

Hyperbolic Directed Hypergraph-Based Reasoning for Multi-Hop KBQA

Abstract
:1. Introduction
- For solving the problem of sparse incidence matrices of directed hypergraphs modeled on a knowledge base, we design a method of modeling a directed hypergraph in hyperbolic space.
- Based on the hyperbolic directed hypergraph, we propose a Hyperbolic Directed Hypergraph Convolutional Network (HDH-GCN) for a directed hypergraph and design a framework on this basis that can handle multi-hop knowledge base question-answering tasks well.
- The modules constitute a new model, namely, HDH-GCN for handling the multi-hop knowledge base question-answering task. Through the experiments on several real-world datasets, we confirm the superiority of HDH-GCN over state-of-the-art models.
2. Related Work
2.1. Multi-Hop Question Answering
2.2. Hypergraph Convolutional Networks
2.3. Hyperbolic Neural Networks
3. Methods
3.1. Hyperbolic Directed Hypergraph Convolutional Networks
3.1.1. Undirected Hypergraph Convolutional Network
3.1.2. Hyperbolic Directed Hypergraph Convolutional Neural Network
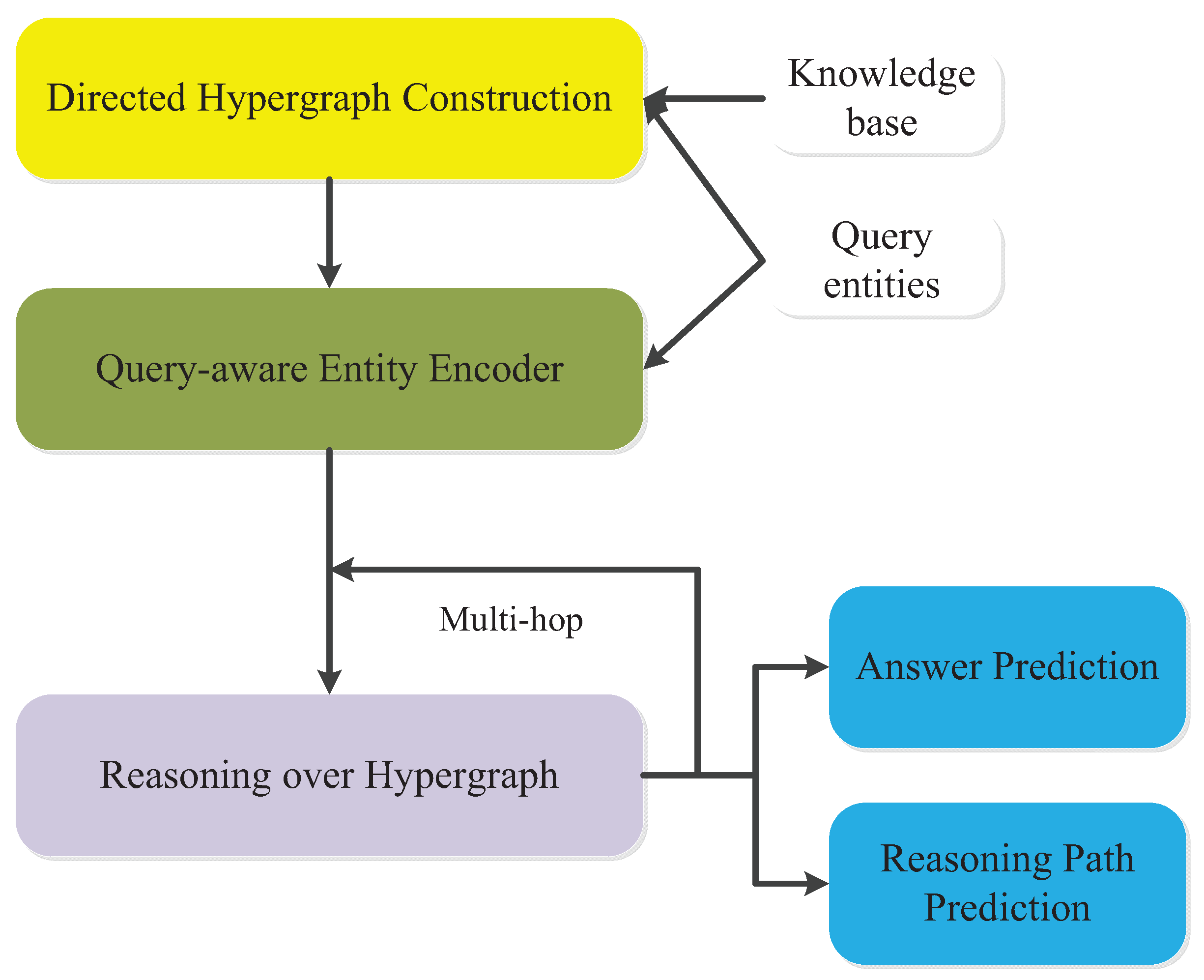
3.2. Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| H | a incidence matrix |
| a diagonal matrices of the hyperedge degrees | |
| a diagonal matrices of the vertex degrees | |
| the hypergraph Laplacian | |
| the eigenvectors of the hypergraph Laplacian | |
| ⊗ | the element-wise Hadamard product |
| a hyperboloid manifold which negative curvature is | |
| the north pole in | |
| the exponential map of the hyperboloid model | |
| the logarithmic map of the hyperboloid model | |
| hyperbolic cosine function | |
| hyperbolic sine function | |
| the aggregate matrix of the head-part of directed hyperedges | |
| the aggregate matrix of the tail-part of directed hyperedges |
3.2.1. Query-Aware Entity Encoder
3.2.2. Reasoning over Hypergraph
3.3. Training
4. Experiment
4.1. Experiment Setup
4.1.1. Datasets
- PQL-2H [48]: PQL-2H is a single answer KBQA dataset, which includes a knowledge base containing 5035 entities and 364 relationships, and a two-hop question set containing 1594 two-hop questions. These questions can be answered by following the reasoning path consisting of several relations and intermediate entities. The path has been given.
