
OCPHN: Outfit Compatibility Prediction with Hypergraph Networks

Abstract
:1. Introduction
- To the best of our knowledge, this is the first attempt to introduce the hypergraph for outfit compatibility prediction. Compared with the existing models using sequence representation or graph representation for compatibility prediction, our model can perform more intuitive and sophisticated modeling of complex relationships.
- We propose a novel method, OCPHN, which can model multiple nodes’ interactions in the hypergraph and learn node representations better. With OCPHN, we can not only model outfit compatibility from visual features and category features but also use the attention mechanism to enhance the representation ability of our model.
- By conducting extensive experiments on a real-world dataset (Polyvore dataset), we demonstrate that our proposed model outperforms the baselines.
2. Related Work
Fashion Compatibility Modeling
3. Technical Background
3.1. Graph Neural Network
3.2. Hypergraph Learning
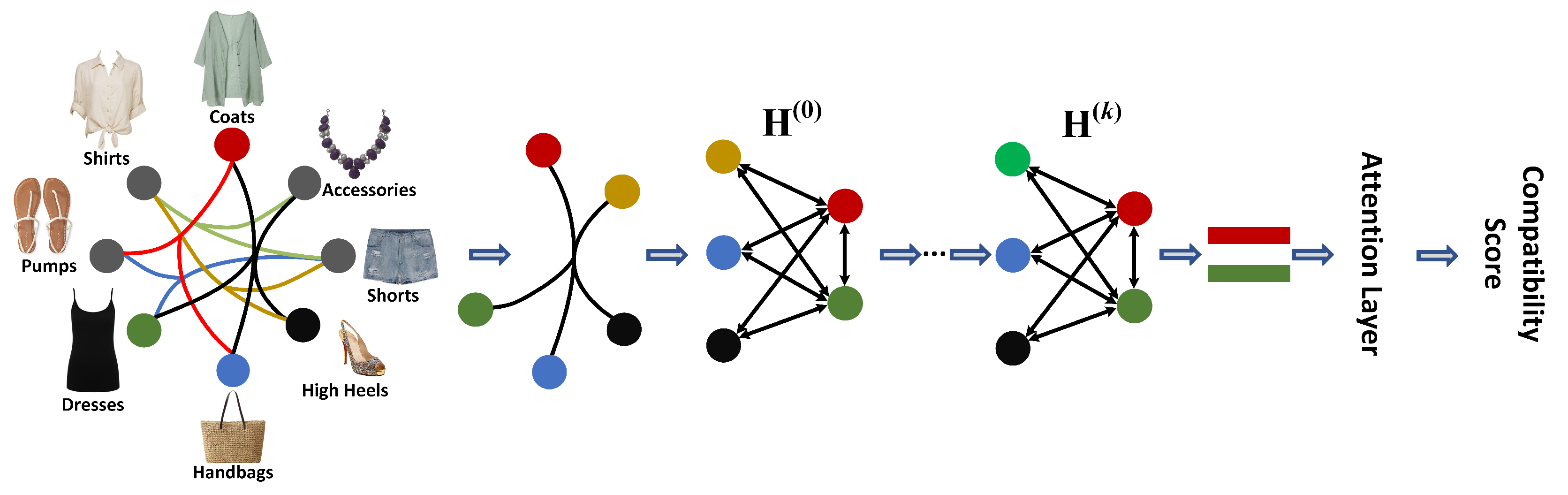
4. Proposed Method
4.1. Problem Formulation
4.2. Model Preparation
4.2.1. Feature Extraction
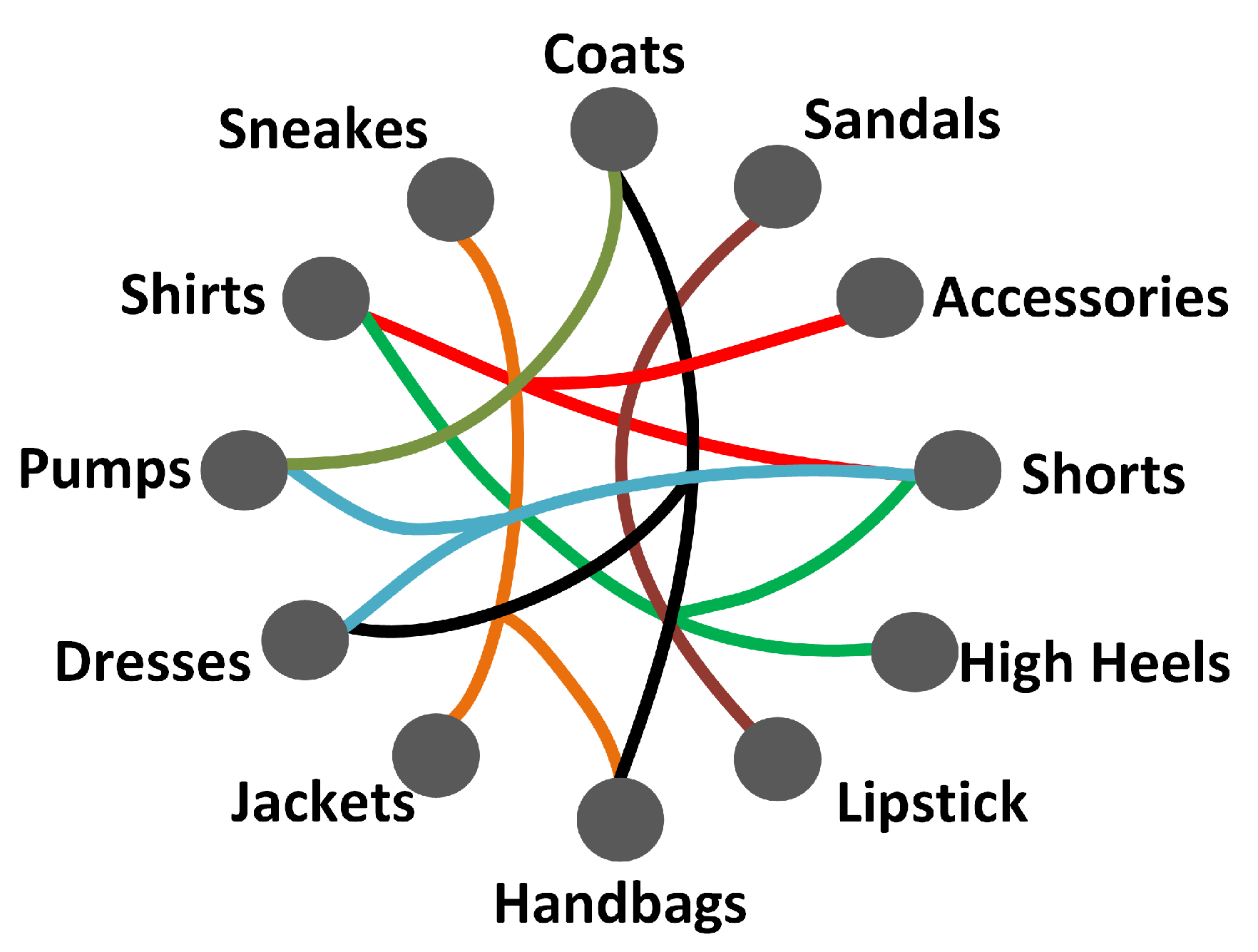
4.2.2. Hypergraph Construction
4.3. Hypergraph Convolution
4.3.1. Node Initialization
4.3.2. Converting a Hyperedge to a Graph
4.3.3. State Propagation Updates the Node Status
4.4. Model Prediction
4.5. Optimization
4.5.1. Objective Function
4.5.2. Parameter Space
5. Experiment
5.1. Dataset
5.2. Experiment Settings
5.3. Tasks
5.3.1. Fill in the Blank (FITB)
5.3.2. Compatibility Prediction
5.4. Baseline
- Random: A model based on random guesses.
- Bi-LSTM [22]: Bi-LSTM regards an outfit as an ordered sequence, and it applies a bidirectional LSTM to predict the next item and learn the outfit compatibility. The method only focuses on visual information. The experimental results are influenced by the memory limitation of the graphics card.
