use a single representation learning technique to perform alignment, and there are very few works that have performed alignment based on a combination of multiple techniques. Each network embedding technique has its own advantages and disadvantages; our proposed method combines multiple embedding techniques to enhance their advantages and overcome their disadvantages. This combination makes our model achieve better results than those of the baseline models, as seen in the experimental section.
- The role of the GAT-based embedding technique helps remarkably enhance the quality of the final network embedding and allows the refinement of more predictable embedding spaces for subsequent fine-tuning steps. The mechanism of multi-headed self-attention in the graph attention neural network causes the output embedding of our proposed model to be better at preserving both the local and high-order neighbor structure of the information network. Thus, it can achieve better prediction results in the network alignment task.
- The role of graph drawing using a high-dimensional embedding technique helps the source and target to be represented in the same latent space by using anchor nodes/pivot nodes. By using graph-drawing embedding in our model, the quality of the generated embedding can emphasize the relationship between the source and target networks. Thus, it can achieve better prediction results in the network alignment task.
- The fuzzy c-mean clustering embedding technique helps our model to be able to exploit the global community structure of each information network. If two corresponding vertices between two networks have a similar community structure, there is a higher probability that they will form an anchor link. Therefore, the global view of network vertices based on the community structure provides a valuable source of information for increasing the accuracy of the prediction results in the network alignment task.
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LDA | Latent Dirichlet Allocation |
| GNN | Graph Neural Network |
| GCN | Graph Convolutional Network |
| GAT | Graph Attention Network |
| WD | Weibo–Douban |
| CCA | Canonical Correlation Analysis |
| RCCA | Regularized Canonical Correlation Analysis |
| FCM | Fuzzy C-Mean Clustering |
References
- Li, S.; Zhu, B.; Zhu, H.; Liu, F.; Zhang, Y.; Wang, R.; Lu, H. Heterogeneous Attention Concentration Link Prediction Algorithm for Attracting Customer Flow in Online Brand Community. IEEE Access 2022, 10, 20898–20912. [Google Scholar] [CrossRef]
- Zhang, C.; Song, D.; Huang, C.; Swami, A.; Chawla, N.V. Heterogeneous graph neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 793–803. [Google Scholar]
- Yang, C.; Zhang, J.; Han, J. Neural embedding propagation on heterogeneous networks. In Proceedings of the 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China, 8–11 November 2019; pp. 698–707. [Google Scholar]
- Ohi, A.Q.; Mridha, M.F.; Safir, F.B.; Hamid, M.A.; Monowar, M.M. Autoembedder: A semi-supervised DNN embedding system for clustering. Knowl.-Based Syst. 2020, 204, 106190. [Google Scholar] [CrossRef]
- Le, V.; Snasel, V. Community detection in online social network using graph embedding and hierarchical clustering. In Proceedings of the International Conference on Intelligent Information Technologies for Industry; Springer: Cham, Switzerland, 2018; pp. 263–272. [Google Scholar]
- Sheikh, N.; Kefato, Z.T.; Montresor, A. Semi-supervised heterogeneous information network embedding for node classification using 1d-cnn. In Proceedings of the 2018 Fifth International Conference on Social Networks Analysis, Management and Security (SNAMS), Valencia, Spain, 15–18 October 2018; pp. 177–181. [Google Scholar]
- Li, B.; Pi, D.; Lin, Y. Learning ladder neural networks for semi-supervised node classification in social network. Expert Syst. Appl. 2021, 165, 113957. [Google Scholar] [CrossRef]
- Shi, C.; Hu, B.; Zhao, W.X.; Philip, S.Y. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Zhang, Y.; Qi, L.; Yan, D.; He, Q. Outer product enhanced heterogeneous information network embedding for recommendation. Expert Syst. Appl. 2021, 169, 114359. [Google Scholar] [CrossRef]
- Carchiolo, V.; Cavallo, C.; Grassia, M.; Malgeri, M.; Mangioni, G. Link Prediction in Time Varying Social Networks. Information 2022, 13, 123. [Google Scholar] [CrossRef]