- PQL-3H [48]: PQL-3H is a single-answer KBQA dataset, which includes the same knowledge base with 5035 entities and 364 relations as PQL-2H, and a three-hop question set with 1031 three-hop questions. The characteristics of questions and the reasoning path are the same as PQL-2H.
- MetaQA-1H [49]: MetaQA-1H contains 116,045 questions for single-hop reasoning QA and the knowledge base in the dataset contains 40,128 entities and nine relations. To test QA systems in more realistic (and more difficult) scenarios, MetaQA-1H also provides neural-translation-model-paraphrased datasets, and text-to-speech-based audio datasets.
- MetaQA-2H [49]: MetaQA-2H contains 148,724 questions for two-hop reasoning and the knowledge base in the dataset contains 40,128 entities and nine relations. MetaQA-2H provides neural-translation-model-paraphrased datasets, and text-to-speech-based audio datasets just like MetaQA-1H.
4.1.2. Metrics and Parameters
4.1.3. Baselines
- KVMemNet [50]: This is an end-to-end memory network which divides the memory into two parts, the key memory stores the head entity and relation, and the value memory stores the tail entity.
- IRN [48]: This is an interpretable reasoning network, which uses a hop-by-hop reasoning process and answers questions based on knowledge maps.
- VRN [49]: An end-to-end variational learning algorithm is proposed, which can effectively solve the multi hop reasoning problem and simultaneously deal with the noise in the problem
- GraftNet [12]: Text information and entities are introduced to construct a graph, and GCN is applied to reasoning.
- SGReader [14]: This also combines the unstructured text and knowledge graph to figure out the incompleteness of the knowledge graph. The model employs graph attention to reason effectively.
- 2HR-DR [15]: This models the entities extracted from questions and their related relationships and entities in the knowledge base into directed hypergraphs, then uses Directed Hypergraph Convolutional Networks to predict relations hop-by-hop and form a sequential relation path to make the reasoning interpretable.