- VCP [26]: VCP is a method that predicts compatibility between two items based on their visual features and context. They define context as the products that are known to be compatible with each of these items. The method only focuses on visual information.
- GGNN [33]: A GGNN uses a graph neural network to model the relationships between outfits and items and calculate the outfit compatibility.
- NGNN [25]: An NGNN utilizes the category information to represent the outfit as a graph and updates the node status information through the graph conventional network and the GRU unit. An NGNN uses the attention mechanism to calculate the graph-level output as an outfit compatibility score. We only focused on the visual features of this method in our experiment.
5.5. Model Comparison
5.5.1. Performance Comparison
- FITB Accuracy: FITB is a difficult task because replacing only one part of the outfit may have little effect on the overall estimation. The comparison between our model and other alternative models in the FITB task is shown in the middle two columns of Table 2. From this table, we can make the following observations: (1) Compared with other existing methods, the performance of Bi-LSTM was poor, which demonstrates that only modeling the items as a sequence is insufficient to infer whether the outfit is compatible. (2) The performance of VCP was better than that of Bi-LSTM, although it also calculates outfit compatibility by averaging the pairwise compatibility. The improvement might be attributed to the introduced context knowledge, which verifies the importance of context information in modeling compatibility. (3) The GGNN and NGNN achieved better performance than the other methods, indicating that the graph structure can model complex interactions among items better. The results show that the graph representation can model the outfit compatibility better than sequence representation and pairwise representation. (4) It is obvious that OCPHN achieved the best performance. OCPHN is capable of modeling complex interactions among items within the same outfit thanks to the hypergraph structure and message propagation across items. Compared with other methods, we selected two key items to represent the outfit and then enhanced the key items embedding representation by aggregating the compatibility information of the neighbours. At the same time, an attention mechanism was utilized to estimate the compatibility of an outfit, which can better capture potential compatibility knowledge and further improve the performance of the model.
- Compatibility Prediction (AUC): Compatibility prediction is useful, since users may create their own outfits and wish to determine if they are compatible and trendy. The last two columns in Table 2 show the performance comparison between our model and other models in the compatibility prediction task. Similar to the FITB task, our model achieved the best performance, indicating that the introduction of a hypergraph can better reflect the relationships between outfits and items. The graph-based approaches (NGNN and GGNN) still showed good performance, indicating that graphs can indeed model relationships between nodes well. The performance