- Giubilei, R.; Brutti, P. Supervised Classification for Link Prediction in Facebook Ego Networks With Anonymized Profile Information. J. Classif. 2022, 39, 302–325. [Google Scholar] [CrossRef]
- Zhang, J.; Yu, P.S.; Zhou, Z.H. Meta-path based multi-network collective link prediction. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1286–1295. [Google Scholar]
- Shu, K.; Wang, S.; Tang, J.; Zafarani, R.; Liu, H. User identity linkage across online social networks: A review. Acm Sigkdd Explor. Newsl. 2017, 18, 5–17. [Google Scholar] [CrossRef]
- Zafarani, R.; Liu, H. Users joining multiple sites: Distributions and patterns. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 635–638. [Google Scholar]
- Mu, X.; Zhu, F.; Lim, E.P.; Xiao, J.; Wang, J.; Zhou, Z.H. User identity linkage by latent user space modelling. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1775–1784. [Google Scholar]
- Hadgu, A.T.; Gundam, J.K.R. Learn2link: Linking the social and academic profiles of researchers. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020; Volume 14, pp. 240–249. [Google Scholar]
- Riederer, C.; Kim, Y.; Chaintreau, A.; Korula, N.; Lattanzi, S. Linking users across domains with location data: Theory and validation. In Proceedings of the 25th international Conference on World Wide Web, Montreal, QC, Canada, 11–15 April 2016; pp. 707–719. [Google Scholar]
- Vosecky, J.; Hong, D.; Shen, V.Y. User identification across multiple social networks. In Proceedings of the 2009 First International Conference on Networked Digital Technologies, Ostrava, Czech Republic, 28–31 July 2009; pp. 360–365. [Google Scholar]
- Liu, J.; Zhang, F.; Song, X.; Song, Y.I.; Lin, C.Y.; Hon, H.W. What’s in a name? An unsupervised approach to link users across communities. In Proceedings of the Sixth ACM international Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 495–504. [Google Scholar]
- Zafarani, R.; Liu, H. Connecting corresponding identities across communities. In Proceedings of the International AAAI Conference on Web and Social Media, San Jose, CA, USA, 17–20 May 2009; Volume 3, pp. 354–357. [Google Scholar]
- Li, X.; Shang, Y.; Cao, Y.; Li, Y.; Tan, J.; Liu, Y. Type-aware anchor link prediction across heterogeneous networks based on graph attention network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 147–155. [Google Scholar]
- Trung, H.T.; Van Vinh, T.; Tam, N.T.; Yin, H.; Weidlich, M.; Hung, N.Q.V. Adaptive network alignment with unsupervised and multi-order convolutional networks. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 85–96. [Google Scholar]
- Man, T.; Shen, H.; Liu, S.; Jin, X.; Cheng, X. Predict anchor links across social networks via an embedding approach. Proc. IJCAI 2016, 16, 1823–1829. [Google Scholar]
- Lan, L.; Peng, H.; Tong, C.; Bai, X.; Dai, Q. Cross-Network Community Sensing for Anchor Link Prediction. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Liu, L.; Cheung, W.K.; Li, X.; Liao, L. Aligning Users across Social Networks Using Network Embedding. Proc. IJCAI 2016, 16, 1774–1780. [Google Scholar]
- Chen, B.; Chen, X.; Lu, P.; Du, Y. CAREA: Cotraining Attribute and Relation Embeddings for Cross-Lingual Entity Alignment in Knowledge Graphs. Discret. Dyn. Nat. Soc. 2020, 2020, 6831603. [Google Scholar] [CrossRef]
- Chen, B.; Chen, X. MAUIL: Multilevel attribute embedding for semisupervised user identity linkage. Inf. Sci. 2022, 593, 527–545. [Google Scholar] [CrossRef]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. STAT 2017, 1050, 20. [Google Scholar]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Harel, D.; Koren, Y. Graph drawing by high-dimensional embedding. J. Graph Algorithms Appl. 2006, 8, 195–214. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Gu, Q.; Yue, T.; Su, S. Identifying the same person across two similar social networks in a unified way: Globally and locally. Inf. Sci. 2017, 394, 53–67. [Google Scholar] [CrossRef]
- Li, X.; Cao, Y.; Li, Q.; Shang, Y.; Li, Y.; Liu, Y.; Xu, G. RLINK: Deep reinforcement learning for user identity linkage. World Wide Web 2021, 24, 85–103. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, B.; Wang, X.; Chen, H.; Li, C.; Jin, F.; Song, G.; Zhang, Y. Mego2vec: Embedding matched ego networks for user alignment across social networks. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 327–336. [Google Scholar]
- Zhou, X.; Liang, X.; Du, X.; Zhao, J. Structure based user identification across social networks. IEEE Trans. Knowl. Data Eng. 2017, 30, 1178–1191. [Google Scholar] [CrossRef]