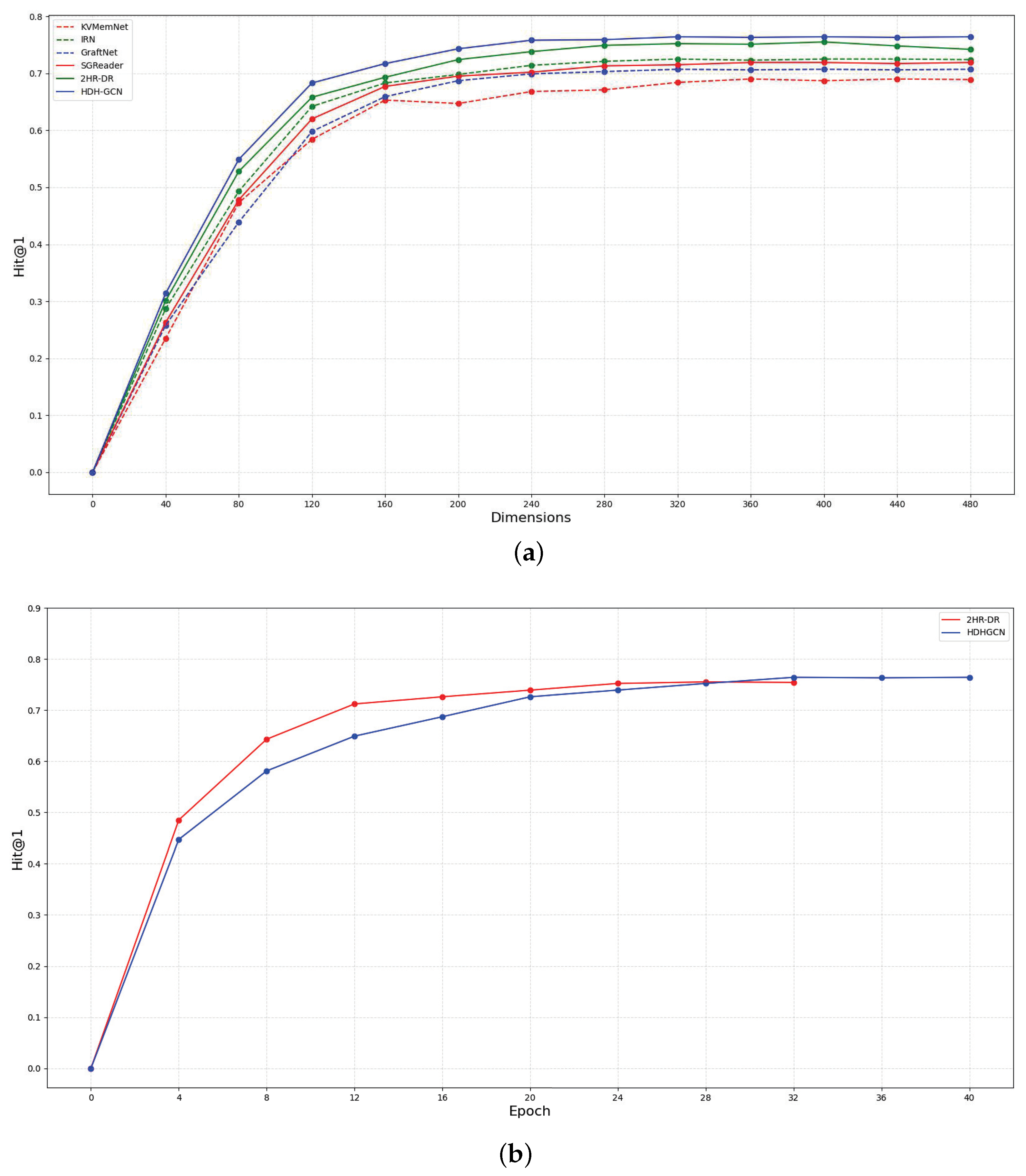
4.2. Results of Main Experiment
4.3. Parameter Analysis
4.4. Approximate Training Time Comparison
4.5. Case Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, X.; Zhang, J.; Li, D.; Li, P. Knowledge Graph Embedding Based Question Answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM 2019, Melbourne, VIC, Australia, 11–15 February 2019; Culpepper, J.S., Moffat, A., Bennett, P.N., Lerman, K., Eds.; ACM: New York, NY, USA, 2019; pp. 105–113. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, TX, USA, 1–4 November 2016; Su, J., Carreras, X., Duh, K., Eds.; The Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 2383–2392. [Google Scholar]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 2: Short Papers, pp. 784–789. [Google Scholar]
- Kociský, T.; Schwarz, J.; Blunsom, P.; Dyer, C.; Hermann, K.M.; Melis, G.; Grefenstette, E. The NarrativeQA Reading Comprehension Challenge. Trans. Assoc. Comput. Linguist. 2018, 6, 317–328. [Google Scholar] [CrossRef] [Green Version]
- Reddy, S.; Chen, D.; Manning, C.D. CoQA: A Conversational Question Answering Challenge. Trans. Assoc. Comput. Linguist. 2019, 7, 249–266. [Google Scholar] [CrossRef]
- Cao, X.; Liu, Y. Coarse-grained decomposition and fine-grained interaction for multi-hop question answering. J. Intell. Inf. Syst. 2022, 58, 21–41. [Google Scholar] [CrossRef]
- Xu, K.; Reddy, S.; Feng, Y.; Huang, S.; Zhao, D. Question Answering on Freebase via Relation Extraction and Textual Evidence. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL 2016, Berlin, Germany, 7–12 August 2016; The Association for Computer Linguistics: Stroudsburg, PA, USA, 2016; Volume 1: Long Papers. [Google Scholar]
- Lin, X.V.; Socher, R.; Xiong, C. Multi-Hop Knowledge Graph Reasoning with Reward Shaping. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 3243–3253. [Google Scholar]
- Zhou, M.; Huang, M.; Zhu, X. An Interpretable Reasoning Network for Multi-Relation Question Answering. In Proceedings of the 27th International Conference on Computational Linguistics, COLING 2018, Santa Fe, NM, USA, 20–26 August 2018; Bender, E.M., Derczynski, L., Isabelle, P., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 2010–2022. [Google Scholar]
- Xu, K.; Lai, Y.; Feng, Y.; Wang, Z. Enhancing Key-Value Memory Neural Networks for Knowledge Based Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 2937–2947. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W.W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Riloff, E., Chiang, D., Hockenmaier, J., Tsujii, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 4231–4242. [Google Scholar]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the Semantic Web—15th International Conference, ESWC 2018, Heraklion, Greece, 3–7 June 2018; Gangemi, A., Navigli, R., Vidal, M., Hitzler, P., Troncy, R., Hollink, L., Tordai, A., Alam, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2018; Volume 10843, pp. 593–607. [Google Scholar]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. Improving Question Answering over Incomplete KBs with Knowledge-Aware Reader. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1: Long Papers, pp. 4258–4264. [Google Scholar]