of VCP with a context message was slightly worse than that of the graph representation, which shows the importance of the context message in outfit compatibility modeling. Although the Bi-LSTM model based on sequence representation can use a sequence directly to predict suite compatibility, it still performed poorly. The results observed in the compatibility prediction task can also be explained by analysis of the FITB accuracy. The performance of OCPHN demonstrated the rationality and effectiveness of hypergraph representation in the compatibility prediction task.
5.5.2. Ablation Study
5.5.3. Case Study
5.6. Study of OCPHN
5.6.1. Effect of the Style Space Dimension
5.6.2. Effect of the Propagation Layer
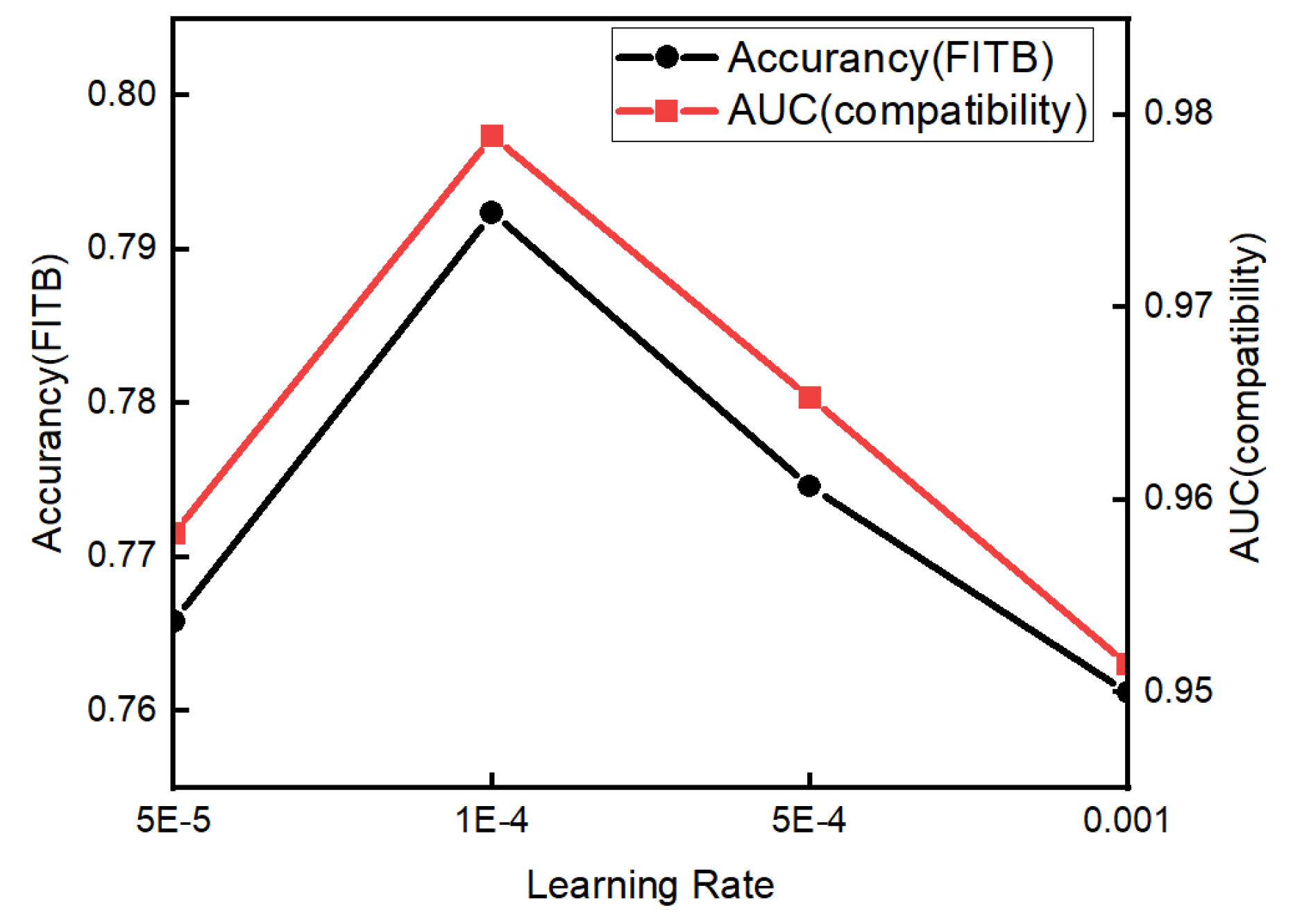
5.6.3. Effect of the Learning Rate
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kang, W.C.; Fang, C.; Wang, Z.; McAuley, J. Visually-Aware Fashion Recommendation and Design with Generative Image Models. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017. [Google Scholar]
- Feng, Z.; Yu, Z.; Yang, Y.; Jing, Y.; Jiang, J.; Song, M. Interpretable Partitioned Embedding for Customized Multi-item Fashion Outfit Composition. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018. [Google Scholar]
- Hsiao, W.L.; Grauman, K. Creating Capsule Wardrobes from Fashion Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Gu, X.; Wong, Y.; Shou, L.; Peng, P.; Chen, G.; Kankanhalli, M.S. Multi-Modal and Multi-Domain Embedding Learning for Fashion Retrieval and Analysis. IEEE Trans. Multimed. 2019, 21, 1524–1537. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, W.; Wei, Y.; Gao, Z.; Wang, Y.; Nie, L. What Aspect Do You Like: Multi-scale Time-aware User Interest Modeling for Micro-video Recommendation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Yu, X.; Gan, T.; Wei, Y.; Cheng, Z.; Nie, L. Personalized Item Recommendation for Second-hand Trading Platform. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Al-Halah, Z.; Stiefelhagen, R.; Grauman, K. Fashion Forward: Forecasting Visual Style in Fashion. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhan, H.; Lin, J.; Ak, K.E.; Shi, B.; Duan, L.Y.; Kot, A.C. A3-FKG: Attentive Attribute-Aware Fashion Knowledge Graph for Outfit Preference Prediction. IEEE Trans. Multimed. 2021, 24, 819–831. [Google Scholar] [CrossRef]
- Vasileva, M.I.; Plummer, B.A.; Dusad, K.; Rajpal, S.; Kumar, R.; Forsyth, D. Learning Type-Aware Embeddings for Fashion Compatibility. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Bell, S.; Bala, K. Learning Visual Similarity for Product Design with Convolutional Neural Networks. ACM Trans. Graph. 2015, 34, 1–10. [Google Scholar] [CrossRef]
- Song, X.; Feng, F.; Han, X.; Yang, X.; Liu, W.; Nie, L. Neural Compatibility Modeling with Attentive Knowledge Distillation. In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar]
- Jing, P.; Zhang, J.; Nie, L.; Ye, S.; Liu, J.; Su, Y. Tripartite Graph Regularized Latent Low-Rank Representation for Fashion Compatibility Prediction. IEEE Trans. Multimed. 2021, 24, 1277–1287. [Google Scholar] [CrossRef]