- Heimann, M.; Shen, H.; Safavi, T.; Koutra, D. Regal: Representation learning-based graph alignment. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 117–126. [Google Scholar]
- Li, C.; Wang, S.; Yu, P.S.; Zheng, L.; Zhang, X.; Li, Z.; Liang, Y. Distribution distance minimization for unsupervised user identity linkage. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 447–456. [Google Scholar]
- Zhou, F.; Wen, Z.; Zhong, T.; Trajcevski, G.; Xu, X.; Liu, L. Unsupervised user identity linkage via graph neural networks. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Zhao, W.; Tan, S.; Guan, Z.; Zhang, B.; Gong, M.; Cao, Z.; Wang, Q. Learning to map social network users by unified manifold alignment on hypergraph. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5834–5846. [Google Scholar] [CrossRef]
- Liu, X.; Chen, Y.; Fu, J. MFRep: Joint user and employer alignment across heterogeneous social networks. Neurocomputing 2020, 414, 36–56. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Kim, D.; Seo, D.; Cho, S.; Kang, P. Multi-co-training for document classification using various document representations: TF–IDF, LDA, and Doc2Vec. Inf. Sci. 2019, 477, 15–29. [Google Scholar] [CrossRef]
- Kuang, D.; Choo, J.; Park, H. Nonnegative matrix factorization for interactive topic modeling and document clustering. In Partitional Clustering Algorithms; Springer: Berlin/Heidelberg, Germany, 2015; pp. 215–243. [Google Scholar]
- Le, V.V.; Pham, P.N.H.; Toai, T.K.; Snasel, V. An approach of anchor link prediction using graph attention mechanism. Bull. Electr. Eng. Inf. 2022, 11, 2895–2902. [Google Scholar] [CrossRef]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of Vertices | # of Edges | Min. Degree | Max. Degree | Avg. Degree | # of Anchors | |
|---|---|---|---|---|---|---|
| 9714 | 117,218 | 2 | 607 | 12.1 | 1397 | |
| Douban | 9526 | 120,245 | 2 | 608 | 12.6 | |
| DBLP17 | 9086 | 51,700 | 2 | 144 | 5.7 | 2832 |
| DBLP19 | 9325 | 47,775 | 2 | 138 | 5.1 |
| Metric | Weibo vs. Douban | DBLP-17 vs. DBLP-19 | ||||
|---|---|---|---|---|---|---|
| Our | MAUIL+ | MAUIL | Our | MAUIL+ | MAUIL | |
| Hit-precision@1 | 0.3242 | 0.2380 | 0.2310 | 0.8000 | 0.7720 | 0.7510 |
| Hit-precision@3 | 0.3861 | 0.2913 | 0.2797 | 0.8499 | 0.8060 | 0.7810 |
| Hit-precision@5 | 0.4227 | 0.3236 | 0.3099 | 0.8735 | 0.8224 | 0.7970 |
| Hit-precision@10 | 0.4784 | 0.3774 | 0.3597 | 0.9020 | 0.8412 | 0.8213 |
| Hit-precision@15 | 0.5148 | 0.4104 | 0.3920 | 0.9172 | 0.8543 | 0.8324 |
| Hit-precision@20 | 0.5411 | 0.4326 | 0.4163 | 0.9269 | 0.8636 | 0.8379 |
| Hit-precision@25 | 0.5612 | 0.4488 | 0.4361 | 0.9342 | 0.8695 | 0.8413 |
| Hit-precision@30 | 0.5779 | 0.4615 | 0.4527 | 0.9397 | 0.8747 | 0.8435 |
| Metric | Weibo vs. Douban | DBLP-17 vs. DBLP-19 | ||||||
|---|---|---|---|---|---|---|---|---|
| Our | Our-1 | Our-2 | Our-3 | Our | Our 1 | Our 2 | Our 3 | |
| Hit-precision@1 | 0.3242 | 0.2380 | 0.2352 | 0.2835 | 0.8000 | 0.7720 | 0.7612 | 0.7861 |
| Hit-precision@3 | 0.3861 | 0.2913 | 0.2867 | 0.3401 | 0.8499 | 0.8060 | 0.7891 | 0.8201 |
| Hit-precision@5 | 0.4227 | 0.3236 | 0.3188 | 0.3923 | 0.8735 | 0.8224 | 0.8073 | 0.8470 |
| Hit-precision@10 | 0.4784 | 0.3774 | 0.3705 | 0.4377 | 0.9020 | 0.8412 | 0.8275 | 0.8643 |
| Hit-precision@15 | 0.5148 | 0.4104 | 0.4042 | 0.4804 | 0.9172 | 0.8543 | 0.8397 | 0.8739 |
| Hit-precision@20 | 0.5411 | 0.4326 | 0.4301 | 0.5032 | 0.9269 | 0.8636 | 0.8490 | 0.8997 |
| Hit-precision@25 | 0.5612 | 0.4488 | 0.4410 | 0.5236 | 0.9342 | 0.8695 | 0.8517 | 0.9131 |
| Hit-precision@30 | 0.5779 | 0.4615 | 0.4587 | 0.5398 | 0.9397 | 0.8747 | 0.8603 | 0.9253 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, V.-V.; Tran, T.K.; Nguyen, B.-N.T.; Nguyen, Q.-D.; Snasel, V. Network Alignment across Social Networks Using Multiple Embedding Techniques. Mathematics 2022, 10, 3972. https://doi.org/10.3390/math10213972
Le V-V, Tran TK, Nguyen B-NT, Nguyen Q-D, Snasel V. Network Alignment across Social Networks Using Multiple Embedding Techniques. Mathematics. 2022; 10(21):3972. https://doi.org/10.3390/math10213972
Chicago/Turabian StyleLe, Van-Vang, Toai Kim Tran, Bich-Ngan T. Nguyen, Quoc-Dung Nguyen, and Vaclav Snasel. 2022. "Network Alignment across Social Networks Using Multiple Embedding Techniques" Mathematics 10, no. 21: 3972. https://doi.org/10.3390/math10213972