- Han, J.; Cheng, B.; Wang, X. Two-Phase Hypergraph Based Reasoning with Dynamic Relations for Multi-Hop KBQA. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, Yokohama, Japan, 11–17 July 2020; Bessiere, C., Ed.; pp. 3615–3621. [Google Scholar]
- Zhang, S.; Chen, H.; Ming, X.; Cui, L.; Yin, H.; Xu, G. Where are we in embedding spaces? A Comprehensive Analysis on Network Embedding Approaches for Recommender Systems. arXiv 2021, arXiv:2105.08908. [Google Scholar]
- Chami, I.; Ying, Z.; Ré, C.; Leskovec, J. Hyperbolic Graph Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; 2019; pp. 4869–4880. [Google Scholar]
- Bordes, A.; Weston, J.; Usunier, N. Open Question Answering with Weakly Supervised Embedding Models. In Proceedings of the Machine Learning and Knowledge Discovery in Databases—European Conference, ECML PKDD 2014, Nancy, France, 15–19 September 2014; Part I; Lecture Notes in Computer Science. Calders, T., Esposito, F., Hüllermeier, E., Meo, R., Eds.; Springer: Berlin, Germany, 2014; Volume 8724, pp. 165–180. [Google Scholar]
- Hao, Y.; Zhang, Y.; Liu, K.; He, S.; Liu, Z.; Wu, H.; Zhao, J. An End-to-End Model for Question Answering over Knowledge Base with Cross-Attention Combining Global Knowledge. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, BC, Canada, 30 July–4 August 2017; Barzilay, R., Kan, M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; Volume 1: Long Papers, pp. 221–231. [Google Scholar]
- Min, S.; Zhong, V.; Socher, R.; Xiong, C. Efficient and Robust Question Answering from Minimal Context over Documents. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; Volume 1: Long Papers, pp. 1725–1735. [Google Scholar]
- Zhong, V.; Xiong, C.; Keskar, N.S.; Socher, R. Coarse-grain Fine-grain Coattention Network for Multi-evidence Question Answering. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kundu, S.; Khot, T.; Sabharwal, A.; Clark, P. Exploiting Explicit Paths for Multi-hop Reading Comprehension. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1: Long Papers, pp. 2737–2747. [Google Scholar]
- Jiang, Y.; Joshi, N.; Chen, Y.; Bansal, M. Explore, Propose, and Assemble: An Interpretable Model for Multi-Hop Reading Comprehension. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1: Long Papers, pp. 2714–2725. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W.W. PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2380–2390. [Google Scholar]
- Tu, M.; Wang, G.; Huang, J.; Tang, Y.; He, X.; Zhou, B. Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1: Long Papers, pp. 2704–2713. [Google Scholar]
- Cao, Y.; Fang, M.; Tao, D. BAG: Bi-directional Attention Entity Graph Convolutional Network for Multi-hop Reasoning Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 357–362. [Google Scholar]
- Tu, M.; Huang, K.; Wang, G.; Huang, J.; He, X.; Zhou, B. Select, Answer and Explain: Interpretable Multi-Hop Reading Comprehension over Multiple Documents. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Menlo Park, CA, USA, 2020; pp. 9073–9080. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1 (Long and Short Papers), pp. 4171–4186. [Google Scholar]