- Song, X.; Fang, S.T.; Chen, X.; Wei, Y.; Zhao, Z.; Nie, L. Modality-Oriented Graph Learning Toward Outfit Compatibility Modeling. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Jing, P.; Ye, S.; Nie, L.; Liu, J.; Su, Y. Low-Rank Regularized Multi-Representation Learning for Fashion Compatibility Prediction. IEEE Trans. Multimed. 2020, 22, 1555–1566. [Google Scholar] [CrossRef]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-Based Recommendations on Styles and Substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015. [Google Scholar]
- Veit, A.; Kovacs, B.; Bell, S.; McAuley, J.; Bala, K.; Belongie, S. Learning Visual Clothing Style with Heterogeneous Dyadic Co-Occurrences. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Han, X.; Song, X.; Yin, J.; Wang, Y.; Nie, L. Prototype-guided Attribute-wise Interpretable Scheme for Clothing Matching. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019. [Google Scholar]
- Shih, Y.S.; Chang, K.Y.; Lin, H.T.; Sun, M. Compatibility Family Learning for Item Recommendation and Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- He, R.; Packer, C.; McAuley, J. Learning Compatibility Across Categories for Heterogeneous Item Recommendation. In Proceedings of the IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016. [Google Scholar]
- Li, Y.; Cao, L.; Zhu, J.; Luo, J. Mining Fashion Outfit Composition Using an End-to-End Deep Learning Approach on Set Data. IEEE Trans. Multimed. 2017, 19, 1946–1955. [Google Scholar] [CrossRef] [Green Version]
- Song, X.; Feng, F.; Liu, J.; Li, Z.; Nie, L.; Ma, J. NeuroStylist: Neural Compatibility Modeling for Clothing Matching. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Han, X.; Wu, Z.; Jiang, Y.G.; Davis, L.S. Learning Fashion Compatibility with Bidirectional LSTMs. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017. [Google Scholar]
- Nakamura, T.; Goto, R. Outfit Generation and Style Extraction via Bidirectional LSTM and Autoencoder. In Proceedings of the KDD Workshop AI for fashion, London, UK, 20–25 August 2018. [Google Scholar]
- Veit, A.; Belongie, S.J.; Karaletsos, T. Conditional Similarity Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cui, Z.; Li, Z.; Wu, S.; Zhang, X.Y.; Wang, L. Dressing as a Whole: Outfit Compatibility Learning Based on Node-Wise Graph Neural Networks. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Cucurull, G.; Taslakian, P.; Vazquez, D. Context-Aware Visual Compatibility Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Hong, R.; Chua, T.S. MMGCN: Multi-Modal Graph Convolution Network for Personalized Recommendation of Micro-Video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019. [Google Scholar]
- Tao, Z.; Wei, Y.; Wang, X.; He, X.; Huang, X.; Chua, T.S. MGAT: Multimodal Graph Attention Network for Recommendation. Inf. Process. Manag. 2020, 57, 102277. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, X.; Nie, L.; He, X.; Chua, T.S. Graph-refined Convolutional Network for Multimedia Recommendation with Implicit Feedback. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A New Model for Learning in Graph Domains. In Proceedings of the International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Networks 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gallicchio, C.; Micheli, A. Graph Echo State Networks. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated Graph Sequence Neural Networks. In Proceedings of the International Conference on Learning Representations, Caribe Hilton. San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with Hypergraphs: Clustering, Classification, and Embedding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 4–9 December 2006. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph Neural Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Yadati, N.; Nimishakavi, M.; Yadav, P.; Nitin, V.; Louis, A.; Talukdar, P. HyperGCN: A New Method for Training Graph Convolutional Networks on Hypergraphs. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Jiang, J.; Wei, Y.; Feng, Y.; Cao, J.; Gao, Y. Dynamic Hypergraph Neural Networks. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Tu, K.; Cui, P.; Wang, X.; Wang, F.; Zhu, W. Structural Deep Embedding for Hyper-Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Zhang, R.; Zou, Y.; Ma, J. Hyper-SAGNN: A Self-attention Based Graph Neural Network for Hypergraphs. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the 31st International Conference on Machine Learning, Bejing, China, 22–24 June 2014. [Google Scholar]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 19–21 June 2009. [Google Scholar]
- Wei, Y.; Wang, X.; Li, Q.; Nie, L.; Li, Y.; Li, X.; Chua, T.S. Contrastive Learning for Cold-Start Recommendation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021. [Google Scholar]
- Wei, Y.; Wang, X.; He, X.; Nie, L.; Rui, Y.; Chua, T.S. Hierarchical User Intent Graph Network for Multimedia Recommendation. IEEE Trans. Multimed. 2022, 24, 2701–2712. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dateset | Training | Validation | Testing | Items | Outfits | Categories |
|---|---|---|---|---|---|---|
| Polyvore-N | 16,983 | 1294 | 2697 | 130,901 | 20,871 | 120 |
| Polyvore-N1 | 16,233 | 1239 | 2594 | 122,708 | 20,066 | 100 |
| Method | Accuracy (FITB) | AUC (Compatibility Prediction) | ||
|---|---|---|---|---|
| Polyvore-N | Polyvore-N1 | Polyvore-N | Polyvore-N1 | |
| Random | 24.97% | 25.01% | 50.24% | 50.12% |
| Bi-LSTM | 46.26% | 43.79% | 77.11% | 75.69% |
| VCP | 60.59% | 58.28% | 93.82% | 90.13% |
| GGNN | 74.19% | 73.93% | 94.77% | 95.15% |
| NGNN | 75.30% | 75.52% | 96.03% | 96.45% |
| OCPHN | 79.24% | 77.29% | 97.89% | 96.67% |
| Method | Accuracy (FITB) | AUC (Compatibility Prediction) |
|---|---|---|
| OCPHN(-W-H) | 76.71% | 96.42% |
| OCPHN(-H) | 77.01% | 96.51% |
| OCPHN(-W) | 77.31% | 96.76% |
| OCPHN | 79.24% | 97.89% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Li, J.; Wang, T.; Gong, X.; Wei, Y.; Luo, P. OCPHN: Outfit Compatibility Prediction with Hypergraph Networks. Mathematics 2022, 10, 3913. https://doi.org/10.3390/math10203913
Li Z, Li J, Wang T, Gong X, Wei Y, Luo P. OCPHN: Outfit Compatibility Prediction with Hypergraph Networks. Mathematics. 2022; 10(20):3913. https://doi.org/10.3390/math10203913
Chicago/Turabian StyleLi, Zhuo, Jian Li, Tongtong Wang, Xiaolin Gong, Yinwei Wei, and Peng Luo. 2022. "OCPHN: Outfit Compatibility Prediction with Hypergraph Networks" Mathematics 10, no. 20: 3913. https://doi.org/10.3390/math10203913