- Bhargav, G.P.S.; Glass, M.R.; Garg, D.; Shevade, S.K.; Dana, S.; Khandelwal, D.; Subramaniam, L.V.; Gliozzo, A. Translucent Answer Predictions in Multi-Hop Reading Comprehension. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; AAAI Press: Menlo Park, CA, USA, 2020; pp. 7700–7707. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph Neural Networks. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Menlo Park, CA, USA, 2019; pp. 3558–3565. [Google Scholar]
- Bai, S.; Zhang, F.; Torr, P.H.S. Hypergraph convolution and hypergraph attention. Pattern Recognit. 2021, 110, 107637. [Google Scholar] [CrossRef]
- Yadati, N.; Nimishakavi, M.; Yadav, P.; Nitin, V.; Louis, A.; Talukdar, P.P. HyperGCN: A New Method For Training Graph Convolutional Networks on Hypergraphs. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; 2019; pp. 1509–1520. [Google Scholar]
- Zhang, R.; Zou, Y.; Ma, J. Hyper-SAGNN: A self-attention based graph neural network for hypergraphs. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Adcock, A.B.; Sullivan, B.D.; Mahoney, M.W. Tree-Like Structure in Large Social and Information Networks. In Proceedings of the 2013 IEEE 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; Xiong, H., Karypis, G., Thuraisingham, B., Cook, D.J., Wu, X., Eds.; IEEE Computer Society: Washington, DC, USA, 2013; pp. 1–10. [Google Scholar]
- Chen, W.; Fang, W.; Hu, G.; Mahoney, M.W. On the Hyperbolicity of Small-World and Treelike Random Graphs. Internet Math. 2013, 9, 434–491. [Google Scholar] [CrossRef] [Green Version]
- Krioukov, D.V.; Papadopoulos, F.; Kitsak, M.; Vahdat, A.; Boguñá, M. Hyperbolic Geometry of Complex Networks. arXiv 2010, arXiv:1006.5169. [Google Scholar] [CrossRef] [PubMed]
- Nickel, M.; Kiela, D. Poincaré Embeddings for Learning Hierarchical Representations. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; 2017; pp. 6338–6347. [Google Scholar]
- Vinh, T.D.Q.; Tay, Y.; Zhang, S.; Cong, G.; Li, X. Hyperbolic Recommender Systems. arXiv 2018, arXiv:1809.01703. [Google Scholar]
- Tran, L.V.; Tay, Y.; Zhang, S.; Cong, G.; Li, X. HyperML: A Boosting Metric Learning Approach in Hyperbolic Space for Recommender Systems. In Proceedings of the WSDM ’20: The Thirteenth ACM International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; Caverlee, J., Hu, X.B., Lalmas, M., Wang, W., Eds.; ACM: New York, NY, USA, 2020; pp. 609–617. [Google Scholar]
- Ganea, O.; Bécigneul, G.; Hofmann, T. Hyperbolic Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; 2018; pp. 5350–5360. [Google Scholar]
- Liu, Q.; Nickel, M.; Kiela, D. Hyperbolic Graph Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; 2019; pp. 8228–8239. [Google Scholar]
- Chamberlain, B.P.; Hardwick, S.R.; Wardrope, D.R.; Dzogang, F.; Daolio, F.; Vargas, S. Scalable Hyperbolic Recommender Systems. arXiv 2019, arXiv:1902.08648. [Google Scholar]
- Wang, X.; Zhang, Y.; Shi, C. Hyperbolic Heterogeneous Information Network Embedding. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Menlo Park, CA, USA, 2019; pp. 5337–5344. [Google Scholar]
- Feng, S.; Tran, L.V.; Cong, G.; Chen, L.; Li, J.; Li, F. HME: A Hyperbolic Metric Embedding Approach for Next-POI Recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, 25–30 July 2020; Huang, J.X., Chang, Y., Cheng, X., Kamps, J., Murdock, V., Wen, J., Liu, Y., Eds.; ACM: New York, NY, USA, 2020; pp. 1429–1438. [Google Scholar]
- Papadis, N.; Stai, E.; Karyotis, V. A path-based recommendations approach for online systems via hyperbolic network embedding. In Proceedings of the 2017 IEEE Symposium on Computers and Communications, ISCC 2017, Heraklion, Greece, 3–6 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 973–980. [Google Scholar]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with Hypergraphs: Clustering, Classification, and Embedding. In Proceedings of the Advances in Neural Information Processing Systems 19, Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 4–7 December 2006; Schölkopf, B., Platt, J.C., Hofmann, T., Eds.; MIT Press: Cambridge, MA, USA, 2006; pp. 1601–1608. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; A meeting of SIGDAT, a Special Interest Group of the ACL. Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL, 2014; pp. 1724–1734. [Google Scholar]
- Zhou, M.; Huang, M.; Zhu, X. An Interpretable Reasoning Network for Multi-Relation Question Answering. In Proceedings of the 27th International Conference on Computational Linguistics (COLING), Santa Fe, NM, USA, 20–26 August 2018; pp. 2010–2022. [Google Scholar]
- Zhang, Y.; Dai, H.; Kozareva, Z.; Smola, A.J.; Song, L. Variational Reasoning for Question Answering With Knowledge Graph. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th Innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, LA, USA, 2–7 February 2018; McIlraith, S.A., Weinberger, K.Q., Eds.; AAAI Press: Menlo Park, CA, USA, 2018; pp. 6069–6076. [Google Scholar]
- Miller, A.H.; Fisch, A.; Dodge, J.; Karimi, A.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, TX, USA, 1–4 November 2016; Su, J., Carreras, X., Duh, K., Eds.; The Association for Computational Linguistics: Stroudsburg, PA, US, 2016; pp. 1400–1409. [Google Scholar]




| Datasets | PQL-2H | PQL-3H | MetaQA-1H | MetaQA-2H |
|---|---|---|---|---|
| Number of Questions | 1594 | 1031 | 116,049 | 148,724 |
| Number of Entities in knowledge base | 5034 | 5034 | 40,128 | 40,128 |
| Number of Relations in knowledge base | 364 | 364 | 9 | 9 |
| Model | PQL-2H | PQL-3H |
|---|---|---|
| KVMemNet | 0.690 | 0.617 |
| IRN | 0.725 | 0.710 |
| GraftNet | 0.707 | 0.910 |
| SGReader | 0.719 | 0.893 |
| 2HR-DR | 0.755 | 0.921 |
| HDH-GCN | 0.764 | 0.933 |
| Model | MetaQA-1H | MetaQA-2H | ||
|---|---|---|---|---|
| Hit@1 | F1 | Hit@1 | F1 | |
| KVMemNet | 0.958 | - | 0.251 | - |
| VRN | 0.975 | - | 0.898 | - |
| GraftNet | 0.970 | 0.910 | 0.948 | 0.727 |
| SGReader | 0.967 | 0.960 | 0.807 | 0.798 |
| 2HR-DR | 0.988 | 0.973 | 0.937 | 0.814 |
| HDH-GCN | 0.990 | 0.968 | 0.951 | 0.822 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, G.; Liao, J.; Tan, Z.; Yu, Y.; Ge, B. Hyperbolic Directed Hypergraph-Based Reasoning for Multi-Hop KBQA. Mathematics 2022, 10, 3905. https://doi.org/10.3390/math10203905
Xiao G, Liao J, Tan Z, Yu Y, Ge B. Hyperbolic Directed Hypergraph-Based Reasoning for Multi-Hop KBQA. Mathematics. 2022; 10(20):3905. https://doi.org/10.3390/math10203905
Chicago/Turabian StyleXiao, Guanchen, Jinzhi Liao, Zhen Tan, Yiqi Yu, and Bin Ge. 2022. "Hyperbolic Directed Hypergraph-Based Reasoning for Multi-Hop KBQA" Mathematics 10, no. 20: 3905. https://doi.org/10.3390/math10203905